【必藏】零基础玩转大模型:Hugging Face Transformers微调实战指南
文章详细介绍了如何使用Hugging Face Transformers库微调预训练模型,以问答任务为例,从基础概念到实战操作。内容涵盖模型架构、Tokenizer使用、数据预处理、训练配置及效果验证,并提供了处理长文本的高级技巧。通过实际案例展示了微调前后的效果对比,帮助读者掌握将通用大模型适配特定业务场景的方法,适合对大模型感兴趣的开发者学习参考。
文章详细介绍了如何使用Hugging Face Transformers库微调预训练模型,以问答任务为例,从基础概念到实战操作。内容涵盖模型架构、Tokenizer使用、数据预处理、训练配置及效果验证,并提供了处理长文本的高级技巧。通过实际案例展示了微调前后的效果对比,帮助读者掌握将通用大模型适配特定业务场景的方法,适合对大模型感兴趣的开发者学习参考。
在自然语言处理(NLP)的浪潮中,大型预训练模型(如 BERT、GPT 等)已成为驱动各类应用的核心引擎。然而,如何让这些通用模型更好地适应我们特定的业务场景?答案便是微调(Fine-tuning)。Hugging Face 推出的 Transformers 库,凭借其无与伦比的易用性和丰富的模型生态,极大地降低了微调的技术门槛。
本文不满足于对 API 的浅尝辄止,而是希望为您提供一份兼具深度与可操作性的“食谱”。读完本文,您将不仅能成功运行代码,更能洞悉其背后的“为什么”,并具备独立解决实际问题的能力。
很多同学可能对模型的认知停留在应用层,本文意在让大家能够有一些针对模型的认知,以及训练一个模型究竟需要分为多少步骤?
基础概念
在动手编码之前,我们有必要先花些时间理解 Transformers 的核心设计哲学。这能帮助我们在遇到问题时,不仅知其然,更能知其所以然。
Transformers 模型
Transformers 模型通常规模庞大。包含数以百万计到数千万计数十亿的参数,训练和部署这些模型是一项复杂的任务。再者,新模型的推出几乎日新月异,而每种模型都有其独特的实现方式,尝试全部模型绝非易事。
Transformers 库应运而生,就是为了解决这个问题。它的目标是提供一个统一的 API 接口,通过它可以加载、训练和保存任何 Transformer 模型。
Transformers 模型用于解决各种 NLP 问题,如
feature-extraction(获取文本的向量表示)fill-mask(完形填空)ner(命名实体识别)question-answering(问答)sentiment-analysis(情感分析)summarization(提取摘要)text-generation(文本生成)translation(翻译)zero-shot-classification(零样本分类)
Transformers 模型主要分为 2 层 :编码器和 解码器,我们可以将其简单理解为 输入 -> 输出
编码器和解码器
- 编码器 (Encoder): 专职“理解”。它负责将输入文本(如一个句子)转换成富含语义信息的数字表示。非常适合做文本分类、命名实体识别等任务。代表选手:BERT、RoBERTa。
- 解码器 (Decoder): 专职“生成”。它能根据一个初始指令(Prompt),逐字逐句地创造出新的文本。我们熟知的 GPT 系列就是典型的解码器架构。
- 编码器-解码器 (Encoder-Decoder): “理解”与“生成”的结合体。先用编码器消化输入文本,再用解码器产出目标文本。是翻译、摘要等任务的标配。代表选手:BART、T5。
| 模型 | 示例 | 任务 |
|---|---|---|
| 编码器 | BERT, DistilBERT, ELECTRA, RoBERTa | 句子分类、命名实体识别、抽取式问答 (从文本中提取答案) |
| 解码器 | CTRL, GPT, GPT-2, Transformer XL | 文本生成 |
| 编码器-解码器 | BART, T5, Marian, mBART | 文本摘要、翻译、生成式问答 (生成问题的回答类似 chatgpt) |
架构和检查点(Checkpoints)
- 架构:这是模型的骨架 —— 即每个层的定义以及模型中发生的每个操作。
- Checkpoints(检查点):这些是将在给架构中结构中加载的权重参数,是一些具体的数值。
举个例子:BERT 是一个架构,而 bert-base-cased ,这是谷歌团队为 BERT 的第一个版本训练的一组权重参数,是一个参数。我们可以说“BERT 模型”和“ bert-base-cased 模型。”
Tokenizer
与其他神经网络一样,Transformers 模型无法直接处理原始文本,因此我们需要引入 Tokenizer。
**Tokenizer**是人类语言与机器语言之间的“翻译官”。其职责重大,主要包括:
- 分词 (Tokenization): 将 “今天天气真好” 这样的句子拆分成模型能认识的最小单元,如
["今", "天", "天", "气", "真", "好"]。 - ID 转换: 将每个词元(Token)映射成一个独一无二的数字 ID,即
input_ids。 - 添加特殊标记: 插入模型必需的特殊符号,比如
[CLS]用于分类任务,[SEP]用于分隔句子。 - 生成注意力掩码 (Attention Mask): 当句子长度不一时,短句子需要被“填充”(Padding)到与长句同样的长度。注意力掩码就是一个由 0 和 1 组成的列表,告诉模型哪些是真实词元(值为 1),哪些是填充物(值为 0),计算时应忽略后者。
我们先通过分词器(Tokenizer)把文本转换为模型能够读懂的数字。
def run_tokenizer(): checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" tokenizer = AutoTokenizer.from_pretrained(checkpoint) result = tokenizer( ["I am very urgent!", "I want to complain!"], padding=True, truncation=True, return_tensors="pt", ) # { # 'input_ids': # tensor([[ 101, 1045, 2572, 2200, 13661, 999, 102],[ 101, 1045, 2215, 2000, 17612, 999, 102]]), # 'attention_mask': # tensor([[1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1]]) # } # 输出是一个包含两个键, input_ids 和 attention_mask # input_ids 包含两行整数(每个句子一行),它们是每个句子中 token 的 ID。 print(result)
Model
模型会接收 Tokenizer 生成的数字,通过模型头等进行处理,最终生成对应任务的输出结果。例如,在情感分类任务中生成类别概率分布,分别是正面和负面。
但这些不是概率,而是 logits(对数几率),是模型最后一层输出的原始的、未标准化的分数。要转换为概率,它们需要经过 SoftMax 层
下面是一个情感分类的一个例子:
def run_model(): from transformers import AutoModel, AutoModelForSequenceClassification, AutoTokenizer import torch.nn.functional as F checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" model = AutoModelForSequenceClassification.from_pretrained(checkpoint) tokenizer = AutoTokenizer.from_pretrained(checkpoint) # 分词得到 input_ids input = tokenizer(["I am very urgent!", "I want to complain!"], padding=True, return_tensors="pt") res = model(**input) # 处理后序输出 probabilities = F.softmax(res.logits, dim=-1) # 获取模型输出对应的label labels = sequence_classication_model.config.id2label
从微调一个小模型学起
学习大模型最好的办法就是动手实践。下面从微调一个简单的问答模型为例子,打开学习大模型的大门吧。
智能流程总结
- 原料(数据)准备:我们需要一批包含
context(上下文)、question(问题)和answers(答案文本及其在上下文中的起始位置)的数据集。- 预处理(分词):调用与预训练模型配套的
Tokenizer,将question和context转化为模型可消化的input_ids、attention_mask等数值输入。对于 QA 任务,这一步至关重要,它还需要计算出答案在分词后序列中所对应的start_positions和end_positions。- 送入模型:将处理好的数据喂给一个专用于问答任务的模型,如
AutoModelForQuestionAnswering。- 训练(微调):
- 配置
TrainingArguments,用于设定学习率、批次大小(Batch Size)等超参数。- 启动
Trainer,它会自动处理设备分配(CPU/GPU)、梯度更新、日志记录等一系列繁杂的后台工作。- 训练的核心目标是:通过不断调整模型权重,使得模型预测的答案起止位置,与我们提供的真实标签越来越接近。
- 出厂(后处理):将新的问题和上下文输入给微调完毕的模型。模型会输出两组分数(
start_logits和end_logits),分别代表每个词元作为答案开头和结尾的可能性。我们通过一个简单的后处理逻辑,找到分数最高的组合,便能解码出最终的答案文本。
获取数据集
训练模型最重要的事情是**数据集!**我们可以从Hugging Face等渠道获取各种各样的数据集。但是这里我们为了效果明显,自己去构建一个极为简单的数据集。
ctx = """ 权限管理平台 ACC(Auth Config Center) 为中台提供一套运行稳定、安全可靠、界面简洁的可视化权限配置能力。包括:权限配置、权限下发及鉴权功能。 其涉及了一些名词: - 权限点(keyword):权限系统中最小的权限粒度映射到业务系统对应系统操作功能。例如:查询,搜索,删除等操作 - 功能权限树:为用户提供权限下发与系统权限管控 - 菜单权限树:提供页面及菜单的权限下发与管控 - 白名单:无需登录、需要登录无需鉴权赋予某一特定角色功能 """ # 原始数据列表 raw_data = [ { "id": "001", "context": ctx, "question": "什么是 ACC", "answer_text": "权限管理平台", }, { "id": "002", "context": ctx, "question": "ACC 有哪些功能", "answer_text": "权限配置、权限下发及鉴权功能", }, { "id": "003", "context": ctx, "question": "ACC 有哪些名词", "answer_text": "权限点", }, { "id": "004", "context": ctx, "question": "权限点是干嘛的", "answer_text": "权限系统中最小的权限粒度映射到业务系统对应系统操作功能", }, ]
有了原始数据,我们需要对其进行格式转换。在学术领域,用于抽取式问答的最常用基准数据集是SQuAD,我们可以去下载一下,看看它的格式是怎样的
from datasets import load_datasetraw_datasets = load_dataset("squad")# DatasetDict({# train: Dataset({# features: ['id', 'title', 'context', 'question', 'answers'],# num_rows: 87599# })# validation: Dataset({# features: ['id', 'title', 'context', 'question', 'answers'],# num_rows: 10570# })# })# 其中answers格式为{text:string[], answer_start:int[]}
context和question字段的使用非常简单直接。answers字段稍显复杂,因为它包含一个带有两个字段的字典,而这两个字段都是列表。这是评估过程中squad指标所期望的格式;如果你使用自己的数据,则不一定需要费心将答案设置为相同的格式。text字段的含义相当明显,answer_start字段包含每个答案在上下文中的起始字符索引。
我们可以把我们的原始数据也转换成这种格式。完整代码如下:
def create_toy_qa_dataset() -> DatasetDict: ctx = """ 权限管理平台 ACC(Auth Config Center) 为中台提供一套运行稳定、安全可靠、界面简洁的可视化权限配置能力。包括:权限配置、权限下发及鉴权功能。 其涉及了一些名词: - 权限点(keyword):权限系统中最小的权限粒度映射到业务系统对应系统操作功能。例如:查询,搜索,删除等操作 - 功能权限树:为用户提供权限下发与系统权限管控 - 菜单权限树:提供页面及菜单的权限下发与管控 - 白名单:无需登录、需要登录无需鉴权赋予某一特定角色功能 """ # 原始数据列表 raw_data = [ { "id": "001", "context": ctx, "question": "什么是 ACC", "answer_text": "权限管理平台", }, { "id": "002", "context": ctx, "question": "ACC 有哪些功能", "answer_text": "权限配置、权限下发及鉴权功能", }, { "id": "003", "context": ctx, "question": "ACC 有哪些名词", "answer_text": "权限点", }, { "id": "004", "context": ctx, "question": "权限点是干嘛的", "answer_text": "权限系统中最小的权限粒度映射到业务系统对应系统操作功能", }, ] # 格式化数据,自动计算 answer_start formatted_data = {"id": [], "context": [], "question": [], "answers": []} for item in raw_data: context = item["context"] answer_text = item["answer_text"] # 找到答案在原文中的起始位置 start_idx = context.find(answer_text) formatted_data["id"].append(item["id"]) formatted_data["context"].append(context) formatted_data["question"].append(item["question"]) formatted_data["answers"].append( {"text": [answer_text], "answer_start": [start_idx]} ) # 创建 Dataset ds = Dataset.from_dict(formatted_data) validation_ds = ds.select(range(4)) dsd = DatasetDict({"train": ds, "validation": validation_ds}) return dsd
我们这次训练使用 google-bert/bert-base-chinese模型,虽然它并不是专门用于问答任务。先展示一下微调前的效果:
model_checkpoint = "google-bert/bert-base-chinese"# 加载 Tokenizertokenizer = AutoTokenizer.from_pretrained(model_checkpoint)# 加载 Datasetraw_datasets = create_toy_qa_dataset()model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)test_context = raw_datasets["train"][1]["context"]test_question = raw_datasets["train"][1]["question"]answer = get_answer(test_question, test_context, model, tokenizer)# answer: ''
这里的 get_answer 的具体代码在下文会详细讲解,这里认为是模型推理即可。
这里大概率为空或乱码(因为该模型没学过这个任务),我们需要对它进行微调来让模型能够满足我们的效果。
预处理数据集
我们需要将数据集中的文本信息处理成Input IDs。利用 DatasetDict中的 map方法,可以对整个数据集做批处理:
tokenized_datasets = raw_datasets.map( lambda x: preprocess_function(x, tokenizer), batched=True, # 是否批处理 remove_columns=raw_datasets[ "train" ].column_names, # 移除原始文本列,只保留分词后的列 即 Input ID 等 )
``````plaintext
def preprocess_function(samples, tokenizer): tokenized_inputs = tokenizer( examples["question"], examples["context"], max_length=384, truncation="only_second", return_offsets_mapping=True, padding="max_length", ) # ...
首先 tokenizer中我们传入了每一个样本 (数据集中的每一条数据) 的 question和 context,这样将会对同时对两者进行处理。
max_length:表示tokenizer处理的最大长度,这里假设答案一定在前 384 个 Token 里。如果文章很长,超出部分直接扔掉。truncation="only_second":跟上述一样,如果超长,直接对context进行丢弃。return_offsets_mapping=True: 返回每个 Token 对应原文的字符位置 (start_char, end_char)
最终输入的 tokenizied_inputs.input_ids是一个 长度为5的数组(因为数据集只有5条数据,每一项都包含 question + context)
我们可以通过 tokenized_inputs.sequence_ids(i)去获取具体某条 input_id中,哪一个部分代表question、哪一个部分代表context。
tokenized_inputs.sequence_ids(0) # [None, 0, 0, 0, 0, None, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...]
tokenized_inputs["offset_mapping"]也是一个 长度为5的数组,它包含了每一个 Token所在的索引
# 对应索引0[(0, 0), (0, 1), (1, 2), (2, 3), (4, 7), (0, 0), (5, 6), (6, 7), (7, 8), (8, 9), (9, 10)...]
可以看到,(0, 0)刚好对应的是 None,其实就是question和context之间的特殊标记。
最后我们要做的,就是需要找到Token**级别下,**答案所在的位置:
- 先排除
question部分,找到context所在的Token下的位置索引 - 从
context的首尾同时遍历,直到找到包含start_char(原始数据中答案所在的位置索引) 的Token
这部分相对简单,代码如下。
def preprocess_function(examples, tokenizer): tokenized_inputs = tokenizer( examples["question"], examples["context"], max_length=384, truncation="only_second", return_offsets_mapping=True, padding="max_length", ) # 2. 处理答案位置 offset_mapping = tokenized_inputs.pop("offset_mapping") answers = examples["answers"] start_positions = [] end_positions = [] for i, offset in enumerate(offset_mapping): answer = answers[i] start_char = answer["answer_start"][0] end_char = start_char + len(answer["text"][0]) # sequence_ids 用于区分哪部分是问题,哪部分是上下文 # 0 代表问题,1 代表上下文,None 代表特殊符号([CLS], [SEP], [PAD]) sequence_ids = tokenized_inputs.sequence_ids(i) # 找到上下文在 Token 序列中的起始和结束索引 idx = 0 while sequence_ids[idx] != 1: idx += 1 context_start = idx while sequence_ids[idx] == 1: idx += 1 context_end = idx - 1 # 如果答案不在当前截断的片段中(针对超长文本),这就标记为 (0, 0) # 这里的 offset[context_end][1] 是当前片段最后一个 Token 对应的原文结束字符位置 if offset[context_start][0] > start_char or offset[context_end][1] < end_char: start_positions.append(0) end_positions.append(0) else: # 否则,我们需要找到 Token 的 start_index 和 end_index # 从上下文的第一个 Token 开始往后找,直到找到包含 start_char 的 Token idx = context_start while idx <= context_end and offset[idx][0] <= start_char: idx += 1 start_positions.append(idx - 1) # 从上下文的最后一个 Token 开始往前找,直到找到包含 end_char 的 Token idx = context_end while idx >= context_start and offset[idx][1] >= end_char: idx -= 1 end_positions.append(idx + 1) # 将计算好的 Token 级别的起始和结束位置放入 inputs 中 tokenized_inputs["start_positions"] = start_positions tokenized_inputs["end_positions"] = end_positions return tokenized_inputs
构建超参数,开始训练
args = TrainingArguments( output_dir="qa-model-finetuned", eval_strategy="no", # 数据太少,不进行分步评估 save_strategy="no", learning_rate=5e-5, per_device_train_batch_size=2, # 小批量 per_device_eval_batch_size=2, num_train_epochs=50, # 增加 epoch 以确保拟合 weight_decay=0.01, push_to_hub=False, logging_steps=10, use_mps_device=False, )
我们先来看一下模型训练时的一些重要参数:
num_train_epochs:要执行的训练轮数总和。通俗来说,1 Epoch表示模型完完整整的看过进行训练的数据集一次。
- 如果
num_train_epochs设置过多,训练出来的模型将会过拟合,即反反复复多次背诵训练的数据集,对数据集就很熟悉,但是如果遇到新的问题则可能回答不出来,泛化能力差。反之,则欠拟合。
学习率 learning_rate: 决定了每次模型训练时参数的更新幅度(0-1)。**简单来说,模型在训练过程中的效果不够好时,模型需要调整的幅度。
- 学习率太大 (比如 0.1):老师大吼一声“全错!重写!”,学生吓得不知所措,可能下次走向另一个极端,永远找不到正确答案(模型不收敛,Loss 震荡)。
- 学习率太小 (比如 1e-8):老师极其温柔地说“这里稍微改一点点…”,学生改了一万次才改对,等到毕业了还没学会(训练太慢,收敛不了)。
- 合适的值 (5e-5):老师指出关键错误,让学生做适度的调整。BERT 微调通常都用这个量级(2e-5 到 5e-5),因为它已经“预习”(预训练)过了,不需要从头学,只需要微调。
批量大小 per_device_train_batch_size:指每台设备训练时的批量大小,在多GPU或分布式训练中,总**Batch size = per_device_train_batch_size * number_of_devices**
- Batch Size = 1 :学生做完一题,老师马上批改一题。学生能立刻得到反馈,但老师会很累(计算慢),而且如果某道题出错了(脏数据),学生会被带偏。
- Batch Size = 100 :学生做完100题,老师统一批改,告诉他“总体方向对了没有”。这样比较稳(梯度稳定),但对老师的脑容量(显存)要求很高。
权重衰减 weight_decay: 通俗来说 ,给“死记硬背”的学生扣分(惩罚项)。
它强制模型不要过于依赖某几个特定的特征(比如不要看到“因为”两个字就无脑选后面的句子做答案)。它让模型的参数尽量小且分散,这样模型的泛化能力更强。
如果模型过拟合了,可以适当调大 weight_decay****。
最后,我们就可以通过Trainer,对模型进行训练啦:
... # 实例化 Trainer data_collator = DefaultDataCollator() trainer = Trainer( model=model, args=args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["validation"], tokenizer=tokenizer, data_collator=data_collator, ) # 开始训练 trainer.train()
在模型训练过程中,终端会输出一些训练时参数
{'loss': 3.9616, 'grad_norm': 17.661741256713867, 'learning_rate': 4.7e-05, 'epoch': 3.33} {'loss': 2.0221, 'grad_norm': 26.38640594482422, 'learning_rate': 4.3666666666666666e-05, 'epoch': 6.67} {'loss': 1.7888, 'grad_norm': 30.200885772705078, 'learning_rate': 4.0333333333333336e-05, 'epoch': 10.0} {'loss': 1.2302, 'grad_norm': 46.9060173034668, 'learning_rate': 3.7e-05, 'epoch': 13.33} {'loss': 0.5915, 'grad_norm': 51.04061508178711, 'learning_rate': 3.366666666666667e-05, 'epoch': 16.67} {'loss': 0.3984, 'grad_norm': 0.5519830584526062, 'learning_rate': 3.0333333333333337e-05, 'epoch': 20.0} {'loss': 0.5358, 'grad_norm': 16.61482810974121, 'learning_rate': 2.7000000000000002e-05, 'epoch': 23.33} {'loss': 0.0591, 'grad_norm': 20.124296188354492, 'learning_rate': 2.3666666666666668e-05, 'epoch': 26.67} {'loss': 0.009, 'grad_norm': 0.022040903568267822, 'learning_rate': 2.0333333333333334e-05, 'epoch': 30.0} {'loss': 0.0018, 'grad_norm': 0.025523267686367035, 'learning_rate': 1.7000000000000003e-05, 'epoch': 33.33} {'loss': 0.0054, 'grad_norm': 0.21060892939567566, 'learning_rate': 1.3666666666666666e-05, 'epoch': 36.67} {'loss': 0.0004, 'grad_norm': 0.01707434467971325, 'learning_rate': 1.0333333333333333e-05, 'epoch': 40.0}
loss表示模型的预测与真实答案之间的差距。这个差距值,就是我们所说的“损失值”。在训练过程中我们可以发现 loss逐渐减少,这证明模型在训练过程中的效果越来越符合验证集中的数据。
为什么这里的**
epoch**是小数?在上述例子中:
- 数据总量 :只有 5 条数据。
- 批次大小 ( per_device_train_batch_size ) :设为 2 。
那么,完成 1 个 Epoch (遍历所有数据一遍)需要走几步(Steps)?
(注:第1步取2条,第2步取2条,第3步取最后1条)
设置了
logging_steps=10 。这意味着 Trainer 每走 10 步 (Steps)就会打印一次日志。
我们来算算 10 步 相当于跑了多少个 Epoch:
所以:
- 第 10 步时,打印日志,此时 Epoch = 10 / 3 ≈ 3.33
- 第 20 步时,打印日志,此时 Epoch = 20 / 3 ≈ 6.67
- 第 30 步时,打印日志,此时 Epoch = 30 / 3 = 10.0
这就是为什么你会看到 3.33 , 6.67 这种非整数的 Epoch。
效果验证和总结
我们以本节开头的例子来验证一下,那么如何去验证呢?
test_context = raw_datasets["train"][1]["context"]test_question = raw_datasets["train"][1]["question"]answer = get_answer(test_question, test_context, model, tokenizer)print(f"问题: {test_question}")print(f"回答: {answer}")
在 get_answer函数中,我们需要进行 **tokenizer、modelc处理以及后处理**三步骤。
def get_answer(question, context, model, tokenizer): # 将模型设为评估模式 model.eval() # 1. 分词 inputs = tokenizer(question, context, return_tensors="pt") # 2. 模型前向传播 with torch.no_grad(): outputs = model(**inputs) # 3. 后处理:获取预测结果 # 模型输出包含 start_logits 和 end_logits,分别表示每个 Token 是答案开头的概率和结尾的概率 answer_start_index = torch.argmax(outputs.start_logits) answer_end_index = torch.argmax(outputs.end_logits) + 1 # +1 是因为切片是左闭右开 # 4. 将 Token ID 转换回文本 predict_answer_tokens = inputs.input_ids[0, answer_start_index:answer_end_index] predicted_answer = tokenizer.decode(predict_answer_tokens, skip_special_tokens=True) return predicted_answer
要注意的是,这里模型输出的是start_logits和end_logits,分别表示每个 Token 是答案开头的概率和结尾的"概率"(对数几率)
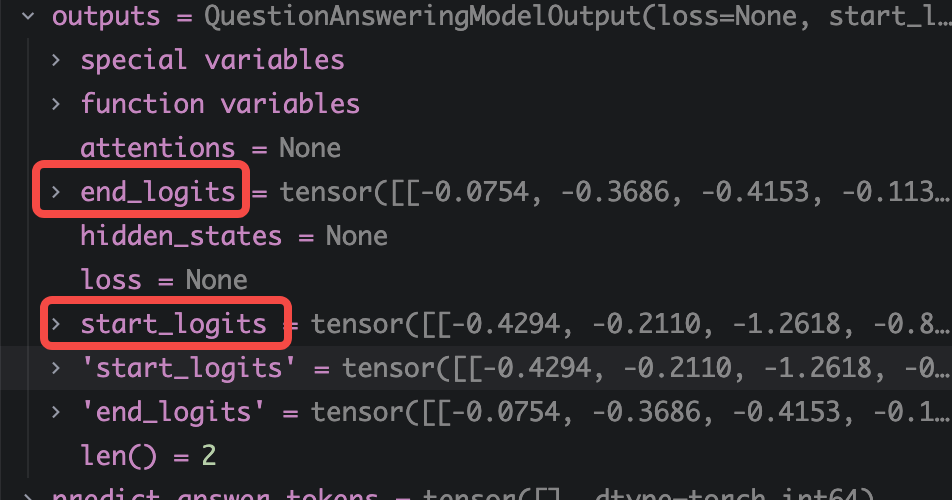
在这里,我们直接通过 torch.argmax分别获取两者概率最大的索引,最后在 Input ids中去获取相对应的 Token,最后再由 tokenizer解码成文本内容。
# 问题: ACC 有哪些功能# 回答: 权 限 配 置 、 权 限 下 发 及 鉴 权 功 能
最后看上去效果还不错,这次次模型微调就结束啦~
拓展内容
注意
本次微调只是一个“玩具”流程,有一些需要注意的地方:
- 正常训练时的数据集不可能这么少,动则上万条文本数据的数据集只是门槛。。
- 由于训练集小,因此我们的
epoch设置了50轮,让模型过拟合来更好的去验证结果。正常模型训练时一般取3轮左右。
拓展内容
预处理训练集(滑动窗口)
在预处理训练集过程中,我们采用简单截断的方式:我假设你的文本很短,或者答案一定在前 384 个 Token 里。如果文章很长,超出部分直接扔掉 ( truncation="only_second")。如果答案不幸在被扔掉的那部分里,模型就永远找不到了。
因此模型不需要处理“一个样本变成多个片段”的情况,代码逻辑是一对一的,非常简单。
如果训练集中的文本内容很长,我们可以给 tokenizer设置 stride(步长),表示将文章分割为若干个切片,每一个切片都有重合的一部分。这就导致了“ 一对多 ”的关系(1 个问题 -> N 个输入片段)。在预测时,则需要收集这 N 个片段的所有输出 Logits,统一比较,找出在这个长文章中到底哪一段的哪个位置分数最高。
def preprocess_function(examples, tokenizer): tokenized_inputs = tokenizer( examples["question"], examples["context"], max_length=384, truncation="only_second", return_offsets_mapping=True, return_overflowing_tokens=Ture stride=100, padding="max_length", ) # 2. 处理答案位置 offset_mapping = tokenized_inputs.pop("offset_mapping") answers = examples["answers"] start_positions = [] end_positions = [] sample_idxs = [] for i, offset in enumerate(offset_mapping): # 表示当前片段所对应的样本索引 sample_idx = inputs["overflow_to_sample_mapping"][i] sample_idxs.append(sample_idx) answer = answers[sample_idx] start_char = answer["answer_start"][0] end_char = start_char + len(answer["text"][0]) # sequence_ids 用于区分哪部分是问题,哪部分是上下文 # 0 代表问题,1 代表上下文,None 代表特殊符号([CLS], [SEP], [PAD]) sequence_ids = tokenized_inputs.sequence_ids(i) # 找到上下文在 Token 序列中的起始和结束索引 idx = 0 while sequence_ids[idx] != 1: idx += 1 context_start = idx while sequence_ids[idx] == 1: idx += 1 context_end = idx - 1 # 如果答案不在当前截断的片段中(针对超长文本),这就标记为 (0, 0) # 这里的 offset[context_end][1] 是当前片段最后一个 Token 对应的原文结束字符位置 if offset[context_start][0] > start_char or offset[context_end][1] < end_char: start_positions.append(0) end_positions.append(0) else: # 否则,我们需要找到 Token 的 start_index 和 end_index # 从上下文的第一个 Token 开始往后找,直到找到包含 start_char 的 Token idx = context_start while idx <= context_end and offset[idx][0] <= start_char: idx += 1 start_positions.append(idx - 1) # 从上下文的最后一个 Token 开始往前找,直到找到包含 end_char 的 Token idx = context_end while idx >= context_start and offset[idx][1] >= end_char: idx -= 1 end_positions.append(idx + 1) # 将计算好的 Token 级别的起始和结束位置放入 inputs 中 tokenized_inputs["start_positions"] = start_positions tokenized_inputs["end_positions"] = end_positions tokenized_inputs["sample_idxs"] = sample_idxs return tokenized_inputs
模型后处理
在上述案例中,我们是基于最简单的“贪心”策略去实现的。我们假设分别获取作为开头、结尾时概率最大的Token,两者中间所包含的文本就是最佳答案。
这样的处理方式会有很大的问题:
- 问题1:开始索引大于结束索引
- 现象:当模型预测的始位置
(start_index)大于结束位置(end_index)时,切片input_ids[0, start_index:end_index]会返回空张量,导致解码后得到空字符串 - 原因:独立使用
argmax选择start和end位置,未考虑两者的依赖关系(答案必须是连续片段,start <= end)
- 问题2:置信度过低
- 现象:即使模型对所有位置的预测置信度都很低(如context中无相关答案),代码仍会返回一个答案
- 原因:直接使用 argmax 强制选择一个位置,未考虑模型的预测不确定性
- 解决方式:通过遍历每一个 Token,寻找出所有的开头和结尾的组合,并计算其概率,找出概率最大的那对组合。
def get_answer(question, context, model, tokenizer): # 将模型设为评估模式 model.eval() # 1. 分词 inputs = tokenizer( question, context, max_length=384, truncation="only_second", return_offsets_mapping=True, return_overflowing_tokens=Ture stride=100, padding="max_length" ) # 2. 模型前向传播 with torch.no_grad(): outputs = model(**inputs) transform_res = [] start_logits = outputs.start_logits.cpu().numpy() end_logits = outputs.end_logits.cpu().numpy() logits_size = start_logits.shape[0] for feature_idx in range(logits_size): sample_idx = inputs["overflow_to_sample_mapping"][feature_idx] offset = inputs["offset_mappings"][feature_idx] start_logit = start_logits[feature_idx] end_logit = end_logits[feature_idx] sequence_ids = inputs.sequence_ids(feature_idx) for start_idx in start_logit: for end_idx in end_logit: if start_idx > end_idx: continue if sequence_ids[start_idx] == 0 and sequence_ids[end_idx] == 0: continue start_token = offset[start_idx][0] end_token = offset[end_idx][1] if start_token == 0 and end_token == 0: continue if end_token < start_token: continue ans_from_ctx = context[start_token:end_token] # 从原始logits中取 scroe = start_logits[logit_idx][start_idx] + end_logits[logit_idx][end] transform_res.append( { "answer": ans_from_ctx, "score": scroe, "start_token": start_token, "end_token": end_token, } ) return transform_res
大模型未来如何发展?普通人如何抓住AI大模型的风口?
※领取方式在文末
为什么要学习大模型?——时代浪潮已至
随着AI技术飞速发展,大模型的应用已从理论走向大规模落地,渗透到社会经济的方方面面。
- 技术能力上:其强大的数据处理与模式识别能力,正在重塑自然语言处理、计算机视觉等领域。
- 行业应用上:开源人工智能大模型已走出实验室,广泛落地于医疗、金融、制造等众多行业。尤其在金融、企业服务、制造和法律领域,应用占比已超过30%,正在创造实实在在的价值。
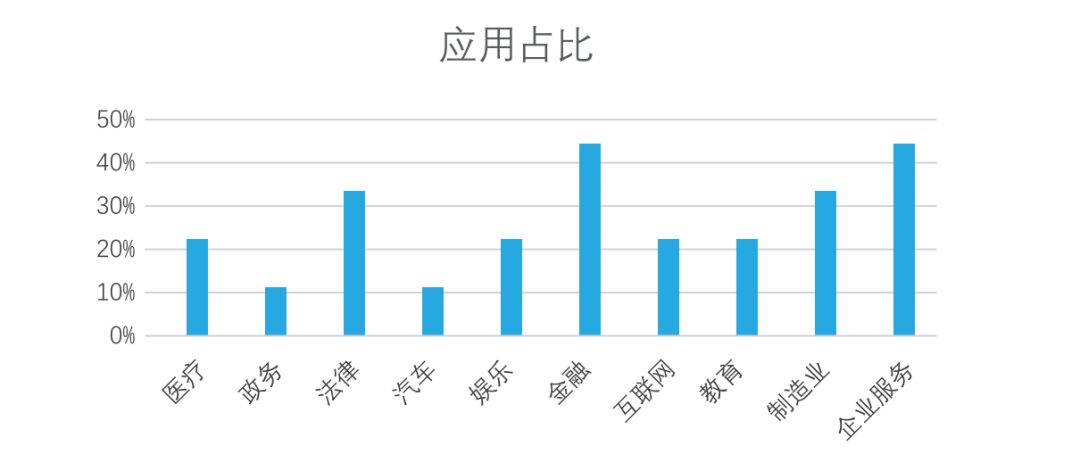
未来大模型行业竞争格局以及市场规模分析预测: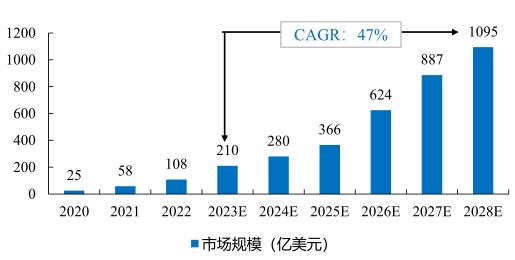
同时,AI大模型技术的爆发,直接催生了产业链上一批高薪新职业,相关岗位需求井喷:
AI浪潮已至,对技术人而言,学习大模型不再是选择,而是避免被淘汰的必然。这关乎你的未来,刻不容缓!
那么,我们如何学习AI大模型呢?
在一线互联网企业工作十余年里,我指导过不少同行后辈,经常会收到一些问题,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题,也不是三言两语啊就能讲明白的。
所以呢,这份精心整理的AI大模型学习资料,我整理好了,免费分享!只希望它能用在正道上,帮助真正想提升自己的朋友。让我们一起用技术做点酷事!
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!

适学人群
我们的课程体系专为以下三类人群精心设计:
-
AI领域起航的应届毕业生:提供系统化的学习路径与丰富的实战项目,助你从零开始,牢牢掌握大模型核心技术,为职业生涯奠定坚实基础。
-
跨界转型的零基础人群:聚焦于AI应用场景,通过低代码工具让你轻松实现“AI+行业”的融合创新,无需深奥的编程基础也能拥抱AI时代。
-
寻求突破瓶颈的传统开发者(如Java/前端等):将带你深入Transformer架构与LangChain框架,助你成功转型为备受市场青睐的AI全栈工程师,实现职业价值的跃升。

※大模型全套学习资料展示
通过与MoPaaS魔泊云的强强联合,我们的课程实现了质的飞跃。我们持续优化课程架构,并新增了多项贴合产业需求的前沿技术实践,确保你能获得更系统、更实战、更落地的大模型工程化能力,从容应对真实业务挑战。 资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
01 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。希望这份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
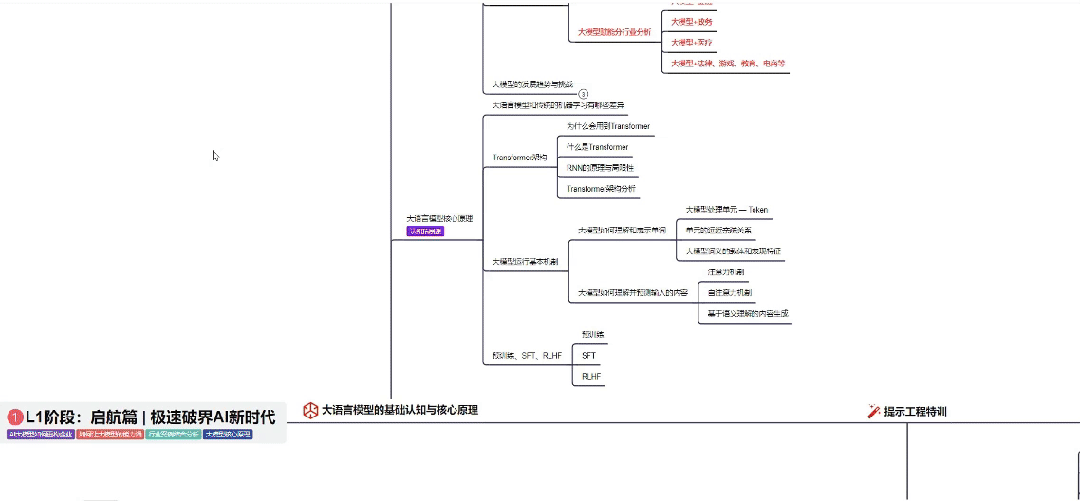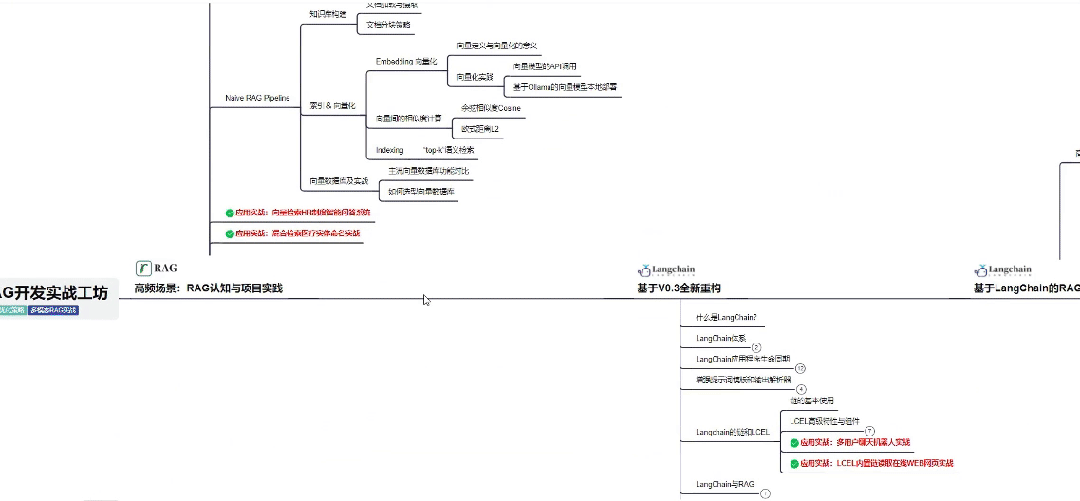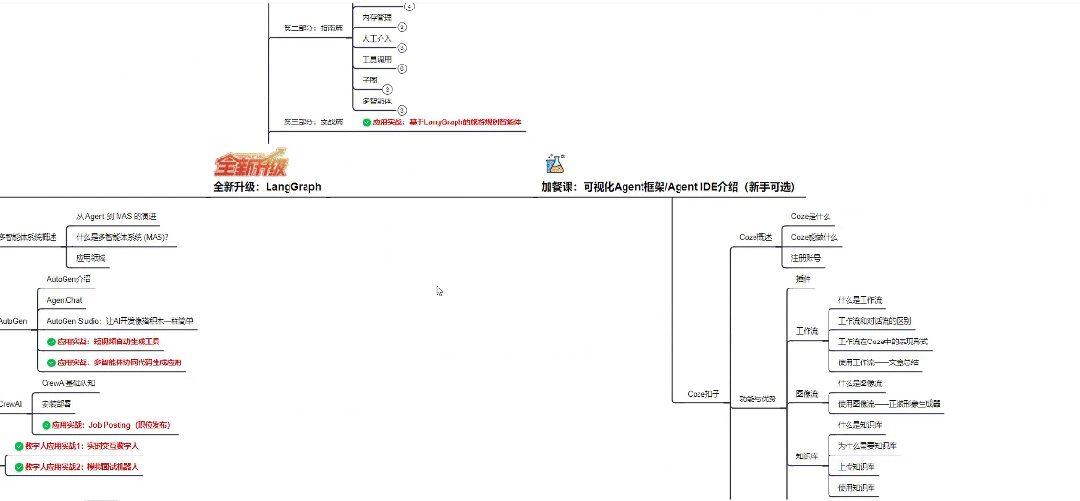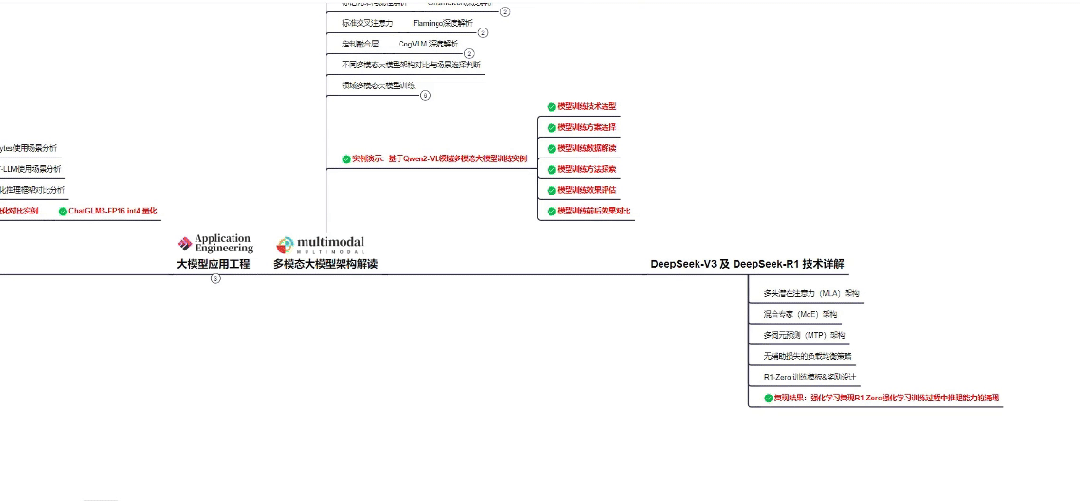
👇微信扫描下方二维码即可~

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
02 大模型学习书籍&文档
新手必备的权威大模型学习PDF书单来了!全是一系列由领域内的顶尖专家撰写的大模型技术的书籍和学习文档(电子版),从基础理论到实战应用,硬核到不行!
※(真免费,真有用,错过这次拍大腿!)

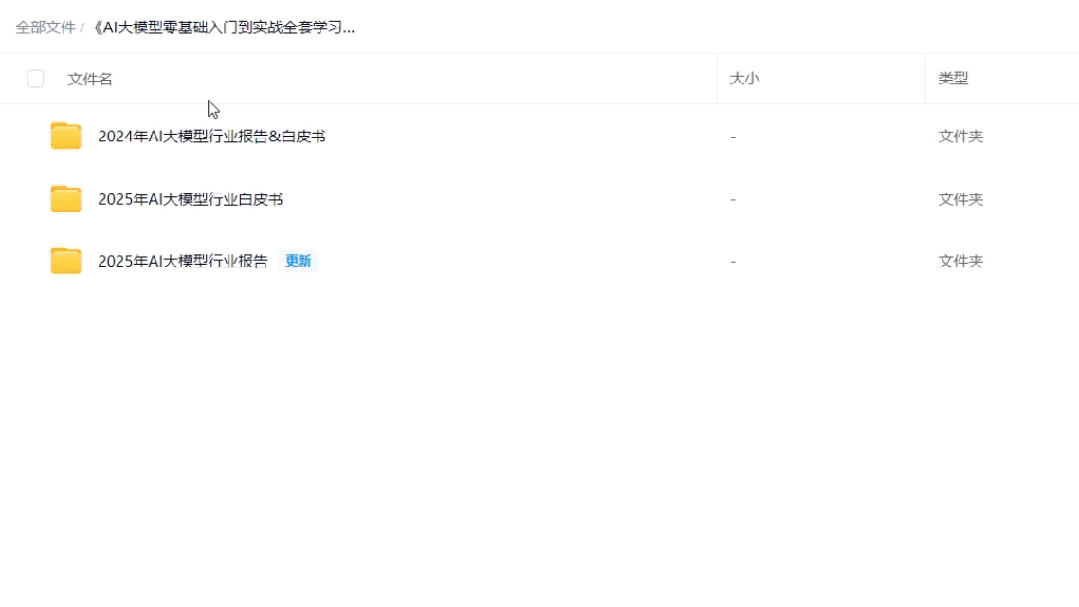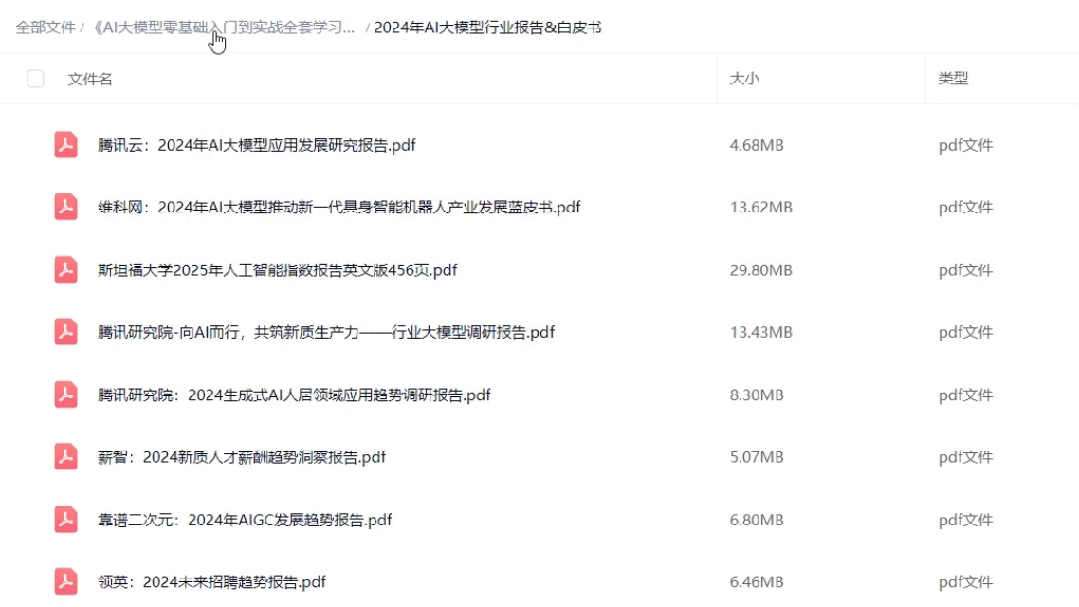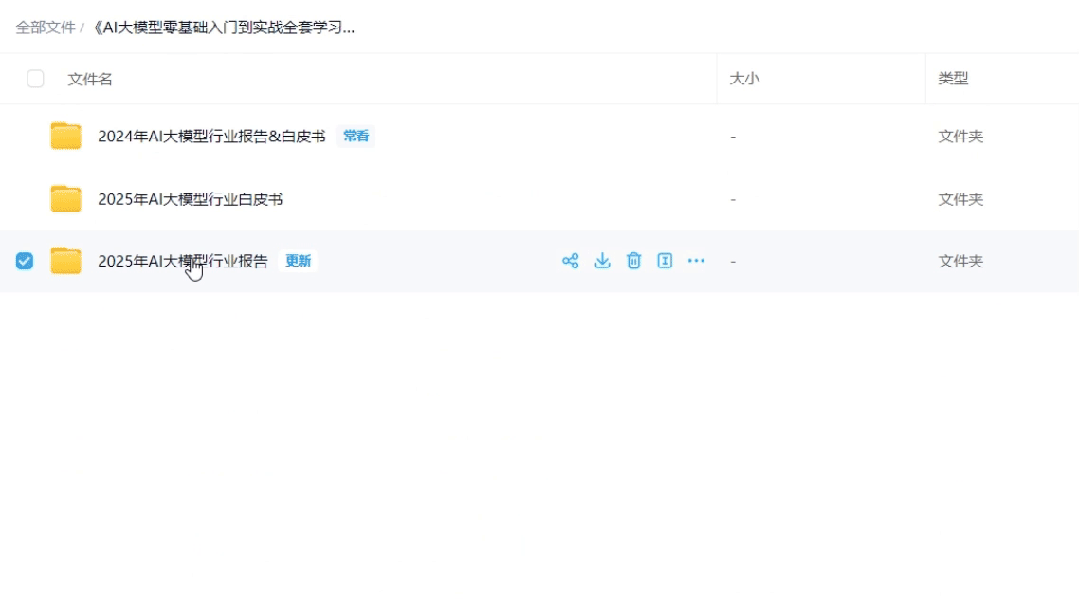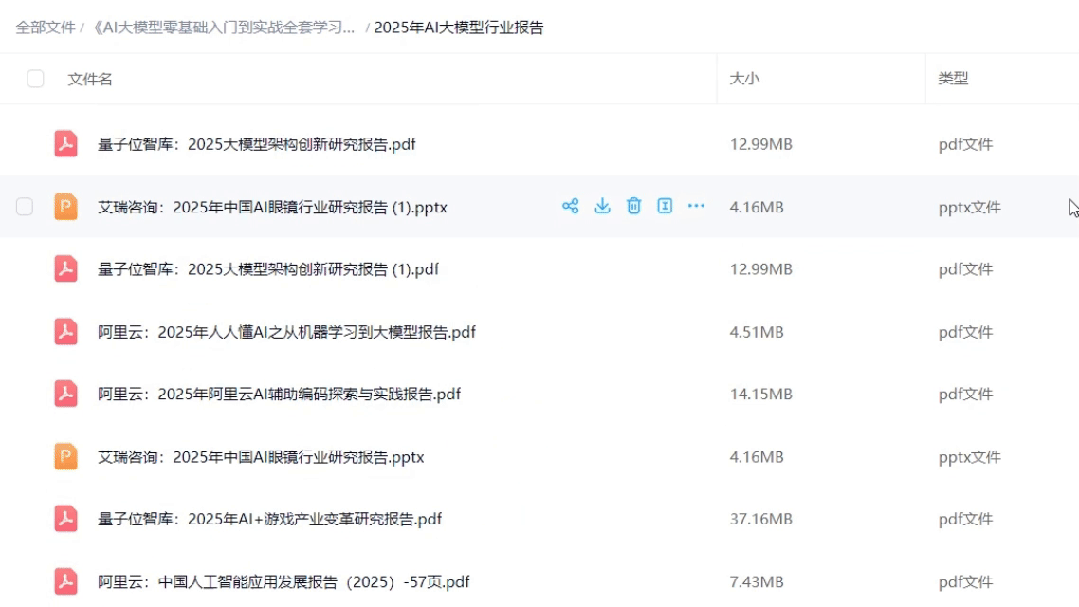
03 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
04 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
05 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

06 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
由于篇幅有限
只展示部分资料
并且还在持续更新中…
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!
最后,祝大家学习顺利,抓住机遇,共创美好未来!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献234条内容
已为社区贡献234条内容

所有评论(0)