AI Ping限时开放GLM-4.7与MiniMax M2.1:从配置到实战的保姆级教程
通过本次测试,我确认了一个趋势:国产大模型正从“演示型 AI”转向“工程型助手”。GLM-4.7 和 MiniMax M2.1 分别在一次性交付与持续编码两个维度上展现出实用价值。而像 AI Ping这样的平台,则让这种能力变得触手可及——无需部署、无需付费、接口标准,普通开发者也能快速验证模型是否适配自身业务。如果你也在做系统设计、自动化开发或 Agent 构建,不妨亲自试试。只需十几分钟配置,
文章目录
AI Ping限时开放GLM-4.7与MiniMax M2.1:从配置到实战的保姆级教程
本文是一份零基础上手指南,将一步步教你如何在AI Ping平台体验并调用最新上线的GLM-4.7与MiniMax M2.1两大国产旗舰模型,并通过Claude Code与Coze等工具将其集成到你的工作流中。
体验 AI Ping,https://aiping.cn/#?channel_partner_code=GQCOZLGJ注册登录立享30元算力金,所有模型及供应商全场通用!
🚀 第一步:快速了解AI Ping与新模型
AI Ping(aiping.cn)是国内领先的大模型服务评测与聚合平台,致力于为开发者提供全面、客观、真实的模型性能数据和统一调用入口。平台已接入智谱、MiniMax、DeepSeek、通义千问等主流厂商,覆盖95+模型,涵盖文本生成、视觉理解、图像生成、Embedding、Reranker 等多种类型。
平台核心优势包括:多供应商统一调用——一套接口切换不同供应商;性能数据可视化——实时展示吞吐、延迟、价格、可靠性等关键指标;智能路由——高峰时段自动选择最优供应商保障稳定性。目前 GLM-4.7、MiniMax-M2.1、DeepSeek-V3.2 等旗舰模型可体验,更有邀请好友双方各得20元算力点的活动,上不封顶。进入AI Ping首页
AI Ping(aiping.cn)是一个大模型“聚合器”与评测平台。你可以把它理解为一个模型超市:
- 统一入口:用一套API(兼容OpenAI格式)调用多个厂商(智谱、MiniMax、DeepSeek等)的模型。
- 免费额度:新注册用户赠送30元算力金,GLM-4.7、MiniMax-M2.1等旗舰模型目前可体验。
- 数据透明:实时查看每个模型的响应速度、价格和稳定性。


模型库
AI Ping 模型库概览,大部分的模型都是免费使用~
- NEW - 新上线:GLM-4.7、MiniMax-M2.1、MiMo-V2-Flash、Ring-1T 等
- FREE - 免费:DeepSeek-V3.2、GLM-4.7、MiniMax-M2.1、Doubao-Seedream-4.5 等
- HOT - 热门:GLM-4.6、MiniMax-M2、DeepSeek系列等
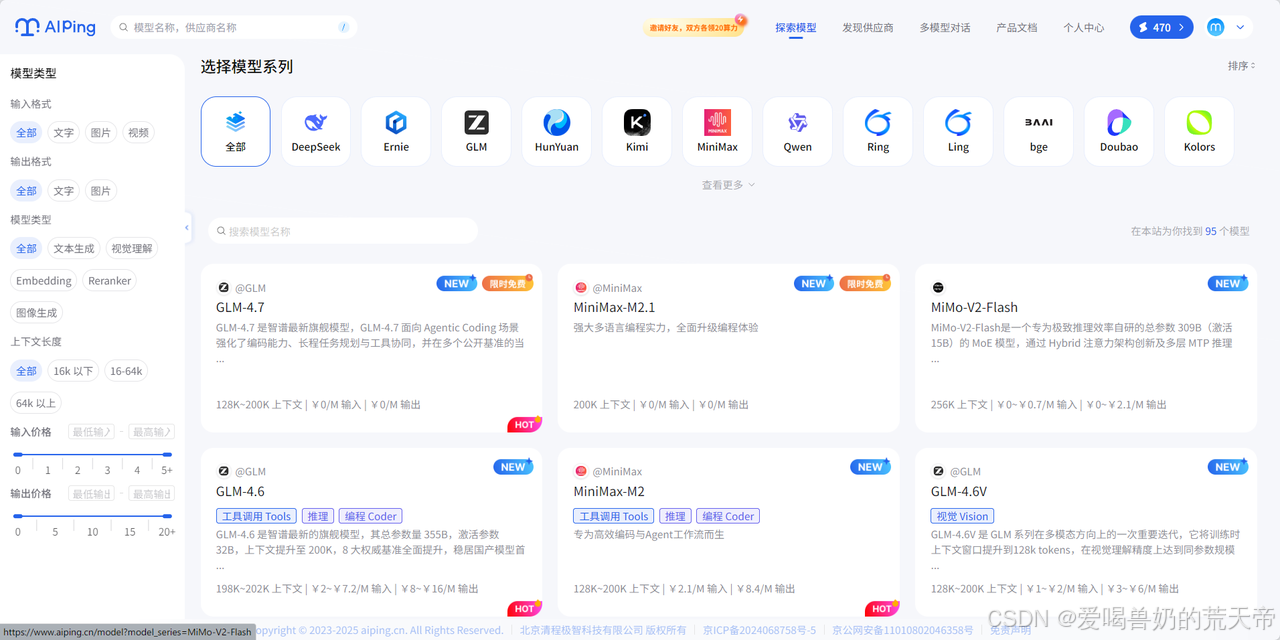
本次上线的两款核心模型定位:
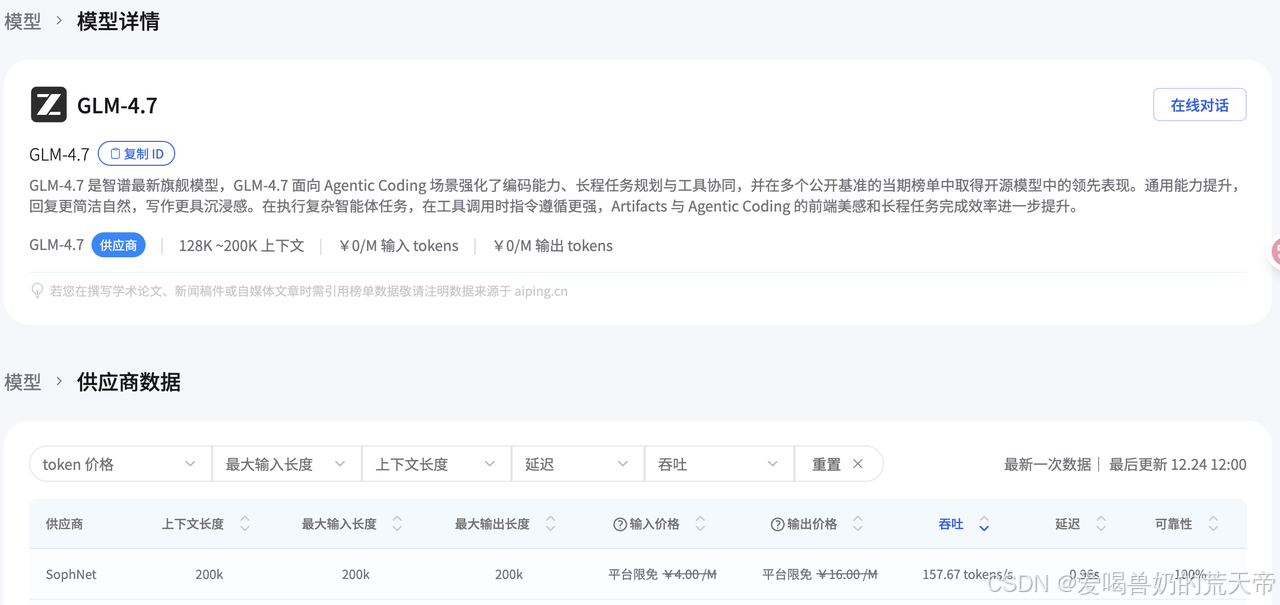
- GLM-4.7(智谱):GLM-4.7 是智谱最新旗舰模型,GLM-4.7 面向 Agentic Coding 场景强化了编码能力、长程任务规划与工具协同,并在可控推理机制支撑下实现了复杂工程任务的稳定交付。通用能力全面提升,回复更简洁自然,写作更具沉浸感。在执行复杂智能体任务时,指令遵循能力更强,Artifacts 与 Agentic Coding 的前端美感和长程任务完成效率进一步提升。
from openai import OpenAI
openai_client = OpenAI(
base_url="https://aiping.cn/api/v1",
api_key="QC-1********f0ee",
)
response = openai_client.chat.completions.create(
model="GLM-4.7",
stream=True,
extra_body={
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
},
messages=[
{"role": "user", "content": "Hello"}
]
)
for chunk in response:
if not getattr(chunk, "choices", None):
continue
reasoning_content = getattr(chunk.choices[0].delta, "reasoning_content", None)
if reasoning_content:
print(reasoning_content, end="", flush=True)
content = getattr(chunk.choices[0].delta, "content", None)
if content:
print(content, end="", flush=True)
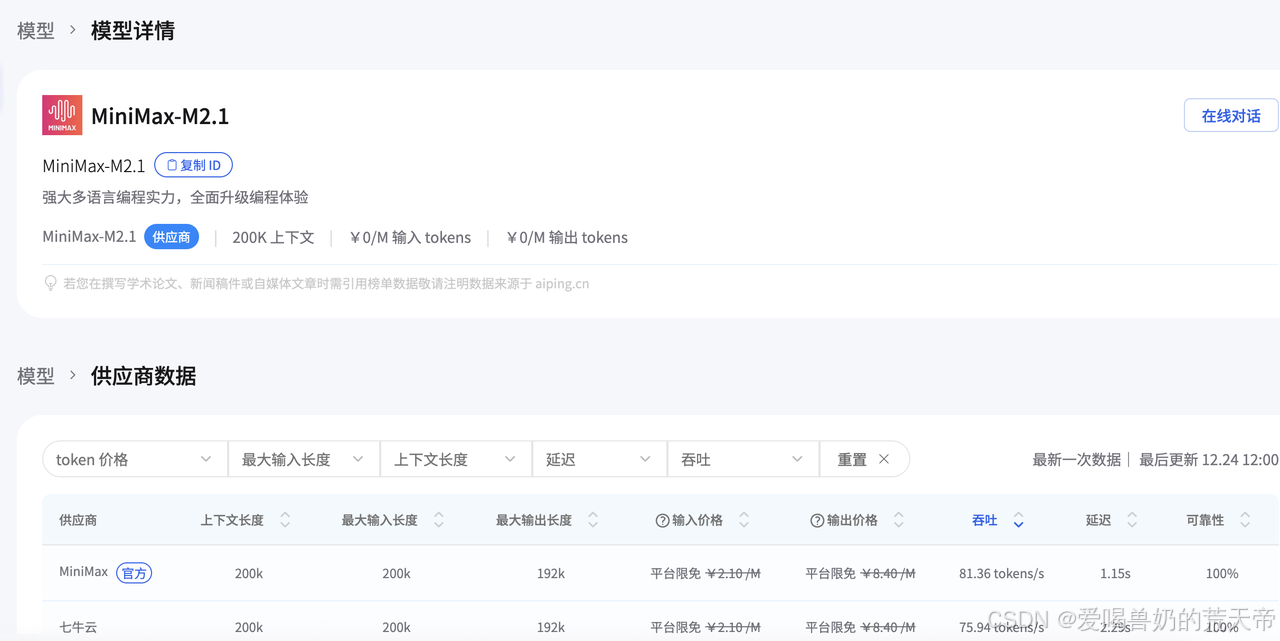
- MiniMax M2.1:MiniMax M2.1 是 MiniMax 最新旗舰模型,MiniMax M2.1 面向长链 Agent 执行场景强化了多语言工程能力、持续运行效率与收敛推理路径,并在高效 MoE 架构支撑下实现了吞吐与稳定性的出色平衡。多语言工程能力强化,对 Rust / Go / Java / C++ 等生产级代码支持更完善。在执行长时间 Agent 工作流时,推理路径更收敛、工具调用更高效,凭借低激活参数与 200k 长上下文优势,连续编码与持续运行吞吐进一步提升。
from openai import OpenAI
openai_client = OpenAI(
base_url="https://aiping.cn/api/v1",
api_key="QC-19ef6e5f37c4ad99973e3c1e12e4a40a-312b8df7de8323b57963ca18253df0ee",
)
response = openai_client.chat.completions.create(
model="MiniMax-M2.1",
stream=True,
extra_body={
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
},
messages=[
{"role": "user", "content": "Hello"}
]
)
for chunk in response:
if not getattr(chunk, "choices", None):
continue
reasoning_content = getattr(chunk.choices[0].delta, "reasoning_content", None)
if reasoning_content:
print(reasoning_content, end="", flush=True)
content = getattr(chunk.choices[0].delta, "content", None)
if content:
print(content, end="", flush=True)
🔑 第二步:获取你的“万能钥匙”(API Key)
所有操作始于API Key,获取只需1分钟:
- 访问 AI Ping官网,使用手机号或邮箱注册登录。
- 登录后,点击个人中心,点击左边进入 「API Keys」 页面。
- 点击 「创建新的密钥」,复制生成的那一串字符(如QC-**************)。请妥善保管,它就像你的密码。
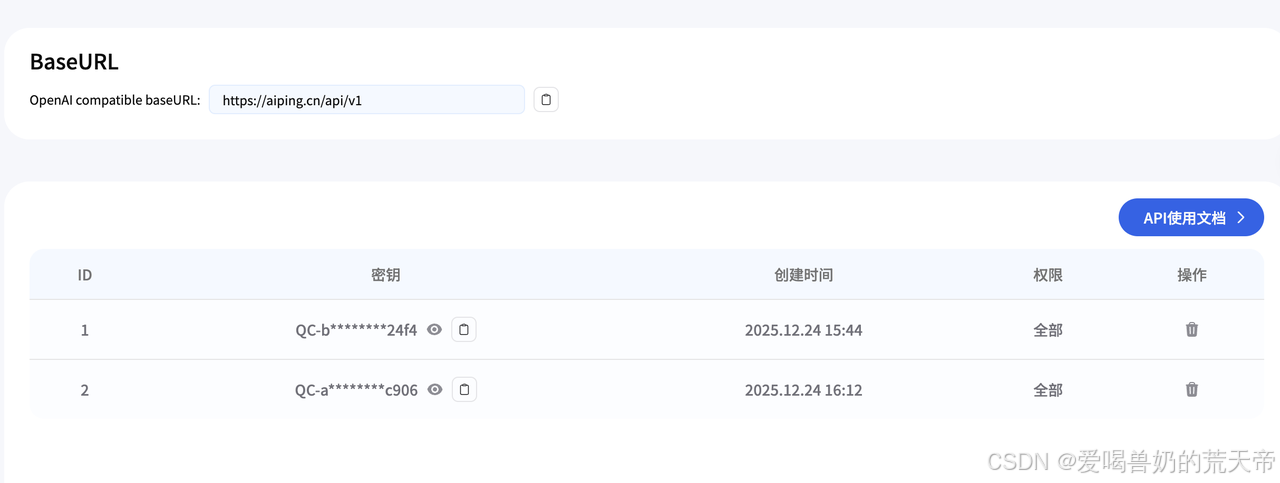
这两项配置适用于任何支持 OpenAI 格式的客户端。为安全起见,建议通过 .env 文件管理密钥,避免提交到版本库。
整个接入过程不到两分钟,且当前所有模型调用均为免费,降低了试错成本。
💻 第三步:GLM-4.7
一、开发环境配置:安装 Kilo Code 插件
为了更贴近日常开发流,我选择使用 Kilo Code —— 一款开源的 VS Code AI Agent 插件(GitHub 可查)。它支持多步任务规划、自动文件创建、模型切换等功能,适合测试模型在复杂任务中的协同能力。
安装方式:
- 在 VS Code 扩展商店搜索 “Kilo Code”;
- 安装后,在插件设置中添加自定义提供商;
- 填入上述 Base URL 与 API Key;
- 保存并重启插件。
二、GLM-4.7 测评:面向复杂任务的一次性交付
测试目标
评估模型在系统设计类任务中的结构化输出能力,以下为GLM-4.7 模型配置。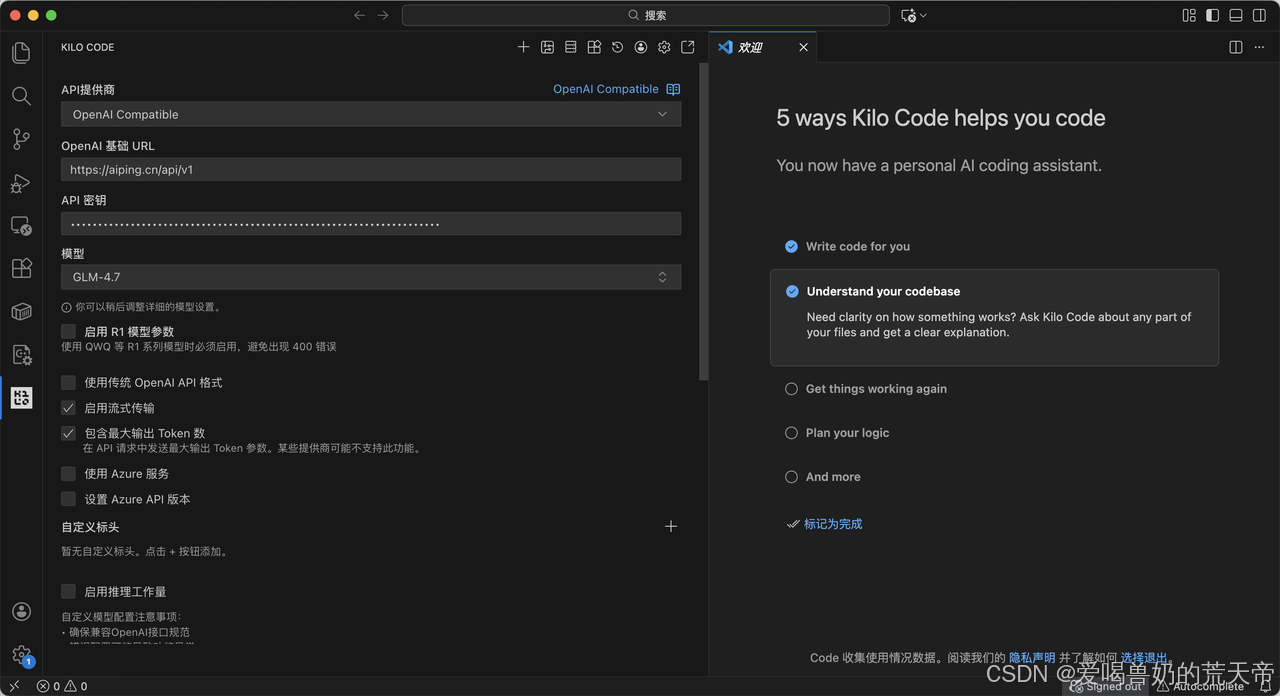
然后滑到最下面点击开始吧,本地环境已具备调用云端大模型的能力,后续只需在插件界面选择模型并输入任务描述即可。
指令输入
“请为一个智能仓储管理系统(WMS)设计完整的技术方案,包含系统架构、核心模块划分、数据库表结构(需考虑批次/库存/货位管理)、API接口列表(支持与AGV/RFID等设备交互)、非功能性需求(如并发处理能力)及安全建议”
执行结果
选择 glm-4.7 模型后,Kilo Code 自动创建 docs/ 目录,并生成多个文件,包括系统概述、架构图、数据库脚本等。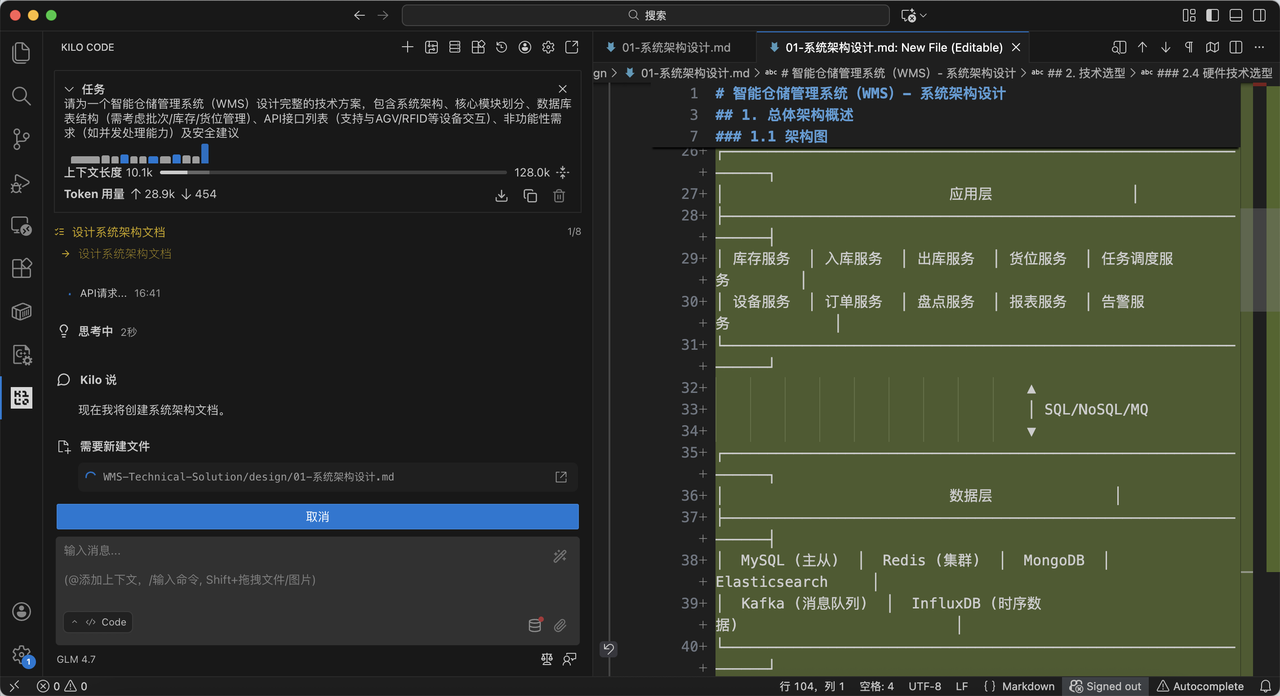
输出内容节选如下:
智能仓储管理系统(WMS)- 系统架构设计
**1. 总体架构概述**
WMS采用**微服务架构**设计,具备高可用、高并发、可扩展的特性。系统基于**分层架构**模式,自下而上分为基础设施层、数据层、服务层、应用层和展示层。
**1.1 架构图**
┌─────────────────────────────────────────────────────────────────┐
│ 展示层 │
├─────────────────────────────────────────────────────────────────┤
│ Web管理端 │ 移动端APP │ H5小程序 │ 数据可视化大屏 │
└─────────────────────────────────────────────────────────────────┘
▲
│ HTTPS/WebSocket/GraphQL
▼
┌─────────────────────────────────────────────────────────────────┐
│ API网关层 │
├─────────────────────────────────────────────────────────────────┤
│ 认证授权 │ 路由转发 │ 限流熔断 │ 负载均衡 │ 日志监控 │
└─────────────────────────────────────────────────────────────────┘
▲
│ gRPC/HTTP
▼
┌─────────────────────────────────────────────────────────────────┐
│ 应用层 │
├─────────────────────────────────────────────────────────────────┤
│ 库存服务 │ 入库服务 │ 出库服务 │ 货位服务 │ 任务调度服务 │
│ 设备服务 │ 订单服务 │ 盘点服务 │ 报表服务 │ 告警服务 │
└─────────────────────────────────────────────────────────────────┘
▲
│ SQL/NoSQL/MQ
▼
┌─────────────────────────────────────────────────────────────────┐
│ 数据层 │
├─────────────────────────────────────────────────────────────────┤
│ MySQL (主从) │ Redis (集群) │ MongoDB │ Elasticsearch │
│ Kafka (消息队列) │ InfluxDB (时序数据) │
└─────────────────────────────────────────────────────────────────┘
▲
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 设备层 │
├─────────────────────────────────────────────────────────────────┤
│ AGV小车 │ RFID读写器 │ 堆垛机 │ 输送线 │ 分拣机 │ 门禁 │
└─────────────────────────────────────────────────────────────────┘
能力分析
GLM-4.7 展现出较强的任务拆解与逻辑组织能力。它没有停留在泛泛而谈,而是输出了可直接用于开发评审的结构化文档。尤其在安全建议部分,提到了具体算法参数和风控阈值,体现出对工程细节的理解。
这类任务通常需要人工查阅资料、反复修改,而模型一次性完成,显著提升了前期设计效率。
💻 第四步:MiniMax M2.1
测试目标
验证模型在系统编程****语言(如 Python)中的代码生成质量,以下为MiniMax M2.1 模型配置。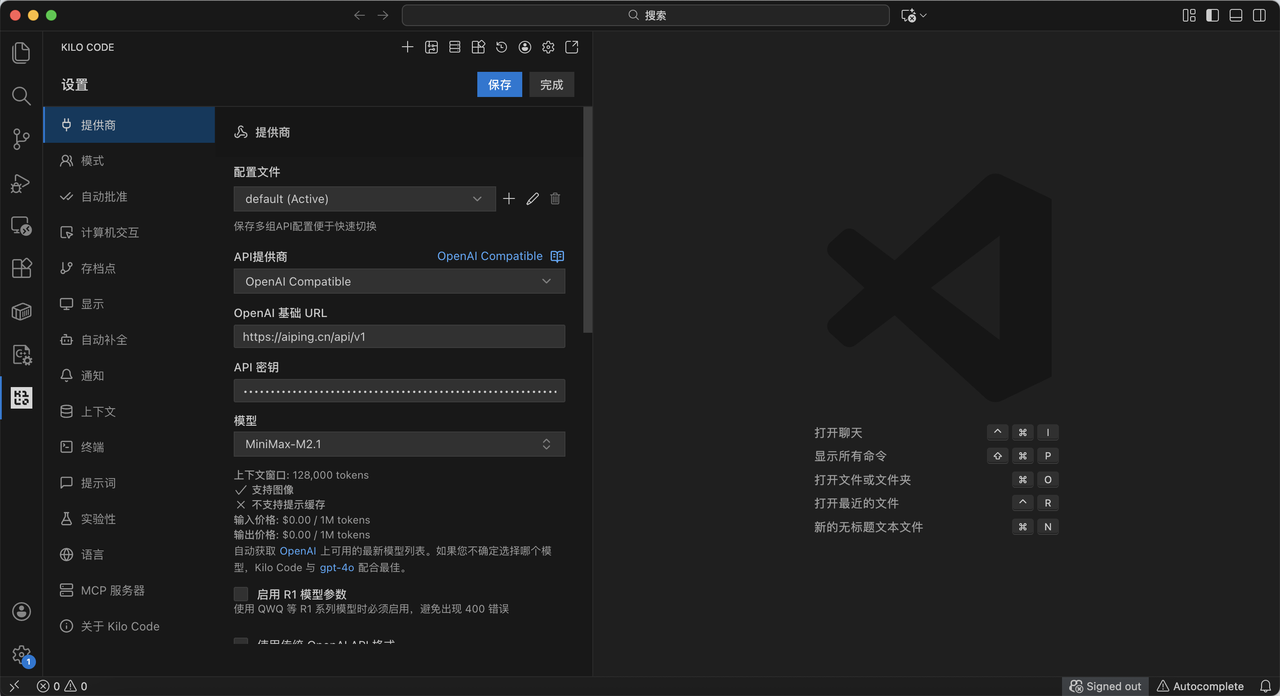
指令输入
“用 Python 写一个基于 Redis 的分布式任务队列系统,包含任务发布、消费者工作进程、任务重试机制、优先级队列支持,返回完整可运行的代码”
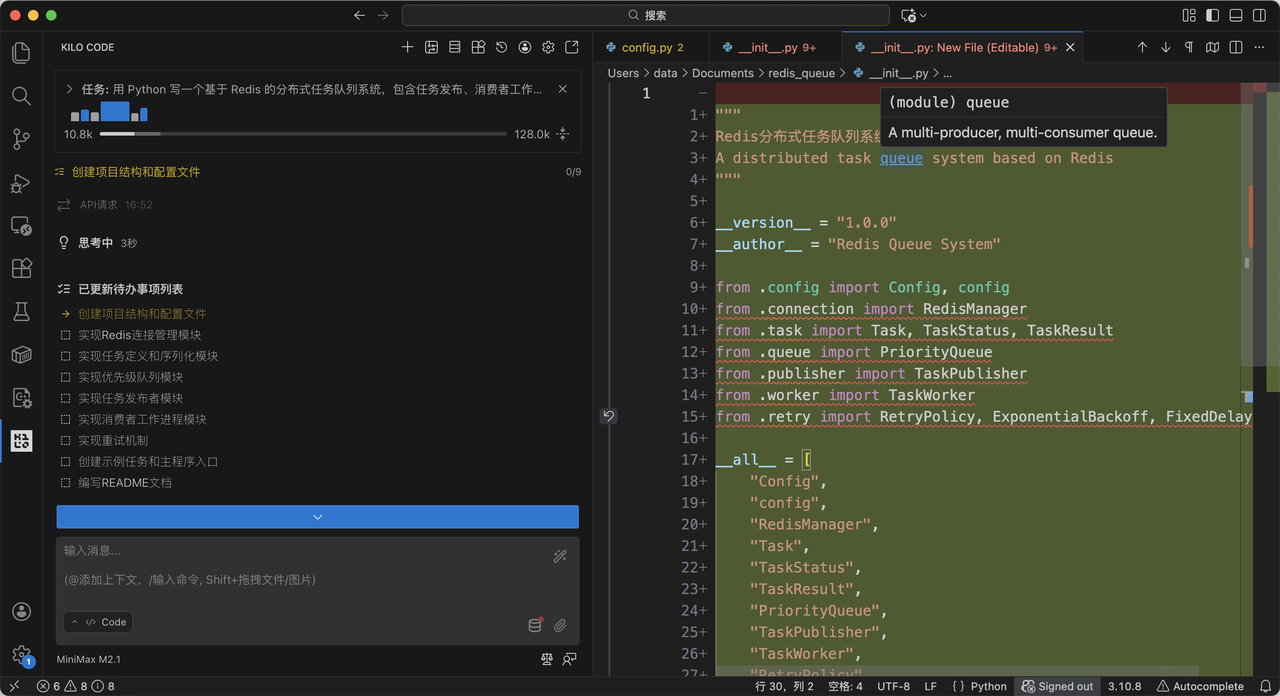
执行结果
切换至 minimax-m2.1 模型后,Kilo Code 生成 redis_queue/config.py 和对应的配置文件。
核心实现如下:
"""
Redis分布式任务队列系统 - 配置文件
"""
import os
from dataclasses import dataclass
from typing import Optional
@dataclass
class RedisConfig:
"""Redis配置类"""
host: str = "localhost"
port: int = 6379
db: int = 0
password: Optional[str] = None
max_connections: int = 50
socket_timeout: int = 30
socket_connect_timeout: int = 5
@dataclass
class QueueConfig:
"""队列配置类"""
# 队列名称
default_queue: str = "task_queue"
priority_prefix: str = "priority:"
# 任务过期时间(秒)
task_ttl: int = 86400 # 24小时
retry_ttl: int = 604800 # 7天
# 重试配置
max_retries: int = 3
retry_delays: tuple = (1, 5, 30) # 重试间隔(秒)
# 消费者配置
prefetch_count: int = 10
poll_interval: float = 0.1 # 轮询间隔
heartbeat_interval: int = 30 # 心跳间隔
@dataclass
class WorkerConfig:
"""工作进程配置类"""
worker_id: Optional[str] = None
concurrency: int = 1
graceful_shutdown_timeout: int = 30
auto_reconnect: bool = True
reconnect_delay: float = 1.0
class Config:
"""配置管理器"""
def __init__(self):
self.redis = RedisConfig(
host=os.getenv("REDIS_HOST", "localhost"),
port=int(os.getenv("REDIS_PORT", 6379)),
db=int(os.getenv("REDIS_DB", 0)),
password=os.getenv("REDIS_PASSWORD", None)
)
self.queue = QueueConfig()
self.worker = WorkerConfig()
def get_redis_url(self) -> str:
"""获取Redis连接URL"""
if self.redis.password:
return f"redis://:{self.redis.password}@{self.redis.host}:{self.redis.port}/{self.redis.db}"
return f"redis://{self.redis.host}:{self.redis.port}/{self.redis.db}"
# 全局配置实例
config = Config()
📊 如何根据场景选择模型?
如果你还在纠结选哪个,这个快速决策树能帮你:
你要解决的任务是什么?
├── 需要**一次性完成**一个复杂、完整的项目(如:生成一个带界面的完整应用)?
│ └── 选 **GLM-4.7**
└── 需要模型**长时间运行**,处理多步骤、持续性的任务(如:持续调试代码、数据监控Agent)?
├── 主要用 **Rust/Go/Java/C++** 等后端语言?
│ └── 选 **MiniMax M2.1**
├── 需要处理超长上下文(20万 tokens)?
│ └── 选 **MiniMax M2.1**
└── 其他
└── 两款都可以试试,按效果和速度偏好选择。
总结
通过本次测试,我确认了一个趋势:国产大模型正从“演示型 AI”转向“工程型助手”。GLM-4.7 和 MiniMax M2.1 分别在一次性交付与持续编码两个维度上展现出实用价值。
而像 AI Ping这样的平台,则让这种能力变得触手可及——无需部署、无需付费、接口标准,普通开发者也能快速验证模型是否适配自身业务。
如果你也在做系统设计、自动化开发或 Agent 构建,不妨亲自试试。只需十几分钟配置,或许就能节省数小时重复劳动。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)