【OpenAI】【全面解析】大数据技术全景指南:架构、核心组件与实战应用获取OpenAI API KEY的两种方式,开发者必看全方面教程!
Volume(大量):数据规模从TB到PB甚至更大Velocity(高速):数据生成和处理速度快Variety(多样):结构化、半结构化、非结构化数据共存Veracity(真实性):数据质量和可信度需保证Value(价值):从数据中挖掘商业价值通过以上步骤,你已经掌握了如何获取和使用 OpenAI API Key 的基本流程。无论你是开发者还是技术爱好者,掌握这些技能都将为你的项目增添无限可能!?
@[TOC]# 【全面解析】大数据技术全景指南:架构、核心组件与实战应用
你是否想了解大数据的核心技术和实际应用?本文将带你系统梳理大数据的架构体系、关键技术栈以及行业落地案例,助你快速掌握大数据核心技能,抢占数字经济风口!
引言:大数据时代的机遇与挑战
随着互联网、物联网、移动互联网的爆发,数据量呈指数级增长。大数据不仅是海量数据的代名词,更是驱动企业数字化转型的关键引擎。如何高效存储、处理和分析这些数据,成为企业竞争力的重要体现。
本文将从大数据的基本概念入手,深入解析大数据架构、核心技术、主流工具及典型应用场景,帮助你构建完整的大数据知识体系。
一、大数据基础概念
1.1 什么是大数据?
大数据指的是规模巨大、类型多样、增长快速的数据集合,通常具备以下“5V”特征:
- Volume(大量):数据规模从TB到PB甚至更大
- Velocity(高速):数据生成和处理速度快
- Variety(多样):结构化、半结构化、非结构化数据共存
- Veracity(真实性):数据质量和可信度需保证
- Value(价值):从数据中挖掘商业价值
1.2 大数据的价值
通过大数据分析,企业可以实现精准营销、风险控制、用户画像、智能推荐等,提升决策效率和业务创新能力。
二、大数据架构体系
2.1 Lambda架构
Lambda架构结合批处理和流处理,分为三层:
- 批处理层:离线处理海量数据,保证结果准确
- 速度层:实时处理最新数据,保证低延迟
- 服务层:将批处理和实时结果合并,提供统一查询接口
2.2 Kappa架构
Kappa架构简化Lambda架构,全部采用流处理,适合实时性要求高且批处理需求较少的场景。
三、大数据核心技术栈
3.1 数据存储
- HDFS:分布式文件系统,支持海量数据存储
- NoSQL数据库:如HBase、Cassandra,支持高并发读写和灵活数据模型
- 分布式数据库:如TiDB,兼顾关系型和分布式特性
3.2 数据处理
- 批处理框架:Hadoop MapReduce、Spark
- 流处理框架:Apache Flink、Apache Kafka Streams、Apache Storm
3.3 数据分析与挖掘
- 机器学习平台:Spark MLlib、TensorFlow、XGBoost
- 数据可视化工具:Tableau、Power BI、Superset
3.4 数据采集与传输
- 数据采集:Flume、Sqoop、Kafka
- 数据传输:Kafka、RocketMQ
四、大数据实战案例
4.1 电商用户行为分析
通过采集用户点击、浏览、购买数据,利用Spark进行离线分析,结合Flink实现实时推荐,提升用户转化率。
4.2 金融风控系统
利用大数据平台整合多源数据,构建风险模型,实现实时欺诈检测和预警。
4.3 智慧城市建设
通过物联网设备采集交通、环境数据,利用大数据分析优化城市资源配置和应急响应。
五、如何快速入门大数据?
5.1 学习路线
- 掌握Linux基础和Shell脚本
- 学习Java或Scala编程
- 熟悉Hadoop生态系统(HDFS、MapReduce、YARN)
- 深入Spark和Flink流批一体化处理
- 掌握Kafka消息队列和NoSQL数据库
- 实践数据分析与机器学习基础
5.2 环境搭建建议
- 使用Docker快速搭建Hadoop、Spark集群
- 利用云服务(阿里云、AWS、Azure)体验大数据平台
- 参与开源项目,积累实战经验
六、未来趋势展望
- 云原生大数据:容器化、微服务架构提升弹性和扩展性
- AI与大数据融合:深度学习驱动智能分析和自动化决策
- 边缘计算结合:实现数据近源处理,降低延迟
- 数据安全与隐私保护:加强合规和技术保障,构建可信数据生态
大数据技术正深刻改变各行各业的运营模式和商业逻辑。掌握大数据核心技术和应用方法,将为你的职业发展和企业创新注入强大动力。
第一种方式(国外):获取 OpenAI API Key
要开始使用 OpenAI 的服务,你首先需要获取一个 API Key。以下是获取 API Key 的详细步骤:
1. 访问 OpenAI
在浏览器中点击 OpenAI 。
2. 创建账户
- 点击网站右上角的“Sign Up”或者选择“Login”登录已有用户。
3. 进入 API 管理界面
- 登录后,导航到“API Keys”部分。
4. 生成新的 API Key
- 在 API Keys 页面,点击“Create new key”按钮,按照提示完成 API Key 的创建。
注意:创建 API Key 后,务必将其保存在安全的地方,避免泄露。🔒

使用 OpenAI API
现在你已经拥有了 API Key 并完成了充值,接下来是如何在你的项目中使用 GPT-4.0 API。以下是一个简单的 Python 示例,展示如何调用 API 生成文本:
import openai
import os
# 设置 API Key
openai.api_key = os.getenv("OPENAI_API_KEY")
# 调用 GPT-4.0 API
response = openai.Completion.create(
model="gpt-4.0-turbo",
prompt="鲁迅与周树人的关系。",
max_tokens=100
)
# 打印响应内容
print(response.choices[0].text.strip())
代码解析
- 导入库:首先导入必要的库。
- 设置 API Key:通过环境变量设置 API Key。
- 调用 API:发送一个包含问题的请求到 GPT-4.0 模型。
- 打印响应:打印出模型生成的答案。
通过这段代码,你可以轻松地与 OpenAI 的 GPT-4.0 模型进行交互,获取你所需的文本内容。✨
第二种方式(国内):获取 能用AI API Key
要开始使用 能用AI 的服务,以下是获取 API Key 的详细步骤:
1. 点击 [能用AI 工具]
在浏览器中打开 能用AI 工具。
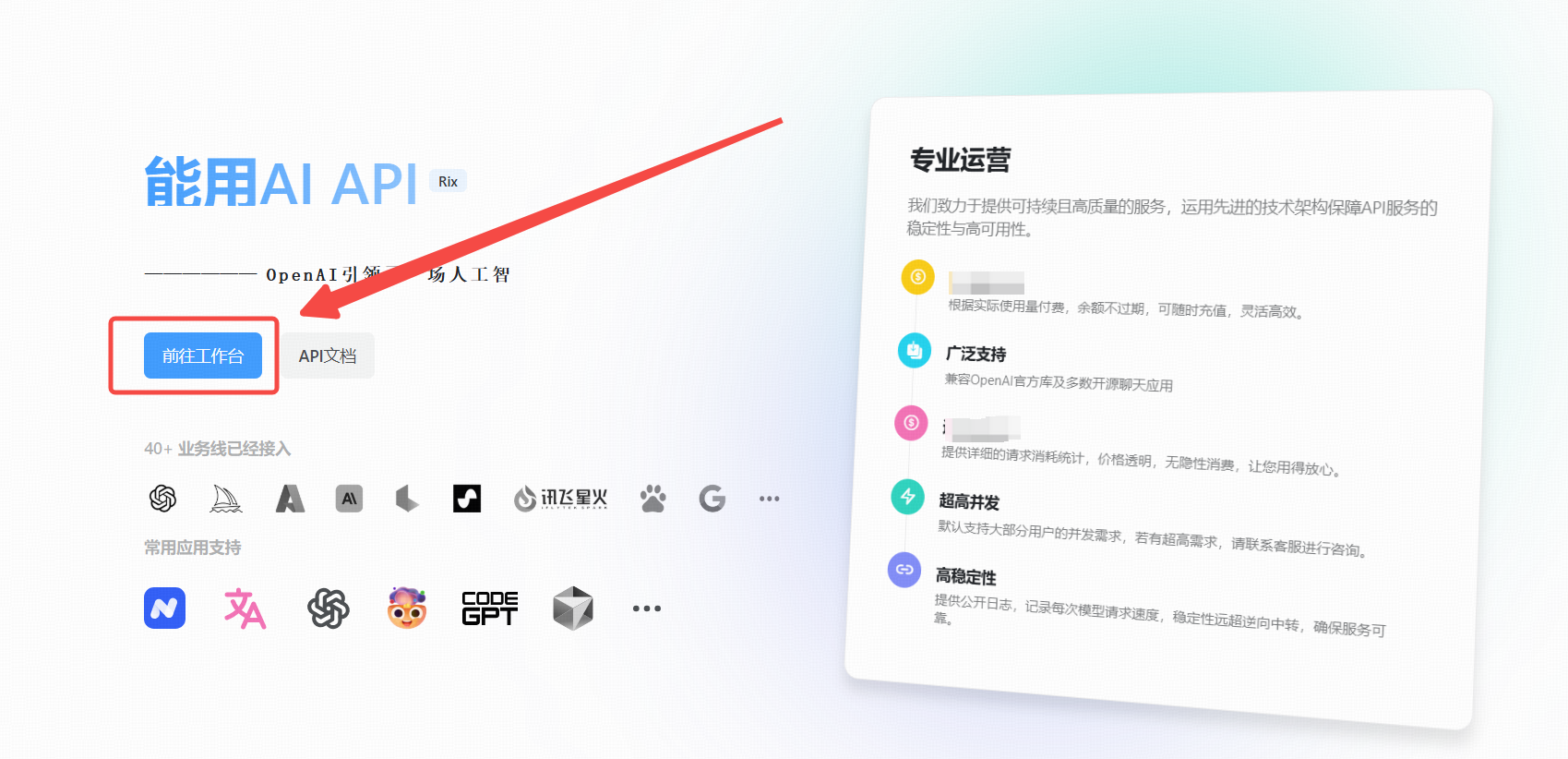
2. . 进入 API 管理界面
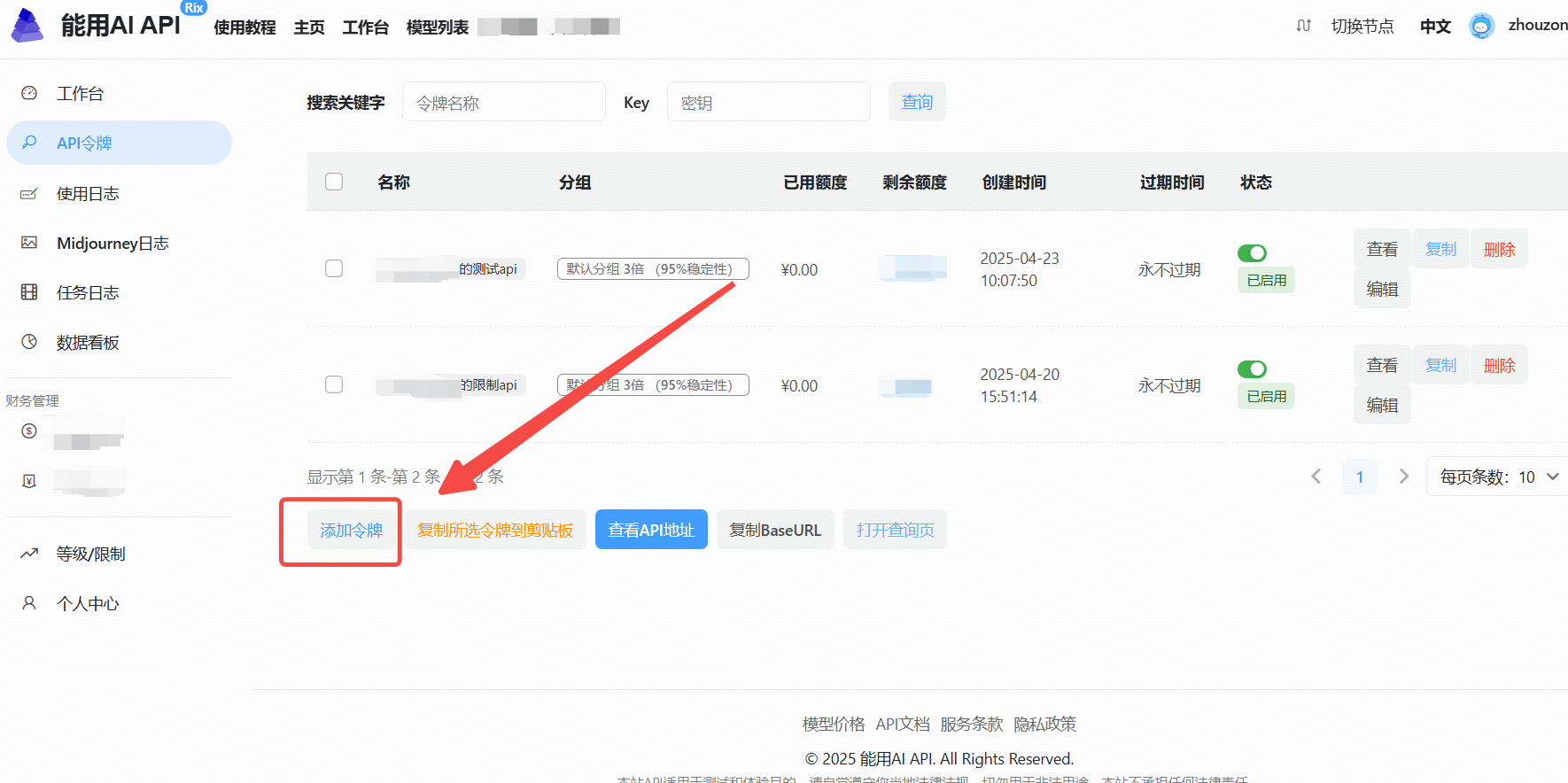
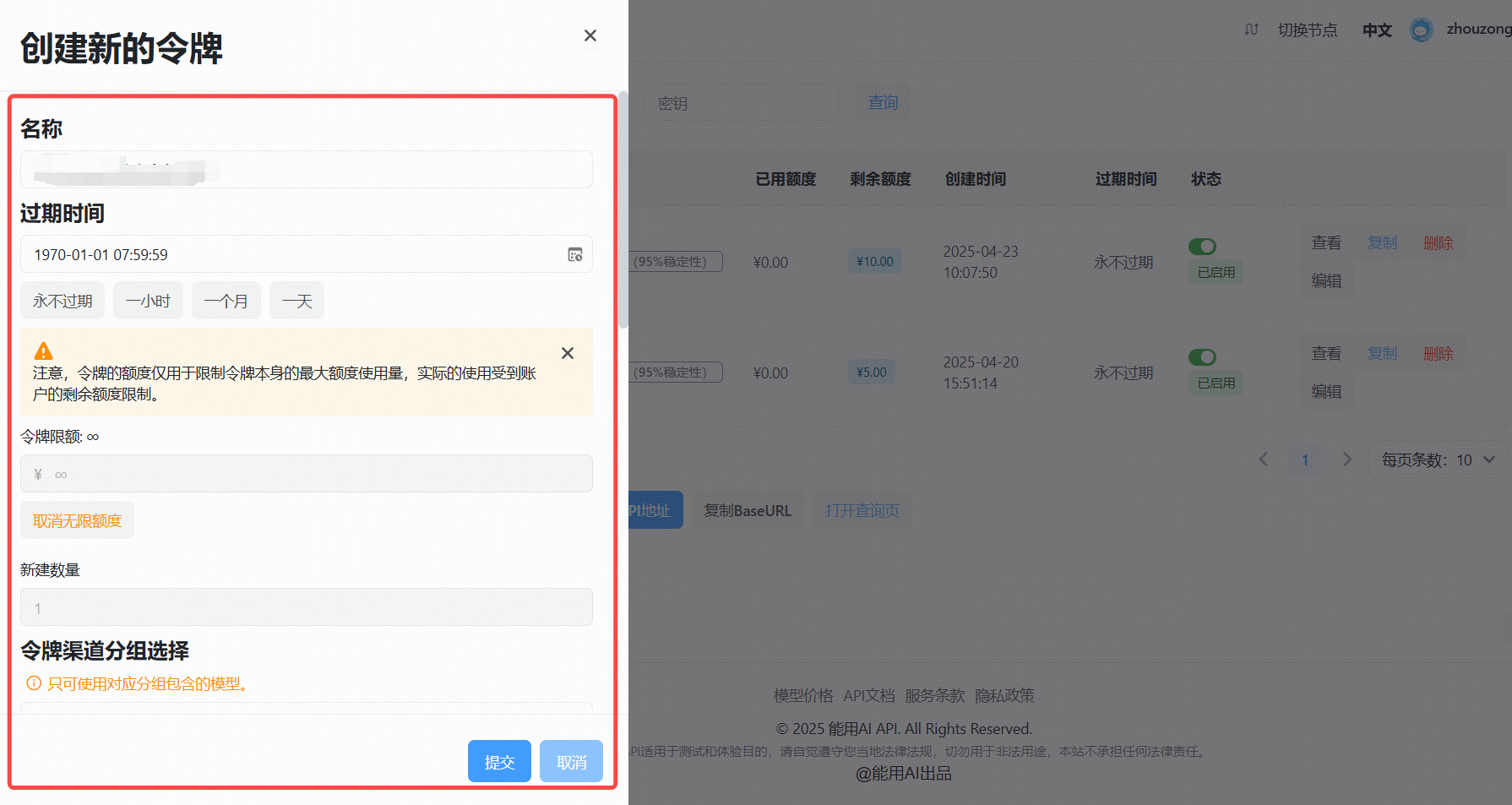
3. 生成新的 API Key
创建成功后点击“查看KEY”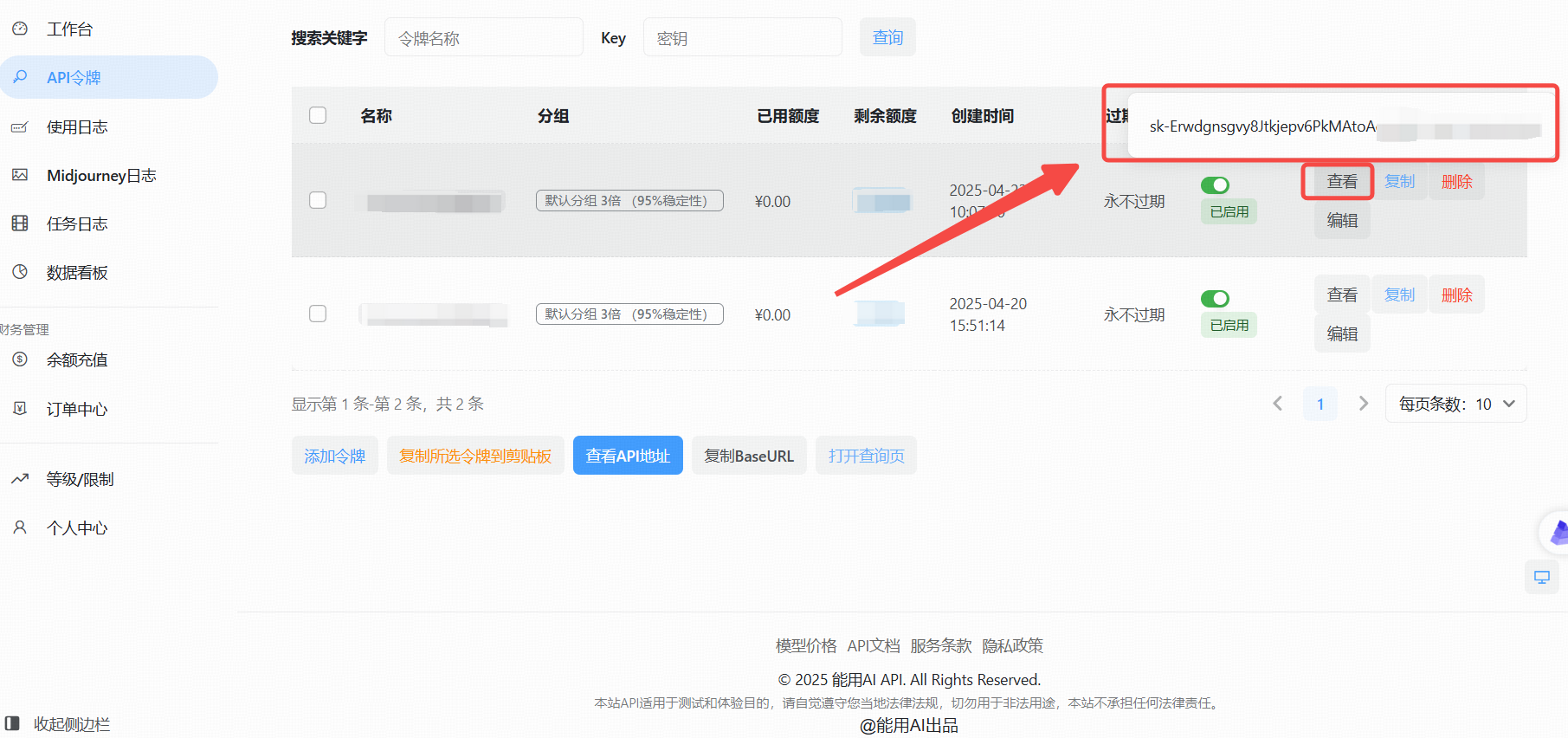
4. 调用代码使用 能用AI API
# [调用API:具体模型大全](https://flowus.cn/codemoss/share/42cfc0d9-b571-465d-8fe2-18eb4b6bc852)
from openai import OpenAI
client = OpenAI(
api_key="这里是能用AI的api_key",
base_url="https://ai.nengyongai.cn/v1"
)
response = client.chat.completions.create(
messages=[
{'role': 'user', 'content': "鲁迅为什么打周树人?"},
],
model='gpt-4',
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="", flush=True)
总结
通过以上步骤,你已经掌握了如何获取和使用 OpenAI API Key 的基本流程。无论你是开发者还是技术爱好者,掌握这些技能都将为你的项目增添无限可能!🌟

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)