机器学习044:深度学习【经典神经网络】卷积神经网络(CNN)池化层 -- 从“细节海洋”到“特征灯塔”的智慧导航
卷积神经网络(CNN)中的池化层是AI实现高效图像识别的关键组件。它通过"抓大放小"的方式,像人类视觉一样提取关键特征而非记忆所有细节。池化层主要有最大池化和平均池化两种类型,能有效实现特征不变性、降维减负、防止过拟合等功能。虽然会损失部分空间信息,但在图像分类、目标检测等场景表现优异。从手机人脸解锁到自动驾驶,从医疗诊断到社交媒体标签,池化层技术已深度融入现代AI应用。尽管存
当AI学会“抓大放小”
想象一下,你第一次看到一张埃菲尔铁塔的照片。你的大脑不会记住每一块铁锈的纹路、每一片云彩的精确形状,而是迅速捕捉到“高耸的铁架结构”“巴黎的地标”“三角形的轮廓”这些关键特征。这种“抓大放小”的能力,正是人类智能的精妙之处。而今天,人工智能也学会了这项技能——其中的关键功臣,就是卷积神经网络(CNN)中的池化层。
让我们一起走进这个让AI从“像素观察员”成长为“特征侦探”的神奇世界。
一、分类归属:CNN在AI家族中的“身份牌”
1.1 神经网络家族的“视觉专家”
在庞大的人工神经网络家族中,卷积神经网络(Convolutional Neural Network, CNN)属于:
- 按网络结构拓扑划分:空间特征提取类网络(专门处理网格状数据)
- 按功能用途划分:图像识别与计算机视觉任务的“王牌选手”
- 按数据处理方式划分:前馈神经网络的一种特殊形式(信息单向流动)
1.2 诞生时刻:从学术论文到改变世界
- 提出者:被誉为“卷积网络之父”的Yann LeCun(杨立昆)
- 关键时间节点:
- 1989年:LeCun在贝尔实验室首次将CNN应用于手写数字识别
- 1998年:提出经典的LeNet-5架构,成功识别银行支票上的手写数字
- 2012年:AlexNet在ImageNet竞赛中夺冠,准确率大幅领先,引爆深度学习革命
1.3 核心使命:解决传统神经网络的“视觉困境”
在CNN出现之前,传统全连接神经网络处理图像时面临三大难题:
问题显而易见:
- 参数爆炸:一张普通图片就有数百万个参数需要学习
- 计算灾难:训练时间和计算资源呈指数级增长
- 忽略空间关系:把图片“压扁”成一维数据,丢失了像素间的空间关联
CNN的智慧回答:“我们不需要观察每一片树叶来认识一棵树。”
二、底层原理:池化层的“化繁为简”之道
2.1 整体架构:CNN的三级火箭系统
2.2 核心设计:局部感受野与权值共享
类比理解:想象你在读一本侦探小说
- 传统神经网络:必须记住每一页每一个字的位置和内容
- 卷积神经网络:像聪明的侦探,只关注关键线索出现的“模式”
- 局部感受野:每次只关注一页中的一个段落(局部区域)
- 权值共享:用同样的“线索识别技巧”扫描整本书
2.3 池化层的本质:特征地图的“精华提炼师”
生活化类比1:选美比赛的“评委筛选”
假设你是一位选美比赛的评委,面前有100位选手的照片:
- 第一步(卷积层):仔细观察每位选手,记录她们的眼睛大小、鼻梁高度、笑容弧度等细节特征
- 第二步(池化层):从每4位选手中选出“笑容最灿烂的那位”,其他人暂时离场
- 结果:从100位选手 → 25位关键选手,保留了“最具代表性的笑容”信息
生活化类比2:地图的“比例尺缩放”
当你从城市地图切换到国家地图时:
- 细节丢失:看不到每个红绿灯的具体位置
- 特征保留:仍然能看到主要城市、山脉、河流的相对位置关系
- 这就是池化:降低分辨率,保留拓扑结构
2.4 池化操作的两种主要类型
最大池化(Max Pooling):选“最能代表的人”
通俗解释:在2×2的小区域中,只保留数值最大的那个特征。就像在四人小组中,只让“发言最有价值”的那个人代表全组。
数学表达(简单版):
输出 = max(区域内的所有值)
平均池化(Average Pooling):听“大家的平均意见”
通俗解释:计算2×2区域内所有数值的平均值。就像小组讨论后,取一个“综合意见”。
数学表达(简单版):
输出 = (区域内所有值之和) ÷ 区域大小
2.5 池化层的五大神奇功效
-
特征不变性:铁塔照片稍微移动几个像素?不影响识别!
- 池化后,特征的位置信息变得“模糊但稳定”
-
降维减负:数据量减少75%(以2×2池化为例)
- 计算速度大幅提升,内存占用显著降低
-
防止过拟合:避免“死记硬背”每一个像素
- 就像学生理解概念,而不是背诵整本教科书
-
扩大感受野:高层神经元能看到图像的更大范围
- 从“看像素”到“看轮廓”再到“看物体”
-
引入平移鲁棒性:物体在图像中轻微移动不影响识别
- 人脸稍微偏左或偏右,仍然能被认出
三、局限性:没有银弹,只有合适的工具
3.1 空间信息丢失:细节的“牺牲”
问题表现:池化层的“压缩”是永久性的
- 就像把高清照片转为缩略图后,再也无法恢复原始细节
- 为什么存在:为了效率和不变性,必须放弃某些空间精度
3.2 固定操作模式:缺乏“灵活性”
问题表现:最大池化只取最大值,平均池化只取平均值
- 不管区域内的特征分布如何,都采用同样的“粗暴”策略
- 可能导致:重要但非最大的特征被丢弃
3.3 对空间层次结构不敏感
问题表现:池化操作不考虑特征的相对位置关系
- 知道“有眼睛和嘴巴”,但不清楚“眼睛在嘴巴上方”
- 特殊场景问题:在需要精确定位的任务(如医学图像分割)中可能不足
3.4 现代改进:更智能的“池化”思路
- 步幅卷积替代:用带有步幅的卷积直接实现下采样
- 空间金字塔池化:多尺度池化,兼顾不同层次的特征
- 可学习的池化:让网络自己决定如何“总结”特征
四、使用范围:什么时候该请出这位“特征总结师”
适合使用CNN(含池化层)的场景 ✅
| 场景类型 | 为什么适合 | 池化层的具体作用 |
|---|---|---|
| 图像分类 | 核心需求是识别“是什么”,而非“精确在哪” | 提取关键特征,忽略位置微小变化 |
| 目标检测 | 需要从复杂背景中找到物体 | 逐步抽象,从边缘到部件再到物体 |
| 图像识别 | 如人脸识别、车牌识别 | 增强模型对光照、角度变化的鲁棒性 |
| 视频分析 | 视频本质是图像序列 | 减少时间维度上的冗余信息 |
| 医学影像 | X光片、CT扫描等 | 聚焦病变区域的关键特征 |
不适合使用传统池化层的场景 ❌
| 场景类型 | 为什么不适合 | 更好的选择 |
|---|---|---|
| 图像分割 | 需要精确到像素级的定位 | 全卷积网络(FCN)、U-Net |
| 超分辨率重建 | 需要恢复细节,而非丢弃细节 | 反卷积、亚像素卷积 |
| 生成对抗网络 | 需要生成高分辨率细节 | 转置卷积、可学习上采样 |
| 姿态估计 | 需要精确的关键点坐标 | 热图回归、坐标直接预测 |
| 图像配准 | 需要亚像素级的对齐精度 | 空间变换网络 |
五、应用场景:池化层在现实世界中的“高光时刻”
5.1 人脸识别解锁:你的脸就是密码
工作原理流程:
手机摄像头 → 捕捉面部图像 → CNN卷积层提取局部特征
→ 池化层压缩关键信息 → 更高层理解五官关系
→ 全连接层对比特征 → 判断“是否匹配机主”
池化层的特殊贡献:
- 你稍微歪头?不影响识别(平移不变性)
- 光线变化?关键特征仍被保留(鲁棒性增强)
- 快速响应?得益于数据压缩(效率提升)
5.2 自动驾驶的“眼睛”:实时看懂道路
特斯拉Autopilot等系统的视觉感知:
8个摄像头同时输入 → 多路CNN并行处理
→ 池化层从每帧提取道路、车辆、行人特征
→ 时间维度上整合 → 理解物体运动轨迹
→ 决策系统规划路径
池化层的核心价值:
- 在高速行驶中,车辆不需要看清每一片树叶的纹理
- 需要快速判断:“前方是障碍物还是阴影?”
- 池化层帮助系统抓住“形状”“颜色块”“运动趋势”等关键线索
5.3 医疗影像辅助诊断:AI医生的“第二意见”
肺结节CT扫描分析:
薄层CT扫描(数百张图像) → 3D CNN处理
→ 三维池化层在空间三个维度上压缩
→ 聚焦疑似结节区域的特征
→ 输出恶性概率评估
池化层的医学意义:
- 减少放射科医生需要查看的图像数量级
- 在不同患者的扫描中,结节的位置、大小各异,池化增强泛化能力
- 帮助识别“毛玻璃状”“分叶状”等关键形态特征
5.4 社交媒体:自动标签与内容审核
Instagram照片自动标记:
用户上传照片 → CNN分析图像内容
→ 池化层提取场景特征(海滩、城市、食物等)
→ 识别物体特征(人脸、动物、建筑等)
→ 自动添加标签建议
池化层的内容理解:
- 照片中人物在不同的位置?不影响识别“有人脸存在”
- 不同用户拍摄的同一景点角度各异?仍能识别“这是埃菲尔铁塔”
- 快速处理每天数十亿张上传图片
5.5 艺术风格迁移:将世界名画的风格“借”给你的照片
Prisma、DeepArt等应用的核心:
输入:你的照片 + 梵高的《星月夜》
→ CNN提取照片的内容特征
→ 另一路CNN提取名画的艺术风格特征
→ 池化层帮助分离“内容”与“风格”
→ 生成具有梵高风格的个人照片
池化层的艺术作用:
- 帮助网络理解“哪些是内容结构”(需要保留)
- 识别“哪些是风格纹理”(需要迁移)
- 实现内容与风格在特征空间的高效分离
六、实践案例:用Python亲手实现一个带池化层的CNN
6.1 环境准备与数据加载
# 初学者友好版本,使用Keras高级API
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
# 加载经典的MNIST手写数字数据集
# 这是深度学习界的“Hello World”
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# 数据预处理:归一化和调整维度
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255.0
print(f"训练集形状: {x_train.shape}") # (60000, 28, 28, 1)
print(f"测试集形状: {x_test.shape}") # (10000, 28, 28, 1)
6.2 构建包含池化层的CNN模型
def create_simple_cnn():
model = keras.Sequential([
# 第一层:卷积层 + 池化层
layers.Conv2D(
filters=32, # 32个不同的特征检测器
kernel_size=(3, 3), # 3x3的滑动窗口
activation='relu', # 激活函数:让网络能学习复杂模式
input_shape=(28, 28, 1), # 输入图像尺寸
padding='same' # 边缘填充,保持尺寸不变
),
# ↓↓↓ 这就是我们今天的主角:池化层 ↓↓↓
layers.MaxPooling2D(
pool_size=(2, 2), # 2x2的池化窗口
strides=2 # 每次移动2个像素(不重叠)
),
# 解释:28x28 → 经过池化 → 14x14(尺寸减半!)
# 第二层:卷积层 + 池化层
layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
layers.MaxPooling2D((2, 2), strides=2), # 14x14 → 7x7
# 展平层:将二维特征图转换为一维向量
layers.Flatten(),
# 全连接层:做最终决策
layers.Dense(128, activation='relu'),
# 输出层:10个数字类别(0-9)
layers.Dense(10, activation='softmax')
])
return model
# 创建模型实例
model = create_simple_cnn()
# 查看模型结构摘要
model.summary()
6.3 可视化池化层的作用
import matplotlib.pyplot as plt
def visualize_pooling_effect():
# 选择一张测试图片
sample_image = x_test[0].reshape(28, 28)
# 模拟池化操作
def manual_max_pooling(image, pool_size=2):
h, w = image.shape
pooled = np.zeros((h//pool_size, w//pool_size))
for i in range(0, h, pool_size):
for j in range(0, w, pool_size):
region = image[i:i+pool_size, j:j+pool_size]
pooled[i//pool_size, j//pool_size] = np.max(region)
return pooled
# 应用池化
pooled_image = manual_max_pooling(sample_image)
# 可视化对比
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
axes[0].imshow(sample_image, cmap='gray')
axes[0].set_title('原始图像 (28×28像素)')
axes[0].axis('off')
axes[1].imshow(pooled_image, cmap='gray')
axes[1].set_title('池化后图像 (14×14像素)\n保留了数字"7"的关键形状')
axes[1].axis('off')
plt.show()
print(f"原始图像像素数: {28*28} = 784")
print(f"池化后像素数: {14*14} = 196")
print(f"数据压缩率: {(1-196/784)*100:.1f}%")
# 运行可视化
visualize_pooling_effect()
6.4 训练与评估模型
# 编译模型:配置学习过程
model.compile(
optimizer='adam', # 智能调整学习速度的优化器
loss='sparse_categorical_crossentropy', # 分类任务的标准损失函数
metrics=['accuracy'] # 我们关心准确率
)
# 训练模型(简单版本,实际需要更多轮次)
print("开始训练...")
history = model.fit(
x_train, y_train,
batch_size=64, # 每次用64张图片更新权重
epochs=5, # 遍历整个训练集5次
validation_split=0.2, # 20%训练数据用于验证
verbose=1 # 显示进度条
)
# 评估模型性能
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(f"\n测试集准确率: {test_acc*100:.2f}%")
print(f"测试集损失: {test_loss:.4f}")
# 实际预测示例
def predict_example():
# 随机选择5张测试图片
indices = np.random.choice(len(x_test), 5)
predictions = model.predict(x_test[indices])
predicted_labels = np.argmax(predictions, axis=1)
plt.figure(figsize=(15, 3))
for i, idx in enumerate(indices):
plt.subplot(1, 5, i+1)
plt.imshow(x_test[idx].reshape(28, 28), cmap='gray')
plt.title(f'真实:{y_test[idx]}\n预测:{predicted_labels[i]}')
plt.axis('off')
plt.tight_layout()
plt.show()
predict_example()
6.5 观察池化层的特征响应
# 创建一个中间层输出模型,可视化池化前后的特征图
layer_outputs = [layer.output for layer in model.layers[:4]] # 获取前4层输出
activation_model = keras.Model(inputs=model.input, outputs=layer_outputs)
# 选择一张图片
test_img = x_test[15:16] # 保持batch维度
activations = activation_model.predict(test_img)
# 可视化不同层的特征图
layer_names = ['卷积层1输出', '池化层1输出', '卷积层2输出', '池化层2输出']
fig, axes = plt.subplots(4, 8, figsize=(16, 8))
for i, (name, activation) in enumerate(zip(layer_names, activations)):
# 显示该层前8个特征图
for j in range(8):
ax = axes[i, j]
if i % 2 == 0: # 卷积层输出
ax.imshow(activation[0, :, :, j], cmap='viridis')
else: # 池化层输出
ax.imshow(activation[0, :, :, j], cmap='plasma')
if j == 0:
ax.set_ylabel(name, fontsize=12)
ax.set_xticks([])
ax.set_yticks([])
plt.suptitle('CNN各层特征图可视化\n注意池化层如何压缩空间尺寸但保留激活模式', fontsize=14)
plt.tight_layout()
plt.show()
七、思维导图:CNN池化层的完整知识体系
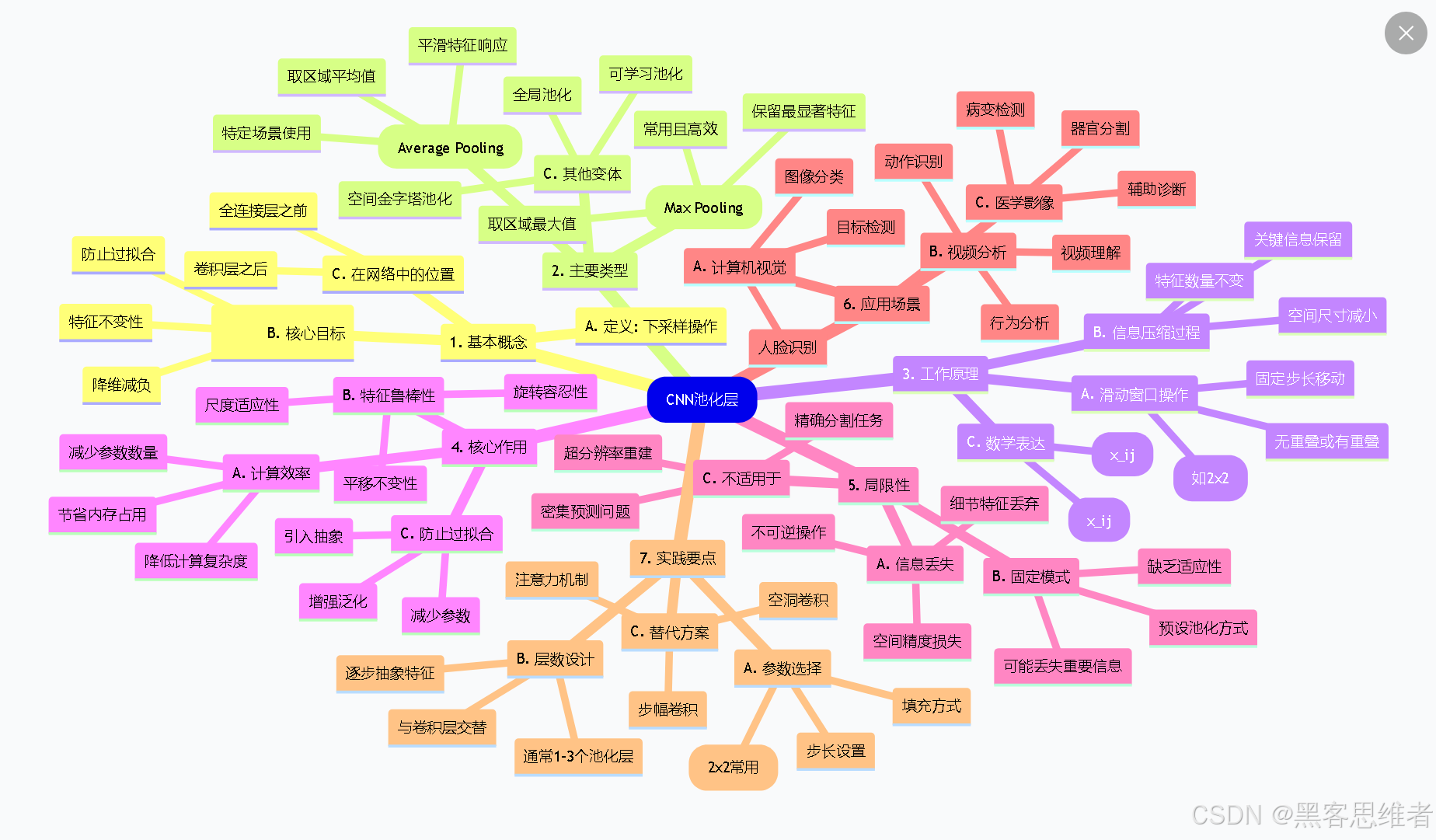
mindmap
root(CNN池化层)
1. 基本概念
A. 定义: 下采样操作
B. 核心目标
::icon(fa fa-bullseye)
特征不变性
降维减负
防止过拟合
C. 在网络中的位置
卷积层之后
全连接层之前
2. 主要类型
A. 最大池化(Max Pooling)
取区域最大值
保留最显著特征
常用且高效
B. 平均池化(Average Pooling)
取区域平均值
平滑特征响应
特定场景使用
C. 其他变体
全局池化
空间金字塔池化
可学习池化
3. 工作原理
A. 滑动窗口操作
固定尺寸窗口(如2x2)
固定步长移动
无重叠或有重叠
B. 信息压缩过程
空间尺寸减小
特征数量不变
关键信息保留
C. 数学表达
最大池化: y=max(x_ij)
平均池化: y=avg(x_ij)
4. 核心作用
A. 计算效率
减少参数数量
降低计算复杂度
节省内存占用
B. 特征鲁棒性
平移不变性
旋转容忍性
尺度适应性
C. 防止过拟合
减少参数
引入抽象
增强泛化
5. 局限性
A. 信息丢失
空间精度损失
细节特征丢弃
不可逆操作
B. 固定模式
预设池化方式
缺乏适应性
可能丢失重要信息
C. 不适用于
精确分割任务
超分辨率重建
密集预测问题
6. 应用场景
A. 计算机视觉
图像分类
目标检测
人脸识别
B. 视频分析
动作识别
行为分析
视频理解
C. 医学影像
病变检测
器官分割
辅助诊断
7. 实践要点
A. 参数选择
池化尺寸(2x2常用)
步长设置
填充方式
B. 层数设计
通常1-3个池化层
与卷积层交替
逐步抽象特征
C. 替代方案
步幅卷积
空洞卷积
注意力机制
总结:从“像素森林”到“特征地图”的智慧之旅
一句话概括池化层的核心价值:
池化层是CNN从“看见所有细节”到“理解本质特征”的关键转折点,它教会了AI如何在信息的海洋中,精准打捞起那些真正重要的“智慧之鱼”。
对于初学者来说,理解池化层最重要的三件事是:
- 它做什么:压缩数据、保留关键特征、增强模型鲁棒性
- 它不做什么:不学习新特征、不改变特征数量、不精确定位
- 何时使用它:当需要位置不变性、计算效率、防止过拟合时
正如人类大脑不会记住每一片浪花的形状,却能理解大海的浩瀚;CNN的池化层不会处理每一个像素的细节,却能识别图像的本质。这种“抓大放小”的智慧,不仅是深度学习的精髓,也是我们在信息爆炸时代值得学习的生活哲学。
记住:好的特征不是知道得更多,而是知道什么更重要。池化层,正是AI世界的“重要性过滤器”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献91条内容
已为社区贡献91条内容

所有评论(0)