Python的人工智能-机器学习
机器学习是人工智能的重要分支,通过数据驱动让计算机自主学习而无需显式编程。主要分为监督学习(分类/回归)、无监督学习(聚类/关联)和强化学习(决策优化)三大类。典型算法包括线性回归、决策树、SVM、KNN和随机森林等。机器学习正面临数据质量、算法偏见等挑战,发展趋势聚焦大模型、AutoML和可信AI等领域。
学习指的是通过学习或经验获得知识或技能。基于此,我们可以定义机器学习(ML)如下 −
它可以被定义为计算机科学领域,更具体地说是人工智能的应用,它为计算机系统提供了利用数据学习并从经验中提升的能力,而无需明确编程。
基本上,机器学习的主要目标是让计算机自动学习,无需人工干预。现在问题来了,如何开始和完成这样的学习?它可以从数据的观察开始。这些数据可以是一些例子、教学或直接的经验。然后,基于这些输入,机器通过寻找数据中的某些模式来做出更好的决策。
机器学习(ML)的类型
机器学习算法帮助计算机在不被明确编程的情况下学习。这些算法分为有监督和无监督。现在让我们看看几个算法——
监督机器学习算法
这是最常用的机器学习算法。之所以称为监督式,是因为从训练数据集中进行算法学习的过程可以看作是教师监督学习过程。在这种机器学习算法中,可能的结果已经已知,训练数据也会标注正确答案。它可以理解为 −
假设我们有输入变量 x 和输出变量 y,并应用算法学习从输入到输出的映射函数,例如 −
Y = f(x)
现在,主要目标是将映射函数近似得非常好,这样当我们有了新的输入数据(x)时,可以预测该数据的输出变量(Y)。
主要监督倾斜问题可分为以下两类问题——
-
分类 − 当我们有分类输出,如黑色、教学、非教学等时,问题称为分类问题。
-
回归 − 当我们有实值输出(如距离、千克等)时,问题称为回归问题。
决策树、随机森林、knn、逻辑回归都是监督机器学习算法的例子。
无监督机器学习算法
顾名思义,这类机器学习算法没有任何导师来提供任何指导。这就是为什么无监督机器学习算法与所谓的真正人工智能高度契合。它可以理解为 −
假设我们有输入变量x,那么不会像监督式学习算法那样有对应的输出变量。
简单来说,在无监督学习中,没有正确答案,也没有老师来指导。算法帮助发现数据中的有趣模式。
无监督学习问题可分为以下两类问题——
-
聚类 − 在聚类问题中,我们需要发现数据中固有的分组。例如,按客户的购买行为进行分组。
-
关联 − 一个问题被称为关联问题,因为这类问题需要发现描述大量数据的规则。例如,找到同时购买 x 和 y 的客户。
K-均值用于聚类,先验算法用于关联,都是无监督机器学习算法的例子。
强化机器学习算法
这类机器学习算法的使用非常少。这些算法训练系统做出具体决策。基本上,机器暴露在一个环境中,通过不断的试错法自我训练。这些算法从以往经验中学习,试图捕捉最佳知识以做出准确决策。马尔可夫决策过程是强化机器学习算法的一个例子。
最常见的机器学习算法
在本节中,我们将了解最常见的机器学习算法。算法如下描述 −
线性回归
它是统计学和机器学习领域最著名的算法之一。
基本概念—— 主要线性回归是一种线性模型,假设输入变量(如x)与单一输出变量(如y)之间存在线性关系。换句话说,我们可以说 y 可以由输入变量 x 的线性组合计算出来。变量之间的关系可以通过拟合最佳直线来确定。
线性回归的类型
线性回归有以下两种类型 −
-
简单线性回归 − 如果线性回归算法只有一个自变量,则称为简单线性回归。
-
多重线性回归 − 如果线性回归算法存在多个自变量,则称为多元线性回归。
线性回归主要用于基于连续变量估计实值。例如,基于实际价值,一家商店一天的总销售额可以通过线性回归估计。
逻辑回归
它是一种分类算法,也称为对数回归。
主要逻辑回归是一种分类算法,用于根据给定的自变量集合估计离散值,如0或1、真或假、是或否。基本上,它预测概率,因此输出介于0和1之间。
决策树
决策树是一种监督学习算法,主要用于分类问题。
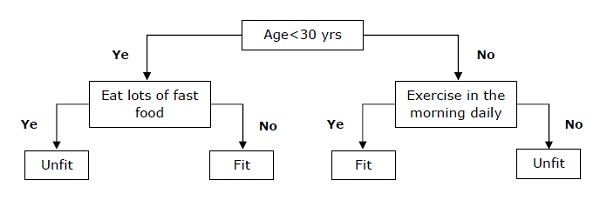
基本上,它是一种基于自变量递归划分的分类器。决策树由构成根树的节点组成。有根树是一种带有称为root的节点的有向树。根节点没有任何输入边,而其他所有节点都有一条进入边。这些节点被称为叶节点或决策节点。例如,考虑以下决策树,以判断一个人是否适合。
支持向量机(SVM)
它用于分类和回归问题。但主要用于分类问题。SVM的主要概念是将每个数据项绘制为n维空间中的一个点,每个特征的值为特定坐标的值。这里 n 就是我们会拥有的特征。以下是理解SVM−概念的简单图形表示
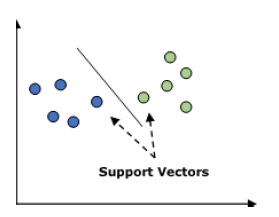
在上图中,我们有两个特征,因此我们首先需要在二维空间中绘制这两个变量,每个点有两个坐标,称为支持向量。该线将数据分为两个不同的分类组。这行就是分类器。
贝叶斯中殿
它也是一种分类技术。这种分类技术背后的逻辑是利用贝叶斯定理来构建分类器。假设预测变量是独立的。简单来说,它假设某一类中某个特征的存在与其他特征的存在无关。以下是贝叶斯定理−的方程
P\left (\frac{A}{B} \right)= \frac{P\left (\frac{B}{A} \right )P\left (A \right ){P\left (B \right )}
Nave Bayes模型易于构建,尤其适用于大型数据集。
K-最近邻(KNN)
它既用于问题的分类,也用于回归分析。它被广泛用于解决分类问题。该算法的主要概念是它会存储所有可用的案例,并通过k个邻居的多数票对新案例进行分类。该情况被赋予在其K最近邻中最常见的类,通过距离函数测量。距离函数可以是欧几里得距离、闵可夫斯基距离和汉明距离。考虑以下情况以使用 KNN −
-
从计算角度看,KNN比其他用于分类问题的算法更昂贵。
-
所需的变量归一化,否则更高范围的变量可能会产生偏差。
-
在KNN中,我们需要做前处理阶段,比如去除噪声。
K-表示聚类
顾名思义,它用于解决聚类问题。它基本上是一种无监督学习。K-均值聚类算法的主要逻辑是通过多个聚类对数据集进行分类。按照以下步骤,通过K-均数 − 形成簇
-
K-均值为每个称为重心的簇选取k个点。
-
现在每个数据点组成一个与最近重心(k个簇)组成的簇。
-
现在,它将根据现有的星团成员来确定每个星系的重心。
-
我们需要反复重复这些步骤,直到趋同发生。
随机森林
它是一种监督分类算法。随机森林算法的优点是既可用于分类问题,也可用于回归类问题。基本上,它是决策树(即森林树)的集合,或者你可以说是决策树的集合。随机森林的基本概念是,每棵树都给出一个分类,森林从中选择最佳分类。以下是随机森林算法的优势——
-
随机森林分类器既可用于分类任务,也可用于回归任务。
-
他们能处理缺失的数值。
-
即使森林中树木数量更多,模型也不会过度拟合。
机器学习(Machine Learning, ML)是人工智能的核心分支,核心是让计算机通过数据自主学习规律、构建模型,无需显式编程即可优化任务性能,其经典定义来自 Tom Mitchell:程序通过经验 E 提升在任务 T 上的性能 P,即实现学习。它与传统编程的核心差异在于,传统是 “数据 + 规则→结果”,而机器学习是 “数据 + 结果→规则”。
核心分类与关键内容
按学习范式划分,主流类型如下表所示:
| 学习类型 | 核心特征 | 典型任务 | 代表算法 | 应用场景 |
|---|---|---|---|---|
| 监督学习 | 数据含输入特征 + 目标标签 | 分类(离散输出)、回归(连续输出) | 线性 / 逻辑回归、决策树、SVM、随机森林 | 垃圾邮件识别、房价预测、疾病诊断 |
| 无监督学习 | 数据仅含输入特征,无标签 | 聚类、降维、关联规则挖掘 | K - 均值、PCA、Apriori | 客户分群、新闻聚类、特征压缩 |
| 半监督学习 | 少量标签 + 大量无标签数据 | 半监督分类 / 回归 | 标签传播、半监督 SVM | 数据标注成本高的场景(如罕见病影像) |
| 强化学习 | 智能体与环境交互,以奖励 / 惩罚驱动学习 | 序列决策、路径优化 | Q - Learning、PPO、DQN | 机器人控制、游戏 AI、仓储路径规划 |
挑战与发展趋势
- 挑战:数据质量与隐私、算法偏见、可解释性、算力成本、泛化边界等。
- 趋势:大模型与多模态融合、自动化机器学习(AutoML)、边缘端机器学习、可信 AI(公平、安全、可解释)成为热点方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)