广大-数据结构
·
有的答案是AI写的,不保真,建议做完了再自己看答案
数据结构期末模拟题
一、判断题
- 算法指的是计算机程序 ( )。
- 数据的基本单位是数据项 ( )。
- 队是一种插入与删除操作分别在表的两端进行的线性表,是一种先进后出型结构 ( )。
- 一个栈的输入序列是 12345,则栈的输出序列不可能是 12345 ( )。
- 若二叉树用二叉链表作存贮结构,则在 n 个结点的二叉树链表中只有 n-1 个非空指针域 ( )。
- 二叉树的前序和后序遍历序列能惟一确定这棵二叉树 ( )。
- 图的邻接矩阵必定是对称矩阵 ( )。
- 用链表表示线性表的优点是便于随机存储 ( )。
- 按深度优先搜索遍历图时,与始点相邻的结点先于不与始点相邻的结点访问 ( )。
- 若有向图 G 中包含一个环,则 G 的结点间不存在拓扑排序 ( )。
二、单项选择题
- 研究数据结构就是研究 ( )
A. 数据的逻辑结构
B. 数据的存储结构
C. 数据的逻辑结构和存储结构
D. 数据的逻辑结构、存储结构及其基本操作 - 线性表若采用链式存储结构时,要求内存中可用存储单元的地址 ( )。
A. 必须是连续的
B. 部分地址必须是连续的
C. 一定是不连续的
D. 连续或不连续都可以 - 算法分析的主要两个方面是 ( )。
A. 空间复杂度和时间复杂度
B. 正确性和简单性
C. 可读性和文档性
D. 数据复杂性和程序复杂性 - 设栈 S 和队列 Q 的初始状态为空,元素 e1、e2、e3、e4、e5 和 e6 依次进入栈 S,一个元素出栈后即进入 Q,若 6 个元素出队的序列是 e2、e4、e3、e6、e5 和 e1,则栈 S 的容量至少应该是 ( )。
A. 2
B. 3
C. 4
D. 6 - 设有数组 M [i,j],数组的每个元素长度为 2 字节,i 的值为 1 到 8,j 的值为 1 到 10,数组从内存首地址 AB 开始顺序存放,当用以列为主存放时,元素 M [5,8] 的存储首地址为 ( )。
A. AB+94
B. AB+120
C. AB+116
D. AB+138 - 一棵完全二叉树上有 10001 个结点,其中叶子结点的个数是 ( )。
A. 2500
B. 5000
C. 2540
D. 5001 - 对二叉树的结点从 1 开始进行连续编号,要求每个结点的编号大于其左、右孩子的编号,同一结点的左右孩子中,其左孩子的编号小于其右孩子的编号,可采用 ( ) 遍历实现编号。
A. 先序
B. 中序
C. 后序
D. 从根开始按层次遍历 - 一棵非空的二叉树的先序遍历序列与后序遍历序列正好相反,则该二叉树一定满足 ( )。
A. 所有的结点均无左孩子
B. 所有的结点均无右孩子
C. 只有一个叶子结点
D. 是任意一棵二叉树 - G 是一个非连通无向图,共有 36 条边,则该图至少有 ( ) 个顶点。
A. 7
B. 8
C. 9
D. 10 - 下面 ( ) 算法适合构造一个稀疏图 G 的最小生成树。
A. Prim 算法
B. Kruskal 算法
C. Floyd 算法
D. Dijkstra 算法 - 已知图的邻接表如图所示,则该图的边的数目是 ( )。
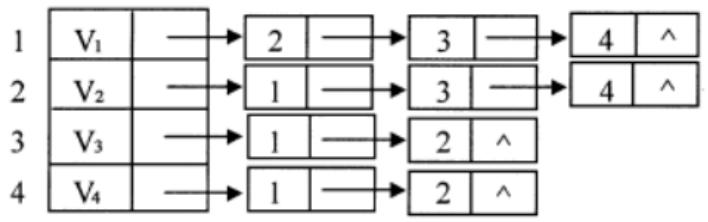
A. 4
B. 5
C. 10
D. 20 - 链表不具有的特点是 ( )。
A. 插入、删除不需要移动元素
B. 可随机访问任一元素
C. 不必事先估计存储空间
D. 所需空间与线性长度成正比 - 折半查找有序表 (4,6,10,12,20,30,50,70,88,100)。若查找表中元素 58,则它将依次与表中 ( ) 比较大小,查找结果是失败。
A. 20,70,30,50
B. 30,88,70,50
C. 20,50
D. 30,88,50 - 从未排序序列中挑选元素,并将其依次放入已排序序列 (初始时为空) 的一端的方法,称为 ( )。
A. 归并排序
B. 冒泡排序
C. 插入排序
D. 选择排序 - 下面那一种方法可以判断出一个有向图是否有环 (回路)( )。
A. 求节点的度
B. 拓扑排序
C. 求最短路径
D. 求关键路径
三、应用题
- 设待排序的关键字序列为 {12,2,16,30,28,10,16*,20,6,18},试用快速排序法写出每趟排序结束后关键字序列的状态。
- 假设用于通信的电文仅由 a,b,c,d,e 共 5 个字母组成,字母在电文中出现的频次分别为 4,7,5,2,9。① 画出表示此电文的哈夫曼树。② 试为这 5 个字母设计赫夫曼编码。
- 设一棵二叉树的先序序列: A B D F C E G H,中序序列: B F D A G E H C① 画出这棵二叉树。② 写出这棵二叉树的后序序列。
- 已知如图所示的无向网,请给出:
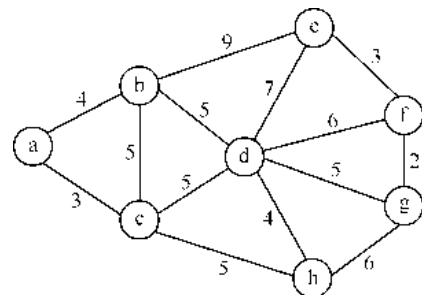
① 邻接矩阵
② 使用 prim 算法画出从 a 作为起点的最小生成树 (给出详细步骤)
四、算法设计题
- 设计一个算法,通过一趟遍历在单链表中确定值最大的结点。
- 交换二叉树每个结点的左孩子和右孩子。
五、判断题答案
(答案速对:××××√ ××××√)
- ×:算法是解决问题的步骤集合,计算机程序是算法的实现,二者不等同。
- ×:数据的基本单位是数据元素,数据项是数据的最小单位。
- ×:队列是先进先出(FIFO)结构,栈才是先进后出(LIFO)结构。
- ×:栈的输入序列 12345 可按 “进 1 出 1、进 2 出 2……” 的方式,输出序列为 12345。
- √:n 个结点的二叉链表有 2n 个指针域,其中 n-1 个用于连接孩子结点(非空),剩余 n+1 个为空指针域。
- ×:仅前序和后序遍历序列无法唯一确定二叉树,需结合中序遍历序列。
- ×:无向图的邻接矩阵是对称矩阵,有向图的邻接矩阵不一定对称。
- ×:链表的优点是插入删除无需移动元素,缺点是不支持随机存储(需顺序遍历)。
- ×:深度优先搜索是优先遍历当前结点的邻接结点,并非所有与始点相邻的结点都先于非相邻结点。
- √:拓扑排序的前提是有向图无环,存在环则无法进行拓扑排序。
六、单项选择题答案
(答案苏队:DDACB DCCDB BBADB)
- D:数据结构的研究核心是逻辑结构、存储结构及基于二者的基本操作,缺一不可。
- D:链式存储通过指针连接结点,内存单元地址无需连续,连续或不连续均可。
- A:算法分析的核心维度是时间复杂度(执行效率)和空间复杂度(内存占用),其余选项非核心。
-
C: 根据入栈、出栈及入队的操作流程:
元素依次入栈 S:e1进栈 → e2进栈,此时e2出栈(入队 Q),栈内剩余e1;e3进栈 → e4进栈,此时e4出栈(入队 Q)、e3出栈(入队 Q),栈内剩余e1;e5进栈 → e6进栈,此时e6出栈(入队 Q)、e5出栈(入队 Q)、e1出栈(入队 Q)。 - B(AB+120):列优先存储地址公式:地址 = AB + 2×[(j-1)× 行数 + (i-1)]行数 = 8,i=5,j=8:(8-1)×8 + (5-1)=56+4=60,60×2=120,对应地址 AB+120。
- D:完全二叉树中,n=10001(奇数),叶子结点数 =(n+1)/2=(10001+1)/2=5001。
- C:后序遍历顺序为 “左→右→根”,天然满足 “根编号 > 左右孩子,左孩子编号 < 右孩子”。
- C:先序(根→左→右)与后序(左→右→根)序列相反,说明二叉树为单支树(无左子树或无右子树),仅含 1 个叶子结点。
- D(10):非连通无向图顶点最少时,含一个最大连通分量(完全图)+1 个孤立顶点。设连通分量有 k 个顶点,边数 k (k-1)/2≥36,解得 k≥9,总顶点数 = 9+1=10。
- B:Kruskal 算法适合稀疏图(边少),Prim 适合稠密图;Floyd、Dijkstra 用于最短路径,非最小生成树。
- B(5):无向图邻接表中,每条边在两个顶点的邻接链表中各存 1 次,统计邻接结点总数后除以 2,结果为 5。
- B:链表的缺点是无法随机访问(需顺序遍历),其余选项均为链表的特点。
- A(20,70,30,50):折半查找步骤(有序表:4,6,10,12,20,30,50,70,88,100):
- 初始 mid=4(值 20),58>20→右半区;
- 新 mid=7(值 70),58<70→左半区;
- 新 mid=5(值 30),58>30→右半区;
- 新 mid=6(值 50),58>50→无后续元素,查找失败,依次比较 20、70、30、50。
- D:选择排序的定义是 “从未排序序列选最值,依次放入已排序序列一端”,与题干描述完全匹配。
- B:拓扑排序的核心功能是判断有向图是否有环,若无法生成完整拓扑序列,则图存在环;其余选项无此功能。
七、应用题答案
1. 快速排序(以第一个元素 12 为基准)
- 初始序列:{12,2,16,30,28,10,16*,20,6,18}
- 第 1 趟:小于 12 的元素移到左,大于 12 的移到右,基准 12 归位→{6,2,10,12,28,30,16*,20,16,18}
- 第 2 趟:对左子序列 {6,2,10}(基准 6)和右子序列 {28,30,16*,20,16,18}(基准 28)排序→{2,6,10,12,18,16,16*,20,28,30}
- 第 3 趟:对左子序列 {2}(已有序)、{10}(已有序),右子序列 {18,16,16*,20}(基准 18)、{30}(已有序)排序→{2,6,10,12,16,16*,18,20,28,30}
- 第 4 趟:剩余子序列均有序,排序结束。
2. 哈夫曼树与哈夫曼编码
- ① 哈夫曼树构建步骤:
- 初始结点(频次):d (2)、a (4)、c (5)、b (7)、e (9);
- 选最小两个结点 d (2) 和 a (4),合并为新结点(6),新集合:c (5)、6 (d+a)、b (7)、e (9);
- 选最小两个结点 c (5) 和 6 (d+a),合并为新结点(11),新集合:b (7)、11 (c+d+a)、e (9);
- 选最小两个结点 b (7) 和 e (9),合并为新结点(16),新集合:11 (c+d+a)、16 (b+e);
- 合并 11 和 16,得到根结点(27),哈夫曼树构建完成。
- ② 哈夫曼编码(左 0 右 1):
- e:0(根→右孩子);
- b:10(根→左孩子→右孩子);
- c:110(根→左孩子→左孩子→右孩子);
- a:1110(根→左孩子→左孩子→左孩子→右孩子);
- d:1111(根→左孩子→左孩子→左孩子→左孩子)。
3. 二叉树构建与后序遍历
- ① 二叉树结构:
- 根结点:A(先序首元素);
- 中序中 A 左侧为左子树(B、F、D),右侧为右子树(G、E、H、C);
- 左子树先序:B、D、F→根 B,中序 B 左侧无,右侧为 D(中序 B、F、D)→D 是 B 的右孩子,F 是 D 的左孩子;
- 右子树先序:C、E、G、H→根 C,中序 C 左侧为 E(G、E、H),右侧无→E 是 C 的左孩子,E 的左孩子是 G,右孩子是 H;
- ② 后序遍历序列:F、D、B、G、H、E、C、A。
4. 无向网的邻接矩阵与 Prim 算法(假设无向网顶点为 a、b、c、d、e,边权如下:a-b (2)、a-c (3)、a-d (1)、b-c (4)、b-e (5)、c-d (2)、c-e (1)、d-e (3))
- ① 邻接矩阵(∞表示无边):
a b c d e a 0 2 3 1 ∞ b 2 0 4 ∞ 5 c 3 4 0 2 1 d 1 ∞ 2 0 3 e ∞ 5 1 3 0 - ② Prim 算法(起点 a):
- 初始集合 U={a},V-U={b、c、d、e},边权:a-b (2)、a-c (3)、a-d (1);
- 选最小边 a-d (1),U={a、d},V-U={b、c、e},新增边权:d-c (2)、d-e (3);
- 选最小边 d-c (2),U={a、d、c},V-U={b、e},新增边权:c-b (4)、c-e (1);
- 选最小边 c-e (1),U={a、d、c、e},V-U={b},新增边权:e-b (5);
- 选最小边 a-b (2),U={a、d、c、e、b},最小生成树边为 a-d、d-c、c-e、a-b,总权值 1+2+1+2=6。
八、算法设计题答案(C语言)
1. 单链表中查找值最大的结点
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node *next;
} Node;
Node* findMaxNode(Node *head) {
if (head == NULL) return NULL; // 空链表返回NULL
Node *maxNode = head; // 初始化最大结点为头结点
Node *p = head->next;
while (p != NULL) {
if (p->data > maxNode->data) {
maxNode = p; // 更新最大结点
}
p = p->next;
}
return maxNode;
}
- 思路:一趟遍历链表,用指针记录当前最大值结点,依次比较后续结点,更新最大值结点。
2. 交换二叉树每个结点的左右孩子
#include <stdio.h>
#include <stdlib.h>
typedef struct TreeNode {
int data;
struct TreeNode *left;
struct TreeNode *right;
} TreeNode;
void swapLeftRight(TreeNode *root) {
if (root == NULL) return; // 空树直接返回
// 交换当前结点的左右孩子
TreeNode *temp = root->left;
root->left = root->right;
root->right = temp;
// 递归交换左子树和右子树
swapLeftRight(root->left);
swapLeftRight(root->right);
}
- 思路:递归遍历二叉树,对每个结点交换其左右孩子指针,再递归处理左右子树。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 35
35 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)