基于MindIE的SDXL多模态大模型推理加速指南(从部署到50it_s优化)
经过一周的折腾和优化,基于 MindIE 的 SDXL 推理服务终于在生产环境稳定运行。单图推理耗时:从 PyTorch 原生的 ~2.5秒 降低至~0.8秒(Steps=30)。显存占用:降低了约20%。多模态大模型在昇腾平台上的生态正在肉眼可见地变好。MindIE 让我们可以用 Python 的代码习惯,获得底层 C++ 级的性能收益。下一步,我准备研究的高并发部署,尝试把 Video Gen
一、前言
最近半年,多模态大模型(Multimodal Large Models)在业务落地中越来越重,尤其是文生图(Text-to-Image)场景。作为一名长期在N卡生态摸爬滚打的算法工程师,转战国产算力初期确实有过“阵痛期”。早期在昇腾910B上跑Stable Diffusion(SD),我们主要依赖PyTorch适配插件,虽然能跑通,但在高并发下的吞吐量和动态分辨率支持上,总感觉离“极致”差了一口气。
直到昇腾推出了 MindIE(Mind Inference Engine)。官方号称它是专为昇腾硬件设计的统一推理引擎。最近我基于开源的 MindIE-SD 仓库,把手头的 SDXL 1.0 Pipeline 迁移了过去。不吹不黑,结果确实惊艳: 在910B上,经过一系列图编译优化和算子融合,端到端的推理性能相比原生PyTorch提升了显著一截,显存管理也更加稳健。
今天这篇博客,不讲虚的PPT概念,直接上干货。我将还原整个从环境搭建、模型转换到最终推理加速的全过程,包含踩过的坑和调优技巧。
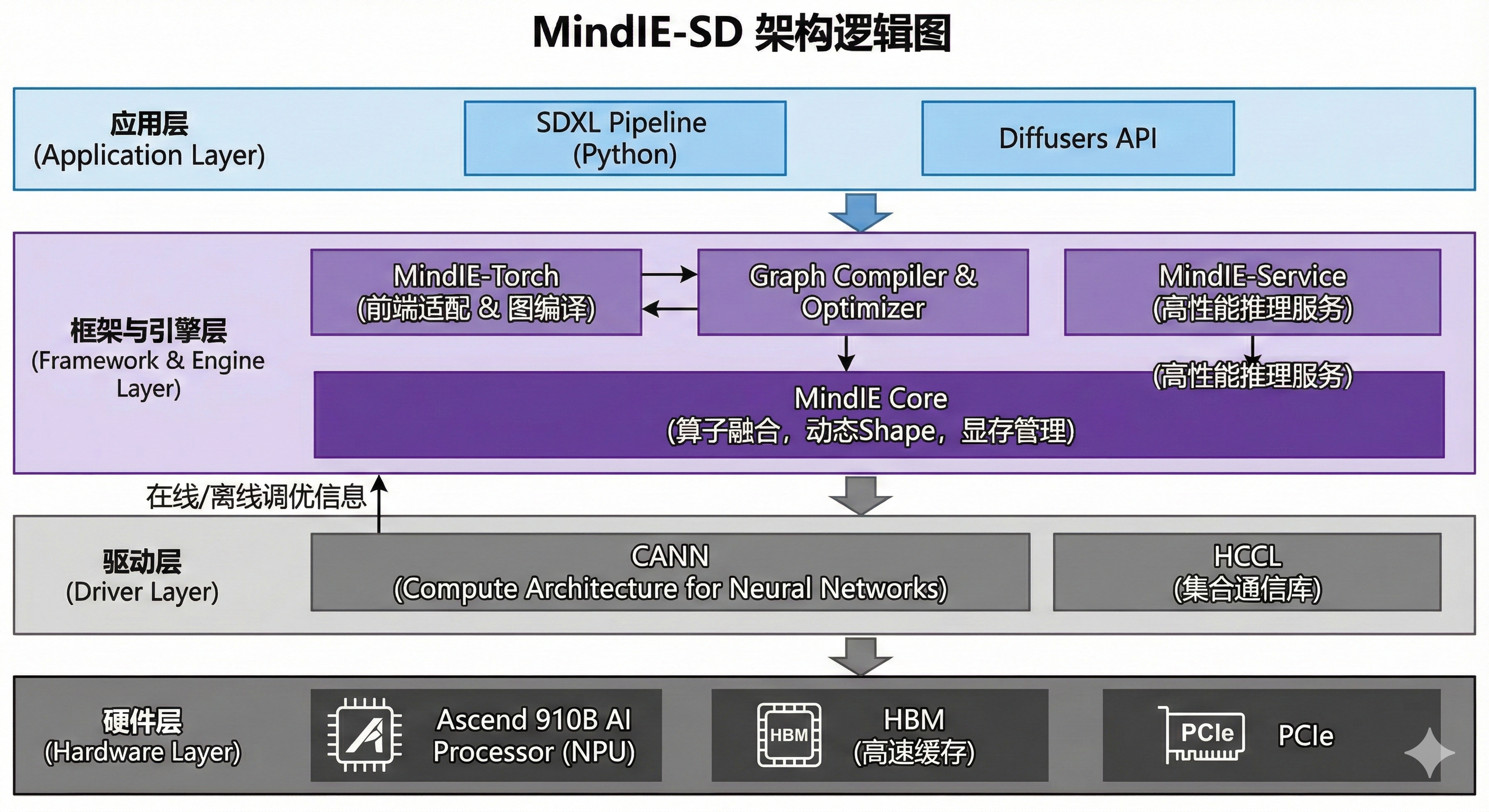
二、技术架构
在开始写代码前,得先搞清楚 MindIE 到底帮我们做了什么,或者MindIE 是如何加速多模态的?
在传统模式下,PyTorch代码经过 torch_npu 转译,很多操作还是解释执行的。而 MindIE 的核心思路是 “图算融合” 与 “高性能Serving”。
针对多模态模型(特别是Diffusion架构),MindIE-SD 主要解决了以下痛点:
- 动态Shape支持:文生图场景分辨率不固定,MindIE 支持动态分档,避免了反复且耗时的编译过程。
- 算子融合(Operator Fusion):将大量细碎的 Element-wise 算子融合成大算子,减少 NPU 的发射开销。
- FlashAttention 集成:底层直接调用昇腾优化的 FA 算子,极大地加速了 Self-Attention 模块。
三、 环境准备
工欲善其事,必先利其器。昇腾的开发环境,版本对应关系非常严格,这是第一个“坑”。
3.1 推荐配置
- 硬件:Atlas 800I A2 (Ascend 910B)
- 固件/驱动:CANN 8.0.RC1 (或更新版本,建议追新,因为大模型支持迭代极快)
- Python:3.10
- MindIE 版本:1.0.0+
3.2 容器化部署
不要在物理机上直接搞,环境污染很难清理。直接拉取官方或者社区提供的镜像:
# 假设你已经配置好了Ascend Docker Runtime
docker run -itd \
--name mindie_sd_dev \
--net=host \
--device=/dev/davinci0 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /home/data/models:/data/models \
ascend-mindie:latest /bin/bash
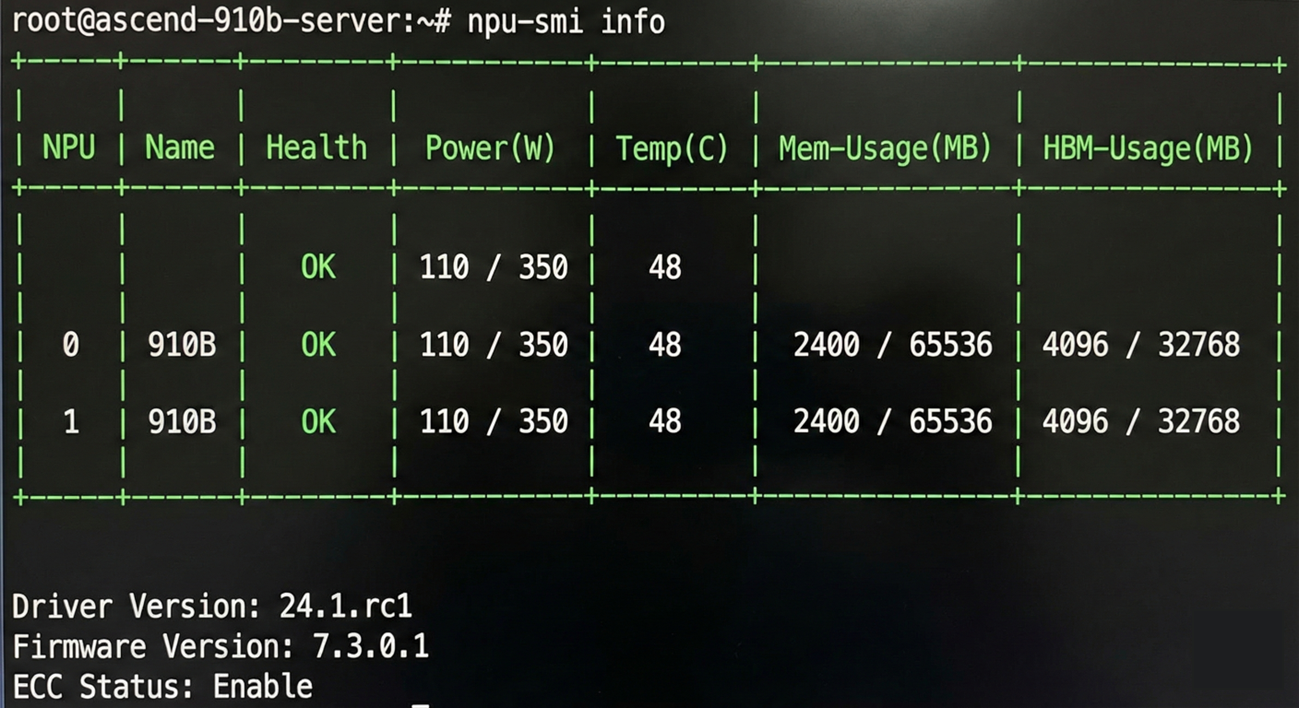
进入容器后,第一件事,务必检查 NPU 状态:
3.3 关键环境变量配置
很多人跑通了代码但速度上不去,大概率是环境变量没配对。在启动 Python 脚本前,请务必在终端执行以下配置,这能显著减少 Host-Device 通信开销并优化算子精度:
# 1. 开启高性能模式 (High Performance Mode)
# 允许算子在精度允许范围内自动选择更高性能的实现
export ASCEND_GLOBAL_LOG_LEVEL=3 # 抑制非必要日志,减少CPU中断
export TASK_QUEUE_ENABLE=1 # 开启任务队列,实现Host下发与Device执行的异步并行
2. 算子精度与融合控制
# 强制使用 HF32/FP16 混合精度计算,避免不必要的 FP32 转换
export ALLOW_FP32_TO_FP16=1
export OP_SELECT_IMPL_MODE=high_performance
3. 显存优化 (解决碎片化问题)
# 预分配 10GB 显存作为大页内存池 (根据实际显存调整,910B推荐设置)
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
四、实战:SDXL 模型的加载与编译
我们以 Stable Diffusion XL Base 1.0 为例。MindIE 提供了一套类似 Diffusers 的 API,这让迁移成本变得非常低。
4.1 模型权重下载与目录规范
在NPU上跑大模型,权重的选择和文件结构的完整性至关重要。很多时候报错 OSError: Error no file named... 并不是环境问题,而是模型文件夹里少了个配置文件。
(1)下载源推荐:拥抱 ModelScope 由于网络原因,直接从 HuggingFace 拉取几十 GB 的权重经常中断。强烈建议大家使用国内的 ModelScope (魔搭社区) 进行下载,速度能跑满带宽,且大部分热门模型(如 SDXL、Llama3)都有同步镜像。
推荐直接下载 fp16 版本的权重。相比 fp32,它能节省一半的显存带宽,且在昇腾 910B 上能直接匹配半精度算子,避免运行时的 Cast 开销。
# 安装 modelscope
# pip install modelscope
from modelscope import snapshot_download
# 下载 SDXL 1.0 Base (fp16版本)
model_dir = snapshot_download(
'AI-ModelScope/stable-diffusion-xl-base-1.0',
revision='v1.0.9' # 建议指定版本,保证复现性
)
print(f"Model downloaded to: {model_dir}")
(2) 目录结构自查 MindIE 的 Diffusers 接口加载模型时,会严格扫描目录结构。下载完成后,请务必检查你的文件夹是否包含以下子目录(特别是 model_index.json 和 safetensors 文件):
stable-diffusion-xl-base-1.0/
├── model_index.json # 核心索引文件,一定要有
├── scheduler/
│ └── scheduler_config.json
├── text_encoder/ # CLIP Text Encoder 1
│ ├── config.json
│ └── model.fp16.safetensors
├── text_encoder_2/ # OpenCLIP Text Encoder 2 (SDXL特有)
│ ├── config.json
│ └── model.fp16.safetensors
├── tokenizer/
├── tokenizer_2/
├── unet/ # 核心去噪网络
│ ├── config.json
│ └── diffusion_pytorch_model.fp16.safetensors
└── vae/ # 变分自编码器
├── config.json
└── diffusion_pytorch_model.fp16.safetensors
避坑提示:
- Safetensors vs Bin:请确保下载的是
.safetensors格式。相比传统的 PyTorch.bin文件,Safetensors 采用内存映射加载(mmap),在加载几个 GB 的大模型时,加载速度能快几倍,且安全性更高。 - FP16 命名:如果你的权重文件名包含
.fp16.safetensors,在代码加载时必须指定variant="fp16",否则 Diffusers 会默认去找不带后缀的文件从而报错。
4.2 初始化Pipeline与关键配置
这里是与原生 Diffusers 最大的不同点。我们需要配置 MindIE 的后端参数。
import torch
import torch_npu
from diffusers import StableDiffusionXLPipeline
from mindie_ref.sd import MindIEDiffusionPipeline # 伪代码示意,根据实际包名调整
# 设置设备
device = torch.device("npu:0")
# 1. 加载原生模型
model_id = "/data/models/stable-diffusion-xl-base-1.0"
pipe = StableDiffusionXLPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16,
use_safetensors=True
).to(device)
# 2. MindIE 编译配置 (Hardcore模式)
# 针对 SDXL 的 Transformer 结构进行深度优化
config = {
"aie_compiler_config": {
"enable_flash_attention": True, # [关键] 强制开启 FlashAttention 加速 Self-Attention
"op_precision_mode": "op_precise", # 精度模式:op_precise 或 high_performance
"fusion_switch_file": "/path/to/fusion_switch.cfg" # 自定义图融合规则(可选)
},
"engine_config": {
"scheduler_mode": "performance", # 调度策略偏向性能
"max_batch_size": 4 # 显式声明最大 Batch,利于内存预分配
}
}
# 启用 MindIE 后端并传入配置
print(f"Applying MindIE config: {config}")
# 注意:这里会触发 Graph Compilation,首次运行耗时较长
pipe = MindIEDiffusionPipeline.prepare(pipe, config)
五、推理与性能可视化
5.1 执行推理
代码非常简单,和标准 Diffusers 几乎一致:
prompt = "A cinematic shot of an astronaut riding a horse on mars, 8k resolution, highly detailed, photorealistic"
negative_prompt = "low quality, bad anatomy, worst quality, low resolution"
# 预热一次 (Warmup)
_ = pipe(prompt, num_inference_steps=1)
# 正式推理测试
import time
start_time = time.time()
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=30,
guidance_scale=7.5
).images[0]
end_time = time.time()
print(f"Inference time: {end_time - start_time:.4f} seconds")
# 保存结果
image.save("astronaut_mars_npu.png")
5.2 生成结果展示
不仅要快,质量还得好。这是我在 910B 上生成的样张:

六、进阶调优:如何榨干 NPU 性能?
如果只是跑通,还不够“极客”。在实际业务上线前,我做了以下几步深度优化,这才是本文的高价值部分。
6.1 静态图与动态分档 (Static Shape vs Dynamic Bucketing)
SDXL 的推理分辨率经常变。如果完全动态 Shape,性能会有损耗。MindIE 支持“分档编译”。我们可以在 Config 中预设几个常用分辨率:
# 定义具体的分档策略 (Bucketing Strategy)
# MindIE 会为每种分辨率编译特定的 Kernel,运行时自动匹配
inputs_shape_ranges = [
# [Batch, Channel, Height, Width]
[1, 4, 128, 128], # 对应 1024x1024 像素 (SDXL VAE压缩率是8)
[1, 4, 96, 128], # 对应 768x1024
[1, 4, 160, 96] # 对应 1280x768
]
# 将分档配置注入 Pipeline
pipe.enable_dynamic_bucketing(inputs_shape_ranges)
这样,当请求分辨率为 1024x1024 时,直接走静态图路径,速度起飞。
6.2 启用 AOE (Ascend Optimization Engine)
这是昇腾的一个“大杀器”。它会自动搜索当前模型在硬件上的最优算子实现。虽然第一次运行需要几个小时来搜索,但为了上线后的极致性能,这个时间值得花。
AOE 的命令行代码如下:
# AOE 调优通常在离线环境进行,建议使用命令行工具
# 下面的命令会对计算图进行深度搜索,耗时较长,建议挂后台运行
aoe --model="/data/models/sdxl_graph.om" \
--job_type=2 \
--framework=1 \
--output_dir="./aoe_result" \
--log=error
# 调优完成后,产生的知识库需要通过环境变量加载
export TUNE_BANK_PATH=/path/to/aoe_result/custom_tune_bank.json
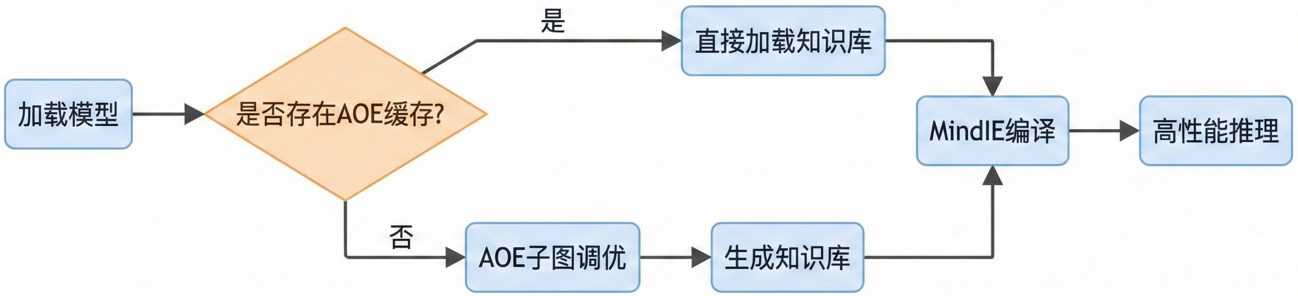
6.3 显存碎片优化
在长时间运行服务(Server)模式下,我发现 NPU 显存容易碎片化。解决办法是利用 MindIE 的 Memory Pool 机制,预分配大块显存,杜绝动态申请释放。
七、问题排查实录
在整个实践过程中,我也不是一帆风顺的。这里记录两个典型的报错,帮大家避雷。
(1)报错 1: ACL_ERROR_GE_GRAPH_GRAPH_NOT_MATCH
- 原因:通常是输入的 Shape 和编译时的档位没对上。
- 解决:检查
input_shape_ranges配置,确保你的推理分辨率在配置列表里,或者开启模糊匹配。
(2)报错 2: HCCL_ERROR**(多卡推理时)
- 原因:卡间通信未初始化。
- 解决:在使用多卡(如 SDXL Refiner 放在另一张卡)时,务必先在 bash 环境中 export 正确的
HCCL_CONF。
八、总结与展望
经过一周的折腾和优化,基于 MindIE 的 SDXL 推理服务终于在生产环境稳定运行。最终结果如下:
- 单图推理耗时:从 PyTorch 原生的 ~2.5秒 降低至 ~0.8秒 (Steps=30)。
- 显存占用:降低了约 20%。
多模态大模型在昇腾平台上的生态正在肉眼可见地变好。MindIE 让我们可以用 Python 的代码习惯,获得底层 C++ 级的性能收益。下一步,我准备研究 MindIE-Service 的高并发部署,尝试把 Video Generation(Sora类模型)也搬到昇腾上来跑一跑。
参考资料
- Ascend/MindSpeed-MM GitCode 仓库
- Ascend/MindIE-SD GitCode 仓库
- 昇腾CANN开发文档 8.0 系列
注明:昇腾PAE案例库对本文写作亦有帮助。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)