深入学习scrapy框架的内置中间件
本文介绍了Scrapy框架中的中间件系统,包括爬虫中间件和下载器中间件的功能与分类。爬虫中间件负责处理爬虫行为规范,如请求验证;下载器中间件则对请求和响应进行预处理。文章详细列举了各类内置中间件,如HttpErrorMiddleware处理状态码、UserAgentMiddleware管理UA、CookiesMiddleware处理cookie等,并通过两个实战案例演示了UA设置和cookie管理
·
1.scrapy中间件类型介绍
爬虫中间件介绍
- 爬虫处理后的对象,都需要经过爬虫中间件后再传出
- 爬虫中间件负责爬虫的行为规范,例如请求网址符号host
下载器中间件介绍
- 爬虫将请求丢给下载器,需要经过下载器中间件
- 下载器接收响应并反给爬虫,需要经过下载器中间件
- 下载器中间件负责对请求和响应预处理
2.scrapy中间件的内置函数
中间件的内置函数
- process_request:处理请求
- process_response: 处理响应
- process_exeception:处理异常
中间件的信号函数
- def from_crawler(cls,crawler):类方法,传递爬虫信号
- spider_opened:爬虫启动时通过信号传递并调用的方法
3.scrapy内置爬虫中间件
HttpErrorMiddleware
- scrapy.spidermiddlewares.httperror.HttpErrorMiddleware
- 负责解析响应的状态码,判断状态以及执行对应操作
- 操作:200成功;301再次请求;400失败重试等
OffsiteMiddleware
- scrapy.spidermiddlewares.offsite.OffsiteMiddleware
- 读取请求的网址,并对比爬虫的allowed_domains
- 在允许范围内,则允许请求;不在范围内则丢弃请求
RefererMiddleware
- scrapy.spidermiddlewares.referer.RefererMiddleware
- 解析请求,并自动读取和标记请求的Referer字段
- 模拟浏览器,自动跟进Referer字段的内容更新
UrlLengthMiddleware
- scrapy.spidermiddlewares.urllength.UrlLengthMiddleware
- 读取请求的网址,统计请求网址的长度
- 通常是没有长度限制的,可以自行设置
DepthMiddleware
- scrapy.spidermiddlewares.depth.DepthMiddleware
- 读取并记录请求的深度,方便对深度进行限制
- 关键词:DETH_LIMIT
4.下载器中间件内置函数介绍
中间件的信号函数
- def from_crawler(cls,crawler);类方法,传递爬虫信号
- spider_opened: 爬虫启动时通过信号传递并掉用的方法
中间件的内置函数
- process_request:处理请求
- process_response: 处理响应
- process_exeception:处理异常
process_request函数的返回值
- 正常情况:None,Request,Response
- 异常情况:ignoreRequest->process_exeception
process_response函数的返回值
- 正常情况:Response,Request
- 异常情况:IgnoreRequest->process_exeception
process_exeception函数的返回值
- 正常情况:None,Request,Response
- 异常情况:无
5.scrapy框架内置的下载器中间件
1.HttpAuthMiddleware
- scrapy.downloadermiddleware.shttpauth.HttpAuthMiddleware
- 负责HTTP请求头的认证信息,例如代理,账号密码等信息
2.DownloadTimeMiddleware
- scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware
- 设置请求的等待时间,默认180秒
3.DefaultHeadersMiddleware
- scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware
- 默认的请求头字段信息,settings.py可以选择设置
4.UserAgentMiddleware
- scrapy.downloadermiddlewares.useragent.UserAgentMiddleware
- 用户代理信息,专门存放浏览器和内核信息
- 常用固定的UserAgent和可变化的UserAgent
- UA顺序在默认请求头的后面,
5.RetryMiddleware
- scrapy.Downloadermiddlewares.retry.RetryMiddleware
- 下载器重试中间件,负责重新请求失败的响应,默认3次
6.MetaRefreshMiddleware
- scrapy.downloadermiddlewares.redirect.MetaRefresh
- 自动处理基于meta-refresh html重定向的响应内容
7.HTTPCompressionMiddleware
- scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware
- 主动压缩与目标站相互发送和接收的HTTP包
8.RedirectMiddleware
- scrapy。Downloadermiddlewares.redirect.RedirectMiddleware
- 基于响应状态信息,自动处理需要跳转的响应
9.CookiesMiddleware
- scrapy.downloadermiddlewares.cookie.CookiesMiddleware
- 模拟浏览器的网站cookie管理,并跟踪Request添加cookie
- cookie可以包含很多信息,例如账户登录信息和广告等
重点为UA,Cookie,proxy
10.HttpProxyMiddleware
- scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware
- 通过设置请求的proxy字段来给请求添加代理信息
11.DownloaderStatsMiddleware
- scrapy.downloadermiddlewares.httpcompression.downloaderStats
- 储存统计信息,包括请求,响应和异常处理的数量等
6.scrapy实战训练之User-Agent管理
4.UserAgentMiddleware
- scrapy.downloadermiddlewares.useragent.UserAgentMiddleware
- 用户代理信息,专门存放浏览器和系统内核信息
- 常用固定的UserAgent和可变化的UserAgent
- UA顺序在默认请求头的后面,
实战训练之UserAgent管理—代码实践
本次代码实践的目的;学习在settings.py文件中添加UA的方法
目标网站:http://www.spbeen.com/tool/request_info/
爬取内容: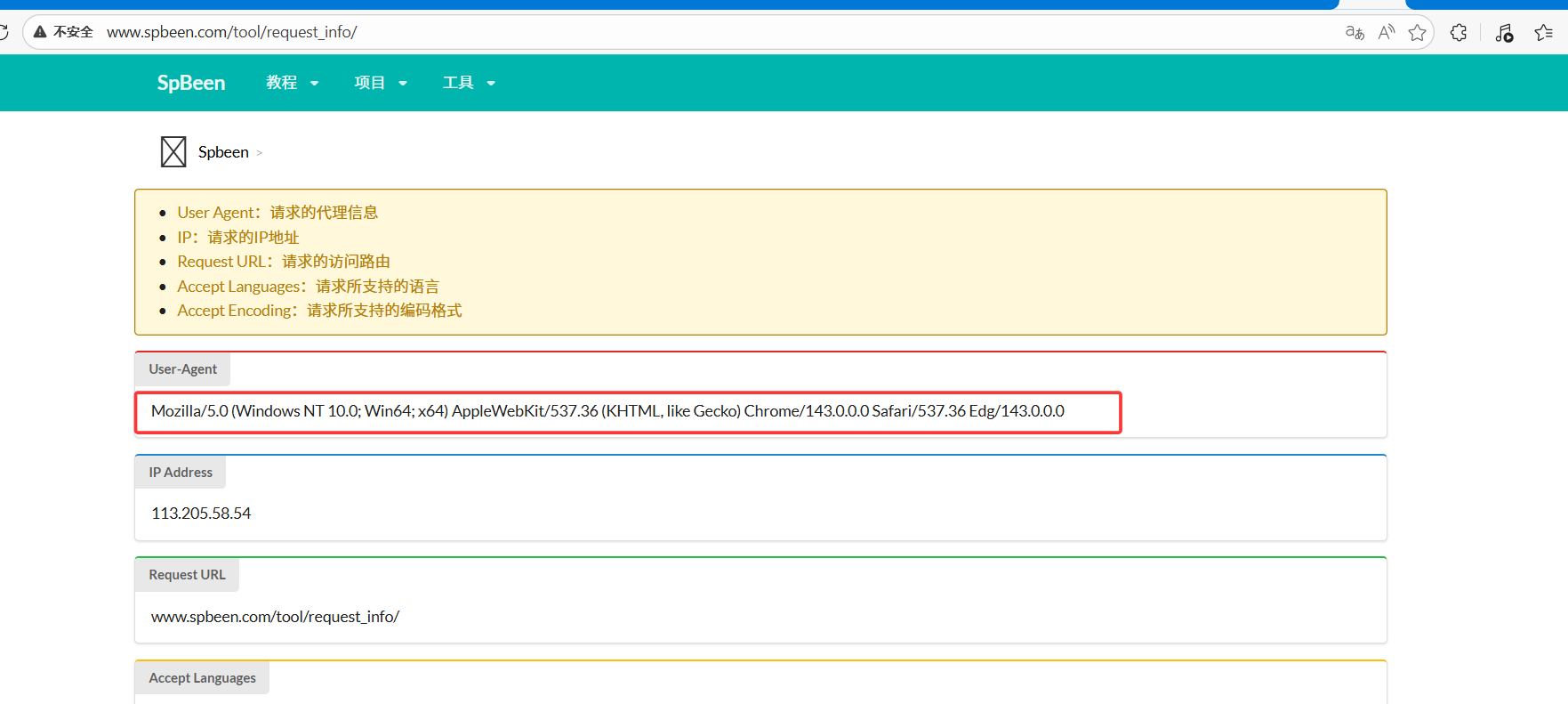
- 创建项目: scrapy startproject firstproject
- 创建爬虫:scrapy genspider first www.spbeen.com/tool/request_info/
- 编写爬虫文件spider.py
import scrapy
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
class SecondSpider(scrapy.Spider):
name = "second"
allowed_domains = ["www.spbeen.com"]
start_urls = ["http://www.spbeen.com/tool/request_info/"]
def parse(self, response):
ua_message = response.xpath('.//div[@class="content"]/div/div[2]/div[2]/text()').extract()
print(ua_message)
- 在settings.py中添加UA:
#本次代码实践的目的;
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0"
- 在项目目录下创建启动文件:
import os
from scrapy.cmdline import execute
if __name__ == "__main__":
# execute(["scrapy", "crawl", "first"])
execute("scrapy crawl first".split())
- 运行结果:

7.下载器中间件实战训练之cookie管理
9.CookiesMiddleware
- scrapy.downloadermiddlewares.cookie.CookiesMiddleware
- 模拟浏览器的网站cookie管理,并跟踪Request添加cookie
- cookie可以包含很多信息,例如账户登录信息和广告等
下载器中间件实战训练之cookie管理----代码实践
-
目标网站:shanzhi.spbeen.com
-
创建项目:scrapy startproject cookieproject
-
创建爬虫:scrapy genspider -t basic cookiespider shanzhi.spbeen.com
-
查看网站:登录账号和密码:demo123,demo123
-
编写spider.py文件
import scrapy
from scrapy.downloadermiddlewares.cookies import CookiesMiddleware
class ThirdSpider(scrapy.Spider):
name = "third"
allowed_domains = ["shanzhi.spbeen.com"]
start_urls = ["http://shanzhi.spbeen.com/detail/?id=2075"]
def parse(self, response):
print(response.text)
print(response.url)
- 运行会发现:爬虫爬取的网页为登录页面,而非首页详细信息
- 在settings.py的DEFAULT_REQUEST_HEADERS添加cookie信息,运行会发现爬取的依然是登录页面信息而非首页信息
DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
'Cookie': 'shanzhi_kmer=ckvgsj6xxkpbv0osqjrqg5g8ytm7cmjd; csrftoken=oNrfuYtcAyIoD6lui4hFpXR0erwzsG66UxEjJ3C3MF5n4Nf7eSxmLWUXQOvavubd',
}
- 关闭下载器中间件cookie:默认下载器中间件是开启的,运行可以爬取到首页信息
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
- 具体原因:我们设置了Cookie,但Cookie中间件运行的时候会将我们设置的Cookie覆盖掉
CookieMiddlewares工作原理
- 主动跟踪响应,并自动配置响应和请求的Cookie
- 默认自动开启,并跟踪Cookie的变化和设置
- 自动处理Cookie时,不支持手动添加的Cookie

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)