快讯 | 智谱发布最新旗舰模型 GLM-4.7!
又到了智谱的高光时刻,在元旦前发布了GLM 4.7,为这一年画上了完美的句号。在 LMArena Code Arena 盲测中位列开源第一、国产第一,超过 GPT-5.2;在 SWE-bench-Verified 获得国产第一;在 LiveCodeBench V6 达到 84.8 的开源 SOTA 分数,超过 Claude Sonnet 4.5。在 AIME 2025 数学竞赛中取得开源 SOTA
#GLM-4.7 #GLM我的编码搭子
智谱发布了最新旗舰模型 GLM 4.7,并已融入 GLM Coding Plan!
又双叒叕到了智谱的高光时刻,在元旦前的这一版本为这一年画上了完美的句号。
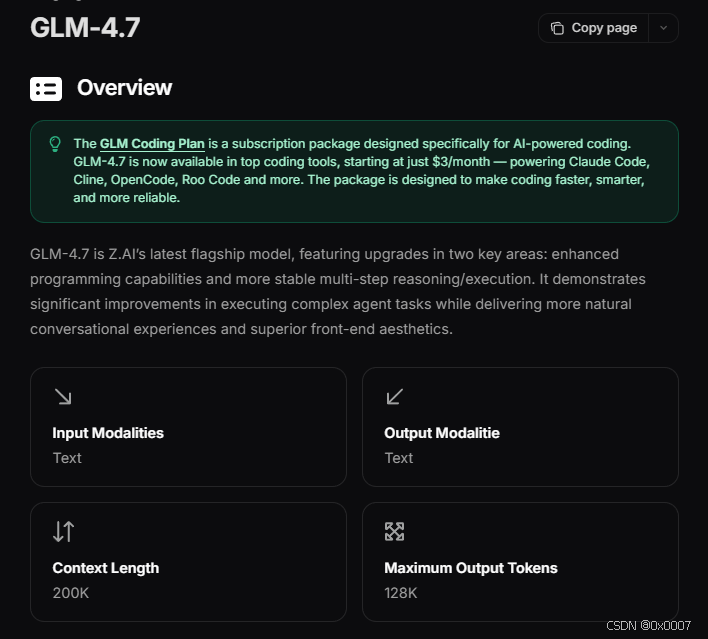
根据官网描述,GLM-4.7 在编程、推理与智能体三个维度实现了显著突破:
编程能力:在 LMArena Code Arena 盲测中位列开源第一、国产第一,超过 GPT-5.2 ;在 SWE-bench-Verified 获得国产第一;在 LiveCodeBench V6 达到 84.8 的开源 SOTA 分数,超过 Claude Sonnet 4.5 。
推理能力:在 AIME 2025 数学竞赛中取得开源 SOTA ,超过 Claude Sonnet 4.5 和 GPT-5.1 ;在 HLE (“人类最后的考试”)基准测试中获得 42% 的成绩,较 GLM-4.6 提升 38% ,接近 GPT-5.1
智能体能力:在 BrowseComp 网页任务评测中获得 67 分;在 τ²-Bench 真实世界交互评测中实现开源 SOTA ,接近 Claude Sonnet 4.5 ( 84.7 分)
我快速体验了一下,老实说这次更新确实有不少惊喜。

专为编程场景打造
GLM-4.7 这次明显是冲着编程场景来的,官方叫"Agentic Coding"。说白了就是让 AI 更像一个真实的开发者,不只是能写几行代码,而是能够:
- 独立规划复杂的开发任务
- 协调各种工具和 API
- 理解项目上下文,写出符合架构的代码
这跟之前的辅助编程有点不一样,更像是在往"独立开发"的方向走。
性能确实不错
根据官方介绍,GLM-4.7 在几个公开基准榜单上都拿了开源第一。我查了一下,确实是实打实的数据。作为开源模型能做到这个水平,性价比挺高的。
有意思的是,这次特别强调了"工具协同"能力。简单说就是模型能更好地理解和使用各种开发工具,比如 IDE 插件、代码库、CI/CD 流程这些。这对我们做实际项目的时候挺有用的。
交互体验更自然了
之前用大模型写代码,经常会遇到一个问题:模型回答太啰嗦,或者理解指令不够精准。GLM-4.7 这次在这方面有改进:
- 回复更简洁,直奔主题
- 指令理解更准确,尤其是工具调用相关
- 生成的代码质量更高,减少修改次数
我自己试了下,让它帮我重构一个遗留的函数,结果确实比之前的版本顺手不少。
Artifacts 前端生成
这个功能挺有意思的。GLM-4.7 可以直接生成完整的前端页面,而且质量比以前好很多。不是那种丑丑的 demo,而是能直接用的东西。
比如做个播放器UI
做个简洁的看板
简洁美观,我是挺喜欢的。
使用体验
API 调用没什么特别的,还是标准的 OpenAI 格式,切换成本很低。官方提供了 Python、Java 等语言的 SDK,文档也比较清晰。
代码示例大概是这个样子:
from zai import ZhipuAiClient
client = ZhipuAiClient(api_key="your-api-key")
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{"role": "user", "content": "帮我写一个 REST API 接口"}
],
thinking={"type": "enabled"},
max_tokens=65536
)
print(response.choices[0].message)总体感受
GLM-4.7 这次给我的感觉是:更实用,更贴近真实开发场景。
如果你是个人开发者或者小团队,需要一些能独立完成复杂任务的 AI 助手,这个模型值得试试。尤其是它的工具协同和任务规划能力,能省不少时间。
当然,它不是完美的, 有兴趣的朋友可以去官方文档看看,自己体验一下。毕竟实际效果,还是要用过才知道。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)