OSKGC开源重磅发布:构建知识图谱新基准,解决大模型本体约束难题,必藏!
本文提出OSKGC基准数据集,解决知识图谱构建中本体模式简单、数据对齐差等问题。该数据集基于WebNLG构建,通过查询DBpedia本体并结合维基百科进行人工细粒度标注,形成包含207种实体类型和382种关系的层次化本体模式。关键创新包括:(1)细粒度实体类型标注(如区分"总统"与"市长");(2)完整的层次结构构建(如"总统→政治家→人"
本文提出OSKGC基准数据集,解决知识图谱构建中本体模式简单、数据对齐差等问题。该数据集包含细粒度实体类型标注(如区分"总统"、“市长”)和完整层次结构,确保文本-三元组-本体模式高度一致。同时提出结构相似度(SS)评估指标。实验显示,即使GPT-4o等先进模型仍存在关系错误和本体违反问题,凸显了该基准的挑战性。
1 引言
知识图谱是一种将信息以结构化方式存储的技术,它把现实世界中的知识表示成"三元组"的形式(主语-关系-宾语),比如(阿拉巴马州,所属国家,美国)。这种结构化的知识存储方式能够支持问答系统、推荐系统等应用。然而,知识图谱常常面临信息不完整的问题,需要从新的文本中提取信息来更新。目前从文本构建知识图谱时存在一个关键挑战:现有的数据集要么完全开放式提取(不考虑知识图谱的结构规范),要么虽然提供了本体模式(相当于知识图谱的"建筑蓝图"),但这些模式过于简单,缺乏层次结构,无法处理复杂的实体类型区分。 更重要的是,现有数据集中的文本、三元组和本体模式之间经常存在不匹配的问题,导致数据质量不高,难以用于实际的知识图谱扩展任务。
综合,本文面临的挑战主要体现在以下几个方面:
- 本体模式过于简单:现有的本体驱动型数据集(如TEXT2KGBENCH)的本体模式呈现星形结构,缺乏层次信息,无法有效区分细粒度的实体类型
- 数据对齐质量差:现有数据集中的文本、三元组和本体模式之间存在不匹配,影响数据的可用性和模型的训练效果
- 缺乏细粒度标注:大多数数据集没有提供实体的细粒度类型标注,比如只标注"政治家"而不区分"总统"、"市长"等具体角色
- 评估指标不完善:缺少专门评估构建的知识图谱与预定义本体模式之间结构相似度的指标
针对这些挑战,本文提出了一种具有层次化本体模式和细粒度实体类型标注的"OSKGC基准数据集":
OSKGC(Ontology Schema-based Knowledge Graph Construction)的核心思想是:为知识图谱构建任务提供一个高质量的基准数据集,其中包含对齐良好的文本、三元组和本体模式。这个数据集的特别之处在于三个方面:第一,它为每个实体提供了细粒度的类型标注,比如不只是标注"政治家",而是具体标注为"总统"、“副总统"或"市长”;第二,它构建了完整的层次结构,比如"总统→政治家→人"这样的从属关系链,就像生物分类学中"金毛犬→犬科→哺乳动物"的层级关系一样;第三,它确保了文本内容、提取的三元组和预定义的本体模式三者之间高度一致,避免了信息错配的问题。研究团队基于WebNLG数据集,通过查询DBpedia本体、结合维基百科和Wikidata等外部知识源进行人工标注,构建了涵盖57个类别、包含207种实体类型和382种关系的数据集。此外,论文还提出了一个新的评估指标"结构相似度"(SS),用来衡量模型构建的知识图谱与预定义本体模式的结构对齐程度,这就像是评估学生绘制的组织架构图与标准答案的相似程度。
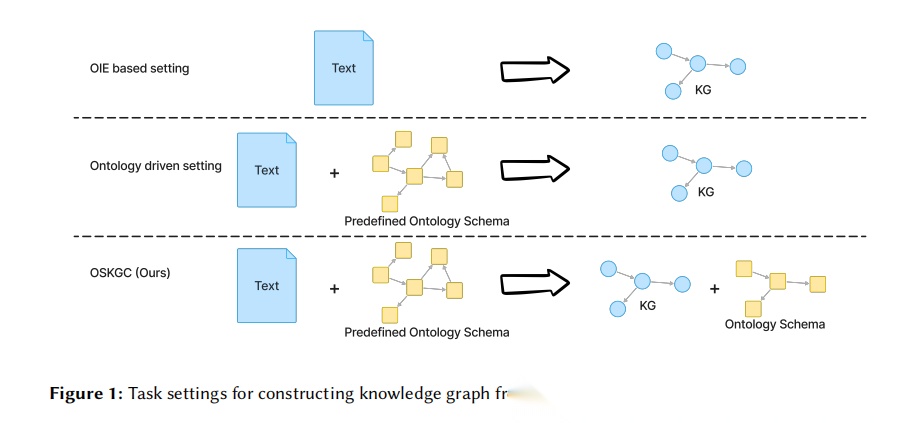
图1. 知识图谱构建任务设置对比图:这幅图清晰展示了三种不同的知识图谱构建任务设置。第一种是基于开放信息抽取(OIE)的设置,仅以文本作为输入,输出知识图谱三元组。第二种是本体驱动设置,以文本和预定义本体模式作为输入,输出知识图谱。第三种是OSKGC的任务设置,同样以文本和预定义本体模式作为输入,但输出包括知识图谱和对应的本体模式两部分。这幅图通过简洁的图标和箭头展示了输入输出关系,突出了OSKGC任务设置的独特性——不仅要抽取正确的三元组,还要确保构建的知识图谱模式与预定义本体模式保持结构一致性。图中使用蓝色矩形表示文本,黄色网格结构表示本体模式,蓝色节点网络表示知识图谱,视觉效果直观明了。
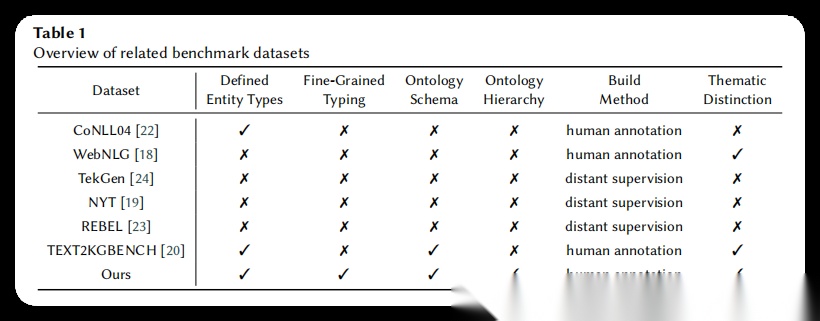
表1. 相关基准数据集对比表:该表系统对比了OSKGC与现有基准数据集在多个关键维度上的差异。对比维度包括:是否定义实体类型、是否进行细粒度类型标注、是否包含本体模式、本体模式是否具有层次结构、构建方法(人工标注或远程监督)以及是否具有主题区分。表中涵盖了CoNLL04、WebNLG、TekGen、NYT、REBEL、TEXT2KGBENCH等现有数据集。通过对比可以清楚看出,只有OSKGC同时满足所有六个维度的要求,特别是在细粒度类型标注和本体层次结构方面,OSKGC填补了现有数据集的空白。
2 研究方法
2.1 本体模式构建总览
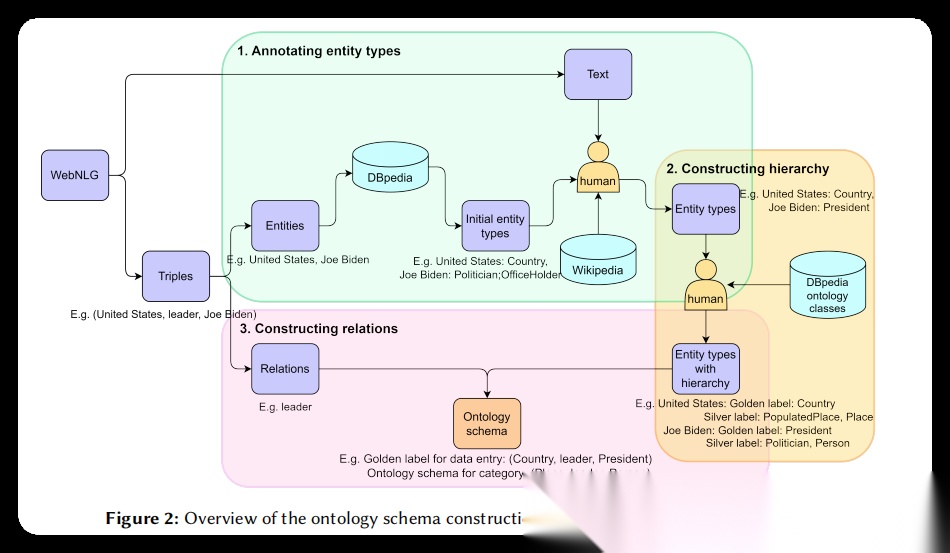
图2. OSKGC本体模式构建流程概览图:这是论文方法部分最核心的算法框图,完整展示了本体模式构建的三个关键步骤及其数据流转过程。图中左侧显示了数据来源WebNLG,包含文本、实体和三元组信息。第一步"标注实体类型"展示了如何查询DBpedia获取初始实体类型,然后利用Wikipedia进行人工细粒度标注的过程,例如将"United States"和"Joe Biden"分别标注为更精确的类型。第二步"构建层次结构"说明了如何基于DBpedia本体层次为实体类型添加包含关系,图中用黄色背景突出显示了人工标注和层次构建的结合过程,展示了实体类型如何通过层次关系组织起来。第三步"构建关系"展示了如何从三元组的关系(如"leader")构建类型级别的模式标签,以及如何通过根节点类型(如"Place"和"Person")形成预定义本体模式。整幅图用不同颜色区分不同步骤,绿色表示实体类型标注,黄色表示层次构建,粉色表示关系构建,逻辑清晰,层次分明,完整呈现了从原始数据到最终本体模式的转换过程。
论文提出的OSKGC数据集构建方法的核心在于本体模式的精心设计。这个本体模式构建过程有两个重要目标:第一个目标是为每个文本-三元组对生成一个模式标签,这个标签会在训练和评估阶段使用;第二个目标是为每个类别构建一个预定义的本体模式,作为知识图谱构建的结构化指南。直觉上,你可以把本体模式理解为知识图谱的"建筑蓝图"——就像盖房子需要先有设计图纸一样,构建知识图谱也需要一个规范的模式来指导。
论文选择WebNLG数据集作为基础,这个数据集包含文本和对应的三元组,但缺少明确的实体类型信息。为了确保本体模式与文本-三元组数据之间的对齐,论文设计了一个三步走的构建流程:首先对每个三元组中的实体标注其对应的实体类型,将实例级的三元组转换为类型级的模式;然后基于DBpedia本体的包含层次,为每个标注的实体类型递归添加更通用的上层类型,构建出包含关系的层次结构;最后,对每个类别聚合所有模式标签,通过关系连接根层级的通用类型,形成核心结构模式。整个构建流程如图2所示,清晰展现了从原始数据到最终本体模式的转换过程。
2.2 实体类型的细粒度标注
实体类型标注是本体模式构建的第一步,也是最基础的一步。这一步的目标是为每个三元组中的实体分配准确的类型标签。具体来说,论文首先查询DBpedia来获取每个实体的最深层次类型作为初始类型。举个例子,对于实体"Rome"(罗马),从DBpedia查询到的初始类型是"City"(城市)。但这还不够精确,因为罗马不是普通的城市,而是意大利的首都。因此,论文在初始类型的基础上,结合Wikipedia和Wikidata等外部知识源,对每个实体进行人工细粒度标注(累!)。对于罗马这个例子,经过人工标注后,类型被细化为"CapitalCity"(首都城市),这样就更准确地反映了实体的真实属性。
这个过程中有一个特别重要的细节:论文会参考实体在文本中的上下文来确保标注的类型与文本内容一致。这是因为很多实体具有多义性。举个例子,实体"Christian Panucci"(克里斯蒂安·帕努奇)在职业生涯早期是一名足球运动员,后来成为了足球教练。对于这种多义实体,论文会根据文本的上下文标注与之匹配的类型。如果文本讲述的是他作为球员的时期,就标注为"SoccerPlayer"(足球运动员);如果讲述的是他作为教练的时期,就标注为"SoccerManager"(足球教练)。通过这种方式,确保构建的本体模式始终与文本内容保持一致,避免出现类型标注与文本语义不符的情况。这就好比给一个人贴标签,你需要根据当前的场景和身份来选择最合适的标签,而不是简单地用一个笼统的标签来概括。
2.3 层次结构的构建
在完成实体类型的细粒度标注后,下一步是为所有实体类型添加包含关系的层次结构。这个层次结构的作用是将标注的实体类型按照从具体到抽象的顺序组织起来,形成一个多层次的分类体系。论文使用DBpedia本体类的层次结构作为参考。具体来说,对于每个实体类型,论文会查询其到根节点的层次路径。举个例子,对于实体类型"President"(总统),查询到的路径是"President → Politician → Person → Animal → Eukaryote → Species → Thing"。
但这个路径太长了,包含了很多过于通用的节点。论文对这些路径进行了精简,删除了那些不利于有效分类的节点。具体来说,论文会删除靠近根节点的过于通用的节点,只保留从能够识别该实体类型的最通用节点开始的路径。对于"President"这个例子,能够识别它的最通用节点是"Person"(人物),因此保留的路径是"President → Politician → Person",而"Person"之上的过于通用的节点都被删除了。这就好比给物品分类,我们不需要从"宇宙中的物质"这样过于宽泛的概念开始,而是从"生物"或"人"这样更有区分度的概念开始分类。
此外,DBpedia层次结构中的某些节点有一些兄弟节点在OSKGC中没有实例化的实体。这些节点不仅无法帮助分类,还会增加不必要的复杂性。因此,论文将它们从路径中删除。举个例子,对于实体类型"FormulaOneRacer"(一级方程式赛车手),其路径是"FormulaOneRacer → RacingDriver → MotorsportRacer → Athlete → Person"。由于"MotorsportRacer"和"RacingDriver"的兄弟节点在OSKGC中没有实例化实体,这些兄弟节点会被删除,从而简化层次结构。
需要注意的是,并非所有实体类型都有层次结构。引入层次结构的目的是为了对细粒度标注的实体类型进行分类,因此对于那些本身就容易区分的实体类型,论文没有构建额外的层次。例如,“EthnicGroup”(民族群体)和"Language"(语言)这样的实体类型本身就很明确,不需要额外的层次来帮助分类。对于所有具有层次结构的实体类型,论文将人工标注的实体类型定义为金标签(golden label),而层次结构中的所有上层节点定义为银标签(silver label)。举个例子,对于类型"President",金标签是"President",而银标签包括"Politician"和"Person"。金标签代表细粒度和精确的实体类型,而银标签对应更通用的实体类型。这些银标签在后续评估构建的知识图谱的结构相似度时会发挥重要作用,如图3所示的本体模式示例中,紫色节点就是根层级的通用类型(类似银标签的最顶层),蓝色节点则是细粒度类型(包含金标签)。
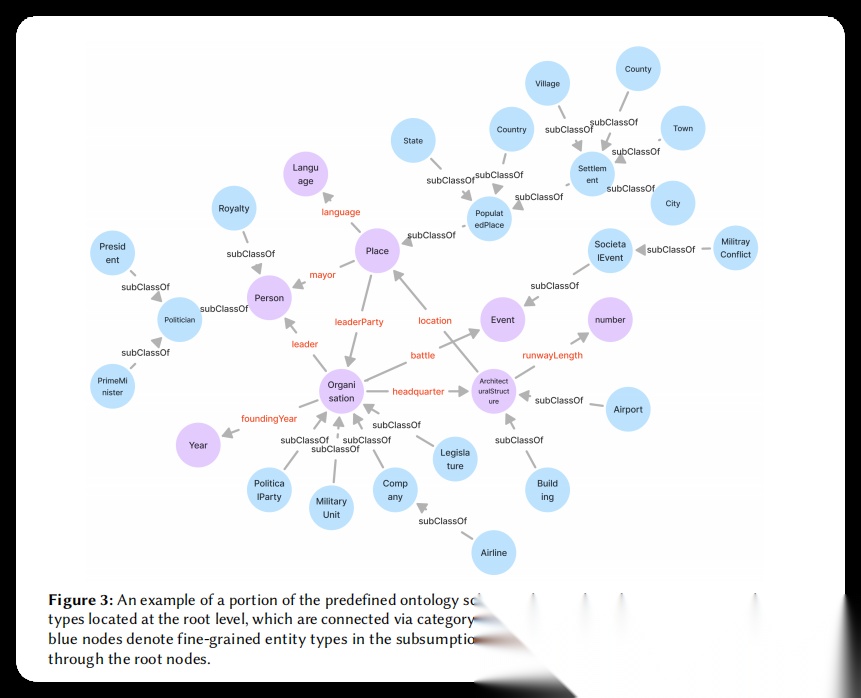
图3. 预定义本体模式示例图:这幅图展示了OSKGC中预定义本体模式的一个局部结构示例,清楚呈现了本体模式的层次化组织方式。图中紫色节点代表位于根层级的通用实体类型,如"Person"(人物)、“Place”(地点)、“Year”(年份)、“Event”(事件)、“Language”(语言)等,这些根节点通过特定领域的关系(用橙色文字标注)相互连接,形成核心结构骨架。蓝色节点表示细粒度的实体类型,它们通过"subClassOf"(子类关系)连接到相应的根节点,构成包含层次。例如,“President”(总统)和"Politician"(政治家)通过subClassOf关系连接到"Person";“Country”(国家)、“State”(州)、“City”(城市)等通过多层subClassOf关系最终连接到"Place"。图中还展示了实体类型之间的关系连接,如"Place"和"Person"之间的"mayor"(市长)关系、“leader”(领导者)关系等。整个图结构既展示了横向的关系网络,又展示了纵向的层次体系,直观反映了OSKGC本体模式同时包含关系和层次两个维度的设计特点。图中使用了清晰的颜色编码和布局,使得复杂的本体结构一目了然。
2.4 关系的构建
在完成实体类型及其层次结构的构建后,第三步是构建实体类型之间的关系。论文基于WebNLG语料中实例化的三元组来构建这些关系。具体来说,论文使用三元组中的关系来连接标注的实体类型及其在层次结构中的根层级类型,从而生成数据的模式标签和预定义本体模式。
举个例子,给定三元组(United States, leader, Joe Biden),其中"United States"的类型是"Country"(国家),“Joe Biden"的类型是"President”(总统),那么这条数据的模式标签就是(Country, leader, President)。接下来,论文基于层次结构确定"Country"和"President"对应的根节点分别是"Place"(地点)和"Person"(人物)。因此,派生出(Place, leader, Person)这个类型级三元组,并将其纳入预定义本体模式中。这就好比从具体的事实"美国的领导人是拜登"抽象出一般规律"地点可以有人物作为领导者"。
由于预定义本体模式中通过关系连接的实体类型都是层次结构中的根节点(代表最通用的分类),因此每个数据实例的具体模式标签不会直接体现在预定义本体模式中,而是通过层次结构与之关联。论文遵循WebNLG的分类标准,根据三元组数量将数据分为三组(包含1个、2个或3个三元组),并进一步细分为19个主题类别,总共形成57个类别。对于每个类别,论文独立总结出一个预定义本体模式。图3展示了预定义本体模式的一个局部示例,其中紫色根节点通过特定领域的关系相互连接形成核心结构,蓝色细粒度节点通过"subClassOf"关系链接到核心结构,整体构成了既包含关系网络又包含层次体系的完整本体模式。
2.5 文本-三元组对的清洗

表2. WebNLG中文本-三元组对存在的问题及示例表:该表列举了WebNLG数据集中存在的三类主要问题,每类问题都配有具体的文本和标签示例。第一类是实体不一致问题,例如文本中提到"American English"作为语言,但三元组中的尾实体是"English Americans"(一个民族群体),存在类型错误。第二类是语义不一致问题,如文本表明"Bacon"和"Sausage"都是"Bacon Explosion"的主要配料,但三元组标签只将"Sausage"标注为主要配料,而"Bacon"仅标注为普通配料。第三类是无关三元组问题,标签中包含了文本未提及的信息,如三元组(Asterix, alternativeName, Astérix)在文本中没有对应内容。表格用加粗标注问题部分,清晰展示了数据清洗的必要性。
除了本体模式,OSKGC的另一个关键组成部分是文本-三元组对。这部分数据来源于WebNLG数据集。为了确保文本和三元组之间的一致性和对齐,论文对文本-三元组对进行了彻底的审查和验证。如表2所示,WebNLG中存在的问题主要包括三类:实体不一致、语义不一致和无关三元组。
第一类问题是实体不一致。举个例子,文本中提到"American English"作为一种语言,但三元组中的尾实体却是"English Americans",这是一个民族群体,存在明显的类型错误。在这种情况下,论文会修正三元组中的实体,确保它与文本一致。这就好比你写了"今天天气很好",但标注却说"今天心情很好",显然不匹配,需要把标注改成"今天天气很好"。
第二类问题是语义不一致。三元组可能包含正确的实体,但它们传达的语义信息与文本不符。举个例子,文本表明"Bacon"(培根)和"Sausage"(香肠)都是"Bacon Explosion"的主要配料,但三元组标签只将"Sausage"标注为主要配料(mainIngredient),而"Bacon"仅标注为普通配料(ingredient)。这种不一致会误导模型,影响评估结果。为了解决这个问题,论文修改了三元组,确保它们准确反映文本内容。
第三类问题是无关三元组。标签中的三元组包含了文本未提及的信息。举个例子,标签包含三元组(Asterix, alternativeName, Astérix),但文本中并没有提到这个信息。在这种情况下,论文删除了与文本无关的三元组。通过上述清洗过程,论文纠正了WebNLG中的错误,确保文本和三元组之间的相互对齐,从而保证了OSKGC的数据质量。
2.6 结构相似度评估指标
在OSKGC的任务设置中,目标不仅是从文本中抽取正确的三元组,还要确保构建的知识图谱与预定义本体模式保持结构对齐。为此,论文提出了一个名为结构相似度(Structural Similarity, SS)的评估指标,用于衡量构建的知识图谱模式与预定义本体模式之间的对齐程度。
这个指标的设计思路是这样的:首先评估单个实体类型对之间的结构相似度,也就是金标准实体类型 和预测实体类型 之间的相似度。设 表示从金标准类型 到本体根节点的路径长度。根据 和 在本体层次结构中的位置关系,论文定义了两种匹配情况。
第一种情况是祖先匹配(ancestor match):如果预测类型 位于金标准类型 到根节点的祖先路径上,那么就属于祖先匹配。在这种情况下,结构相似度得分使用如下公式计算:
其中, 是从 到 的路径长度, 是控制得分衰减速率的参数,论文设为2。这个设计体现了一个直观的原则:预测类型在层次结构中离金标准类型越近,获得的SS得分就越高。举个例子,如果金标准类型是"President"(总统),预测类型是"Politician"(政治家),由于"Politician"是"President"的直接上层类型, 较小,所以得分较高;但如果预测类型是更上层的"Person"(人物), 较大,得分就会降低。这就好比射箭,越接近靶心得分越高。
第二种情况是最低公共祖先匹配(LCA match):如果预测类型 不在 的祖先路径上,但它们有一个最低公共祖先(Lowest Common Ancestor, LCA),那么就属于LCA匹配。在这种情况下,相似度得分同时考虑 和 到它们LCA的距离。此外,论文还引入了局部结构熵作为惩罚因子,用于建模预测节点周围局部拓扑结构的复杂性。得分计算公式为:
其中, 和 分别表示从 和 到LCA的路径长度; 是预测类型 的兄弟节点数量; 是控制熵惩罚强度的参数,论文设为1.5。在图表示学习中,结构熵通常用于量化图结构的复杂性和不确定性。局部结构熵项 用于捕捉预测节点所在子树的分支复杂性。更多的兄弟节点意味着更高的局部不确定性和更大的误分类可能性,因此会带来更大的惩罚。这个设计符合信息论中熵的原理,熵用于量化系统中的不确定性和复杂性。
举个例子,假设金标准类型是"President",预测类型是"Scientist"(科学家),它们的LCA是"Person"。由于"President"和"Scientist"处于完全不同的分支,虽然它们有共同祖先,但得分会因为两者距离LCA都较远而降低。如果"Scientist"这个节点有很多兄弟节点(比如"Engineer"工程师、"Doctor"医生等),那么局部结构熵会进一步降低得分,因为这意味着模型在众多选项中选错了。
如果 和 之间不存在公共祖先,说明它们属于本体中不同的连通分量,此时SS得分为0,表示完全不匹配。
对于每个预测的模式,最终的SS得分通过将其头实体类型和尾实体类型的SS得分相乘来计算。在数据条目层面,由于一个条目可能包含多个模式,整体SS通过对所有模式的得分求和并除以对应金标准标签的数量来计算。值得注意的是,当预测三元组的数量超过金标准三元组的数量时,论文引入了额外的惩罚因子来抑制预测中的冗余,从而确保指标在不同规模的结果中保持强大的区分能力和鲁棒性。
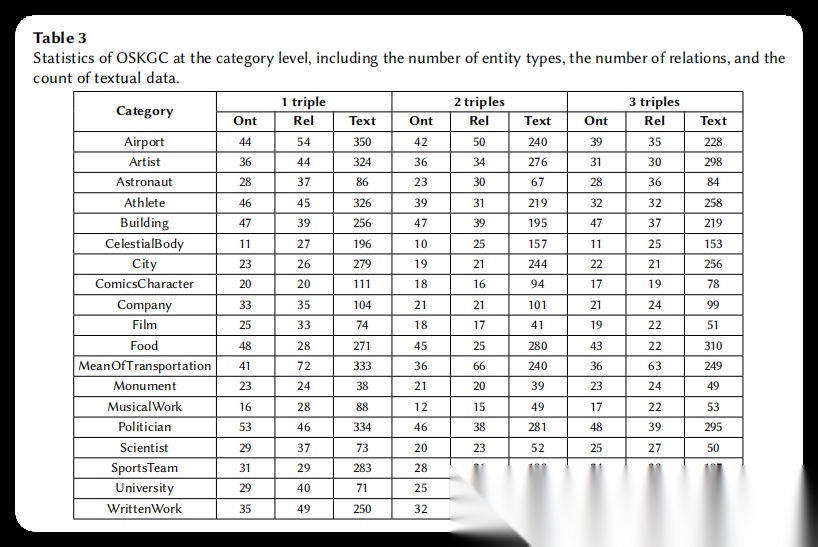
**表3. OSKGC类别级统计表**:这是一个详细的数据统计表,展示了OSKGC数据集在57个类别上的分布情况。表格按照三元组数量(1个、2个、3个三元组)分为三组,每组又包含19个主题类别。对于每个类别,表格统计了本体类型数量(Ont)、关系数量(Rel)和文本数据数量(Text)。从表中可以看出,不同类别的复杂度差异较大,例如Politician类别包含的本体类型和关系数量较多,而ComicsCharacter类别相对较少。整个数据集总计包含207个实体类型、382个关系和10,183条文本数据。
3 实验
3.1 实验设置
- 数据集:使用自建的OSKGC数据集,包含57个类别,涵盖机场、艺术家、宇航员、运动员等19个主题领域。数据集包含10,183条文本条目、3,446个实体、207种实体类型和382种关系。每个类别按7:1:2的比例划分为训练集、验证集和测试集,测试集中的实体不在训练集和验证集中出现。
- 基线模型:选择了7个主流大语言模型进行评估,包括4个开源模型(Llama3-8b、Phi-3-small、Qwen2.5-7b、Mistral-7b)和3个商业模型(GPT-4o、Gemini 1.5 Pro、Claude 3.5 Sonnet)。
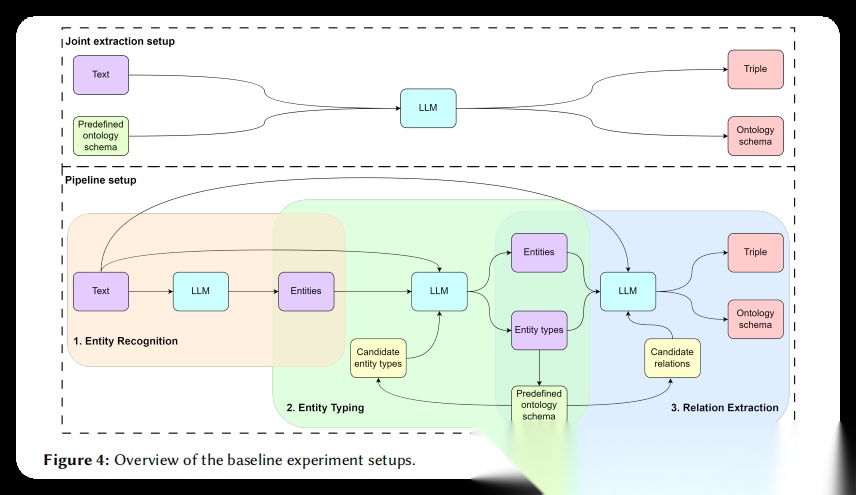
- 实验设置:采用两种实验方案——联合抽取和流水线方法。联合抽取通过单个提示一次性完成知识图谱构建;流水线方法分为三个步骤**:实体识别、实体类型标注和关系抽取**。两种方案都使用one-shot示例,示例选择采用随机选择和基于相似度选择两种方式。
- 评估指标:使用精确率(Precision)、召回率(Recall)、微观F1(Micro F1)、宏观F1(Macro F1)评估三元组抽取性能;使用结构相似度(SS)评估构建的知识图谱模式与预定义本体模式的对齐程度。
- 实现细节:在联合抽取中,将实体类型、关系和层次结构信息与测试文本一起输入模型。在流水线方法中,实体识别步骤提取实体名称;实体类型标注步骤根据候选实体类型为实体分配类型;关系抽取步骤根据实体类型的根节点筛选候选关系,减少无关关系的干扰。
3.2 实验结果
| 实验类型 | 实验目的 | 图表 | 主要结果 |
|---|---|---|---|
| 联合抽取实验 | 评估模型一次性处理复杂本体信息并构建知识图谱的能力 | 表4、图4 | 联合抽取在三元组抽取指标上表现更好,但在结构相似度上不如流水线方法 |
| 流水线实验 | 评估模型分步骤构建知识图谱的能力 | 表4、图4 | 流水线方法在结构相似度上表现更好,但三元组抽取性能略低于联合抽取 |
| 示例选择对比实验 | 比较随机选择和相似度选择示例的效果 | 表4 | 基于相似度选择的示例在所有指标上都优于随机选择 |
| 错误分析 | 识别基线模型存在的主要问题类型 | 表5 | 发现五类主要错误:关系错误、实体错误、事实错误、幻觉和本体违反 |
3.2.1 实验一、联合抽取实验
 目的:评估大语言模型是否能够在单次提示中处理大量复杂的本体模式信息,并一次性完成实体和关系的联合抽取来构建知识图谱。
目的:评估大语言模型是否能够在单次提示中处理大量复杂的本体模式信息,并一次性完成实体和关系的联合抽取来构建知识图谱。
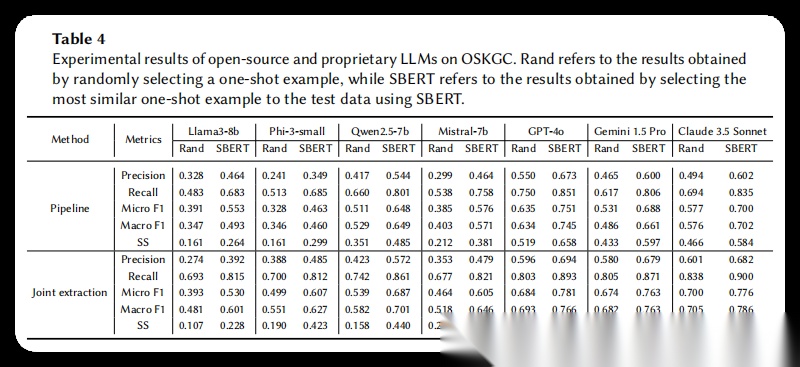
涉及图表:表4(此表展示了各个模型在联合抽取设置下的详细性能表现,包括使用随机选择和相似度选择示例时的精确率、召回率、F1值和结构相似度)、图4(此图展示了联合抽取的完整流程,即将文本和预定义本体模式直接输入大语言模型,一次性输出三元组和对应的本体模式)
实验细节概述:这是论文的核心实验之一。研究者设计了专门的提示模板(Prompt 1),将实体类型、关系和层次结构等本体模式信息与测试文本一起作为输入。提示中包含一个one-shot示例来指导模型理解任务和输出格式。模型需要在理解复杂本体约束的同时,从文本中提取正确的三元组并为其分配对应的本体模式标签。实验采用了两种示例选择策略:随机选择(从训练集中随机抽取固定样本)和相似度选择(使用SBERT为每个测试样本找到最相似的训练样本)。输入的本体模式信息是原始数据,未经任何额外处理,同一类别的所有测试数据共享相同的本体模式。模型输出包括抽取的三元组及其对应的本体模式。研究者在7个主流大语言模型上进行了测试,覆盖不同参数规模和架构类型,以全面评估联合抽取方法在处理本体驱动的知识图谱构建任务时的表现。
结果:在联合抽取设置下,商业模型整体表现优于开源模型。使用相似度选择示例时,GPT-4o达到了最高的微观F1值0.781,Claude 3.5 Sonnet的宏观F1达到0.786,而Gemini 1.5 Pro在结构相似度SS指标上取得了最高分0.691。对比随机选择和相似度选择,后者在所有模型上都带来了显著提升,平均提升幅度在10-20个百分点。联合抽取在召回率上表现出色,大多数模型的召回率超过0.8,说明模型能够捕捉到文本中的大部分事实信息。但精确率相对较低,表明模型倾向于生成更多三元组,导致部分错误预测。在结构相似度方面,联合抽取的表现不如流水线方法,说明在一次性处理大量信息时,模型难以准确把握本体模式的层次结构约束。
3.2.2 实验二、流水线实验
目的:评估将知识图谱构建任务分解为实体识别、实体类型标注和关系抽取三个独立步骤后,模型在各个子任务上的表现及整体构建效果。
涉及图表:表4(此表展示了流水线方法在不同模型和示例选择策略下的性能表现)、图4(此图展示了流水线方法的三阶段流程)、Prompt 2-4(这三个提示模板分别展示了实体识别、实体类型标注和关系抽取三个步骤的具体实现)
实验细节概述:流水线方法将复杂的知识图谱构建任务分解为三个相对简单的子任务,每个子任务使用独立的提示模板。第一步实体识别(Prompt 2)要求模型从文本中找出所有命名实体,包括数字、代码和日期,至少识别两个实体,避免提取形容词或数值单位。第二步实体类型标注(Prompt 3)为识别出的实体分配类型,输入包括实体名称、候选实体类型、原文本和示例,候选类型来自该数据所属类别的本体模式。第三步关系抽取(Prompt 4)识别实体间的关系形成三元组,为了简化提示并减少无关信息,研究者采用了智能的候选关系筛选策略:根据第二步得到的实体类型,沿层次结构追溯到根节点类型,然后收集这些根节点之间存在的所有关系作为候选。这种设计有效降低了候选关系的数量,使模型能够更专注于相关关系的判断。每个步骤都提供one-shot示例,同样采用随机选择和相似度选择两种策略。
结果:流水线方法在结构相似度SS指标上普遍优于联合抽取,使用相似度选择时,Gemini 1.5 Pro和Claude 3.5 Sonnet的SS分数分别达到0.597和0.584,明显高于联合抽取设置。这表明将任务分解后,模型能够更好地理解和遵循本体模式的层次结构约束。然而,在三元组抽取的准确性上,流水线方法略逊于联合抽取。GPT-4o在流水线设置下的微观F1为0.751,低于联合抽取的0.781。这种性能差异可能是由于误差传播:实体识别阶段的错误会影响后续的类型标注和关系抽取。相似度选择示例同样带来了显著改进,Claude 3.5 Sonnet使用相似度选择后微观F1从0.577提升到0.700。在开源模型中,Qwen2.5-7b表现最佳,使用相似度选择时微观F1达到0.648,SS达到0.485,展现了较强的任务理解能力。
3.2.3 实验三、示例选择策略对比
目的:比较随机选择和基于文本相似度选择one-shot示例对模型性能的影响。
涉及图表:表4(此表的Rand和SBERT两列对比展示了两种示例选择策略的效果差异)
实验细节概述:研究者设计了两种示例选择方法来评估示例质量对模型表现的影响。随机选择方法为每个类别从训练集中随机抽取一个固定样本作为示例,该类别的所有测试数据共享这个示例。相似度选择方法使用SBERT(Sentence-BERT)模型计算测试文本与训练集文本的语义相似度,为每个测试样本选择最相似的训练样本作为示例。这意味着每个测试数据都有其独特的、与其内容最相关的示例。通过这种对比,可以评估示例与测试数据的相关性对模型理解任务和生成正确输出的重要性。
结果:相似度选择策略在所有模型和所有评估指标上都取得了明显优于随机选择的结果。在联合抽取设置中,各模型使用相似度选择后平均F1提升约13-18个百分点,SS提升约10-12个百分点。在流水线设置中,提升幅度甚至更大,部分模型的F1提升超过20个百分点。以Llama3-8b为例,在流水线设置下,使用相似度选择后微观F1从0.391提升到0.553,SS从0.161提升到0.264,提升幅度超过40%。这一结果充分说明了示例质量和相关性对于引导大语言模型完成复杂知识图谱构建任务的重要性。与测试数据内容相似的示例能够帮助模型更好地理解任务需求、本体约束和输出格式,从而生成更准确的结果。
3.2.4 实验四、错误分析
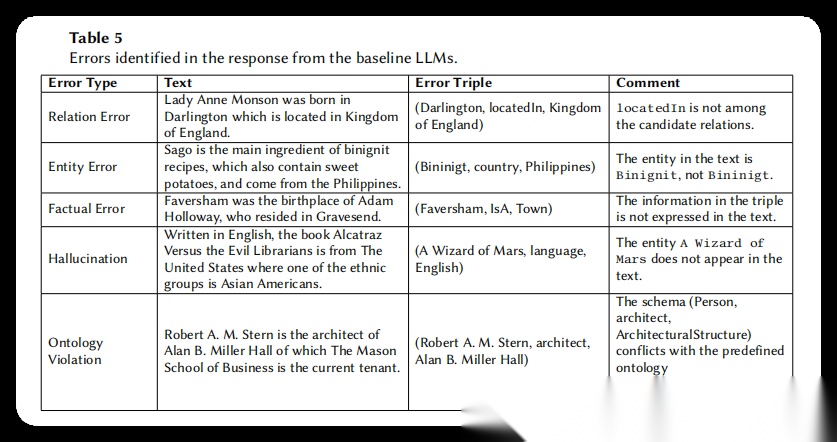
表5(此表展示了五种主要错误类型的具体示例,包括关系错误、实体错误、事实错误、幻觉和本体违反)
目的:深入分析基线模型在知识图谱构建过程中产生的主要错误类型,为未来改进方向提供指导。
涉及图表:表5(此表展示了五种主要错误类型的具体示例,包括关系错误、实体错误、事实错误、幻觉和本体违反)
实验细节概述:研究者对基线大语言模型生成的响应进行了系统性审查,特别关注了Claude 3.5 Sonnet这一性能较好的商业模型的输出。通过人工检查和分类,识别出了五种典型的错误模式。研究者为每种错误类型收集了代表性案例,记录了输入文本、模型生成的错误三元组以及错误说明。这种定性分析补充了定量实验结果,揭示了当前大语言模型在处理本体驱动的知识图谱构建任务时面临的具体挑战。
结果:分析发现五类主要错误:(1)关系错误——模型生成了不在候选关系中的关系,如将"location"错误生成为"locatedIn";(2)实体错误——模型提取的实体名称与文本不一致,如将"Binignit"错误识别为"Bininigt";(3)事实错误——生成的三元组与文本语义不符,如从"Faversham是Adam Holloway的出生地"推断出"Faversham是一个城镇"这一文中未提及的信息;(4)幻觉——生成文本中完全不存在的实体,如在讨论《Alcatraz Versus the Evil Librarians》的文本中凭空生成了《A Wizard of Mars》;(5)本体违反——生成的三元组结构与预定义本体模式冲突,如将应为(建筑,建筑师,人)的模式错误生成为(人,建筑师,建筑)。值得注意的是,这些错误即使在性能最好的商业模型中也频繁出现,在参数量较小的开源模型中则更为普遍。这表明当前的大语言模型在理解和遵循复杂本体约束方面仍有很大提升空间。
4 总结后记
本论文针对从文本构建知识图谱时缺乏层级化本体约束的问题,提出了OSKGC基准数据集。该数据集基于WebNLG重新构建,为每个实体标注了细粒度类型(比如将"政治家"细分为总统、副总统、市长等),并引入了DBpedia的层级结构来支持实体类型识别。同时提出了结构相似度(SS)评估指标,用于衡量构建的知识图谱与预定义本体schema的对齐程度。实验显示,即便是GPT-4o、Claude等先进模型,在这个任务上仍存在关系抽取错误、实体幻觉、违反本体结构等问题,证明了该基准的挑战性。
疑惑和想法:
- 文中只考虑了1-3个三元组的简单场景,对于包含更多三元组的复杂文本,现有方法会不会完全失效?能否设计增量式的构建策略?
- 层级结构目前主要依赖DBpedia,但不同领域的本体层级可能差异很大。如何让模型自适应学习领域特定的层级关系?
- Pipeline方法在schema对齐上表现更好,但triple抽取效果不如联合抽取。能否设计混合方法,在不同阶段动态选择策略?
- 评估指标SS虽然考虑了层级距离和局部结构熵,但对于"部分正确"的预测(比如预测了父类而非子类)的惩罚是否合理?
可借鉴的方法点:
- 细粒度类型标注+层级结构的思路可以应用到其他信息抽取任务,比如事件抽取中为事件类型建立层级(冲突→军事冲突→边境冲突)。
- 基于层级的结构相似度计算方法可以推广到其他需要评估结构对齐的场景,如跨语言知识图谱对齐、schema匹配等。
- 从数据源倒推构建本体的方法论值得借鉴——先从实例数据出发标注类型,再归纳出层级结构,最后形成完整schema,这种"自下而上"的方式能保证数据与schema的一致性。
- Pipeline中根据实体类型动态筛选候选关系的策略很实用,可以减少搜索空间,提升效率。这个思路可以用在大规模知识图谱补全、关系预测等任务中。
AI时代,未来的就业机会在哪里?
答案就藏在大模型的浪潮里。从ChatGPT、DeepSeek等日常工具,到自然语言处理、计算机视觉、多模态等核心领域,技术普惠化、应用垂直化与生态开源化正催生Prompt工程师、自然语言处理、计算机视觉工程师、大模型算法工程师、AI应用产品经理等AI岗位。
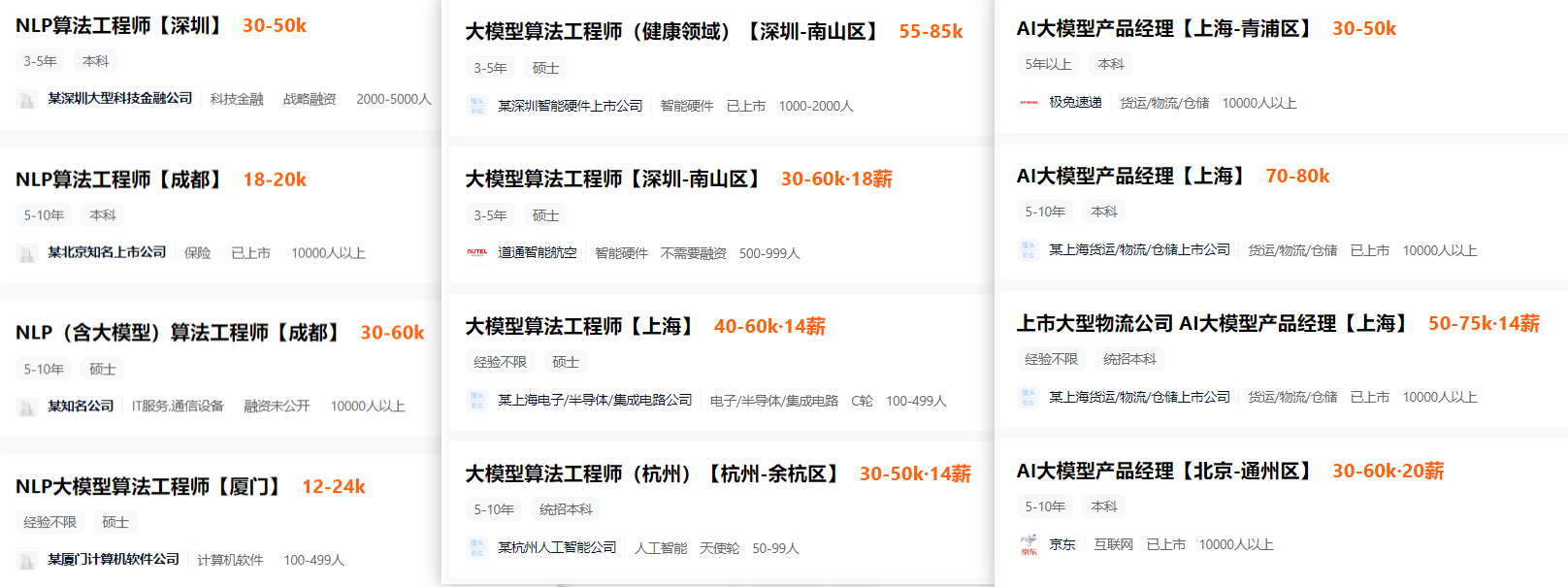
掌握大模型技能,就是把握高薪未来。
那么,普通人如何抓住大模型风口?
AI技术的普及对个人能力提出了新的要求,在AI时代,持续学习和适应新技术变得尤为重要。无论是企业还是个人,都需要不断更新知识体系,提升与AI协作的能力,以适应不断变化的工作环境。
因此,这里给大家整理了一份《2025最新大模型全套学习资源》,包括2025最新大模型学习路线、大模型书籍、视频教程、项目实战、最新行业报告、面试题等,带你从零基础入门到精通,快速掌握大模型技术!
由于篇幅有限,有需要的小伙伴可以扫码获取!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。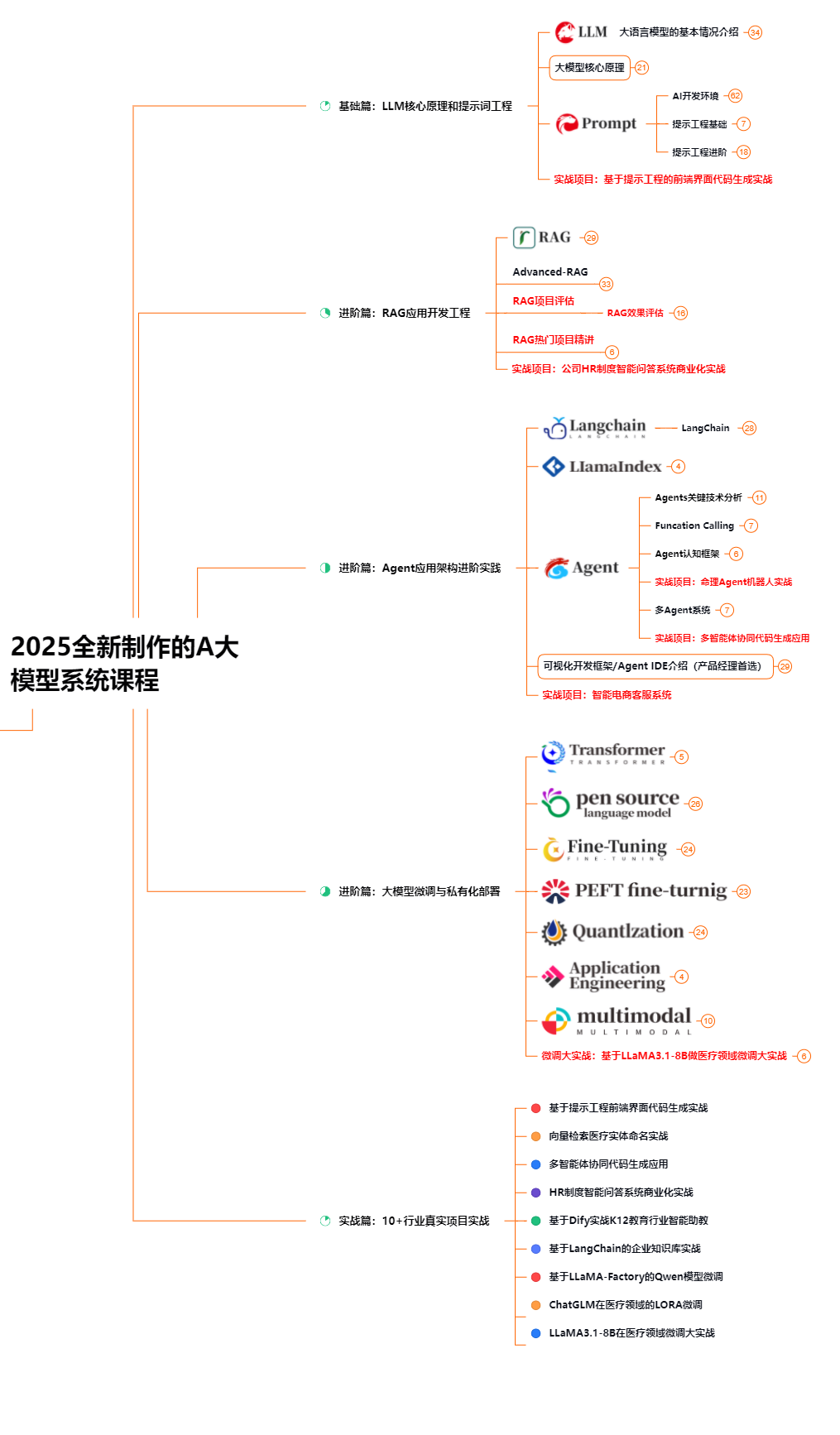
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
5. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

为什么大家都在学AI大模型?
随着AI技术的发展,企业对人才的需求从“单一技术”转向 “AI+行业”双背景。企业对人才的需求从“单一技术”转向 “AI+行业”双背景。金融+AI、制造+AI、医疗+AI等跨界岗位薪资涨幅达30%-50%。
同时很多人面临优化裁员,近期科技巨头英特尔裁员2万人,传统岗位不断缩减,因此转行AI势在必行!

这些资料有用吗?
这份资料由我们和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


大模型全套学习资料已整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献464条内容
已为社区贡献464条内容

所有评论(0)