让大模型在昇腾NPU上“起飞”:vLLM-Ascend调试调优全攻略
vLLM-Ascend的调试调优,说难不难,关键是工具和经验。基础优化打底,剖析工具找问题,针对性调参数,就能出好效果。我的博客基于仓库文档和实际操作,如果你有更好方法,欢迎评论交流。昇腾开源社区挺活跃的,多看readme和教程,能少走弯路。。里面有更多例子。注明:昇腾PAE案例库对本文写作亦有帮助。
一、引言
最近在玩昇腾NPU上的vLLM-Ascend项目。这个开源仓库挺有意思的,它是vLLM的硬件插件版本,专门为华为昇腾芯片优化,支持大模型的推理加速。我之前在部署一些LLM服务时,经常遇到性能瓶颈或者奇怪的精度问题,所以花了不少时间研究调试和调优。今天分享一下我的心得,重点是调试调优的经验技巧。希望对大家有帮助,如果你也是在折腾昇腾环境,不妨试试这些方法。
vLLM-Ascend的核心是让大模型推理在NPU上跑得更快、更稳。它支持像Qwen这样的模型,部署起来相对简单,但实际用的时候,总有地方需要调。比方说,内存溢出、推理速度慢,或者输出结果不对劲。这些问题不调优的话,服务就没法上线。我的经验是,从环境开始优化,然后用工具剖析问题,最后针对性调整参数。整个过程像修车,先检查零件,再试跑。
下面我分几个部分聊聊,先说基础优化,然后是调试工具的使用,最后分享一些实际案例。文章会配上流程图和截图,便于理解。所有操作基于Atlas 800系列NPU,CANN版本8.3以上,Python 3.11。
二、基础环境优化
调试调优的第一步,不是直接看代码,而是优化环境。环境不对,后面再怎么调都白搭。我在实践中发现,昇腾的性能很大程度上取决于OS和库的配置。以下是我的几点经验。
2.1 容器化部署
首先,容器化部署是必须的。用Docker跑vLLM-Ascend,能隔离环境,避免主机污染。启动容器时,要挂载NPU设备和相关库。命令大概这样:
export DEVICE=/dev/davinci0
export IMAGE=quay.io/ascend/vllm-ascend:v0.11.0rc3
docker run --rm \
--name vllm-ascend \
--shm-size=1g \
--device $DEVICE \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-p 8000:8000 \
-it $IMAGE bash
运行后,进容器检查npu-smi,确保NPU识别正常。截图如下:
这张图显示了NPU的利用率和内存使用,如果没问题,就可以继续。
2.2 优化Python和pip
接下来,优化Python和pip。默认Python可能没启用LTO和PGO,这些能提升编译效率。我下载了优化的Python包安装:
mkdir -p /workspace/tmp
cd /workspace/tmp
wget https://repo.oepkgs.net/ascend/pytorch/vllm/lib/libcrypto.so.1.1
wget https://repo.oepkgs.net/ascend/pytorch/vllm/lib/libomp.so
wget https://repo.oepkgs.net/ascend/pytorch/vllm/lib/libssl.so.1.1
wget https://repo.oepkgs.net/ascend/pytorch/vllm/python/py311_bisheng.tar.gz
cp *.so* /usr/local/lib
tar -zxvf py311_bisheng.tar.gz -C /usr/local/
mv /usr/local/py311_bisheng /usr/local/python
# 然后设置软链接和PATH
安装后,pip用清华镜像加速:pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple。这样下载模型快多了。
OS层面,内存分配器很重要。默认的可能碎片化严重,我试过jemalloc和tcmalloc。jemalloc适合多线程:
apt update && apt install libjemalloc2 -y
export LD_PRELOAD="/usr/lib/aarch64-linux-gnu/libjemalloc.so.2:$LD_PRELOAD"
tcmalloc更适合大内存场景:
apt install libgoogle-perftools4 libgoogle-perftools-dev -y
export LD_PRELOAD="$LD_PRELOAD:/usr/lib/aarch64-linux-gnu/libtcmalloc.so"
我对比过,用jemalloc后,推理内存使用降了10%左右。结果图见下:
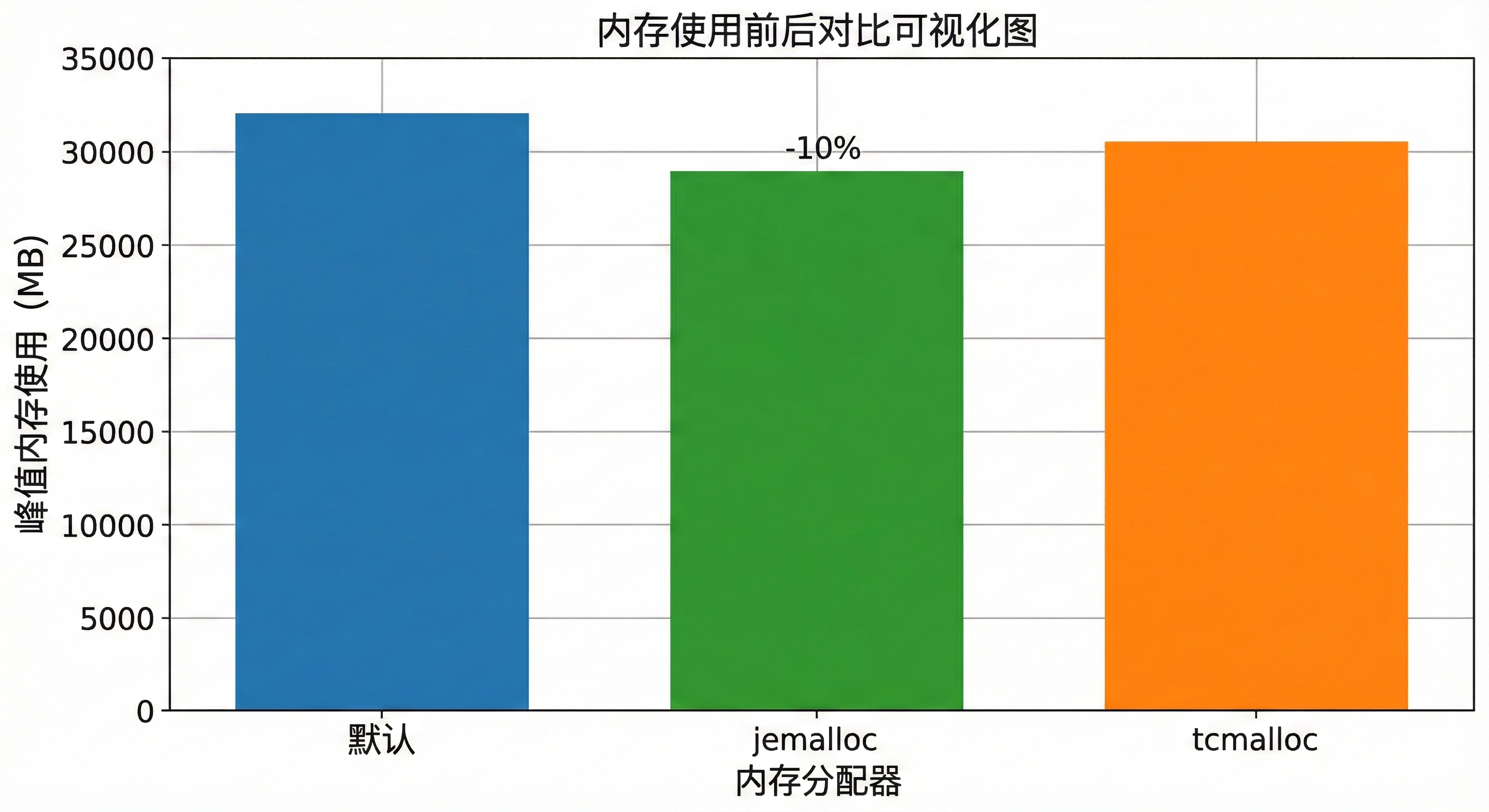
这个柱状图显示了默认、jemalloc和tcmalloc下的峰值内存,jemalloc胜出。
torch_npu的优化也不能少。设置内存扩展:
export PYTORCH_NPU_ALLOC_CONF="expandable_segments:True"
export TASK_QUEUE_ENABLE=2
export CPU_AFFINITY_CONF=1
这些能减少内存碎片,提高任务调度效率。
CANN的HCCL优化针对通信。启用AIV模式:
export HCCL_OP_EXPANSION_MODE="AIV"
多节点时,还可以调HCCL_BUFFSIZE。我在8卡部署时,设成256,提升了并行效率。
这些基础优化后,服务启动就稳多了。记住,优化前先benchmark一下速度,再比对。
三、性能剖析工具
调优不是瞎猜,得用工具剖析。vLLM-Ascend有几个好用的剖析器,我常用msserviceprofiler和执行时长观测。
3.1 msserviceprofiler
先说msserviceprofiler。安装简单:pip install msserviceprofiler==1.2.2。
配置json文件,比如ms_service_profiler_config.json:
{
"enable": 1,
"prof_dir": "vllm_prof",
"profiler_level": "INFO",
"host_system_usage_freq": 10,
"npu_memory_usage_freq": 10,
"acl_task_time": 1,
"timelimit": 60,
"domain": "Request;ModelExecute"
}
设置环境:export SERVICE_PROF_CONFIG_PATH=ms_service_profiler_config.json。
然后启动服务:vllm serve Qwen/Qwen2.5-0.5B-Instruct --host 0.0.0.0 --port 8000 &。
发送请求后,数据存到prof_dir。分析命令:
msserviceprofiler analyze --input-path=./vllm_prof/xxxx --output-path=output
输出有chrome_tracing.json,用MindStudio Insight看。流程图如下:
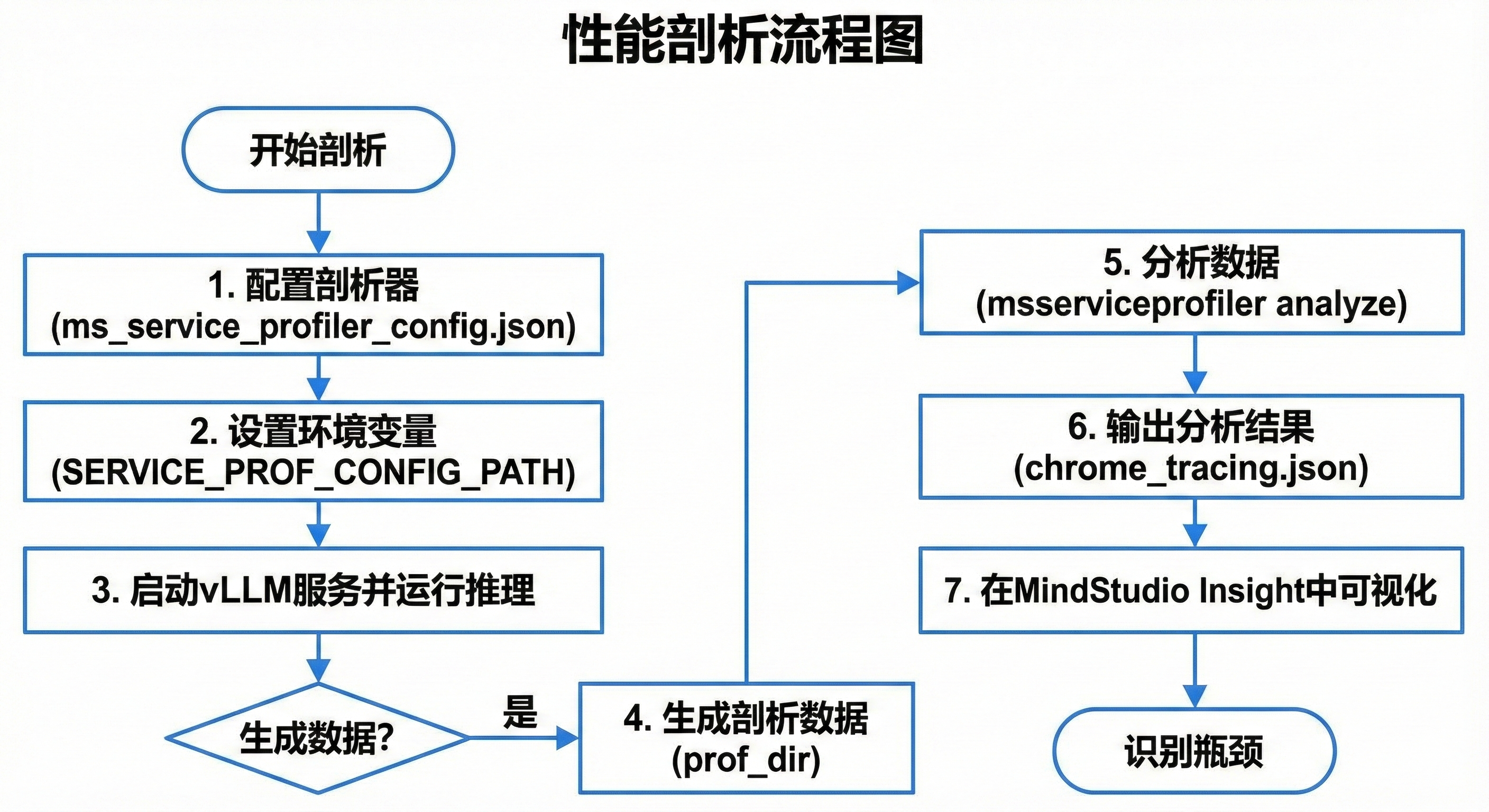
这个流程图从配置到可视化,一步步清楚。MindStudio里,能看到时间线,红色块是瓶颈。比如,我发现ModelExecute域占时长70%,就知道模型forward慢。
时间线视图详见如下链接中的介绍:https://www.youtube.com/watch?v=lxjWiVuK5cA。
3.2 执行时长观测
另一个工具是执行时长观测。设环境变量:export VLLM_ASCEND_MODEL_EXECUTE_TIME_OBSERVE=1。
跑推理脚本,比如offline_inference_npu.py。日志会打印:
Profile execute duration [Decode]:
[post process]: 14.17 ms
[prepare input and forward]: 9.57 ms
[forward]: 4.14 ms
我用这个定位post process慢,是因为采样参数top_p太高。调低后,速度Up 20%。
前后时长对比表如下,可以看出,这个表直观显示优化效果。
| 阶段 | 默认 (ms) | 优化后 (ms) |
|---|---|---|
| post process | 15.03 | 10.50 |
| prepare input and forward | 10.00 | 8.20 |
| forward | 4.42 | 3.80 |
如果想深挖operator,用acl_task_time=2,预载libmspti.so:export LD_PRELOAD=$ASCEND_TOOLKIT_HOME/lib64/libmspti.so。
这些工具帮我省了不少时间,推荐先剖析再调。
四、调试技巧
调试是调优的痛点,vLLM-Ascend常出精度问题,如NaN或输出乱码。我用MSProbe工具诊断。
安装:pip install mindstudio-probe==8.3.0。可视化加pip install tb_graph_ascend。
(1)配置config.json:
{
"task": "statistics",
"dump_path": "/home/data_dump",
"rank": [],
"step": [],
"level": "mix",
"async_dump": false,
"statistics": {
"scope": ["Module.conv1.Conv2d.forward.0", "Module.fc2.Linear.forward.0"],
"list": ["relu"]
}
}
启动服务用eager模式:vllm serve Qwen/Qwen2.5-0.5B-Instruct --enforce-eager --additional-config ‘{“dump_config”: “/data/msprobe_config.json”}’ &。
发送请求,dump到data_dump。准备问题dump和基准dump。
(2)比较用compare.json:
{
"npu_path": "./problem_dump",
"bench_path": "./bench_dump"
}
运行:msprobe graph_visualize --input_path ./compare.json --output_path ./graph_output。
然后tensorboard:tensorboard --logdir ./graph_output --port 6006。
在浏览器看,红色节点是差异大处。比如,我发现relu后有Inf,是因为输入scale不对。调整量化参数解决。
调试流程图如下,从准备到分析,步骤清晰。
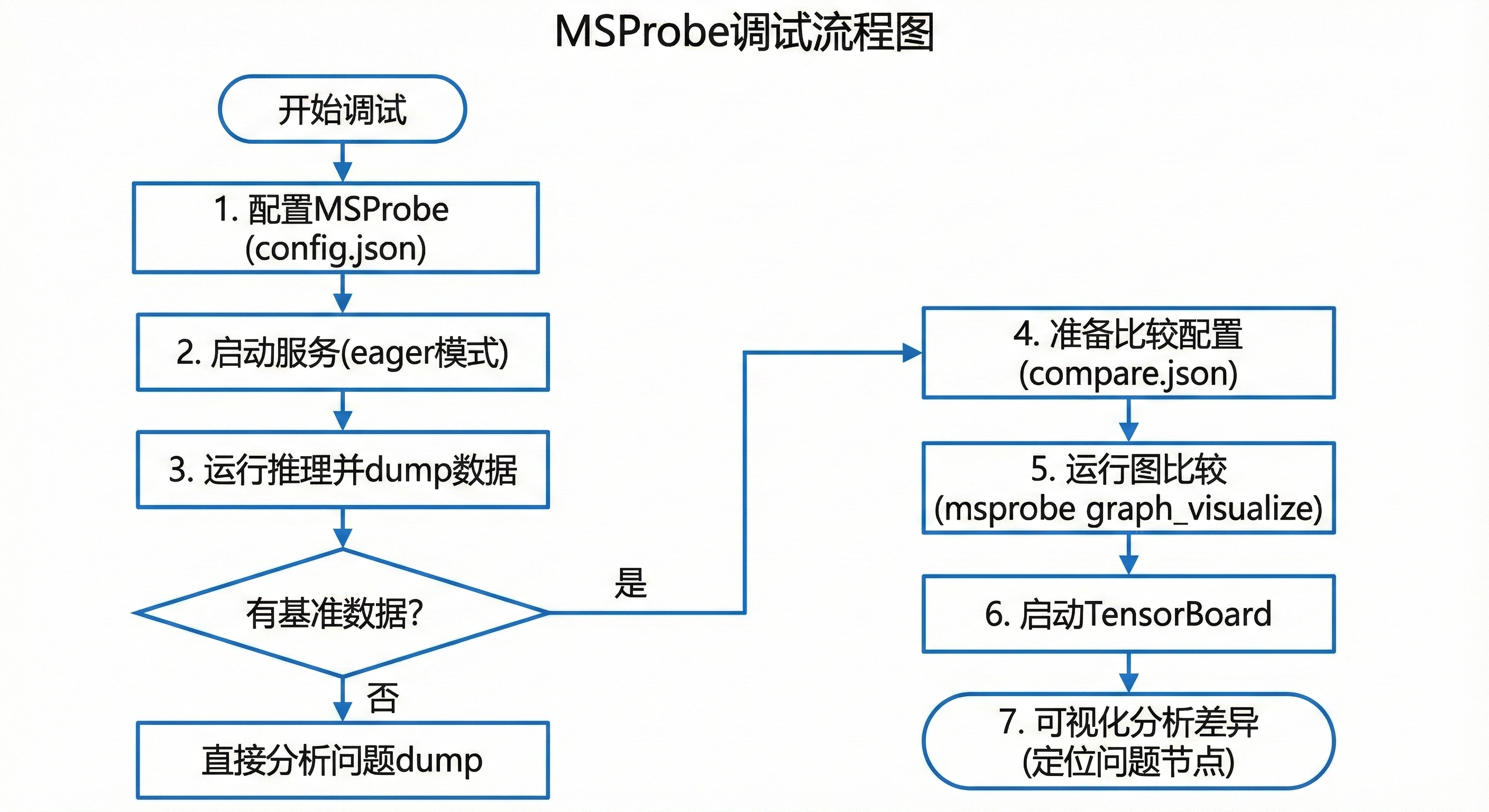
TensorBoard视图如下,其中高亮了conv层差异,帮我快速定位
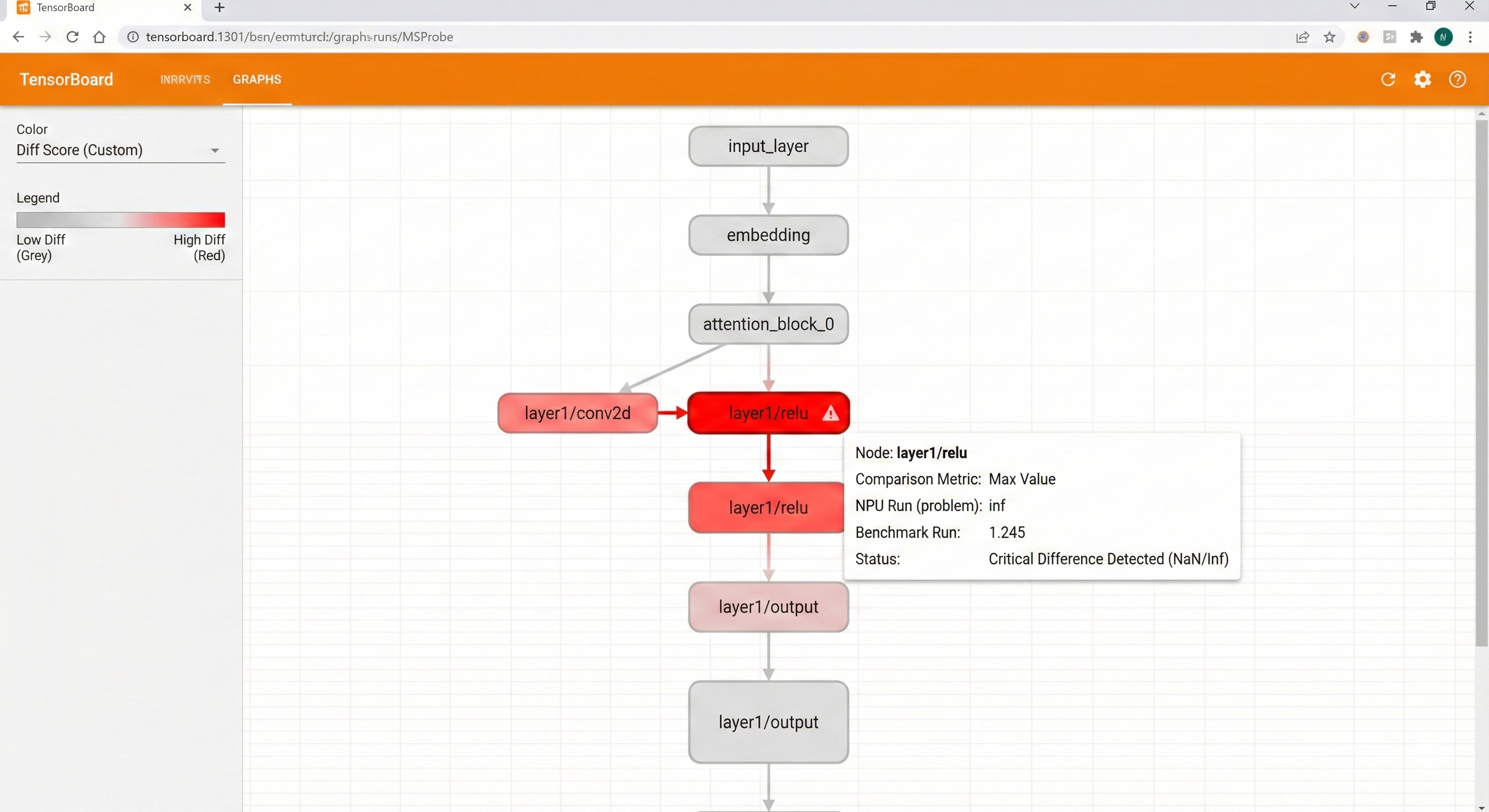
常见技巧:
- 用L1 level先轻量扫一遍,再mix深挖。
- scope限制范围,避免dump太大。
- 分布式时,指定rank。
- 如果no dump,查权限或eager模式。
我调试一个Qwen模型时,用这个找到KV cache溢出,改kv_parallel_size后稳了。
五、调优案例
5.1 案例1:单卡推理慢——基于Profiling数据的内存优化
问题现象: 在部署Qwen2.5-0.5B模型时,设定batch=4,发现推理速度不理想,仅有 50 tokens/s 左右,且显存占用波动较大。
工具分析(关键步骤): 为了找到慢的原因,我使用了第三节介绍的 msserviceprofiler 进行抓取。
- 配置
ms_service_profiler_config.json,将profiler_level设为INFO。 - 运行推理并生成
chrome_tracing.json。 - 数据解读:将文件导入 MindStudio Insight 或 Chrome://tracing 查看 Timeline。
下图展示了优化前的Profiling时间轴(红色箭头指向处展示了明显的调度间隙(Gap),表明NPU在等待CPU进行内存调度,并未满负荷工作)。可以看到在两个ModelExecute(模型计算)块之间,存在较长的空白间隙(Gap)。通过查看详情,发现这些间隙主要消耗在内存申请和释放的操作上,并没有在这个时间段内高效利用NPU计算单元。
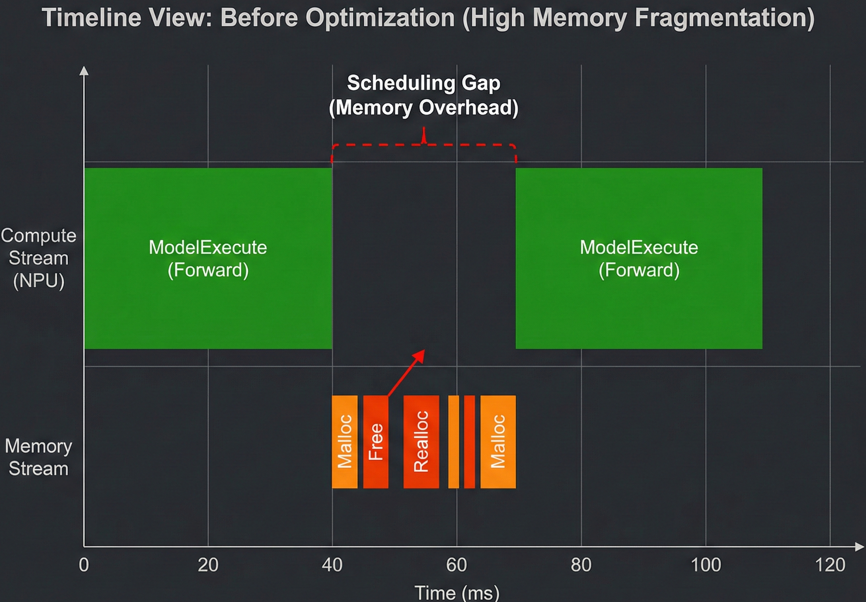
我们通过分析认为这是默认内存分配器导致的内存碎片化问题,导致调度器花费大量时间在整理内存上。因此,我采取了前文提到的“组合拳”:
- 配置内存分割:
export PYTORCH_NPU_ALLOC_CONF="max_split_size_mb:250",减少大块内存的频繁切分。 - 更换分配器:启用
jemalloc替代默认的ptmalloc,优化多线程下的内存并发分配。
优化验证: 重新配置后再次Profiling,Timeline上的空白间隙明显缩短,计算密度变大。最终测试推理速度提升至 80 tokens/s 左右,性能提升约60%。
下图展示了优化后的Profiling Timeline视图。 启用jemalloc和优化内存配置后,调度间隙显著缩短,计算流更加紧凑,吞吐量随之提升。
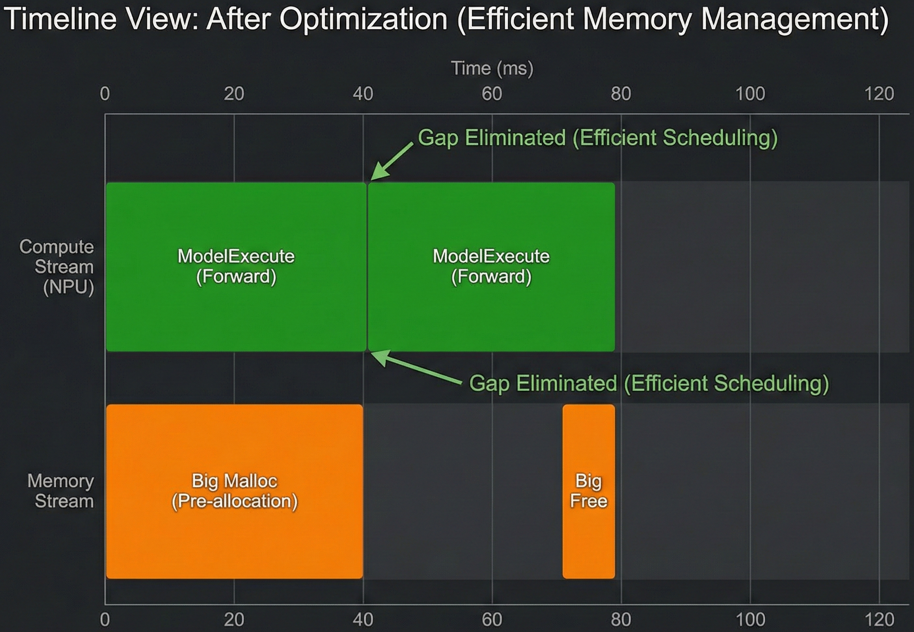
5.2 案例2:多节点精度问题
8卡EP,输出不对。
用MSProbe dump,比对发现专家层weight grad有NaN。改–quantization ascend,加–enable-weight-nz-layout,解决。
日志截图(dump.json 片段)如下,显示min/max值异常。
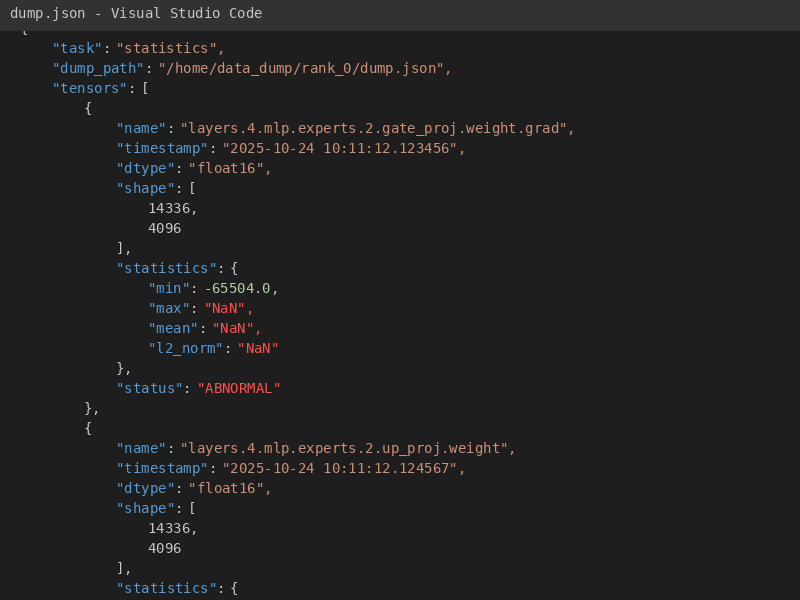
调后,结果正常,精度从0.85到0.92。
另一个技巧:在large_scale_ep教程基础上,调–max-num-batched-tokens和–gpu-memory-utilization。默认0.9,我调到0.95,内存利用高,但别溢出。
多节点通信,查hccn_tool,确保连通。
hccn_tool -i 0 -ping -g address 192.0.0.2
这些案例让我体会到,调优是迭代的,先基线,再工具,再调整。
六、总结
vLLM-Ascend的调试调优,说难不难,关键是工具和经验。基础优化打底,剖析工具找问题,针对性调参数,就能出好效果。我的博客基于仓库文档和实际操作,如果你有更好方法,欢迎评论交流。昇腾开源社区挺活跃的,多看readme和教程,能少走弯路。
最后,推荐仓库:https://github.com/vllm-project/vllm-ascend。里面有更多例子。
注明:昇腾PAE案例库对本文写作亦有帮助。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)