为 LLM/RAG 准备数据时,清洗流程与传统 ETL 清洗有何不同?
这一现象也让 “LLM/RAG 数据清洗” 与 “传统 ETL 清洗” 的差异浮出水面:在大模型时代,数据清洗不再是简单的 “修正错误”,而是要为模型构建 “可理解、高关联、语义完整” 的输入环境,而文档解析作为数据清洗的前置核心环节,其技术能力直接决定了两种清洗模式的效果差异。传统 ETL 清洗:仅能处理 “字段定义明确” 的结构化数据,如将 “用户表” 中的 “手机号” 字段统一为 11 位格
大模型竞速倒逼数据处理升级,清洗差异成能力分水岭
2025 年 12 月,谷歌在无预热情况下突然发布 Gemini 3 Flash 模型,不仅在多项基准测试中显著优于上一代旗舰 Gemini 2.5 Pro(如 SWE-bench 编码测试得分 78%,超过 Gemini 3 Pro),更以输入 0.5 美元 / 百万 Token、输出 3 美元 / 百万 Token 的极低价格,将大模型应用推向 “轻量化、低成本” 新阶段。这一动作背后,折射出当前 AI 行业的核心竞争逻辑:当模型架构与基础能力逐渐趋同,数据质量与处理效率成为决定模型落地效果的关键变量。
Gemini 3 Flash 的发布进一步验证了 “大模型性能天花板由输入数据质量决定” 的行业共识 —— 即便模型具备 “闪电速度” 与 “低成本优势”,若输入数据存在结构混乱、语义断裂、噪声冗余等问题,仍无法发挥其高效推理能力(如文档中提到,Gemini 3 Flash 在处理 “WebRTC 纯前端投屏” 等复杂任务时,因代码逻辑依赖的结构化数据不足,最终需 Gemini 3 Pro 修正)。这一现象也让 “LLM/RAG 数据清洗” 与 “传统 ETL 清洗” 的差异浮出水面:在大模型时代,数据清洗不再是简单的 “修正错误”,而是要为模型构建 “可理解、高关联、语义完整” 的输入环境,而文档解析作为数据清洗的前置核心环节,其技术能力直接决定了两种清洗模式的效果差异。
自 2025 年初起,国内大模型厂商同样加速迭代,但 “模型强、数据弱” 的矛盾普遍存在。调研机构 Epoch AI 预测,人类公开文本总量约 300 万亿个 Token,大语言模型将在 2026-2032 年间消耗殆尽。在数据总量有限的背景下,“如何通过差异化清洗流程挖掘数据价值” 成为行业焦点 —— 传统 ETL 清洗面向结构化数据的 “标准化处理” 已无法满足 LLM/RAG 对非结构化数据的 “语义化需求”,二者在目标、流程、工具选择上的差异,正成为企业 AI 应用落地成功与否的关键。

LLM/RAG 数据清洗与传统 ETL 清洗的核心定义
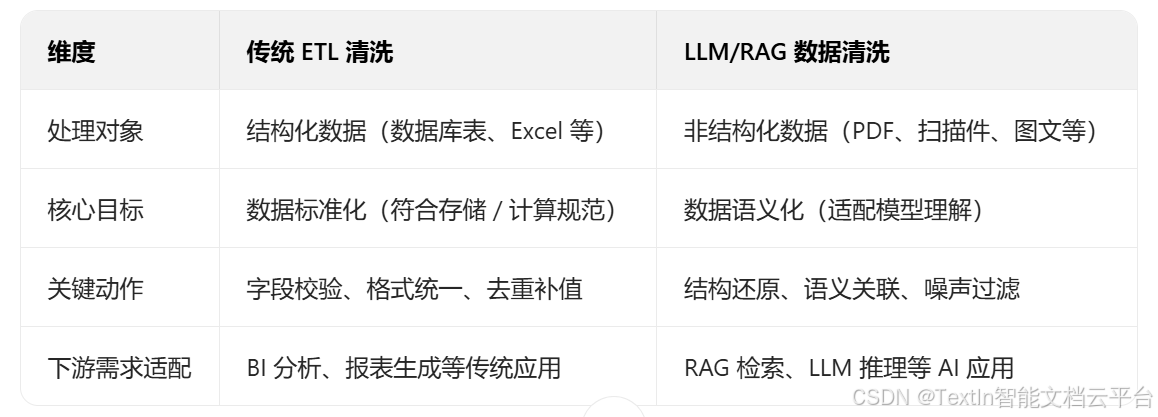
要理解二者的不同,首先需明确各自的核心定位与目标,其差异本质源于 “处理对象” 与 “下游需求” 的根本区别:
(一)传统 ETL 清洗
传统 ETL(Extract-Transform-Load)清洗聚焦于结构化数据(如数据库表、Excel 表格),核心目标是 “保证数据符合业务系统的存储与计算规范”,本质是 “数据标准化” 过程。其核心逻辑围绕 “字段级校验” 展开,例如:
● 修正格式错误(如日期统一为 “YYYY-MM-DD”、数值保留 2 位小数);
● 剔除重复记录(如基于 “用户 ID” 删除重复注册数据);
● 补全缺失值(如用 “平均值” 填充缺失的销售数据);
● 过滤异常值(如剔除 “年龄 = 200 岁” 的无效用户信息)。
最终目的是将分散的结构化数据整合为统一格式,满足 BI 分析、报表生成等传统数据应用需求,不涉及对数据 “语义关系” 的理解。
(二)LLM/RAG 数据清洗
LLM/RAG 数据清洗则面向非结构化数据(如 PDF 报告、扫描件、技术文档、多模态图文),核心目标是 “将数据转化为大模型可理解的语义化格式”,本质是 “数据语义化重建” 过程。其核心逻辑围绕 “内容级理解” 展开,需解决三大核心问题:
● 结构还原:将文档中的标题层级、段落顺序、表格结构、跨页内容等按人类阅读逻辑重组(如还原多栏论文的阅读顺序、合并跨页表格);
● 语义关联:捕捉元素间的内在联系(如图表与注释的对应关系、公式与上下文的推导逻辑);
● 噪声过滤:剔除对模型无用的冗余信息(如页眉页脚、水印、重复注释),同时保留关键语义(如参考文献、公式符号)。
最终目的是为 LLM/RAG 提供 “结构化、高关联、无噪声” 的语料,支撑精准检索(RAG)与逻辑推理(LLM),避免模型因数据理解偏差产生 “幻觉输出”。
点击链接 体验LLM/RAG 数据清洗![]() https://cc.co/16YSab
https://cc.co/16YSab
核心差异总结
从 TextIn xParse 实践看两种清洗的效果差异
合合信息是大模型时代下文本智能处理技术领先者,以旗下 TextIn xParse 文档解析工具在实际场景中的应用为例,其对 LLM/RAG 数据清洗的支撑作用,直观体现了与传统 ETL 清洗的差异:

(一)效率层面:非结构化数据处理速度的突破
传统 ETL 工具处理非结构化文档时,需先通过 OCR 将图像转文字(100 页 PDF 解析需 15 秒以上,复杂版式甚至达数分钟),再人工整理结构,清洗流程耗时且易出错。而 TextIn xParse 通过 “工程 + 算法” 双轮优化,实现 100 页 PDF 最快 1.5 秒解析(P90 解析时间控制在 2 秒内),单日可承载数百万级调用量,成功率达 99.99%。例如某金融机构处理 500 万页年报,传统 ETL 流程需 10 天以上,而 TextIn xParse 结合 LLM/RAG 清洗流程,3 天即可完成 “解析 - 结构化 - 语义关联” 全链路处理,效率提升 300%。
(二)精度层面:语义化处理对模型效果的影响
某科研团队搭建学术 RAG 知识库时,初期使用传统 OCR 工具解析论文(传统 ETL 清洗仅做文字提取),导致:
● 表格识别错误:合并单元格拆分、跨页表格断裂,RAG 检索时无法定位完整数据;
● 公式语义丢失:仅提取公式文字符号,未保留 LaTeX 格式,LLM 无法理解推导逻辑;
● 标题层级混乱:章节顺序颠倒,检索时关键知识点匹配准确率不足 60%。
改用 TextIn xParse 后,其支持 16 种元素高精度识别(文字识别率 99.7%、表格识别率超 99%),可还原标题层级、保留公式 LaTeX 格式、合并跨页表格,最终 RAG 检索准确率提升至 92%,LLM 生成文献综述的逻辑完整性提升 75%,充分验证了 LLM/RAG 清洗 “语义化” 的核心价值。
(三)业务适配层面:复杂场景的针对性优化
传统 ETL 清洗无法处理 “合并单元格、无线表格、弯折图片” 等复杂场景,而 TextIn xParse 针对 LLM/RAG 需求做了专项优化:
表格识别:精准处理跨行合并、嵌套表格、密集少线表格,某企业处理带注释的财务报表,表格解析准确率较传统 OCR 提升 40%;
图像处理:一键解决水印、图片弯曲问题,某医疗机构解析弯折的病历扫描件,文字识别准确率从 85% 提升至 99.2%;
多语言支持:覆盖 50 + 种语言(含简体 / 繁体中文、西欧 / 东欧语言),某跨国公司构建多语言知识库时,语义提取完整性较传统 ETL 工具提升 55%。
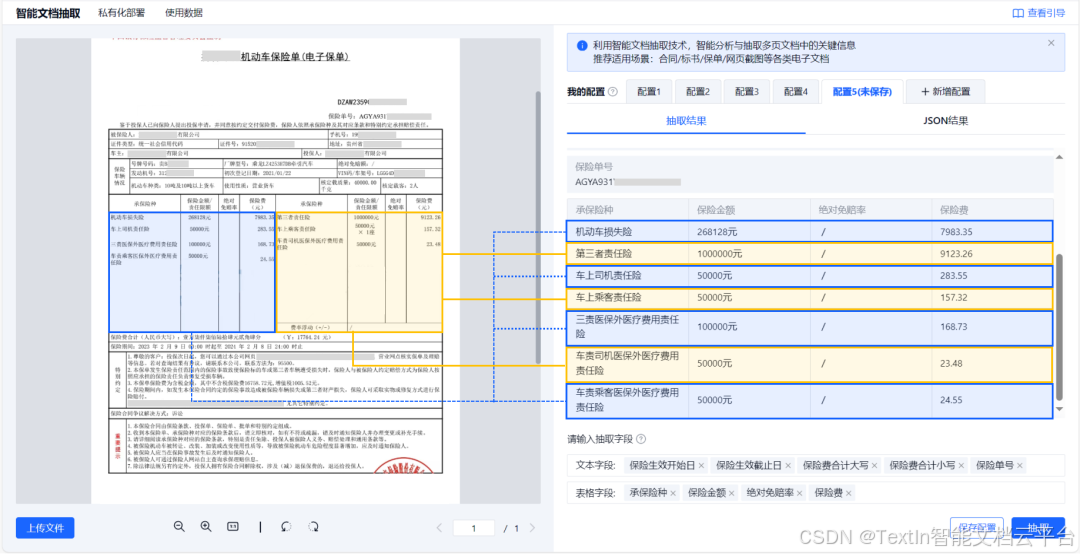
LLM/RAG 清洗与传统 ETL 清洗的核心差异
(一)数据结构处理能力 —— 从 “字段级” 到 “内容级”
传统 ETL 清洗:仅能处理 “字段定义明确” 的结构化数据,如将 “用户表” 中的 “手机号” 字段统一为 11 位格式,无法理解非结构化文档的 “内容结构”(如无法区分论文的 “摘要” 与 “结论” 章节)。
LLM/RAG 数据清洗:需具备 “内容级结构还原” 能力。例如 TextIn xParse 通过自研文档树引擎,可基于语义提取段落 embedding 值,预测标题层级关系(如 sec_0-sec_5 级标题),同时还原多栏版式、跨页段落的阅读顺序。某学术平台使用其解析 10 万篇论文后,构建的文档树使 RAG 检索时 “章节定位” 效率提升 80%,避免传统 ETL 清洗导致的 “结构混乱” 问题。
(二)语义关联能力 —— 从 “无关联” 到 “强关联”
传统 ETL 清洗:不关注数据间的语义联系,仅按字段独立处理。例如处理 Excel 表格时,仅校验 “销售额” 字段的数值格式,不关心 “销售额” 与 “产品类别” 的对应关系。
LLM/RAG 数据清洗:需主动捕捉元素间的语义关联。TextIn xParse 可识别图表与注释的对应关系、公式与上下文的推导逻辑,例如某科技公司解析技术文档时,其将 “产品参数表” 与 “性能曲线图” 关联标注,使 LLM 在回答 “参数与性能关系” 时,准确率提升 65%,避免传统 ETL 清洗导致的 “语义断裂” 问题。
(三)工具适配能力 —— 从 “单一工具” 到 “多模态工具”
传统 ETL 清洗:依赖 SQL、Python(Pandas)等工具,仅能处理结构化数据,面对非结构化文档需额外集成 OCR 工具(如 Tesseract),但无法解决结构还原与语义关联问题。
LLM/RAG 数据清洗:需适配多模态解析工具。TextIn xParse 支持 PDF、Word、图片(jpg/png/webp)等近 20 种格式,输出 Markdown/JSON 等模型友好格式,同时提供 API 接口(支持 Java、Python、Go 等语言,3 行代码即可接入),可无缝集成到 LLM/RAG 流程中。例如某企业搭建 RAG 系统时,通过 TextIn xParse 将文档解析为 Markdown 后,直接导入向量数据库,清洗流程无需人工干预,较传统 ETL 工具的 “OCR + 人工整理” 模式,人力成本降低 70%。
LLM/RAG 清洗为 AI 时代数据处理带来的新突破
在 Gemini 3 Flash 等轻量化模型推动 AI 应用普及的背景下,LLM/RAG 数据清洗的独特价值,不仅在于与传统 ETL 清洗的差异,更在于其为大模型落地提供了 “不可替代的语义化能力”:
(一)降低非结构化数据的 AI 应用门槛
传统 ETL 清洗无法将非结构化数据转化为模型可理解的格式,导致大量企业因 “数据处理难” 无法落地 AI 应用。而 LLM/RAG 清洗通过 TextIn xParse 等工具,可自动化完成 “解析 - 结构化 - 语义关联”,例如开发者仅需 3 行代码接入 API,10 分钟完成部署,即可将 PDF、扫描件等转化为 Markdown/JSON 格式,直接导入 RAG 向量数据库或 LLM 训练流程,使中小企业也能低成本享受 AI 红利。
(二)支撑多场景 AI 应用的差异化需求
传统 ETL 清洗的 “标准化” 特性无法适配不同 AI 场景的需求,而 LLM/RAG 清洗具备 “场景化定制” 能力。例如:
金融场景:TextIn xParse 可完整还原年报的多级标题、跨页表格、ESG 指标关联,支撑 AI 合规审查;
学术场景:其精准提取论文的公式(LaTeX 格式)、实验数据、参考文献,助力智能文献综述生成;
医疗场景:其解析电子病历的时间线逻辑、药品剂量标注,为临床决策 AI 提供结构化数据。
未来,随着 Gemini 3 Flash 等模型推动 AI 进入 “轻量化、普惠化” 阶段,LLM/RAG 数据清洗与传统 ETL 清洗的差异将进一步凸显。而 TextIn xParse 等工具的持续优化,也将不断降低非结构化数据处理门槛,为大模型落地构建 “高质量数据底座”—— 毕竟,只有让模型 “读懂” 数据,才能真正释放 AI 的价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)