一文详解具身智能:从大模型到世界模型
本文全面探讨具身智能(Embodied AI) 的基础与前沿进展,核心聚焦大语言模型/ 多模态大模型与世界模型(WMs) 对具身智能的赋能作用 ——LLMs/MLLMs 通过语义推理和任务分解强化具身认知,WMs 通过构建外部世界的内部表征和未来预测支撑物理合规交互,二者融合形成的MLLM-WM 联合架构成为突破复杂物理世界任务的关键方向。
本文全面探讨具身智能(Embodied AI) 的基础与前沿进展,核心聚焦大语言模型/ 多模态大模型与世界模型(WMs) 对具身智能的赋能作用 ——LLMs/MLLMs 通过语义推理和任务分解强化具身认知,WMs 通过构建外部世界的内部表征和未来预测支撑物理合规交互,二者融合形成的MLLM-WM 联合架构成为突破复杂物理世界任务的关键方向。
具身智能(Embodied AI)作为迈向通用人工智能(AGI)的核心范式,正推动智能系统从数字空间走向物理世界的深度交互。
近年来,大语言模型(LLMs)的语义推理能力与世界模型(WMs)的物理建模能力,为具身AI带来了突破性进展——前者赋予智能体理解复杂指令、分解任务的高阶认知能力,后者则为其提供贴合物理规律的环境表征与未来预测能力。
本文将系统梳理具身AI的发展脉络、核心技术与组件,深入解析LLMs/多模态(MLLMs)和WMs的赋能机制,提出二者融合的联合架构,并探讨其在服务机器人、救援无人机等领域的应用及未来研究方向,为读者呈现这一前沿领域的全景图景。
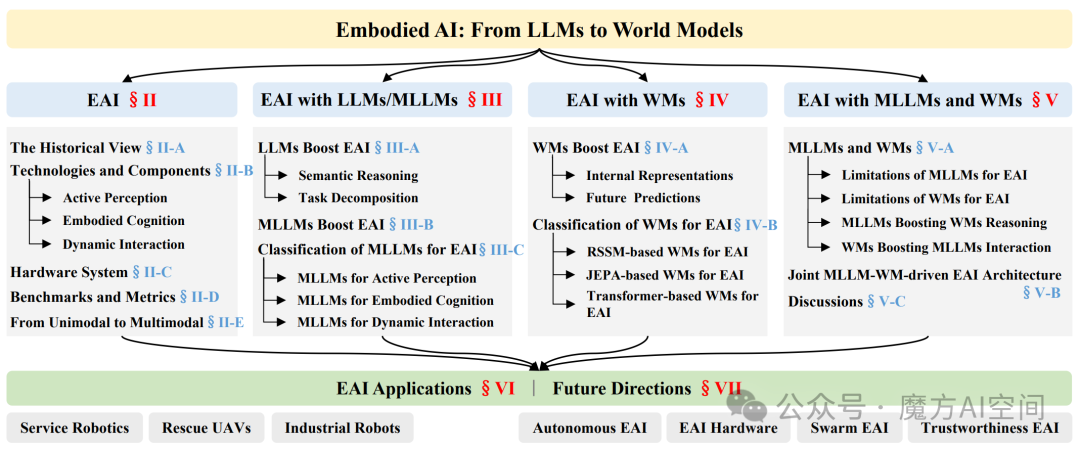 图1:具身智能基础知识概览
图1:具身智能基础知识概览
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
一、具身AI基础
Embodied AI—— 就是能像人一样,通过 “身体”(硬件载体)与物理世界互动,而非仅在数字空间处理抽象问题。其智能源于感知、认知、互动的动态结合,形成 “主动感知 -具身认知- 动态互动” 的闭环,同时依赖硬件载体支撑计算与能耗需求。如图2所示。
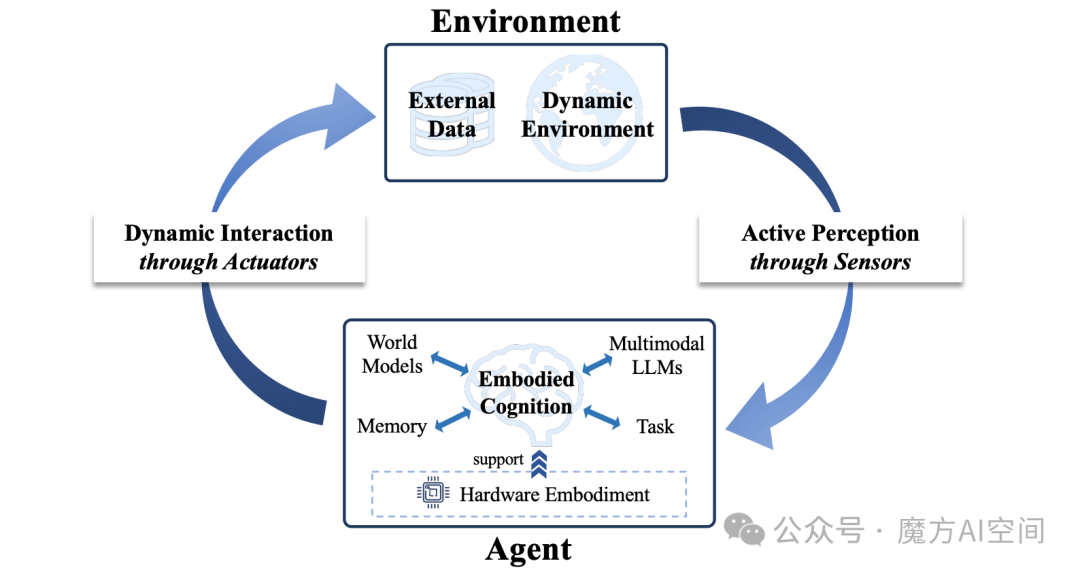 图2:具身人工智能的概念
图2:具身人工智能的概念
发展范式演进
历史脉络:
- 1950 年:图灵提出 “具身图灵测试”,奠定理论基础。
- 1980-1990 年代:认知科学明确 “智能源于身体体验”,机器人技术实现落地(如布鲁克斯的包容架构、Cog 人形机器人项目)。
- 近年:深度学习推动从 “运动控制” 向 “自适应互动” 转变,**大语言模型(LLMs)和世界模型(WMs)**成为关键突破点。
关键技术
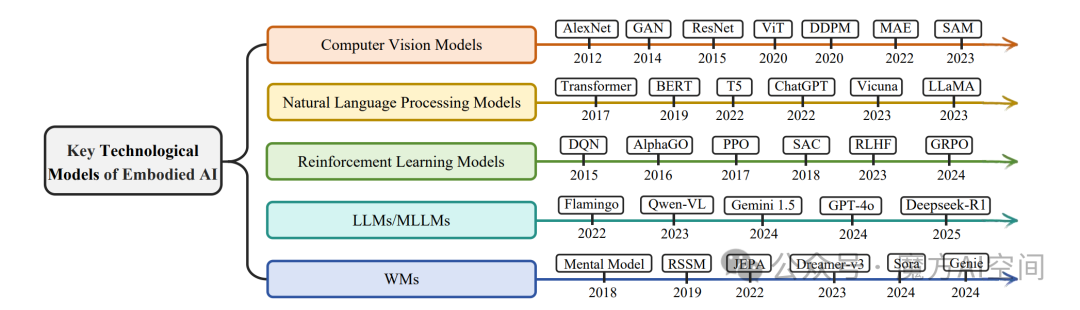 图3:具身智能的关键技术模型。计算机视觉(CV)模型、自然语言处理(NLP)模型、强化学习(RL)模型、大模型/多模态大模型(LLMs/MLLMs)以及世界模型(WMs)的进步推动了具身人工智能的发展
图3:具身智能的关键技术模型。计算机视觉(CV)模型、自然语言处理(NLP)模型、强化学习(RL)模型、大模型/多模态大模型(LLMs/MLLMs)以及世界模型(WMs)的进步推动了具身人工智能的发展
具身智能的快速发展与基础技术模型的进步密切相关,例如CV、NLP、RL、LLMs/MLLMs以及WMs(如图 3所示),这些模型能够显著提升智能体在感知、认知和交互方面的能力。
计算机视觉中的经典模型,如 AlexNet、GAN、ResNet、ViT、DDPM、MAE 和 SAM,为具身智能体在复杂环境中解析高维感官输入提供了感知基础。
在自然语言处理领域,从 Transformer、BERT 和 T5 等基础架构到 ChatGPT、Vicuna 和 LLaMA 等大规模系统的发展,使具身智能体在语言理解、任务规划和指令遵循方面具备了更强的能力。
强化学习为智能体通过与环境交互进行学习提供了核心算法框架,包括 DQN、AlphaGo、PPO、SAC、RLHF 和 GRPO等。
具身智能中最具前景的方向之一是将大模型(LLMs)/多模态大模型(MLLMs)与世界模型(WMs)相结合。LLMs 和 MLLMs(如Flamingo、Qwen-VL、Gemini-1.5、GPT-
4o 和 DeepSeek-R1)为智能体提供了理解指令、对多模态输入进行推理以及在不同任务和环境之间实现泛化的能力。
世界模型WMs(如 Mental Model、RSSM、JEPA、Dreamer-v3、Sora 和 Genie)使智能体能够建模和预测环境动态,支持基于想象的规划以及在动态且不确定环境中的前瞻性决策。
核心组件
三大闭环组件:主动感知(传感器驱动的环境观测)、具身认知(基于历史经验的认知更新)、动态交互(执行器介导的动作控制)。
主动感知:分为视觉 SLAM(定位与建图,如 ORB-SLAM、GS-SLAM)、3D 场景理解(结构化语义解析,如 OpenScene、Lexicon3D)、主动环境探索(自主获取信息,如 Active Neural SLAM、ActiveRIR),核心是 “选择性获取环境信息”。
具身认知:包括任务驱动自规划(自主生成任务计划,如 LLM-Planner、EvoAgent)、记忆驱动自反思(利用历史经验优化决策,如 Reflexion、REMAC)、具身多模态基础模型(统一规划与推理能力,如 EmbodiedGPT、ManipLLM),是具身 AI 的 “核心决策中枢”。
动态交互:涵盖动作控制(生成电机指令,如 PaLM-E、RT-2)、行为交互(基于动作序列的高阶控制,如 GAIL、Behavior-1K)、协同决策(多智能体 / 人机协作,如 QMIX、MetaGPT),核心是 “基于感知与认知影响环境”。
硬件优化
硬件载体:需满足实时部署场景下的计算、能耗、延迟约束,是具身 AI 落地的关键支撑。
四大优化方向:模型压缩(量化、剪枝,适配低功耗硬件)、编译器优化(如 TVM,优化计算图与内存访问)、专用加速器(TPU、FPGA、ASIC,适配具身任务计算特性)、软硬件协同设计(联合优化模型结构与硬件架构,提升实时性与能效)。
基准测试与指标
主流基准测试:Habitat(3D 室内导航)、ManiSkill(物理操纵)、MuJoCo(连续状态控制)、EmbodiedBench(多模态综合评估)、BEHAVIOR-1K(1000 项日常任务)。
核心指标:任务成功率、实时响应性、能效(FLOPS / 功耗)、路径长度、泛化性得分、安全违规率,多智能体场景新增协同效率与通信开销。
从单模态到多模态
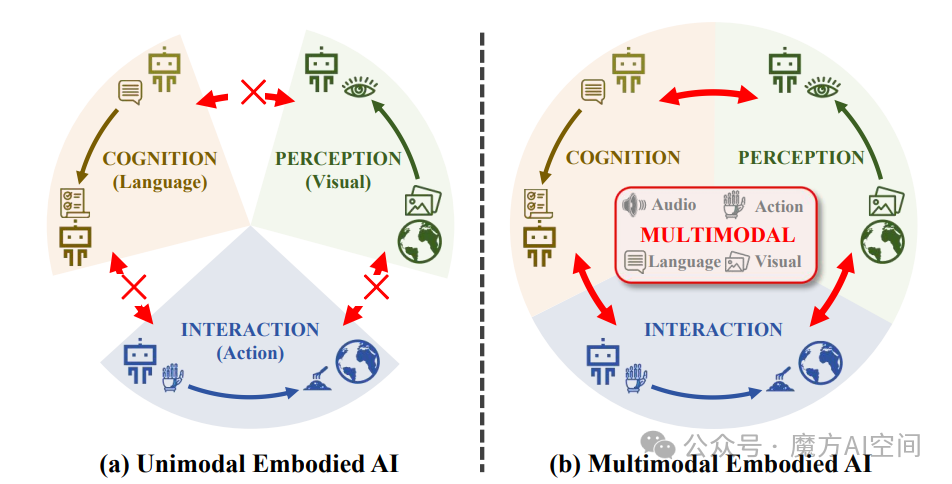 图4:单模态具身智能与多模态具身智能
图4:单模态具身智能与多模态具身智能
早期聚焦视觉、语言、动作等单一模态组件(如视觉主导感知、语言主导认知),受限于信息范围窄、模态间割裂;多模态范式通过融合多感官输入,实现更自适应、鲁棒的复杂任务处理。
单模态具身智能得益于计算机视觉、自然语言处理和强化学习等基础领域的快速发展。这些单模态方法在处理具身智能中的特定模块方面表现出色。
相比之下,多模态具身智能已成为一个更具前景的范式。通过整合来自多种感知模态的数据,例如视觉、听觉和嗅觉反馈,这些方法能够对环境提供更加全面和精确的理解。更重要的是,多模态具身智能能够促进感知、认知与交互之间的深度融合。
近年来,**多模态大模型(MLLMs)和世界模型(WMs)**的发展使智能体能够更有效地处理多种模态,有望提升具身智能的能力。
这些模型的融合被认为是实现动态、不确定环境中多模态具身智能的关键一步。
二、LLMs/MLLMs 赋能具身 AI
大模型赋能具身智能
LLMs 通过语义推理(semantic reasoning) 与任务分解(task decomposition) 两大核心能力赋能具身 AI,核心价值是将高层自然语言指令与低层自然语言动作融入具身认知过程,为机器人等具身智能体执行长时程、自然语言驱动的任务提供关键支撑。
语义推理:LLMs 依托 Transformer 架构,将输入文本令牌映射为 latent 表征,实现句法、语用层面的层级语义抽象。通过注意力机制筛选关键语义线索、抑制噪声,结合预训练语料中的世界知识与任务特定提示,动态构建概念图谱,支持多跳逻辑推理与类比推理,可解析文本指令中的语言模式、上下文关系及隐含知识,解决指令歧义问题。
任务分解:利用 LLM 的时序逻辑能力,通过思维链(chain-of-thought)提示,将复杂目标层级拆解为可执行子任务,优先处理子任务间的依赖关系,同时通过语义一致性校验消解歧义,形成结构化动作序列。
LLMs 仅覆盖具身 AI 的具身认知环节,存在显著约束:依赖固定的自然语言动作库,难以适配新类型机器人;受限于特定物理环境,无法实现跨场景自适应扩展。
多模态大模型赋能具身智能
多模态大语言模型(MLLMs)突破了传统大语言模型(LLMs)仅聚焦具身认知的局限,通过贯通高维多模态输入与低阶电机动作序列,实现对具身 AI 全系统(主动感知、具身认知、动态交互)的端到端赋能,核心解决了 LLMs 依赖固定动作库、跨场景适配能力弱的关键问题。
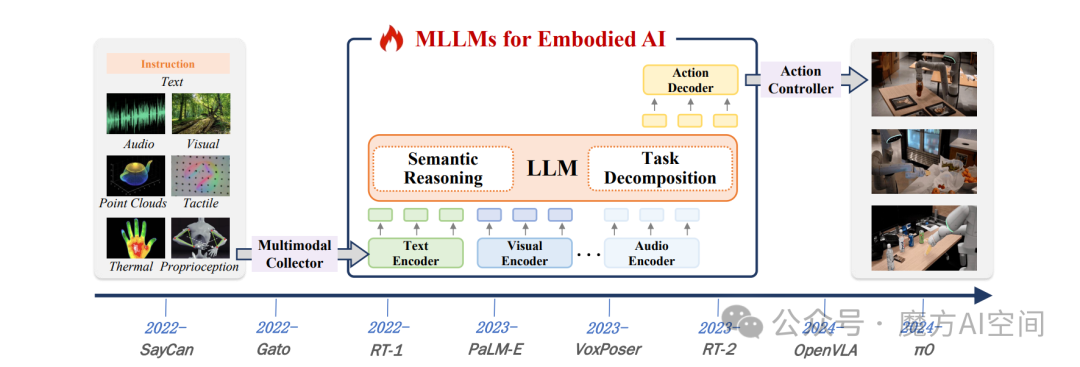 图5:多模态大模型赋能具身智能的发展路线图
图5:多模态大模型赋能具身智能的发展路线图
相较于 LLMs,MLLMs 的赋能逻辑在两大核心能力上实现扩展:
- 语义推理跨模态化:不再局限于文本语义解读,而是通过跨模态理解能力,从视觉、听觉、触觉等多源感官输入中提取语义信息,例如识别物理世界中的物体属性、推断空间关系、预判环境动态变化。
- 任务分解动态化:在利用时序逻辑拆解复杂目标的基础上,新增传感器反馈自适应机制,可根据环境实时变化动态调整子任务规划,实现 “感知 - 决策 - 行动” 的闭环优化。
MLLMs 主要通过两类模型架构支撑具身 AI 应用,覆盖从固定场景到开放场景的需求:
视觉语言模型(VLM):聚焦视觉与语言的跨模态融合,适配固定动作空间的任务场景。
- 核心流程:先对视觉与语言特征进行端到端联合训练,融入连续传感器模态编码建立 “语言 - 感知” 关联,最终通过固定动作空间映射完成任务。
- 代表工作:PaLM-E 通过融合视觉、语言及传感器数据,实现多任务端到端完成;ShapeNet 通过优化 3D 空间推理的对比嵌入,显著降低导航路径规划误差。
视觉语言动作模型(VLA):通过可微分流水线实现多模态输入与低阶动作控制的深度耦合,核心优势是跨机器人、跨场景的自适应扩展。
- 核心流程:先将机器人实时图像、语言指令、动作数据编码为文本令牌,经 LLM 完成语义推理与任务分解后,再解码为最终执行动作。
- 代表工作:RT-2 实现网页知识到机器人控制的迁移;Octo 基于 10 万条带语言标注的机器人演示数据预训练,达成跨载体工具使用能力;PerAct 借助 3D 体素表征,将精密抓取精度提升至毫米级。
面向具身 AI 的 MLLMs 分类应用
赋能主动感知:增强 3D SLAM(语义标注优化目标检测)、3D 场景理解(2D 视觉到语义特征映射)、主动探索(结合碰撞反馈优化动作序列)。
赋能具身认知:提升任务自规划(生成子目标图像辅助推理)、记忆自反思(语言反馈存储与复用)、多模态基础模型适配(如 Qwen-VL、InternVL 的物理世界适配)。
赋能动态交互:优化动作控制(生成可执行代码或连续控制信号)、行为交互(生成平滑行为轨迹)、协同决策(多智能体任务分配与人类指令对齐)。
三、世界模型赋能具身 AI
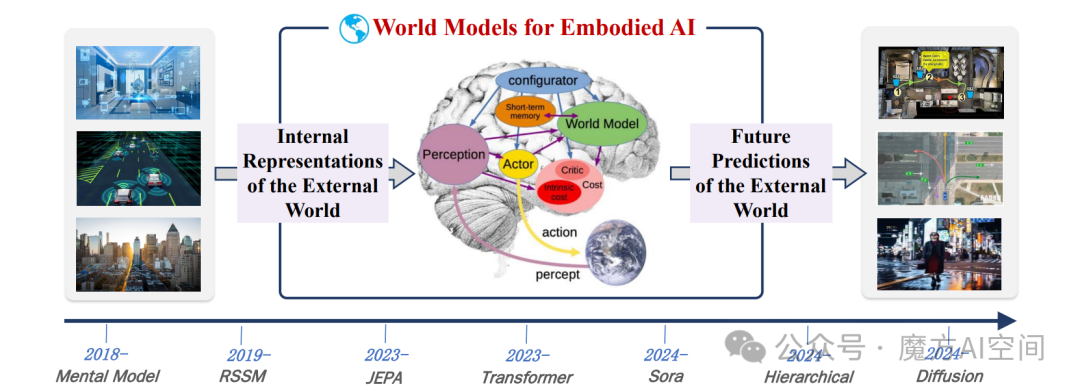 图6:身智能中世界模型(WMs)的发展路线图
图6:身智能中世界模型(WMs)的发展路线图
世界模型作为具身 AI 的关键赋能技术,核心通过构建外部世界的内部表征与实现未来预测两大能力,为具身智能体提供物理规律合规的交互支撑,解决纯语义模型(如 LLMs/MLLMs)缺乏物理接地的核心痛点,是具身 AI 适配动态物理环境的核心技术支柱。
世界模型对具身 AI 的赋能机制
WMs 通过双重核心能力,实现物理世界与具身智能体的高效耦合:
- 外部世界的内部表征(Internal Representations):将高维、复杂的多模态感官输入(视觉、触觉等)压缩为结构化潜空间,精准捕捉物体动态、物理定律(如重力、摩擦)与空间结构。该表征具备层级化与解纠缠特性,既保留实体与环境的关联关系,又分离物体固有属性与外部关系,支持反事实推理(如 “若推动物体将如何移动”)与因果理解,同时能主动识别自身对环境状态的不确定性,引导智能体补充关键信息。
- 外部世界的未来预测(Future Predictions):基于物理定律,跨多个时间尺度模拟动作序列的潜在结果,提前规避物理上不可行(如穿墙)或低效的行为。预测过程融入不确定性量化,区分环境中的规律事件与随机变化,通过 “心理演练” 替代部分真实试错,提升样本效率,尤其适用于自动驾驶、机器人手术等安全关键场景;同时通过持续最小化预测误差,实现模型自校正,让内部物理模拟器与真实世界动态对齐。
具身 AI 中世界模型的分类
根据核心架构差异,WMs 主要分为三类,另有分层式、扩散式等衍生类型,适配不同具身场景需求:
- RSSM-based WMs:即循环状态空间模型,是 Dreamer 算法家族的核心架构。通过视觉输入学习环境时序动态,将隐藏状态分解为概率组件与确定性组件,明确建模系统规律与环境不确定性,在机器人运动控制中表现突出,为后续相关研究提供基础框架。
- JEPA-based WMs:即联合嵌入预测架构,区别于传统生成模型的像素级重建,专注于抽象潜空间的语义特征提取。基于自监督训练范式,通过学习推断遮挡或未观测的数据片段,实现视觉与非视觉领域的高效迁移学习,泛化能力较强。
- Transformer-based WMs:依托注意力机制实现输入序列的并行化上下文加权,突破循环神经网络(RNNs)的时序处理限制,在记忆密集型交互场景中性能优于 RSSM。典型代表如 Google 的 Genie 框架,通过时空 Transformer(ST-Transformer)进行大规模自监督视频预训练,生成可交互的合成环境,为具身 AI 提供新的世界建模范式。
四、MLLM-WM 联合架构
多模态大模型与世界模型联合架构是具身 AI 突破复杂物理世界任务的关键方向,核心逻辑是通过二者 “语义推理 - 物理建模” 的优势互补,解决单一模型局限,实现更稳健的具身智能。
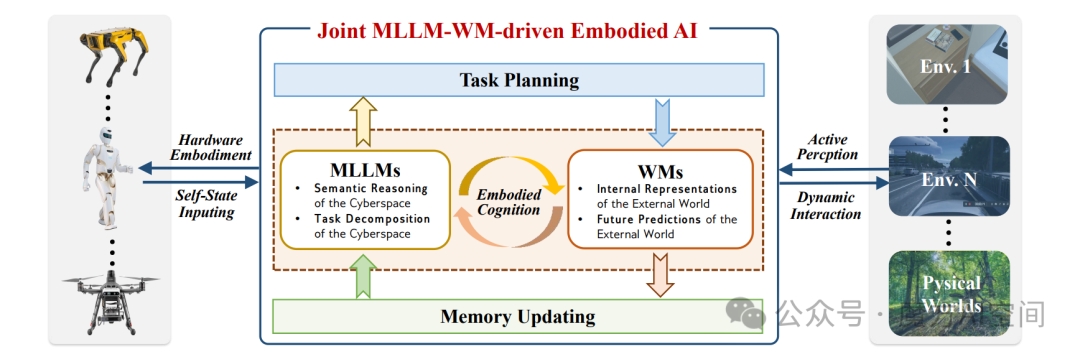 图7:具身智能中的多模态大模型与世界模型。多模态大模型可通过注入语义知识来增强世界模型,实现任务分解和长时程推理;而世界模型则可通过构建物理世界的内部表示和未来预测来辅助多模态大模型,使得多模态大模型与世界模型的协同架构成为具身系统的一个有前景的方向
图7:具身智能中的多模态大模型与世界模型。多模态大模型可通过注入语义知识来增强世界模型,实现任务分解和长时程推理;而世界模型则可通过构建物理世界的内部表示和未来预测来辅助多模态大模型,使得多模态大模型与世界模型的协同架构成为具身系统的一个有前景的方向
单一模型局限与互补性
MLLM 擅长上下文任务推理与多模态语义理解,但缺乏物理约束接地能力,易生成不符合现实规律的计划,且实时环境适应性弱;WM 则精通物理规律建模与未来预测,能保障交互合规性,却存在开放语义推理不足、任务分解泛化性差的问题。
二者形成天然互补,可打通语义智能与物理交互的壁垒。
相互赋能与架构设计
MLLM 为 WM 注入多模态语义与灵活任务分解能力,还可通过人类反馈优化其物理建模精度;WM 则为 MLLM 提供物理约束、稳定时空推理上下文,并通过闭环交互迭代修正其决策误差。
联合架构以 “闭环迭代” 为核心,整合机器人自状态输入、任务规划 - 记忆更新、环境感知 - 动态交互三大流程,实现从指令到动作的端到端优化,兼顾语义准确性与物理可行性。
优势与挑战
优势在于实现语义 - 物理对齐,提升长 horizon 任务适配性与跨场景泛化能力,典型如 EvoAgent 可自主完成多环境长周期任务;
挑战主要包括 MLLM 高延迟与 WM 实时性的同步冲突、语义 - 物理错位风险、内存管理压力,以及对大规模多模态数据集和抗干扰鲁棒性的高需求。
五、具身 AI 应用
具身 AI 在服务机器人、救援无人机、工业机器人等核心领域的落地实践,以 MLLM-WM 联合架构为关键支撑,突破传统系统局限,实现动态环境自适应与复杂任务自主执行,同时拓展至教育、虚拟环境、太空探索等场景,展现出广泛的现实实用性。

六 未来研究方向
自主具身 AI:自适应感知、环境意识、实时物理交互建模;
具身 AI 硬件:模型压缩优化、专用加速器、软硬件协同设计;
群体具身 AI:协同 WM、多智能体表征学习、人机交互接口;
可解释性与可信度:行为基准测试、伦理约束、安全认证;
其他:终身学习(持续技能获取)、人机协同学习、道德决策。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献132条内容
已为社区贡献132条内容

所有评论(0)