MindSpore开发之路:计算图与nn.Cell
本文介绍了MindSpore深度学习框架中的核心概念:计算图和nn.Cell模块。计算图作为AI模型的"蓝图",分为静态图(GRAPH_MODE)和动态图(PYNATIVE_MODE)两种执行模式,前者优化性能而后者便于调试。nn.Cell是构建网络的基础模块,通过继承并实现__init__和construct方法,可以像搭积木一样组合各种神经网络层。文章以线性网络y=W*x+
1. 计算图:AI模型的“蓝图”
在构建一个AI模型时,我们实际上是在定义一系列数学运算。计算图就是用来可视化和组织这些运算流程的“设计蓝图”。
简单来说,计算图是一个有向无环图(DAG),它由两种核心元素构成:
- 节点(Nodes): 代表数据(通常是
Tensor)或施加在数据上的运算(Operation,例如加、减、乘、除、卷积等)。 - 边(Edges): 代表数据从一个运算节点流向下一个运算节点的路径,清晰地展示了计算的依赖关系和执行顺序。
以一个基础的线性方程 y = W * x + b为例,其计算图可以直观地表示为:
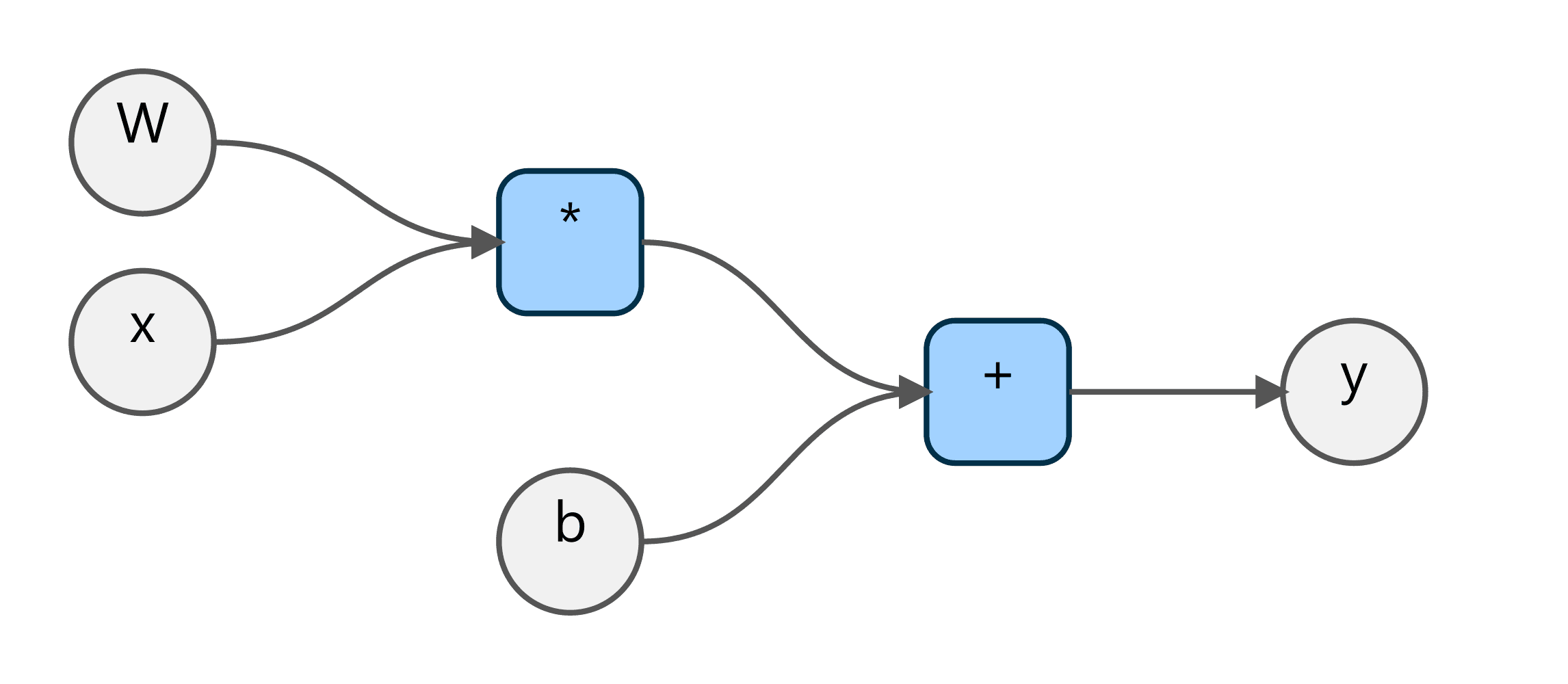
在这个图中:
x,W,b是输入的数据节点(Input Tensors)。*(乘法) 和+(加法) 是运算节点(Operations)。y是最终的输出节点(Output Tensor)。
数据 x和 W首先流入乘法节点,其结果再与 b一同流入加法节点,最终得到输出 y。这个流程清晰地定义了模型的前向传播过程。
1.1 静态图 vs. 动态图:两种不同的“执行策略”
MindSpore支持两种计算图模式,这在之前的文章中提到过,现在我们来深入理解它们:
-
静态图模式 (GRAPH_MODE):
- 策略: “先规划,后执行”。MindSpore会先将你的Python代码转换成一个完整、固定的计算图。然后,它会对这个图进行深度优化(比如合并一些运算、利用并行计算等),最后才一次性地执行整个优化后的图。
- 比喻: 像修建一条地铁线路。在动工前,工程师会绘制出完整的线路图、站点分布图,并进行全面优化。一旦开工,就按照这个固定蓝图高效建设,中途不能随意更改线路。
- 优点: 性能极致。因为提前知道了全部计算流程,所以可以做到最大程度的优化。
- 缺点: 调试相对困难。代码执行流和Python的写法不完全一致,报错信息可能不易定位到原始代码。
-
动态图模式 (PYNATIVE_MODE):
- 策略: “边解释,边执行”。MindSpore会逐行解释并执行你的Python代码,每执行一行运算,就动态地构建一小块计算图并立即计算。
- 比喻: 像开车使用实时导航。你每经过一个路口,导航会根据实时路况告诉你下一步怎么走。你可以随时根据路况(比如前方堵车)改变路线。
- 优点: 灵活、易于调试。完全符合Python的编程习惯,可以随时打印Tensor的值、使用
if/else或for循环等进行复杂的流程控制。 - 缺点: 性能通常低于静态图模式,因为无法进行全局优化。
如何选择?
- 初学和调试阶段: 强烈推荐使用 PYNATIVE_MODE。
- 模型训练和部署阶段: 为了追求极致性能,应切换到 GRAPH_MODE。
我们可以通过set_context轻松切换模式:
import mindspore
# mindspore.set_context(mode=mindspore.GRAPH_MODE) # 切换到静态图
mindspore.set_context(mode=mindspore.PYNATIVE_MODE) # 切换到动态图2. nn.Cell:构建网络的“乐高积木”
计算图描述了“做什么”,而nn.Cell则是“用什么来做”的答案。
在MindSpore中,nn.Cell是所有网络结构和神经网络层(如卷积层、全连接层)的基类。你可以把它想象成一块最基础的“乐高积木”。你可以用这些小积木(比如一个卷积层nn.Conv2d)拼成一个稍大的组件(比如一个残差块),然后用这些组件再拼成一个完整的模型(比如一个ResNet网络)。
一个自定义的nn.Cell通常包含两部分:
__init__(self)方法: 用于定义和初始化你将要用到的“子积木”(其他的Cell或ops算子)。construct(self, ...)方法: 用于定义数据(Tensor)是如何在这些“子积木”之间流动的,也就是在此处搭建计算图的“流程”。
3. 实战:用nn.Cell搭建一个简单的线性网络
让我们来构建一个前面提到的 y = W * x + b线性变换网络。在神经网络中,这通常被称为“全连接层”或“稠密层”。
import numpy as np
import mindspore
from mindspore import nn, ops, Tensor
# 确保在动态图模式下
mindspore.set_context(mode=mindspore.PYNATIVE_MODE)
# 1. 定义我们的网络,它继承自 nn.Cell
class MyLinearNet(nn.Cell):
def __init__(self):
# 调用父类的初始化方法,这是必须的
super().__init__()
# 在这里,我们定义需要的“积木”
# MindSpore提供了现成的全连接层 nn.Dense
# nn.Dense(in_channels=3, out_channels=4) 表示输入是3个特征,输出是4个特征
# 它会自动创建并管理权重W和偏置b
self.dense = nn.Dense(in_channels=3, out_channels=4)
def construct(self, x):
# 在这里,我们定义数据x如何“流过”积木
# 将输入x传入我们定义好的dense层
output = self.dense(x)
return output
# 2. 实例化我们的网络
net = MyLinearNet()
print("网络结构:\n", net)
# 3. 准备输入数据
# 创建一个形状为(2, 3)的Tensor,表示有2个样本,每个样本有3个特征
input_data = Tensor(np.random.rand(2, 3), mindspore.float32)
print("\n输入数据:\n", input_data)
# 4. 执行前向计算
# 直接调用实例化的net对象,并传入数据,MindSpore会自动调用construct方法
output_data = net(input_data)
print("\n输出数据:\n", output_data)
print("\n输出数据的形状:", output_data.shape) # 形状应为(2, 4)代码解读:
- 我们创建了一个
MyLinearNet类,它是一个nn.Cell。 - 在
__init__中,我们实例化了一个nn.Dense层。nn.Dense本身也是一个nn.Cell,这就是“积木”的嵌套。MindSpore会自动为nn.Dense层创建并初始化权重W和偏置b,这些参数会被自动追踪和管理。 - 在
construct中,我们定义了前向传播的逻辑:就是把输入x喂给self.dense层,然后返回结果。 - 最后,我们像调用一个普通Python函数一样调用
net(input_data),得到了计算结果。
4. 总结
本文我们学习了两个构建MindSpore模型的核心概念:
- 计算图: 描述运算流程的“蓝图”,分为高性能的静态图和易于调试的动态图两种模式。
nn.Cell: 构建网络的“积木”,通过继承它并实现__init__和construct方法,我们可以像搭乐高一样自由地组合、嵌套,构建出任意复杂的神经网络。
现在,你不仅拥有了“原材料”(Tensor),还掌握了搭建“工厂蓝图”(计算图)和制造“生产线”(nn.Cell)的方法。在接下来的文章中,我们将学习更多更强大的“积木”——MindSpore提供的各种神经网络层,并开始构建一个能解决实际问题的完整模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)