别再靠 print 调试 AI!打造 MCP 自动化评测与可视化调试框架
摘要:本文提出了一套MCP(ModelContextProtocol)自动化评测与调试框架,旨在解决AIAgent开发中的常见问题。框架从协议合规性、工具正确性和上下文一致性三个维度进行验证,通过构建Mock MCPServer实现隔离测试,提供细粒度评分机制,并开发可视化调试面板展示全链路交互。该方案可与CI/CD集成,实现质量左移和回归测试自动化,使MCP集成从手动调试转变为可度量的工程化交付
在开发 MCP(Model Context Protocol)集成的 AI Agent 时,你是否经历过这些困境?
- Agent 没调工具?调了但参数不对?结果没用上?
- 工具行为正确,但 LLM 决策逻辑有偏差?
- 每次修改 Agent 逻辑后,都要手动测试几十个用例?
这些问题的根源在于:缺乏系统化的评测与调试能力。
MCP 虽然定义了标准协议,但 Agent 是否“正确使用”MCP,工具是否“按预期响应”,上下文是否“一致传递”,都需要可量化、可自动化、可追溯的验证机制。
本文将带你从零设计一个 MCP 自动化评测与调试框架,覆盖协议合规性、工具正确性、上下文一致性三大维度,并集成 Mock Server、可视化面板与 CI/CD,让 AI Agent 开发进入工程化时代。
一、评测维度:如何定义“MCP 集成成功”?
评测不是简单看“有没有返回结果”,而是多维度验证:
1. 协议合规性(Protocol Conformance)
- MCP 请求是否包含
type: "tool_request"? arguments是否符合工具注册时的 JSON Schema?request_id和context_id是否格式正确、不为空?
目标:确保 Agent 生成的请求能被任何标准 MCP Server 接受。
2. 工具正确性(Tool Correctness)
- 工具是否返回了预期业务结果?(如查询用户应返回真实数据)
- 错误场景是否返回了结构化错误信息?(而非 panic)
- 工具是否在合理时间内完成?(避免超时)
注意:此处不关心 LLM 是否“理解”结果,只验证工具本身行为。
3. 上下文一致性(Context Consistency)
- 同一会话中,
context_id是否保持不变? ContextUpdate是否被正确应用?(如第二步能否读取第一步写入的状态)- 工具执行前后,上下文是否按预期变更?
这是 MCP 区别于简单 Function Calling 的核心验证点。
二、构建 Mock MCP Server:隔离 Agent 测试
为避免依赖真实工具(如数据库、支付网关),我们构建一个 可编程的 Mock MCP Server。
核心能力
- 动态注册 Mock 工具:测试时注入预设行为;
- 记录所有调用:用于后续断言;
- 模拟异常:如超时、500 错误、参数校验失败。
实现示例(Go)
// mock/server.go
type MockTool struct {
Name string
OnCall func(args map[string]interface{}) (interface{}, error)
CallLog []CallRecord
}
func (m *MockTool) Exec(args map[string]interface{}) (interface{}, error) {
result, err := m.OnCall(args)
m.CallLog = append(m.CallLog, CallRecord{Args: args, Result: result, Err: err})
return result, err
}使用场景
// 测试用例
tool := &MockTool{
Name: "get_user",
OnCall: func(args map[string]interface{}) (interface{}, error) {
if args["user_id"] == "U123" {
return map[string]interface{}{"name": "Alice"}, nil
}
return nil, errors.New("user not found")
},
}
mockServer.Register(tool)
// 启动 Agent,发起请求
// 断言:tool.CallLog[0].Args["user_id"] == "U123"优势:测试速度快、可重复、无外部依赖。
三、自动化打分:量化 Agent 行为质量
评测不应止于“通过/失败”,而应提供细粒度打分,指导优化方向。
评分维度示例
|
维度 |
评分规则 |
权重 |
|
工具调用必要性 |
该调用是否真正必要?(vs. 可纯文本回答) |
20% |
|
调用路径最优性 |
是否用最少工具步骤达成目标? |
30% |
|
参数准确性 |
参数是否完整、无冗余、格式正确? |
25% |
|
错误恢复能力 |
工具失败后是否尝试替代方案? |
25% |
实现方式
- 预设“黄金路径”:专家定义理想调用序列;
- 对比实际路径:计算编辑距离或 DAG 匹配度;
- LLM 辅助评分:用评判模型(如 GPT-4)评估决策合理性(需谨慎使用)。
关键原则:评分规则必须可解释、可配置、可审计,避免黑盒打分。
四、可视化调试面板:看清 Agent 的“思考-执行”链
当测试失败时,开发者需要快速定位问题环节。我们构建一个 Web 调试面板,展示全链路:
面板功能
- 会话列表:按
context_id聚合所有交互; - 时间线视图:
-
- LLM 生成的推理步骤;
- 发出的 MCP 请求(含参数);
- 收到的工具响应;
- 最终用户回复;
- 上下文快照:每一步执行前后的上下文状态;
- 协议合规性提示:高亮 JSON Schema 校验失败字段。
技术栈
- 前端:React + D3.js(时间线可视化)
- 后端:记录所有事件到 SQLite / PostgreSQL
- 数据模型:
{
"session_id": "sess-001",
"events": [
{ "type": "llm_thought", "content": "用户要查余额,需调用 query_balance" },
{ "type": "mcp_request", "tool": "query_balance", "args": {"user_id":"U123"} },
{ "type": "mcp_response", "result": {"balance": 987.65} },
{ "type": "final_answer", "content": "您的余额是 987.65 元" }
]
}效果:5 秒内定位问题——是 LLM 决策错?参数错?还是工具返回异常?
五、与 CI/CD 集成:每次提交自动验证 MCP 兼容性
将评测框架嵌入 GitLab CI/CD,实现质量左移:
.gitlab-ci.yml 示例
stages:
- test
mcp-compliance-test:
stage: test
script:
- go test -v ./test/mcp/... # 协议合规性
- python -m pytest test/agent/... # Agent 行为评测
- ./scripts/generate_debug_report.sh # 生成调试报告(失败时)
artifacts:
when: on_failure
paths:
- debug-report.html # 上传可视化报告集成价值
- 阻止破坏性变更:如修改工具参数但未更新 Agent;
- 回归测试自动化:每次提交验证核心用例;
- 质量门禁:评测分数低于阈值则构建失败。
从此,MCP 集成不再是“手动点点看”,而是可度量的工程交付物。
六、MCP 评测与调试框架架构图
下图展示了整个框架的组件协作关系:
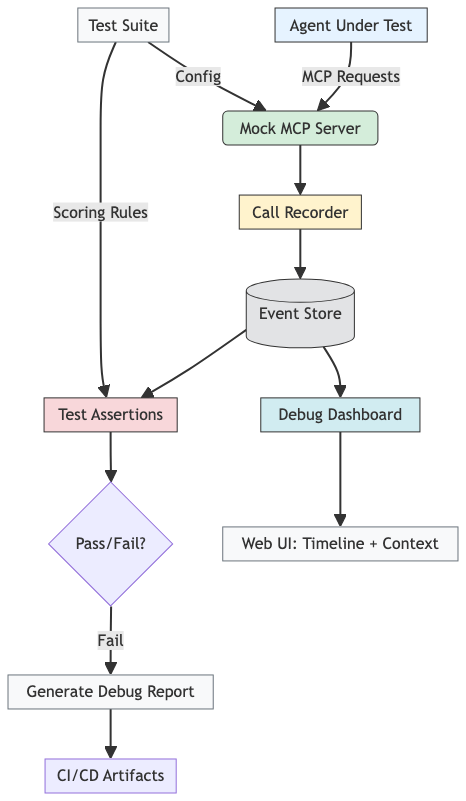
该架构实现了 “录制-验证-可视化-反馈”闭环,大幅提升开发效率。
结语:评测能力,是 MCP 落地的最后一块拼图
MCP 协议定义了“如何通信”,但只有评测框架能确保“通信正确”。
通过自动化测试、Mock 服务、可视化调试与 CI 集成,你不再依赖“感觉”判断 Agent 是否 work,而是用数据说话、用报告定位、用分数驱动优化。
这不仅是调试工具,更是AI 工程化的核心基础设施。
现在,是时候告别 fmt.Println 调试 AI 的时代了——让每一次 Agent 迭代,都有据可依,有迹可循。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)