(论文速读)基于M-LLM的高效视频理解视频帧选择
本文提出了一种基于多模态大语言模型(M-LLM)的自适应视频帧选择方法,以提高视频理解效率。针对现有均匀采样方法可能导致关键帧丢失的问题,该方法通过轻量级帧选择器,结合空间和时间双重监督信号,智能选取与问题相关的视频帧。实验表明,该方法在中长视频问答任务上显著提升性能(最高+3.7%),并能用更少帧数达到更好效果(4帧接近32帧的均匀采样效果)。核心创新在于问题导向的帧选择策略,仅需1.5B参数即
论文题目:M-LLM Based Video Frame Selection for Efficient Video Understanding(基于M-LLM的高效视频理解视频帧选择)
会议:CVPR2025
摘要:多模态大语言模型(m - llm)的最新进展在视频推理中显示出令人鼓舞的结果。流行的多模态大语言模型(M-LLM)框架通常采用朴素的均匀采样来减少输入到M-LLM的视频帧的数量,特别是对于长上下文视频。然而,它可能会在视频的某些时期失去关键的上下文,因此下游的M-LLM可能没有足够的视觉信息来回答问题。为了解决这个痛点,我们提出了一种轻量级的基于m - llm的帧选择方法,该方法自适应地选择与用户查询更相关的帧。为了训练所提出的帧选择器,我们引入了两个监督信号(i)空间信号,其中单个帧重要性通过提示M-LLM进行评分;(ii)时间信号,其中通过使用所有候选帧的标题提示大语言模型(Large Language Model, LLM)进行多帧选择。然后,选定的帧被一个冻结的下游视频M-LLM消化,用于视觉推理和问答。实证结果表明,所提出的M-LLM视频帧选择器提高了各种下游视频大语言模型(video- llm)跨中(ActivityNet、NExT-QA)和长(EgoSchema、longvideobbench)上下文视频问答基准的性能。

让视频理解更智能:基于M-LLM的自适应帧选择
引言:视频理解的"看图说话"困境
想象你在看一部3小时的电影,但只能看32张截图,然后要回答关于剧情的问题。这听起来很荒谬,但这正是当前视频多模态大语言模型(M-LLM)面临的困境。
来自CMU、UCF和Amazon的研究团队在CVPR 2025上提出了一个优雅的解决方案:不是盲目地均匀采样,而是让AI自己选择最重要的帧。这就像给AI配了一双"慧眼",能够聪明地挑选出真正有用的关键帧。
问题:均匀采样,一刀切的代价
当前方法的困境
现有的视频M-LLM通常这样工作:
3分钟视频(5400帧)→ 均匀采样32帧 → 输入M-LLM → 回答问题
这种方法有三个严重问题:
1. 关键信息可能被跳过 每隔6秒才采样一帧,如果关键动作发生在这6秒之间呢?就像图1中展示的例子,问题是"男孩帽子上贴着什么?",答案是"价格标签"。均匀采样可能完全错过展示价格标签的帧。
2. 大量冗余帧占用资源 一个32帧的输入,使用传统方法需要4608个token(32帧×144 token/帧),其中可能大部分帧对回答问题毫无帮助。
3. 缺乏问题针对性 不同的问题需要关注视频的不同部分,但均匀采样对所有问题一视同仁。
创新:双重视角的智能选择
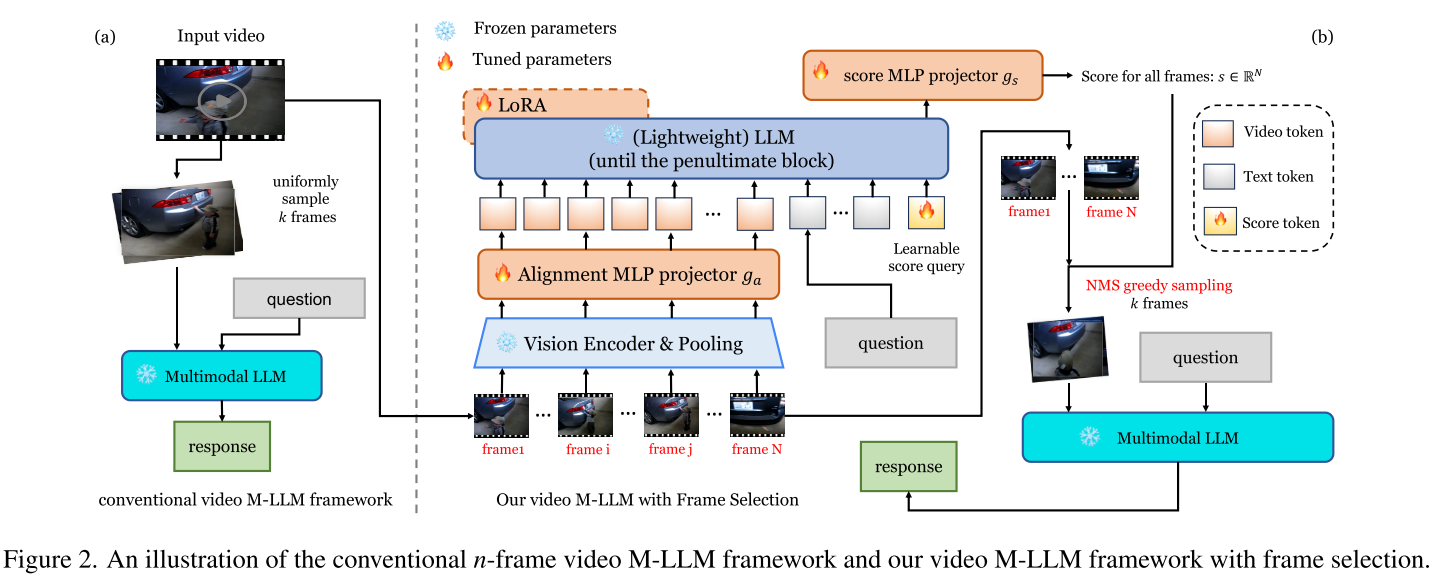
核心思想:让AI自己挑帧
研究团队提出的方法核心是:训练一个轻量级的帧选择器,根据问题内容自适应地选择最相关的帧。
架构设计:小而精
选择器的设计非常巧妙:
- 轻量级骨干:使用1.5B参数的Qwen2.5模型,而不是庞大的M-LLM
- 极简token表示:每帧只用9个token(3×3),相比传统的144个token减少了94%
- 可学习评分机制:
输入:128帧 + 问题文本 + 评分查询向量输出:128维的重要性分数向量
这个设计哲学是:判断帧的重要性不需要看清所有细节,只需要大致轮廓。就像人类快速浏览视频时,也是先粗略判断哪些部分重要,再仔细观看。
训练策略:双重伪标签
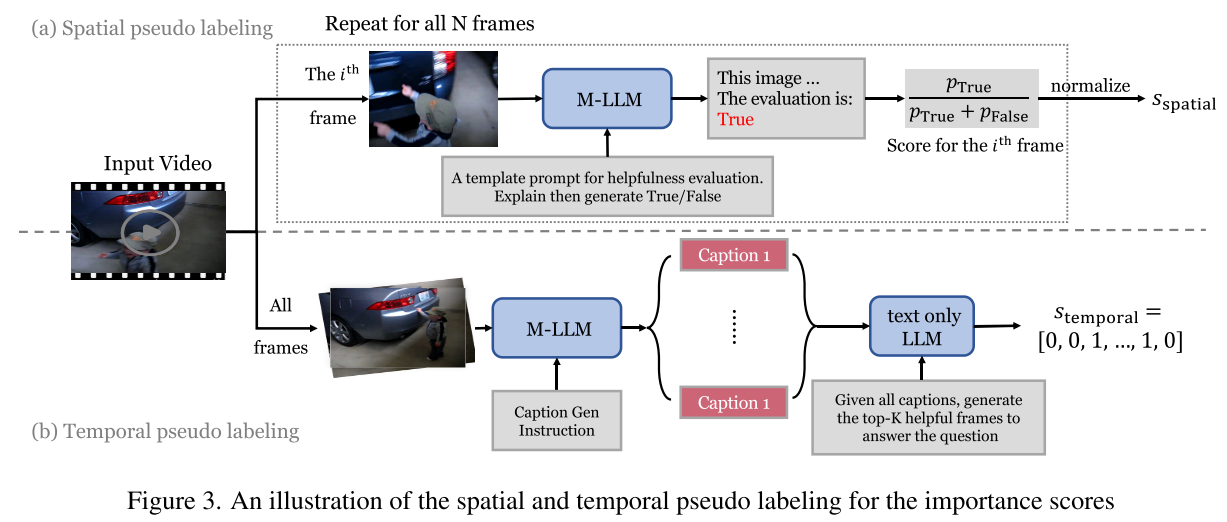
由于没有现成的帧重要性标注数据,研究团队设计了两种互补的伪标签生成方法:
空间伪标签:逐帧评估
对于每一帧:
1. 向Qwen2-VL提问:"这一帧对回答问题有帮助吗?"
2. 使用Chain-of-Thought:先让模型解释,再给出True/False
3. 计算概率:score = P(True) / [P(True) + P(False)]
时间伪标签:全局推理
1. 为所有128帧生成详细字幕
2. 将所有字幕+问题输入GPT-4o-mini
3. LLM基于时间上下文,选出最有帮助的K帧
为什么需要两种标签?
- 空间标签:精确评估单帧内容,但缺乏时间上下文
- 时间标签:考虑帧间关系,但可能有信息损失
- 结合使用:取平均值,兼顾两者优势
NMS-Greedy采样:避免冗余

选出重要性分数后,不能直接取Top-K,因为相邻帧往往内容相似。研究团队设计了NMS-Greedy算法:
for i in range(k):
# 贪心:选择当前最高分的帧
selected_frame = argmax(scores)
# NMS:屏蔽邻近帧
for neighbor in get_neighbors(selected_frame):
scores[neighbor] = -1
这就像拍照时,不会连续拍10张几乎一样的照片,而是在不同时刻各拍一张。
实验
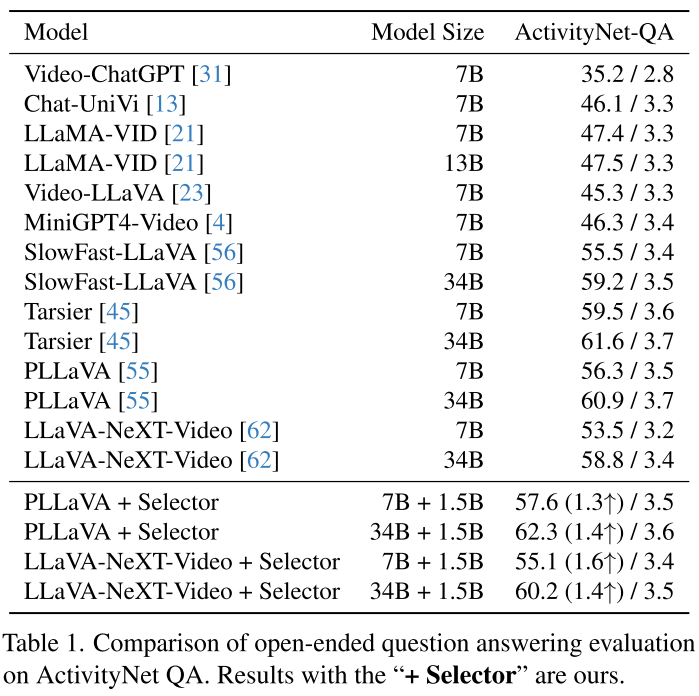
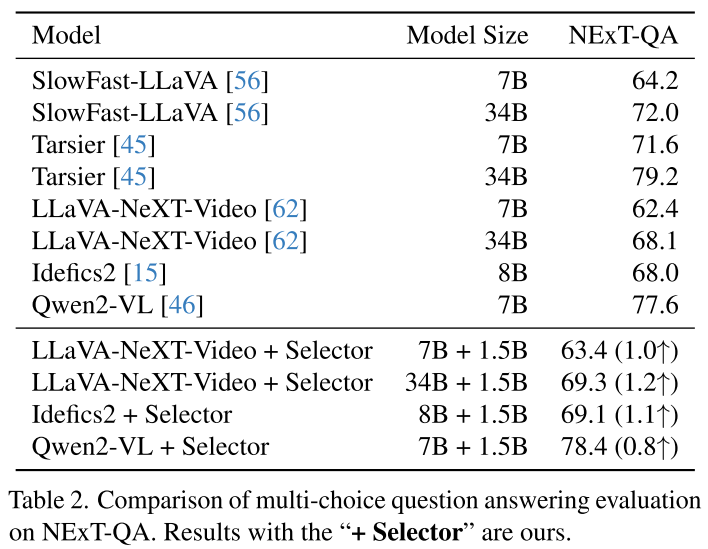
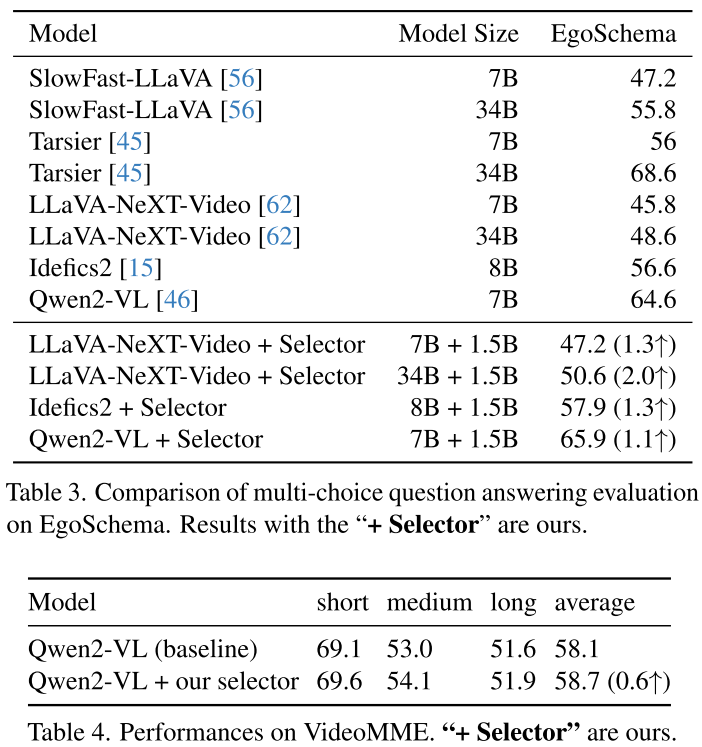
性能提升:少即是多
在ActivityNet-QA上:
- PLLaVA-7B:56.3% → 57.6% (+1.3%)
- PLLaVA-34B:60.9% → 62.3% (+1.4%)
在EgoSchema上(长视频理解):
- LLaVA-NeXT-Video-34B:48.6% → 50.6% (+2.0%)
效率革命:用一半帧达到更好效果
这是最令人惊讶的发现:
| 配置 | 帧数 | 准确率 | 推理时间 |
|---|---|---|---|
| 均匀采样 | 8帧 | 68.7% | 0.92s |
| 均匀采样 | 16帧 | 69.1% | 1.71s |
| 选择器 | 128→8帧 | 69.3% | 1.12s |
使用选择器,从128帧中挑选8帧,性能超过均匀采样16帧,同时速度更快!
长视频测试:优势更明显
在LongVideoBench(平均473秒的长视频)上:
Qwen2-VL测试:
- 均匀采样32帧:53.3%
- 选择器挑选32帧:57.0% (+3.7%)
LLaVA-NeXT-Video-34B测试:
- 均匀采样32帧:49.7%
- 选择器挑选32帧:50.0% (+0.3%)
- 更重要的是:选择器只用4帧就达到49.5%,接近均匀采样32帧的效果!
可视化:AI的"慧眼"
论文展示了两个生动的例子:
例子1:"男孩转头后做了什么?"
- 答案:"向女孩挥手"
- 均匀采样:可能错过转头和挥手的关键帧
- 选择器:精准定位到"转头"和"挥手"两个动作的帧
例子2:"戴帽子的男人为什么在开始时移动手?"
- 答案:"喝水"
- 选择器:准确选中拿水杯和喝水的帧
技术细节:魔鬼藏在实现中
训练细节
阶段1(2个epoch):
- 冻结:视觉编码器 + LLM主体
- 训练:对齐投影器 + 评分查询 + 评分投影器
- 任务:视觉指令跟随 + 重要性分数预测(交替)
阶段2(5个epoch):
- 新增训练:LLM的LoRA权重
- 任务:仅重要性分数预测
消融研究的发现
1. Token数量的影响:
- 1 token/帧:46.6%(信息不足)
- 9 tokens/帧:47.2%(最佳平衡)
- 25 tokens/帧:47.3%(提升有限,成本高)
2. 模型大小的权衡:
- 0.5B:46.4%(能力不足)
- 1.5B:47.2%(性价比最高)
- 7B:47.9%(提升有限,成本高3倍)
3. 伪标签策略对比:
- CLIP相似度:63.2%(简单基线)
- SeViLA方法:63.2%(单帧评估)
- 仅空间标签:63.6%(改进的单帧)
- 空间+时间:63.9%(最佳组合)
方法的局限与未来
当前局限
-
视频定位任务表现一般:在QVHighlights基准上,性能略低于SeViLA(43.9% vs 54.5%),因为没有专门针对该任务训练
-
伪标签质量依赖:依赖于Qwen2-VL和GPT-4o-mini的判断质量
-
计算开销:虽然推理时高效,但生成伪标签的过程计算密集(需要对每帧调用M-LLM)
未来方向
- 端到端训练:结合帧选择器和下游QA模型联合优化
- 自适应帧数:根据视频复杂度动态决定需要多少帧
- 多模态融合:结合音频、文本等其他模态信息
实践启示:为什么这项工作重要?
1. 即插即用的实用性
无需重新训练下游M-LLM,可以立即为现有模型"赋能"。这对于已经部署的系统特别有价值。
2. 效率优先的设计理念
在AI模型动辄百亿参数的今天,这项工作提醒我们:智能的算法设计比暴力堆参数更重要。用1.5B的小模型做帧选择,提升7B甚至34B模型的性能,这是真正的"四两拨千斤"。
3. 问题导向的范式转变
从"看完整视频"到"按需观看",这种思路转变不仅适用于视频理解,也可能启发其他长上下文任务(如长文档理解、多轮对话等)。
4. 资源受限环境的福音
对于边缘设备、移动端应用,这种高效方法使得复杂的视频理解成为可能。
代码实现思路(伪代码)
class VideoFrameSelector:
def __init__(self):
self.vision_encoder = SigLIP_ViT_Large()
self.llm = Qwen2_5_1_5B()
self.alignment_projector = MLP()
self.score_query = LearnableQuery()
self.score_projector = MLP()
def forward(self, frames, question):
# 1. 视觉编码 + 激进池化
visual_features = self.vision_encoder(frames) # [128, 16, 16, dim]
visual_tokens = avg_pool(visual_features, target_size=(3, 3)) # [128, 9, dim]
# 2. 对齐到LLM空间
aligned_tokens = self.alignment_projector(visual_tokens) # [128, 9, dim]
# 3. 拼接问题和评分查询
text_tokens = self.tokenize(question)
all_tokens = concat(aligned_tokens, text_tokens, self.score_query)
# 4. LLM处理(到倒数第二层)
hidden_states = self.llm(all_tokens, output_hidden_states=True)
score_token_hidden = hidden_states[-2][-1] # 倒数第二层的最后一个token
# 5. 生成重要性分数
importance_scores = self.score_projector(score_token_hidden) # [128]
# 6. NMS-Greedy采样
selected_indices = self.nms_greedy_sampling(importance_scores, k=8)
return selected_indices
def nms_greedy_sampling(self, scores, k):
selected = []
scores = scores.copy()
neighbor_gap = len(scores) // (4 * k)
for _ in range(k):
# 贪心选择最高分
idx = np.argmax(scores)
selected.append(idx)
# NMS:屏蔽邻近帧
for j in range(len(scores)):
if abs(idx - j) <= neighbor_gap:
scores[j] = -inf
return sorted(selected)
结论:智能视频理解的新范式
这项工作的核心贡献不仅是性能的提升,更是提出了一种新的思维方式:
不是让模型被动接受所有帧,而是让模型主动选择需要的帧。
这种"按需观看"的范式,就像人类观看视频时的自然行为——我们会快进无关内容,在关键部分暂停仔细观察。将这种智能引入AI系统,是视频理解走向实用化的重要一步。
随着视频内容的爆炸式增长(每分钟有500小时视频上传到YouTube),高效的视频理解技术将变得越来越重要。这项工作为我们指明了一个方向:智能不在于看得多,而在于看得准。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)