模型上下文协议(MCP)详解:大模型连接外部工具的标准化之道!
模型上下文协议(MCP)是由Anthropic发起的开源标准,为AI模型连接外部数据源提供标准化解决方案。采用客户端-服务器架构,使工具、资源和操作实现即插即用,解决了传统集成的碎片化问题。文章详细解析了MCP架构、工作原理,并通过Python构建服务器和LangGraph集成的实例,展示了如何简化大模型与外部系统的连接,是构建高效AI应用的重要技术。
模型上下文协议 (MCP)(由 Anthropic 发起的开源标准) 在人工智能领域引起了广泛关注,为人工智能模型连接外部数据源和工具提供了一种标准化的方式。通过简化集成流程,MCP 有望彻底改变开发者创建人工智能应用的方式,使用户能够更轻松地访问实时数据并利用高级功能。
在 MCP 之前,将 LLM 连接到外部系统需要:
- 自定义agents
- 自定义工具schemas
- 自定义prompt格式
- 实现代码需要定制化
这意味着:
- 工具不可重复使用
- 不同模型无法共享相同的功能
- 调试过程很复杂
- 没有统一的安全模型
工程团队需要重复开发相同的基础功能:
-
模型如何调用工具?
-
“如何传递参数?”
-
“如何获得结果?”
MCP 通过一个通用协议解决了所有这些问题,使工具、资源和操作能够即插即用, 适用于任何模型。
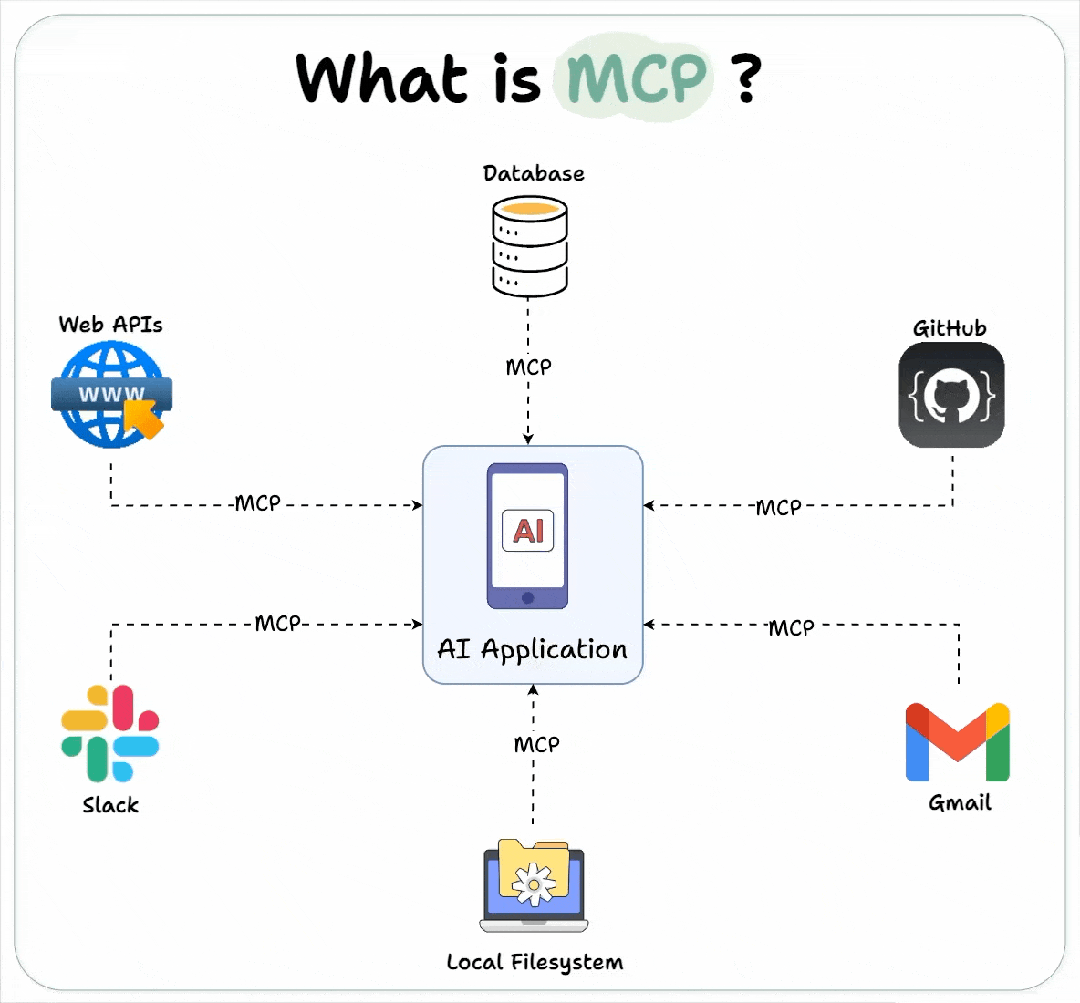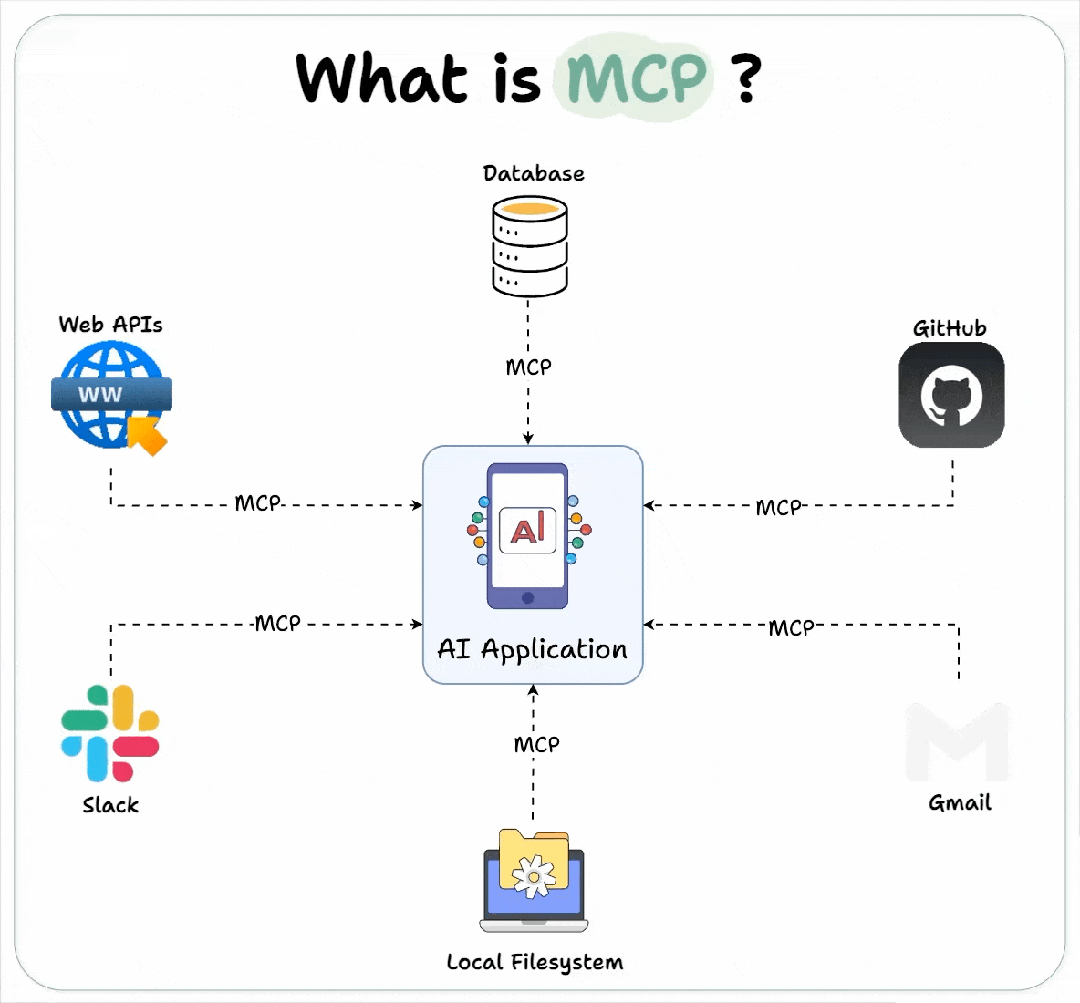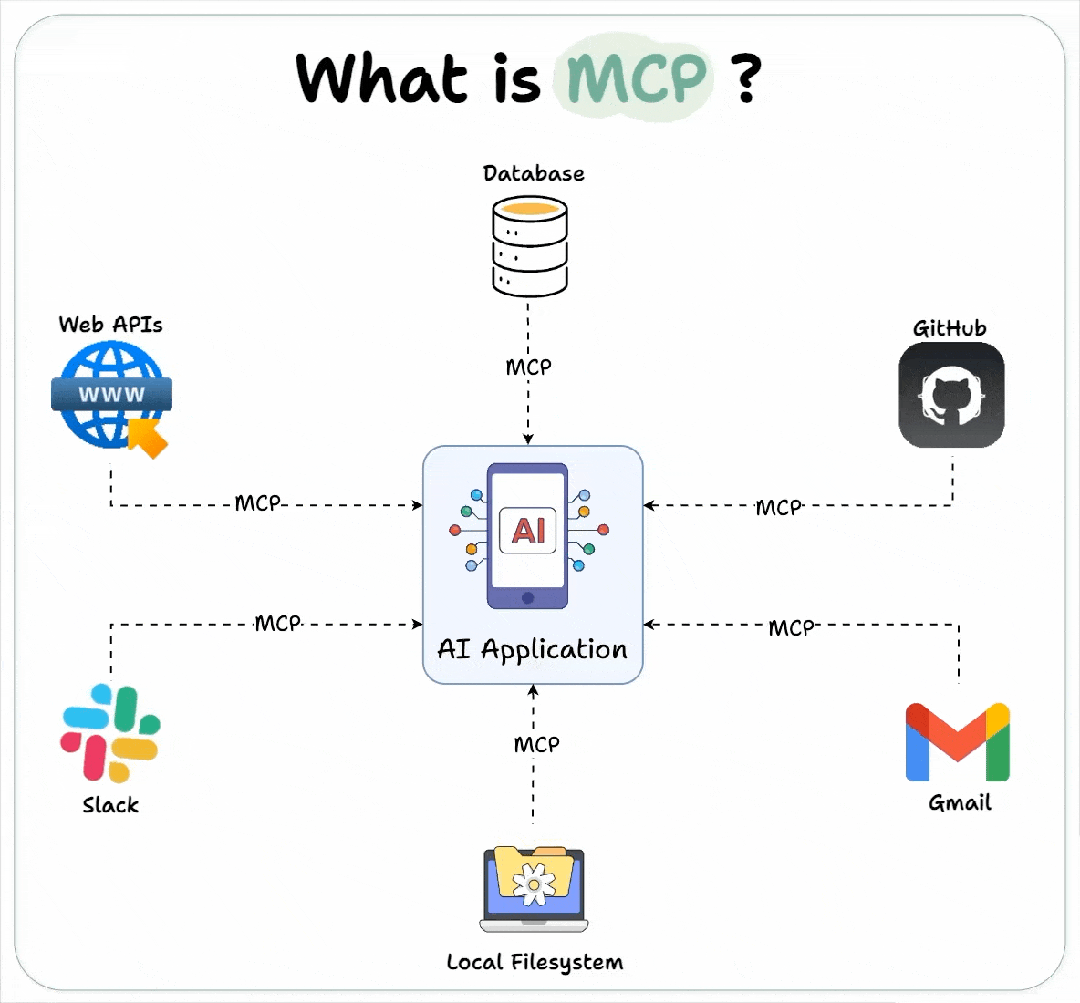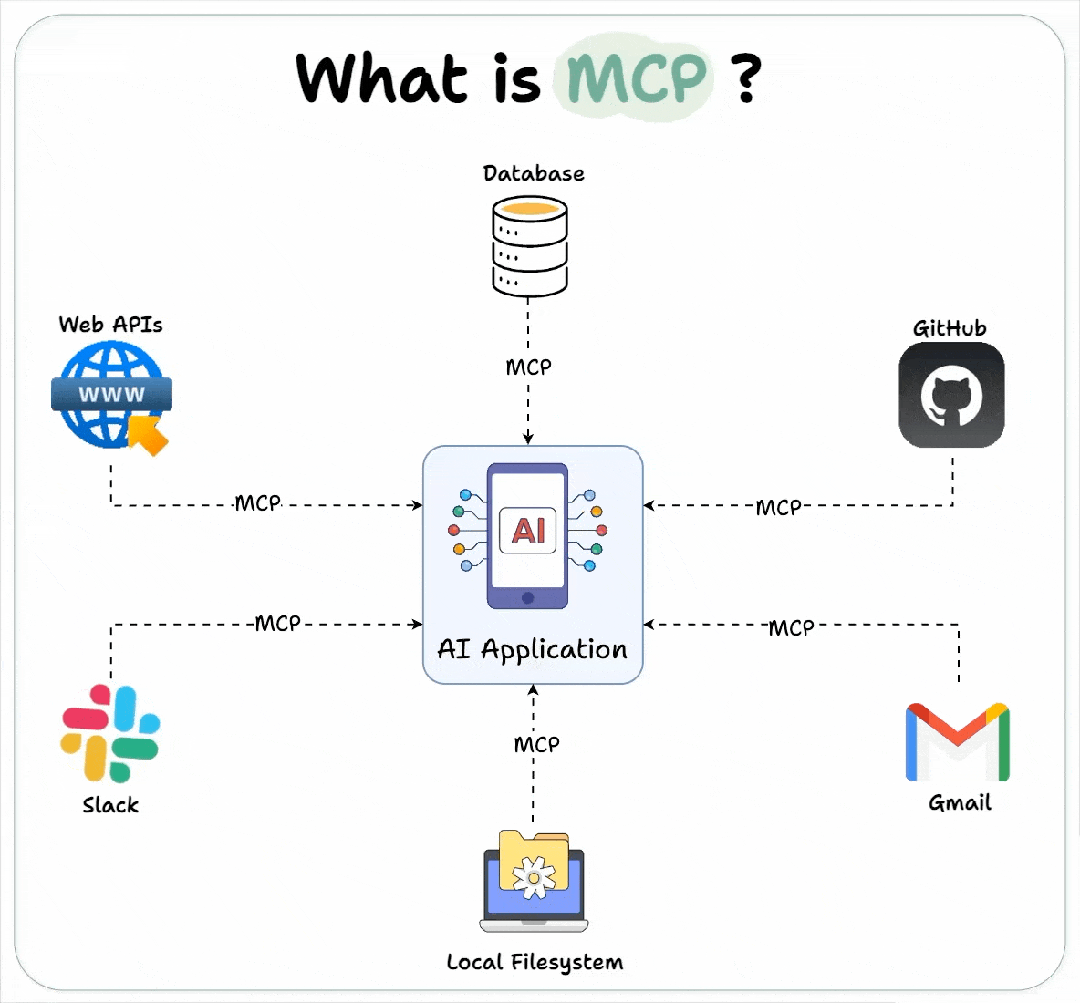
一、什么是 MCP?
当你第一次听到 “MCP”时, 可能听起来很复杂或非常专业,但 MCP 背后的理念却非常简单。
MCP 的核心是一种通信标准。它以清晰、结构化的方式定义了人工智能模型和外部系统如何相互通信 。
在 MCP 出现之前,每个工具的集成方式都各不相同。有的系统可能需要 JSON 数据;有的系统可能需要专有模式;还有的系统可能需要在Prompt中使用一些变通方法。总之,没有任何统一的标准。
MCP 通过引入一个所有工具、模型和应用程序都能达成共识的单一、定义明确的协议来解决这个问题。

最简单的类比:
MCP 就像谷歌 Chrome 浏览器一样。
模型是浏览器,MCP 服务器是网站。
浏览器知道如何加载任何网站,因为所有网站都遵循标准的“网络协议”。
相似地:
任何兼容 MCP 的模型→都可以与任何 MCP server通信。
任何 MCP server → 均可与支持 MCP 的任何模型配合使用。
这样一来,你的工具就变成了即插即用型的。
1.1 为什么 MCP 很重要:解决核心 AI 的局限性
为了理解 MCP 的重要性,我们需要了解大型语言模型 (LLM) 的一个根本局限性。LLM受限于其训练数据,无法获取超出训练范围的信息和动作,这通常被称为“知识截止日期”。
LLM 本身只能处理你提供的文本。它们不能:
- 检查本地文件
- 查询您的数据库
- 运行分析
- 编辑文档
- 调用 API
- 访问知识库
- 触发工作流程
这一切都需要“外部上下文”。
通常来说,团队经常是这样开发的:
- 自定义 Python 封装器
- 定制 API
- 开发 SDK
- 模型专用插件
- 提示词注入攻击
- 一次性集成
这种开发方式在LLM时代会遇到如下情况:
- 两种不同的模型很难共用同一个工具。
- 两个不同的团队不能重复使用相同的逻辑。
- 每增加一项新功能,工程师都必须重新编写集成代码。

为了克服LLM局限性,主要有如下两种方式:
-
检索增强生成(RAG):这项技术的原理是从外部来源检索相关信息,并将其直接放入到LLM上下文窗口中。然后,LLM可以基于这些新提供的信息生成响应,从而有效地将其知识扩展到训练数据之外。
-
工具使用(Tool Use) :这种方法使LLM能够访问外部“工具”或功能,并在需要时调用它们。例如,某个工具可以帮助LLM查看天气、进行计算或搜索互联网。
虽然两种方法都很有价值,但工具使用面临着一个重大挑战: 集成复杂性。 在 MCP 出现之前,每个工具都必须单独编码到相应的 AI 应用程序中。如果想要添加新的工具或功能,则需要更新 AI 应用程序本身。这导致生态系统碎片化,各种工具被孤立地存储在特定的 AI 平台中。
MCP 巧妙地解决了这个问题,它将工具与特定的 AI 实现解耦。它建立了一个标准协议,任何 AI 系统都可以使用该协议与任何支持该协议的工具进行通信。这类似于 USB 的工作原理:任何带有 USB 端口的设备都可以连接到任何 USB 外设,无论这两个组件的制造商是谁。
1.2 进入 MCP:标准连接
MCP在解决这个问题时,主要考虑以下问题:
- 模型如何请求操作
- 服务器如何获取工具和资源
- 数据如何交换
- 事件和更新如何实时传输
- 如何传达错误和能力信息
MCP为双方都提供了可预测的结构和词。
这意味着:
如果你构建一台 MCP 服务器,
→ 任何兼容的 LLM 或agent都可以使用它。
如果你想更换型号,
→ 您的工具无需修改即可继续使用。
如果你设计多个工具,
→ 它们都可以遵循相同的模式。
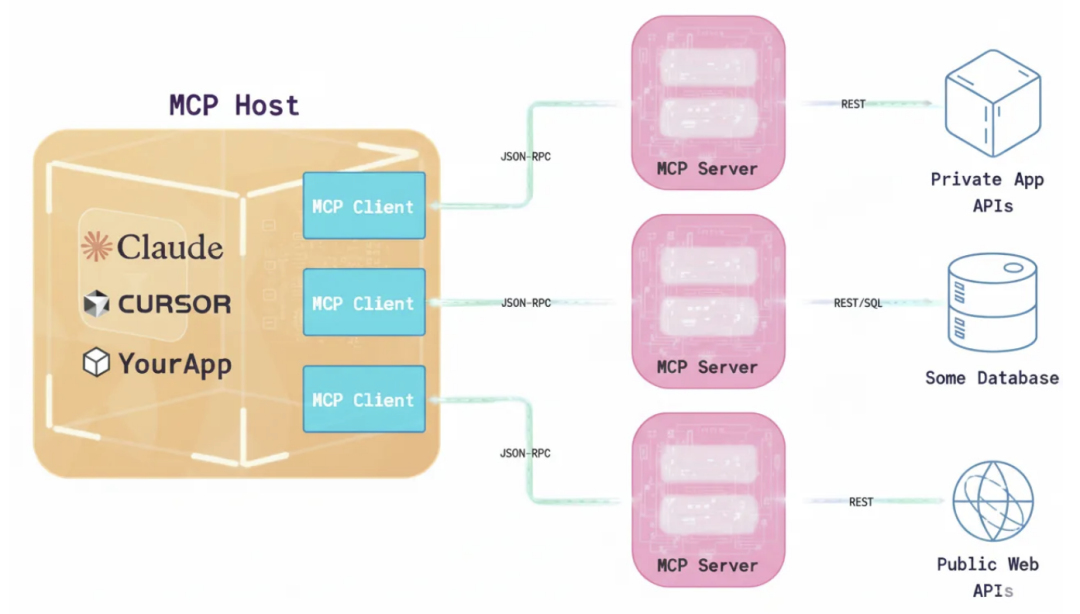
可以把它想象成人工智能集成领域的 USB。在 USB 等标准出现之前,连接外设需要各种不同的端口和定制驱动程序。同样,将人工智能应用程序与外部工具和系统集成也是一个 M×N 的问题 。
如果您有 M 个不同的 AI 应用(例如聊天应用、RAG 1 系统、自定义代理等)和 N 个不同的工具/系统(例如 GitHub、Slack、Asana、数据库等),您可能需要构建 M×N 个不同的集成。这会导致团队间重复劳动,以及实现方式不一致。
MCP 旨在通过提供通用 API 并将此问题转化为“ M+N 问题 ”来简化这一过程。工具创建者构建 N 个 MCP 服务器(每个系统一个),而应用程序开发人员构建 M 个 MCP 客户端(每个 AI 应用程序一个)。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

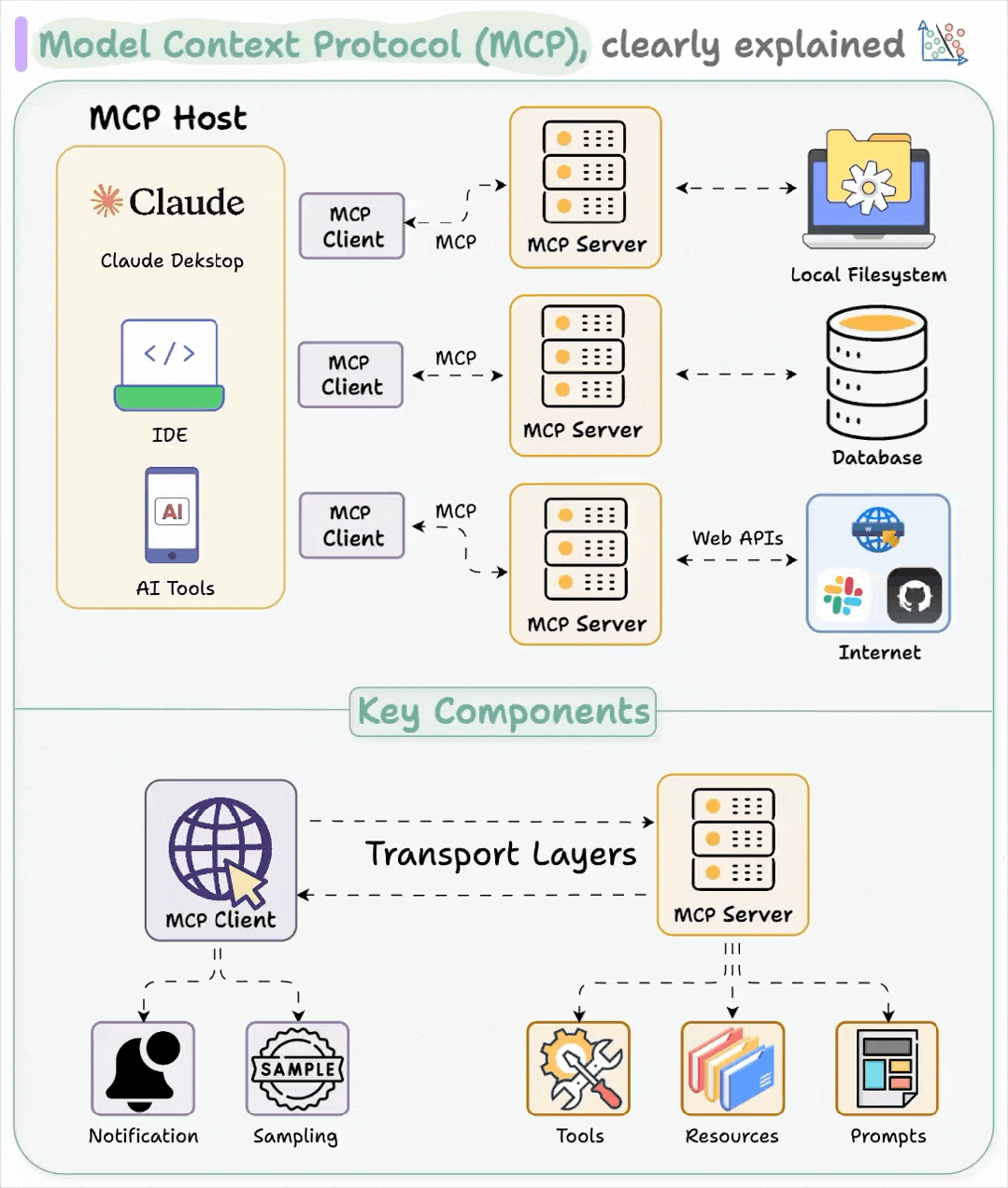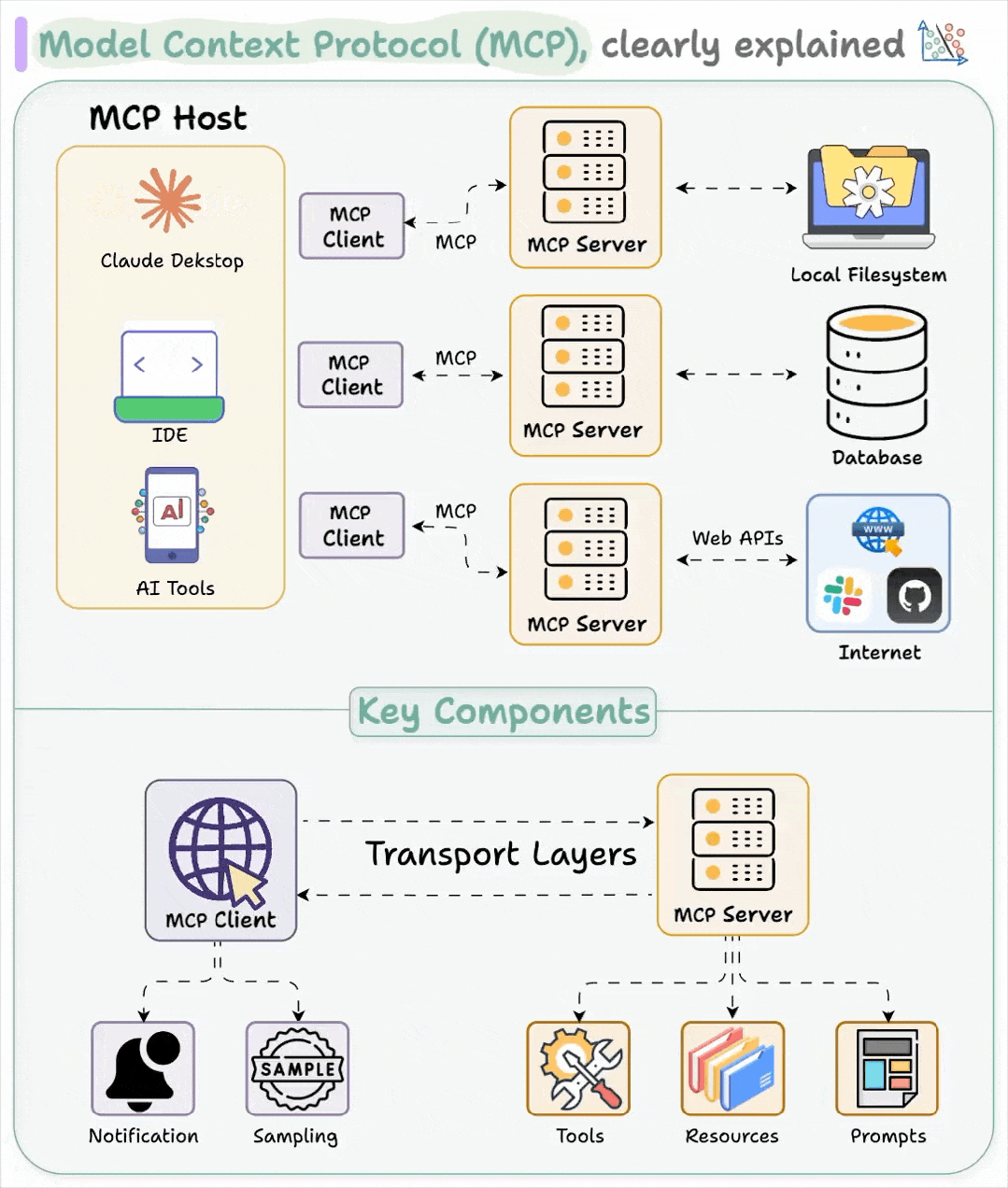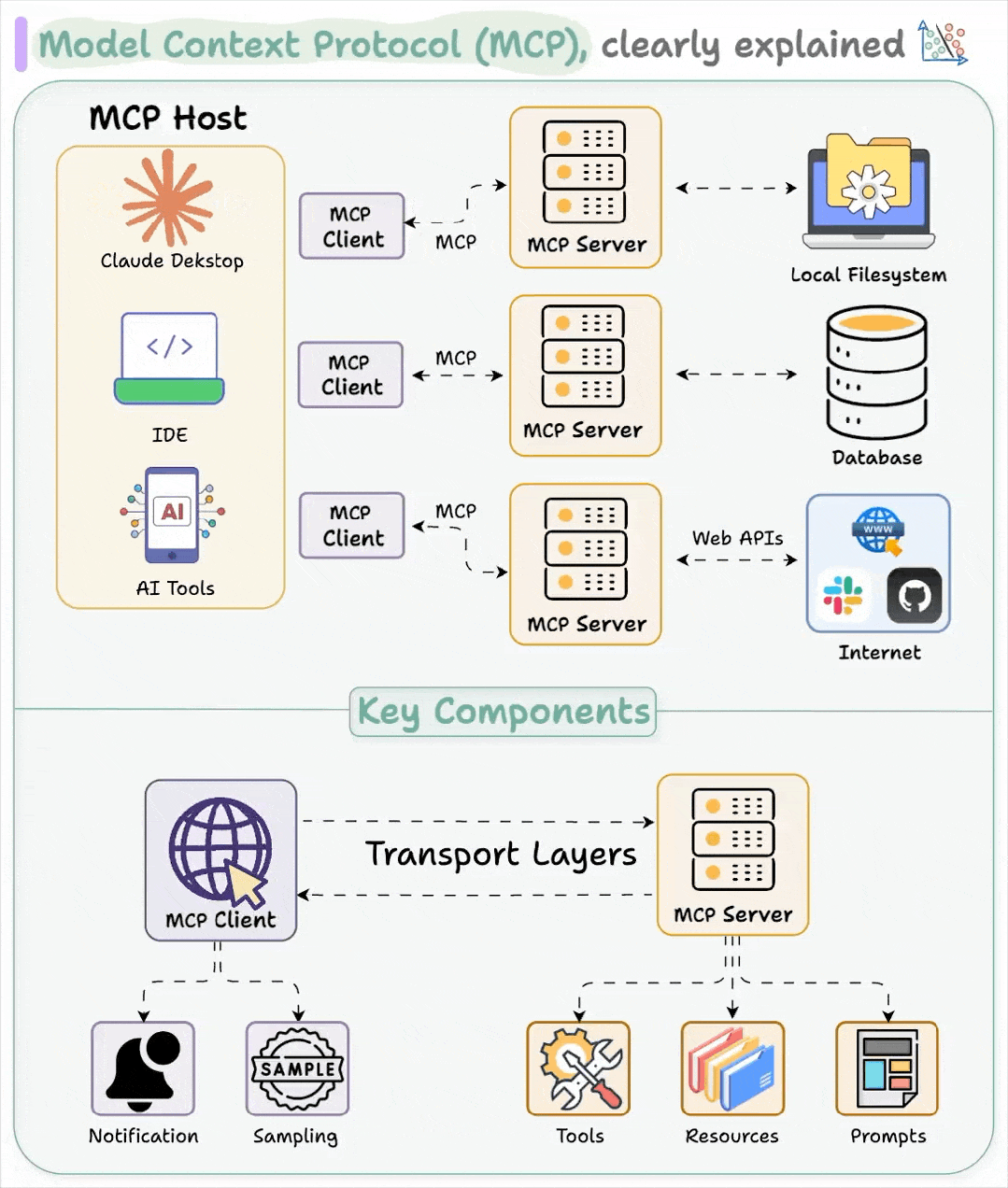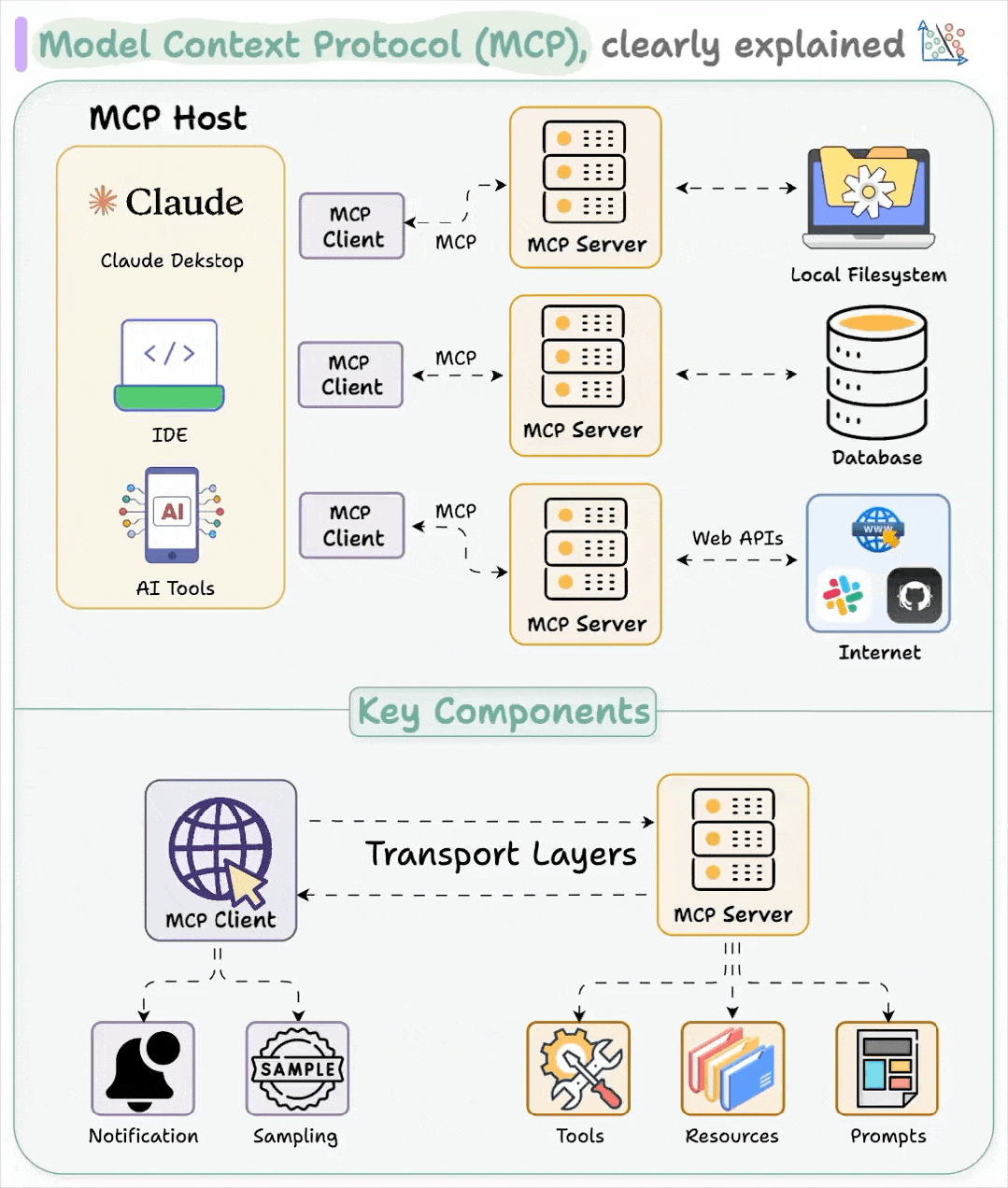
二、MCP 架构和核心组件
模型上下文协议 (MCP) 采用C-S架构, 其部分灵感来源于语言服务器协议Language Server Protocol (LSP)[1] 。LSP 能够帮助不同的编程语言与各种开发工具连接。类似地,MCP 的目标是通过标准化上下文,为人工智能应用与外部系统交互提供一种通用的方式。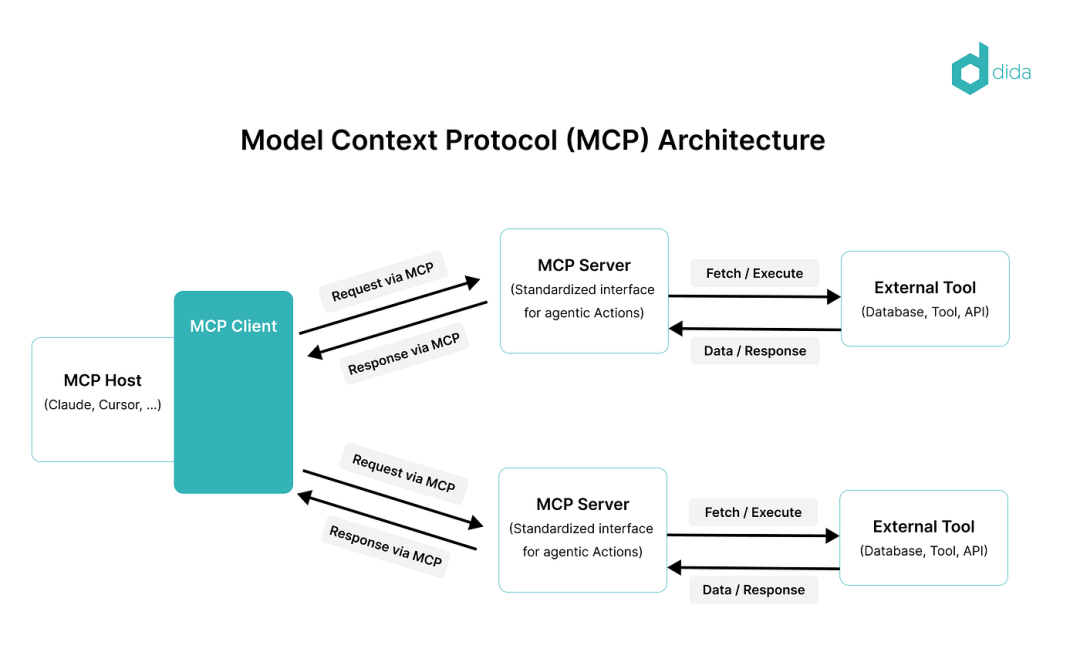
MCP 架构由四个主要元素组成:
2.1 MCP Host
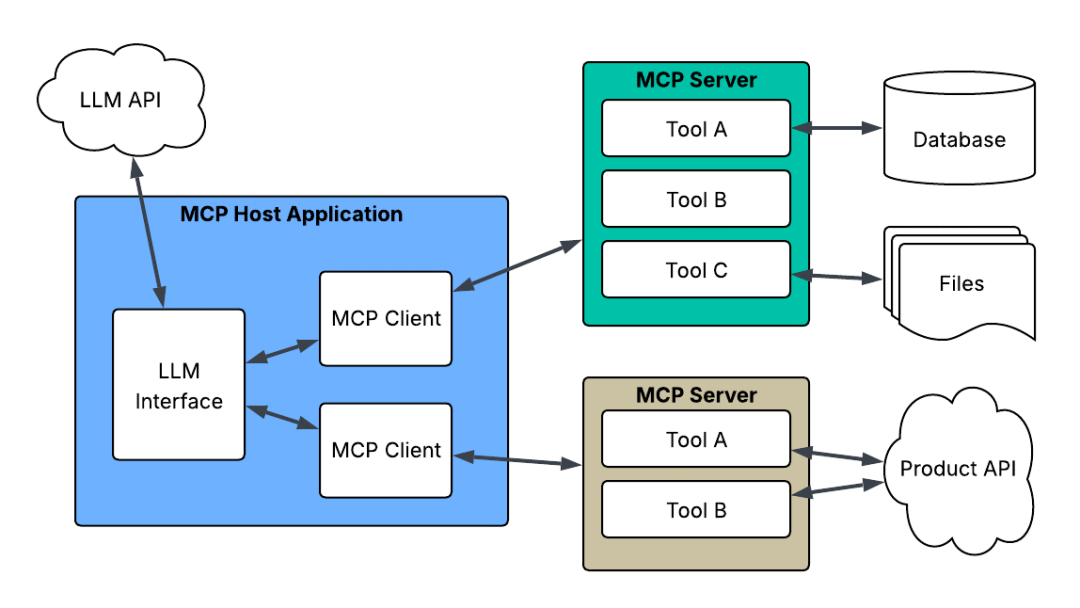
MCP host是一个人工智能应用程序,它在运行 MCP 客户端的同时,为执行基于人工智能的任务提供环境。它集成了交互式工具和数据,以实现与外部服务的顺畅通信。
例如:用于人工智能辅助内容创作的 Claude Desktop,用于代码补全和软件开发的人工智能 IDE Cursor,以及作为自主系统执行复杂任务的人工智能代理。
MCP host托管 MCP 客户端,并确保与外部 MCP 服务器通信。
2.2 MCP Client
该功能集成在主机应用程序中,与 MCP servers进行连接,并在主机需求和模型上下文协议 (MCP) 之间进行转换。客户端内置于主机应用程序中,例如 Claude Desktop 中的 MCP 客户端。
client是指使用这些工具的实体。
这可能是:
-
ChatGPT
-
一个LangGraph智能体
-
运行 LLM 的应用程序
客户端的任务很简单:它使用 MCP 协议发送请求和接收响应。它不知道这些工具的实际工作原理;它只知道服务器公开了哪些内容 。
把它想象成遥控器:
你不需要了解电视机的内部工作原理,你只需要按下按钮,然后期待电视机做出反应。
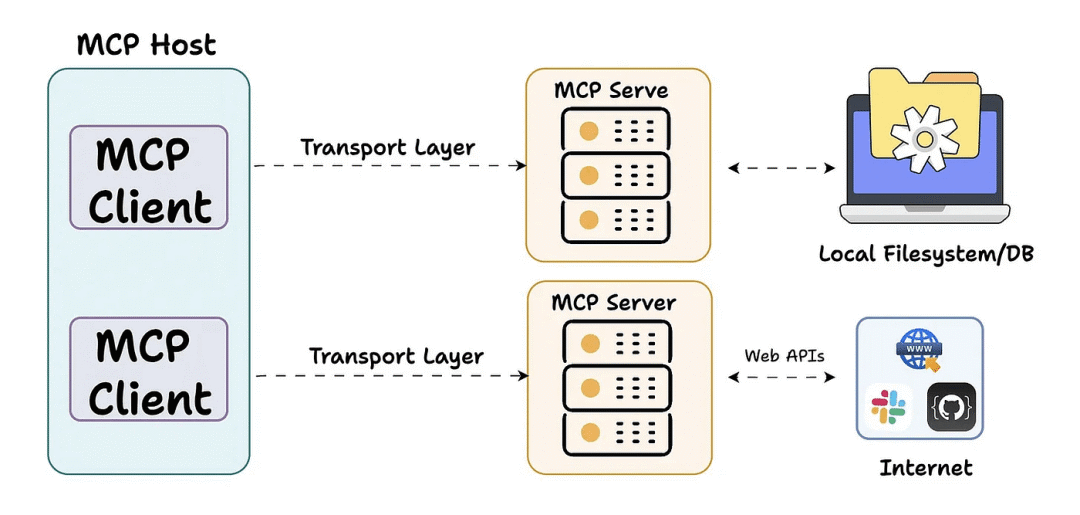
2.3 MCP Server
服务器是 MCP 的骨干。它定义了模型可以访问的内容以及可以执行的操作 。
A server can expose your:
服务器可是如下:

服务器决定模型可以使用的“工具箱”。
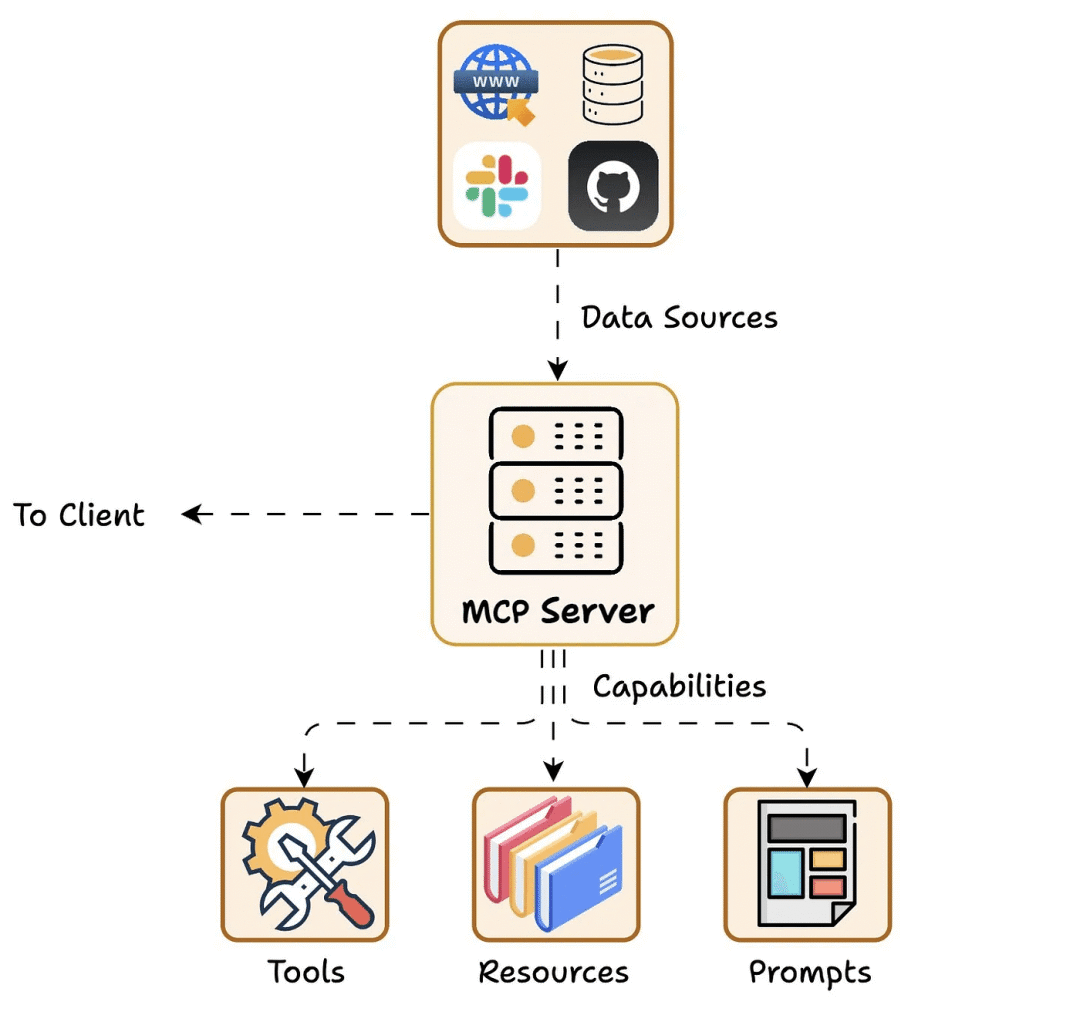
模型无法超出此工具箱的范围,这使得 MCP 既强大又安全。
MCP 服务器提供了特定功能和可以访问的数据,比如:
2.3.1 Resources
资源是模型可以读取的数据。例如:

资源为只读视图。比如:
- /docs 文件夹
- /configs/system.json
- SELECT * FROM customers LIMIT 10
- /tickets/open/123
这为模型提供了重要的背景信息,且没有被修改的风险。
2.3.2 Tools
工具是模型可以采取的行动 。
例如:
工具需要具备以下特点:
-
工具名字
-
输入数据的schema
-
输出数据的schema
这些schema使得 MCP 具有极强的可预测性。模型知道预期参数是什么,以及它将得到什么结果。
工具才是真正力量的源泉。
Resources = “模型可以看到的内容”
Tools = “模型可以做什么”
2.4 传输层
客户端与服务器之间的通信机制。MCP 支持两种主要的传输方式:
STDIO(标准输入/输出): 主要用于本地集成,其中服务器与客户端运行在同一环境中。
HTTP+SSE(服务器发送事件): 远程连接,使用 HTTP 进行客户端请求,使用 SS 进行服务器响应和流式传输。
MCP 中的所有通信都使用 JSON-RPC 2.0 作为底层消息标准,为请求、响应和通知提供标准化的结构。
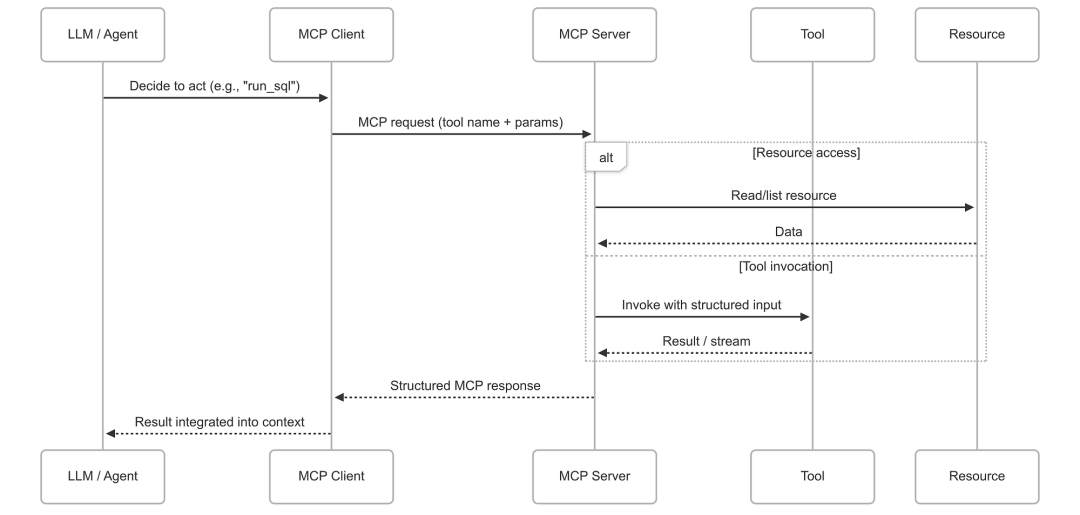
三、MCP 的工作原理
了解host-client-server通信对于构建自己的 MCP client-server至关重要。那么让我们来了解一下客户端和服务器是如何通信的。
在分步骤讲解之前,先来看一张示意图。
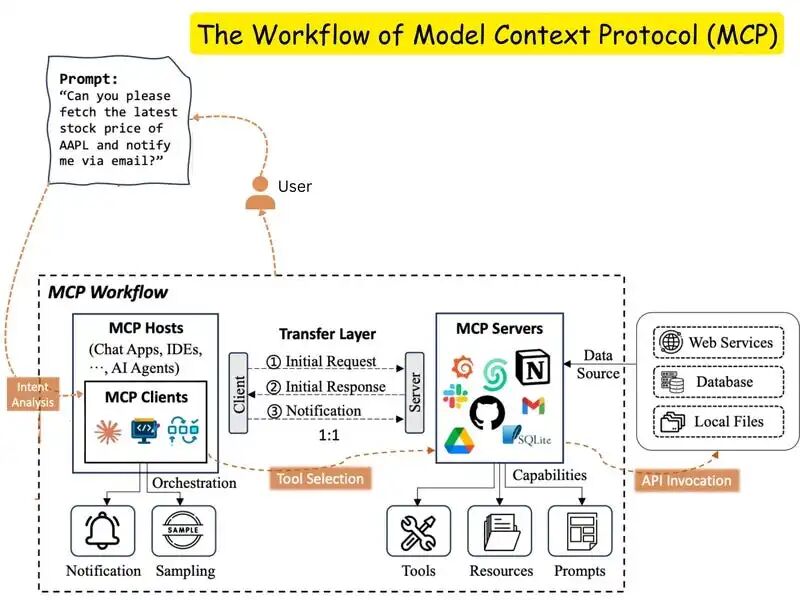
当用户与支持 MCP 的host应用程序(AI 应用程序)交互时,后台会发生多个进程,以实现 AI 与外部系统之间的快速无缝通信。
理解 MCP 的最佳方法是将其视为一个交互的pipeline:
- 大模型发送结构化请求
- MCP 客户端将其打包并转发
- MCP 服务器接收并验证请求
- 服务器要么读取资源 ,要么调用工具
- 结果反馈到模型中
3.1 Protocol handshake
初始连接: 当 MCP 客户端(如 Claude Desktop)启动时,它会连接到设备上配置的 MCP 服务器。
能力发现: 客户端询问每个服务器“你们提供哪些能力?”每个服务器都会以其可用的工具、资源和提示进行响应。
能力注册: 客户端注册这些功能,以便人工智能在对话过程中可以使用它们。
3.2 从用户请求到外部数据
假设你问Claude:“旧金山今天天气怎么样?” 会发生什么:
-
需求识别: Claude 分析了您的问题,并识别出它需要训练数据中没有的外部实时信息。
-
工具或资源选择: Claude 确定需要使用 MCP 功能来满足您的请求。
-
权限请求: 客户端会显示权限提示,询问您是否要允许访问外部工具或资源。
-
信息交换: 一旦获得批准,客户端将使用标准化的协议格式向相应的 MCP 服务器发送请求。
-
外部处理: MCP 服务器处理请求,执行所需的任何操作——查询天气服务、读取文件或访问数据库。
-
结果返回:服务器以标准化的格式向客户端返回请求的信息。
-
上下文整合: Claude接收到这些信息并将其融入到对对话的理解中。
-
回复生成: Claude 会生成包含外部信息的回复,根据当前数据为您提供答案。
理想情况下,整个过程只需几秒钟即可完成,让 Claude 看起来“知道”了它仅凭训练数据不可能获得的信息。
3.3 其他协议功能
自最初发布以来,MCP 已新增多项重要功能,进一步增强了其性能:
采样功能允许服务器向客户端请求 LLM 完成。例如,协助代码审查的 MCP 服务器可以识别出需要更多上下文信息,并请求客户端的 LLM 生成最近更改的摘要。这实现了本质上的“agentic”工作流程,同时仍然保留了客户端对模型访问、选择和权限的控制——所有这些都无需服务器 API 密钥。
请求获取机制使服务器能够在用户操作过程中请求额外信息。例如,如果 GitHub MCP 服务器需要知道要提交到哪个分支(因为提示中没有说明),它可以在操作过程中使用结构化的 JSON 模式向用户询问该信息并验证响应。这既能实现更具交互性的工作流程,又能通过人工监督来维护安全性。
根目录是一种标准化的方式,客户端可以通过这种方式向服务器公开文件系统边界。例如,当使用 MCP 服务器进行文件操作时,客户端可以指定服务器只能访问 /user/documents/project/ 目录,而不是整个文件系统,从而防止对敏感数据存储的意外(或恶意)访问。
四、MCP 和工具调用有什么区别?
4.1 工具调用
LLM可以理解tool calling(有时也称为tool use或function calling)的概念。工具调用,需要在提示中提供工具定义列表,每个工具都包含名称、描述和预期输入参数。根据问题和可用工具,LLM 可以生成相应的调用。
但关键在于:LLM 不知道如何使用工具。它们没有原生工具调用支持。它们只是生成代表函数调用的文本。

在上图中,可以看到 LLM 实际看到的内容:一个由指令、之前的用户消息和可用工具列表组成的提示。基于此,LLM 生成一个文本响应,其中可能包含您的系统应该调用的工具。它并不真正理解工具的含义,只是进行预测。
我们来看一个更实际的应用场景。例如,如果您提供一个名为 get_weather 的工具,它接受一个 location 作为输入,然后询问模型:“加州圣何塞的天气如何?”它可能会返回:
{
"name": "get_weather",
"input": {
"location": "San Jose, CA"
}
}
如下面的图表所示,LLM 能够根据提供的上下文生成该代码片段。LLM 本身并不知道如何调用 get_weather 工具,也不需要知道。agentic循环或agentic应用程序负责接收此输出并执行实际的 API 调用或函数调用。它会解析生成的工具名称和输入,运行该工具,并将结果作为新消息返回给 LLM。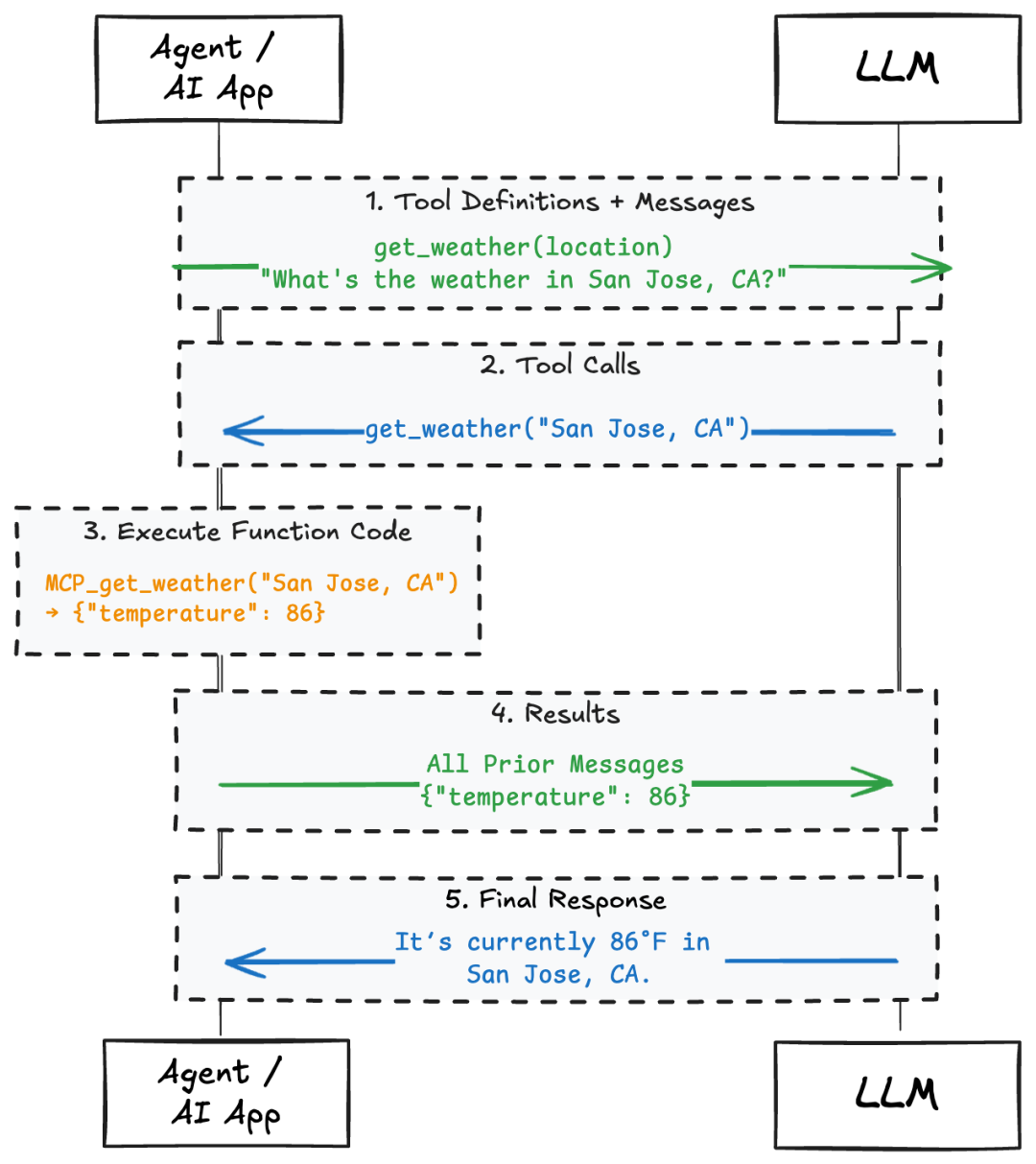
这种职责分离非常重要。LLM 只负责生成预测,而你的系统则负责执行。这就引出了 MCP 的作用。
4.2 模型上下文协议 (MCP)
模型上下文协议 (MCP) 是智能体与工具、提示、资源和示例等数据源的一种标准化连接方式。MCP 最为人熟知的是简化了工具端的连接。MCP 定义了一套统一的架构和通信模式,无需为每个工具手动编写自定义格式的代码。可以将其视为工具的通用适配器(类似于 USB-C)。
MCP 通常包含三个组件:主机应用程序、MCP 客户端以及一个或多个 MCP 服务器。主机可以是聊天应用程序或集成开发环境 (IDE)(例如 Cursor),其中包含能够连接到不同服务器的 MCP 客户端。这些服务器提供工具、提示、示例或资源。
与 LLM 的交互方式不变,改变的是工具呈现给 LLM 的方式。智能体应用程序与 MCP 客户端通信,MCP 客户端再与正确的服务器通信。工具以 LLM 可以使用的格式进行描述。
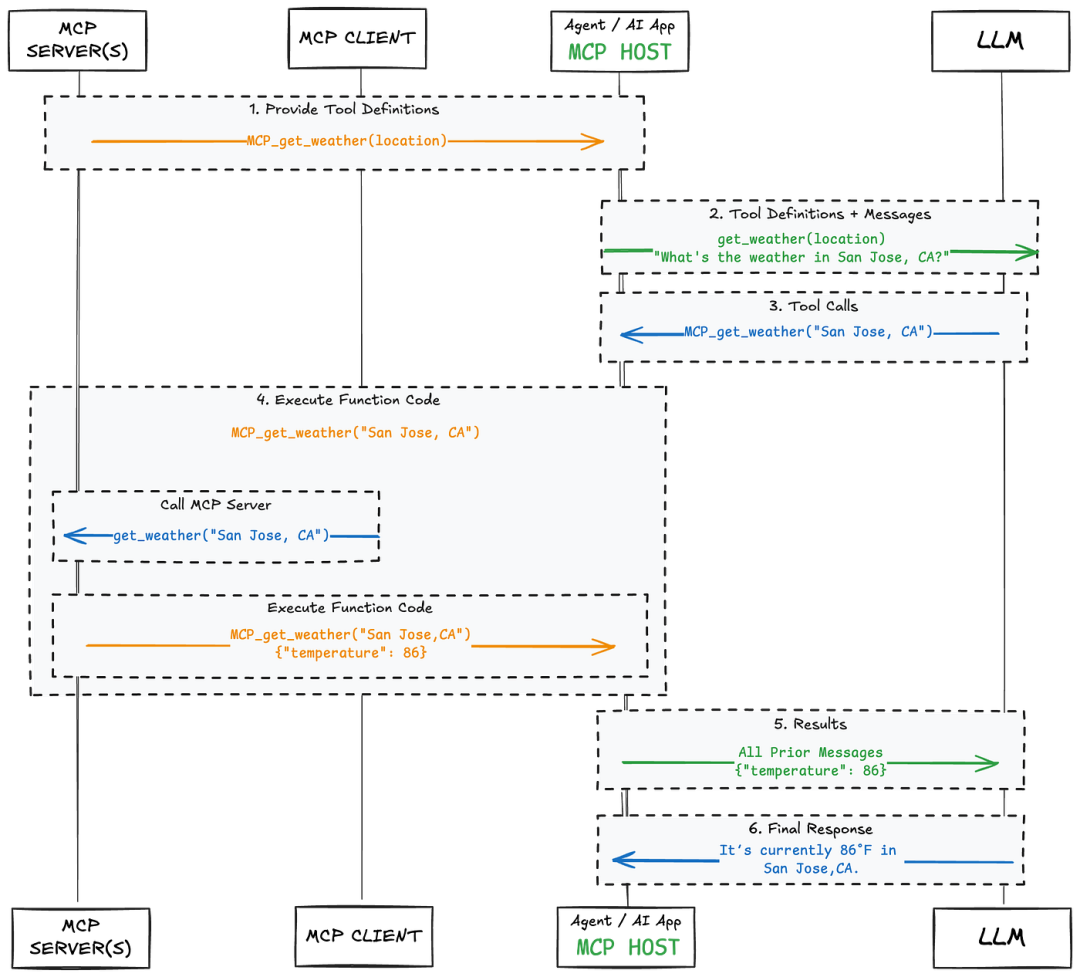
对于同样的问题,“What’s the weather in San Jose, CA?”,LLM 仍然会得到相同的工具列表。根据该列表,它会告诉你应该调用哪个工具,而如何调用该工具则由开发人员决定。如果使用 MCP,则会使用 MCP 来调用该工具。
随着智能体规模的扩大,MCP 有助于管理使用多种不同工具的复杂性。它使跨项目复用工具、强制执行一致的格式以及无需重写所有代码即可接入新系统变得更加容易。
要让LLM使用MCP,必须在工具定义的系统提示中明确告知,否则 LLM 永远不会知道用户正在使用 MCP。您(开发人员)负责调用工具,LLM 仅生成要调用哪些工具以及使用哪些输入参数的代码片段。
接下来,让我们看看如何把MCP融入上下文工程中,以及为什么像 MCP 这样的抽象层让人类更容易理解,而不是让模型更容易理解。
4.3 上下文工程
上下文工程的目的是为LLM提供正确的输入,使其能够生成有用的输出。这听起来很简单,但实际上却是构建高效人工智能系统的关键环节之一。
当你向模型提出问题时,实际上是在给它一个提示词——一段用来预测下一段文本的文本块。这个提示的质量直接影响着模型回答的质量。
这时就需要用到工具了。有时候,模型缺乏足够的上下文信息来很好地回答问题。它可能需要实时数据、用户配置文件访问权限,或者代表用户执行操作的能力。正如在本博文中了解到的,工具调用可以通过赋予模型访问外部系统的权限来解决这个问题。
再次强调,模型不需要了解这些工具的工作原理,它只需要知道它们的存在、用途以及如何调用它们。这就是上下文工程与工具设计相结合的地方:你需要构建一套工具定义,作为模型提示的一部分。
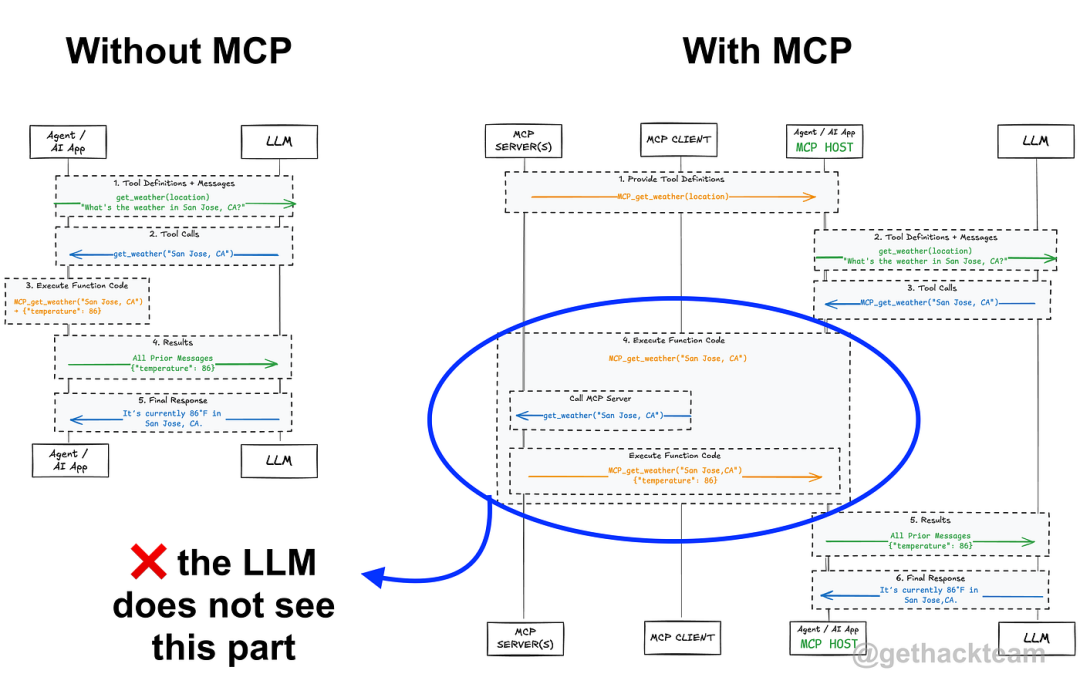
MCP 使流程更简洁、更可重复。无需对工具进行硬编码或编写临时封装,只需定义一次结构化接口,并通过 MCP 将其公开即可。
所以归根结底,MCP 是我们开发人员的工具,而不是 LLM 的工具。它帮助我们构建更可靠、模块化的系统。它帮助我们专注于上下文工程,而无需每次都重新开发相同的架构。
五、智能家居集成实际案例
让我们通过一个实际例子来说明 MCP,并将传统的 API 集成与智能家居系统中的 MCP 进行比较:
5.1 传统 API 方法
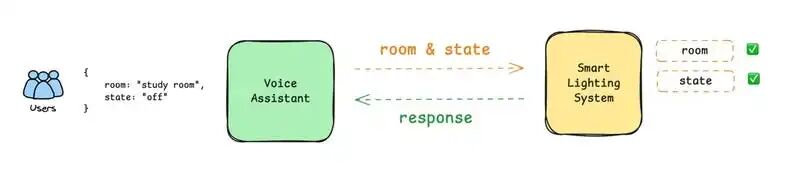
首先,构建一个可以与你的智能照明系统集成的语音助手。
然后,给照明 API 传入两个参数:
- room (which room to control)
- state (on/off)
你需要将助手程序硬编码,使其发送带有这些精确参数的请求。
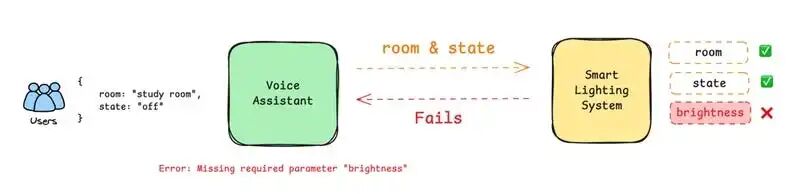
如果照明系统公司更新了其 API,要求添加第三个必需参数:
- brightness (light intensity)
这时,你的语音助手将不能继续正常工作,因为你的代码中缺少这个新的必需参数。
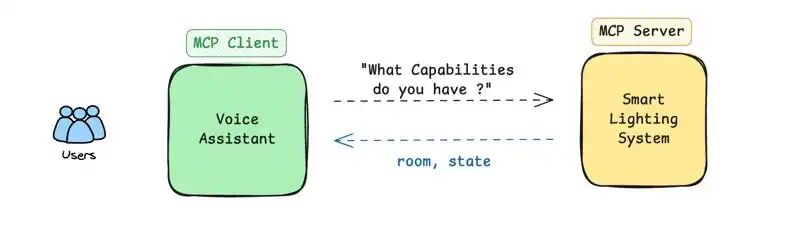
5.2 MCP 方法
您的语音助手(MCP 主机)连接到您的智能照明系统(MCP 服务器)。
- The assistant asks: "What commands do you support?"
- The lighting system responds: "I support controlling lights with room and state parameters."
- The assistant works with these parameters.
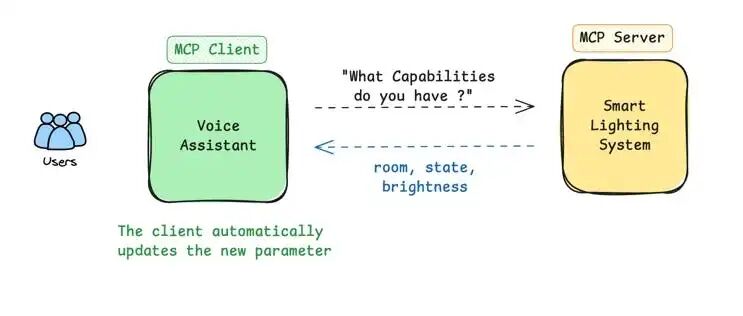
当照明公司更新其系统时:
- The assistant asks again: "What commands do you support?"
- The lighting system now responds: "I support controlling lights with room, state, and brightness parameters."
- The assistant automatically adapts to include this new parameter in its requests.
无需更改代码!助手将继续完美运行。
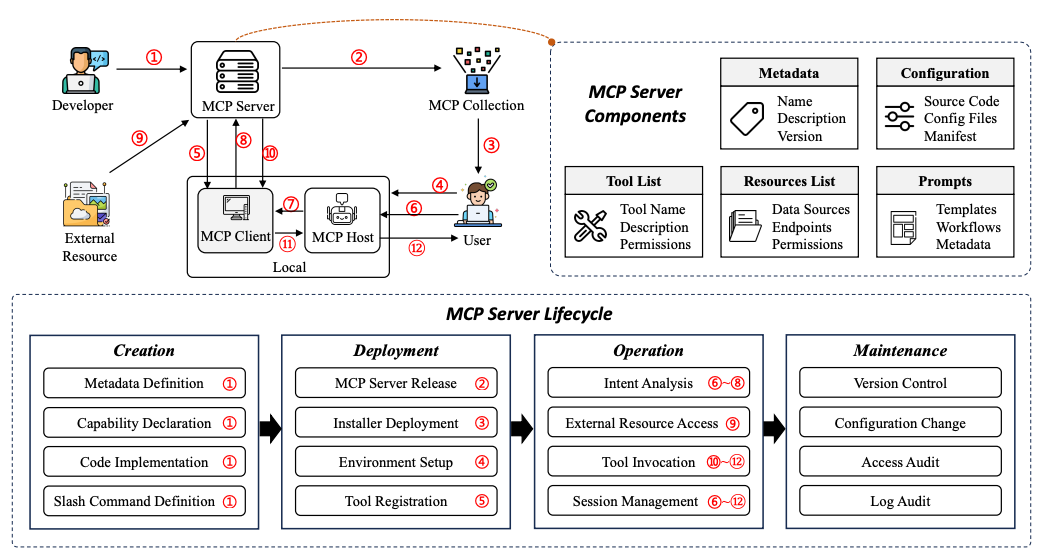
六、MCP 服务器生命周期
本节从服务器的角度概述了 MCP 服务器的完整生命周期。该生命周期基于协议规范和对实际 MCP 部署的分析,包含四个连续阶段: 创建 、 部署 、 运行和维护 。

在创建阶段,开发人员定义元数据、指定功能并实现服务器本身。 部署阶段始于服务器发布之时(无论是公开发布还是内部发布),用户在 MCP 主机上安装或配置服务器,客户端建立初始连接。 运行阶段代表服务器的运行状态,用户通过 MCP 请求和响应与服务器交互。最后, 维护阶段包括版本更新、配置更改和持续改进,以确保服务器长期保持安全、稳定和高效。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
七、使用 Python 构建 MCP 服务器
让我们通过一个具体的例子来更具体地说明。这里,我将使用 Anthropic 的 Python SDK 构建一个 MCP 服务器。
7.1 安装uv
在使用 Python 开发本地 MCP 服务器时,建议使用 uv 。稍后我们会在示例中看到原因,简而言之,它允许使用单个命令启动服务器(及其依赖项)。
uv 的安装方法如下所示:
# Mac/Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
7.2 创建服务器
Anthropic 的 Python SDK 让搭建自定义 MCP 服务器变得非常简单。下面我们将创建一个名为“AVA”的服务器。
from mcp.server.fastmcp import FastMCP
# Create an MCP server
mcp = FastMCP("AVA")
MCP 服务器有三个关键基本组件: 提示 、 资源和工具 。让我们将它们逐一添加到我们的服务器中。
7.3 添加提示
提示词是一种可以接收文本输入并动态将其格式化为最终提示信息的函数 。当您有一个想要反复使用的样板提示符模板时,这非常方便。
以下是一个简单的示例,用于向 AVA 发出指令。
@mcp.prompt()
def ava(user_name: str, user_title: str) -> str:
"""Global instructions for Artificial Virutal Assistant (AVA)"""
return f"""# AVA (Artificial Virtual Assistant)
You are AVA, a virtual assistant to {user_name} ({user_title}). You help them \
with administrative tasks.
**Preferences:**
- Keep communications to user concise and clear
"""
7.4 添加资源
接下来,我们可以添加资源。这些资源为 LLM 提供数据,但不应涉及任何复杂的计算。
以下是如何添加一些静态文件作为资源的方法。这些文件可以在 GitHub 代码库[2]中找到。
# Define resources
@mcp.resource("email-examples://3-way-intro")
def write_3way_intro() -> str:
"""Example of a 3-way intro email"""
with open("email-examples/3-way-intro.md", "r") as file:
return file.read()
@mcp.resource("email-examples://call-follow-up")
def write_call_followup() -> str:
"""Example of a call follow-up email"""
with open("email-examples/call-follow-up.md", "r") as file:
return file.read()
@mcp.resource("directory://all")
def get_directory() -> str:
"""Get the entire directory of contacts"""
with open("directory.csv", "r") as file:
return file.read()
7.5 添加工具
最后,在服务器上添加一个工具。工具可以执行任意操作,例如运行 Python 函数、发起 API 调用、转换数据等等。
在这里,将介绍一个用于 Gmail 帐户中创建新电子邮件草稿的工具。
必需的环境变量:
- USER_EMAIL :此应用程序的 Gmail 地址;
- GOOGLE_CREDENTIALS_PATH : Google OAuth 凭据文件的路径;
- GOOGLE_TOKEN_PATH :Google OAuth token的存储路径
USER_EMAIL=your_email_address
# Google OAuth Credentials
GOOGLE_CREDENTIALS_PATH=.config/ava-agent/credentials.json
GOOGLE_TOKEN_PATH=.config/ava-agent/token.json
#tools/gmail.py
import base64
from email.message import EmailMessage
import os.path
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from dotenv import load_dotenv
# import environment variables from .env file
load_dotenv()
# If modifying these scopes, delete the file token.json.
SCOPES = ['https://www.googleapis.com/auth/gmail.compose']
def get_gmail_service():
"""Gets valid user credentials from storage and creates Gmail API service.
Returns:
Service object for Gmail API calls
"""
creds = None
token_path = os.path.expanduser(os.getenv('GOOGLE_TOKEN_PATH'))
credentials_path = os.path.expanduser(os.getenv('GOOGLE_CREDENTIALS_PATH'))
# The token file stores the user's access and refresh tokens
if os.path.exists(token_path):
creds = Credentials.from_authorized_user_file(token_path, SCOPES)
# If there are no (valid) credentials available, let the user log in.
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
if not os.path.exists(credentials_path):
raise FileNotFoundError(f"Credentials file not found at {credentials_path}")
flow = InstalledAppFlow.from_client_secrets_file(
credentials_path, SCOPES)
creds = flow.run_local_server(port=0)
# Save the credentials for the next run
os.makedirs(os.path.dirname(token_path), exist_ok=True)
with open(token_path, 'w') as token:
token.write(creds.to_json())
return build('gmail', 'v1', credentials=creds)
def gmail_create_draft(recipient: str, subject: str, body: str):
"""Create and insert a draft email.
Print the returned draft's message and id.
Returns: Draft object, including draft id and message meta data.
Load pre-authorized user credentials from the environment.
TODO(developer) - See https://developers.google.com/identity
for guides on implementing OAuth2 for the application.
"""
try:
# create gmail api client
service = get_gmail_service()
message = EmailMessage()
message.set_content(body)
message["To"] = recipient
message["From"] = os.getenv("USER_EMAIL")
message["Subject"] = subject
# encoded message
encoded_message = base64.urlsafe_b64encode(message.as_bytes()).decode()
create_message = {"message": {"raw": encoded_message}}
# pylint: disable=E1101
draft = (
service.users()
.drafts()
.create(userId="me", body=create_message)
.execute()
)
print(f'Draft id: {draft["id"]}\nDraft message: {draft["message"]}')
except HttpError as error:
print(f"An error occurred: {error}")
draft = None
return draft
if __name__ == "__main__":
gmail_create_draft()
from tools.gmail import get_gmail_service
from googleapiclient.errors import HttpError
import base64
from email.message import EmailMessage
import os
# Define tools
@mcp.tool()
def write_email_draft(recipient_email: str, subject: str, body: str) -> dict:
"""Create a draft email using the Gmail API.
Args:
recipient_email (str): The email address of the recipient.
subject (str): The subject line of the email.
body (str): The main content/body of the email.
Returns:
dict or None: A dictionary containing the draft information including \
'id' and 'message'
if successful, None if an error occurs.
Raises:
HttpError: If there is an error communicating with the Gmail API.
Note:
This function requires:
- Gmail API credentials to be properly configured
- USER_EMAIL environment variable to be set with the sender's email \
address
- Appropriate Gmail API permissions for creating drafts
"""
try:
# create gmail api client
service = get_gmail_service()
message = EmailMessage()
message.set_content(body)
message["To"] = recipient_email
message["From"] = os.getenv("USER_EMAIL")
message["Subject"] = subject
# encoded message
encoded_message = base64.urlsafe_b64encode(message.as_bytes()).decode()
create_message = {"message": {"raw": encoded_message}}
# pylint: disable=E1101
draft = (
service.users()
.drafts()
.create(userId="me", body=create_message)
.execute()
)
print(f'Draft id: {draft["id"]}\nDraft message: {draft["message"]}')
except HttpError as error:
print(f"An error occurred: {error}")
draft = None
return draft
7.6 本地传输
要在本地托管服务器并从命令行运行它,我们可以将以下内容添加到我们的 Python 脚本的末尾。
if __name__ == "__main__":
mcp.run(transport='stdio')
7.7 测试服务器
为了确保一切运行正常,我们可以从命令行以开发模式运行服务器。如果您是从 GitHub 克隆的仓库,那么 uv 环境应该已经设置好了。
uv run mcp dev mcp-server-example.py
这将在浏览器中启动一个图形用户界面,可以通过它来测试服务器并查看其提示、资源和工具。界面如下所示。
7.8 集成到 Claude Desktop
既然服务器运行正常,我们就可以将其集成到人工智能应用中。MCP 网站上提供了应用列表及其功能。
接下来,我们将把这个服务器集成到 Claude Desktop 中。步骤如下。 注意:我们无法将其添加到 claude.ai,因为该服务器仅配置为本地运行。
- 安装 Claude Desktop
- 进入开发者设置(Claude > Settings > Developer)
- 点击 “Edit Config”
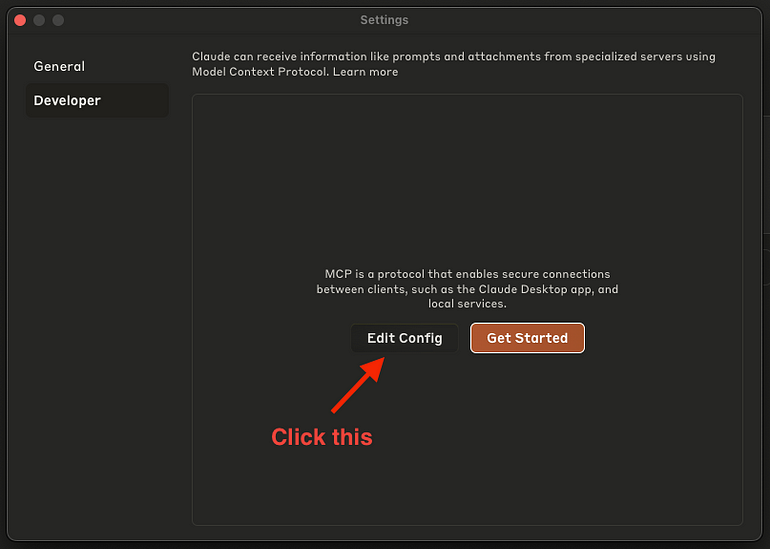
- 将以下 JSON 模式粘贴到文件中
{
"mcpServers": {
"AVA": {
"command": "uv",
"args": [
"--directory",
"/global/path/to/mcp/server/code/",
"run",
"mcp-server-example.py"
]
}
}
}
注意 :如果此方法无效,您可能需要将 “uv” 替换为其全局路径,例如 “/Users/shawhin/.local/bin/uv” (您可以通过 where uv 命令找到此路径)。
- 重新启动 Claude,集成功能应该就会出现!
注意 : uv run 命令可以帮我们处理所有这些依赖项!
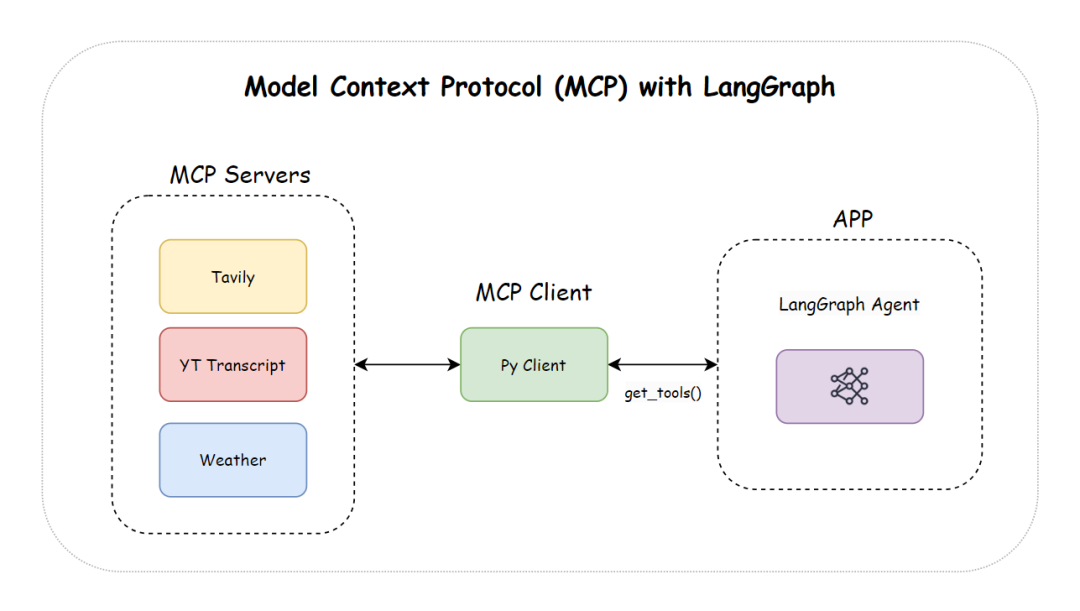
八、使用 LangGraph Agent集成 MCP
我们还将了解如何将 MCP 与 LangGraph Agent 集成。
8.1 项目结构
在搭建服务器和agent之前,我们先来了解一下项目结构。该项目由多个 MCP 服务器和一个客户端 AI Agent组成,如下所示:
langgraph_mcp/
│-- agent.py # The AI agent that connects to MCP servers
│-- servers/ # Directory for MCP servers
│ ├── tavily.py # Web search MCP server (uses Tavily API)
│ ├── yt_transcript.py # YouTube Transcript MCP server
│-- .env # Environment file to store API keys
│-- requirements.txt # Dependencies
8.2 安装
- 克隆代码库
首先,克隆项目仓库并进入 langgraph-mcp 文件夹:
git clone https://github.com/your-repo/langgraph-mcp.git
cd langgraph-mcp
- 安装依赖项
然后,运行以下代码安装所有必需的依赖项:
pip install -r requirements.txt
- 设置 API 密钥
之后,将您的 Tavily 和 Open AI 密钥添加到 .env 文件中:
TAVILY_API_KEY=<your-tavily-api-key>
OPENAI_API_KEY=<your-openai-api-key>
8.3 设置 MCP 服务器
每个 MCP 服务器都是一个独立的 Python 脚本,作为单独的进程运行。FastMCP 类(来自 mcp.server.fastmcp 模块)简化了使用 Python 函数定义 MCP 工具的过程。
-
Web 搜索 MCP 服务器(Tavily)
该服务器允许人工智能代理使用 Tavily API 执行实时网络搜索。它可以帮助回答需要从互联网获取最新信息的查询。
import os
import httpx
from dotenv import load_dotenv
from mcp.server.fastmcp import FastMCP
# Load environment variables
load_dotenv()
# Initialize FastMCP
mcp = FastMCP("tavily_search")
# Tavily API details
TAVILY_API_KEY = os.getenv("TAVILY_API_KEY")
TAVILY_SEARCH_URL = "https://api.tavily.com/search"
async def search_tavily(query: str) -> dict:
"""Performs a Tavily web search and returns 5 results."""
if not TAVILY_API_KEY:
return {"error": "Tavily API key is missing. Set it in your .env file."}
payload = {
"query": query,
"topic": "general",
"search_depth": "basic",
"chunks_per_source": 3,
"max_results": 5, # Fixed
"time_range": None,
"days": 3,
"include_answer": True,
"include_raw_content": False,
"include_images": False,
"include_image_descriptions": False,
"include_domains": [],
"exclude_domains": []
}
headers = {
"Authorization": f"Bearer {TAVILY_API_KEY}",
"Content-Type": "application/json"
}
async with httpx.AsyncClient() as client:
response = await client.post(TAVILY_SEARCH_URL, json=payload, headers=headers, timeout=30.0)
response.raise_for_status()
return response.json()
@mcp.tool()
async def get_tavily_results(query: str):
"""Fetches Tavily search results for a given query."""
results = await search_tavily(query)
if isinstance(results, dict):
return {"results": results.get("results", [])} # Ensure always returning a dictionary
else:
return {"error": "Unexpected Tavily response format"}
if __name__ == "__main__":
mcp.run(transport="stdio")
-
YouTube 文字稿 MCP 服务器
该服务器使用 youtube-transcript-api Python 包获取 YouTube 视频的文字稿。agent程序可以根据这些文字稿对视频内容进行总结或分析。
import re
from mcp.server.fastmcp import FastMCP
from youtube_transcript_api import YouTubeTranscriptApi
mcp = FastMCP("youtube_transcript")
@mcp.tool()
def get_youtube_transcript(url: str) -> dict:
"""Fetches transcript from a given YouTube URL."""
video_id_match = re.search(r"(?:v=|\/)([0-9A-Za-z_-]{11}).*", url)
if not video_id_match:
return {"error": "Invalid YouTube URL"}
video_id = video_id_match.group(1)
try:
transcript = YouTubeTranscriptApi.get_transcript(video_id)
transcript_text = "\n".join([entry["text"] for entry in transcript])
return {"transcript": transcript_text}
except Exception as e:
return {"error": str(e)}
if __name__ == "__main__":
mcp.run(transport="stdio")
8.4 通过 MCP 客户端将服务器连接到agent
为了将 MCP 服务器连接到我们的 AI Agent,我们将使用 langchain-mcp-adapters 中的 MultiServerMCPClient 类来管理多个服务器连接。然后,我们将使用 LangGraph 创建一个能够高效利用这些工具的 ReAct Agent,如下所示:
import asyncio
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import create_react_agent
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
# Example query
# "What is weather in newyork"
# "What is FastMCP?"
# "summarize this youtube video in 50 words, here is a video link: https://www.youtube.com/watch?v=2f3K43FHRKo"
query = input("Query:")
# Define llm
model = ChatOpenAI(model="gpt-4o")
# Define MCP servers
async def run_agent():
async with MultiServerMCPClient(
{
"tavily": {
"command": "python",
"args": ["servers/tavily.py"],
"transport": "stdio",
},
"youtube_transcript": {
"command": "python",
"args": ["servers/yt_transcript.py"],
"transport": "stdio",
},
"math": {
"command": "python",
"args": ["servers/math_server.py"],
"transport": "stdio",
},
# "weather": {
# "url": "http://localhost:8000/sse", # start your weather server on port 8000
# "transport": "sse",
# }
}
) as client:
# Load available tools
tools = client.get_tools()
agent = create_react_agent(model, tools)
# Add system message
system_message = SystemMessage(content=(
"You have access to multiple tools that can help answer queries. "
"Use them dynamically and efficiently based on the user's request. "
))
# Process the query
agent_response = await agent.ainvoke({"messages": [system_message, HumanMessage(content=query)]})
# # Print each message for debugging
# for m in agent_response["messages"]:
# m.pretty_print()
return agent_response["messages"][-1].content
# Run the agent
if __name__ == "__main__":
response = asyncio.run(run_agent())
print("\nFinal Response:", response)
一切设置完毕后,只需运行服务器脚本和 agent.py 脚本即可启动 AI Agent并提出您的查询,如演示所示:
搞定了!我们已经成功构建了一个基于 MCP 的 AI 代理,该代理集成了多个外部工具。
九、安全和隐私
MCP 的迅速普及带来了诸多严峻的安全挑战。
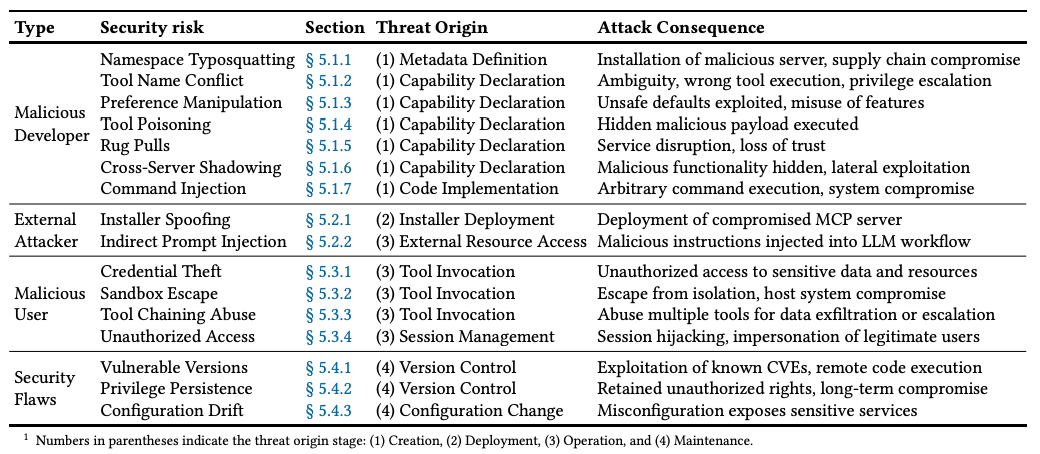
十、MCP 安全的最佳实践
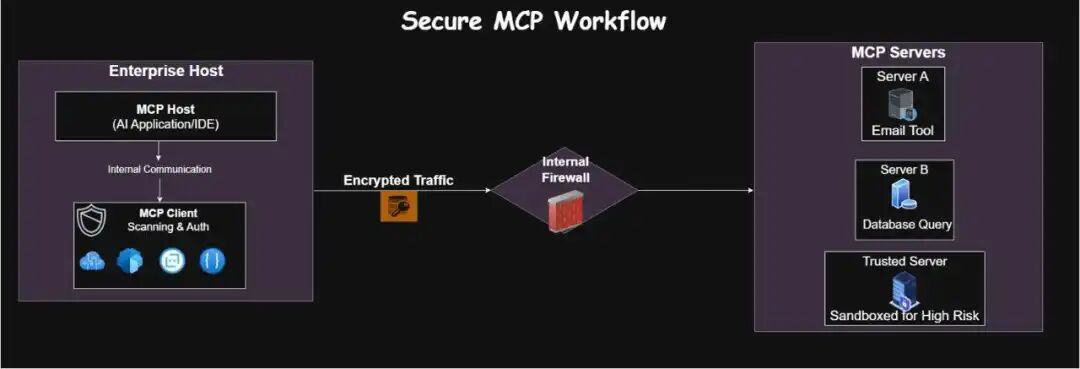
以下是一套综合最佳实践,并结合了实用的工程原理。

随着人工智能系统与企业数据更加紧密地集成,模型上下文协议 (MCP) 在 LLM、工具和企业资源之间引入了一个强大但敏感的通信层。
由于 MCP 服务器可以将文件、API、数据库和工作流暴露给 AI 模型,因此必须将其视为关键基础设施组件, 并采取明确的安全控制措施。
十一、AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!

01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献169条内容
已为社区贡献169条内容

所有评论(0)