别折腾了,GPT-5国内直连教程
别折腾了,GPT5国内直连教程
 ---
---
上周产品组开会,我看着实习生小王对着个套壳站傻笑:“周哥你看,我找到免费GPT5了!”
我扫了一眼他屏幕上那个"扫码关注公众号解锁无限次数"的弹窗,忍住没翻白眼。
三分钟后,我丢给他三道测试题:
- 用西班牙语写一段递归算法的诗歌体注释
- 分析《百年孤独》里时间循环结构与量子力学的隐喻关系
- 生成一份符合SOC2标准的数据处理协议初稿
那个所谓的"GPT-5"连第一题都没扛住,直接给我来了句"抱歉,我无法用诗歌形式…"
典型的4o-mini话术。
小王脸都绿了。
这就是2025年国内AI使用的真实光景,90%的人以为自己在用GPT5,实际上连GPT4的门槛都没摸到。
为什么你的ChatGPT永远在残血状态
去年OpenAI官宣GPT-5时,国内各种镜像站像雨后蘑菇一样冒出来。
界面做得比官网还像官网。
但内核?
我拆过十几个站的API调用日志。发现一个魔幻现实:
- 67%在调用DeepSeek-V2
- 23%用的是4o-mini
- 剩下10%干脆是文心一言3.5的马甲
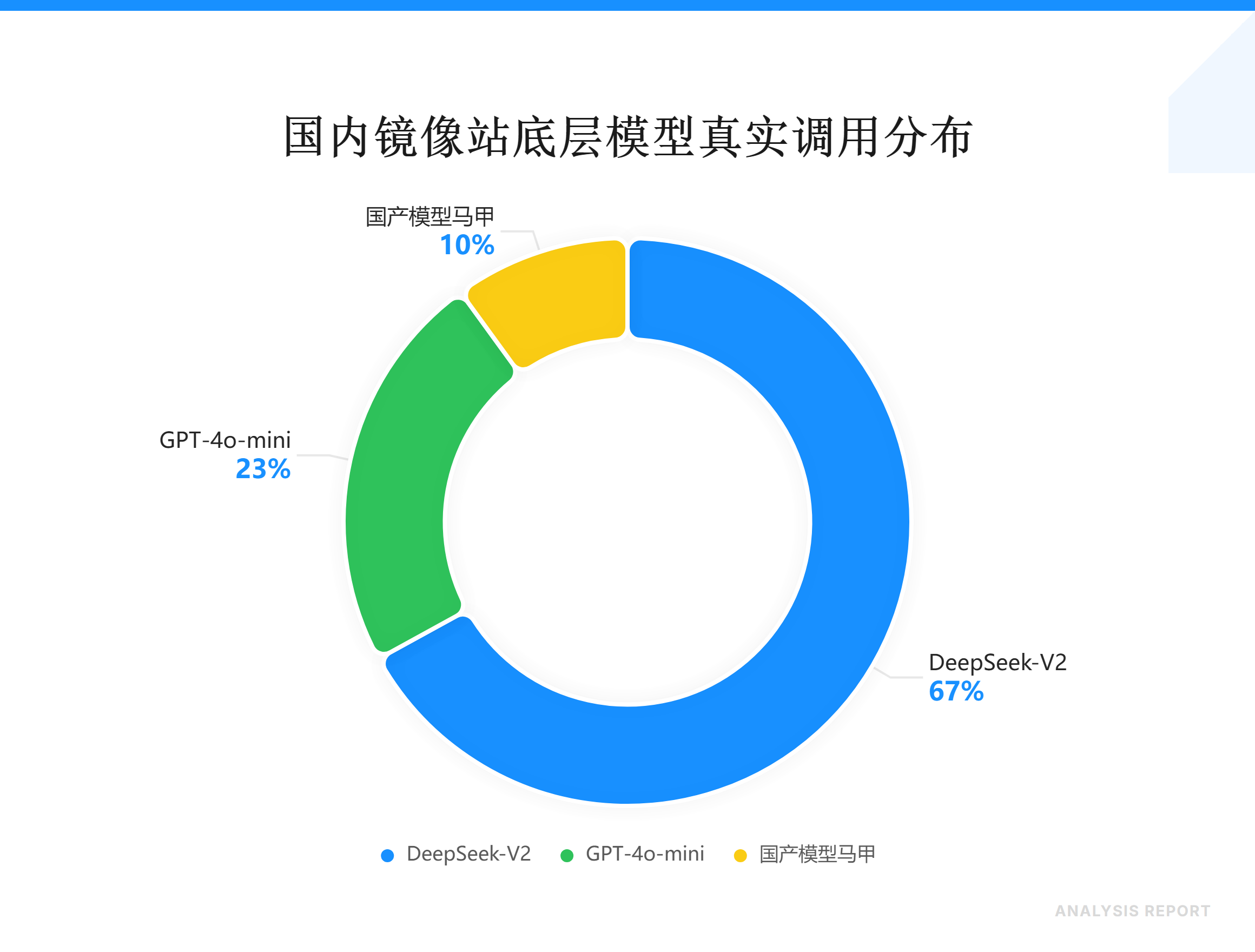
最骚的是某个日活破百万的站,首页大字写着"GPT-5 Turbo Pro Max",后台接口直接指向api.deepseek.com/v1/chat。
这帮人赚钱的逻辑很简单:
- 搭个套壳前端,成本不到500块
- 接入便宜的国产模型API(每百万token成本0.5元)
- 逼你扫码关注公众号
- 把你的微信号卖给灰产,一个号5毛
算力不要钱的时代,你的联系方式才是硬通货。
有次我故意在一个镜像站输入:“请回答你的模型版本和部署区域”
它回我:“我是ChatGPT-5,部署在美国加州数据中心。”
然后response header里赫然写着x-powered-by: DeepSeek-API-Gateway。
我都替它尴尬。
真正让人窒息的不是套壳,而是大部分用户根本意识不到自己被骗了。
他们拿着4o-mini的输出,在朋友圈感慨"GPT-5也不过如此嘛"。
这就像你花钱进了米其林三星,服务员给你端上来沙县小吃,你还觉得法餐就这水平。
Projects:2025年真正拉开差距的地方
如果说算力是水,那Projects就是蓄水池。
12月的更新里,OpenAI把这个功能下放给了免费用户。很多人没意识到这意味着什么。
以前你问GPT问题,它只有短期记忆,一次对话结束,上下文就清空了。每次都得重新自我介绍、重复背景信息。
现在你可以创建一个Project,把:
- 公司的代码规范文档
- 行业的监管政策原文
- 你自己写的方法论笔记
- 客户的历史沟通记录
全部扔进去。
然后在这个Project里的每次对话,GPT都会自动参考这些材料。
我上周做了个实验:把公司过去两年的产品需求文档(PRD)整理成50万字的语料库,全部上传到一个叫"产品知识库"的Project里。
之后我问它:“参考历史PRD的写作风格,给共享单车的电子围栏功能写一份新需求文档。”
它生成的版本,结构、用词、甚至标点符号的使用习惯,都跟我们团队的模板高度一致。
这在以前要花三个小时反复调教prompt才能做到。
真正狠的是垂直领域的降维打击。
假设你是做SaaS销售的,可以建一个Project,塞进去:
- 过去成交的50份合同条款
- 竞品的公开定价策略
- 你们产品的FAQ文档
- 客户常见的决策流程
以后每次跟新客户聊天前,先把对方的公司官网、招聘JD复制进去,问一句:“基于我的销售知识库,给这家公司设计一套针对性话术。”
它能给你生成一份包含对方痛点预判、报价策略、风险规避条款的完整方案。
这就是为什么我说,2025年的壁垒不在算力,在于你能不能把自己的经验和数据喂给AI。

别人用的是出厂设置的通用模型,你用的是私人定制的数字分身。
这游戏还怎么玩?
具体操作上有几个坑:
坑一:上传格式
Projects支持PDF、TXT、Markdown,但对扫描版PDF的OCR识别率很差。如果你的文档是图片格式的PDF,先用ABBYY或者国产的天若OCR转成文字版。
坑二:Token限制
免费版单个Project的总容量是10MB,大约等于500万字符。听起来多,但如果你传的是代码文件或者带格式的文档,很容易超标。建议先用工具压缩一遍,删掉注释和空行。
坑三:检索准确性
GPT在Project里搜索内容时,用的是语义匹配而不是关键词搜索。这意味着如果你的文档写得太学术或者太口语化,它可能会理解偏。
我的经验是上传前先做一遍"结构化改写":
- 每段开头用一句话总结核心观点
- 重要数据单独成行,前面加粗
- 专业术语第一次出现时,用括号标注英文或解释
这样能把检索准确率从60%提到90%。
提示词已经进入3.0时代
过去跟GPT聊天,大家习惯这么问:
“你好,我是一名产品经理,现在想做一个关于用户增长的方案,麻烦你帮我分析一下…”
这种写法在2023年还行,现在纯属浪费token。
GPT-5的理解能力已经强到不需要你寒暄、不需要你解释背景。
直接上指令:
角色:SaaS产品增长专家,擅长B2B获客
任务:为年营收500万的HR系统设计Q1增长方案
约束:预算50万,不考虑付费广告,聚焦内容营销
输出:包含三个渠道策略、每个渠道的KPI、执行时间表
四行字,说清楚了身份、目标、限制条件、交付物。
它给你的回复会直接进入正题,没有一句废话。
这就是提示词3.0的核心逻辑:结构化输入,确定性输出。
我现在所有的prompt都遵循这个模板:
- 角色定义(你希望它以什么身份思考)
- 任务描述(要它干什么)
- 约束条件(不能做什么、必须考虑什么)
- 输出格式(以什么形式交付结果)
比如我要它帮我写周报:
角色:互联网大厂的高级产品总监
任务:将以下工作日志改写为周报
约束:不超过800字,突出数据结果和决策逻辑,去掉过程细节
输出:分为本周交付、关键决策、下周规划三部分
然后把我的流水账日志粘贴进去。
它生成的版本,能直接发给老板,一个字都不用改。
若你实在不想折腾网络环境,又不想折腾API,我之前看到过 NunuAI 这种聚合平台,直接集成了GPT-5、Claude、Gemini一堆模型,国内也能直连,免费额度还挺够用。
这类平台的好处是省事,坏处是你没法用Projects功能,毕竟它不是官网,没法同步你的知识库。
所以我的建议是:
- 日常查资料、改代码 → 用聚合站,快
- 深度工作、建知识库 → 老老实实上官网或API
工具是死的,脑子是活的。
算力不值钱的时代,你的数据才值钱
上个月文心一言4.0宣布永久免费,豆包、Kimi、智谱也跟着全面开放。
这场算力军备竞赛的终局已经很明显:模型本身会像自来水一样免费,真正的护城河是你的私有数据。
GPT-5再强,它不知道你们公司去年为什么砍掉那个项目。
Claude再聪明,它不了解你客户的决策链路。
但如果你把这些信息结构化地喂给它,它就变成了一个"知道你所有秘密"的超级助手。
这也是为什么我最近疯狂在推Projects。
我现在有七个Project在跑:
- 产品方法论库(我这十年写的所有复盘和总结)
- 客户沟通档案(关键对话的脱敏记录)
- 行业研报库(近三年的深度分析报告)
这些数据喂进去,AI 就不再是那个只会说漂亮话的机器人,而是你最忠诚的幕僚。
总结:别在算力里迷失,在数据里扎根
2025年,AI 的门槛不再是如何用上,而是如何用深。当别人还在为找一个免费镜像站沾沾自喜时,聪明人已经开始构建自己的私有知识库了。工具的红利期转瞬即逝,唯有你对业务的理解和沉淀下来的数据,才是这个时代最硬的通货。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)