全景图单目尺度深度估计基座模型
影石Insta360联合多所高校推出全景深度估计基础模型DAP,通过构建200万张全景图数据集和渐进式三阶段训练方法,有效解决了数据稀缺和泛化难题。该模型采用DINOv3-Large作为骨干网络,结合几何感知优化策略,在多个基准测试中展现出优异的零样本性能。DAP不仅能精准处理真实拍摄的全景图像,对AIGC生成的艺术风格图像也表现出良好适应性,为全景深度估计提供了新的研究思路和实践路径。相关代码和

最近,来自 影石Insta360、加利福尼亚大学圣迭戈分校、武汉大学 和 加利福尼亚大学默塞德分校 的研究者们联手,推出了一篇名为 《Depth Any Panoramas: A Foundation Model for Panoramic Depth Estimation》 的重磅论文,提出了一个名为 DAP 的全景图深度估计基础模型。该模型在实验中表现出良好的性能,更重要的是,它为应对该领域中的核心问题提供了一种新的研究思路。
-
论文标题: Depth Any Panoramas: A Foundation Model for Panoramic Depth Estimation
-
机构:影石Insta360;加利福尼亚大学圣迭戈分校;武汉大学;加利福尼亚大学默塞德分校
-
Demo: https://huggingface.co/spaces/Insta360-Research/DAP
-
代码仓库(已开源): https://github.com/Insta360-Research-Team/DAP
-
项目主页: https://insta360-research-team.github.io/DAP_website/
-
论文地址: https://arxiv.org/abs/2512.16913
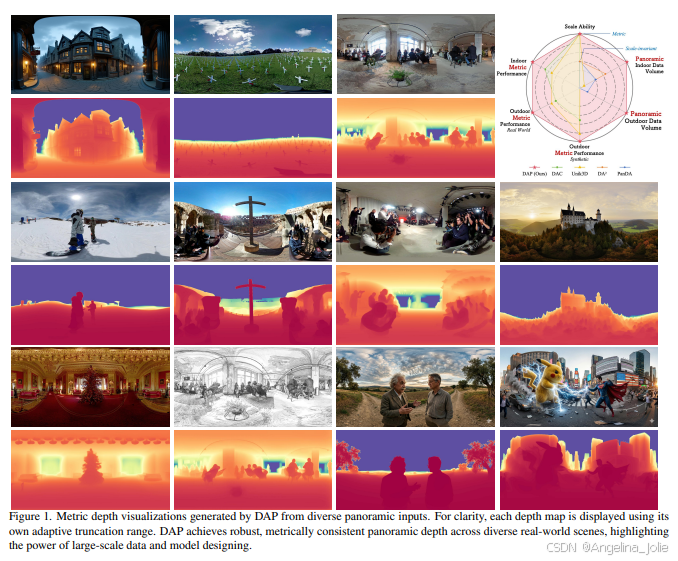
全景深度估计:机遇与挑战
深度估计,就是计算出图像中每个像素点到相机的距离。这个任务一旦切换到360°全景图,难度便指数级上升。
首先,全景图(通常是等距柱状投影,ERP格式)存在严重的几何畸变,越靠近两极区域,物体被拉伸得越厉害,这给卷积神经网络带来了巨大挑战。其次,全景图的视场极广,一个画面里可能既有近在咫尺的桌面,又有远在天边的山峦,距离跨度极大。
更核心的痛点在于数据。深度学习是数据驱动的,但获取带有精确深度标签的大规模、多样化的全景数据集极其困难。因此,以往的方法大多局限于特定场景(如纯室内),或者依赖合成数据,导致模型的泛化能力很差,换个环境就“水土不服”。
DAP的“数据飞轮”:用数据驱动解决数据难题
从方法论角度看,DAP 的有效性与其数据构建与使用方式密切相关。
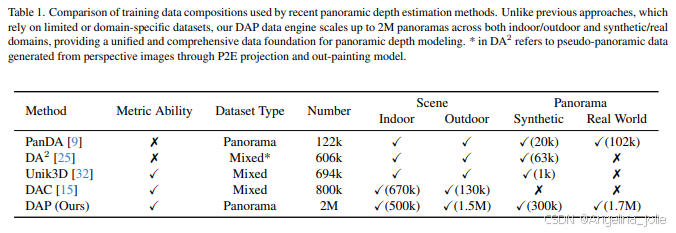
研究者们构建了一个包含约 200万 张全景图的庞大数据集,在规模上较以往相关研究有明显扩展。这个数据集的构成:
-
高质量合成数据:利用UE5模拟器(Airsim360)生成了超过9万帧带有精确深度标签的室外场景图像,并结合了Structured3D等高质量室内合成数据。
-
海量真实世界数据:从网络上收集了 170万 张真实的、无标签的全景图像,并利用文生图模型额外生成了20万张室内图像,覆盖各种各样的复杂场景。
面对海量的无标签真实图像,如何获取训练所需的深度信息?这引出了DAP的第二个核心创新:一个渐进式的三阶段伪标签生成流程。
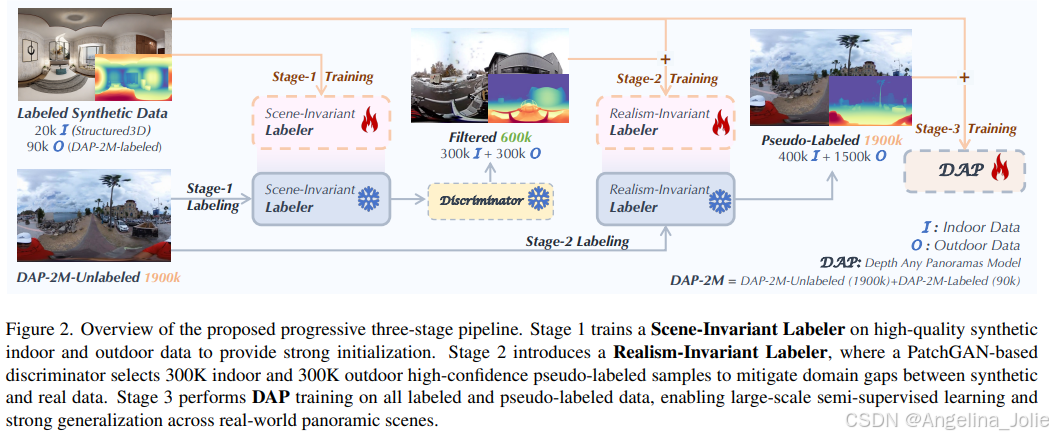
渐进式三阶段流程:从合成到真实的优雅跨越
研究者们设计了一套聪明的“学生-教师”模型流程,让模型分三步走,逐步从合成数据过渡到真实世界,自己为自己生产高质量的“精神食粮”(伪标签)。
-
阶段一:训练场景不变的标签器 (Scene-Invariant Labeler)首先,在高质量的合成数据(室内+室外)上训练一个初始模型。这个模型的任务是学习通用的、不受场景布局或光照影响的物理深度线索,为后续步骤打下坚实基础。
-
阶段二:训练现实主义不变的标签器 (Realism-Invariant Labeler)接下来,用阶段一的模型为一部分真实图像生成伪深度标签。同时,引入一个基于PatchGAN的判别器来判断这些伪标签的“真实度”,筛选出置信度最高的约60万张(室内外各30万)样本,用它们来进一步“微调”模型。这一步的核心是弥合合成数据与真实数据之间的“域差距”(Domain Gap),让模型适应真实世界的光影和纹理。
-
阶段三:DAP最终训练最后,将所有带标签的数据(真实的和高质量的伪标签数据)混合在一起,进行大规模的半监督学习,训练出最终的DAP模型。通过这个流程,DAP有效地利用了海量无标签数据,极大地提升了泛化能力。
DAP模型架构:DINOv3为骨,几何感知为魂
DAP 的架构体现了对任务特点的系统性建模:
-
视觉骨干:采用了强大的 DINOv3-Large 作为编码器。DINOv3系列因其卓越的预训练泛化能力而闻名,能为模型提供高质量的视觉特征。
-
解码器与优化:解码器部分不仅考虑了ERP畸变,还在优化目标上“多管齐下”。它同时关注深度值的准确性(LSILog损失)、边缘的清晰度(LDF和Lgrad损失)以及三维几何的一致性(Lnormal和Lpts损失)。这种“锐度为中心”和“几何为中心”的联合优化,确保了生成的深度图既有清晰的轮廓,又有平滑、合理的曲面。
-
即插即用的范围掩码头 (Range Mask Head):针对全景图距离跨度大的问题,DAP引入了一个可插拔的模块,可以根据场景(如室内近景或室外远景)选择不同的距离阈值,可以有效处理室外场景的天空部分。
核心损失函数解析
DAP的优化策略可以分为“锐度为中心”和“几何为中心”两个方面。
锐度为中心的优化 (Sharpness-centric Optimization)

几何为中心的优化 (Geometry-centric optimization)
为了保证预测出的三维空间是合理、连续的,模型还引入了两种几何约束:

总体优化目标

实验效果:零样本条件下的室内外数据集评估结果,真实开放世界表现优异
跨基准数据集的性能表现
DAP 在零样本设置下展示了优异的泛化能力。研究者在三个主流基准数据集(Stanford2D3D、Matterport3D、Deep360)上对模型进行了评估,在不进行任何额外微调的情况下,直接使用训练完成的模型进行测试。
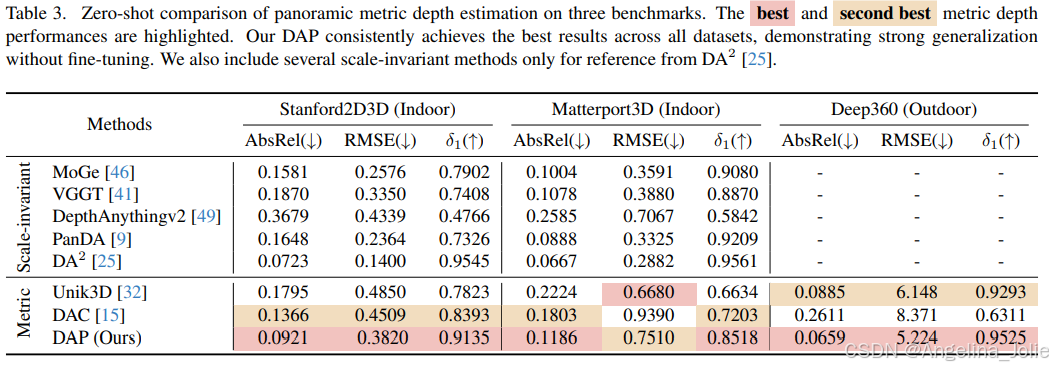
结果显示,DAP在多个数据集上都均取得了具有竞争力的表现,表明该方法强大的泛化能力。
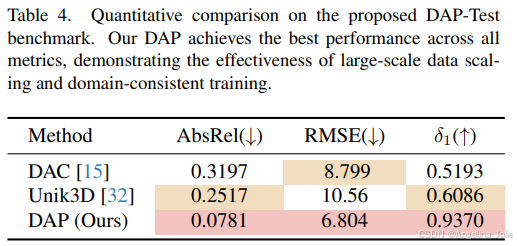
在团队自己构建的更高质量的室外测试集DAP-Test上,DAP相比现有方法表现出更为稳定的性能,在多项误差指标上取得了进一步降低。
清晰合理的视觉观感
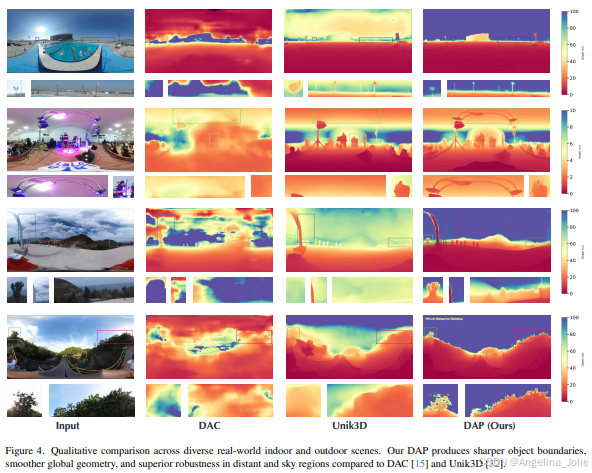
从上图可以看出,无论是在室内还是室外,相较于之前的方法(如DAC和Unik3D),DAP生成的深度图在物体边缘上更清晰,在平面(如墙壁和地面)上更平滑,并且对于远处物体和天空区域的处理也更稳定、更真实。

在上面这张对比图里,DAP对精细结构(如家具边缘)的保留和对整体尺度感的把握都明显更胜一筹,生成的深度图看起来非常接近真实情况(Ground Truth)。
风格变化也游刃有余
同时研究团队称DAP对全景图风格不设限:DAP 的强大不仅仅在于“看地多”,更在于“悟得深”。
全风格覆盖:无论是真实拍摄的高动态影像,还是各种光影奇特的艺术风格图,模型都能精准提取几何特征。
AIGC 友好:模型对由 Gemini 或 DiT-360 等合成的全景图同样展现出了极佳的预测效果,生成的深度图边缘锐利、逻辑自洽,是空间 AIGC 链路中理想的几何基石。
除了静态图像,DAP 在处理全景视频流时同样展现出了极佳的预测效果,具备优秀的帧间一致性与稳定性 。
结论
总体来看,DAP 的贡献并不局限于性能指标的提升。其通过大规模数据构建、渐进式半监督学习以及具有良好泛化能力的模型架构,为探索跨场景、跨领域的视觉基础模型提供了一种具有参考价值的实践路径。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)