(0)YOLO项目目录构造分析(基于魔傀面具V11-12项目)
txt存放转换成YOLO数据集标签(格式txt)文件的地方;dataset文件夹是自己新建的文件夹(原始YOLO项目中,此文件夹应该在ultralytics/cfg/datasets路径);其同样包括了训练集文件夹(train)、验证集文件夹(val)、测试集文件夹(test);tasks.py:定义了使用神经网络完成的不同任务的流程,例如分类、检测或分割,所有的流程基本上都定义在这里,定义模型前
一、本文介绍
本篇文章主要介绍了YOLO项目文件夹内各个文件的功能作用,文章基于魔傀面具V11-12项目;文章对于后期YOLO模型改进具有重要作用,能够使大家快速了解项目的构造架构,避免对YOLO学习改进无从下手的局面;(声明:其实V8后YOLO项目目录构造大体相同,所以这篇文章适用于V8后的全系列项目目录,大家也不用纠结自己的项目版本)
大家看这篇文章的时候大致看一下有个印象就可以了,因为内容太多不可能都记住的。只需要记住加粗有颜色的就可以了。
二、项目目录构造分析
大家注意不同YOLO版本项目的项目目录内文件顺序可能不同,大家只需要记住文件的名称知道其对应功能作用就可以了。
魔傀面具V11-12项目目录
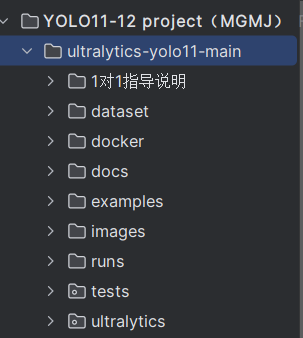
2.1 dataset(记住)
dataset文件夹是自己新建的文件夹(原始YOLO项目中,此文件夹应该在ultralytics/cfg/datasets路径);此文件夹就是放你自己数据集的地方;
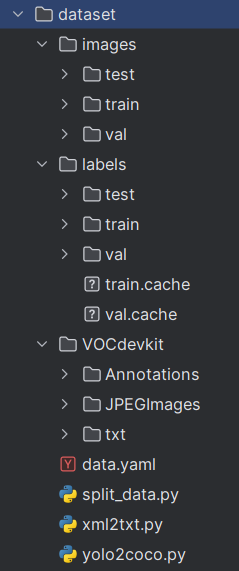
2.1.1 images
images就是放自己数据集图片的文件夹;其包括了训练集文件夹(train)、验证集文件夹(val)、测试集文件夹(test);
2.1.2 labels
images就是放自己数据集标注标签的文件夹;其同样包括了训练集文件夹(train)、验证集文件夹(val)、测试集文件夹(test);
train.cache、val.cache是 YOLO 为训练/验证集自动生成的 数据集缓存索引文件,用来加快后续训练时读取数据的速度,删了也没事,会自动重新生成。
2.1.3 VOCdevkit
VOCdevkit是进行VOC数据集转换YOLO数据集的功能性文件夹;Annotations存放VOC数据集标签文件(格式XML)的地方;JPEGImages存放VOC数据集图片的地方;txt存放转换成YOLO数据集标签(格式txt)文件的地方;(这个文件夹大家可以不用管)
2.1.4 同级目录下其他文件
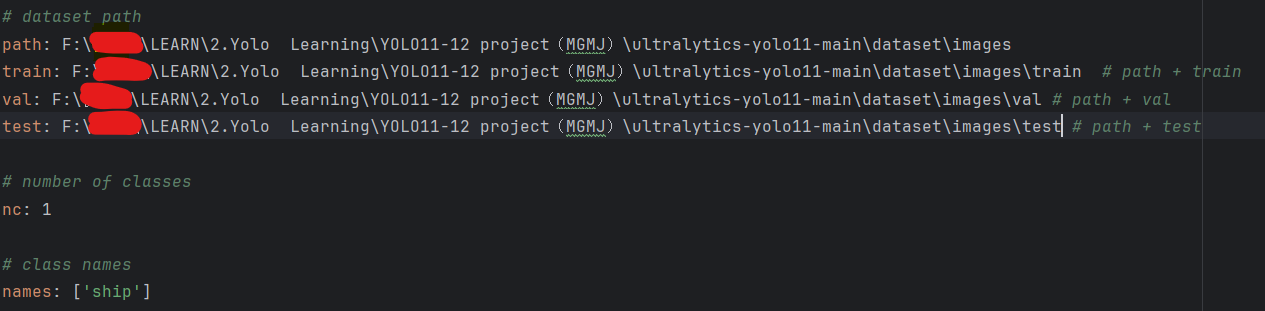
data.yaml数据集的配置文件,很重要的文件一定要记住;该文件告诉了模型训练、验证、测试时的数据集文件来源;
split_data.py用于将数据集划分训练集、验证集、测试集的文件;(大家在网上应该可以搜索到,或者直接使用AI写出)
xml2txt.py将VOC数据集的标签文件由xml转化为txt文件;(一般也用不上)
yolo2coco.py将yolo数据集的标签文件由txt转化为json文件;(一般也用不上)
2.2 docker(了解)
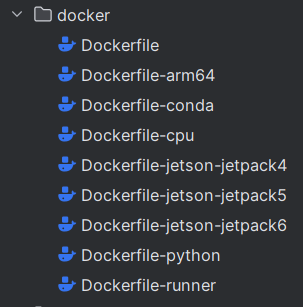
docker 目录包含多个Dockerfile,每个文件都是为不同环境或平台配置的,例如:
· Dockerfile:主要的Docker配置文件,用于构建项目的默认Docker镜像。
· Dockerfile-arm64:针对ARM64架构的设备(如某些类型的服务器或高级嵌入式设备)定制的
Docker配置。
· Dockerfile-conda:使用Conda包管理器配置环境的Docker配置文件。
· Dockerfile-cpu:为不支持GPU加速的环境配置的Docker配置文件。
· Dockerfile-jetson:专为NVIDIA Jetson平台定制的Docker配置。
· Dockerfile-python:可能是针对纯Python环境的简化Docker配置。
· Dockerfile-runner:可能用于配置持续集成/持续部署(CI/CD)运行环境的Docker配置。
这些配置文件 是用来部署用的,用户可以根据自己的需要选择合适的环境来部署和运行项目。
(部署的时候才可能用到)
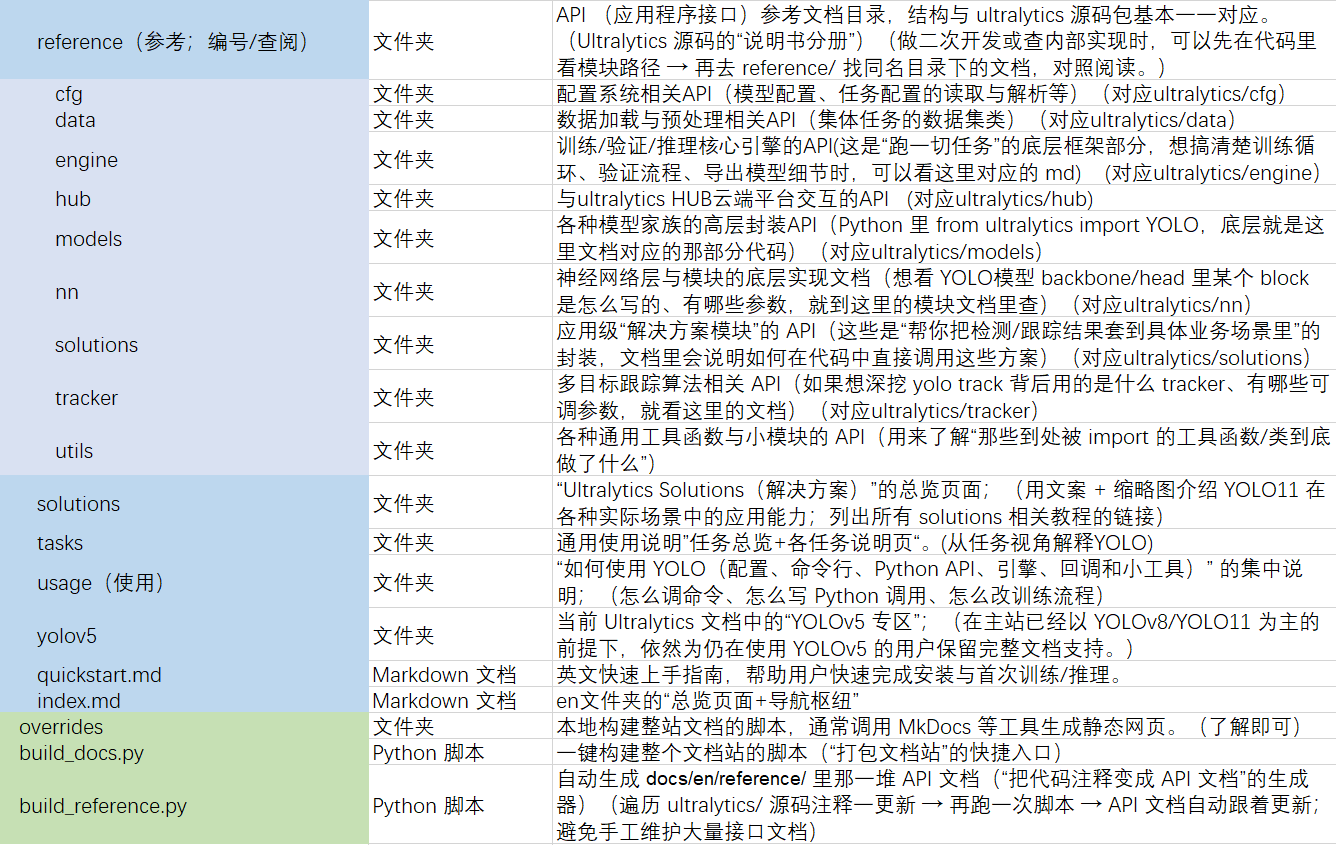
2.3 docs(了解)
|
|
|
|


2.4 examples(了解)
在examples文件夹中,可以找到不同编程语言和平台的YOLOv8实现示例:
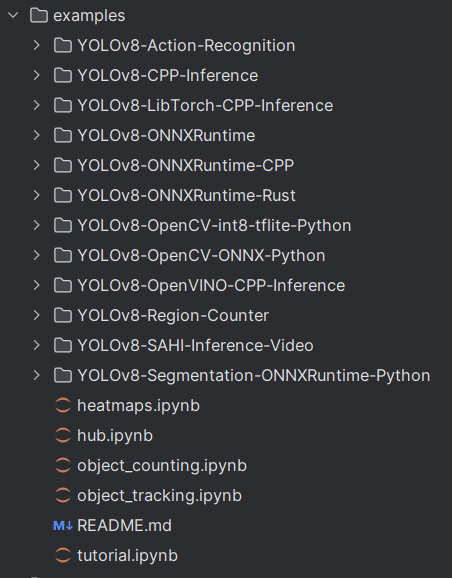
YOLOv8-CPP-Inference:包含C++语言实现的YOLOv8推理示例,内有CMakeLists.txt(用于项目构
建的CMake配置文件),inference.cpp和inference.h(推理相关的源代码和头文件),main.cpp(主
程序入口)以及README.md(使用说明)。
YOLOv8-ONNXRuntime:提供Python语言与ONNX Runtime结合使用的YOLOv8推理示例,其中
main.py是主要的脚本文件,README.md提供了如何使用该示例的指南。
YOLOv8-ONNXRuntime-CPP:与上述ONNX Runtime类似,但是是用C++编写的,包含了相应的
CMakeLists.txt, inference.cpp,inference.h和main.cpp文件,以及用于解释如何运行示例的
README.md.
每个示例都配有相应的文档,是当我们进行模型部署的时候在不同环境中部署和使用YOLOv8的示
例。
2.5 images(了解)
部分网络模块的架构图。
2.6 runs(记住)
runs文件夹是保存训练结果的文件夹;exp代表训练的次数;best.pt在验证集指标(mAP)最好的权重;last.pt:最后一个 epoch 的权重。
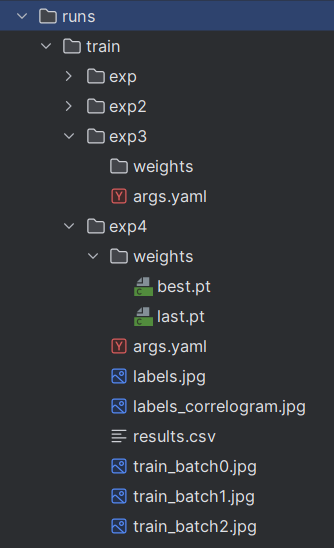
2.7 tests(了解)
tests目录包含了项目的自动化测试脚本,每个脚本针对项目的不同部分进行测试:
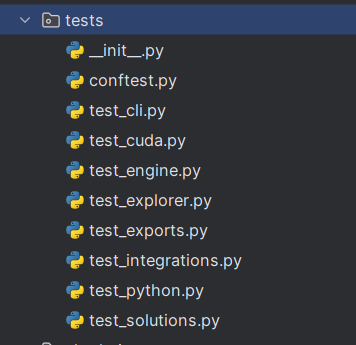
_int_.py:把tests文件夹标记成一个python包;可以用 import 导入,而且可以在这个文件里写包的初始化代码、对外暴露的变量等(当 import tests 时,python 会执行ultralytics-yolo11-main/tests/__init__.py 里的代码);能够通过 __all__ 控制 from xxx import * 时导出哪些*名字;
conftest.py:configuration(cfg配置) test.py tests文件夹的全局配置文件,会被同一层级及其子目录下所有测试自动加载;(避免在每个 test_xxx.py 里重复写相同的准备代码)
test_cli.py:用于测试命令行界面(CLI)的功能和行为。
test_cuda.py:专门测试项目是否能正确使用NVIDIA的CUDA技术,确保GPU加速功能正常。
test_engine.py:测试底层推理引擎,如模型加载和数据处理等。
test_explorer.py:对应 ultralytics.data.explorer(数据集可视化/管理工具)的测试;测试Explorer 是否能正常扫描数据集目录;数据索引、缩略图生成是否不报错;GUI/API 的关键调用是否可以跑通基本流程。
test_exports.py:测试模型导出功能;
test_integrations.py:测试项目与其他服务或库的集成是否正常工作。
test_python.py:用于测试项目的Python API接口是否按预期工作。
test_solutions.py:对应 ultralytics.solutions 里“解决方案模块”的测试;目的是保证官方文档 solutions/ 里那些“现成方案示例”,在代码更新后不会突然失效。
这些测试脚本确保大家在改进了文件之后更新或添加的新功能后仍能运行的文件。
2.8 utlralytics(记住)
utlralytics文件是YOLO项目的重点,项目的所有功能都集成在这个文件目录内。
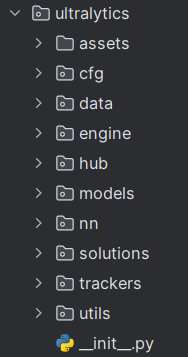
2.8.1 assets(了解)
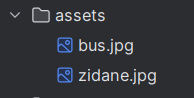
这个文件下面保存了YOLO历史上可以说最最最经典的两张图片了,这个是大家用来基础推理时候
的图片,给大家测试用的。
2.8.2 cfg/configuration配置文件(记住)
这个文件夹保存了整个yolo项目的配置文件。
dataset文件夹:数据集配置文件;包含了各种类型数据集(VOC、COCO)在各种任务条件下(seg、pose)的数据配置文件。(相当于2.1中的data.yaml文件)
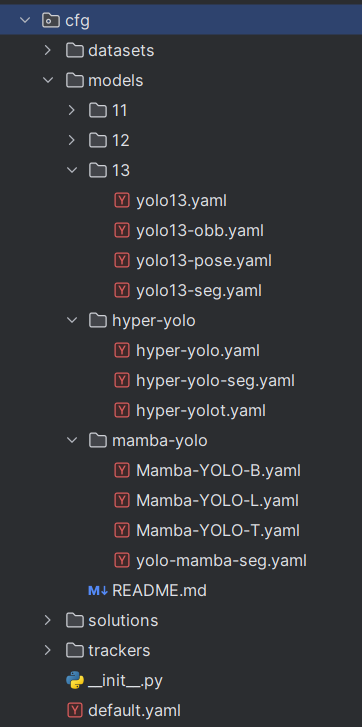
models文件夹:模型配置文件;文件夹内包含了各个模型及其对应的各种任务类型的yaml文件。
solutions文件夹:为(计数、排队管理、AI 健身、热力图等解决方案模块)准备的默认配置文件。

trackers文件夹:用于追踪算法的配置文件
_init_.py文件:把cfg文件夹标记成一个python包;可以用 import 导入,而且可以在这个文件里写包的初始化代码、对外暴露的变量等(当 import ultralytics.cfg 时,python 会执行ultralytics-yolo11-main/ultralytics/cfg/__init__.py 里的代码);
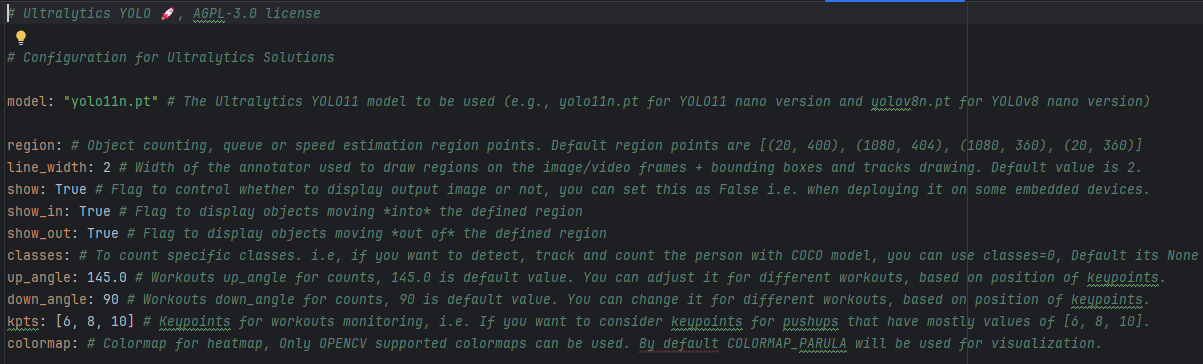
default.yaml:这个ultralytics/cfg/default.yaml是整套YOLO的“总配置模板/默认参数表”,所有 yolo train / yolo val / yolo predict / yolo export 等命令,如果你不自己写参数,都是先按这份文件来的,再被命令行参数或你自己的 cfg 覆盖。
2.8.3 data(了解)
data文件夹是YOLO 的数据流水线模块;包括了“数据集加载 → 划分 → 数据增强 → 打包成 DataLoader → 可视化 / 分析 / 转换” 全流程。
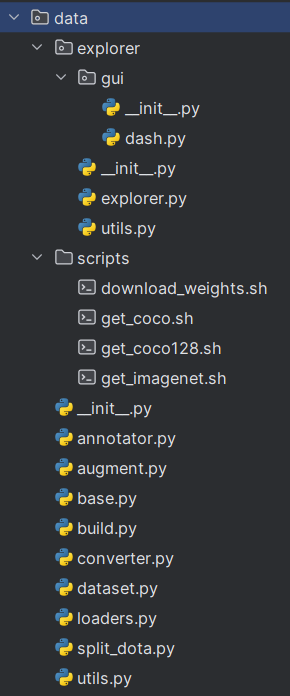
在data/explorer文件夹中:
_init_.py文件:把GUI文件夹标记成一个python包;
dash.py文件:提供一个可视化界面来操作data explorer;
_init_.py文件:把explorer文件夹标记成一个python包;
explorer.py文件:核心逻辑文件,可以理解为data.explorer的主类/主入口;
utils.py文件:data/explorer目录下的公用工具包;
在data/scripts文件夹中:
download_weights.sh:用来下载预训练权重的脚本;get_coco.sh,get_coco128.sh,get_imagenet.sh:用于下载COCO数据集完整版、128张图片版以及lmageNet数据集的脚本。
在data文件夹中,包括:
annotator.py:用于数据注释的工具。
augment.py:数据增强相关的函数或工具。
base.py,build.py,converter.py:包含数据处理的基础类或函数、构建数据集的脚本以及数据格式转
换工具。
dataset.py:数据集加载和处理的相关功能。
loaders.py:定义加载数据的方法。
split_data.py:数据集划分方法。
utils.py:各种数据处理相关的通用工具函数。工具包
2.8.4 engine(了解)
engine文件夹是“YOLO的执行引擎层”;凡是“训练、验证、推理、导出、调参”这些高层操作,底层几乎都在这个文件夹里完成。
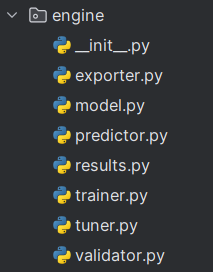
_init_.py文件:把engine文件夹标记成一个python包;
exporter.py:用于将训练好的模型导出到其他格式,例如ONNX或TensorRT(导出打包到其他框夹)
model.py:包含模型定义,还包括模型初始化和加载的方法。
predictor.py:包含推理和预测的逻辑,如加载模型并对输入数据进行预测。(负责推理)
results.py:用于存储和处理模型输出的结果。
trainer.py:包含模型训练过程的逻辑。(让模型学)
tuner.py:用于模型超参数调优。(帮你自动调参)
validator.py:包含模型验证的逻辑,如在验证集上评估模型性能。(帮你评估)
2.8.5 hub(了解)
hub文件夹通常用于处理与平台或服务集成相关的操作。
_init_.py文件:把google文件夹标记成一个python包;
_init_.py文件:把hub文件夹标记成一个python包;
auth.py:处理认证流程,如API密钥验证或OAuth流程。
session.py:管理会话,包括创建和维护持久会话。
utils.py: hub文件下的公用工具包;包含一些通用工具函数,可能用于支持认证和会话管理功能。
2.8.6 models(记住)
models文件夹包含了所有网络结构模型的集合。
fastsam文件夹:FastSAM(快速 Segment Anything);包含了模型的网络结构、预测、验证文件;
nas文件夹:基于神经网络架构搜索(Neural Architecture Search, NAS)的模型实现;
rtdetr文件夹:基于 Transformer / DETR 思路的实时检测模型;
sam文件夹:集成 Meta 的 Segment Anything Model;
utils文件夹:models文件夹下的公共工具包;
yolo文件夹:yolo不同任务模型的实现方法;
classify:这个目录可能包含用于图像分类的YOLO模型。
detect:包含用于物体检测的YOLO模型。
obb:包含用于旋转框的YOLO模型
pose:包含用于姿态估计任务的YOLO模型。
segment:包含用于图像分割的YOLO模型。
world:YOLO-world模型。
_init_.py文件:把yolo文件夹标记成一个python包;
model.py文件:yolo模型的封装文件;
2.8.7 nn(一定一定记住)
项目模型中的组成模块均在这个文件夹内,后期的改进优化均需要在这个文件夹内添加修改模块。
backbone:模型主干层可能包含的主干模块网络;
extra_modules:额外的网络模块;
modules文件夹:
_init _. py:把modules文件夹标记成一个python包;
activation.py:包含网络激活的相关的实现;
block.py:包含定义神经网络中的基础块,如残差块或瓶颈块。
conv.py:包含卷积层相关的实现。
head.py:定义网络的头部,用于预测。
transformer.py:包含Transformer模型相关的实现。
utils.py:提供构建神经网络时可能用到的辅助函数。
_init _. py:把nn文件夹标记成一个python包;
autobackend.py:用于自动选择最优的计算后端。
tasks.py:定义了使用神经网络完成的不同任务的流程,例如分类、检测或分割,所有的流程基本上都定义在这里,定义模型前向传播都在这里。
2.8.8 solutions(了解)
_init_py:标识这是一个Python包。
ai_gym.py:与强化学习相关,例如在OpenAl Gym环境中训练模型的代码。
heatmap.py:用于生成和处理热图数据,这在物体检测和事件定位中很常见。
object_counter.py:用于物体计数的脚本,包含从图像中检测和计数实例的逻辑。
2.8.9 trackers(了解)
trackers文件夹包含了实现目标跟踪功能的脚本和模块:
init _. py:指示该文件夹是一个Python包。
basetrack.py:包含跟踪器的基础类或方法。
bot_sort.py:实现了SORT算法(Simple Online and Realtime Tracking)的版本。
byte_tracker.py:是一个基于深度学习的跟踪器,使用字节为单位跟踪目标。
track.py:包含跟踪单个或多个目标的具体逻辑。
README.md:提供该目录内容和用法的说明。
2.8.10 utils(了解)
utils是ultralytics文件夹的公共工具包;
这个utils目录包含了多个Python脚本,每个脚本都有特定的功能:
callbacks.py:包含在训练过程中被调用的回调函数。
autobatch.py:用于实现批处理优化,以提高训练或推理的效率。
benchmarks.py:包含性能基准测试相关的函数。
checks.py:用于项目中的各种检查,如参数验证或环境检查。
dist.py:涉及分布式计算相关的工具。
downloads.py:包含下载数据或模型等资源的脚本。
errors.py:定义错误处理相关的类和函数。
files.py:包含文件操作相关的工具函数。
instance.py:包含实例化对象或模型的工具。
loss.py:定义损失函数。
metrics.py:包含评估模型性能的指标计算函数。
ops.py:包含自定义操作,如特殊的数学运算或数据转换。
patches.py:用于实现修改或补丁应用的工具。
plotting.py:包含数据可视化相关的绘图工具。
tal.py:一些损失函数的功能应用
torch_utils.py:提供PyTorch相关的工具和辅助函数,包括GFLOPs的计算。
triton.py:可能与NVIDIA Triton Inference Server集成相关。
tuner.py:包含模型或算法调优相关的工具。
三、总结
yolo项目目录的构造分析对后期模型的改进有重要的作用,其使大家明白了那几个文件夹是要修改的重点。
参考:https://blog.csdn.net/java1314777/article/details/134824995?spm=1001.2014.3001.5506

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)