【收藏学习】上下文工程:大模型能力提升的关键技术
当大模型进入实用阶段,“比模型参数更重要的是信息架构”。上下文工程的本质,是把大模型从"通用工具"改造成"专用系统"——它不直接提升模型能力,却能让能力"用在对的地方"。对于开发者来说,掌握上下文工程意味着:不再依赖"撞大运"式的提示词,而是能系统性设计大模型的"思考路径";对于用户来说,这意味着更可靠的输出、更贴合需求的服务(比如医疗AI不再漏掉你的过敏史)。未来,大模型的竞争将越来越少是"参数
当我们惊叹于GPT-4能写代码、Claude能处理百万字文档时,可能忽略了一个关键问题:这些大模型的"超能力",其实高度依赖于给它们的"信息料包"。
就像顶级厨师需要新鲜食材才能做出好菜,大模型的表现也完全由输入的上下文信息决定。而如何系统性地设计、优化这些"信息料包",已经形成了一门专门的学问——上下文工程(Context Engineering)。
最近,中科院等机构的研究者发布了一篇涵盖1400+篇论文的综述,首次为这一领域建立了完整框架。今天,我们就来聊聊这门让大模型"更聪明"的核心技术。
从"提示词"到"上下文工程":AI能力的进化密码
过去,我们靠"提示词工程(Prompt Engineering)“调教大模型——比如用"请用中文总结"让输出更贴合需求。但随着大模型从"听话的工具"变成"复杂任务的决策者”,这种单点优化的方式已经不够了。
想象一下:当你让AI分析一份10万字的医疗报告,还需要结合最新研究、调用计算器验证数据、记住之前的分析结论时,简单的提示词根本hold不住。这时候,就需要"上下文工程"登场了。
上下文工程的核心,是把大模型的输入从"静态字符串"变成"动态信息系统"。它像一个智能的"信息管家",会根据任务需求:
- 自动找资料(从知识库、网络中检索)
- 整理信息(提炼重点、处理长文本、整合表格/图片等结构化数据)
- 管理记忆(区分短期工作记忆和长期存储)
- 协调工具(调用计算器、数据库、其他AI等)
用论文里的公式来说,传统提示词是C = prompt(静态),而上下文工程是C = A(c₁, c₂, ..., cₙ)(动态组装)。这个"A"就是那个"信息管家",负责把不同来源的信息(指令、知识、工具定义、记忆等)整合成最优输入。
过去用大模型,更像"猜谜"——同样的问题,换个说法可能得到完全不同的答案。这背后的核心问题是:我们对大模型的"输入信息"缺乏系统性控制。
上下文工程的出现,正是把这种"玄学"变成"工程学"。我们可以用一组对比看清它的革命性:
| 维度 | 传统提示词工程(Prompt Engineering) | 上下文工程(Context Engineering) |
|---|---|---|
| 核心逻辑 | 静态字符串:C = 提示词 |
动态系统:C = A(c₁, c₂, ..., cₙ)(A为组装函数) |
| 信息来源 | 仅依赖人工编写的提示词 | 整合外部知识、记忆、工具、实时数据等多源信息 |
| 处理能力 | 单次输入,无法处理超长文本或复杂结构 | 支持长文本分段、结构化数据转换、动态更新 |
| 典型场景 | 简单问答、文本生成(如写邮件、摘要) | 复杂任务(如医疗诊断、多步骤推理、团队协作) |
| 本质区别 | “给模型喂答案”(告诉它怎么做) | “给模型建系统”(让它自己知道需要什么) |
举个直观例子:
- 用提示词工程处理"分析某公司2023年财报并预测明年趋势",你需要手动写清"关注营收、成本、行业对比"等细节,一旦遗漏就会出错;
- 用上下文工程,系统会自动:① 检索该公司财报原文(外部知识);② 调用计算器计算增长率(工具);③ 关联过去3年数据(记忆);④ 对比行业报告(多源信息),最终生成分析。
关键差异:提示词工程是"人主导",上下文工程是"系统主导"——后者让大模型从"被动执行"变成"主动解决问题"。
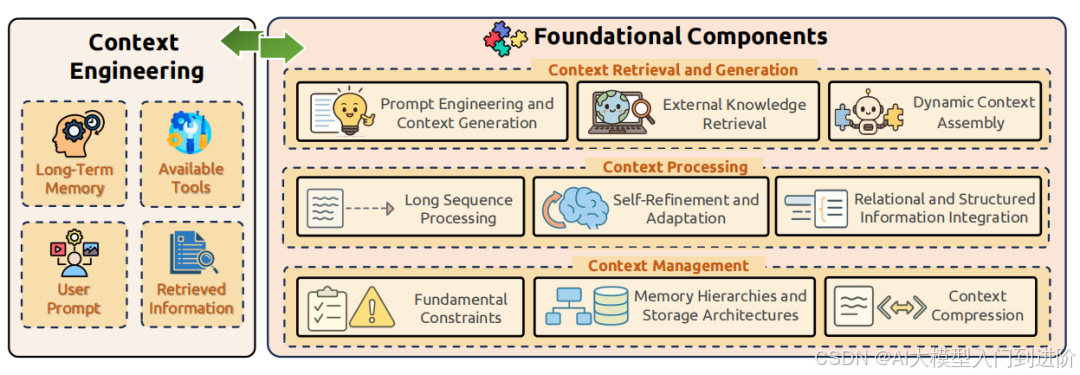
上下文工程的"三板斧":基础组件解析
要当好这个"信息管家",需要三大核心能力,也就是上下文工程的基础组件:
1. 上下文检索与生成:给AI找对"原材料"
核心目标:从海量信息中精准获取任务所需的"食材"。
| 技术方案 | 原理 | 优势 | 局限 |
|---|---|---|---|
| 提示词生成 | 设计结构化指令(如思维链、角色设定) | 轻量、无需外部资源 | 依赖人工经验,复杂任务难以覆盖 |
| 外部知识检索(RAG) | 从知识库/网络中实时调取信息 | 知识新鲜、可验证 | 检索不准确时会引入错误 |
| 动态组装 | 按任务需求自动拼接多源信息(指令+知识+记忆) | 适配复杂场景,信息全面 | 组装逻辑复杂,需优化顺序和权重 |
典型案例:医疗AI问诊时,系统会先检索患者病历(记忆)、最新治疗指南(外部知识),再生成结构化问诊流程(提示词),而不是单纯依赖预设的问答模板。
2. 上下文处理:给AI"整理食材"
核心目标:把原始信息加工成模型能高效理解的形式。
| 技术方案 | 原理 | 适用场景 | 代表技术 |
|---|---|---|---|
| 长文本处理 | 拆分超长输入(如滑动窗口)或优化注意力机制 | 处理书籍、法律文档等长内容 | Mamba(线性复杂度)、LongNet(稀释注意力) |
| 自我优化 | 模型自主检查并修正信息(如"这段分析是否遗漏成本因素") | 提升输出准确性,减少错误 | Self-Refine(迭代修正)、Reflexion(反思记忆) |
| 多模态整合 | 将图片/表格/音频转换为文本描述或嵌入向量 | 处理跨模态任务(如图文结合的报告分析) | CLIP(图文转换)、StructGPT(表格处理) |
关键对比:传统Transformer处理10万字文本时,计算量随长度平方增长(O(n²)),而Mamba等新型架构通过线性复杂度(O(n)),能轻松处理百万字内容,这也是Claude能"读小说"的核心技术。
3. 上下文管理:给AI建"智能仓库"
核心目标:高效存储和调度信息,避免"内存溢出"或"遗忘关键信息"。
| 技术方案 | 原理 | 价值 | 挑战 |
|---|---|---|---|
| 记忆分层 | 区分短期工作记忆(当前对话)和长期记忆(用户偏好) | 平衡实时性和持续性,减少冗余 | 记忆更新策略需适配场景(如用户偏好可能变化) |
| 上下文压缩 | 提炼核心信息(如把1000字会议纪要缩为100字要点) | 节省上下文空间,突出重点 | 压缩过度可能丢失关键细节 |
| 动态调度 | 模型自主决定"保留/丢弃"信息(如优先保留数据而非寒暄) | 适配动态任务,提升效率 | 调度逻辑需避免"误删"重要信息 |
生动比喻:就像手机相册会自动分类(短期照片、珍藏回忆)、压缩低清图片,上下文管理让模型的"内存"用在刀刃上。
从组件到系统:四大核心应用场景
基于三大模块,研究者们已构建出四大类成熟系统,覆盖从简单查询到复杂协作的全场景:
| 系统类型 | 核心能力 | 典型案例 | 技术亮点 |
|---|---|---|---|
| 检索增强生成(RAG) | 实时调用外部知识,避免"一本正经地胡说" | 企业问答机器人(如查产品手册) | Graph-RAG(用知识图谱关联信息)、Agentic RAG(主动检索) |
| 记忆系统 | 持续积累信息,实现长期个性化交互 | 智能助手(如记住用户饮食禁忌) | MemGPT(模拟操作系统内存管理)、MemoryBank(遗忘曲线建模) |
| 工具集成推理 | 调用外部工具(计算器/数据库/API)扩展能力 | 数据分析AI(自动用Python计算并绘图) | Toolformer(函数调用)、Chameleon(多工具协同) |
| 多智能体系统 | 多个AI分工协作,处理超复杂任务 | 科研团队(一个查文献,一个做数据分析) | AutoGen(动态组队)、MetaGPT(角色分工) |
直观案例:用多智能体系统写一篇市场分析报告:
- 智能体A:调用爬虫工具获取竞品数据(工具集成);
- 智能体B:用记忆系统关联公司历史销售数据(记忆);
- 智能体C:检索最新行业政策(RAG);
- 智能体D:整合所有信息生成报告,并自我优化逻辑(处理)。
1. 检索增强生成(RAG):给AI装"活字典"
传统大模型的知识截止到训练时,而RAG能让它实时调用外部知识,就像带了本"活字典"。现在的RAG已经从"简单找资料"进化出多种形态:
- 模块化RAG:像搭积木一样组合不同功能(比如先扩写查询词,再检索,最后验证结果)。
- 智能体RAG:让AI像侦探一样主动查资料。例如分析公司财报时,会先决定"需要查行业平均数据",再自主检索并对比。
- 图谱增强RAG:用知识图谱整合零散信息。比如研究疾病时,不仅找症状,还能关联病因、治疗方案的关系网络。
2. 记忆系统:给AI配"笔记本"
人类靠记忆积累经验,AI也需要"笔记本"来记住过去。现在的记忆系统已经相当 sophisticated:
- 分层记忆:短期记忆存对话上下文,长期记忆存用户资料。例如,教育AI会记住学生"昨天没弄懂的微积分公式"(短期)和"总是在几何题上犯错"(长期)。
- 动态更新:像人类会忘记不重要的事,AI的记忆也会"衰减"。例如用"艾宾浩斯遗忘曲线"模型,自动弱化过时信息。
- 记忆增强智能体:能主动调用记忆解决问题。比如客服AI遇到老用户时,会先调出"该用户上次投诉的物流问题"再回应。
3. 工具集成推理:让AI会"用工具"
光有知识还不够,AI还得会用工具。现在的大模型已经能像人一样:
- 调用函数:比如用计算器算复杂数值,用API查实时天气。
- 多工具协同:分析市场时,先调用数据库取销售数据,再用Excel工具绘图,最后用PPT工具生成报告。
- 环境交互:不只是处理数据,还能操作软件。例如自动在网页上填写表单,或控制机器人完成物理任务。
4. 多智能体系统:让AI"组队干活"
复杂任务需要分工,于是"AI团队"应运而生。多智能体系统的核心是让多个AI协同工作:
- 通信协议:就像人类开会有规则,AI之间也有"对话规范"。例如用KQML协议定义"请求"、“回应”、"拒绝"等交互方式。
- 任务分配:自动给不同AI派活。比如写论文时,一个AI查文献,一个AI分析数据,一个AI组织语言。
- 协同策略:解决冲突和配合问题。例如,当两个AI的结论矛盾时,会自动找第三个AI仲裁。
四、未来决胜点:上下文工程的3大技术突破方向
当前上下文工程仍有"阿喀琉斯之踵"——大模型在"理解复杂信息"和"生成复杂内容"上存在显著能力不对称(能读懂10万字却写不好1万字分析)。未来突破将集中在:
- 长文本生成优化:解决"写长文逻辑断裂"问题,可能通过"规划-执行-修正"三阶段架构,像人写论文一样先列提纲再填充内容。
- 跨模态深度融合:让模型不仅能"看图片、听声音",还能理解其中的隐含信息(如从表情判断用户情绪)。
- 自主进化系统:上下文工程从"人工设计"走向"自我学习",模型能根据任务效果自动调整信息处理策略(如发现检索经常出错就优化检索关键词)。
- 安全与伦理框架:随着AI处理的信息越来越敏感(医疗记录、商业数据等),需要建立严格的"信息权限管理"——确保AI只看该看的,只记该记的。
结语:从"用模型"到"建系统"的必然选择
当大模型进入实用阶段,“比模型参数更重要的是信息架构”。上下文工程的本质,是把大模型从"通用工具"改造成"专用系统"——它不直接提升模型能力,却能让能力"用在对的地方"。 对于开发者来说,掌握上下文工程意味着:不再依赖"撞大运"式的提示词,而是能系统性设计大模型的"思考路径";对于用户来说,这意味着更可靠的输出、更贴合需求的服务(比如医疗AI不再漏掉你的过敏史)。 未来,大模型的竞争将越来越少是"参数军备竞赛",而更多是"上下文工程的精细化比拼"。毕竟,能把普通食材做出顶级味道的,才是真正的大师。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献355条内容
已为社区贡献355条内容

所有评论(0)