7步解析大模型“思考“全过程:从输入到输出的硬核技术揭秘
本文系统阐述了大模型的工作原理,将其分解为6个关键步骤:输入处理、分词、嵌入向量转换、位置编码、Transformer核心计算和输出生成。重点剖析了Transformer架构的三大核心组件:自注意力机制、多头注意力和前馈神经网络,揭示了模型如何通过数学计算实现语言理解。文章指出"大模型"的核心特征在于参数规模、训练数据和算力需求,当参数突破临界点时会产生涌现能力。理解这些原理有
本文详细解析了大模型(LLM)的工作原理,从输入到输出的6个关键步骤:输入层、分词、嵌入层、位置编码、Transformer层和输出层。重点解释了Transformer架构中的自注意力机制、多头注意力和前馈神经网络等核心组件。揭示了"大模型"的"大"体现在参数规模、训练数据和算力需求上,当参数超过临界点时会产生涌现能力。理解这些原理有助于开发者更好地使用和优化大模型应用。
在这个大模型(LLM)应用遍地开花的2025年,会用ChatGPT或Claude已经不算什么稀奇技能了。但当我们在对话框里输入一句“你好”,屏幕对面那个“大脑”内部究竟发生了什么?它是如何像人类一样“思考”并吐出每一个字的?
很多人觉得这是深奥的黑盒,只有科学家能懂。其实不然。理解大模型的原理,是你在这个AI时代建立技术直觉的关键一步。 只有懂了它是怎么工作的,你才能写出更好的Prompt,更精准地调试模型,甚至开发出更强大的应用。
今天,我们就剥开这层神秘面纱,用最直观的图解,带你完成一次从输入层到输出层的硬核探险。🚀
- 从输入到输出:大模型的“思考”流水线
大模型的工作流程,本质上就是一个复杂的数学函数,把输入的文本转换成输出的文本。这个过程并非魔法,而是一条严密的流水线。
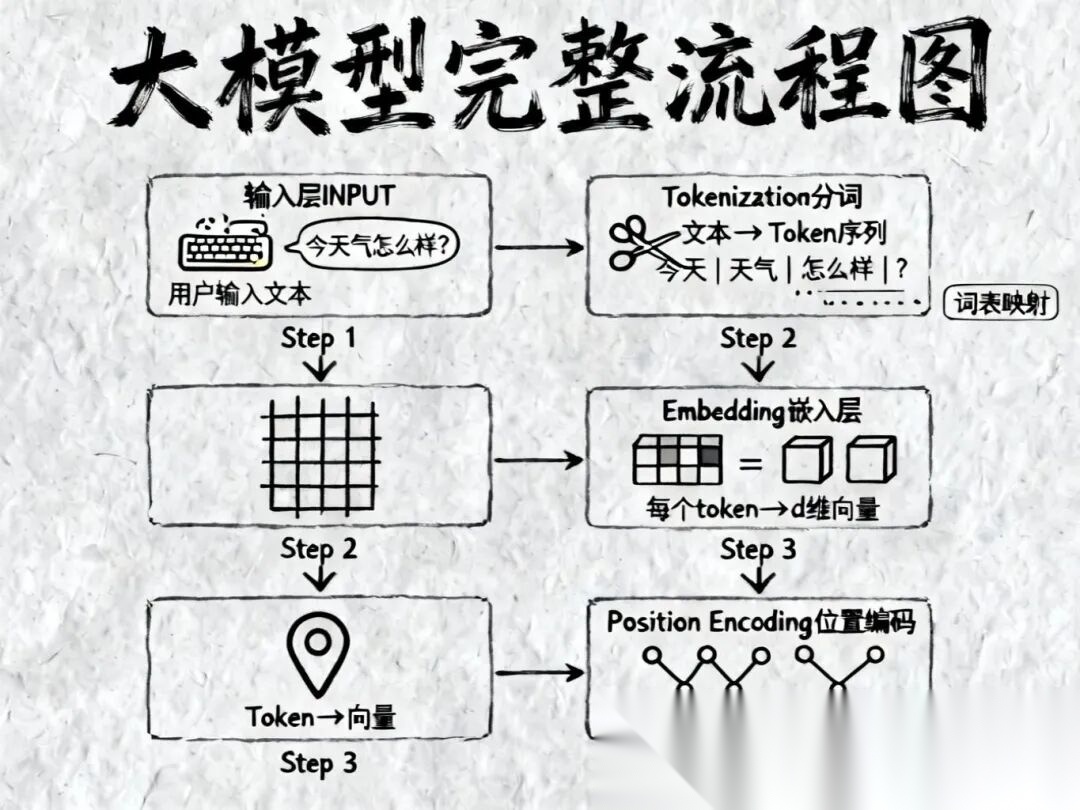
我们可以把这个过程拆解为6个关键步骤,以你问AI“今天天气怎么样?”为例:
Step 1: 输入层 (Input)
一切始于你的键盘。你输入了一串字符序列:“今天天气怎么样?”。对计算机来说,这目前还只是一串毫无意义的字节。
Step 2: 分词 (Tokenization)
模型读不懂整句话,它需要把句子“切”成它认识的最小单位,叫做 Token。
- 例子:“今天天气怎么样?”
["今天", "天气", "怎么样", "?"] - 这就像让一个刚学外语的人,先把句子拆成一个个单词或词组。模型有一个巨大的词表,每个Token都有一个唯一的ID。
Step 3: 嵌入层 (Embedding)
这是文字变成数学的关键一步。模型把每个Token ID转换成一个高维的向量(Vector)。
- 这就好比给每个词发了一张“身份证”,这张身份证上有一长串数字(比如4096个数字)。
- 神奇之处:意思相近的词,在数学空间里的距离也会很近。比如“猫”和“狗”的向量距离,肯定比“猫”和“冰箱”要近。
Step 4: 位置编码 (Position Encoding)
Attention机制本身是不看顺序的(这是它的一个特性,也是缺陷)。为了让模型知道“小明打小刚”和“小刚打小明”的区别,我们需要把位置信息“加”到Embedding向量里。
- 这就像给每个词的向量上打了个戳:“你是第1个”,“你是第2个”……
Step 5: Transformer层 (The Core)
这是真正的“大脑”区域。经过位置编码的向量,会进入几十甚至上百层的Transformer模块。在这里,Token之间会进行疯狂的信息交换(Self-Attention)和特征提取(FFN)。我们将在第二部分详细展开。
Step 6: 输出层 (Output)
经过层层计算,模型最终输出一个概率分布。它会告诉你:在“今天天气怎么样?”这句话后面,接哪个词的概率最大?
- 比如,概率最高的可能是“晴”,或者是“很”。
- 自回归生成:模型选定一个词后,会把这个新词加到输入里,再次循环上述过程,生成下一个词,直到它吐出一个“结束符”。
- 拆解心脏:Transformer架构详解
如果说大模型是一辆跑车,Transformer就是它的V12引擎。自2017年Google发表《Attention Is All You Need》以来,这个架构几乎统治了NLP领域。
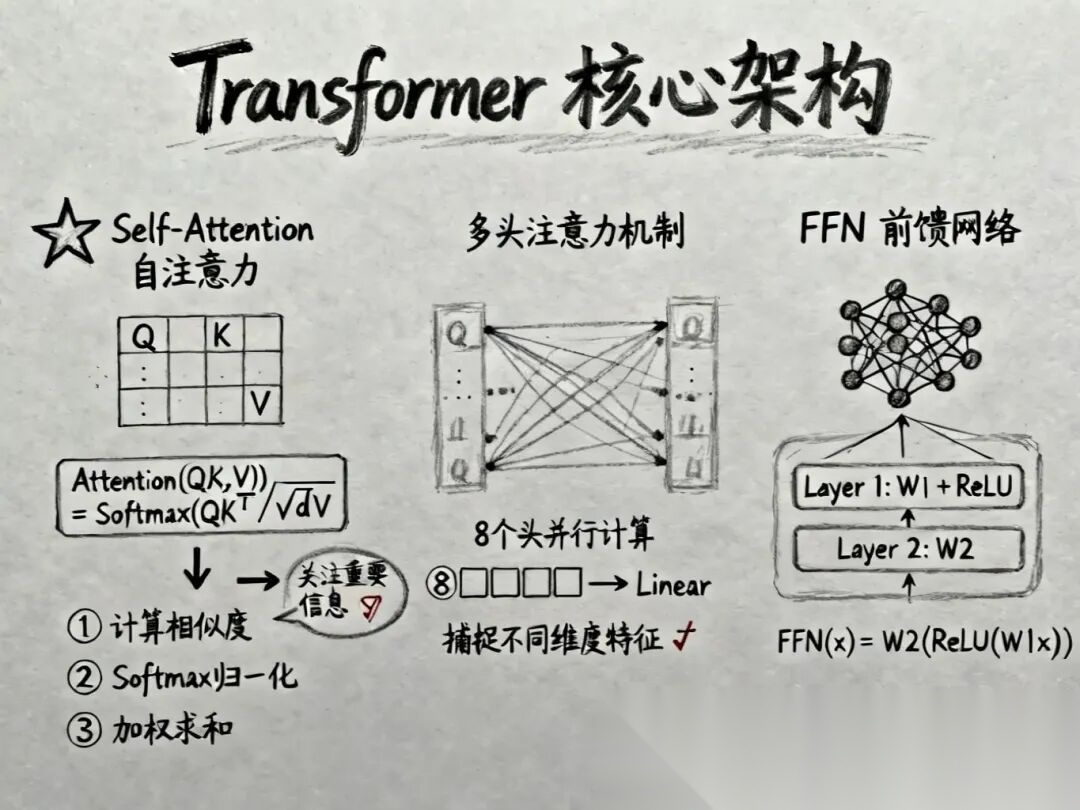
Transformer内部主要由三个精密部件组成:
🎯 Self-Attention (自注意力机制)
这是Transformer的灵魂。它的核心任务是:在处理当前词时,应该关注上下文中的哪些词?
想象你在读一段长文,当读到“它”这个字时,你的大脑会瞬间回溯前文,寻找“它”指代的是“小猫”还是“桌子”。这就是Attention。
在数学上,它通过三个矩阵来实现:
- Query (Q):查询向量。相当于“我在找什么?”
- Key (K):键向量。相当于“我有什么特征?”
- Value (V):值向量。相当于“我的实际内容是什么?”
计算过程简单来说就是:拿Q去和所有的K做点积(算相似度),根据相似度对V进行加权求和。
🧠 Multi-Head Attention (多头注意力)
俗话说“兼听则明”。如果只用一组Q、K、V,可能只能捕捉到一种关系(比如语法关系)。
多头机制就是把这套操作复制8份、16份甚至更多,让模型同时从不同的“角度”去理解上下文:
- 头1可能关注指代关系;
- 头2可能关注时态;
- 头3可能关注情感色彩……
最后把所有头的计算结果拼起来,就得到了对当前Token全面而深刻的理解。
⚡ FFN与残差连接
- FFN (前馈神经网络):如果是Attention负责“看全局”,FFN就负责“想细节”。它对每个位置的信息进行独立的非线性变换,增强模型的表达能力。
- Residual (残差连接):在每层计算后,把输入直接加到输出上()。这就像修了一条高速公路,让梯度能无损地传到深层网络,防止模型“学傻了”(梯度消失)。
- Layer Norm (层归一化):让数据分布保持稳定,保证训练过程不翻车。
- 大模型的“大”:参数、算力与涌现
为什么现在的模型叫“大”模型(Large Language Model)?这个“大”不仅仅是体积大,更是量变引起质变的关键。
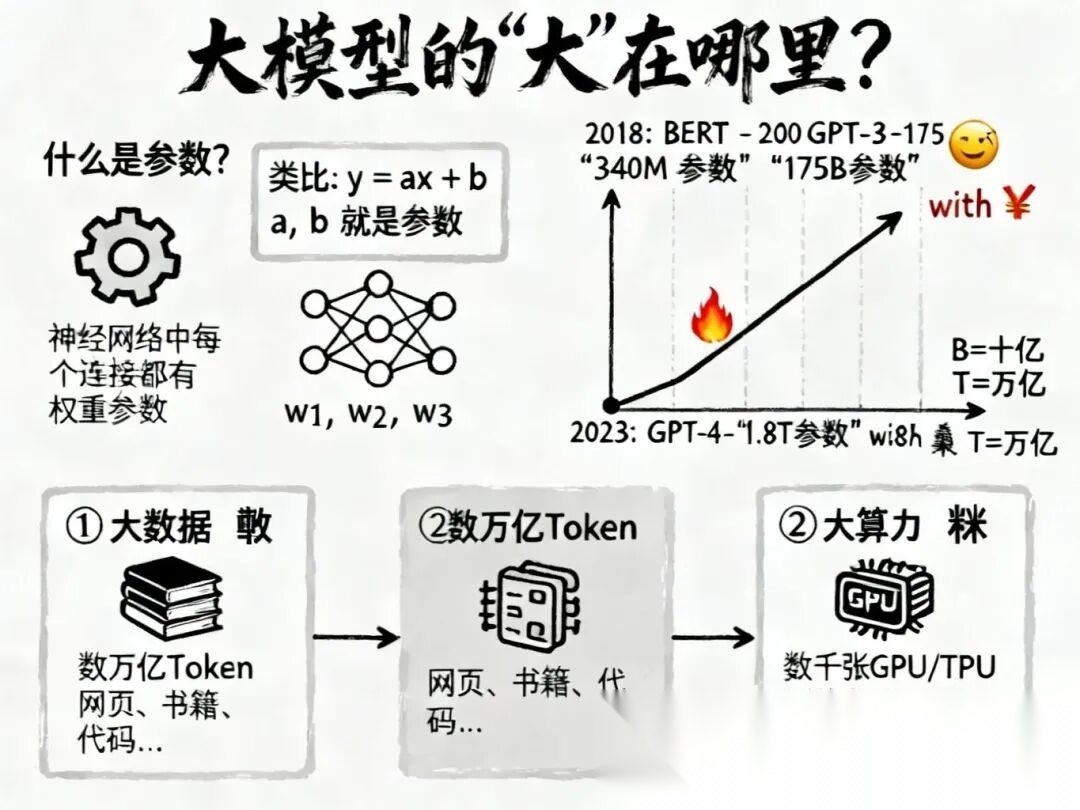
📈 什么是“参数”?
我们在初中数学学过线性方程 ,这里的 和 就是参数。你需要调整 和 的值,让这条线尽可能拟合数据点。
神经网络也是一样,只不过它不是一条线,而是一个超级复杂的网。Transformer里的每一个矩阵权重(W)、每一个偏置项(Bias)都是参数。
- BERT (2018):约3.4亿参数。
- GPT-3 (2020):1750亿参数。
- GPT-4 (2023):推测在1.8万亿参数级别。
这些参数就像大脑里的突触连接,参数越多,模型能存储的知识和逻辑模式就越丰富。
🔥 训练三要素:大力出奇迹
要训练这样一个庞然大物,需要三个条件同时具备:
- 大数据 (Data):这是模型的“粮食”。需要把几乎整个互联网的文本(万亿级Token)喂给它。
- 大算力 (Compute):这是模型的“肌肉”。需要数千甚至数万张H100/A100显卡,日夜不停地算上几个月。
- 强算法 (Algorithm):即Transformer架构及其变体,保证在如此大规模下还能高效收敛。
✨ 涌现能力 (Emergent Abilities)
最迷人的是,当参数规模超过某个临界点(比如百亿级)时,模型突然展现出了设计者未曾预料的能力:逻辑推理、代码生成、情景理解。这就好比量变引起了质变,一堆只会做概率预测的数学公式,突然仿佛有了“灵魂”。
总结:数学与工程的奇迹
大模型并没有什么神秘的“意识”,它的本质是:
- Input层把人类语言翻译成机器语言(向量);
- Transformer层利用Attention机制在海量数据中寻找上下文的关联模式;
- Output层基于概率预测下一个最合理的词。
看似简单的“单字接龙”,在千亿参数和万亿数据的加持下,最终演绎出了惊人的智能。
理解了这些,下次当你看到AI一本正经地胡说八道(幻觉),或者惊叹于它写出的绝妙代码时,你会明白——这都是概率在向量空间里起舞的结果。
💡 学习建议:如果你想深入这个领域,不要只停留在概念上。尝试去读一读Transformer的源码(如PyTorch实现),或者亲手跑一个小规模的GPT模型,那是通往AI深处的最佳门票。
AI时代,未来的就业机会在哪里?
答案就藏在大模型的浪潮里。从ChatGPT、DeepSeek等日常工具,到自然语言处理、计算机视觉、多模态等核心领域,技术普惠化、应用垂直化与生态开源化正催生Prompt工程师、自然语言处理、计算机视觉工程师、大模型算法工程师、AI应用产品经理等AI岗位。
掌握大模型技能,就是把握高薪未来。
那么,普通人如何抓住大模型风口?
AI技术的普及对个人能力提出了新的要求,在AI时代,持续学习和适应新技术变得尤为重要。无论是企业还是个人,都需要不断更新知识体系,提升与AI协作的能力,以适应不断变化的工作环境。
因此,这里给大家整理了一份《2025最新大模型全套学习资源》,包括2025最新大模型学习路线、大模型书籍、视频教程、项目实战、最新行业报告、面试题等,带你从零基础入门到精通,快速掌握大模型技术!
由于篇幅有限,有需要的小伙伴可以扫码获取!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。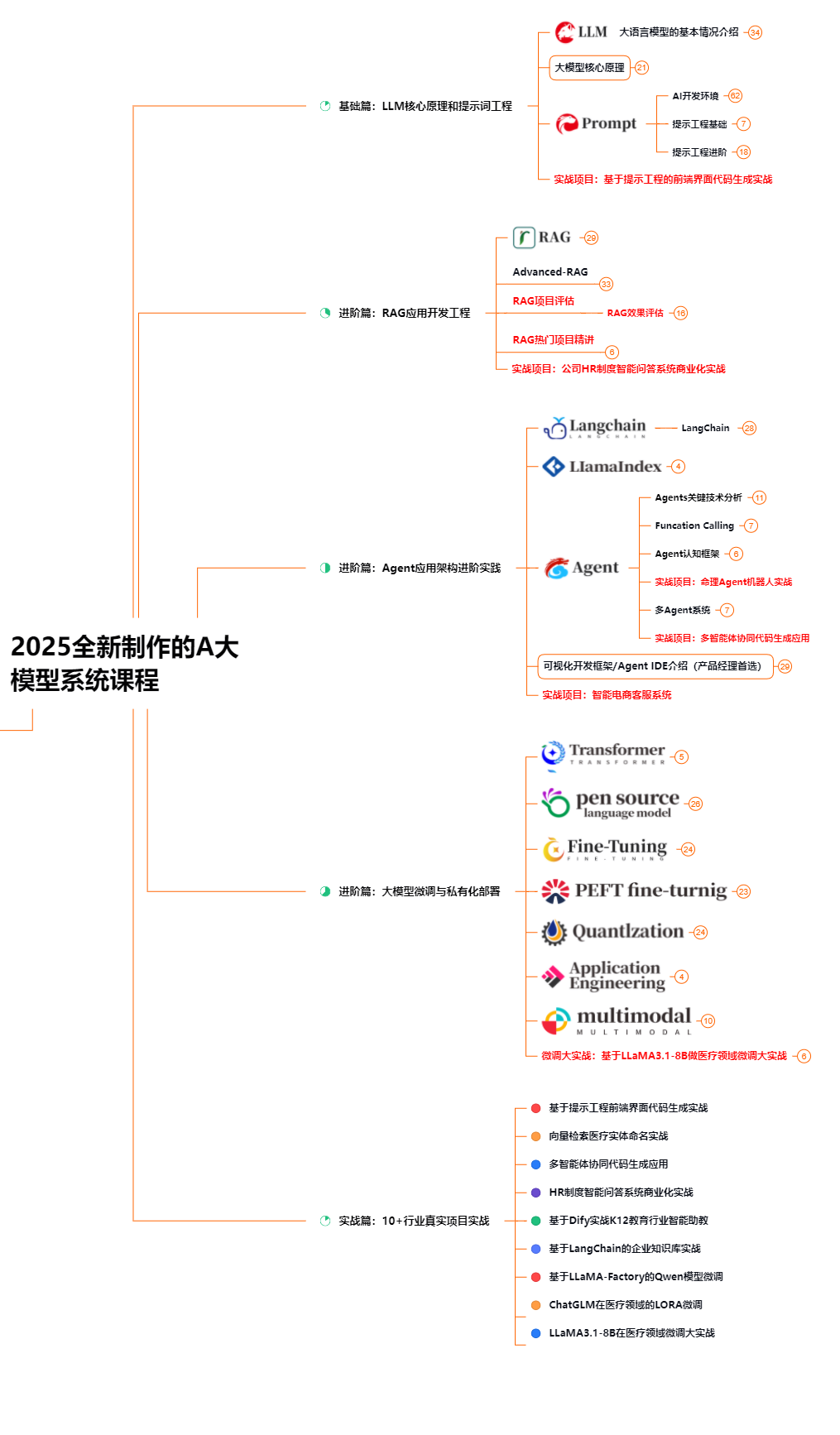
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
5. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

为什么大家都在学AI大模型?
随着AI技术的发展,企业对人才的需求从“单一技术”转向 “AI+行业”双背景。企业对人才的需求从“单一技术”转向 “AI+行业”双背景。金融+AI、制造+AI、医疗+AI等跨界岗位薪资涨幅达30%-50%。
同时很多人面临优化裁员,近期科技巨头英特尔裁员2万人,传统岗位不断缩减,因此转行AI势在必行!

这些资料有用吗?
这份资料由我们和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


大模型全套学习资料已整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献434条内容
已为社区贡献434条内容

所有评论(0)