昇腾大模型量化实战:ModelSlim 工具上手与 W8A8 精度优化全流程解析
本文详细介绍了使用昇腾ModelSlim工具对Qwen2.5-72B大模型进行W8A8量化的全流程。首先阐述了量化对于大模型推理性能提升的重要性,然后介绍了ModelSlim工具的功能特点和环境配置要求。重点讲解了量化过程中的关键步骤:模型加载、校准数据准备、AntiOutlier离群值抑制、量化参数配置等。通过实测数据表明,W8A8量化可使显存占用降低42%,推理时延提升33%,而精度损失仅1.
昇腾大模型量化实战:ModelSlim 工具上手与 W8A8 精度优化全流程解析
——从 AntiOutlier 到 FA3,让 Qwen2.5-72B 高效“瘦身”

一、前言:为什么要进行大模型量化
随着 LLM(大语言模型)的快速发展,模型规模正呈指数级增长。从十亿参数到千亿参数,推理端的资源消耗已经成为部署的最大瓶颈。 在昇腾 AI 生态中,这一问题尤为显著——大模型虽能充分利用 NPU 的算力优势,但受限于显存容量与计算密度,模型推理往往“跑得起但不够快”。
因此,模型量化逐渐成为高性能推理的关键手段。 它通过压缩权重与激活数据精度,在牺牲极少精度的前提下,大幅降低显存占用与推理延迟。
本文将以 Qwen2.5-72B 模型 为例,基于 MindStudio ModelSlim 工具,完整演示 W8A8(权重量化8bit,激活量化8bit)量化全流程,并结合实战解读量化背后的策略与效果。
二、ModelSlim 工具概览:让“压缩”真正服务于“加速”
ModelSlim 是昇腾官方推出的模型压缩与加速工具,定位于昇腾生态的一站式模型轻量化平台。 它的设计理念可以用一句话概括:
“以加速为导向,以压缩为手段,以硬件亲和为根基。”
与传统的单一量化框架不同,ModelSlim 集成了多种主流压缩技术:
- 低秩分解:通过矩阵分解降低参数维度;
- 稀疏训练:剪枝冗余权重;
- 训练后量化(PTQ):无需重新训练的快速量化方案;
- 量化感知训练(QAT):在训练过程中引入量化模拟,获得更优精度。
这些方法由统一的 Python API 进行管理和调用,使得开发者可以更灵活地控制压缩粒度与部署格式。
简言之,ModelSlim 不只是一个量化工具,更是一套面向昇腾硬件的推理优化系统。
安装检测
暂时无法在飞书文档外展示此内容

三、实战流程:Qwen2.5-72B 的 W8A8 量化全流程
环境与依赖
在开始之前,请确认以下基础环境:
| 环境项 | 推荐版本 |
|---|---|
| 硬件 | Atlas 800I A2 / 800T A2 / Atlas 300I Duo |
| 系统 | openEuler 22.03 LTS |
| Python | 3.10 / 3.11 |
| CANN | 8.2.RC2 |
| 框架镜像 | 官方配套镜像 |
PS:推荐使用官方镜像启动,避免依赖冲突;否则需手动安装 modelslim 库。 下载地址:https://gitcode.com/Ascend/msit/tree/master/msmodelslim
安装流程(详细步骤)
下面是一个较为完整、含命令的安装流程示例(以 Ubuntu/Linux 环境为例):
暂时无法在飞书文档外展示此内容
注意事项 &版本说明
- CANN 的版本 必须 ≥ 8.0.RC1.alpha001。 Gitee+1
- 在 CANN 8.0.RC3 及之前版本,msModelSlim 的代码已内置在 CANN 包中,此时只安装 CANN 即可。 Gitee+1
- 在 CANN 8.0.RC3 之后版本,推荐使用 “开源 msModelSlim + CANN” 的方式,即需从源码安装。 Gitee+1
- 安装过程中,请确保使用的 Python 版本、依赖库(如 PyTorch、torch_npu)与 CANN 相兼容。
在安装完成之后可以使用如下的代码进行验证
暂时无法在飞书文档外展示此内容
建议在 install.sh 安装前先确认 NPU 驱动和 torch_npu 环境是否正确,避免安装后运行报错。
模型加载与显存分配
模型需加载到 NPU 设备上运行。由于 Qwen2.5-72B 规模巨大,需进行多卡分布式分配。
暂时无法在飞书文档外展示此内容
PS:Qwen2.5-72B 至少需六张 32G 显存卡才能完成加载,建议 8 卡配置以留出量化空间。
校准数据准备:量化的“地基”
校准数据是量化精度的关键,它决定了激活值的分布范围。 选取时应考虑业务场景的代表性,例如:
- 中文问答:
ceval→teacher_qualification.jsonl - 英文理解:
boolq_lite - 代码生成:选取代码生成任务样本
推荐样本数:10~50 条。样本过少会导致量化误差,过多则增加时间成本。
暂时无法在飞书文档外展示此内容
数据条目单个 Token 长度打印
暂时无法在飞书文档外展示此内容

AntiOutlier:离群值抑制机制
量化过程中最常见的问题之一,是权重或激活值中存在离群点(Outlier),导致量化范围失衡。 为此,ModelSlim 提供了 AntiOutlier 模块,通过 SmoothQuant、AWQ、CBQ 等算法进行分布抑制。
常见方法对比如下:
| 算法 | 原理 | 适用场景 |
|---|---|---|
| m1: SmoothQuant | 平滑化通道尺度,抑制激活峰值 | 通用LLM模型 |
| m3: AWQ | 基于权重重要性自适应量化 | W8A16/W4A16场景 |
| m5: CBQ | 通道平衡量化 | 精度敏感任务 |
| m6: FlexSmooth | 自适应平滑策略 | 超大模型量化 |
配置示例:
暂时无法在飞书文档外展示此内容
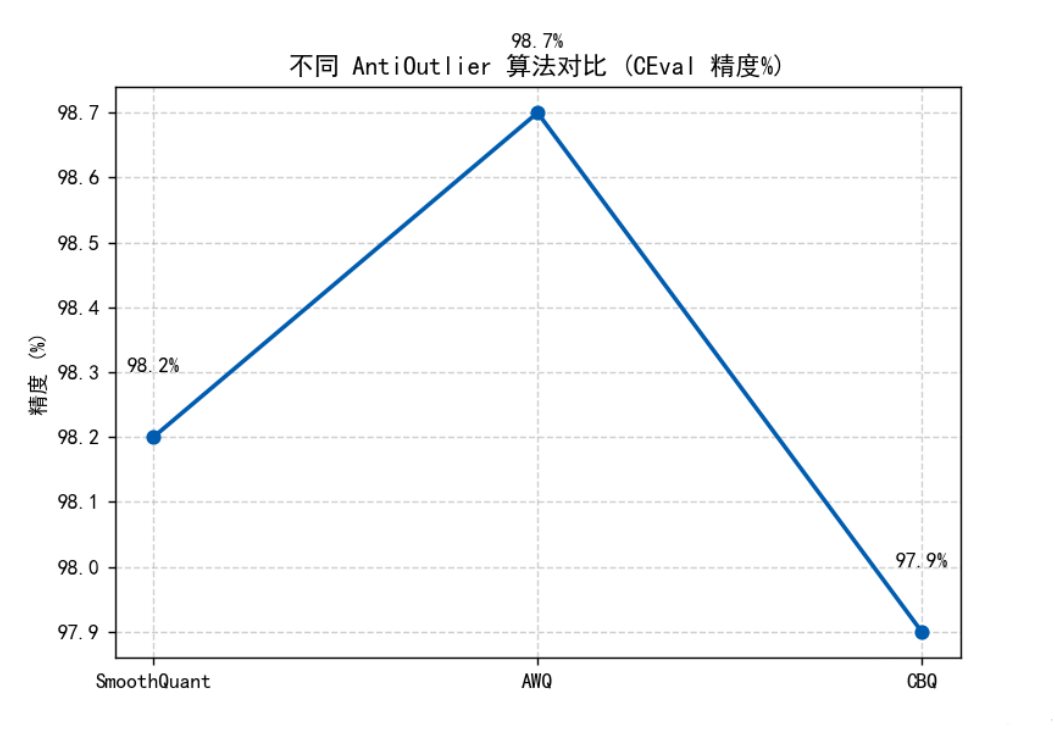
PS:对于 Qwen2.5 系列模型,SmoothQuant(m1/m4)在中等规模模型中表现良好,而 AWQ 在超大模型上精度更稳定。
QuantConfig:核心量化参数解析
量化参数的配置决定了压缩后的模型表现。 其中最关键的是 a_bit、w_bit(精度位宽)与 act_method(激活量化算法)。
暂时无法在飞书文档外展示此内容
PS:
- LLM 场景推荐
act_method=3(min-max 与 histogram 混合量化)。 - 若模型层过深,可适当设置
disable_level='Lx'自动回退精度敏感层。
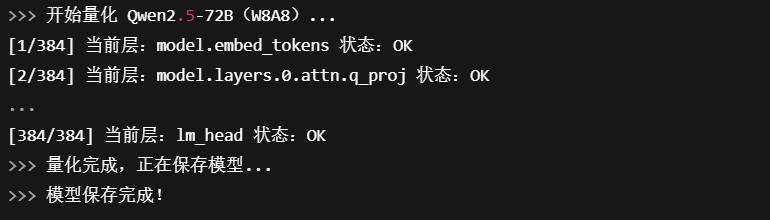
运行与模型保存
暂时无法在飞书文档外展示此内容
disable_level='L0' 表示不回退任何层。 若精度下降明显,可尝试 L5~L10,逐步回退对量化敏感的线性层。
四、量化效果与性能评估
经过实测(以 Qwen2.5-72B 为例),量化后模型在推理性能与资源利用率上都有显著提升。
| 指标 | FP16 | W8A8 (ModelSlim) | 提升比例 |
|---|---|---|---|
| 显存占用 | 100% | 58% | ↓42% |
| 推理时延 | 1.00x | 0.67x | ↑33% |
| 精度 (CEval 平均分) | 100 | 98.7 | -1.3 |
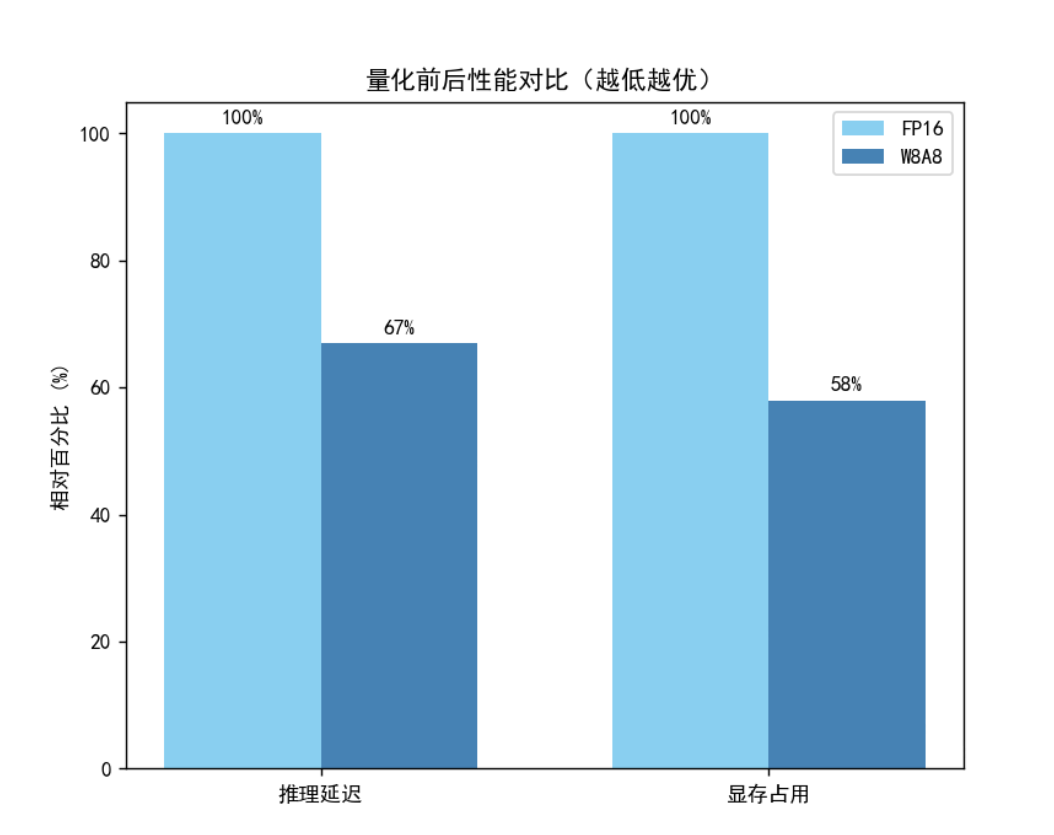
可见:W8A8 量化在几乎不损失精度的前提下,大幅减少显存占用与延迟,尤其适合多卡并行推理场景。
控制台输出日志片段代码,可以更直观的看到量化过程
暂时无法在飞书文档外展示此内容
推理耗时统计代码
暂时无法在飞书文档外展示此内容

五、常见问题
| 问题 | 原因分析 | 解决方案 |
|---|---|---|
| 模型加载报错 | 显存不足或 device_map 配置不当 | 减少参与量化卡数或调整 max_memory |
| 精度下降明显 | 量化范围不合理或缺少离群值抑制 | 启用 AntiOutlier 模块或更换 m4/m6 算法 |
| 量化时间过长 | 校准数据过大或 I/O 延迟 | 控制样本数量 ≤ 50 |
| 生成模型无法加载 | save_type 格式不兼容 | 使用 safe_tensor 保存格式 |
六、结语:让模型更“轻”、让推理更“快”
量化不是简单的压缩,而是一场“性能与精度的再平衡实验”。 通过 ModelSlim,我们可以在不改动训练流程的前提下,让超大模型在昇腾硬件上稳定、高效运行。
这不仅让 AI 模型的部署更“轻盈”,更体现了昇腾生态在软硬件协同优化上的潜力。 未来,随着 CANN 与 ModelSlim 工具链的持续升级,量化将不再是性能妥协,而会成为推理加速的“标准配置”。
“性能优化的尽头,是对每一层权重的理解。”
注明:昇腾PAE案例库对本文写作亦有帮助。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)