Agent Memory 是什么?一文讲清它与 RAG、上下文工程、LLM Memory 的本质区别
通过新一代AI智能体记忆系统的核心架构。
在过去一年里,一个深刻的转变正在AI领域悄然发生:记忆(Memory)从可选模块迅速变成了Agent系统的基础设施。这一转变不仅仅是技术迭代的产物,更标志着我们正在进入一个全新的智能系统时代。
概念辨析:智能体记忆 ≠ RAG ≠ 长上下文
在大量工程实践中,记忆一词常被简化为几个具体实现:一个向量数据库加上相似度检索(RAG),或者干脆等同为更长的上下文窗口、更大的 KV cache。
这些技术与真正意义上的智能体记忆之间确实存在交集,但也有着根本性的差异。
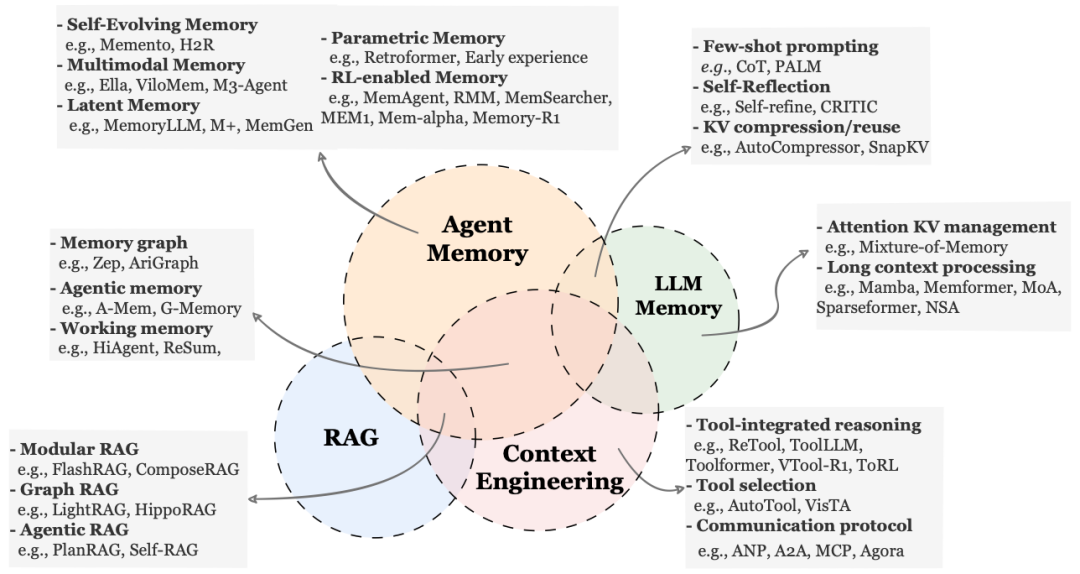
核心概念对比
| 维度 | Agent Memory (智能体记忆) | LLM Memory (模型内部记忆) | RAG (检索增强生成) | Context Engineering (上下文工程) |
|---|---|---|---|---|
| 本质定位 | 持久且自我演化的“认知状态” | 模型内部的长序列处理机制 | 静态知识访问模块 | 当下推理的外部脚手架 |
| 研究重点 | 交互中的更新、整合、纠错与抽象 | 计算过程中序列信息的保留与利用 | 从外部库检索信息以提升事实性 | 窗口受限时的提示词组织与信息压缩 |
| 时域跨度 | 跨任务、长周期的一致性维护 | 单次或有限次推理(Session内) | 通常为即时检索,缺乏时间感知 | 针对“此刻”输入(单次推理) |
| 状态机制 | 有状态(Read-Write-Update) | 针对长距离依赖的内部建模 | 无状态(通常为只读检索) | 临时状态(随Session结束重置) |
| 演化能力 | 具备自我演化机制,能将经历转化为知识 | 无(即便无Agent行为也成立) | 间接(需手动更新外部文档) | 无(优化接口而非提升能力) |
| 系统角色 | 支持学习与自主性的内部基底/基础设施 | 模型的内部计算动态 | 知识辅助组件 | 针对窗口限制的工程优化手段 |
深入理解差异
智能体记忆:持久且自我演化的认知状态
智能体记忆的核心是一个持久(persistent)且能自我演化(self-evolving)的认知状态。它不仅仅是信息的"存储",更是一个有状态的读写基底。智能体可以在与环境的交互中不断更新、整合、纠错和抽象其中的信息。
简单来说,智能体记忆关心的是:
- “智能体知道什么”
- “经历过什么”
- “这些认知如何随时间变化”
特点:
- 自我演化 从经历中学习,掌握用户的习惯和偏好
- 有状态 支持读写更新,可以修正记忆中的错误理解
- 时间感知 理解时序关系,知道"bug修复"发生在"方法创建"之后
模型内部记忆 (LLM Memory):长序列处理的内部机制
这指的是大模型在处理长上下文时的内部计算机制,包括:
- 注意力机制 如何在长序列中保持对早期token的关注
- KV Cache 如何高效缓存中间计算状态
- 位置编码 如何理解token之间的相对位置关系
局限:
- 受限于上下文窗口大小
- 一旦会话结束或超长截断,信息永久丢失
- 无法跨会话、跨任务积累经验
Context Engineering (上下文工程) :临时的推理工作区
长上下文窗口本质上是模型在单次或有限次推理中处理长序列信息的能力。它更像一个 临时的 工作区,用于在计算过程中避免早期信息的衰减。
一旦会话结束或重置,其中的信息便会丢失,无法实现跨任务、跨周期的交互式学习。
RAG(检索增强生成):静态的知识访问模块
RAG传统上作为一种只读(read-only)机制运行,其主要功能是从外部静态知识库中检索事实性信息。虽然它可以作为记忆系统的一部分,但它:
- 缺乏时间感知能力
- 无法在推理过程中更新自身知识库
它更像一个知识访问模块,而非一个能够记录经验并随之成长的完整记忆系统。
统一分析框架:Forms-Functions-Dynamics三角框架
为了系统性地理解智能体记忆,学术界提出的**Forms–Functions–Dynamics(三角框架)**提供了一个强大的统一视角。它试图分别回答三类核心问题:
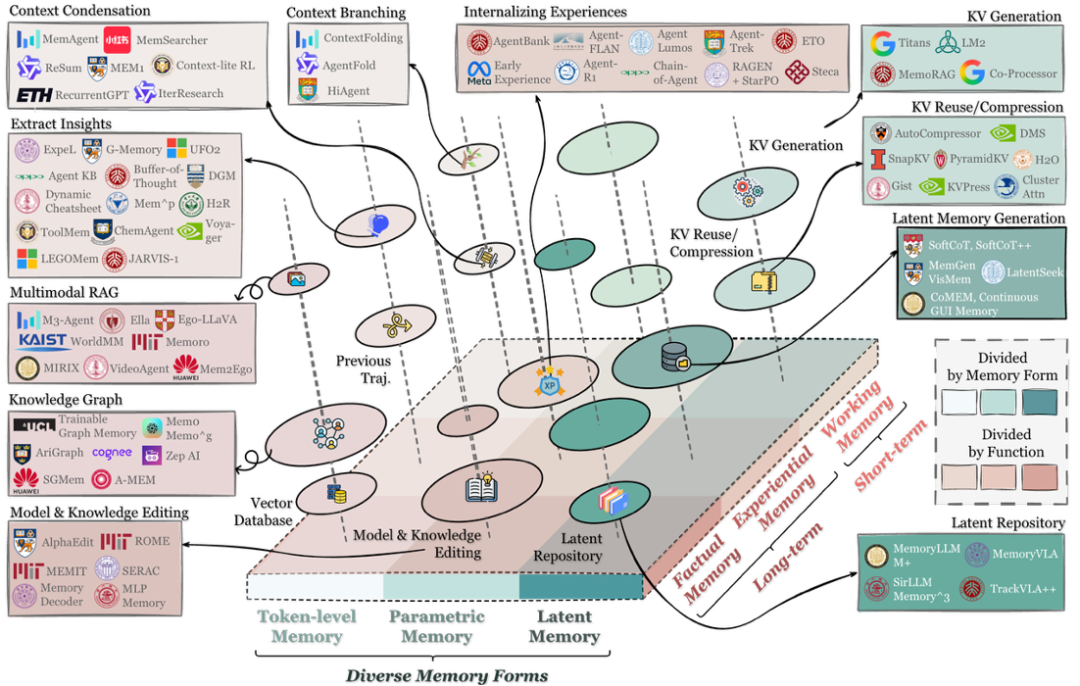
记忆以什么形式存在(Forms)——What Carries Memory? 是外部 token、参数,还是潜在状态?
记忆解决什么问题(Functions)——Why Agents Need Memory? 它服务于事实一致、经验成长,还是任务内工作记忆?
记忆如何运转与演化(Dynamics)——How Memory Evolves? 它如何形成、如何被维护与更新、又如何在决策时被检索与利用?
Forms(形态):记忆的载体是什么?
1. Token-level Memory:最显式的记忆层
信息以持久、离散、可外部访问与检查的单元存储(文字token、视觉token、音频帧等)。
优势:
- ✅ 透明度高(能看到存了什么)
- ✅ 可编辑(能删改、能纠错)
- ✅ 易组合(适合作为检索、路由的中间层)
三种组织方式:
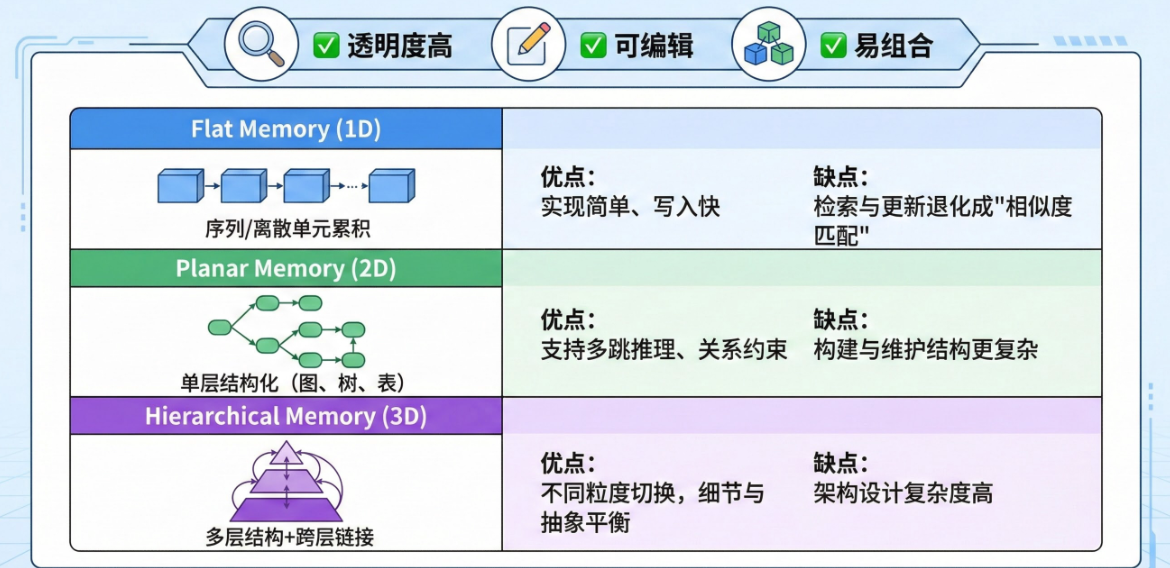
| 类型 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| Flat Memory (1D) | 序列/离散单元累积 | 实现简单、写入快 | 检索与更新退化成"相似度匹配" |
| Planar Memory (2D) | 单层结构化(图、树、表) | 支持多跳推理、关系约束 | 构建与维护结构更复杂 |
| Hierarchical Memory (3D) | 多层结构+跨层链接 | 不同粒度切换,细节与抽象平衡 | 架构设计复杂度高 |
2. Parametric Memory:把记忆写进权重
信息存储在模型参数中,通过参数空间的统计模式编码。
- 优点:零延迟推理,知识已成为模型的一部分
- 缺点:更新成本高、难编辑、面临灾难性遗忘风险
3. Latent Memory:藏在隐状态的动态记忆
记忆以模型内部隐状态、连续表示存在,可在推理过程中持续更新。
- 优点:比token-level更紧凑,比parametric更容易在推理期更新
- 缺点:可解释性和可审计性较差
Functions(功能):记忆解决什么问题?
该框架的核心观点是:抛弃简单的长/短期二分法,转向从功能角色来分类记忆。
1. Factual Memory(事实记忆)
目标:让智能体记住事实,维持一个可更新、可核查的外部事实层。
包含内容:
- 用户偏好
- 环境状态
- 代码库结构
- 交互轨迹等
失败模式:当事实记忆缺失时,智能体会在对话中遗忘、误引甚至编造事实。
2. Experiential Memory(经验记忆)
目标:让智能体吃一堑,长一智。
通过积累和提炼历史执行轨迹、策略与结果,智能体可以实现能力的增量提升和跨任务迁移。
按抽象层级分为三类:
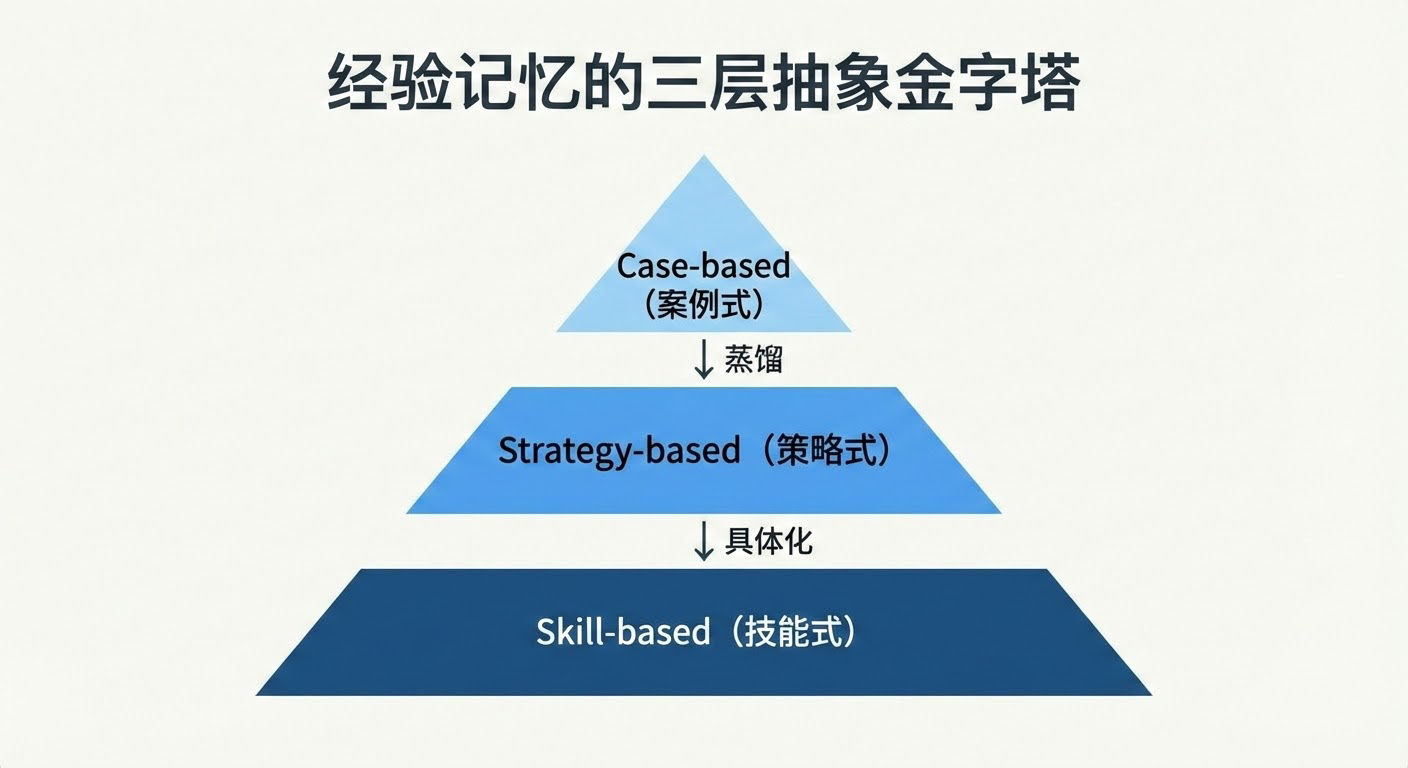
- Case-based:近乎原始的历史记录,用作上下文范例
- Strategy-based:从轨迹中蒸馏可迁移的推理模式
- Skill-based:可执行的技能(代码片段、API调用序列)
3. Working Memory(工作记忆)
目标:在单次任务执行中有效管理"工作区"。
当即时输入的信息过大、过杂(长文档、网页DOM流)时,通过建立可写的临时空间来压缩、组织信息,避免信息过载。
Dynamics(动态):记忆系统如何运转?
动态维度揭示了记忆的完整生命周期——它不是一个静态的存储库,而是一个持续反馈的循环过程。
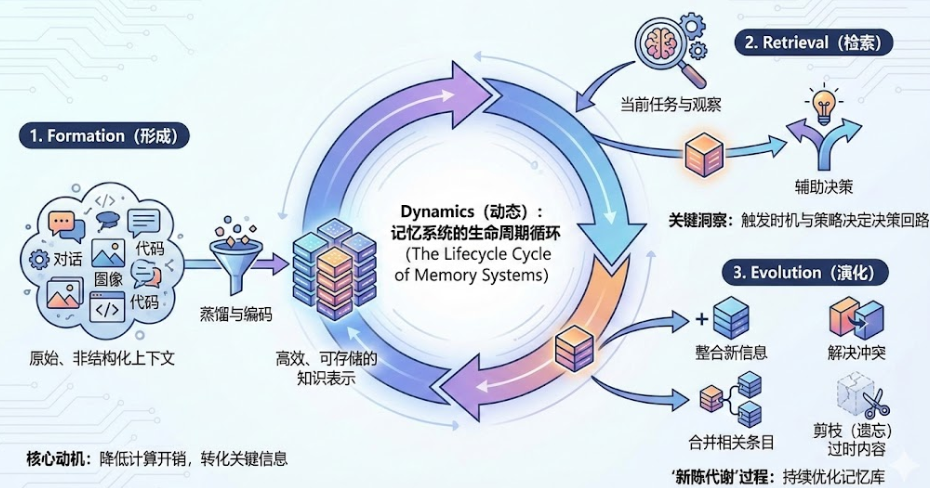
1. Formation(形成)
将原始、非结构化的上下文(对话、图像、代码)蒸馏并编码成高效、可存储的知识表示。
核心动机:降低计算开销,将关键信息转化为更易于利用的形式。
2. Retrieval(检索)
根据当前任务和观察构造查询,从记忆库中返回相关内容以辅助决策。
关键洞察:检索的触发时机和策略直接决定了记忆能否在关键时刻进入决策回路。
3. Evolution(演化)
记忆系统的"新陈代谢"过程:
- 整合新信息
- 解决冲突
- 合并相关条目
- 剪枝(遗忘)过时或低价值的内容
开源记忆框架:从理论到实践的桥梁
随着智能体记忆技术的成熟,一系列开源项目应运而生,让开发者能够轻松为AI应用添加持久记忆能力。
Mem0:通用的AI记忆层
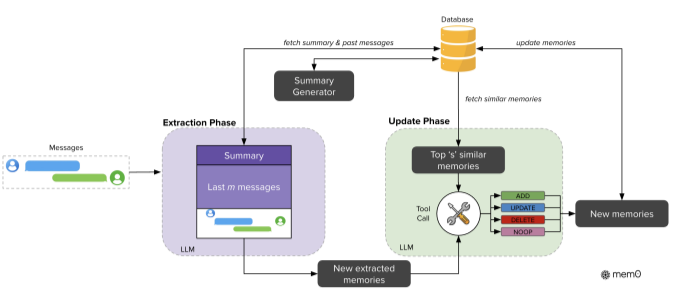
核心特性
- 智能记忆层:使AI助手和智能体能够维持个性化交互
- 长期记忆管理:专为AI智能体保留信息而设计
- 上下文感知:提供从持续对话中回忆和整合关键信息的能力
- 可扩展架构:专为生产级AI应用设计
技术实现
- 云集成:支持Amazon ElastiCache for Valkey和Amazon Neptune Analytics
- 动态记忆操作:自动提取、整合和检索信息
- 单行代码启用:
memori.enable()即可开启持久记忆
memU:智能体记忆框架
核心架构由三层组成:资源层 → 内存项层 → 内存分类层
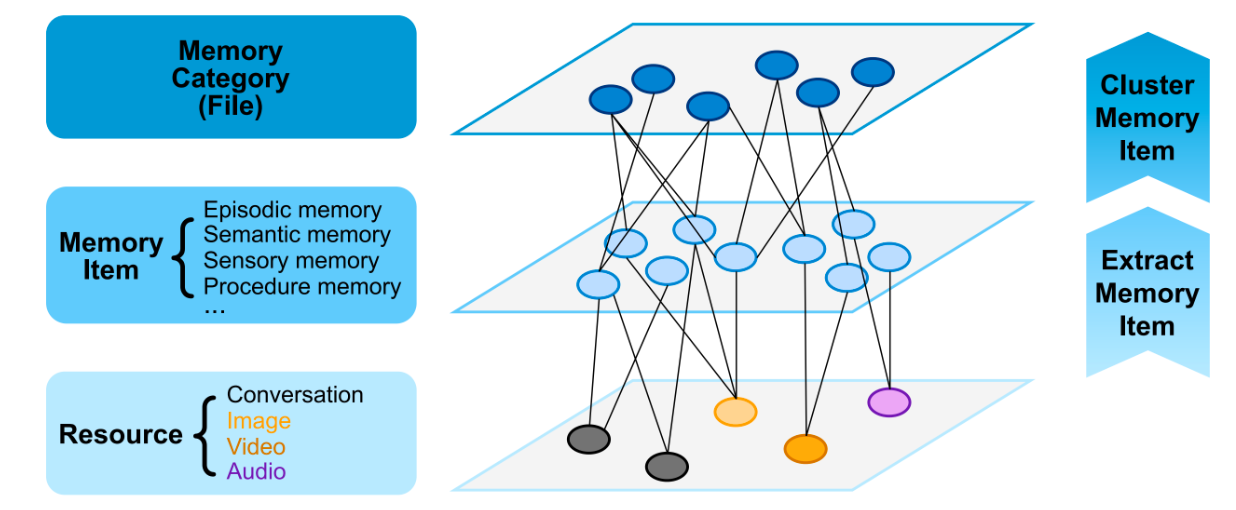
- 资源层:多模态原始数据仓库
- 记忆项层:离散提取的记忆单元
- 记忆类别层:聚合的文本记忆单元
核心特性
- 高精度记忆:在 Locomo 数据集上达到 92.09% 的平均准确率
- 快速检索:毫秒级的记忆访问响应
- 可追溯性:从原始数据到记忆项再到文档的完整追踪链路
- 多模态支持: 统一处理文本、图像、音频、视频等多种数据格式
- 自我演进: 基于使用模式自适应优化记忆结构
PowerMem:企业级混合记忆架构
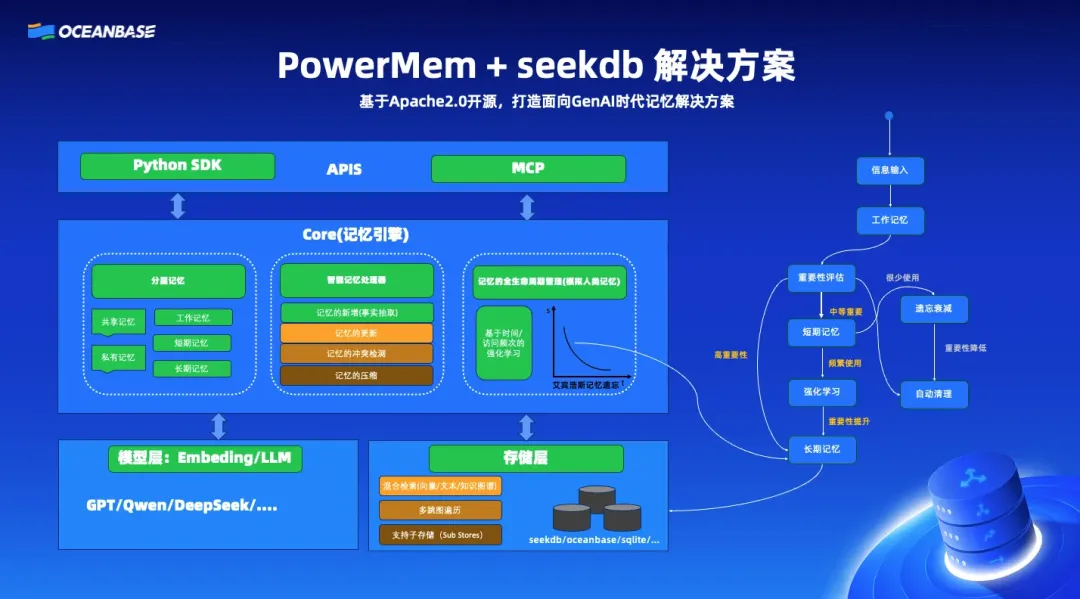
核心特性
- 混合存储架构:
- 向量检索(Vector Retrieval)- 语义相似度搜索
- 全文搜索(Full-text Search)- 关键词查询
- 图数据库(Graph Database)- 关系映射
- 艾宾浩斯遗忘曲线:模拟人类记忆衰减模式
- RAG 支持:增强检索上下文生成
- 企业级可靠性:基于 OceanBase 数据库技术
技术优势
- 多模态检索能力:结合语义、关键词和关系三种检索方式
- 记忆生命周期管理:智能的记忆重要性评估和遗忘机制
- 框架集成:支持 AgentScope 等主流智能体框架
- MCP 协议兼容:符合 Model Context Protocol 标准
三大框架对比
| 特性 | Mem0 | memU | PowerMem |
|---|---|---|---|
| 定位 | 通用记忆层 | AI记忆框架 | 企业级混合架构 |
| 核心优势 | 简单易用 | 场景优化 | 混合检索架构 |
| 特色功能 | 单行代码启用 | 自我演进、可追溯记忆 | 艾宾浩斯遗忘曲线 |
| 目标场景 | 通用AI应用 | 智能体应用 | 企业级应用 |
前沿展望:记忆系统的未来方向
从记忆检索到记忆生成
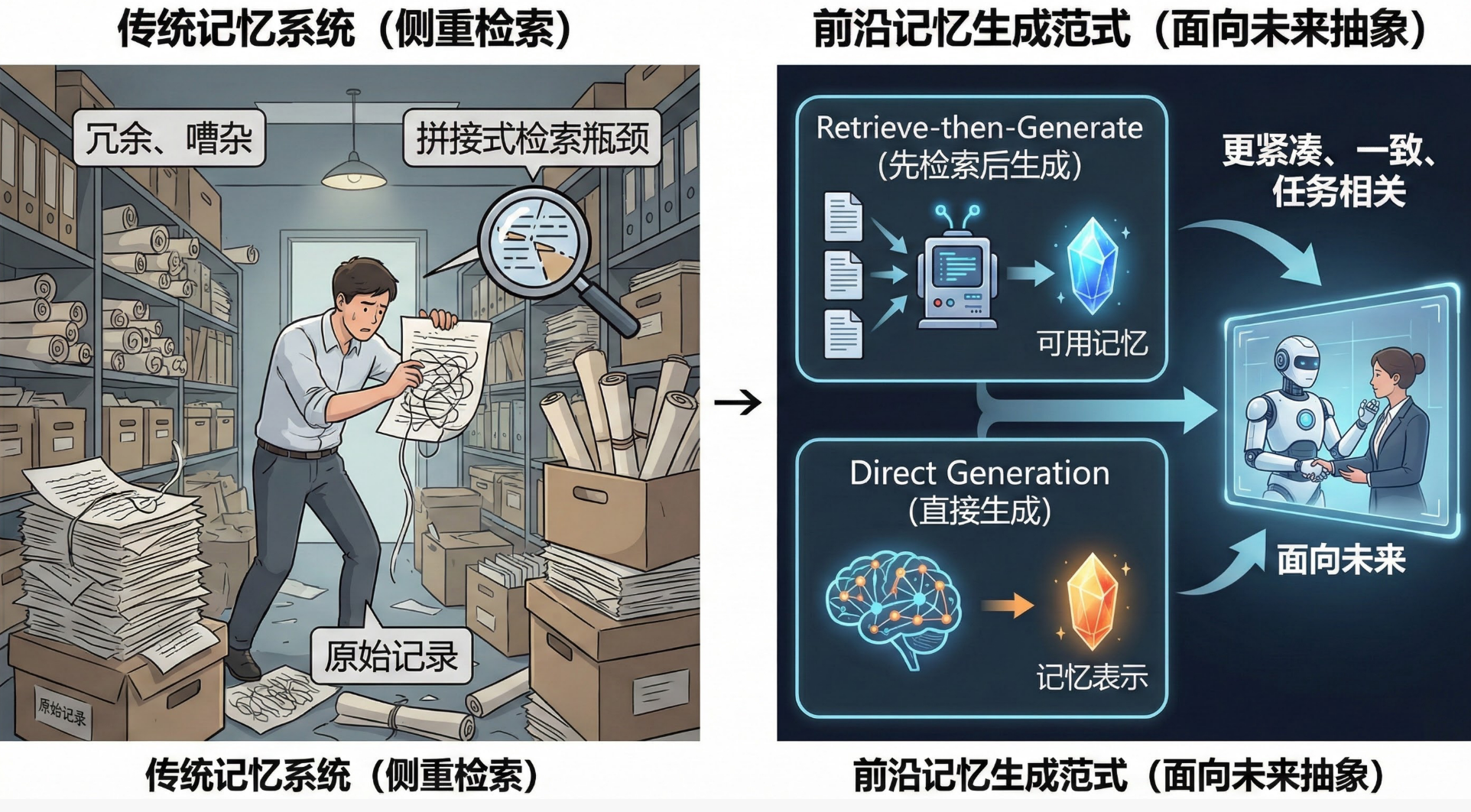
传统记忆系统侧重于检索——从历史记录中准确地获取相关片段。但这种方式存在瓶颈:
- 原始记录往往是冗余、嘈杂且与当前任务不完全对齐的
- 拼接式检索容易把上下文塞满,却不一定让模型更会做事
前沿的记忆生成范式依赖于面向未来的抽象:
Retrieve-then-Generate(先检索后生成)
如ComoRAG和G-Memory等系统,将检索到的材料重写为更紧凑、更一致、更任务相关的可用记忆。
Direct Generation(直接生成)
不显式检索,直接从当前上下文/交互轨迹中生成记忆表示。
强化学习驱动的自动化记忆管理
这标志着从人工写规则到Agent自己管记忆的演进。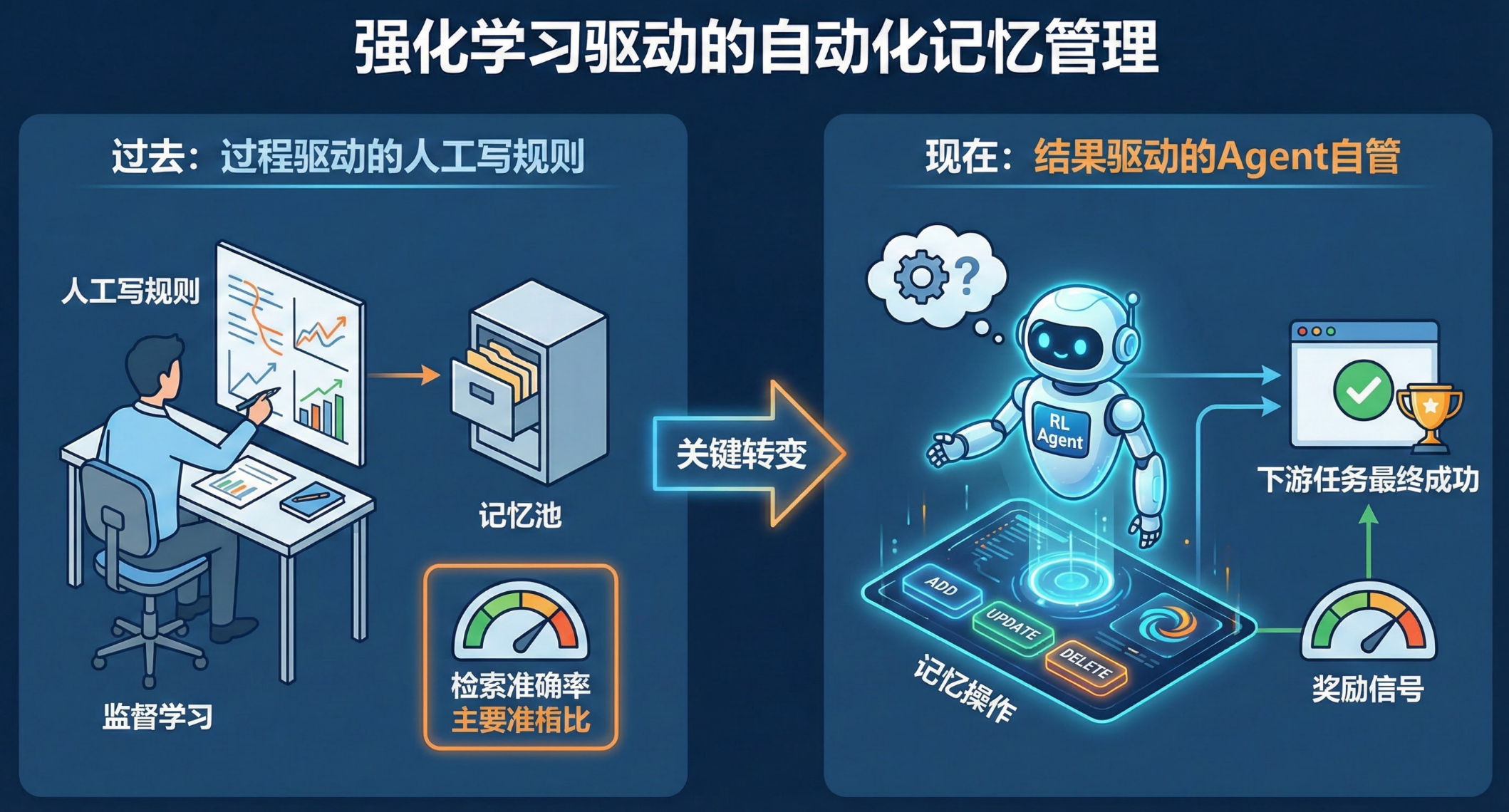
关键转变
- 从过程驱动的监督学习转向结果驱动的强化学习(RL)
- 智能体通过试错来学习最优的记忆操作策略(ADD/UPDATE/DELETE)
- 奖励信号不再是检索的准确率,而是下游任务的最终成功与否
多模态与多智能体共享记忆
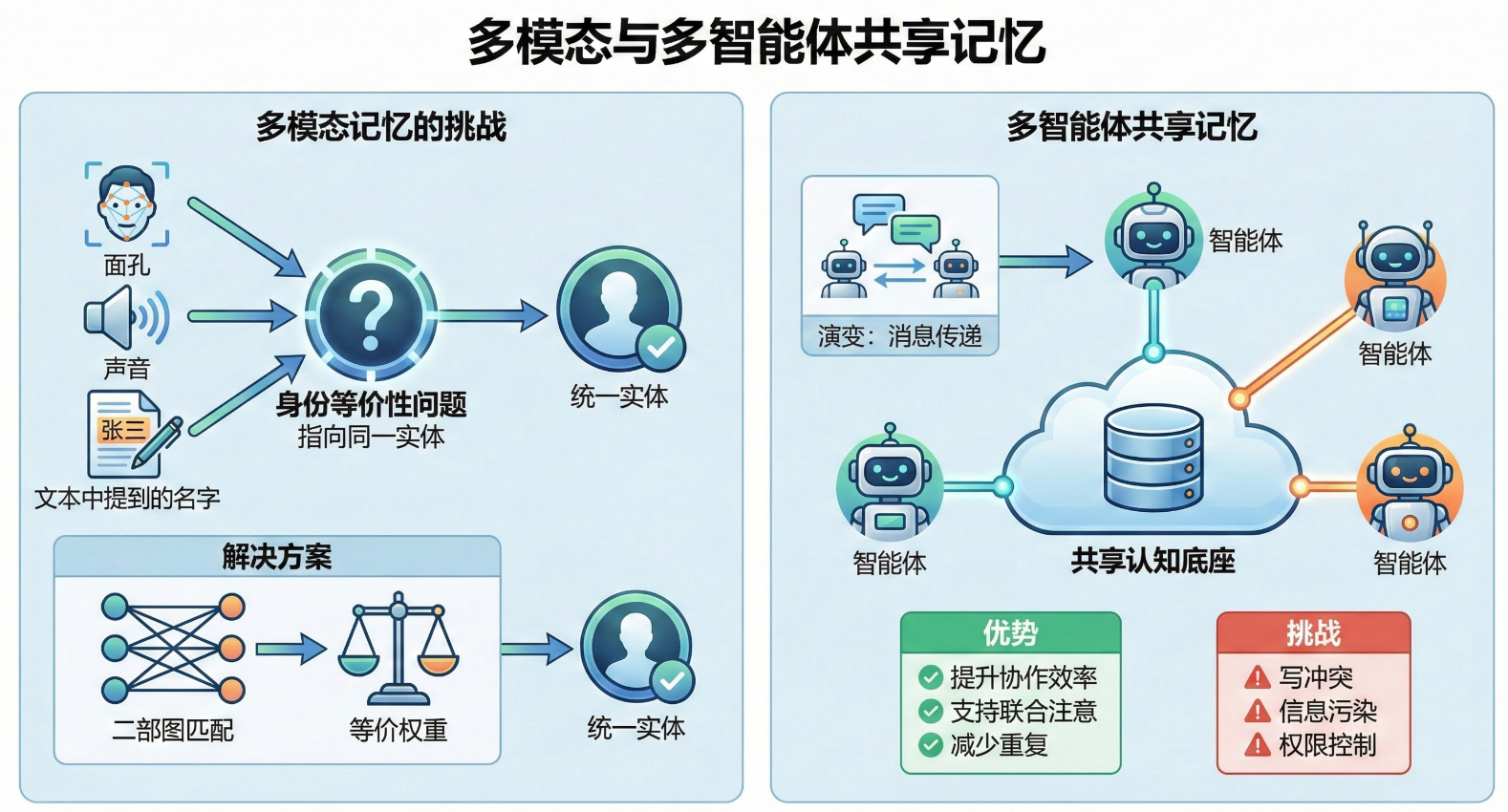
多模态记忆的挑战
核心难题是身份等价性(identity equivalence)问题——即识别出:
- 一个人的面孔
- 声音
- 文本中提到的名字
指向同一实体。解决方案通常涉及二部图匹配和等价权重等机制。
多智能体共享记忆
从智能体间的消息传递演变为共享认知底座:
- 优势:提升协作效率、支持联合注意、减少重复
- 挑战:写冲突、信息污染、权限控制
可信记忆:安全、隐私与治理
当记忆变得持久化和个性化后,其风险从简单的事实性问题扩展到了隐私、安全和可审计性等更广泛的领域。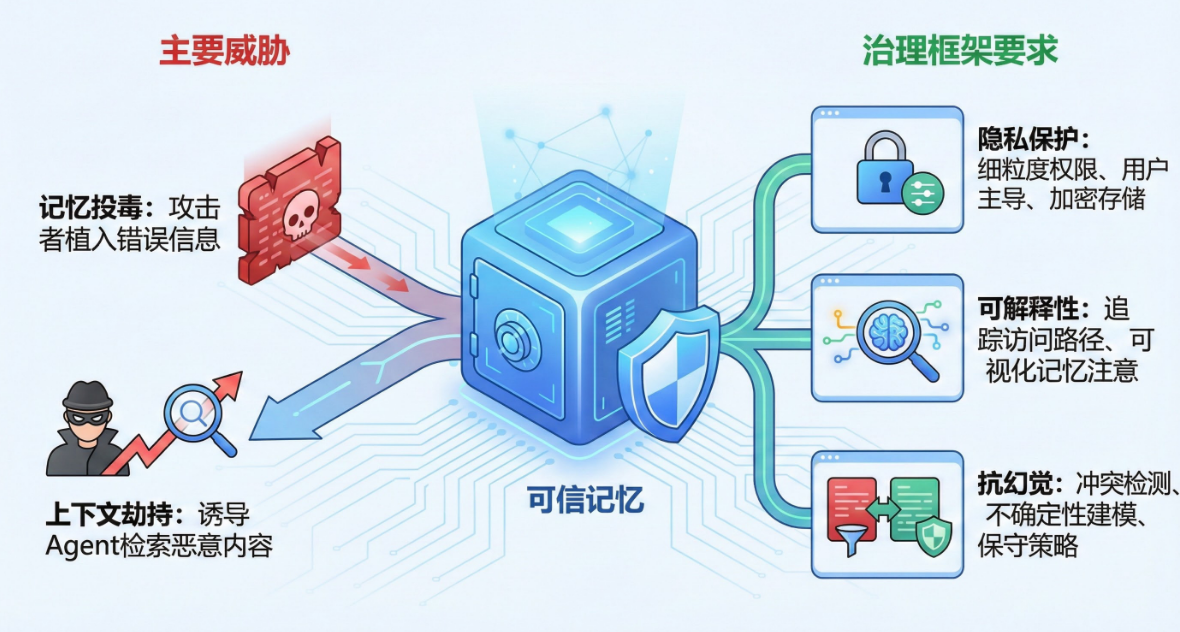
主要威胁
- 记忆投毒:攻击者植入错误信息
- 上下文劫持:诱导Agent检索恶意内容以执行危险操作
治理框架要求
- 隐私保护:细粒度权限、用户主导的保留策略、加密存储
- 可解释性:追踪访问路径、可视化记忆注意
- 抗幻觉:冲突检测、不确定性建模、保守策略
总结:将记忆视为智能体的第一公民
通过新一代AI智能体记忆系统的核心架构。我们看到,智能体记忆正在经历一场深刻的范式革命:
从外挂插件到核心基底
它不再是一个简单的外挂插件,而是演变为智能体实现长期能力、持续学习和行为一致性的核心基底(first-class primitive)。
催生Agent原生应用范式
这种转变正在催生一种新的Agent原生应用范式:
- 传统架构:数据库是被后端算法调用的被动组件
- Agent原生架构:记忆层是与Agent层并列、相互协作的主动核心层
展望未来
顶尖AI系统的差异化优势,将不再仅仅取决于其底层大模型的性能。更关键的,将在于:
- 其记忆系统的复杂与精妙程度
- 它作为可信赖的人类协作伙伴,实现共同成长的能力
记忆,正是通往这一未来的基石。
如果你想深入学习 AI智能体记忆系统、RAG架构设计、Agent开发、企业级AI应用实战 等前沿技术,欢迎关注我们!
我们提供系统的课程体系,帮助你从零开始掌握:
- AI Agent 开发:从记忆系统到决策引擎,掌握Agent完整架构设计与实战。
- RAG 技术进阶:从基础检索到混合架构,构建高性能知识库问答系统。
- 大模型微调:掌握 Fine-tuning、RL等 技术,打造专属垂直领域模型。
- 企业项目实战:15+ 项目实战(多模态RAG、实时语音助手、个性化AI助手、智能客服系统等),将理论知识应用到实际项目中,解决真实业务问题。
立即加入👉 赋范空间,开启你的 AI 进阶之旅!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)