新兴存储全景与未来架构走向
报告的核心结论是,未来没有一种“万能”的存储技术。AI计算系统将依赖于DRAM、NAND与多种新兴存储技术(如HBM, CXL, PIM, SOM/MRAM等)的“组合创新”,通过架构层面的深度融合来满足不同场景对性能、能效和成本的要求。为了支撑更强大的AI,计算、内存和存储必须进行系统性的协同革新。如果你对其中某一种具体的技术(比如HBM是如何工作的,或者PIM如何实现“存内计算”)特别感兴趣,
报告的主要逻辑和核心内容可以概括为下图: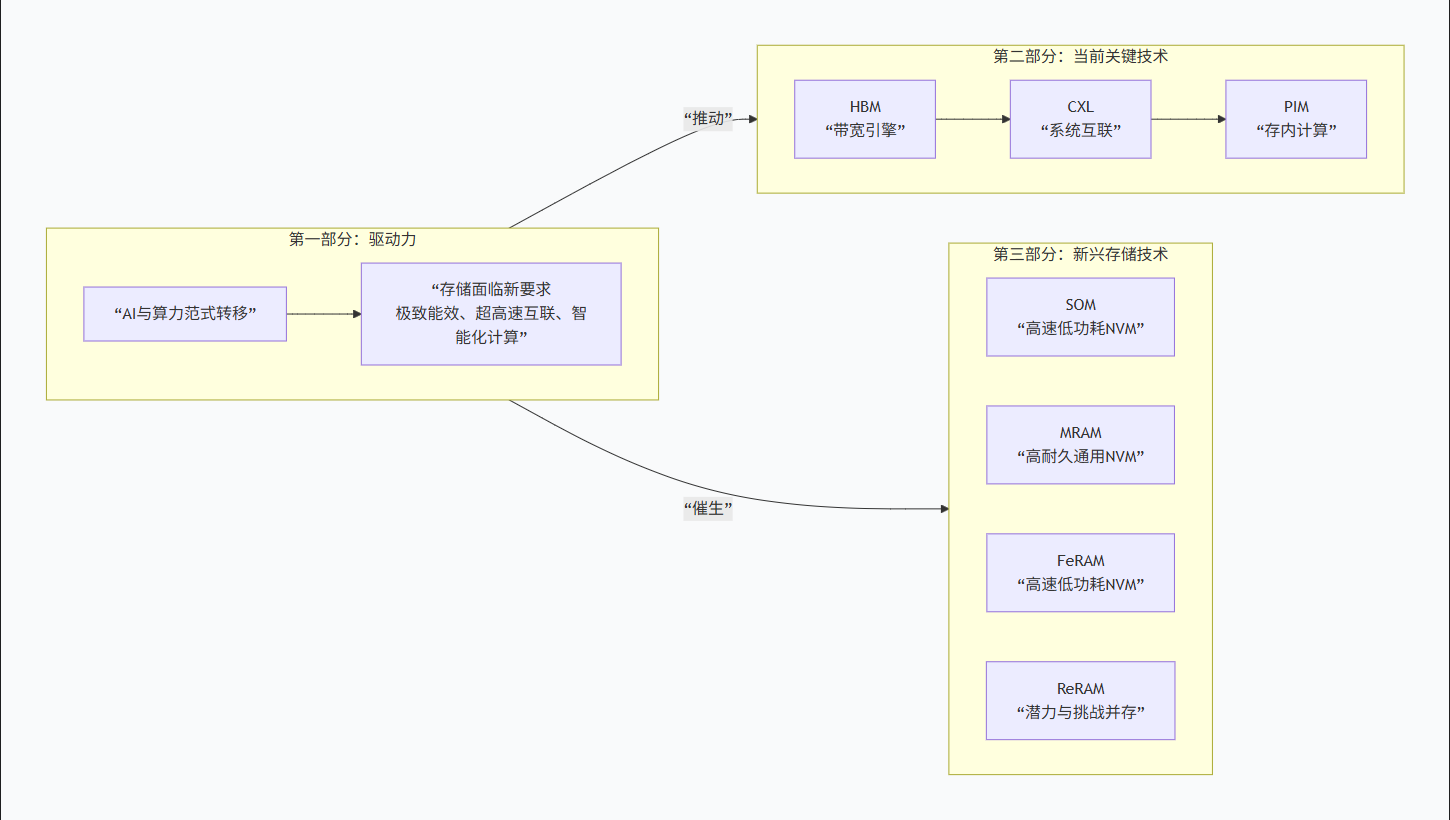
🔍 新兴存储技术盘点
报告重点分析了四种有潜力的新兴存储技术,它们的定位和特点各不相同:
-
SOM:目标是取代PCM,特点是结构简化、能效极高,写入电流仅20μA,耐久性达10⁷次,适合作为AI推理缓存或存储级内存。
-
MRAM:技术最成熟的非易失存储器,写入速度可媲美SRAM(10ns内),耐久性超过10¹⁴次,但主要挑战在于存储密度提升受限。
-
FeRAM:因新材料而复兴,拥有高速、低功耗、高耐久的特点,支持3D堆叠,在嵌入式存储和边缘AI场景有潜力,但需解决极化稳定性等工艺挑战。
-
ReRAM:虽具备结构简单和高密度潜力,但产业化受限于机制随机性大、参数一致性差等工程难题。
💎 总结与联系
报告的核心结论是,未来没有一种“万能”的存储技术。AI计算系统将依赖于 DRAM、NAND与多种新兴存储技术(如HBM, CXL, PIM, SOM/MRAM等)的“组合创新” ,通过架构层面的深度融合来满足不同场景对性能、能效和成本的要求。
这与你之前关注的Gemini 3 Flash(依赖高效的“Titans”架构处理长上下文)和NeurIPS模型优化(旨在降低计算和存储开销)在底层逻辑上是一致的:为了支撑更强大的AI,计算、内存和存储必须进行系统性的协同革新。
如果你对其中某一种具体的技术(比如HBM是如何工作的,或者PIM如何实现“存内计算”)特别感兴趣,我们可以深入探讨。或者,你也可以分享更具体的场景,我们可以一起分析哪种技术组合可能成为关键。
-----------------------------------
详细介绍:
过去十年,计算的瓶颈从处理器转向了内存。AI模型越来越大,数据越来越近,能效和带宽的压力正在重新定义系统架构。传统的冯·诺依曼模型难以应对密集的数据流动,DRAM 和 NAND 在性能和功耗上也逐渐逼近极限。此时,内存不再只是存储数据的容器,而是开始参与计算、调度资源、重构路径。
SK hynix 最近在 VLSI 技术会议上提出了他们对新兴内存技术的系统判断:既要解决传统存储的结构瓶颈,也要为未来的计算架构提供能效更优、路径更短的解决方案。从 HBM、CXL 到 SOM、MRAM、FeRAM,再到用于 AI 推理的 ACiM,这些不同类型的内存技术正在形成新的组合,推动内存从“配角”走向“平台”。
——————————————————
一、计算环境演进推动内存技术革新
过去数十年,半导体行业的每一次跃迁背后,几乎都能看到计算环境范式转移的身影。从PC时代到移动互联网,再到云服务与大模型AI的爆发,算力需求的急剧增长持续拉动内存市场扩容,成为驱动产业增长的核心引擎之一。根据SEMI与VLSI的数据预测,全球半导体市场规模预计将在2030年突破1万亿美元大关,生成式AI在其中的贡献不可小觑。
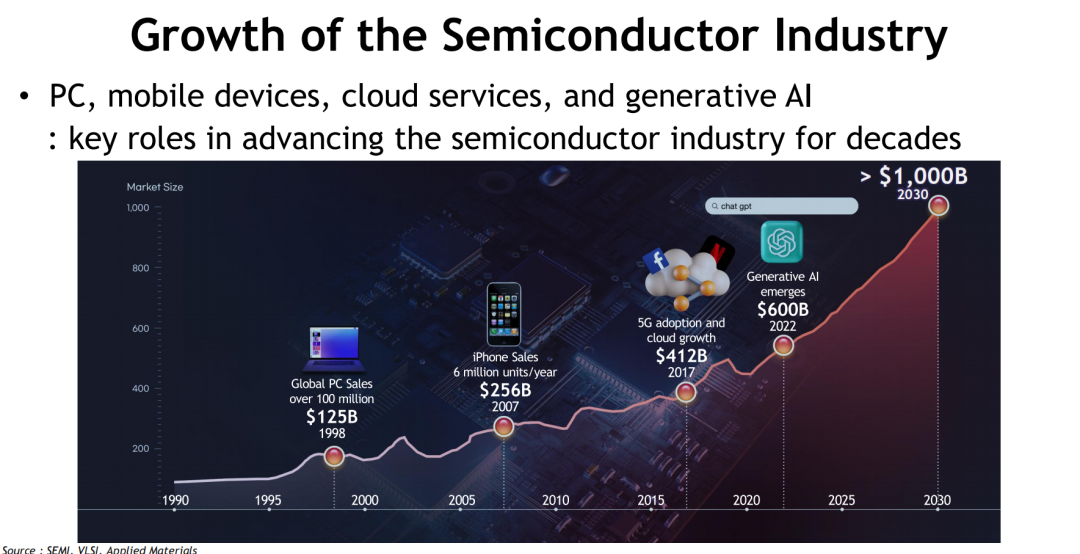
在此背景下,计算平台的重心正从传统的中心化云计算架构,向云边协同和终端智能延展。这一趋势催生出三个核心要求:“极致能效”、“超高速互联”与“智能化计算”,共同构建出新时代的信息处理范式。设备不再仅是算力终端,更成为数据处理与智能决策的前沿节点。
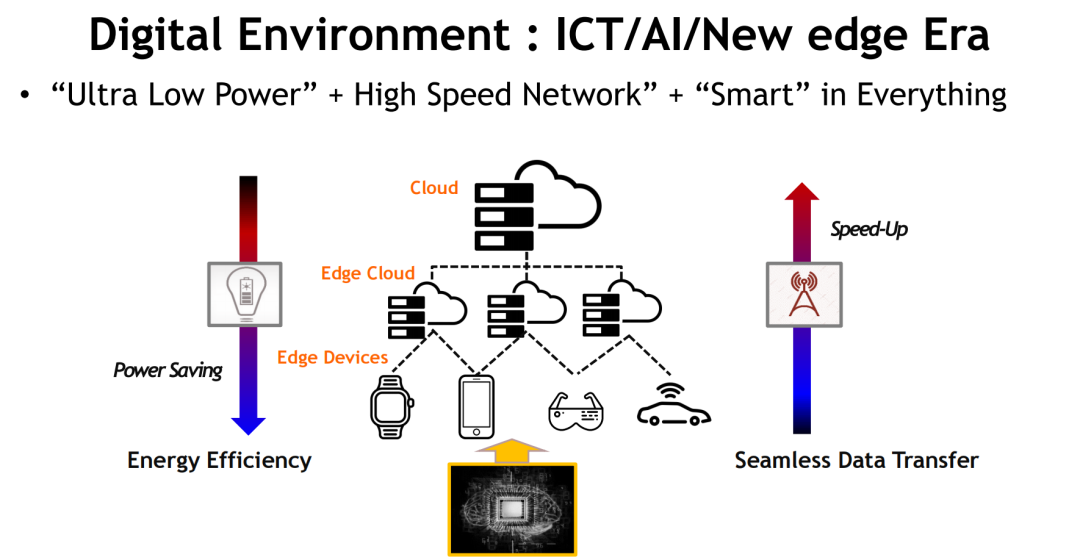
与此同时,AI负载的崛起带来了前所未有的数据读写压力,传统内存体系在带宽、延迟、能耗上的瓶颈日益凸显。内存不再是简单的存储容器,而是被重新定义为决定系统性能上限的“计算参与者”。这正是当前新型内存技术发展浪潮的起点,也是DRAM与NAND不断演进的根本动因。
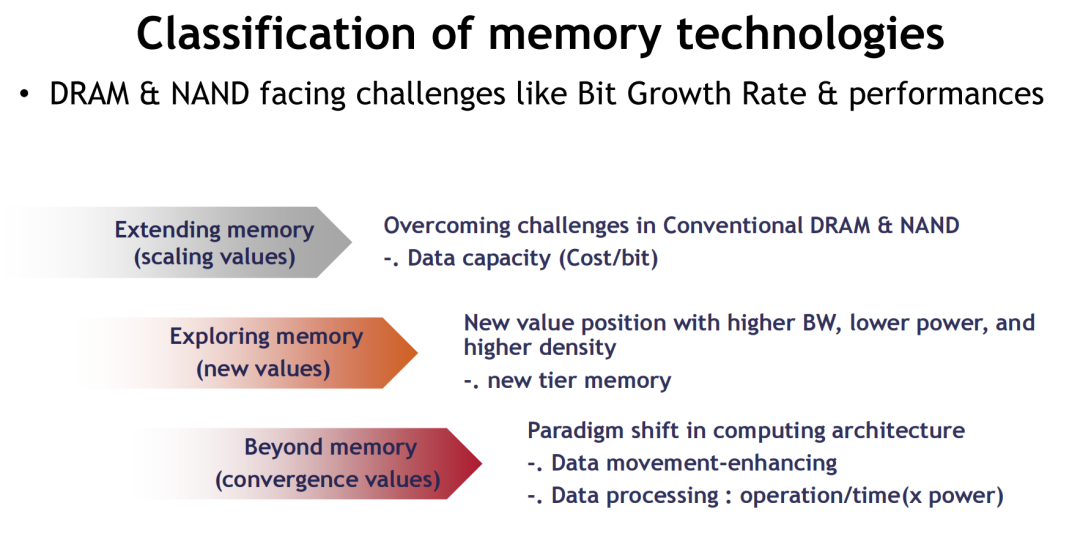
未来计算系统的竞争,实质上是围绕内存架构、数据路径与能效比展开的系统性博弈。谁能更快、更稳、更省地搬运与处理数据,谁就能掌握AI时代的算力制高点。
二、存储技术核心要素与平台演进
无论技术形态如何更迭,内存技术始终围绕着三大核心维度演进:成本(Cost)≈容量、性能(Performance)与功耗(Power)。这三者构成了产业发展的“铁三角”,在所有新旧架构切换与技术升级中始终未被打破。
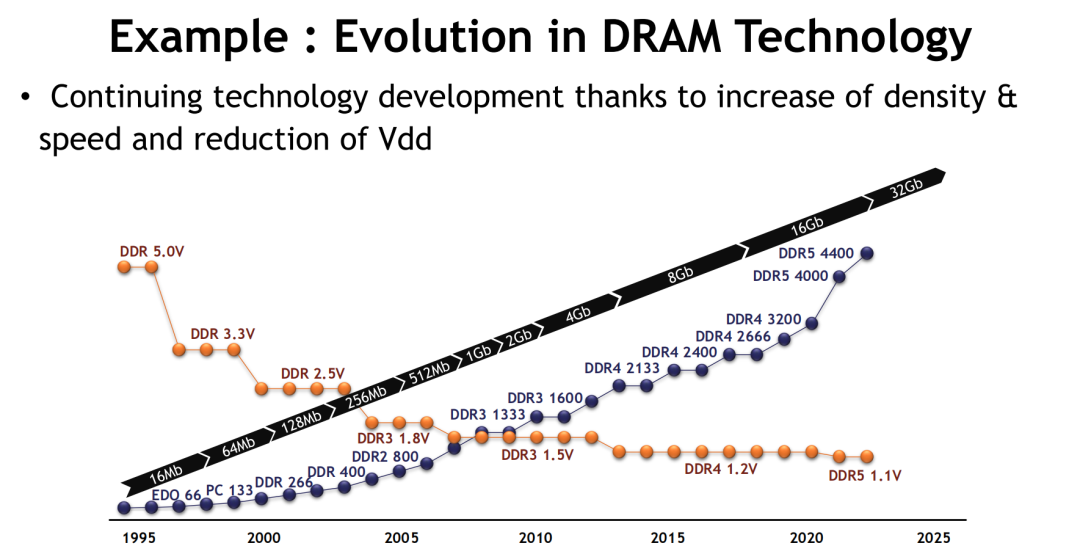
以DRAM为例,其演进路径清晰体现了性能与能效的双重提升。图像资料显示,自1995年起,DRAM频率从EDO 66MHz逐步提升至DDR5的6400MHz以上,同时工作电压从5.0V下降至当前主流的1.1V以下。这一过程不仅带来带宽的大幅跃升,也显著降低了单位能耗,为高性能计算系统提供了基础支撑。
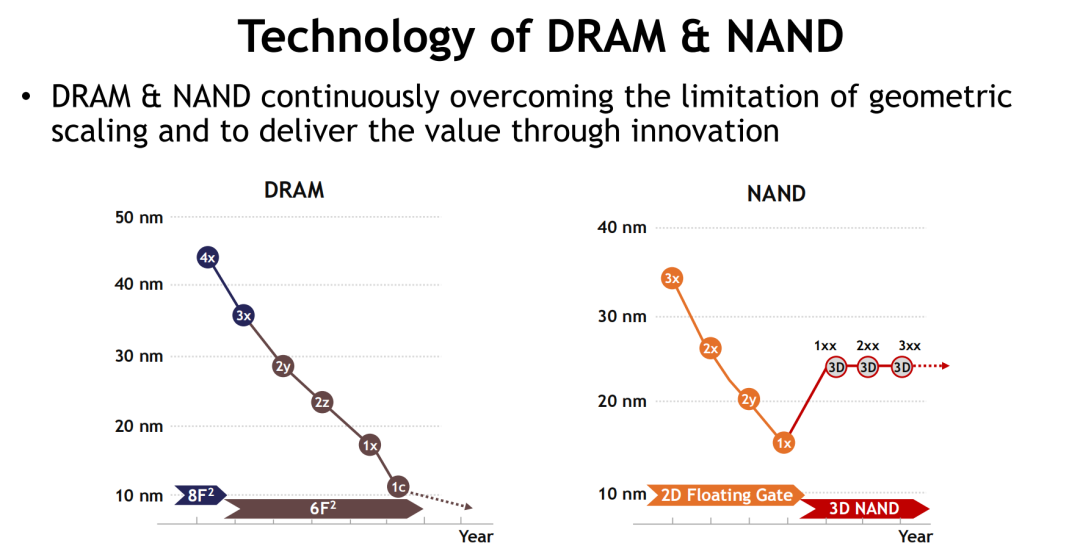
与此同时,NAND Flash的技术路线则以堆叠高度为突破口,成功摆脱二维微缩极限。当前主流的3D NAND架构通过Cell层数的持续增加,大幅提升单位面积存储密度,缓解了几何缩放带来的成本压力。得益于Wafer Bonding等关键工艺创新,NAND平台正加速向更高堆叠、更强可靠性与更快写入速度演进。
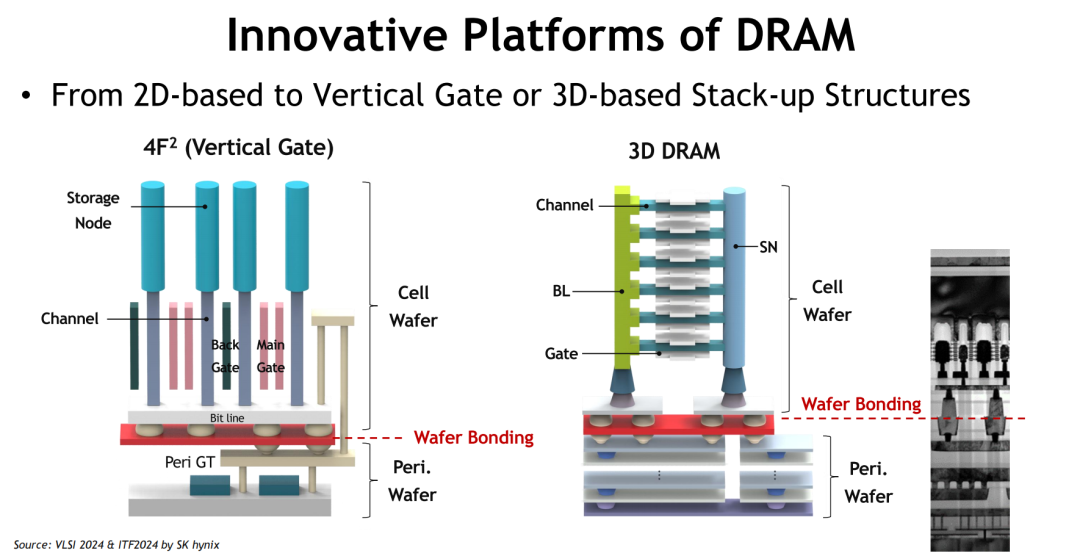
值得关注的是,无论是DRAM还是NAND,其平台创新路径均展现出两个共同特征:
-
从平面走向垂直堆叠:DRAM正在尝试4F² Vertical Gate和3D Stack结构,意图突破2D平台物理瓶颈;
-
从工艺优化走向架构重构:Wafer Bonding、Periphery-Cell分离等设计,旨在实现热管理、制程简化与良率提升的多重目标。
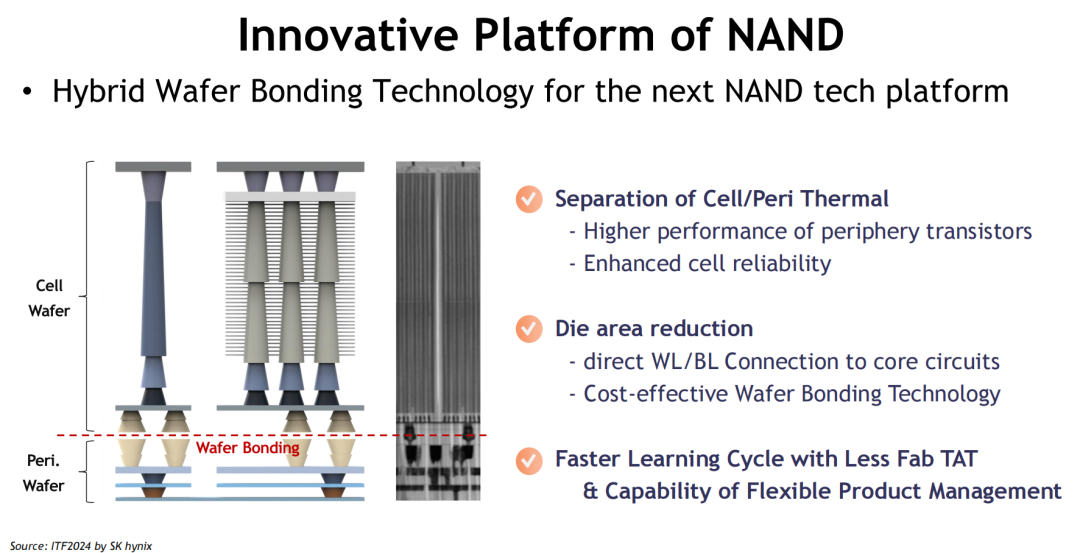
这种平台级别的结构创新,预示着内存产业正由“几何演进”转向“架构主导”。这不仅是对摩尔定律放缓的正面回应,也为新型存储技术的导入提供了技术土壤。
DRAM与NAND的持续演进并非线性路径,而是以“微缩极限”为边界,通过平台革新与功能重构延续其生命力。在AI与边缘智能需求主导的新周期中,它们仍将是存储系统的底层基石,但已难以独力支撑系统对高带宽、低延迟和能效比的极致要求。
三、AI时代的存储系统重构
AI模型参数爆炸式增长,直接将“内存”推向计算系统性能的前沿。传统CPU-DRAM架构难以满足AI在带宽、延迟与能效方面的需求,内存技术开始从“容量扩展”转向“架构重构”,成为算力基础设施的核心组成。
HBM:带宽革命的核心武器
高带宽内存(HBM)以TSV(硅通孔)堆叠技术为基础,通过垂直整合多层DRAM芯片实现超大带宽与小尺寸封装。在HBM3E时代,单颗芯片可实现高达36GB容量和1.18TB/s的带宽,单pin传输速度达到9.2Gbps,堪称AI训练与推理的带宽引擎。

通过引入先进的MR-MUF封装,HBM3E在减小堆叠高度的同时提升热阻性能,使其更适用于功耗密集型AI加速器平台。这一系列优化,使HBM成为AI大模型时代不可替代的“内存引擎”。
CXL:重新定义系统内存边界
Compute Express Link(CXL)通过高速互联扩展主机与内存之间的通信带宽,使系统内存容量得以突破主板插槽限制。通过引入PNM(Processing Near Memory)架构,CXL不仅提升系统容量与带宽,更通过任务卸载显著降低主处理器负载。

根据SK hynix数据,CXL市场正以年复合增长率31.5%的速度快速扩张,成为下一代数据中心架构的关键组件。其潜力不仅在于“扩展内存”,更在于“连接异构计算”,为高效AI部署提供了系统级解法。
PIM:内存即计算的范式突变
Process-in-Memory(PIM)架构打破了冯·诺依曼架构“计算-存储分离”的根本限制。PIM将处理单元嵌入到内存模块内部,实现数据在本地的“边存边算”。这一设计显著提升数据处理带宽并降低数据搬运能耗,是面向AI推理场景的高效路径。
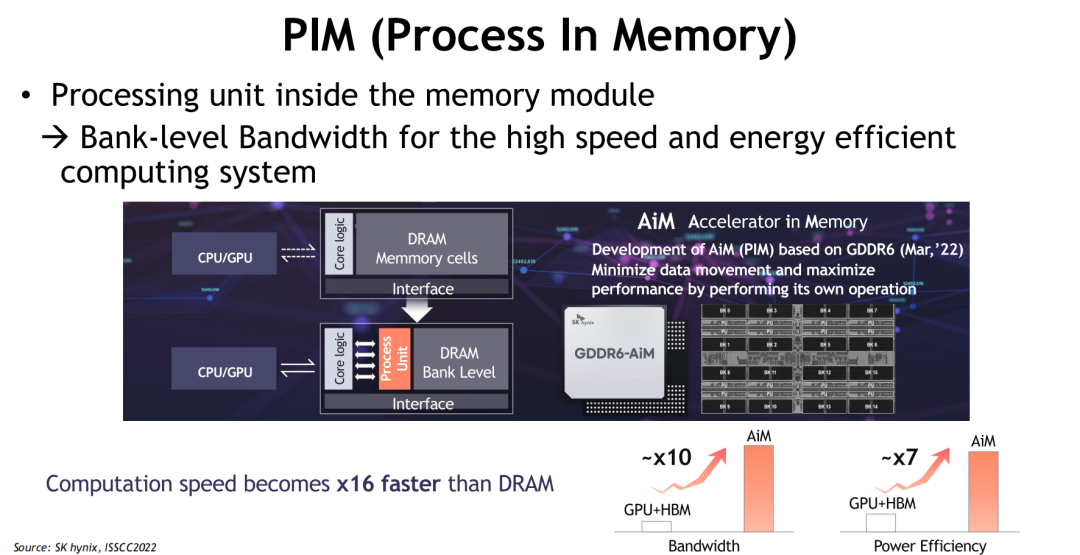
以SK hynix为例,其PIM设计在银行级别支持高速读写,具有极高的能效比与扩展性,为未来“存内AI”奠定基础。相比传统计算架构,PIM在功耗与延迟上的优势,使其成为边缘智能、实时推理等场景下的理想选择。
从HBM的带宽突破,到CXL的系统互联,再到PIM的架构融合,AI时代的内存系统正在经历从“性能堆叠”到“计算协同”的根本跃迁。内存的价值不再仅限于容量或速度,而是作为算力协同的关键枢纽,嵌入整个系统架构核心。
四、新兴存储技术的全景扫描与演进路线
随着AI推理、边缘计算与低延迟应用场景的兴起,传统DRAM与NAND虽持续演进,但在密度、功耗与速度方面的物理极限逐步显现。新兴存储技术(Emerging Memory)应运而生,不仅填补传统架构的技术空档,更推动整个计算系统架构向融合化、智能化演进。
这一代新型存储技术不仅要满足更高带宽、更低延迟、更强能效等性能指标,还需具备高可靠性、长寿命、良好扩展性等工程属性,为未来AI时代的多样化负载提供系统支撑。
新兴内存谱系中,包含了多种物理机制、材料体系与架构形态,既有技术成熟度逐渐提升的SOM、MRAM、FeRAM,也有正处于机制探索与架构验证阶段的ReRAM与ACiM。以下我们逐一分析其技术路径、性能特征与应用前景。
4.1 SOM:继PCM之后的优选方案
Selector-Only Memory(SOM)作为近年来新兴的非易失性存储技术,正逐渐成为超高速、低功耗、高密度应用场景中的新宠。其诞生初衷,正是为了解决传统PCM(相变存储器)在尺寸缩放、热稳定性与功耗上的瓶颈。
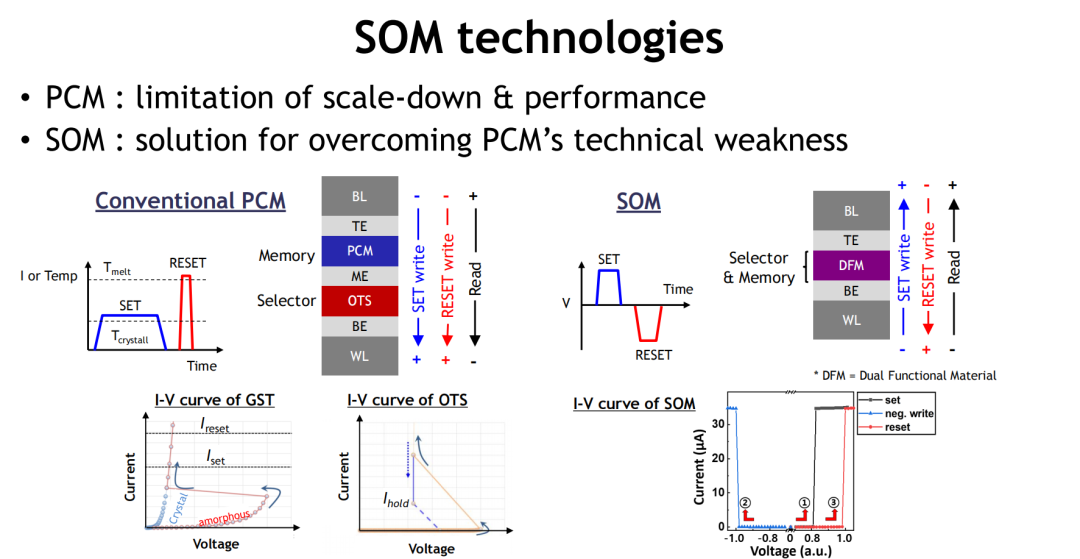
相比PCM的三大技术跃迁:
-
结构简化:SOM通过双功能材料(DFM)集成Selector与Memory功能,简化堆栈结构,提升阵列密度;
-
能效提升:写入电流低至20μA,写入脉冲仅30ns,功耗显著低于PCM;
-
可靠性增强:写入耐久性高达10⁷次,读出循环甚至可达10⁹次以上,高温下(125°C)保持超10年数据稳定。
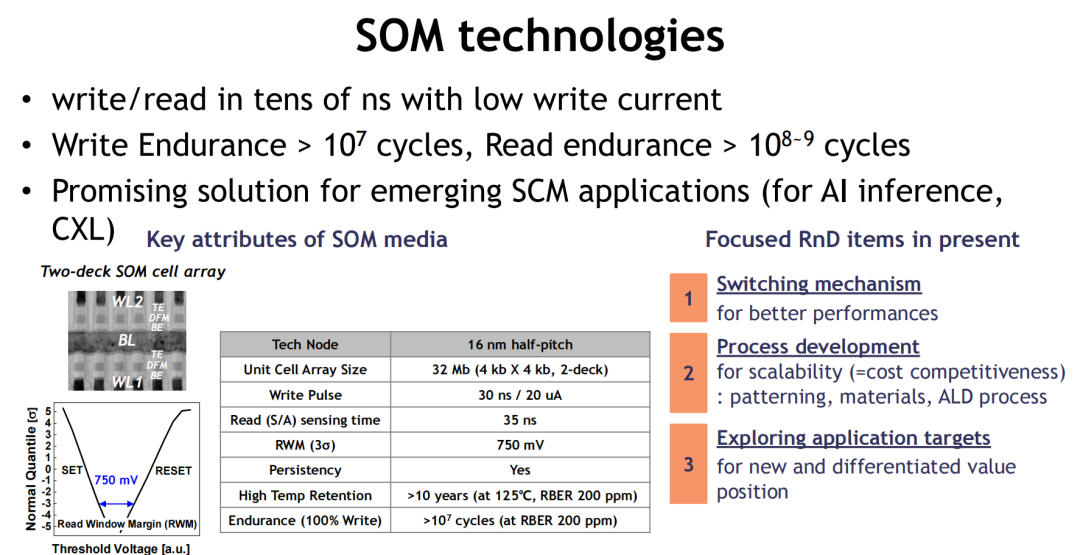
技术路径清晰,落地节奏加快:
SOM自2019年起逐步从1-deck原型发展至当前的4-deck堆栈结构,在结构复杂度与芯片密度之间取得良好平衡。当前主流版本采用16nm工艺节点、双层堆栈、32Mb阵列,已具备工程验证与规模化潜力。

应用落点清晰:
-
AI推理中的中间参数缓存(Intermediate Buffer)
-
SCM(Storage Class Memory)作为CXL内存扩展的核心介质
-
高温或严苛环境下的边缘设备持久存储
SOM的产业意义不仅在于其“替代PCM”,更在于其突破嵌入式非易失存储能效瓶颈的系统价值。作为具备高性能、高密度与高可靠性的解决方案,SOM正成为构建下一代AI内存系统的重要拼图。
4.2 MRAM:功耗优势与密度挑战
磁阻式随机存取存储器(MRAM)被广泛视为新型非易失性存储器中技术成熟度最高的一类。其核心在于利用自旋极化电流实现磁矩翻转,完成数据写入,具备高速度、高耐久与非易失性等多重优势,在嵌入式存储、工业控制、汽车电子等领域已有商用落地。
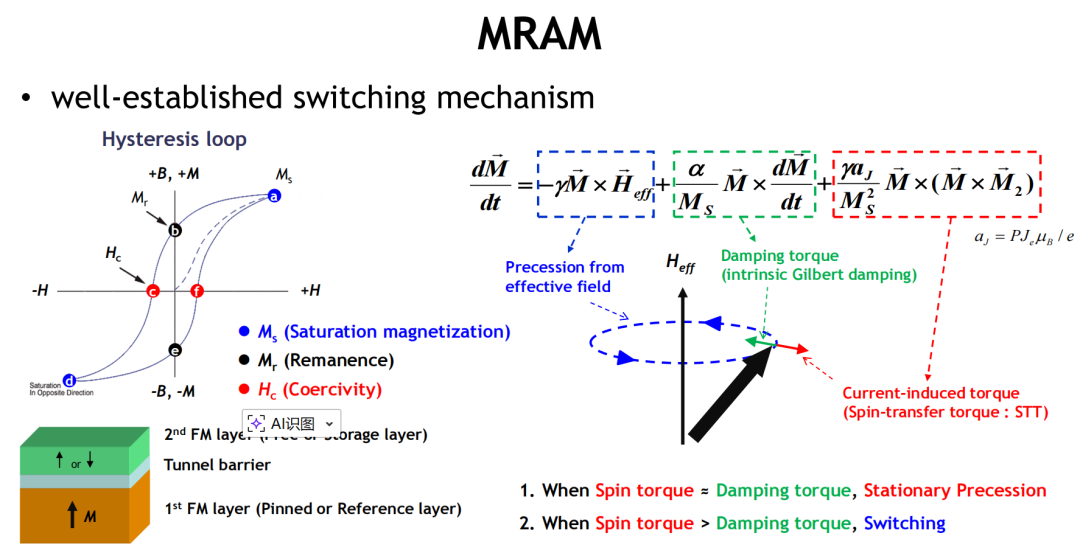
技术机理稳定,演进路径明确
MRAM基于磁隧道结(MTJ)结构,其写入过程由自旋转移力矩(STT)或自旋轨道力矩(SOT)驱动完成。不同于ReRAM或PCM等依赖材料相态变化的机制,MRAM的开关过程稳定、重复性强、数据保持时间长,天然适配工业级高可靠场景。
SK hynix等企业已完成64Gb测试芯片(1S-1M架构)开发,单元尺寸压缩至20.5nm、4F²结构,展示出MRAM在先进工艺节点下的可扩展性。
功耗与耐久优势突出
-
写入速度可达10ns以内,媲美SRAM
-
写入耐久超过10¹⁴次,远超Flash类存储
-
具备抗回流焊能力,满足封装工艺要求
-
可支持缓存类、Flash类、NVM类多种工作模式,展现强大灵活性
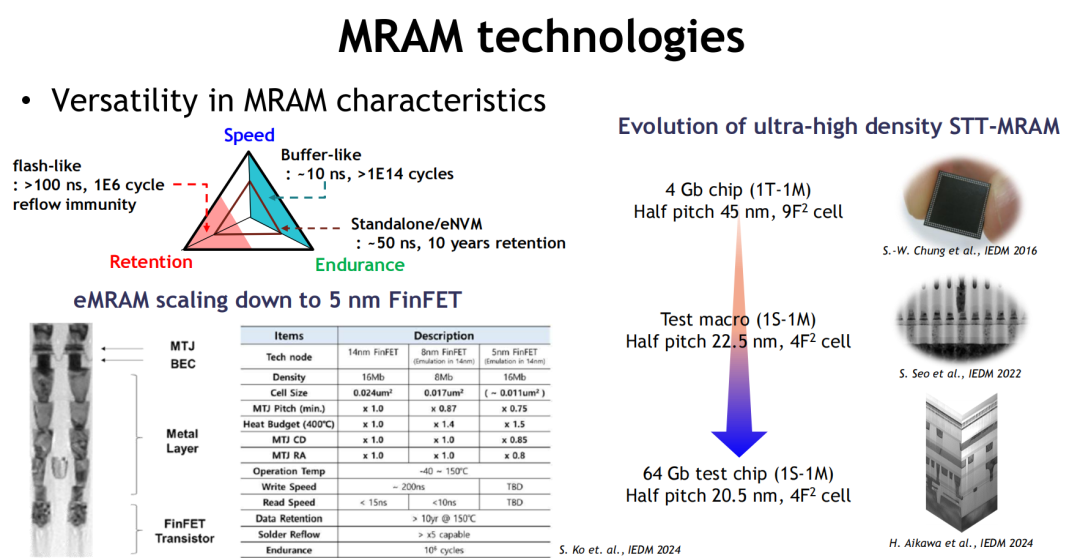
面临最大挑战:密度扩展受限
尽管MRAM在速度与功耗方面优势显著,但其面临的主要瓶颈仍在于密度扩展能力不足。由于MTJ结构对尺寸与CD pitch的物理限制,其密度远低于DRAM与NAND,限制其在大容量存储场景中的应用拓展。
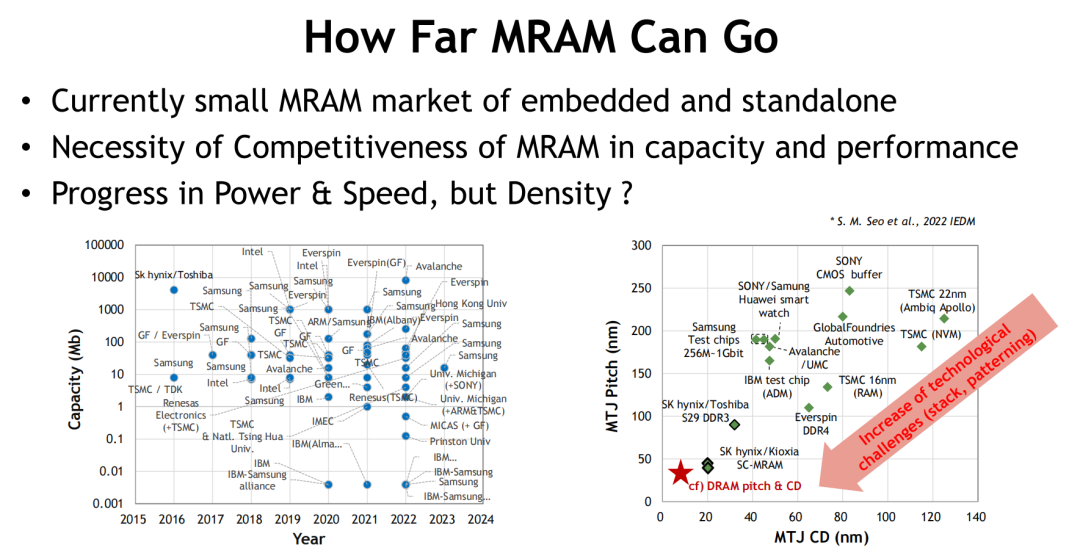
从图像资料看,主流MRAM CD与Pitch仍集中在40~100nm之间,相较于DRAM显著滞后。因此,尽管市场布局已从嵌入式、NVM、汽车电子扩展至AI加速器缓存等新兴场景,其在“主存替代”路径上仍需时间验证。
技术突破路径:新机制与材料系统
未来MRAM发展方向包括:
-
SOT-MRAM、VCMA等新型写入机制,降低写入电流
-
高各向异性材料与精细化MTJ堆叠结构
-
与FinFET/CFET工艺兼容的超薄MTJ整合技术
MRAM代表的是一种“以功耗和速度为核心卖点”的通用型NVM路径,其最大价值在于打破了“快=易失,慢=非易失”的传统逻辑。在算力与能效的博弈中,它是性能优先场景的可靠选项,但若要真正挑战DRAM或NAND,还需跨越密度与成本的“高墙”。
4.3 FeRAM:铁电材料路线分化
铁电存储器(FeRAM)因其低功耗、高速度、高耐久等特性,正重获产业界关注。随着HfO₂基铁电材料(如HZO)的铁电性被广泛验证,FeRAM实现了从实验室向高密度产品形态的关键跃迁,构建出一条兼顾CMOS兼容性与存储性能的全新路径。
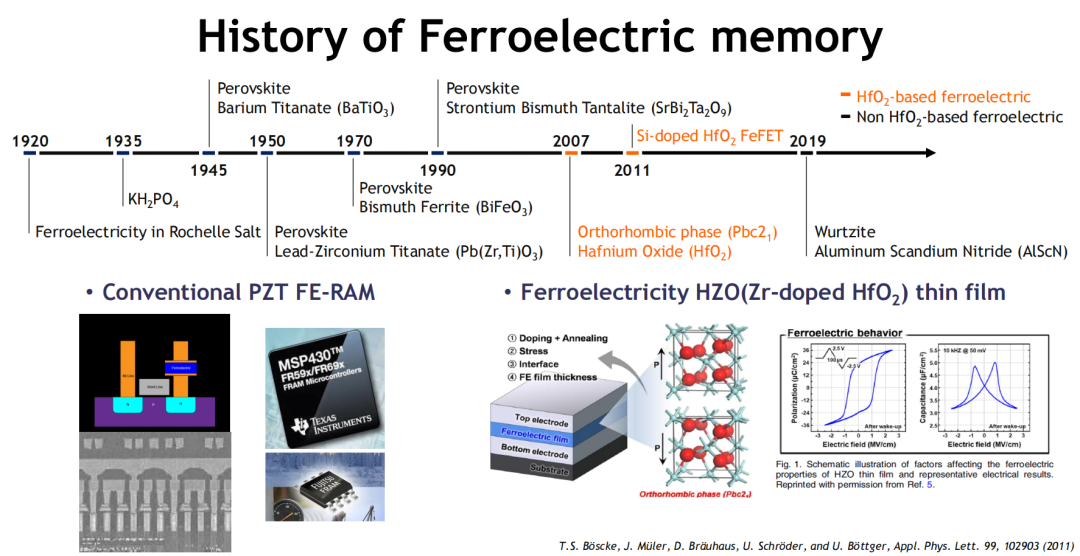
多元路线并行,技术架构百花齐放
FeRAM技术的最大特征,在于其架构形态极为多样。目前主流方向包括:
-
1T1F FeRAM:传统铁电电容结构,已实现1Xnm制程与8Gb容量;
-
FeFET(铁电晶体管):通过极化控制阈值电压,实现电荷存储与读取,适配高耐久、多级存储(MLC)需求;
-
FTJ(铁电隧穿结):依赖铁电层极化态调制势垒厚度,追求更高的on/off比与更小尺寸;
-
3D FeNAND结构:将铁电层引入类NAND堆叠结构,世界首个3D堆叠FeRAM实现QLC操作已由SK hynix于2023年完成。

这一多路线并行格局,既体现了FeRAM材料系统的高度灵活性,也反映出其“面向不同应用场景精准适配”的发展思路。
性能亮点:速度快、耐久强、功耗低
-
写入速度可达10ns以内,与DRAM同级
-
写入耐久超过10¹¹次,可支撑频繁更新场景
-
工作电压低至1V以下,极适合移动与边缘设备
-
可支持3D堆叠,实现更高密度与更低bit cost
挑战仍存:极化稳定性与工艺整合
FeRAM虽然具备强势物理属性,但在大规模落地中仍面临几项关键挑战:
-
极化退化:多次循环后on/off比下降,影响可靠性;
-
写入窗口控制:需提升多级电平可控性,支持AI推理精度需求;
-
CMOS工艺整合:高温退火工艺与HfO₂材料兼容性需持续优化。
尽管如此,随着5nm FinFET兼容工艺、AOS通道材料引入等技术突破,FeRAM在嵌入式NVM、边缘AI存储与安全存储等领域的应用可期。
FeRAM代表了“铁电复兴”在半导体存储领域的具体实践,它融合了材料物理突破与系统架构需求,在低功耗AI、汽车电子与多功能SoC中的价值愈加凸显。在非易失性与高速写入的交汇点,FeRAM已步入产业化关键期。
4.4 ReRAM:结构潜力与机制难题
电阻式存储器(ReRAM)曾一度被视为“通吃型”新兴内存解决方案,具备简单结构、高密度潜力与CMOS兼容性,并被用于Intel与Micron联合推出的3D XPoint技术。然而,经历多年发展,ReRAM的产业化进展始终受限,其背后的技术瓶颈值得深思。

技术原理:缺陷态诱导的电导调控
ReRAM的工作机制本质上依赖于材料内部的缺陷迁移,如氧空位、电离迁移或金属离子桥接等方式,实现电导状态的切换。常见机制包括:
-
氧空位形成与迁移(如 HfO₂₋ₓ)
-
金属离子导电桥(如 Ag/Al₂O₃)
-
阳离子/阴离子迁移(如 TiO₂₋ₓ、Ta/HfO₂)
-
非迁移型能带调控机制(如 HfO₂/TiOx)
不同机制下,ReRAM可支持多级存储、低功耗写入与高速切换,理论上极具灵活性。
瓶颈突出:可控性差与一致性问题
ReRAM最大的工程难题在于其写入机制的随机性与非确定性,表现在:
-
阈值电压、导通电流等参数分布宽广,读写窗口小;
-
状态切换依赖缺陷形核与迁移,空间与时间分布不均;
-
读写一致性与耐久性差,影响多周期应用稳定性。
这类问题不仅影响设备性能,还极大提升了阵列级校准与误差容忍成本,限制了ReRAM在大规模、高精度AI推理中的适用性。
应用转向:从“存储”到“计算”
由于其结构简单、可实现多级电导调控,ReRAM在传统存储路径受阻后,逐步向计算型内存(ACiM)场景演进,成为构建类脑计算与模拟加速器的核心构件之一。这一“反向利用”路径,为ReRAM带来了新的生命力。
ReRAM展示了极致结构潜力,但受限于机制随机性,其难以胜任高可靠、大规模存储任务。然而,它在模拟计算、权重存储、低精度AI推理等场景中却恰好“物尽其用”,成为构建未来ACiM架构的重要一环。
4.5 ACiM:计算与存储深度融合之路
Analog Compute-in-Memory(ACiM)被广泛视为新型存储技术迈向“计算融合”时代的终极形态。它不再仅仅关注数据的存储,而是通过存储单元本身完成矩阵计算与权重操作,直接嵌入AI推理路径,颠覆传统处理器-内存分离结构。
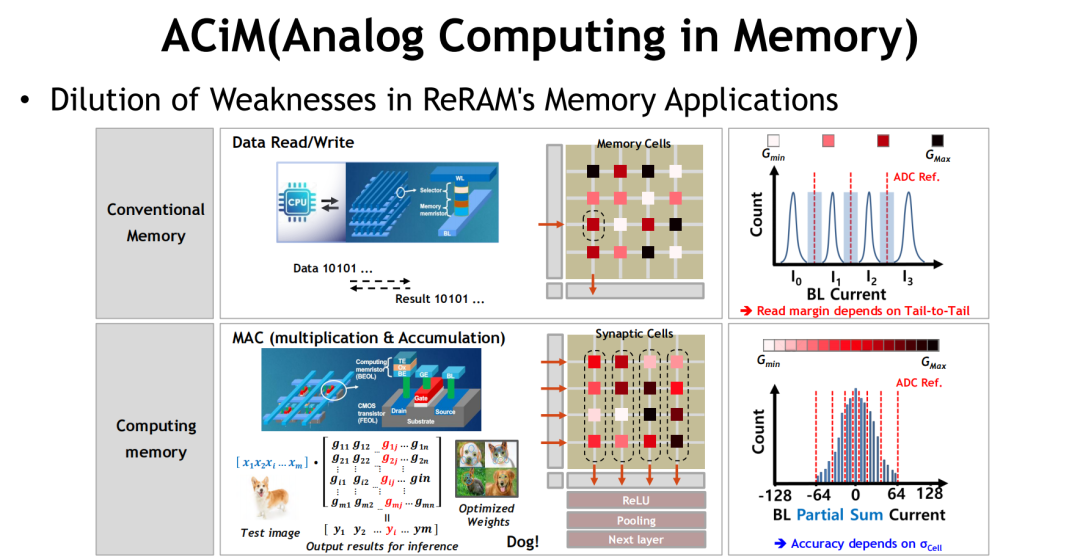
本质:以电导为信息载体的并行计算阵列
ACiM采用电导型非易失单元(如ReRAM、FeFET等)构建Crossbar结构,利用其多电平状态进行矩阵-向量乘(MAC)计算,实现推理中的核心算子操作。相比数字MAC结构,ACiM具备以下突出优势:
-
能效比提升5.2倍
-
芯片面积压缩至1/20
-
模拟并行性实现“类脑式”处理
其在IoT、边缘AI与高通量模型中展现出巨大潜力,特别适用于功耗敏感、延迟敏感或带宽受限场景。
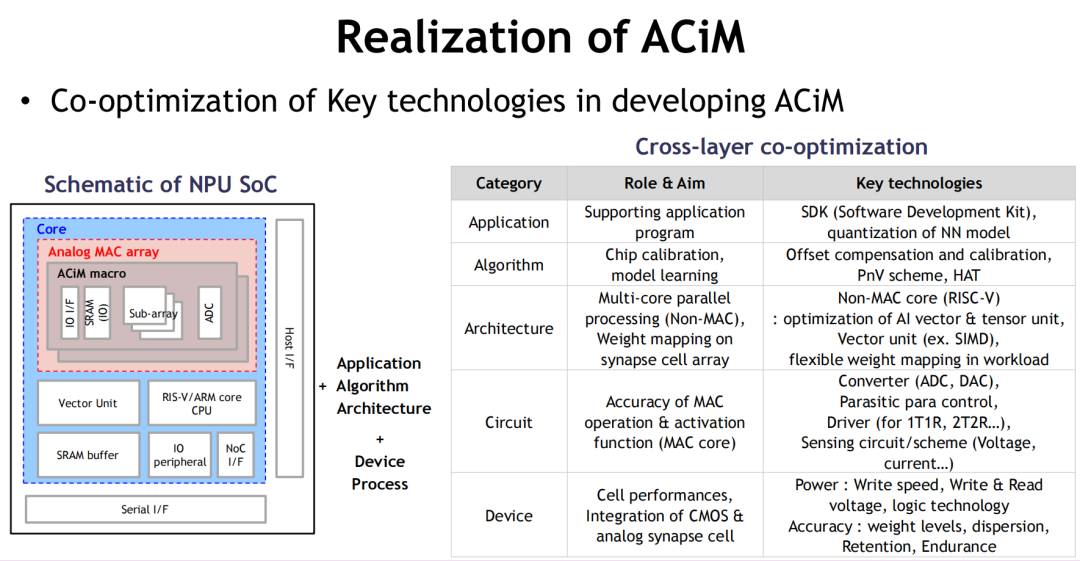
架构要求高度系统协同
ACiM不是简单的芯片堆叠,它要求从器件、架构、算法、应用四层进行协同优化:
|
层级 |
关键目标 |
技术要素 |
|---|---|---|
|
Device层 |
精准权重、多级状态、可靠性 |
ALD工艺、电导一致性、写入线性化 |
|
Circuit层 |
高精度MAC、低干扰读取 |
ADC/DAC方案、电压驱动、干扰抑制 |
|
Architecture层 |
并行结构、可扩展性 |
RISC-V控制、SIMD优化、矢量调度 |
|
Algorithm/Application层 |
偏移补偿、权重量化 |
Calibration技术、HAT训练优化 |
上述结构已在SK hynix原型SoC中完成验证,集成了模拟MAC阵列 + RISC-V核 + SRAM缓存的异构AI推理平台,为后摩尔时代AI芯片提供参考架构。
ReRAM的“意外主角”身份
有趣的是,ReRAM虽然在高可靠存储中遭遇挑战,却因其模拟特性、电导多级性与简单结构,在ACiM中发挥独特价值。弱点转为优势,这正是ACiM的系统性魅力所在。
ACiM不是一种产品形态,而是一种系统思维。它将“数据即计算”的理念具象为电路,实现计算与存储的物理融合,是AI原生硬件架构的关键跳板。
五、面向未来的融合架构与异构集成
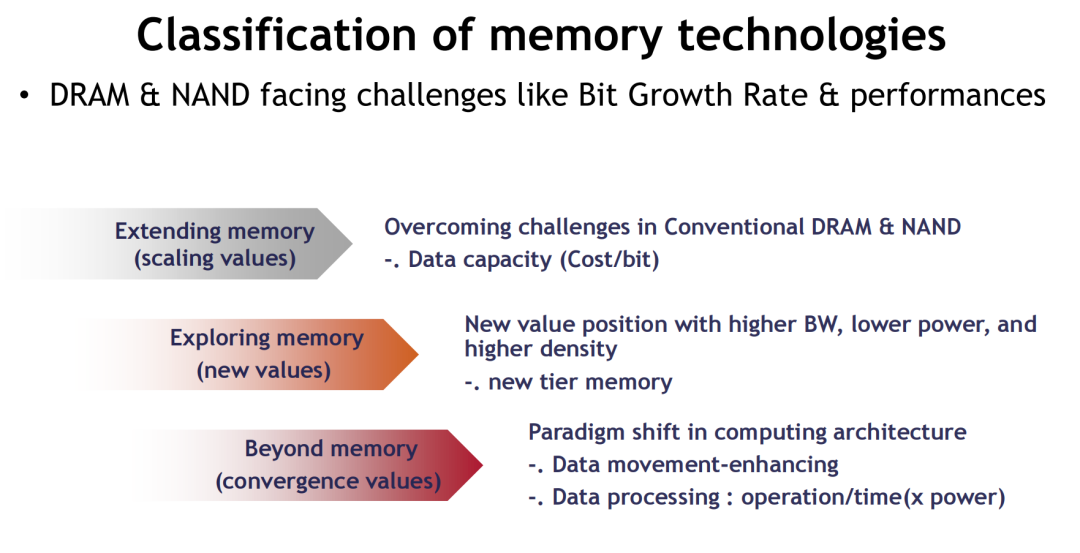
当单一存储技术已无法满足AI时代对带宽、容量、功耗与可扩展性的多重要求,系统级融合成为新一轮技术革新的必然路径。存储技术正从“单体优化”走向“架构协同”,从“接口资源”转变为“系统调度核心”,构建以任务为中心、资源自适应的智能系统架构。
从“扩展价值”走向“融合价值”
传统DRAM/NAND侧重于几何微缩与单位成本优化,推动“容量增长”。新兴存储则进一步延展系统性能边界,实现如下三类价值跃迁:
-
Extending Memory:通过堆叠、通道增强等方式延续传统DRAM/NAND技术路径;
-
Expanding Memory:引入新材料与结构,实现更高带宽、更低功耗、更强密度;
-
Beyond Memory:内存不再只是数据容器,而是成为计算节点、任务调度器、甚至推理单元。
这一演进路径背后的核心推动力,正是异构集成(Heterogeneous Integration)。

异构集成:突破摩尔极限的系统武器
异构集成不是简单的“封装整合”,而是系统级资源的功能耦合与空间调度。其在未来AI与通用计算架构中的价值主要体现在:
-
3D封装技术:通过TSV与Hybrid Bonding实现存储芯片与逻辑芯片的高密度堆叠,提升互联密度(>10⁸ interconnect/mm²);
-
Chiplet架构:支持不同功能模组按需集成,内存、逻辑、模拟、IO各自演进,形成系统级弹性平台;
-
SoC层次融合:在统一IP中集成SRAM缓存、模拟MAC、AI Core与控制逻辑,打破传统边界。
如图示,未来AI SoC或NPU将集成模拟MAC阵列、SRAM缓存、RISC-V矢量核、Crossbar权重矩阵等模块,形成“类脑型”系统体系结构,实现性能与能效的动态均衡。
存储的角色重构
在融合系统中,内存将承担五大角色:
-
高速缓存(如MRAM):支持SoC级别低延迟访问;
-
类存储(如FeRAM、SOM):取代部分DRAM/NAND容量与持久性负载;
-
智能计算节点(如ACiM):参与AI核心计算流程;
-
任务调度与中间结果缓存:支撑多任务异步执行;
-
系统能效优化器:借助架构特性减少数据搬运能耗。
六、总结与未来展望
从存储作为系统“配角”的时代,迈向内存架构成为“算力主角”的时代,新兴内存技术的演进,实质上是在回应一个核心命题:AI时代的计算系统,内存将扮演什么角色?
过去,性能焦点集中在处理器;未来,决定系统边界的,是内存架构。
在当前这一关键拐点上,我们观察到三大结构性趋势:
1. 计算范式变化倒逼内存架构重构
随着生成式AI、边缘智能与实时推理等需求爆发,系统对内存提出更高带宽、更强容量、更低延迟、更好能效的多重要求。HBM、CXL、PIM等架构创新,正在系统层面重塑“内存的角色”。
2. 新兴技术多点突围,形成技术谱系
SOM以结构简化与高耐久优势成为PCM替代者;MRAM在功耗与速度中取得平衡但密度仍是瓶颈;FeRAM多架构共存、兼容CMOS,展现极强弹性;ReRAM机制虽有缺陷,却反向支撑ACiM兴起;ACiM则以系统协同优化,展现下一代AI架构可能。
这些技术不再追求单点极致,而是在不同应用场景中各展所长,共同拓展内存体系的系统边界。
3. 异构融合成就“Beyond Memory”新范式
内存正从“存”走向“算”,成为算力体系的组织者与能效优化器。异构集成技术(如3D封装、Chiplet、SoC级整合)提供了实现路径,推动存储、计算与通信的深度融合,为AI原生硬件奠定基础。
未来计算架构的核心,不再是存算协同,而是让存储成为计算的一部分。
这不仅是工艺的延续,更是范式的颠覆。无论是存储公司、芯片厂商,还是AI系统开发者,都必须基于这一趋势重新思考产品定义与系统规划。
最终,在“成本-性能-功耗”铁律仍未被打破的前提下,那些能够兼顾性能延展与架构重构的内存技术,将率先突破天花板,定义AI时代的算力范式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)