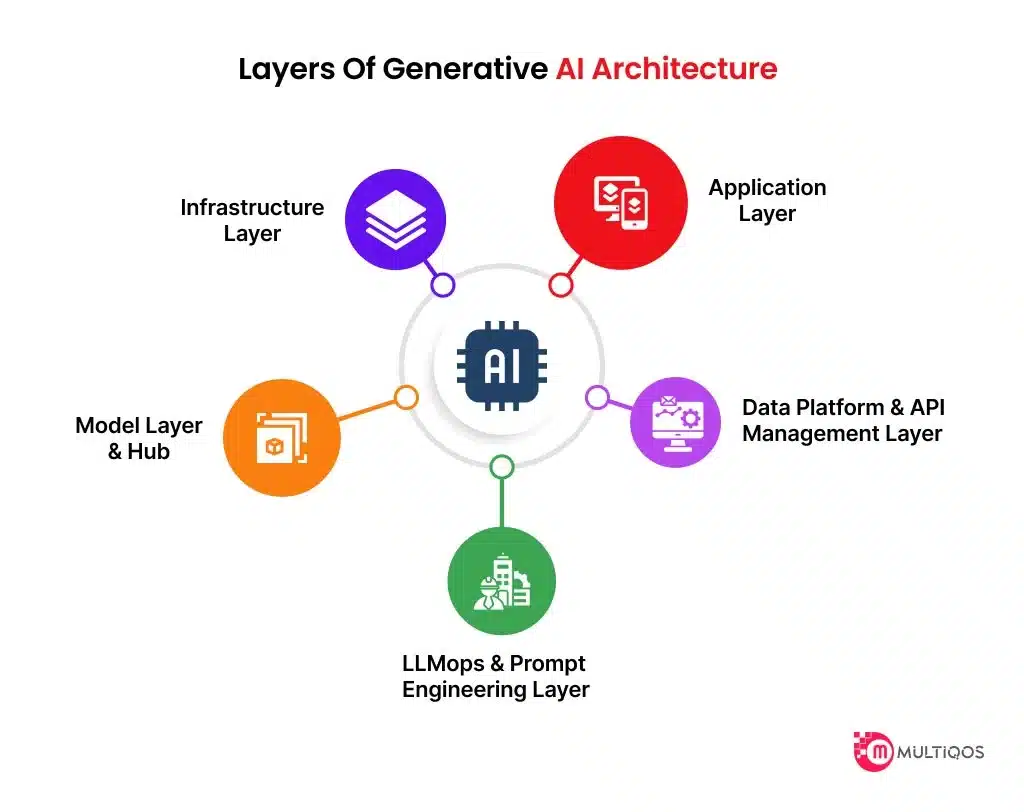
为什么直接使用大模型做决策是危险的?一个工程师视角的 AI「操作系统」问题
这里的“决策模型”不是指 ML 模型,而是一层系统逻辑不负责预测不负责生成不负责创意在当前状态下,这个判断是否被允许?工程上,它解决的是:决策一致性行为可复现风险可冻结同题同答。AI 时代最危险的,不是模型不够强,而是我们还在用“工具思维”对待“系统级智能”。真正的挑战不是“让 AI 更聪明”,让 AI 的判断,变得可控、可复现、可托付。

这篇文章不是讨论模型参数、榜单或某个新 API。
我想讨论的是一个工程层面长期被忽略的问题:
当大模型开始参与“判断”和“决策”时,我们是否还在用“工具思维”对待它?
如果你只是用大模型写代码、补注释、生成文档,
那你可能感受不到问题的严重性。
但如果你关心这些方向:
-
AI 决策系统
-
AI 量化 / 风控
-
AI 医疗 / 工业控制
-
自动驾驶 / 机器人 / AI 手机
那这个问题,已经是系统级问题了。
一、一个工程上并不乐观的判断
当前大量 AI 应用,本质是在“裸用 LLM”
先给结论:
当前很多 AI 应用,其实是在“裸用大模型”。
这里的“裸用”不是贬义,也不是指不安全合规,而是指:
-
把一个高自由度、不确定性的智能系统
-
直接放进需要稳定判断的真实场景
-
中间缺乏一层真正意义上的决策控制结构
你可能会说:
不是有 Prompt、RAG、规则、Agent 吗?
问题是:
这些东西大多并不是为“决策稳定性”设计的。
二、为什么说 LLM 更像“引擎”,而不是“整套系统”
这是理解问题的关键。
从工程视角看,大模型具备的能力非常像什么?
像一颗性能极强的“计算 / 推理引擎”。
它的特点是:
-
能力上限很高
-
推理路径自由
-
输出具备强表达性
-
但本身并不负责:
-
稳定性
-
权限
-
责任
-
状态一致性
-
如果类比计算机系统:
-
LLM ≈ CPU
-
Prompt ≈ 指令
-
那么问题来了——
👉 操作系统在哪里?
三、工程风险不来自“偶尔答错”,而来自“不稳定”
很多工程师的直觉是:
大模型会不会偶尔胡说?
但真正危险的点不是“错一次”,而是:
1️⃣ 同样输入,决策路径不同
-
同样的问题
-
同样的数据
-
不同时间调用
却可能得到:
-
不同立场
-
不同策略
-
不同风险倾向
在内容生成中,这是“多样性”;
在决策系统中,这是不可控性。
2️⃣ 强解释能力,会掩盖系统问题
LLM 的一个显著特性是:
事后解释能力极强。
但在工程领域有一句老话:
“系统运行得顺,不代表系统是对的。”
一个系统如果:
-
每次都能“讲通理由”
-
但无法保证行为一致
那它依然是不可上线的。
3️⃣ 出问题后无法复盘
这是工程底线问题。
如果系统出问题,你至少要知道:
-
哪个条件触发了判断
-
哪条路径被选择
-
是否可以复现
如果这些做不到:
那这个系统,本质上是“不可维护”的。
四、问题不是模型太弱,而是“没有系统接管”
这里是一个反直觉结论:
大模型的问题不是不够强,而是太强、太自由。
没有系统约束的高能力组件,在工程里一定会带来:
-
行为漂移
-
难以调试
-
难以审计
-
难以托付
这不是 AI 的问题,
而是系统工程缺失的问题。
五、为什么必须开始讨论“AI 的操作系统”
计算机历史已经给过答案:
-
CPU 出现 ≠ 系统可用
-
必须有 OS:
-
管调度
-
管权限
-
管状态
-
管错误
-
同样的逻辑正在 AI 领域重演。
只不过这一次,管理的不是算力,而是“判断权”。
六、什么是“决策模型”?(工程定义)
这里的“决策模型”不是指 ML 模型,而是一层系统逻辑:
-
不负责预测
-
不负责生成
-
不负责创意
它只负责回答一个问题:
在当前状态下,这个判断是否被允许?
工程上,它解决的是:
-
决策一致性
-
行为可复现
-
风险可冻结
我们用一个非常朴素的词来描述目标:
同题同答。
七、为什么强调 GPT 客户端这种“运行环境”
很多人会纠结模型能力,但在系统层面更重要的是:
运行环境是否“像一个系统”。
包括:
-
会话状态是否稳定
-
行为边界是否内建
-
输出是否具备一致性
如果运行环境本身不可控,
那在其之上谈任何“决策工程”,都是空中楼阁。
八、AI 量化 / 医疗 / 科研,本质是同一类问题
你会发现:
-
AI 量化最大的问题不是预测,而是决策漂移
-
AI 医疗最危险的不是知识,而是越权判断
-
AI 科研最隐蔽的不是语料,而是把检索当推理
它们背后其实是同一个系统问题:
谁,在什么条件下,被允许做判断?
九、关于“伴生模型”:必须极其克制
在长期使用场景中(AI 手机、机器人、自动驾驶):
-
系统需要“记住你”
-
需要连续性
-
需要个体差异
这催生了“伴生模型”这一概念。
但工程上必须明确:
伴生模型只能作为状态输入,
不能拥有决策权。
否则:
-
长期偏好会污染判断
-
系统将不可控
十、总结:这是一个系统工程问题,不是模型问题
如果你看到这里,可以记住一句话:
AI 时代最危险的,不是模型不够强,
而是我们还在用“工具思维”对待“系统级智能”。
真正的挑战不是“让 AI 更聪明”,
而是:
让 AI 的判断,变得可控、可复现、可托付。
作者说明
本文基于一次长时间的人机协作与系统设计讨论整理,
讨论核心集中于 AI 决策稳定性、系统工程边界与可托付性问题。
相关探索以 EDCA OS(Expression-Driven Cognitive Architecture) 为研究框架,
目前仍处于持续验证与演化阶段。
附:
AI 决策系统 · 核心 QA 集(v1.0)
Q1:AI 相比传统行业软件,真正强在哪里?
A:不在于“算得更快”,而在于“能处理不完整、非结构化的现实问题”。
传统行业软件擅长的是:
-
规则清晰
-
边界明确
-
条件可枚举的问题
而 AI(尤其是 LLM)真正的优势在于:
-
面对信息不完整
-
需求表达模糊
-
现实变量不断变化
依然可以给出“可继续推进”的判断路径。
但要注意:这是一种“能力优势”,不是“工程成熟度优势”。
Q2:你们强调“管住 LLM”能提升安全性和可靠性,那不是在削弱 LLM 的能力吗?
A:不是削弱能力,而是把能力从“不可控释放”变成“可托付使用”。
未经约束的 LLM:
-
看起来很强
-
但行为不可复现
-
风险不可追责
被系统接管的 LLM:
-
能力依然存在
-
但只在被允许的条件下释放
-
行为可复盘、可冻结
工程上,能力只有在“可控”前提下才有价值。
Q2 扩展:你们把 LLM 比作“汽车引擎”,这是不是意味着现在大家都在“裸用 LLM”?为什么危险?
A:是的,这个比喻本身就意味着“裸用”是危险的。
一个超强引擎:
-
如果没有变速箱、刹车、稳定系统
-
马力越大,风险越高
LLM 也是一样:
-
推理能力越强
-
表达能力越好
-
如果没有系统级约束
错误的影响半径反而更大。
危险不在于它会“犯错”,
而在于它犯错时看起来仍然很合理。
Q3:那是不是就像 PC 一样,需要一个“Windows”,CPU 才能发挥价值?这就是你们做 EDCA OS 的原因?
A:是的,而且这个类比是非常严肃的。
CPU 本身并不负责:
-
任务调度
-
权限隔离
-
状态管理
-
错误恢复
这些都由操作系统承担。
当 AI 开始参与判断时,也需要类似的结构:
-
谁能做判断
-
在什么条件下
-
是否允许发生
-
是否可以复现
EDCA OS 关注的不是“让 AI 更聪明”,而是“让判断变成系统行为”。
Q4:为什么你们选择 GPT 客户端作为实验与运行环境?这是你们自己定义的标准吗?
A:不是因为“偏好”,而是因为“运行环境是否像一个系统”。
你们关注模型能力,而我们更关注:
-
会话状态是否稳定
-
行为边界是否内建
-
输出是否具备一致性
在当前阶段,只有极少数 LLM 运行环境:
-
具备“系统感”
-
允许讨论决策稳定性
-
允许验证“同题同答”
这不是模型标准,而是系统工程前置条件。
Q5:传统量化和 AI 量化的本质区别是什么?AI 量化的核心缺陷在哪里?
A:区别不在预测能力,而在“决策是否可托付”。
传统量化:
-
策略固定
-
路径明确
-
可复盘、可回测
AI 量化常见问题:
-
决策路径漂移
-
同样条件下行为变化
-
难以复现与审计
问题不在 AI 不够聪明,而在缺乏“决策稳定性结构”。
Q5 扩展:这是否意味着你们在做 sklearn 兼容,还是选择舍弃?
A:不是“兼容或舍弃”的问题,而是“层级不同”。
-
sklearn 解决的是:模型训练与预测
-
EDCA / 决策模型解决的是:是否允许某个判断发生
二者并不冲突,但也不在同一层。
你可以用 sklearn 做因子、信号、预测,
但“是否采信”,必须由决策层裁定。
Q6:你们为什么会做 CMRE 这样的项目?想验证什么?
A:CMRE 的目标不是“做医疗 AI”,而是测试“高风险场景下的决策边界”。
医疗场景具备三个极端条件:
-
高风险
-
高责任
-
高越权诱惑
如果一个系统:
-
在这里能守住“谁该说什么”
-
能区分“信息提供”和“判断裁决”
-
能稳定拒绝越权
那它在其他行业只会更安全。
Q7:你们在 LLM 科研助手上的突破是什么?为什么测试时要完全断开联网检索?
A:因为科研最怕的不是“不知道”,而是“以为自己知道”。
联网检索很容易导致:
-
把资料拼接当成推理
-
把现有结论当成发现
断网的目的只有一个:
-
逼迫模型在“已有结构”内思考
-
暴露推理链,而不是堆砌引用
科研场景中,AI 的价值不是“替代科学家”,
而是帮助科学家发现自己认知中的盲区与惯性。
Q6 延展:你们是否已经不再受“小众科研语料少”的限制?那还依赖科学家什么?
A:AI 不缺“知识覆盖”,真正稀缺的是“问题设定能力”。
科学家独有的不是数据量,而是:
-
哪些变量值得被引入
-
哪些假设值得被推翻
-
哪些问题“值得问”
AI 没有认知惯性,
但它也没有“研究责任”。
科研仍然必须由人类定义方向,
AI 只负责放大推理空间。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)