人工智能的“巨脑”:AI大模型的崛起、影响与未来
摘要: 近年来,AI大模型(如GPT-3、通义千问)凭借海量参数和跨领域能力引发技术革命。其核心依托Transformer架构、大规模数据与算力支撑,展现出内容创作、编程辅助、科研加速等广泛应用。然而,资源消耗、数据偏见、伦理风险等挑战亟待解决。未来趋势包括模型小型化、AI对齐、开源生态及向通用人工智能(AGI)探索。需平衡创新与治理,确保技术向善发展。(149字)
引言
2010年代末以来,人工智能(Artificial Intelligence, AI)领域迎来了一场由“大模型”驱动的革命。从GPT-3到PaLM,从LLaMA到通义千问(Qwen),参数规模动辄数十亿甚至上万亿的AI大模型正以前所未有的能力重塑我们对智能的理解。这些被称为“基础模型”(Foundation Models)或“通用人工智能雏形”的系统,不仅在自然语言处理、计算机视觉、语音识别等传统任务中屡创佳绩,更展现出跨模态理解、逻辑推理乃至代码生成等复杂能力。本文将系统探讨AI大模型的发展脉络、核心技术、现实应用、潜在风险及其未来走向。
一、何为AI大模型?
AI大模型通常指参数量巨大(通常超过十亿)、在海量数据上训练而成的深度神经网络模型。其核心特征包括:
- 规模效应:模型性能随参数量、数据量和计算资源的增加而显著提升,呈现出“越大越聪明”的趋势。
- 通用性:不同于传统专用模型(如仅用于图像分类),大模型具备跨任务、跨领域的泛化能力,可通过提示(Prompt)或微调(Fine-tuning)适应多种下游任务。
- 涌现能力(Emergent Abilities):当模型规模达到某一临界点时,会突然展现出训练数据中未显式包含的能力,如多步推理、零样本学习(Zero-shot Learning)等。
典型的AI大模型包括以Transformer架构为基础的语言模型(如GPT系列、BERT、通义千问)、多模态模型(如Flamingo、GPT-4V)以及扩散模型(如Stable Diffusion)等。

二、技术基石:从Transformer到Scaling Law
AI大模型的爆发并非偶然,而是建立在多项关键技术突破之上。
1. Transformer架构的革命
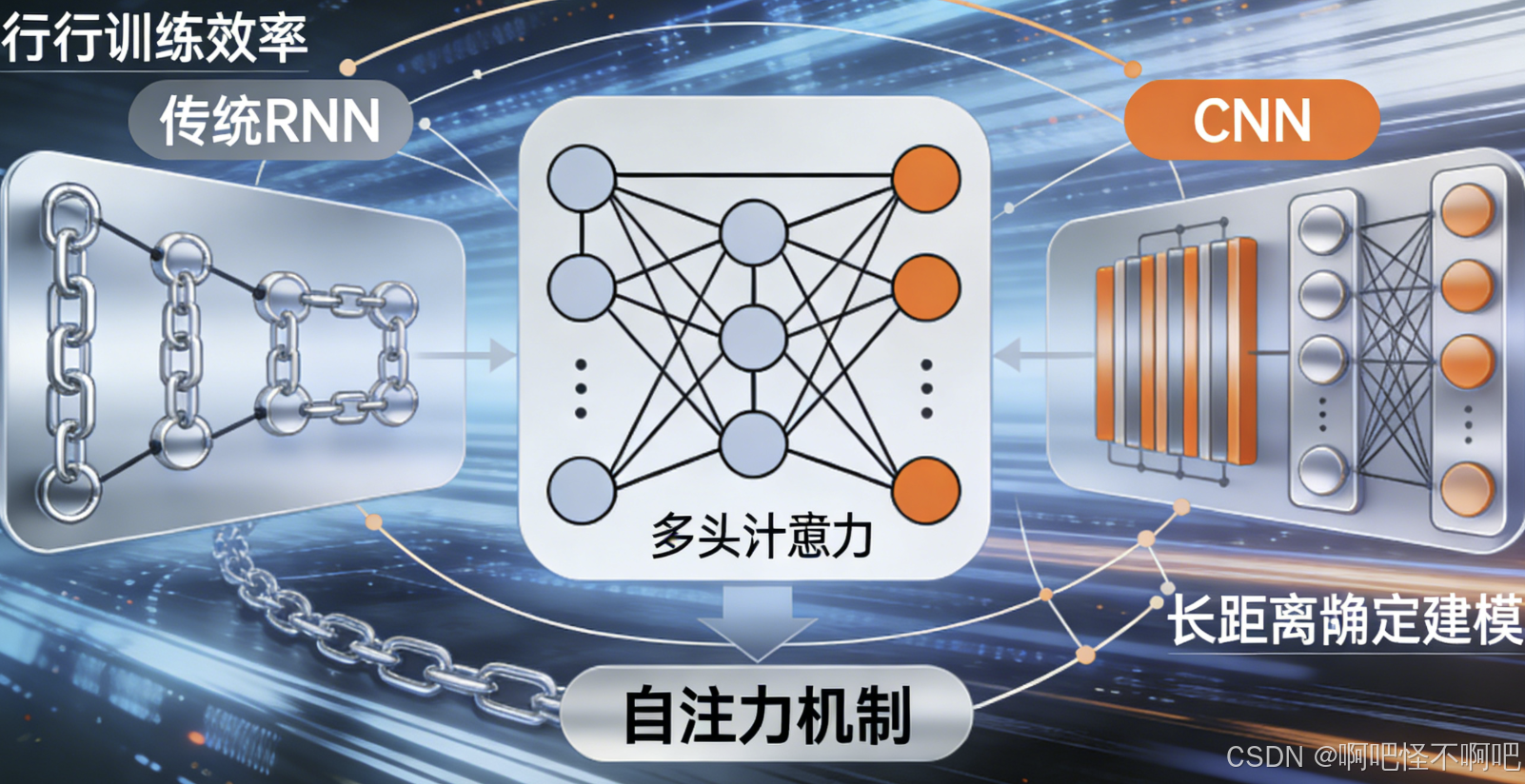
2017年,Google提出的Transformer架构彻底改变了序列建模的方式。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),完全依赖“自注意力机制”(Self-Attention)来捕捉输入序列中任意两个元素之间的依赖关系。这一设计不仅提升了模型并行训练效率,还显著增强了长距离依赖建模能力,成为大模型时代的“标准引擎”。
2. 数据与算力的双轮驱动
大模型的训练需要海量文本、图像、音频等多源异构数据,以及强大的算力支撑。以GPT-3为例,其训练数据包含约570GB的互联网文本,使用了数千块GPU进行数周训练。近年来,云计算、专用AI芯片(如TPU、NPU)和分布式训练框架(如DeepSpeed、Megatron-LM)的发展,使得训练超大规模模型成为可能。
3. 缩放定律(Scaling Laws)
OpenAI等机构的研究发现,模型性能与模型规模、数据规模和计算量之间存在可预测的幂律关系。这意味着只要持续扩大三者规模,模型能力将持续提升。这一发现为“大力出奇迹”的工程路径提供了理论依据,也推动了业界对更大模型的追求。
三、应用场景:从科研到产业的全面渗透
AI大模型正在迅速从实验室走向现实世界,赋能千行百业。
1. 内容创作与知识服务
大语言模型可生成高质量文本,广泛应用于新闻写作、广告文案、剧本创作、教育辅导等领域。例如,通义千问可回答用户提问、撰写邮件、总结文档,甚至进行诗歌创作。在知识密集型行业,如法律、医疗、金融,大模型能快速检索信息、辅助决策,提升专业效率。
2. 软件开发与工程自动化
GitHub Copilot等基于大模型的编程助手,能根据自然语言描述自动生成代码,显著提升开发者效率。研究表明,使用AI编程工具可减少30%以上的编码时间。此外,大模型还可用于代码审查、漏洞检测和系统调试。
3. 多模态交互与智能终端
结合视觉、语音与语言的大模型(如GPT-4V、通义万相)正推动人机交互进入新阶段。用户可通过语音、图像或文字混合输入与AI对话,实现更自然的交互体验。智能手机、智能汽车、家庭机器人等终端设备正逐步集成大模型能力,打造个性化智能助理。
4. 科学研究加速器
在生物医药、材料科学、气候模拟等领域,大模型被用于蛋白质结构预测(如AlphaFold)、新材料发现、高维数据分析等任务,极大缩短科研周期。例如,Meta的ESMFold利用大模型技术,在几天内预测了超过6亿种蛋白质结构。

四、挑战与隐忧:光环下的阴影
尽管前景广阔,AI大模型仍面临多重挑战。
1. 巨大的资源消耗
训练一个千亿参数模型的碳排放量相当于数百辆汽车终身排放总和。高昂的算力成本也导致技术垄断,仅有少数科技巨头能负担得起大模型研发,加剧了“AI鸿沟”。
2. 幻觉与可靠性问题
大模型常生成看似合理但事实错误的内容(即“幻觉”)。在医疗、司法等高风险场景,此类错误可能导致严重后果。如何提升模型的事实一致性与可验证性,仍是开放难题。
3. 数据偏见与伦理风险
训练数据中的性别、种族、文化偏见会被模型放大,导致歧视性输出。此外,大模型可能被滥用于生成虚假新闻、深度伪造(Deepfake)或恶意代码,威胁社会安全。
4. 知识产权与法律空白
大模型训练依赖大量网络数据,其中包含受版权保护的内容。模型生成的内容是否构成侵权?责任归属如何界定?现行法律体系尚未给出明确答案。
五、未来展望:走向更智能、更安全、更普惠
面对挑战,AI大模型的发展正呈现以下趋势:
1. 模型小型化与高效推理
通过知识蒸馏、量化、稀疏化等技术,研究人员正致力于将大模型压缩为可在手机、边缘设备运行的小模型(如Qwen-Max、Phi-3),实现“大模型能力,小设备部署”。
2. 对齐(Alignment)与可控性提升
“AI对齐”旨在使模型行为符合人类价值观。通过强化学习人类反馈(RLHF)、宪法AI(Constitutional AI)等方法,提升模型的诚实性、无害性与有用性。
3. 开源生态与社区共建
以Llama、通义千问为代表的开源大模型降低了技术门槛,激发全球开发者创新。开源不仅促进技术透明,也有助于构建多元、包容的AI生态。
4. 通向通用人工智能(AGI)?
尽管当前大模型尚不具备真正的意识或因果推理能力,但其展现出的泛化与适应性,被视为通往通用人工智能的重要一步。未来,结合符号推理、记忆机制与具身智能(Embodied AI),大模型或将成为AGI的核心组件。
结语
AI大模型如同数字时代的“新电力”,正深刻改变人类生产与生活方式。它既是技术奇迹,也带来前所未有的伦理与治理挑战。我们既不能因噎废食,也不可盲目乐观。唯有在技术创新、伦理规范与公共政策之间寻求平衡,才能确保这一强大工具真正服务于人类福祉,引领我们走向一个更智能、更公平、更可持续的未来。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 46
46 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)