大语言模型实战(六)——面向目标架构案例之FunctionCall技巧介绍
1. 为什么要深度掌握 Function Call 技巧
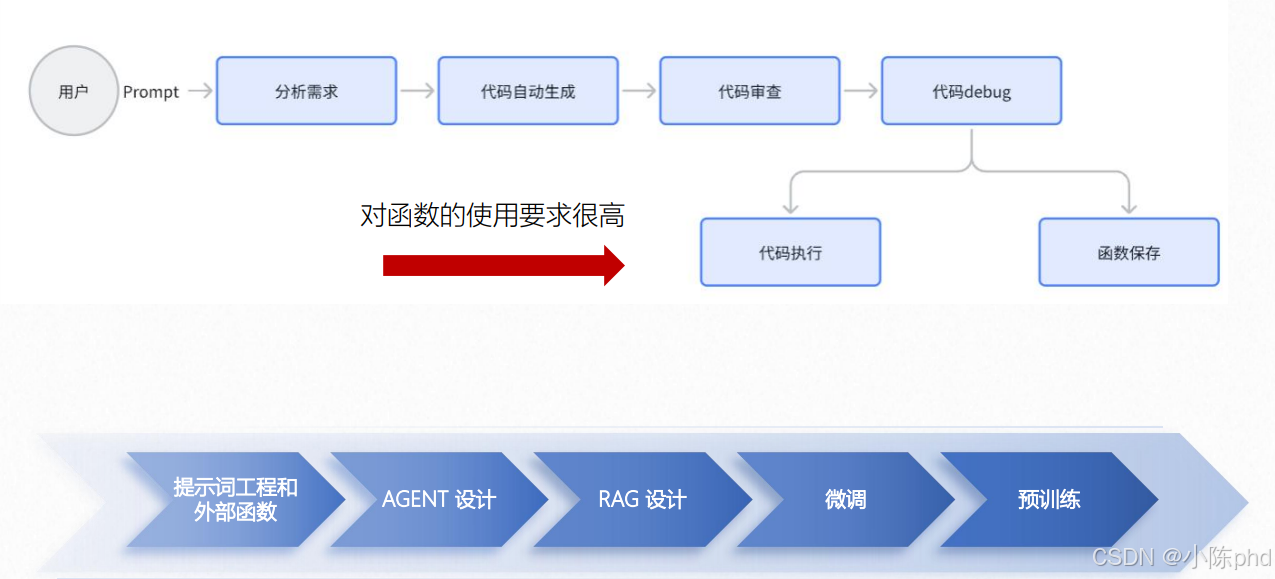
1.1 业务场景:自动代码生成流程高度依赖函数调用
在“用户Prompt→分析需求→代码生成→审查→debug→代码执行/函数保存”的自动代码生成全流程中:
- 核心环节(如“代码执行”“函数保存”)均需调用外部函数(例如代码解释器、文件操作接口);
- 许多步骤无法脱离Function Call独立完成。
1.2 技术覆盖:所有大模型开发范式都需要Function Call
大模型主流开发方案(提示词工程/Agent/RAG/微调/预训练),均以Function Call作为“能力延伸接口”:
- 提示词工程+外部函数:直接通过Function Call调用工具;
- Agent设计:Agent的“工具调用”核心逻辑就是Function Call;
- RAG设计:检索知识库的操作需通过Function Call触发;
- (微调/预训练):模型能力落地时,也需要Function Call对接外部系统。
因此结论是“所有方案都有可能需要Function Call”——它是大模型从“纯文本生成”升级为“能交互、能做事”的核心桥梁。
1.3 核心结论:Function Call是大模型落地的必备能力
Function Call并非可选技能,而是大模型实现业务目标的基础:
- 从业务端看:复杂任务(如自动代码生成)的关键步骤依赖函数调用;
- 从技术端看:所有大模型开发范式都需要Function Call连接外部工具/系统。
深度掌握Function Call,是大模型从“理论能力”转化为“业务价值”的核心前提。
2. Function Call实战中的四大挑战
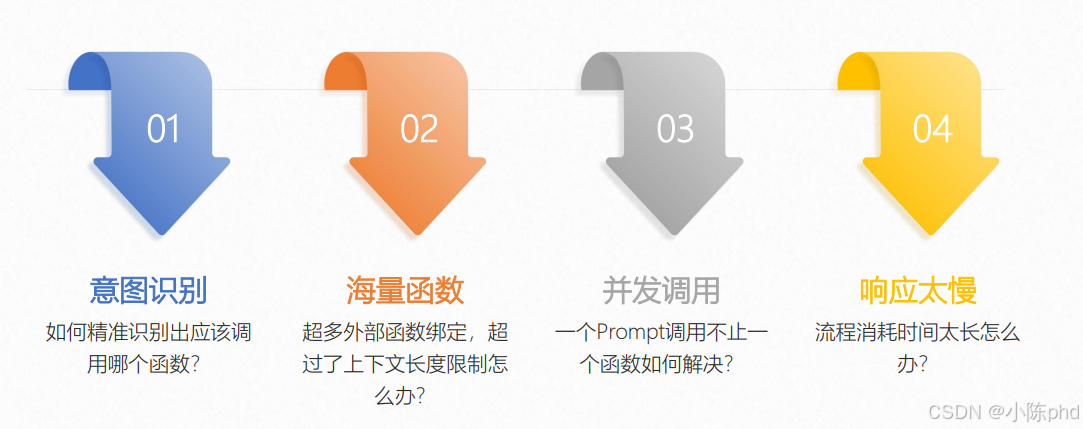
2.1 挑战1:意图识别——如何精准识别应该调用哪个函数?

在实际场景中,用户需求通常是自然语言描述(而非明确的“调用XX函数”),核心难点是让大模型从模糊的需求中,精准匹配到对应的函数。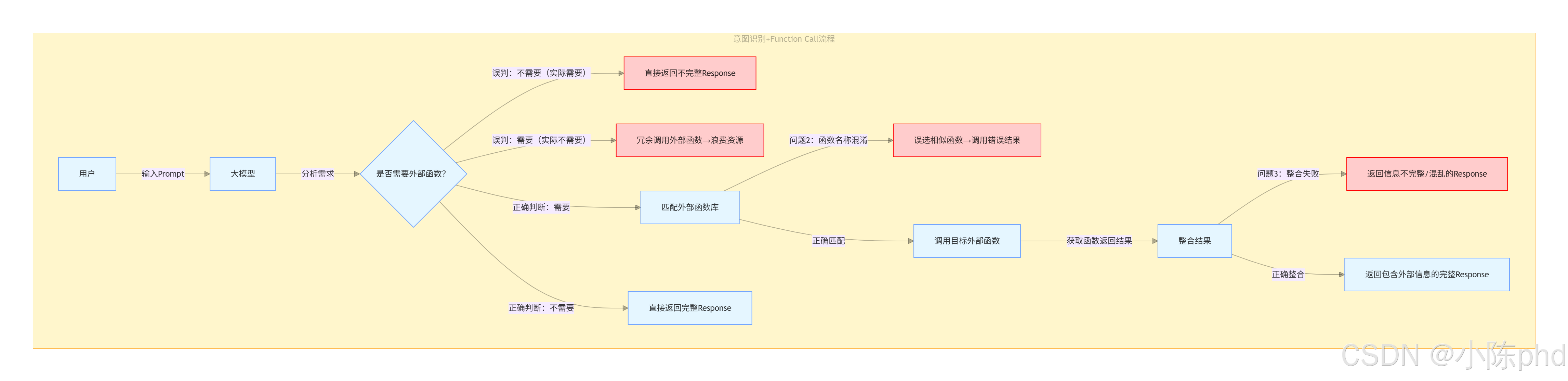
- 示例:用户说“帮我查明天北京的天气”,模型需要识别出应调用“天气查询函数”,而非“日历函数”或“地图函数”;
- 痛点:需求表述模糊、函数功能重叠时,容易出现“调用错误函数”的情况。
2.2 挑战2:海量函数——外部函数过多时,超出上下文长度限制怎么办?
当业务场景中需要绑定的外部函数数量较多时,函数的描述信息(名称、参数、功能)会占用大量上下文空间,而大模型的上下文长度是有限的。
- 示例:若绑定了50个业务函数,每个函数的描述需要100字,总描述会超过多数模型的上下文限制;
- 痛点:无法将所有函数信息传递给模型,导致模型“不知道有哪些函数可用”。
- 在function call使用过程中,我们输入给模型的所有信息(包括但不限于prompt、函数的JSONSchema、设置的system背景信息、全部的上下文等等)都会被记录在Token消耗当中。
- 函数越多,大模型精准识别的能力就越弱
2.3 挑战3:并发调用——一个Prompt需要调用多个函数如何解决?
部分复杂需求无法通过单次函数调用完成,需要同时/连续调用多个函数,但大模型默认是“单次调用一个函数”的逻辑。
- 示例:用户说“帮我查明天北京的天气,再推荐合适的穿搭”,需要先调用“天气查询函数”,再调用“穿搭推荐函数”;
- 痛点:如何让模型规划调用顺序、整合多个函数的返回结果,避免流程混乱。
- 一个Prompt里面需要多个外部函数串行执行。
- 一个Prompt里面需要多个外部函数并行执行
2.4 挑战4:响应太慢——流程消耗时间太长怎么办?
Function Call涉及“模型决策→调用工具→工具返回→模型整合”的多步流程,每一步都有时间开销,复杂任务的响应时间会显著增加。
- 示例:调用“航班查询+酒店预订+餐厅推荐”三个函数,每个工具调用需要2秒,加上模型推理时间,总耗时可能超过10秒;
- 痛点:响应速度慢会影响用户体验,尤其在实时交互场景中问题更突出。
2.5 补充
“这是常见的4大挑战,但不限于于此”——实际项目中还可能遇到“函数参数格式不匹配”“工具返回结果解析失败”等问题,需要结合具体场景针对性解决。
3. Function Call实战进阶技巧:提升JSON Schema质量
JSON Schema是大模型识别、匹配函数的核心依据,其质量直接决定Function Call的精准度。以下是4个提升JSON Schema质量的实用技巧:
3.1 技巧1:优化关键字——让函数名与Prompt高度匹配
大模型匹配函数的逻辑是:对Prompt提示词和函数名分别做Embedding(向量化),再通过相似度匹配函数。
- 具体操作:让函数名包含用户Prompt中常见的关键字(比如用户常说“查天气”,函数名就设为
query_weather,而非模糊的get_data)。 - 核心价值:提升Prompt与函数名的相似度,减少“意图识别错误”。
3.2 技巧2:用特定前缀对函数分类——降低相似函数的混淆
当函数数量较多时,通过前缀分类帮模型快速区分函数的场景/权限:
- 具体操作:在函数名前添加前缀,比如:
- 用户侧函数:
user_book_ticket(用户订票); - 测试侧函数:
test_get_log(测试日志查询); - 管理员函数:
admin_delete_user(管理员删用户)。
- 用户侧函数:
- 核心价值:让模型通过前缀快速定位函数的适用场景,减少“函数误选”。
3.3 技巧3:给核心函数增加权重——优先匹配高频/重要函数
对于高频使用、核心业务的函数,通过名称/描述强化提升其优先级:
- 具体操作:
- 名称中加入
primary/core等标识(比如core_query_order,代表核心订单查询); - 函数描述中补充“非常重要、经常使用、核心业务”等说明。
- 名称中加入
- 核心价值:让模型优先匹配高价值函数,保证核心业务的调用精准度。
3.4 技巧4:用否定句明确函数的禁用场景——避免错误调用
通过否定约束帮模型明确“什么情况下不能用这个函数”:
- 具体操作:在函数的描述字段中补充禁用条件,比如:“当用户问题包含‘删除订单’时,该函数(
query_order)不能使用”。 - 核心价值:减少“函数在错误场景下被调用”的情况,提升Function Call的鲁棒性。
3.5 技巧5:使用自查Prompt进行干预——让模型先“自我判断”
核心逻辑是:在调用函数前,先让模型自查“这个问题是否需要外部函数”,避免不必要的调用或误判。
具体实现(代码示例)
def function_call(prompt, tools_):
# 构造自查Prompt:让模型判断问题是否在自身知识库内
judge_words = "这个问题的答案是否在你的语料库里?\
请回答‘这个问题答案在我的语料库里’或者‘这个问题的答案不在我的语料库里’\
不要回答其他额外的文字"
message = [{"role": "user", "content": prompt + judge_words}]
# 第一步:模型自查
response1 = client.chat.completions.create(
model="glm-4",
messages=message
)
# 第二步:根据自查结果决定是否调用函数
if "这个问题答案在我的语料库里" in response1.choices[0].message.content:
# 不需要调用函数,直接回答
message = [{"role": "user", "content": prompt}]
response2 = client.chat.completions.create(model="glm-4", messages=message)
print(response2.choices[0].message.content)
else:
# 需要调用函数,触发Function Call
message = [{"role": "user", "content": prompt}]
response2 = client.chat.completions.create(
model="glm-4",
messages=message,
tools=tools_,
tool_choice="auto"
)
print(response2.choices[0].message.tool_calls[0].function.name)
通过“先自查、后决策”的流程,减少“模型能直接回答却调用函数”或“需要调用函数却直接回答”的误判,提升流程的合理性。
3.6 技巧6:依赖匹配好于依赖理解——用关键词匹配替代模型推理
核心逻辑是:对于明确场景的需求,直接通过关键词匹配判断是否调用函数,而非依赖模型的“自然语言理解”(避免理解偏差)。
具体实现(代码示例)
def function_call(prompt, tools_):
# 定义目标场景的关键词列表(比如“点餐”相关需求)
judge_words = ["我要点菜", "我要下单", "我要吃饭", "我看看菜单"]
# 第一步:关键词匹配
if prompt not in judge_words:
# 非目标场景,直接回答
message = [{"role": "user", "content": prompt}]
response1 = client.chat.completions.create(model="glm-4", messages=message)
print(response1.choices[0].message.content)
else:
# 目标场景,触发Function Call
message = [{"role": "user", "content": prompt}]
response2 = client.chat.completions.create(
model="glm-4",
messages=message,
tools=tools_,
tool_choice="auto"
)
- 降低模型理解的不确定性:关键词匹配的准确率远高于自然语言理解;
- 提升效率:跳过模型推理步骤,减少Token消耗与响应时间。
| 方法 | 适用场景 | 核心优势 |
|---|---|---|
| 自查Prompt干预 | 需求场景模糊、需要灵活判断 | 适配复杂/多变的需求 |
| 关键词匹配干预 | 需求场景明确、关键词固定 | 精准度高、效率高 |
3.7 技巧7:从“默认格式”到“升级优化”——提升返回信息的可读性
大模型对“结构化、明确的返回信息”处理效果更好,因此需要优化函数返回的内容格式,避免模糊描述。
(1)常见的“默认格式”问题
以OpenAI/GLM-4的默认返回为例:
- OpenAI风格:直接拼接函数名+结果,信息模糊;
- GLM-4官网样例:仅返回JSON格式的结果,缺少上下文说明。
这类默认格式容易导致大模型“无法理解返回结果的含义”,进而整合出错误信息。
(2)升级优化方案:明确描述+格式约束
通过补充上下文说明+限定输出格式,让大模型精准识别函数返回结果:
# 升级后的返回逻辑
message = []
# 1. 明确告知模型“使用了哪个工具,结果是什么”
message.append({
"role": "assistant",
"content": "你使用了tools工具,最终获得的答案是" + str(function_response),
})
# 2. 约束模型仅返回结果(避免额外描述)
message.append({
"role": "user",
"content": prompt + "请仅返回答案的数字,不要包括其他描述"
})
# 调用模型整合结果
response_a = client.chat.completions.create(
model="glm-4",
messages=message
)
print(response_a.choices[0].message.content)
- 降低模型理解成本:通过“工具说明+结果描述”,让模型明确返回信息的含义;
- 提升结果准确性:通过格式约束(如“仅返回数字”),避免冗余信息干扰;
- 增强流程稳定性:统一的返回格式让Function Call的后续步骤更可控。
函数返回信息的优化原则
- 明确上下文:告诉模型“这是哪个工具的返回结果”;
- 简化内容:只保留核心结果,避免无关信息;
- 约束格式:限定输出的格式(如数字、JSON、纯文本),匹配业务需求。
3.8 技巧8:分层设计函数库——从“全量匹配”到“逐层缩小范围”

核心逻辑是:参考传统软件的“三层架构”(表示层→业务逻辑层→数据访问层),将海量函数按业务类型/功能维度拆分,让模型先“选大类”,再“选具体函数”。
(1)分层设计的步骤
步骤1:按业务/功能拆分函数库
将所有函数按“功能、业务、生命周期”等维度拆分为函数集合(大类),比如:
- 订单类函数集合:包含
query_order(查订单)、create_order(创建订单)、cancel_order(取消订单); - 用户类函数集合:包含
query_user(查用户)、update_user(更新用户); - 支付类函数集合:包含
pay_order(订单支付)、refund_order(订单退款)。
步骤2:粗略对齐——先匹配函数集合
让模型先识别用户需求的业务类型,定位到对应的函数集合(而非具体函数):
- 示例:用户说“帮我查一下我的订单”,模型先识别出“这是订单类业务”,定位到“订单类函数集合”。
步骤3:精准对齐——在集合内匹配具体函数
模型仅在“订单类函数集合”中匹配具体函数(而非全量函数),最终精准调用query_order。
(2)分层设计的核心价值
- 降低Token消耗:每次仅向模型传递“当前集合的函数Schema”,而非全量函数;
- 提升识别精度:缩小匹配范围,减少相似函数的混淆;
- 适配海量函数:即便是数百个函数,拆分为多个集合后也能高效匹配。
(3)与传统架构的对应关系
传统软件的“三层架构”(表示层→业务逻辑层→数据访问层),对应Function Call的分层逻辑:
- 表示层:用户需求的自然语言描述;
- 业务逻辑层:函数集合的分类(订单类/用户类/支付类);
- 数据访问层:具体函数(
query_order等)。
通过“分层→粗略对齐→精准对齐”,可将海量函数的调用精准度从“随机匹配”提升至“稳定命中”,同时解决Token超限问题,是企业级海量函数场景的核心解决方案。
3.9 技巧9:串行调用——拆分步骤,逐步执行函数
核心逻辑是:将复杂任务拆分为多个子步骤,让模型先规划步骤,再按顺序调用函数,最终整合结果。
(1)串行调用的实现流程
以“计算656565655与34534321的和与积的差”为例:
步骤1:让模型规划任务步骤
先让模型明确“解决这个问题需要分几步”,并输出步骤列表:
prompt = "请问656565655与34534321的和与积作差等于几?"
# 构造Prompt,要求模型输出步骤
message.append({
"role": "user",
"content": prompt + "解决这个问题要分几步?只告诉我步骤,不要解决问题\n请按照1. xxx;2. xxx;...的格式列举\n步骤与步骤之间使用半角分号相隔,整个句子用半角分号结尾"
})
# 调用模型生成步骤
response_step = client.chat.completions.create(
model="glm-4",
messages=message,
temperature=0.1
)
模型输出步骤:1. 计算两个数的和;2. 计算两个数的积;3. 对结果进行相减;
步骤2:解析步骤列表
用正则表达式提取模型输出的步骤:
import re
str_content = response_step.choices[0].message.content
pattern = r'(\d+\..*?)(?=;|$)'
steps = re.findall(pattern, str_content)
steps = [step.strip() for step in steps if step.strip()]
# 得到步骤列表:["1. 计算两个数的和", "2. 计算两个数的积", "3. 对结果进行相减"]
步骤3:按步骤串行调用函数
依次执行每个步骤对应的函数,并记录中间结果:
step_answer = ""
for step in steps:
# 构造每一步的Prompt,包含当前步骤和已得结果
message = [
{"role": "user", "content": prompt + "正在分步解决问题,已知条件是" + step_answer},
{"role": "assistant", "content": "当前步骤是" + step}
]
# 调用模型,触发对应函数
response_per_step = client.chat.completions.create(
model="glm-4",
messages=message,
tools=basic_math_tools, # 数学运算函数库
tool_choice=True,
temperature=0.1
)
# 执行函数并记录结果
try:
function_calls = response_per_step.choices[0].message.tool_calls[0]
function_to_call = available_math_functions[function_calls.function.name]
function_args = json.loads(function_calls.function.arguments)
function_response = function_to_call(**function_args)
except:
function_response = response_per_step.choices[0].message.content
# 累加中间结果
step_answer += f"步骤{step.split('.')[0]}结果:{str(function_response)};"
步骤4:整合最终结果
将所有步骤的结果整合,输出最终答案:
# 构造整合Prompt
message.append({
"role": "assistant",
"content": "你使用了tools工具,最终获得的答案是" + step_answer
})
message.append({
"role": "user",
"content": prompt + "请仅返回答案的数字,不要包括其他描述"
})
# 生成最终结果
response_a = client.chat.completions.create(
model="glm-4",
messages=message
)
print(response_a.choices[0].message.content)
(2)串行调用的核心价值
- 解决复杂任务:将“无法一次完成”的任务拆分为多步,逐步推进;
- 提升结果准确性:每一步的结果可验证,减少“一步错、步步错”的风险;
- 增强流程可控性:可在每一步插入校验、调整逻辑,适配复杂业务场景。
(3)适用场景
需要多步计算、多工具协作的复杂任务(如“数据分析→生成图表→撰写报告”“查天气→查航班→订酒店”)。
3.10 技巧10:并行调用——同时处理多个独立函数请求
核心逻辑是:对无依赖关系的多个任务,同时触发函数调用(而非串行等待),最后统一整合结果,提升效率。
当需要同时处理多个独立任务(无依赖关系)时,通过并行调用可大幅缩短整体响应时间,这是LangChain等框架的核心能力之一。
(1)并行调用的实现(以LangChain为例)
以“同时查询‘机器学习’‘AIGC’‘大模型技术’的定义”为例:
步骤1:定义多个独立任务的Prompt
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage, HumanMessage
# 初始化大模型
chat = ChatOpenAI(model="gpt-3.5-turbo")
# 定义3个独立任务的消息列表
messages1 = [
SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是机器学习")
]
messages2 = [
SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是AIGC")
]
messages3 = [
SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是大模型技术")
]
步骤2:并行调用大模型
通过LangChain的batch方法,同时发送多个请求:
# 并行执行3个任务
response = chat.batch([
messages1,
messages2,
messages3
])
步骤3:解析并行结果
统一处理所有任务的返回结果:
# 提取每个任务的回答
result1 = response[0].content
result2 = response[1].content
result3 = response[2].content
# 整合输出
print("1. 机器学习的定义:", result1)
print("2. AIGC的定义:", result2)
print("3. 大模型技术的定义:", result3)
(2)并行调用的核心价值
- 大幅缩短耗时:若3个任务串行执行需
T1+T2+T3时间,并行仅需max(T1,T2,T3)(取最长的单个任务耗时); - 提升资源利用率:充分利用大模型的并发处理能力,避免资源闲置;
- 适配多任务场景:可同时处理多个独立的用户请求或业务任务。
(3)适用场景
- 多个无依赖的查询任务(如“同时查多个城市的天气”“同时查多个产品的价格”);
- 批量处理任务(如“批量生成多个文案”“批量分析多个数据文件”)。
(4)并行与串行的对比
| 调用方式 | 适用场景 | 核心优势 | 核心限制 |
|---|---|---|---|
| 串行调用 | 任务有依赖关系 | 流程可控、结果可验证 | 耗时较长 |
| 并行调用 | 任务无依赖关系 | 耗时短、资源利用率高 | 无法处理有依赖的任务 |
在实际项目中,通常会结合使用两种方式:对有依赖的子任务用串行,对无依赖的任务用并行,最大化提升Function Call的效率。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)