4行代码,给你的AI 应用外接“记忆大脑”
PowerMem + seekdb:为AI打造持久化记忆系统 摘要:传统AI应用存在"金鱼记忆"问题,每次对话都需重新介绍。PowerMem + seekdb组合提供了智能化的持久化记忆解决方案,具有三大突破性优势:1)性能提升:准确率提高48.77%,响应速度提升91.83%;2)成本优化:Token用量降低96.53%;3)智能记忆管理:自动提取关键信息、支持多模态数据、实
想象一下这样的场景:
你正在和一个AI医疗助手聊天,它刚刚帮你记录了头痛的症状。第二天,你再次咨询时,它竟然完全忘记了你是谁,还要你重新介绍一遍病情...
是不是很抓狂?
这就是传统AI应用的"金鱼记忆"问题——每次对话都是"初次见面",永远记不住历史信息。
但今天,我要告诉你一个极佳的解决方案:PowerMem + seekdb —— 一个让AI拥有"超强记忆力"的持久化记忆系统!
1. 数据说话:48.77%准确率提升,96.53%成本降低!
先看一组压测数据:

- 准确率提升 48.77%:在LOCOMO基准测试中,准确率从52.9%提升至78.70%
- 响应速度快 91.83%:检索延迟从17.12秒降至1.44秒
- Token用量降低 96.53%:从26k降至0.9k,成本暴降!
这意味着什么?
你的AI应用不仅能记得更准,还能答得更快,同时花得更少!
2. 不是简单的"记事本",而是"最强大脑"
2.1. PowerMem 是什么?
PowerMem建立在这样一个原则之上:AI系统应该能够像人类一样随着时间积累知识和经验。这一理念驱动了PowerMem设计和实施的每个方面:
- 智能提取和保留:PowerMem通过 LLM 模型进行记忆的提取,根据重要性和相关性确定哪些信息值得记住。
- 上下文理解:PowerMem维护跨交互的上下文以实现有意义的个性化体验。
- 持续学习:PowerMem使AI系统能够从每次交互中学习并随着时间的推移而改进。
- 自适应遗忘:像人类记忆一样,PowerMem实现了自适应遗忘机制以防止信息过载。
powermem 的核心特性包括:
- 开发者友好
- 轻量级接入方式:提供简洁的 Python SDK / MCP支持,让开发者快速集成到现有项目中
2. 智能记忆管理
- 记忆的智能提取:通过 LLM 自动从对话中提取关键事实,智能检测重复、更新冲突信息并合并相关记忆,确保记忆库的准确性和一致性。
举个例子:还记得上学时老师让你划重点吗?PowerMem就是AI的"学霸助手"!
# 用户说了一堆话
messages = [
{"role": "user", "content": "Hi, my name is Alice. I'm a software engineer at Google."},
{"role": "assistant", "content": "Nice to meet you, Alice!"},
{"role": "user", "content": "I love Python programming and machine learning."}
]
# PowerMem自动提取关键事实
memory.add(messages=messages, user_id="alice", infer=True)
# 结果:自动提取出4条关键记忆
# 1. Name is Alice
# 2. Is a software engineer at Google
# 3. Loves Python programming
# 4. Loves machine learning不需要你手动标注,AI自动帮你"划重点"!
- 艾宾浩斯遗忘曲线:基于认知科学的记忆遗忘规律,自动计算记忆保留率并实现时间衰减加权,优先返回最近且相关的记忆,让 AI 系统像人类一样自然"遗忘"过时信息
还记得那个著名的遗忘曲线吗?PowerMem把它用在了AI记忆上!
👀最近的信息:权重高,优先召回
👀久远的信息:权重低,自然衰减
👀过时信息:自动清理,保持记忆库新鲜
就像人类大脑一样,重要的、最近的信息记得更牢!
3. 多智能体支持
- 智能体共享/隔离记忆:为每个智能体提供独立的记忆空间,支持跨智能体记忆共享和协作,通过作用域控制实现灵活的权限管理
4. 多模态支持:不仅记得文字,还"看得懂"图片
- 文本、图像、语音记忆:自动将图像和音频转换为文本描述并存储,支持多模态混合内容(文本+图像+音频)的检索,让 AI 系统理解更丰富的上下文信息
# 存储图片记忆
memory.add(
messages=[{"role": "user", "content": "这是我的X光片"}],
images=["xray_image.jpg"],
user_id="patient_001"
)
# 搜索时,文字+图片一起检索
results = memory.search("X光片结果", user_id="patient_001")5. 深度优化数据存储
- 支持子存储(Sub Stores):通过子存储实现数据
的分区管理,支持自动路由查询,显著提升超大规模数据的查询性能和资源利用率 - 混合检索:融合向量检索、全文搜索和图检索的多路召回能力,通过 LLM 构建知识图谱并支持多跳图遍历,精准检索复杂的记忆关联关系
2.2. seekdb 是什么?
OceanBase seekdb 是 OceanBase 打造的一款开发者友好的 AI 原生数据库产品,专注于为 AI 应用提供高效的混合搜索能力,支持向量、文本、结构化与半结构化数据的统一存储与检索,并通过内置 AI Functions 支持数据嵌入、重排与库内实时推理。 seekdb 在继承 OceanBase 原核心引擎高性能优势与 MySQL 全面兼容特性的基础上,通过深度优化数据搜索架构,为开发者提供更符合 AI 应用数据处理需求的解决方案。
2.3. PowerMem + seekdb (1+1 >2 ) 的持久化记忆解决方案
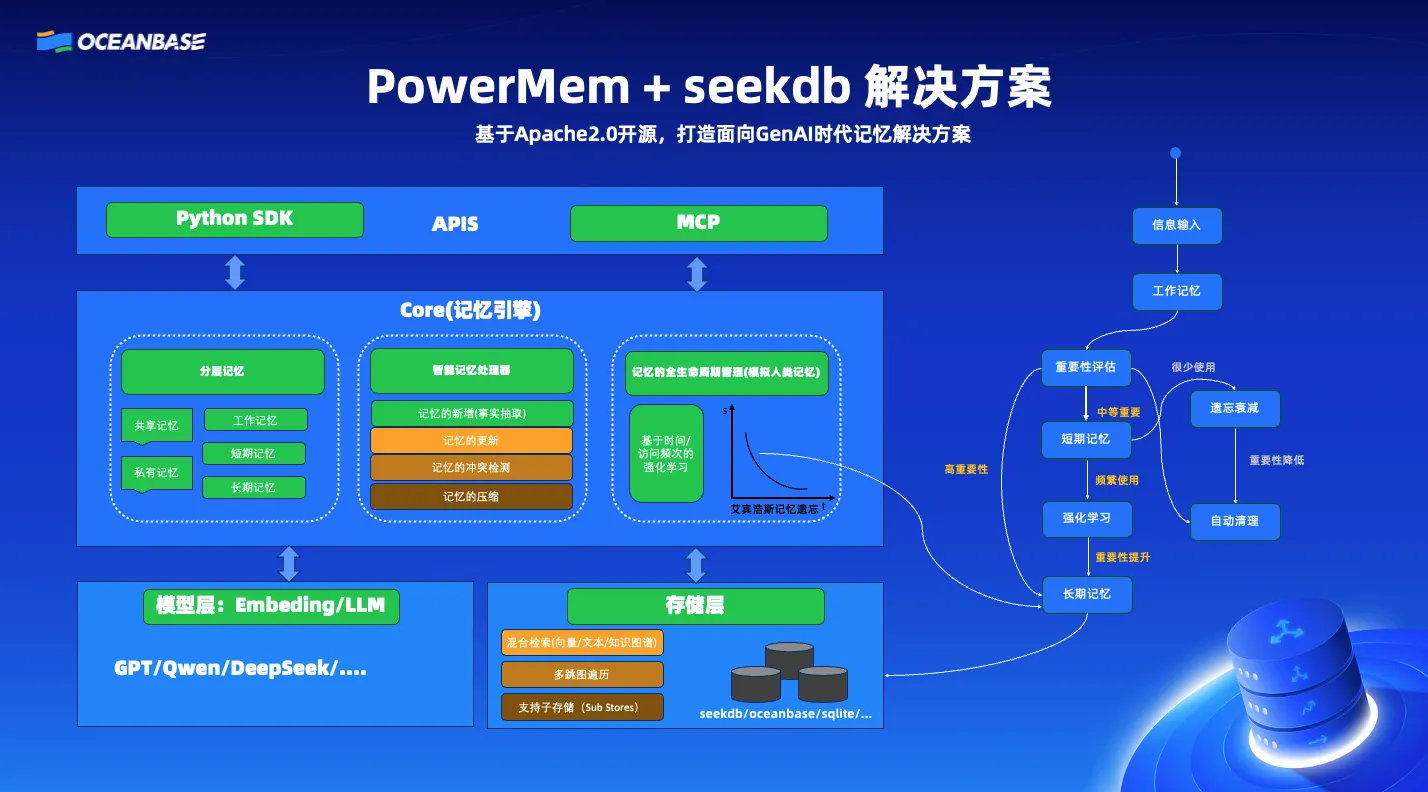
PowerMem的架构旨在模块化、可扩展,包括如下层:
- 核心记忆引擎(core):管理所有记忆操作,包括智能记忆处理器、分层记忆管理、全生命周期记忆管理模块
- 模型层:提供与流行LLM和嵌入模型的无缝集成
- 存储层:支持多种存储后端的灵活接口。特别的,我们在seekdb/oceanbase 上做了深度适配,充分利用了seekdb的混搜能力。
所以,PowerMem + seekdb 的组合不是简单的数据存储,而是一个真正智能的持久化记忆系统
3. 一分钟快速上手:让AI秒变"记忆大师"
3.1. 第一步:安装
pip install powermem3.2. 第二步:使用
from powermem import Memory, auto_config
# 自动从.env加载配置
memory = Memory(config=auto_config())
# 添加记忆(自动提取事实)
memory.add("用户喜欢喝咖啡", user_id="user123")
# 搜索记忆(智能检索)
results = memory.search("用户偏好", user_id="user123")就这么简单!4行代码,让你的AI应用拥有"记忆力"!
结语:是时候给AI装个"外挂记忆"了!
还在为AI的"金鱼记忆"而烦恼吗?
还在为Token成本居高不下而头疼吗?
还在为检索准确率低而困扰吗?
PowerMem来了!
- 准确率提升48.77%
- 响应速度快91.83%
- 成本降低96.53%
让AI拥有"最强大脑",从PowerMem开始!
4.1. 相关资源

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)