给OB社区的圣诞礼物——结构化上下文语言(Structured Context Language)项目
本文探讨了智能体系统中MCP与RAG的双向协同机制。作者通过实践发现,借助PowerMem和seekdb可以构建类RAG系统,而反向利用RAG的向量相似度查询也能模拟MCP的渐进式加载特性。文章提出了结构化上下文语言(SCL)的构想,将其定位为智能体时代的"SQL",并从业务内容、工具调用和记忆管理三个维度解构上下文工程。通过渐进式加载工具调用和"Hint"
“Apple Pen”式的启发:当MCP与RAG双向奔赴
最近在搭建智能体(Agent)系统时,发现一个有意思的事情:借助 PowerMem(一款 AI 记忆组件) MCP接口和 seekdb(一款AI 原生数据库),我们就能快速组装出一个功能完整的类 RAG(Retrieval-Augmented Generation)系统。
但有趣的是,当我反过来思考:依靠 RAG 最核心的基于嵌入向量的相似度查询机制能否模拟出类似 MCP 的“渐进式加载”。比如,让系统根据当前上下文动态决定召回多少信息……结果发现,这种“自底向上”的尝试竟然也是能跑通的。
于是就出现了这样一幅画面:一边是用 PowerMem + seekdb 通过 MCP “正向”构建出简洁高效的 类 RAG式系统;另一边是我用纯 RAG 机制“逆向”还原出 MCP 的“渐进式加载”。两条路径,一个自上而下,一个自下而上,却在中间某处悄然相遇。那一刻,脑海里不由自主响起那句魔性旋律:“I have a pen, I have an apple… Apple Pen!”
为什么需要SCL?从提示工程到上下文工程
面向Agent时代的探索,我们没必要舍弃当下成熟的做法,但也要怀着开放的心态在探索的道路上前行。这个项目名字,我和社区的伙伴们纠结了2~3天,最终决定以Structured Context Language来“捏他”一下SQL,也算某种基于“meme”的命名了。
愿景:智能体时代的“SQL”
大家都很熟悉用于与数据库交互的 SQL。如今,面对大语言模型,我们的焦点正从提示工程转向上下文工程。
在本项目中,我们尝试构建一种结构化上下文语言(Structured Context Language),旨在借鉴上下文工程的实践,占据一个类似于 SQL 的生态位。
我们希望通过这一实践,能够总结出一套中间件。该中间件将为智能体提供标准化的接口,其角色类似于 Hibernate 之于 Java 应用程序。
解构 SCL:上下文工程的三个维度
如果将提示词视为一种面向大语言模型(LLM)的查询语言,那么上下文工程无疑是这种查询语言的一种实现方式。我们可以从三个相互独立的维度来解构上下文工程:
- 业务内容:面向具体提示词和场景的具体指示。
- 工具调用:LLM 能够使用的各种工具,旨在获取额外的外部数据。
- 记忆管理:在多轮对话场景下,决定哪些历史内容与当前查询相关。
我们可以将工具调用视为对信息的空间扩展,而将记忆管理视为信息在时间维度的扩展。
考虑到在工程实践中,我们可以通过工具调用来实现记忆管理的交互,因此在上下文工程中,对于信息的扩展查询可以使用一种标准化接口来完成,并进一步总结为一个标准化流程。
受益于 Claude Skill 的渐进式加载机制,我们也看到在不同工具之间,可以通过渐进式加载的方式实现大模型对工具的自主选择。这与在 SQL 中定义并显式调用执行的存储过程不同,它通过渐进式加载提供了额外的自主性。
SCL核心思想初探:动态、渐进与人机协同
show me the code,给源码爱好者。
从Hardcode开始
我这个人比较懒,硅基流动 给了我们一个例子。我们看到在这个例子里无论什么问题,在和大模型对话的时候我们都hardcode了一个工具列表,这造成了无效token损耗。
渐进式加载的尝试
我们以console log来看渐进式加载的过程,首先我们把4个工具注册到一张表里,然后通过查询其embedding字段的相似度,并以0.5这个数值进行过滤。这样就实现了在比较9.9和9.11的时候只把compare函数给到大模型。
add 相似度 0.32546818256378174 低于阈值 0.5
count_letter 相似度 0.32466569542884827 低于阈值 0.5
mul 相似度 0.2988240958661941 低于阈值 0.5
找到 1 个相似函数
[{'type': 'function', 'function': {'name': 'compare', 'parameters': {'type': 'object', 'required': ['a', 'b'], 'properties': {'a': {'type': 'number', 'description': 'A number'}, 'b': {'type': 'number', 'description': 'A number'}}}, 'description': 'Compare two number, which one is bigger'}}]
ChatCompletionMessage(content='我来帮你比较这两个数字的大小。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[ChatCompletionMessageFunctionToolCall(id='call_00_EkmojHiXrc28KIl7kMm0oXbe', function=Function(arguments='{"a": 9.11, "b": 9.9}', name='compare'), type='function', index=0)])
compare
{"a": 9.11, "b": 9.9}
**9.11 更小。**
**比较过程:**
- 两个数字的整数部分都是 9,所以比较小数部分
- 9.11 的小数部分是 0.11
- 9.9 的小数部分是 0.9
- 因为 0.11 < 0.9,所以 9.11 < 9.9
**结论:** 9.11 比 9.9 小。
人机协作:来自“Hint”的指导
如果你真的跑了现在的代码,show me the code,你会发现在计算重复字母的时候,count_letter工具是没有过阈值的。这里通过OTel把人机协作的过程展开给大家看。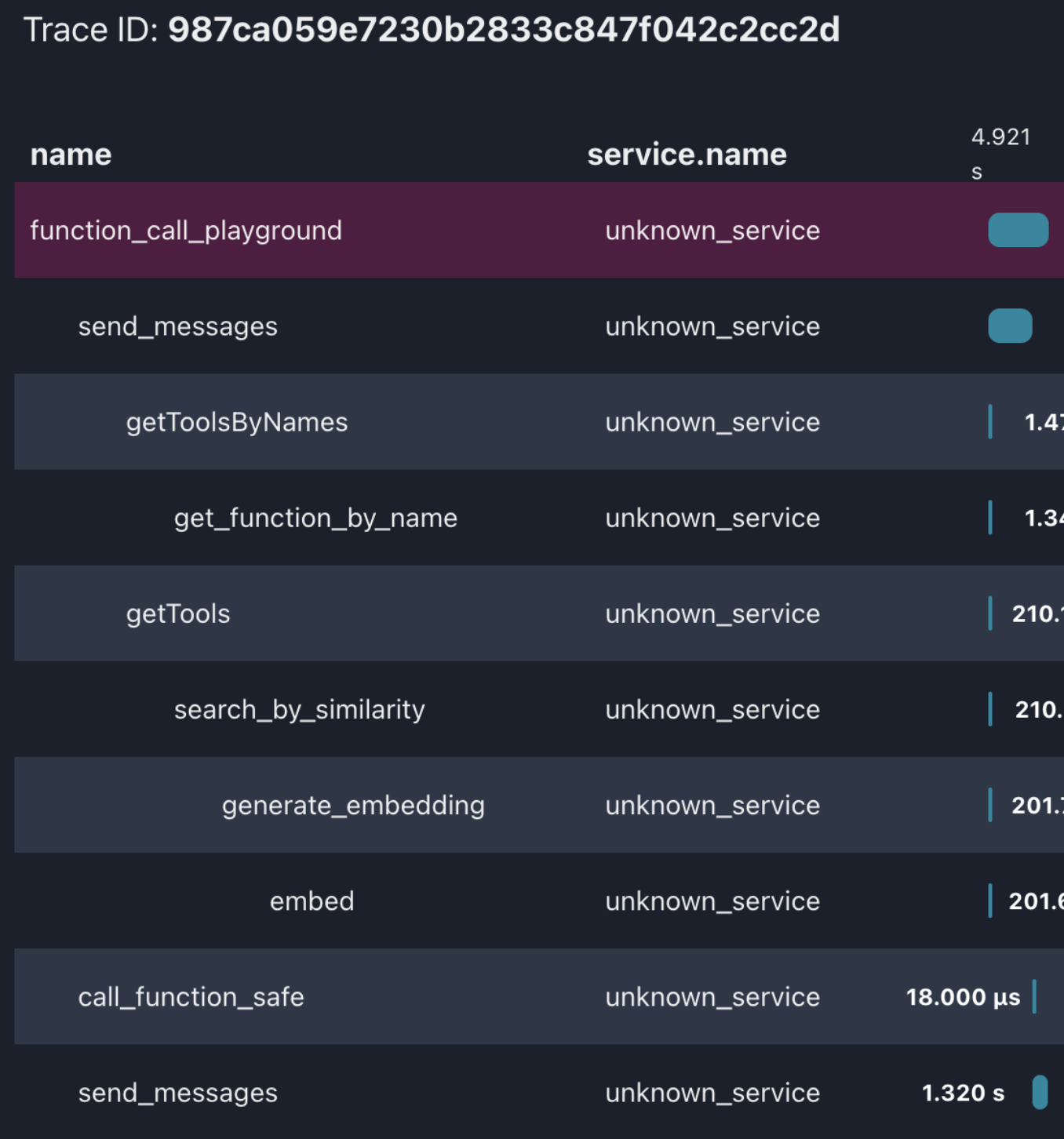
朴素的方式往往有效,类似于SQL的hint,我们设计一个getToolsByNames的逻辑,人给定count_letter这个工具,然后和RAG渐进式查询的结果(getTools)做一个合并,之后在送给大模型就好了。——是不是颇有一种SQL hint的风格?
开源共建:邀请你一起定义未来
笔者实际上也在思考如何应对大模型带来的挑战。诚然现在这个代码大家去看的话有很多vibe的影子,也有很多不完美的地方。这反映了笔者对于大模型加速开发这个问题的回答——以后的软件工程是一个调研,研发和交流不分家的情况。
理想情况下,笔者希望借由结构化上下文语言(Structured Context Language)项目和社区一起通过这一实践,探索总结出一套中间件。该中间件将为智能体提供标准化的接口,其角色类似于 Hibernate 之于 Java 应用程序。
笔者相信,SCL 的最终形态绝非一人之力可达。无论你是对上下文工程有独到见解,想参与规范设计;还是对向量检索效率优化有心得,想提升渐进式加载性能;或是 simply 被这个‘Apple Pen’式的想法所打动——社区都期待你的加入。从这里开始,一起定义智能体时代的‘SQL’。
项目地址:
https://github.com/ob-labs/StructuredContextLanguage
欢迎反馈(issue),PR。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)