拒绝“无效思考”!UIUC、MIT 等顶级高校发布 LORE:大模型推理也得讲“基本法”?
目前的模型训练主要靠海量的 CoT(思维链)数据,但这些数据大多是启发式生成的,没有明确的规则告诉模型:“多难的问题该花多少精力”。这导致了模型在推理预算分配上的低效。动机很简单:我们能不能用数学理论来定义什么是“合理的推理行为”?如果模型能像人一样,根据问题的复杂度动态调整思考量,它的性能会不会更上一层楼?这篇文章最大的贡献在于,它给一直处于“玄学”状态的大模型推理过程提供了一把科学的尺子。它告

论文链接:https://arxiv.org/pdf/2512.17901v1
项目地址:https://github.com/ASTRAL-Group/LoRe
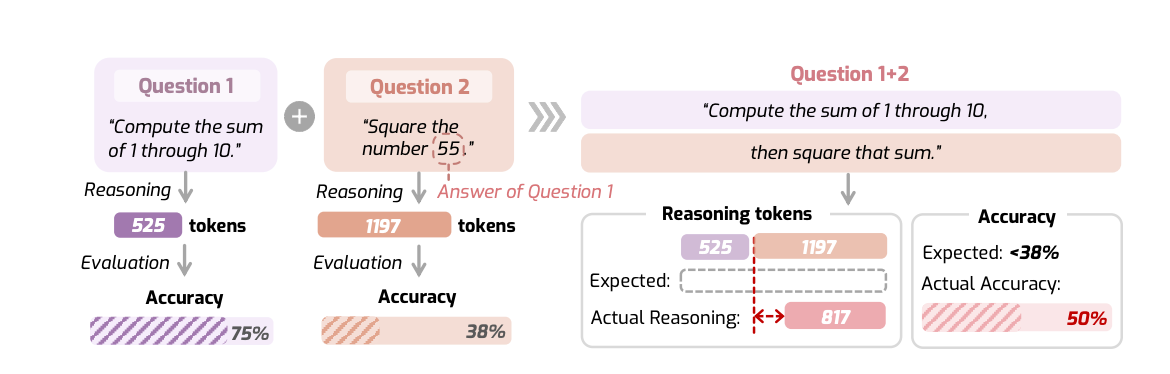
现在的推理大模型(LRM)像 OpenAI o1 和 DeepSeek-R1 确实很强,但它们有时候表现得非常“神经质”。你给它一个超简单的数学题,它可能在那儿嘀咕半天(过度思考);或者给它一个复杂的嵌套问题,它反而草草了事。这就像是一个学生,做加减法用掉一张草稿纸,做微积分却只写一个“解”,这显然不符合咱们人类的思维逻辑。
为了解决这个问题,来自 UIUC、MIT、宾大、纽大等机构的研究者们提出了 LORE (Laws of Reasoning),试图给大模型的推理行为立规矩。
一、 研究背景:为什么 AI 需要“基本法”?
在过去的一年里,我们见证了推理模型的爆发。这些模型采用“先思考、后回答”的模式,在处理复杂逻辑时表现惊人。但研究者发现,大模型的推理行为往往是反直觉的。
1. 任务定义与动机
目前的模型训练主要靠海量的 CoT(思维链)数据,但这些数据大多是启发式生成的,没有明确的规则告诉模型:“多难的问题该花多少精力”。这导致了模型在推理预算分配上的低效。动机很简单:我们能不能用数学理论来定义什么是“合理的推理行为”?如果模型能像人一样,根据问题的复杂度动态调整思考量,它的性能会不会更上一层楼?
2. 核心贡献
论文提出了 LORE(推理定律) 框架,首次对推理复杂度和计算量之间的关系进行了形式化定义。他们不仅提出了“计算定律”和“准确率定律”,还搞出了一个 LORE-BENCH 来考评现有的模型,并最终通过一种叫 SFT-Compo 的微调方法,让模型真正学会了“看菜下饭”。
二、 相关工作:从 o1 到各种“长度控制”
在 LORE 出现之前,学术界和工业界已经意识到推理长度是个问题。比如 OpenAI o1 开启了推理缩放(Scaling Law)的大门,证明了增加测试时计算量(Test-time Compute)能变强。
随后,DeepSeek-R1 和 Phi-4 等模型通过强化学习(RL)进一步压榨了这种推理能力。为了不让模型乱说话,出现了一系列“推理长度控制”的技术,有的在后处理阶段干预,有的在训练阶段加入长度约束。但这些方法大多是“头痛医头”,缺乏一个统一的理论支撑。LORE 的不同之处在于,它不只是想控制长度,而是想让长度和问题的“本质难度”挂钩。
三、 核心方法:LORE 推理定律的“奥义”
两大核心定律
研究者提出了推理的两大基本定律,就像物理学中的牛顿定律一样:
1. 计算定律(Compute Law)
核心假设:推理所需的计算量应该与问题复杂度成正比。
用数学表达就是:
Cθ(x)=αθκ(x)+o(κ(x))C_\theta(x) = \alpha_\theta \kappa(x) + o(\kappa(x))Cθ(x)=αθκ(x)+o(κ(x))
其中:
- Cθ(x)C_\theta(x)Cθ(x):模型在问题x上生成的推理token数量
- κ(x)\kappa(x)κ(x):问题的复杂度(用最少步骤数衡量)
- αθ\alpha_\thetaαθ:比例常数
- o(κ(x))o(\kappa(x))o(κ(x)):可忽略的系统开销
简单说就是:问题越难,思考时间应该越长,而且是线性增长的关系。
2. 准确率定律(Accuracy Law)
核心假设:准确率应该随复杂度指数衰减。
Aθ(x)=exp(−λθκ(x))A_\theta(x) = \exp(-\lambda_\theta \kappa(x))Aθ(x)=exp(−λθκ(x))
其中Aθ(x)A_\theta(x)Aθ(x)是准确率,λθ\lambda_\thetaλθ是衰减率。
这个很好理解:问题越复杂,每一步出错的可能性累积,整体准确率就像滚雪球一样下降。
两个可测量的性质
但问题来了:如何衡量"复杂度"κ(x)\kappa(x)κ(x)?论文巧妙地绕过了这个难题,提出用两个容易验证的性质来替代:
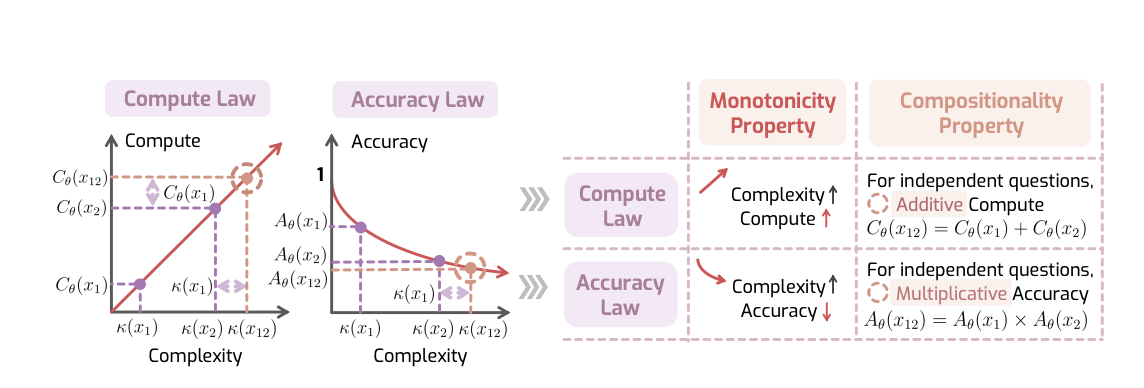
性质1:单调性(Monotonicity)
- 对于计算定律:问题越复杂,推理token越多
- 对于准确率定律:问题越复杂,准确率越低
性质2:可组合性(Compositionality)
-
对于计算定律:两个独立问题的组合,推理token应该等于各自的和
Cθ(x1⊕x2)≈Cθ(x1)+Cθ(x2)C_\theta(x_1 \oplus x_2) \approx C_\theta(x_1) + C_\theta(x_2)Cθ(x1⊕x2)≈Cθ(x1)+Cθ(x2) -
对于准确率定律:组合问题的准确率应该等于各自的乘积
Aθ(x1⊕x2)=Aθ(x1)×Aθ(x2)A_\theta(x_1 \oplus x_2) = A_\theta(x_1) \times A_\theta(x_2)Aθ(x1⊕x2)=Aθ(x1)×Aθ(x2)
这两个性质的妙处在于:不需要知道具体的复杂度值,只需要比较相对关系或测试加法/乘法规律就能验证。
LoRE-Bench评估基准
为了测试模型是否遵守这些定律,研究者开发了两套测试集:
LoRE-Mono(测单调性)

核心思路:从一个种子问题出发,生成30个难度递增的变体。比如矩阵更新问题:
- 变体1:执行1次矩阵操作
- 变体2:执行2次矩阵操作
- …
- 变体30:执行30次矩阵操作
这样复杂度的排序就非常明确了。覆盖数学、科学、语言、代码四个领域,共40个种子问题。
LoRE-Compo(测可组合性)
从MATH500数据集中随机抽取不同学科的问题对(如代数+几何),构成250个三元组:(x1,x2,x1⊕x2)(x_1, x_2, x_1 \oplus x_2)(x1,x2,x1⊕x2)。然后用归一化平均绝对偏差(nMAD)来衡量偏离程度:
nMADf=∑∣fθ(x12)−(fθ(x1)+fθ(x2))∣∑∣fθ(x1)+fθ(x2)∣\text{nMAD}_f = \frac{\sum |f_\theta(x_{12}) - (f_\theta(x_1) + f_\theta(x_2))|}{\sum |f_\theta(x_1) + f_\theta(x_2)|}nMADf=∑∣fθ(x1)+fθ(x2)∣∑∣fθ(x12)−(fθ(x1)+fθ(x2))∣
nMAD越小,说明可组合性越好。
改进方法:SFT-Compo
发现问题后,如何改进?论文提出了一个简单但有效的监督微调方法。
核心思想:挑选那些最符合可组合性的推理路径作为训练样本。
具体步骤:
- 对每个三元组(x1,x2,x12)(x_1, x_2, x_{12})(x1,x2,x12),让模型生成K=8个输出
- 从所有答案正确的组合中,选出最满足加法规则的那组:
argmin∣ℓ(r1)+ℓ(r2)−ℓ(r12)∣\arg\min |\ell(r_1) + \ell(r_2) - \ell(r_{12})|argmin∣ℓ(r1)+ℓ(r2)−ℓ(r12)∣ - 用这些精选的样本进行微调
就像教学生做题,专门挑那些"思考时间分配合理"的答案作为范例。
四、 实验效果:AI 竟然不识“加法”?
研究者用 LORE-BENCH 测试了包括 DeepSeek-R1、Phi-4 在内的多款顶级模型,结果让人大跌眼镜。
1. 模型虽然不傻,但不懂协作
实验发现,大部分模型在单调性上表现尚可——给更难的题,它们确实会多想一会儿。但在组合性上几乎全部翻车!当你把两个简单的题拼成一个大题时,模型往往会产生“思考塌缩”,总思考量远少于单独做两道题的和,这直接导致了组合问题准确率的暴跌。
2. SFT-Compo:让模型学会“1+1=2”
针对这个弱点,研究者提出了一种微调方法。他们专门筛选出那些推理过程符合“相加原则”的正确样本,对模型进行有针对性的训练。
实验结果显示,经过这种微调的模型,不仅在 LORE 考评中得分更高,在 GSM8K、MATH500 等硬核数学竞赛榜单上也全面进化。比如在 8B 规模的模型上,平均 Pass@1 准确率提升了足足 5 个百分点!
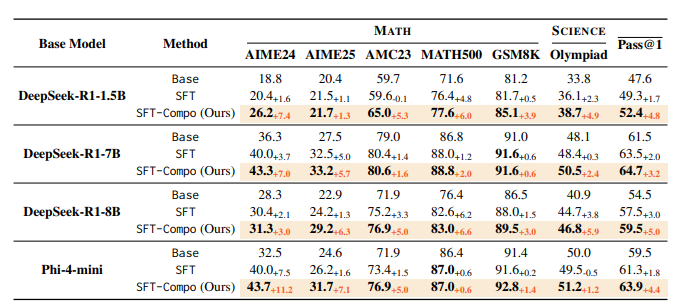
有趣的是,这种训练还产生了“协同效应”:你只是教模型在思考长度上学会加法,结果它在代码和科学问题的逻辑单调性上也变强了。这说明,“学会如何高效分配思考量”是通用推理能力的底层基石。
五、 论文总结
这篇文章最大的贡献在于,它给一直处于“玄学”状态的大模型推理过程提供了一把科学的尺子。它告诉我们,一个优秀的 A大模型不应该只是回答正确,它的思考过程也必须是“合乎比例”的。
通过 LORE 框架,我们发现当前的推理模型虽然在刷榜,但在处理复杂逻辑组合时依然存在巨大的缺陷。而通过强制模型遵循“组合性”原则,我们可以不费吹灰之力地提升它们的实战表现。这为未来开发更智能、更像人类思维的“Agentic RAG”或科学发现大模型 提供了非常重要的指导。
你想知道如何在你自己的本地模型上实装这种“推理基本法”吗?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)