机器学习025:无监督学习【聚类算法】(K-Means)-- 用“分堆游戏”理解数据分组的智慧
今天我们要学一个特别有意思的算法——K-Means聚类算法。别被这个“高大上”的名字吓到,其实它的核心思想特别简单,就像给一堆混在一起的彩色糖果分类一样自然。
想象一下:你面前有一大盒混在一起的红、绿、蓝三种颜色的糖果。你的任务是把它们分成三堆,每堆尽量是同一种颜色。你会怎么做呢?
你很可能会先大概看看这些糖果的颜色分布,心里设定三个“目标颜色”(红色、绿色、蓝色的代表),然后开始分:“这颗糖果比较接近红色代表,放红堆;那颗更接近绿色,放绿堆…”分完之后再看看,可能发现有些分错了,就调整一下目标颜色,重新再分一次,直到满意为止。
K-Means算法做的,和你的这个“糖果分类”过程几乎一模一样,只不过它处理的是数据而不是糖果。接下来,就让我们一起揭开它的神秘面纱吧!
一、从生活场景到数据世界
1.1 无处不在的“分类”需求
在我们生活中,“分类”无处不在:
- 超市里:蔬菜区、水果区、零食区分类摆放
- 图书馆里:文学类、科技类、历史类书籍分区陈列
- 手机相册里:自动识别照片中的人物、地点、风景类型
- 电商平台:根据你的购买记录,把你分到“时尚青年”“居家宝妈”“科技爱好者”等客户群
这些分类让杂乱无章的事物变得井然有序,让我们能更快找到想要的东西,也让商家能更精准地服务不同的客户。
1.2 从人工分类到智能聚类
当数据量很小的时候,人工分类还行得通。但设想一下:
- 淘宝有10亿用户,每个用户有上百条浏览、购买记录
- 一家医院每天产生数万张医学影像
- 一个社交平台每分钟新增百万条动态
人脑已经无法处理这么大规模的分类任务了,这时候就需要算法来帮忙。K-Means就是其中最经典、最常用的“自动分类员”之一。
1.3 为什么从K-Means学起?
对于AI初学者来说,K-Means是绝佳的入门选择:
- 原理直观:就像刚才的糖果分类,容易理解
- 没有复杂的数学:不需要微积分、线性代数基础
- 应用广泛:从商业到科研,处处可见它的身影
- 是理解更复杂算法的基础:很多高级算法都借鉴了它的思想
准备好了吗?让我们正式开始吧!
二、分类归属:K-Means在AI大家族中的位置
在进入具体原理前,我们先给K-Means在人工智能的“家族树”上找到它的位置。
2.1 按功能用途划分:无监督学习算法
人工智能算法主要分两大类:
- 有监督学习:像有答案的练习题。我们给算法很多“题目(数据)”和对应的“正确答案(标签)”,让它学习规律。比如给很多猫和狗的图片,并告诉算法“这是猫”“这是狗”,让它学会区分。
- 无监督学习:像没有答案的探索题。我们只给数据,没有标签,让算法自己发现数据中的结构。K-Means就属于这一类。
通俗理解:
想象你要整理一屋子乱七八糟的玩具。如果有个“分类指南”(哪些是积木、哪些是玩偶、哪些是车模),这就是有监督学习。如果没有任何指南,只能靠观察玩具的形状、大小、颜色自己来分堆,这就是无监督学习。K-Means做的就是后面这种工作。
2.2 按算法类型划分:聚类算法
无监督学习里又主要有两种任务:
- 聚类(Clustering):把相似的数据点分到同一组
- 降维(Dimensionality Reduction):把高维数据压缩到低维,方便可视化
K-Means是最经典的聚类算法之一,它的目标就是:物以类聚,人以群分。
2.3 神经网络分类体系中的位置
你可能听说过“神经网络”,这是现在AI的主流技术。K-Means虽然不算严格意义上的神经网络(它没有神经元、层级结构),但:
- 它是很多神经网络的基础思想来源
- 它处理的问题(数据分组)也是神经网络常处理的问题
- 理解它能帮你更好地理解更复杂的深度学习模型
你可以把K-Means看作AI世界的“基础积木块”,虽然简单,但非常重要。
三、底层原理:K-Means如何工作的?
3.1 核心思想类比:选班长和分小组
让我们通过一个更生动的类比来理解K-Means:
场景:你是班主任,班上有30个学生,你要把他们分成5个学习小组,希望每个小组内的学生成绩水平差不多(物以类聚)。
K-Means的做法:
- 随机选“临时组长”:先随便指定5个学生当临时组长
- 第一次分组:让每个学生选择离自己成绩最近的组长,加入那个组
- 重新选组长:每个组内,重新计算平均成绩,选最接近平均分的人当新组长
- 重新分组:学生再根据新组长的成绩重新选择加入哪个组
- 重复3-4步:直到组长不再变化,或者分组稳定下来
这个过程的核心就是:找中心 → 分成员 → 调中心 → 再分配,不断优化。
3.2 K-Means的工作流程
正式来说,K-Means的工作分为四个步骤:
第一步:初始化
- 确定要把数据分成几类(这就是“K”的含义,比如K=3就是分3类)
- 随机选择K个点作为初始的“聚类中心”(就像随机选临时组长)
第二步:分配
- 对于数据集中的每一个点,计算它到K个中心的距离
- 把它分配给距离最近的那个中心所在的类
- 这样就把所有数据点分成了K个簇(组)
第三步:更新
- 对于每个簇,重新计算它的中心点(通常取簇内所有点的平均值)
- 这些新的中心点替代旧的成为新的聚类中心
第四步:迭代
- 重复第二步和第三步
- 直到中心点不再显著变化,或者达到设定的最大迭代次数
3.3 可视化理解:K-Means的“舞蹈”
让我们用mermaid图示来看看这个动态过程:
想象这个画面:
在一片草地上,有K个领舞者(中心点)和一群舞者(数据点)。开始领舞者随机站位置,每个舞者找到最近的领舞者跟着跳。跳一会儿后,每个小组的舞者重新推选新的领舞者(站在小组的中心位置)。然后舞者再根据新领舞者的位置重新选择跟谁。这样反复几次后,每个小组都稳定下来,形成了K个舞蹈团体。
3.4 数学公式(了解即可,不懂没关系)
如果你好奇背后的数学,这里是最核心的距离计算公式:
距离公式(通常用欧几里得距离):
d(x,c)=(x1−c1)2+(x2−c2)2+⋯+(xn−cn)2 d(x, c) = \sqrt{(x_1 - c_1)^2 + (x_2 - c_2)^2 + \cdots + (x_n - c_n)^2} d(x,c)=(x1−c1)2+(x2−c2)2+⋯+(xn−cn)2
其中x是数据点,c是中心点,n是特征维度。
中心更新公式:
ck=1∣Sk∣∑xi∈Skxi c_k = \frac{1}{|S_k|} \sum_{x_i \in S_k} x_i ck=∣Sk∣1xi∈Sk∑xi
其中ckc_kck是第k个簇的新中心,SkS_kSk是第k个簇的所有点,∣Sk∣|S_k|∣Sk∣是簇中点的数量。
不用担心看不懂公式,只要记住核心思想:不断让每个点靠近自己簇的中心,同时让各个中心相互远离。
3.5 关键概念通俗解释
1. 距离度量:
就是判断两个点“有多像”的标准。就像判断两个人像不像,可以看身高差、年龄差、兴趣爱好重合度等。K-Means最常用的是“直线距离”,就像地图上两点间的直线距离。
2. 聚类中心(质心):
一个簇的“代表”或“平均值点”。比如一个小组学生的平均成绩对应的那个虚拟学生。
3. 迭代:
重复执行相同的过程。就像你整理房间,第一次粗略整理,第二次调整细节,第三次微调,直到满意。
四、局限性:K-Means不是万能的
理解一个算法的局限性,和了解它的能力同样重要。K-Means虽然强大,但也有它的“短板”。
4.1 局限一:需要事先指定K值
问题:你必须提前告诉算法要分成几类。
为什么这是个问题:
就像让你分糖果,但不说要分几堆。有时候你根本不知道数据应该分几类才合适。分太多类,每个类数据太少;分太少类,不同类的数据混在一起。
实际影响:
- 在客户分群时,你并不知道有多少种客户类型
- 在图像压缩时,你不知道用多少种颜色代表原图最合适
解决方法:
- 尝试不同的K值,看哪个效果最好
- 用“肘部法则”等技巧辅助选择
- 使用改进算法如K-Means++
4.2 局限二:对初始中心点敏感
问题:随机选的初始中心点可能影响最终结果。
类比理解:
还是分糖果的例子。如果你一开始随机抓的三颗糖果恰好都是深红色的,那么最终可能把所有红色系糖果都分到了一起,浅红色和深红色没有分开。但如果初始抓的是红色、粉红色、橙色,结果就会更好。
实际影响:
- 同样数据运行多次,可能得到不同结果
- 可能陷入局部最优,而不是全局最优
解决方法:
- 多次运行,取最好的结果
- 使用K-Means++算法更好地初始化中心点
4.3 局限三:只能发现球状簇
问题:K-Means假设每个簇是“球状”的,即各个方向均匀分布。
这是什么意思:
想象你要给人群分类。如果按“身高和体重”分,高瘦、矮胖、高胖、矮瘦会形成四个“球状”区域,K-Means能很好区分。但如果数据是“环绕状”的(比如一个月内每天的气温变化,形成循环),K-Means就力不从心了。
实际影响:
- 无法识别复杂形状的簇
- 对噪声和异常值敏感
解决方法:
- 对数据进行预处理
- 使用密度聚类(如DBSCAN)等替代算法
4.4 局限四:所有特征同等重要
问题:K-Means默认所有特征维度对距离的贡献相等。
类比:
判断两个人像不像,如果同时考虑“身高差1厘米”和“兴趣完全不同”,在K-Means眼里这两者权重相同。但实际上,兴趣不同可能比身高差更重要。
实际影响:
- 不重要的特征可能干扰聚类结果
- 需要先进行特征选择或加权
4.5 正确看待局限性
重要心态:
没有一个算法是完美的,就像没有一种工具能解决所有问题。锤子适合钉钉子,但不适合拧螺丝。了解K-Means的局限,不是要否定它,而是要知道什么时候用它最合适。
五、使用范围:什么样的问题适合用K-Means?
了解了K-Means的能力和局限后,我们来看看它最适合解决哪些问题。
5.1 适合使用K-Means的场景特征
特征一:数据量中等或较大
- K-Means适合处理成百上千到百万级的数据点
- 数据太少可能不够分,数据太多计算可能变慢(但有优化方法)
特征二:簇的形状大致为球状或凸形
- 数据自然形成“一团一团”的分布
- 每个簇在各个方向上大致均匀
特征三:你知道或能估计出大致的类别数
- 或者你愿意尝试不同的K值来寻找最佳分类
特征四:对聚类速度有要求
- K-Means计算效率高,适合需要快速得到结果的场景
5.2 具体适合的任务类型
1. 客户细分与市场分析
- 把客户分成不同群体,针对性营销
- 为什么适合:客户特征(年龄、消费额、购买频率)通常形成自然分组
2. 图像压缩与量化
- 减少图像颜色数量,减小文件大小
- 为什么适合:图像中颜色在RGB空间形成聚类
3. 文档聚类
- 自动将相似文档归为一类
- 为什么适合:文档向量化后在高维空间可能形成簇
4. 异常检测
- 找出与其他数据显著不同的点
- 为什么适合:异常点远离所有簇的中心
5. 数据预处理
- 为其他算法准备数据
- 为什么适合:简单快速,能提供数据的初步结构信息
5.3 不适合使用K-Means的场景
场景一:不知道数据应该分几类,且无法通过简单方法确定
- 这时候考虑层次聚类等算法
场景二:数据簇的形状复杂
- 如环形、半月形、嵌套形
- 考虑DBSCAN、谱聚类等
场景三:数据有大量噪声和异常值
- K-Means对异常值敏感
- 考虑使用鲁棒性更强的算法
场景四:簇的大小差异很大
- K-Means倾向于产生大小相似的簇
- 如果实际情况是有的簇很大,有的很小,结果可能不准确
场景五:需要层次化的聚类结果
- K-Means产生的是扁平结构(所有类别并列)
- 如果需要树状结构(大类别包含小类别),考虑层次聚类
5.4 简单判断法则
当你遇到一个聚类问题时,可以问自己:
- 我大概知道要分几类吗?(是→考虑K-Means)
- 我的数据看起来是“一团一团”的吗?(是→考虑K-Means)
- 我需要快速得到结果吗?(是→考虑K-Means)
- 我的数据有复杂形状或很多噪声吗?(是→考虑其他算法)
如果前三个问题都是“是”,最后一个“否”,那么K-Means很可能是个好选择。
六、应用场景:K-Means在现实世界的精彩表现
理论说了这么多,现在让我们看看K-Means在真实世界中的精彩应用。这些例子会让你真切感受到算法的力量。
6.1 案例一:电商客户细分(精准营销)
场景:
淘宝/京东有数亿用户,每个用户有浏览记录、购买历史、搜索关键词、停留时间等上百个特征。如何针对不同用户推荐他们可能喜欢的商品?
传统做法:
人工划分,比如“男性/女性”“年轻/中年”,但这样太粗糙了。
K-Means的做法:
- 收集每个用户的上百个行为特征
- 确定要分成多少类客户(比如通过分析发现分8类效果最好)
- 运行K-Means算法,自动把相似用户分到同一类
- 分析每一类用户的共同特点
可能发现:
- 簇1:高频高价用户(喜欢奢侈品,购买频繁)
- 簇2:性价比追求者(总在打折时购买,比较价格)
- 簇3:母婴产品专家(大量购买尿布、奶粉、玩具)
- 簇4:数码爱好者(只看不买,研究参数)
- …等等
价值:
平台可以针对每一类用户设计不同的营销策略。对“性价比追求者”推送打折信息,对“高频高价用户”推送新品首发,对“数码爱好者”推送深度评测。转化率能提升30%以上!
6.2 案例二:图像颜色量化(高效压缩)
场景:
一张高清照片可能有上千万种颜色,但很多颜色人眼几乎分辨不出差异。如何减少颜色数量,让图片文件变小,同时保持视觉质量?
传统做法:
简单减少颜色位数,但可能导致重要颜色丢失。
K-Means的做法:
- 把图片中每个像素的颜色(RGB值)看作一个三维空间中的点
- 决定用多少种颜色代表原图(比如256色)
- 运行K-Means,把所有像素颜色分成256个簇
- 每个簇用一个中心颜色代表(簇内所有颜色的平均值)
- 原图中每个像素用所在簇的代表颜色替换
效果:
一张24位真彩色图片(约1677万色)可以压缩到256色,文件大小减少到原来的约1/3,而人眼几乎看不出差别。这在早期计算机存储有限、网速慢的时代特别重要,现在仍用于GIF等格式。
你试过吗?:
微信发送图片时,如果选择“原图”和“普通发送”,后者很可能就用了类似的颜色量化技术。
6.3 案例三:城市区域功能划分(城市规划)
场景:
城市规划部门想要了解城市不同区域的功能特征(商业区、住宅区、工业区、混合区),以便合理配置资源。
数据来源:
- 每个区域的人口密度
- 商业设施数量
- 工业企业数量
- 绿地面积比例
- 交通流量
- 房价水平
- 白天/夜晚人口比(反映通勤情况)
K-Means的应用:
- 将城市网格化,每个网格作为一个数据点
- 收集每个网格的上述特征数据
- 运行K-Means聚类
- 分析每个簇的特征,给它们命名
可能发现:
- 中心商业区:商业设施多,白天人口远多于夜晚
- 传统住宅区:人口密度高,商业少,多为老旧小区
- 新兴开发区:工业企业多,交通流量大,绿地少
- 生态居住区:绿地比例高,房价高,人口密度适中
价值:
帮助政府更科学地规划:商业区增加停车设施,住宅区增建学校和医院,工业区完善物流配套,生态区限制开发强度。
6.4 案例四:新闻/文档自动归类(信息管理)
场景:
新华社每天产生上万篇新闻稿,如何自动将它们归类到“政治”“经济”“体育”“娱乐”等栏目?
挑战:
有些新闻跨多个领域,比如“某明星投资科技公司”既涉及娱乐又涉及经济。
K-Means的解决方案:
- 将每篇新闻转化为向量(通过词频、主题模型等技术)
- 在高维向量空间中运行K-Means
- 自动形成新闻簇
- 人工查看每个簇的典型文章,给簇命名
有趣的是:
K-Means可能发现一些人工没想到的类别,比如“科技金融”“健康养生”“国际教育”等新兴交叉领域。
实际应用:
今日头条、百度新闻等推荐系统背后都有类似的聚类技术,用于理解海量内容并推荐给感兴趣的用户。
6.5 案例五:基因表达数据分析(生物医学)
场景:
医学研究人员收集了1000名癌症患者的基因表达数据(测量每个基因的活跃程度),想发现是否存在不同的癌症亚型,以便个性化治疗。
数据特点:
- 每个患者有上万个基因的表达值
- 数据维度极高
- 希望发现未知的癌症亚型,而不是验证已知分类
K-Means的作用:
- 将每个患者表示为高维空间中的一个点
- 运行K-Means聚类
- 发现患者自然分成的几个群体
- 分析每个群体的基因表达特征、临床预后、药物反应
重大价值:
可能发现新的癌症亚型,这些亚型对特定药物反应更好。这直接关系到治疗方案选择和患者生存率。比如乳腺癌就被K-Means等聚类方法进一步细分为Luminal A、Luminal B、HER2-enriched、Basal-like等亚型,每种需要不同治疗。
七、动手实践:用Python实现一个简单案例
读到这里,你可能已经跃跃欲试了。让我们用一个超级简单的Python例子,亲身体验K-Means的魅力。
7.1 环境准备
如果你从未写过代码,别担心!我会一步步解释。
推荐使用:Google Colab(免费在线Python环境)
- 打开 https://colab.research.google.com
- 点击“新建笔记本”
- 直接复制下面的代码运行
7.2 完整代码示例
# 1. 导入必要的库
import numpy as np # 数学计算库
import matplotlib.pyplot as plt # 画图库
from sklearn.cluster import KMeans # K-Means算法库
from sklearn.datasets import make_blobs # 生成模拟数据
# 2. 创建模拟数据(这样我们知道自己造的数据长什么样)
# 生成300个点,分成4个簇,添加一些随机噪声
X, y_true = make_blobs(n_samples=300, centers=4,
cluster_std=0.6, random_state=0)
# 3. 可视化原始数据
plt.figure(figsize=(12, 5))
plt.subplot(1, 3, 1)
plt.scatter(X[:, 0], X[:, 1], s=50, c='gray', alpha=0.7)
plt.title("原始数据(未分类)")
plt.xlabel("特征1")
plt.ylabel("特征2")
# 4. 使用K-Means进行聚类
# 告诉算法我们要分成4类
kmeans = KMeans(n_clusters=4, random_state=0)
# 训练模型(就是运行K-Means算法)
kmeans.fit(X)
# 获取预测结果(每个点属于哪一类)
y_kmeans = kmeans.predict(X)
# 获取聚类中心
centers = kmeans.cluster_centers_
# 5. 可视化聚类结果
plt.subplot(1, 3, 2)
# 用不同颜色画出不同簇的点
colors = ['red', 'blue', 'green', 'purple']
for i in range(4):
plt.scatter(X[y_kmeans == i, 0], X[y_kmeans == i, 1],
s=50, c=colors[i], label=f'簇{i+1}', alpha=0.7)
# 画出聚类中心(用黑色X标记)
plt.scatter(centers[:, 0], centers[:, 1],
c='black', s=200, alpha=0.8, marker='X', label='中心点')
plt.title("K-Means聚类结果")
plt.xlabel("特征1")
plt.ylabel("特征2")
plt.legend()
# 6. 可视化真实类别(与我们生成数据时知道的真实分类对比)
plt.subplot(1, 3, 3)
for i in range(4):
plt.scatter(X[y_true == i, 0], X[y_true == i, 1],
s=50, c=colors[i], label=f'真实类{i+1}', alpha=0.7)
plt.title("真实分类(供对比)")
plt.xlabel("特征1")
plt.ylabel("特征2")
plt.legend()
plt.tight_layout()
plt.show()
# 7. 打印一些统计信息
print("="*50)
print("K-Means聚类结果分析")
print("="*50)
print(f"聚类中心坐标:\n{centers}")
print(f"\n前20个点的预测类别:{y_kmeans[:20]}")
print(f"前20个点的真实类别:{y_true[:20]}")
print(f"\n算法迭代次数:{kmeans.n_iter_}")
7.3 代码逐行解释(给零基础的你)
第1部分:导入库
- 就像做菜前准备食材和厨具
numpy:数学工具,处理数字计算matplotlib:画图工具,让我们能看到数据sklearn:机器学习工具箱,里面有现成的K-Means算法
第2部分:创建数据
- 我们“造”一些假数据来实验,这样我们知道“标准答案”
make_blobs:生成一团一团的数据,就像我们说的“球状簇”- 300个点,4个中心,每个簇有一定的扩散(cluster_std)
第3部分:画原始数据
- 把300个点画在二维平面上(特征1和特征2是两个坐标轴)
- 这时候所有点都是灰色的,还没分类
第4部分:运行K-Means
KMeans(n_clusters=4):创建K-Means模型,告诉它要分4类kmeans.fit(X):训练模型,就是执行我们前面讲的四步过程kmeans.predict(X):用训练好的模型预测每个点属于哪一类kmeans.cluster_centers_:获取最终的聚类中心坐标
第5部分:画聚类结果
- 用不同颜色画出不同簇的点
- 用黑色“X”标出聚类中心
- 你可以看到算法成功地把数据分成了4个颜色不同的组
第6部分:画真实分类
- 这是我们生成数据时就知道的真实分类
- 对比K-Means的结果和真实情况,看看算法多准确
第7部分:打印信息
- 显示聚类中心坐标
- 显示一些点的预测类别和真实类别
- 显示算法迭代了几次才收敛
7.4 运行结果解读
运行代码后,你会看到:
-
三张并排的图:
- 左:原始数据(灰点一片)
- 中:K-Means聚类结果(四色点+黑色中心)
- 右:真实分类(供你对比)
-
控制台输出:
- 聚类中心的坐标
- 前20个点的预测vs真实类别
- 通常预测和真实高度一致,说明算法有效!
自己动手修改:
- 把
n_clusters=4改成n_clusters=3或5,看看会发生什么 - 把
cluster_std=0.6改成cluster_std=1.5,让簇更分散,看看效果 - 尝试把
centers=4改成centers=5,但n_clusters还是4,看看算法如何处理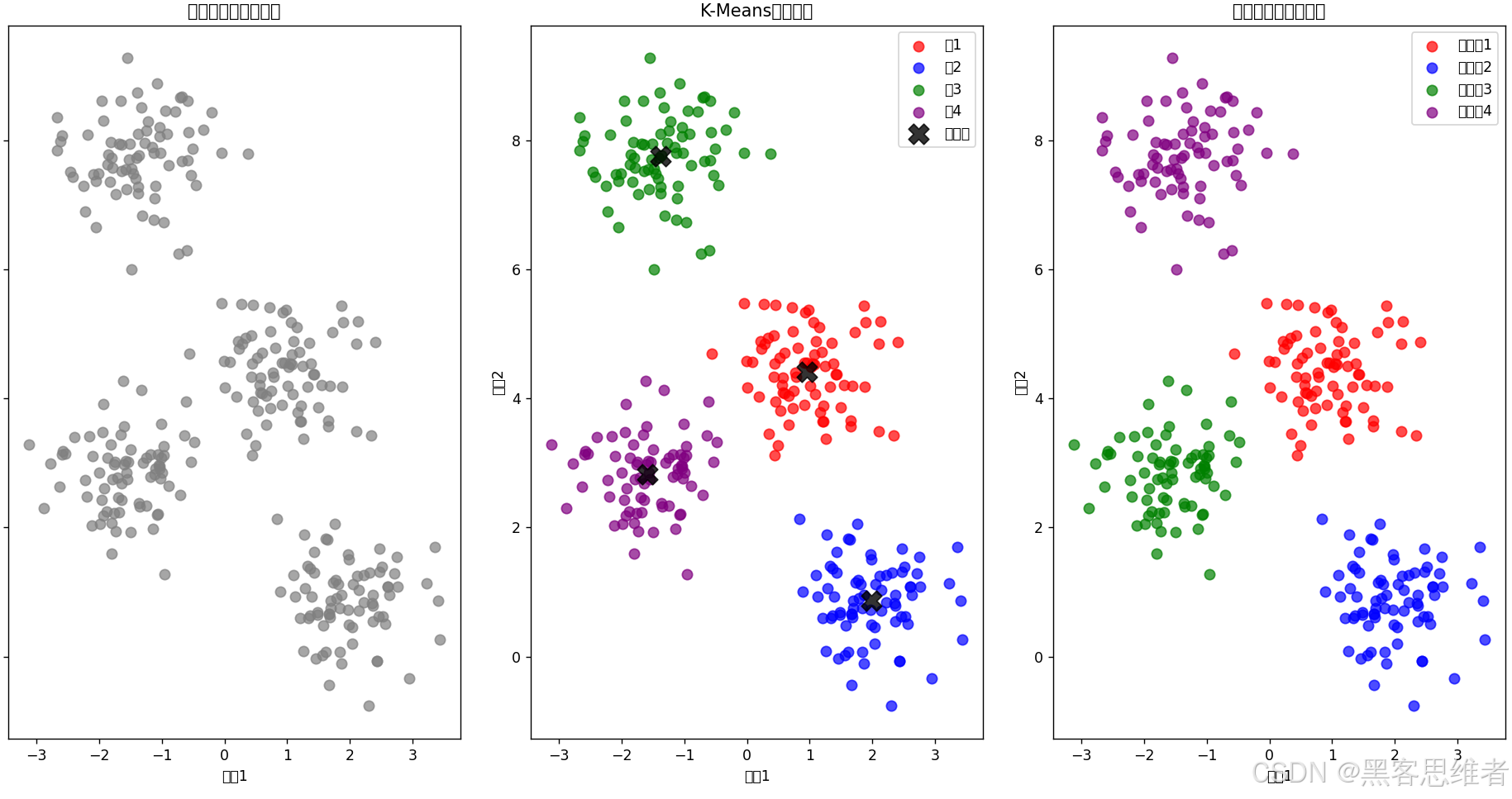
7.5 进阶挑战(如果你想深入)
如果你已经掌握了上面的例子,可以尝试更实际的数据:
# 使用真实数据集:鸢尾花数据集
from sklearn.datasets import load_iris
# 加载数据
iris = load_iris()
X_real = iris.data # 特征:花萼长度、宽度,花瓣长度、宽度
y_real = iris.target # 真实类别:三种鸢尾花
# 运行K-Means(我们知道有3种鸢尾花)
kmeans_real = KMeans(n_clusters=3, random_state=0)
kmeans_real.fit(X_real)
# 评估准确率(但注意:聚类是无监督学习,不一定和真实标签对应)
# 需要调整标签对应关系
from sklearn.metrics import confusion_matrix, accuracy_score
# 调整标签对应(因为K-Means给的标签编号不一定和真实标签编号对应)
y_pred = kmeans_real.labels_
# 这里需要一个简单的标签重映射,我们简化处理
print("聚类中心坐标:")
print(kmeans_real.cluster_centers_)
print("\n你可以分析每个簇的特征,对应到哪种鸢尾花")
这个例子使用了经典的鸢尾花数据集,包含150朵花的4个测量特征和3个真实品种。你可以观察K-Means是否能正确区分这三种花。
八、总结与展望
8.1 一句话概括K-Means的核心价值
K-Means通过不断“找中心-分配点-调中心”的迭代舞蹈,将无标签数据自动分组,让机器学会发现数据中隐藏的自然结构。
8.2 给初学者的学习路线建议
如果你刚刚入门AI,建议这样继续学习:
- 先掌握K-Means:理解它的思想、会用、知道优缺点
- 尝试其他聚类算法:DBSCAN(处理任意形状)、层次聚类(树状结构)
- 学习有监督学习:K近邻(KNN,和K-Means有点像但不同)、决策树、线性回归
- 进入神经网络:从感知机开始,到多层感知机,再到CNN、RNN
- 深入实践:参加Kaggle竞赛,做自己的小项目
8.3 K-Means在AI发展中的位置
虽然深度学习现在是AI的明星,但像K-Means这样的经典算法:
- 仍然是很多应用的首选:简单、快速、可解释
- 常作为预处理步骤:为更复杂的模型准备数据
- 思想影响深远:很多深度学习模型有K-Means的影子
8.4 最后的话
学习AI就像探索一个巨大的迷宫,K-Means是你拿到的第一张简单地图。它可能不展示所有细节,但能帮你建立方向感。
记住:
- 不要被数学公式吓倒,核心思想往往很直观
- 多动手实践,代码跑起来比读十篇文章更有用
- 理解一个算法的局限和它的能力一样重要
- AI本质上是工具,思考“用它解决什么问题”比“它多高级”更重要
恭喜你!已经完成了K-Means的学习之旅。现在你对这个经典算法有了全面的了解:它是什么、如何工作、能做什么、不能做什么。带着这份理解,继续探索AI的奇妙世界吧!
如果有任何问题,或者想了解更多AI知识,随时可以继续交流。学习路上,我们一起进步!🚀
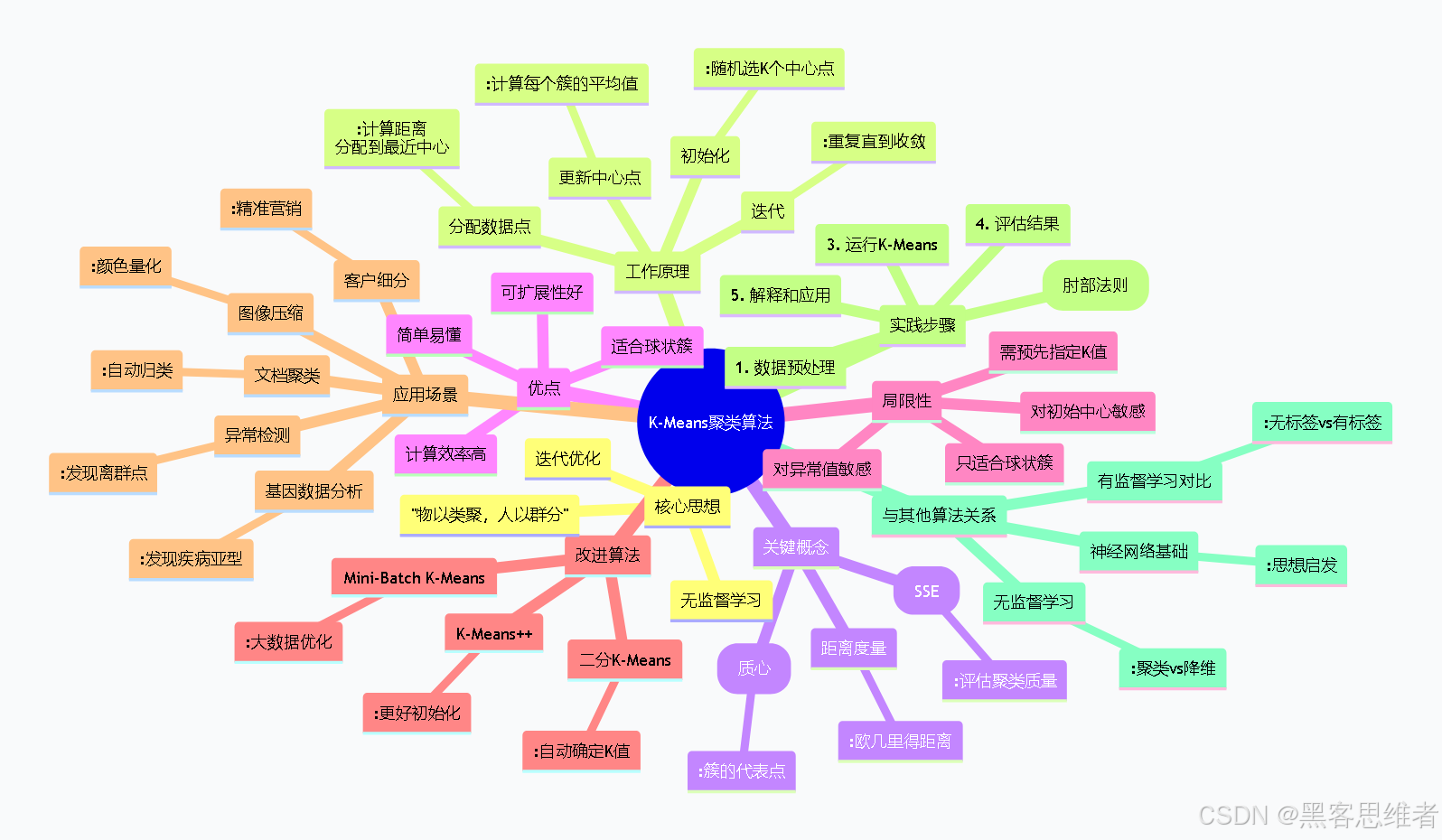
附录:K-Means知识体系思维导图
mindmap
root((K-Means聚类算法))
核心思想
"物以类聚,人以群分"
无监督学习
迭代优化
工作原理
初始化
:随机选K个中心点
分配数据点
:计算距离<br/>分配到最近中心
更新中心点
:计算每个簇的平均值
迭代
:重复直到收敛
关键概念
距离度量
:欧几里得距离
聚类中心(质心)
:簇的代表点
簇内误差平方和(SSE)
:评估聚类质量
优点
简单易懂
计算效率高
可扩展性好
适合球状簇
局限性
需预先指定K值
对初始中心敏感
只适合球状簇
对异常值敏感
改进算法
K-Means++
:更好初始化
Mini-Batch K-Means
:大数据优化
二分K-Means
:自动确定K值
应用场景
客户细分
:精准营销
图像压缩
:颜色量化
文档聚类
:自动归类
异常检测
:发现离群点
基因数据分析
:发现疾病亚型
实践步骤
1. 数据预处理
2. 确定K值(肘部法则)
3. 运行K-Means
4. 评估结果
5. 解释和应用
与其他算法关系
无监督学习
:聚类vs降维
有监督学习对比
:无标签vs有标签
神经网络基础
:思想启发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 36
36 0
0- 0



 已为社区贡献126条内容
已为社区贡献126条内容

所有评论(0)