Palantir本体工程对传统产业AI+有什么启示?(3)知识库的机遇与挑战
但从社会级架构的宏大视角看,要实现高效的全局调度,无法依赖单一实体的强制统一,而必须在“公共知识-领域规则-应用调度”的三层架构中,构建起精密、无损的语义接口标准与执行协议,从而搭建一个开放、可协同的 “语义共同体”。因此,它并非简单的知识库,而是一个“领域知识模型”与“专属规则执行器”深度捆绑的自治单元——这实质上是将Palantir在企业级构建“数字孪生”的模式,复制到行业或区域尺度,形成一个
摘要与导读
近期有篇文章提出的“企业到底该为‘资历’付费,还是为‘判断力’买单?”这一问题,对于探索AI发展非常有启发性。本文尝试从知识库建设的维度回答这个问题,并延伸探讨如下几个议题:
-
Palantir的企业级数字孪生模式,能否扩展到整个数字社会?
-
智能知识系统建设,是否仍然只是“专家的工作”?
-
传统的知识库与当下“AI+”落地需求之间的核心差距是什么?
2018年底我在一家中型云公司时,曾极力推动政企市场开拓,并在国家出台建设县级融媒体政策的起步阶段,研究设计了一套基于知识库的融媒体建设规划方案。

2019年4月定稿版
由于我此前一直从事营销宣传工作,并无技术背景,甚至不了解已有“知识库”这类产品,全凭逻辑推演得出一个核心判断:要重建主流媒体话语权和根治内容乱象,必须搭建一个公共的、通用的底层知识库,将历史文献数字化的同时,通过相关标准、法规建设,规范知识构建(比如词条定义)与信息传播过程,形成内容的全链可溯源机制。



基于这一判断,我勾画了一个理想蓝图,甚至推演了技术架构的基本框架(下图)。有趣的是,方案中提出的从系统融合、信息融合再到业务融合的三阶段演进路线,竟与两年多以后(2021年底)国家出台的《“十四五”推进国家政务信息化规划》中相关思路高度吻合。
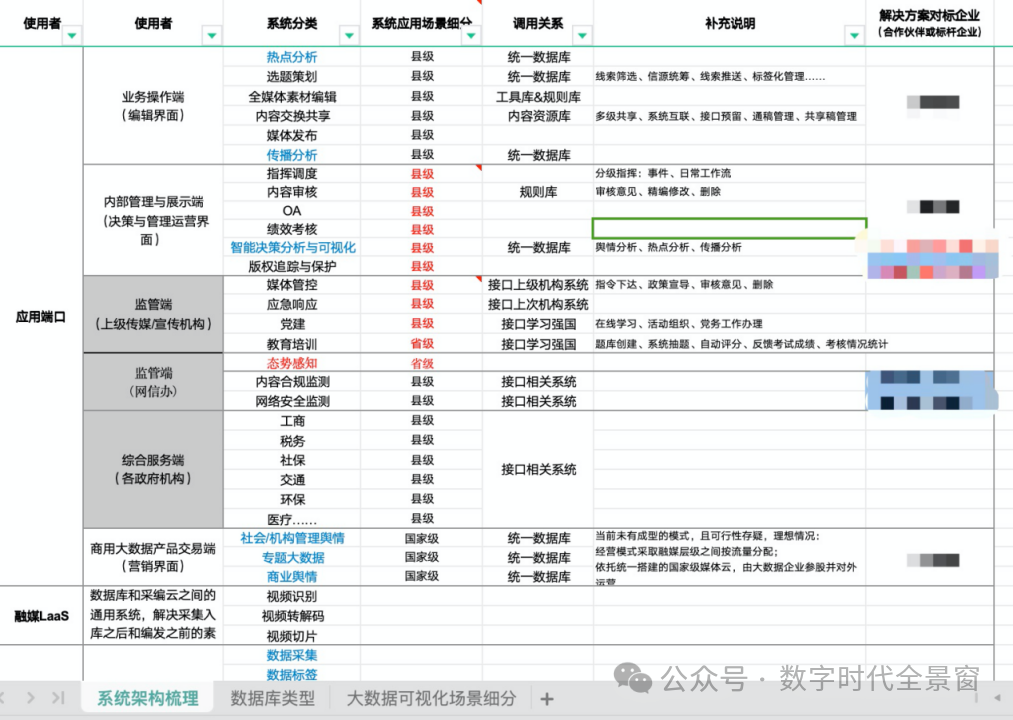
这个项目虽未实际推进,整个方案从今天看也纯属两眼一抹黑之下的yy,但成为我探索数字世界的起点,也是产生“数字世界到底是如何运行的”、以及“数字世界底层架构如何构建”这两个根本追问的由来。
当时的思路其实是清晰的:(目标)重建主流舆论阵地⇥ (方案)公共知识库建设 ⇥ (实施)技术实现与标准支撑。但症结就恰好在技术实现上:彼时的知识库多为静态数据库或文档管理系统,无论是架构弹性、语义理解能力还是规模扩展性,都远不足以支撑重塑整个互联网内容生态秩序这一宏大命题。
这个在当时还是天马行空的构想,却恰好指向当下必须破解的一个关键命题:当社会呼唤数字化的“公共认知基础设施”时,我们究竟需要怎样的技术架构?
“AI+”已经成为各行各业的共同方向,这就意味着企业及其一切流程、环节都将经历深刻的 “本体化” ——即被精确地建模、定义并映射为机器可理解、可计算的数字存在。物理世界与数字世界的运行逻辑逐渐趋于一致,实现无缝的融合与联动。
在这一进程中,通用知识库、规则引擎与基础模型所构成的智能系统“铁三角”,将不再局限于某个特定领域,而是成为所有智能化场景的通用基础架构。它如同数字文明的“操作系统”,为机器提供认知世界、遵循规则并自主决策的核心能力。
Palantir的产品正是这一理念在企业级的极致实践。它本质上是一个将知识库与规则引擎深度、原生融合的统一平台,其中知识与规则是同一业务“本体”的一体两面。
但这套高度集成的 “企业数字孪生”模式,其成功依赖于封闭、可控的环境与自上而下的统一权威设计。如果将尺度扩大到整个社会,则必须探索一条基于开放协议与分层治理的新路径。
这一路径,有可能会呈现为这样的三层架构:
第一层 公共知识库体系(“事实”层)
核心是提供稳定、共识度高、跨领域的权威事实定义与关系(比如“北京是中国的首都”、“水的分子式是H₂O”)。它不处理复杂的商业逻辑,但会提供最基础的语义校验、一致性推理和查询服务,可以看作是一个“基础语义引擎”。
第二层 领域知识与规则库(“逻辑”层)
主要承载特定领域(金融、医疗、汽车等)或区域的法规、标准、业务流程等“领域宪法”。比如汽车业的Catena-X负责定义全供应链的数据交换规则,欧盟的GAIA-X旨在构建可信的欧洲数据基础设施框架。
这一层必须内嵌或紧密绑定一个强大的领域规则引擎,用于实时解释、裁决并执行本领域的复杂逻辑与合规要求。
因此,它并非简单的知识库,而是一个“领域知识模型”与“专属规则执行器”深度捆绑的自治单元——这实质上是将Palantir在企业级构建“数字孪生”的模式,复制到行业或区域尺度,形成一个个领域级的“合规与运营数字孪生”。
第三层 需求与应用引擎(“执行”层)
面向具体业务场景进行任务分解和流程编排,并灵活调用下层的规则与知识服务。核心价值在于将下层的静态知识与规则,转化为针对动态场景的、可执行的工作流,是智能价值最终实现的“总控中心”。例如,一个跨境贸易合规应用,其执行引擎可能需要依次完成以下调度:
-
调用第一层服务:查询“商品归类知识库”,确定货物的唯一标准化编码。
-
调用第二层服务:将编码及贸易方信息,提交至“欧盟贸易规则引擎”进行合规性判定,并获取关税与许可要求。
-
协调外部服务:接入“国际物流状态接口”,结合规则引擎输出的时效要求,规划最优路径。
-
生成执行指令:综合所有结果,自动生成报关文件、物流指令和财务预案。
Palantir通过将“调度与执行”的能力深度内化到其“本体-行动-应用”的一体化架构中,从而消解了独立“引擎”的外部必要性。但从社会级架构的宏大视角看,要实现高效的全局调度,无法依赖单一实体的强制统一,而必须在“公共知识-领域规则-应用调度”的三层架构中,构建起精密、无损的语义接口标准与执行协议,从而搭建一个开放、可协同的 “语义共同体”。
“语义共同体”建设,将会是自互联网基础协议诞生以来,最复杂、也最具决定性的大工程。
这项工程的本质,恰好回答了关于“资历”与“判断力”哪个更重要的问题:
第一层的公共知识与第二层的领域规则,构成了数字世界的“共同记忆”与“成文法”。它们是协同的基石与信任的锚点,是对话得以展开的“语法”与“词典”。没有这份“资历”,一切“判断”都将失去坐标,陷入无意义的混乱。
然而,面对瞬息万变的新场景与复杂现实,真正驱动价值创造的,是在此既定框架下进行灵活调度、创造性提出解决方案、并推动规则持续演进的能力。这份“判断力”,才是将静态知识转化为动态智慧,将数字基座升华为未来图景的关键。
所以,无论对AI技术本身的演进,还是对于搭建AI产业化基石——“语义共同体”(企业级、产业级或社会级)——这项工程而言,路径其实都是清楚的:我们必须先为“资历”付费,即投入建设共识资源;而最终都是在为“判断力”买单,即直面未知、解决问题的智慧与勇气。
相应的,企业用人逻辑也是一样,核心还是判断力。这种判断力有时候来自于直接经验,但在面对新兴领域或者一些复杂问题,经验无法提供现成答案时,能够穿透迷雾、开辟道路的,往往是基于系统认知与第一性原理(其实就是我国传统智慧中的“本末论”)的深度洞察,以及在此之上形成的、敢于承担风险的前沿决策与创新实践。
有了这个认知,回答“知识库是否只是专家的工作”就很简单了:当然不是。
在传统视角下,知识库是专家经验的单向归档,是一个可以被完成的“项目”。但在AI驱动的“语义共同体”蓝图中的知识库建设,目标是打造持续运营、集体共建、人机协同的“认知基础设施”。它不再是知识的终点,而是智能的起点。
这也正是为什么Palantir的FDE(前沿部署工程师)这类角色如此关键,并且必须同时具备顶尖的业务洞察与技术直觉的原因。而其唯一被验证成功的部署方式,是FDE与企业方的业务专家和技术骨干深度捆绑、并肩工作、共同创造。
这项工作的核心,不是简单地将专家的文档录入系统,而是通过紧密协作,将专家的隐性知识、业务的深层逻辑与机器的计算模型,融合锻造为一个活的、可计算的“业务本体”。
它不再是一个存放答案的仓库,而是一个能够不断提出新问题、发现新联系、催生新判断的智慧引擎。
这也就构成Palantir平台与传统知识库的根本差异:
传统知识库本质上是一个静态的“数字图书馆”,其核心架构主要围绕文档的存、管、查来构建,目标是管理好作为“藏品”的文档与数据。
而智能时代需要的知识系统是一个动态的“可计算的本体对象”。比如Palantir的Foundry,其核心目标是对企业这一复杂有机体进行数字孪生。它通过“本体”定义企业的核心概念、关系与逻辑,将散乱的数据转化为可理解、可推理、可操作的业务对象,是对运行中世界的实时映射与操控。
与传统知识架构相比,智能架构实现了三大根本转变:
-
从“文档存储”到“本体建模”:核心资产从孤立、静态的文档,转变为一个能够精确定义业务现实、并刻画概念间关系、实时映射对象动态变化的“本体”模型。这如同从建造一个存放“历史标本”的档案馆,转向构建一个能够同步呼吸与脉动的“数字生命体”。
-
从“关键词匹配”到“语义推理”:交互从寻找文档升级为直接获得答案、洞察与可执行方案,甚至自动触发业务流程。
-
从“被动查询”到“主动赋能”:系统从等待用户提问的工具,变为融入业务流程、主动提供支持甚至自动执行的伙伴。
所以,从传统知识库迈向智能知识系统,绝非简单的技术升级,更不是知识库与知识图谱的机械叠加,而是一场从思维模式、组织架构到技术体系的系统性变革。它没有一键切换的按钮,但有一条清晰的“先建模,后智能”的演进路径:
第一阶段:认知启动——从“文档思维”到“本体思维”
选定突破口:选择一个业务价值高、数据基础好、痛点明确的场景(如“设备故障维修”、“合规合同审查”)。
定义最小本体:召集业务专家与技术架构师,回答:这个场景涉及哪些核心概念(如设备、故障、工单、备件)?它们之间有什么关键关系?这就是初始“本体”。
产出:一份业务概念图谱和实体关系定义,而非任何代码或数据库。
第二阶段:能力筑基——构建“可计算”的知识层
建立知识图谱:基于“本体”,将散落在各处的数据(手册、工单、传感器日志)进行清洗、关联,存入图数据库,形成可查询、可追溯的关系网络。
封装业务规则:将专家的决策逻辑(如“若设备A连续报警3次,则自动创建最高优先级工单”)转化为可被系统执行的规则或模型。
产出:一个活的、可查询的知识图谱和一套可执行的规则包。
第三阶段:智能涌现——实现“主动赋能”
接入AI能力:
感知:利用NLP自动解析工单、报告,丰富图谱。
交互:部署智能问答,让员工用自然语言查询知识、获取方案。
决策与行动:将规则引擎与工作流系统打通,实现从诊断到派单、备件调拨的自动化闭环。
建立运营闭环:设计机制,让系统在实际使用中产生的反馈、新案例能反哺优化本体、规则和模型。
产出:一个能够主动预警、推荐方案、自动执行的智能业务伙伴。
【相关专题】
“一半天堂一半地狱”:人才富集与产业空心化,AI为什么也这么难?
汽车工业第四代生产范式,为什么没有率先出现在中国?(1)四个问题,读懂特斯拉超级工厂和第四代生产范式
汽车工业第四代生产范式,为什么没有率先出现在中国(2):智能制造的核心竞争逻辑,从上海超级工厂的特殊地位说起
汽车工业第四代生产范式,为什么没有率先出现在中国(3):为什么也没有诞生在德国?
汽车工业第四代生产范式,为什么没有率先出现在中国(4):美国“去工业化”与特斯拉崛起的悖论
汽车工业第四代生产范式,为什么没有率先出现在中国(5):工业强国的真正标准
从“互联网+”到“人工智能+”:云计算生态演进揭示AI应用破局之道
解密Palantir:AI+时代企业IT演进与“本体”变革的深度剖析
Palantir解密:从企业数字化能力构成说起,“本体”如何破解现代企业数据应用难题?
Palantir解密:从AI到AI Agent,为什么需要“本体”?有没有其他方案?
Palantir解密:李飞飞与强化学习之父对大模型的批评有何不同?兼论“本体”的哲学本质
大模型、VLA模型、世界模型:谁代表通用人工智能未来?“智能仿生学”视角的分析
Palantir解密:从单智能体到多智能体社会,本体、AIP、Apollo如何成就群体智能?
“智能”的归途:空间智能是世界模型的终点吗?Palantir研究总结(2)
商业的魔法:“本体”如何点石成金?Palantir研究总结(3)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 29
29 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)