NanobananaPro/GPT-4o/Sora2/国产模型谁最强?ViStoryBench:全能故事可视化基准首发!
评估对象涵盖开源图像生成(StoryDiffusion, OmniGen2)、商业闭源模型(MOKI, Doubao, MorphicStudio)、多模态大模型(GPT-4o, Gemini)及视频生成模型(Sora2, Vlogger),揭示不同技术路线的结构性优势与短板。如果把“故事可视化”理解成一次跨媒介的“编码—传输—解码”:文本剧本(编码)→ 模型生成图像/分镜(传输)→ 观众在多镜头

论文链接: https://arxiv.org/abs/2505.24862
项目链接: https://vistorybench.github.io
代码链接: https://github.com/vistorybench/vistorybench
亮点直击
如果把“故事可视化”理解成一次跨媒介的“编码—传输—解码”:文本剧本(编码)→ 模型生成图像/分镜(传输)→ 观众在多镜头中读出人物与情节(解码)。那么,难点从来不只是“画得好看”,而是叙事信息能否稳定、可控、可验证地被传递。ViStoryBench 的价值就在于:第一次把这套“传播链路”拆开来测。
-
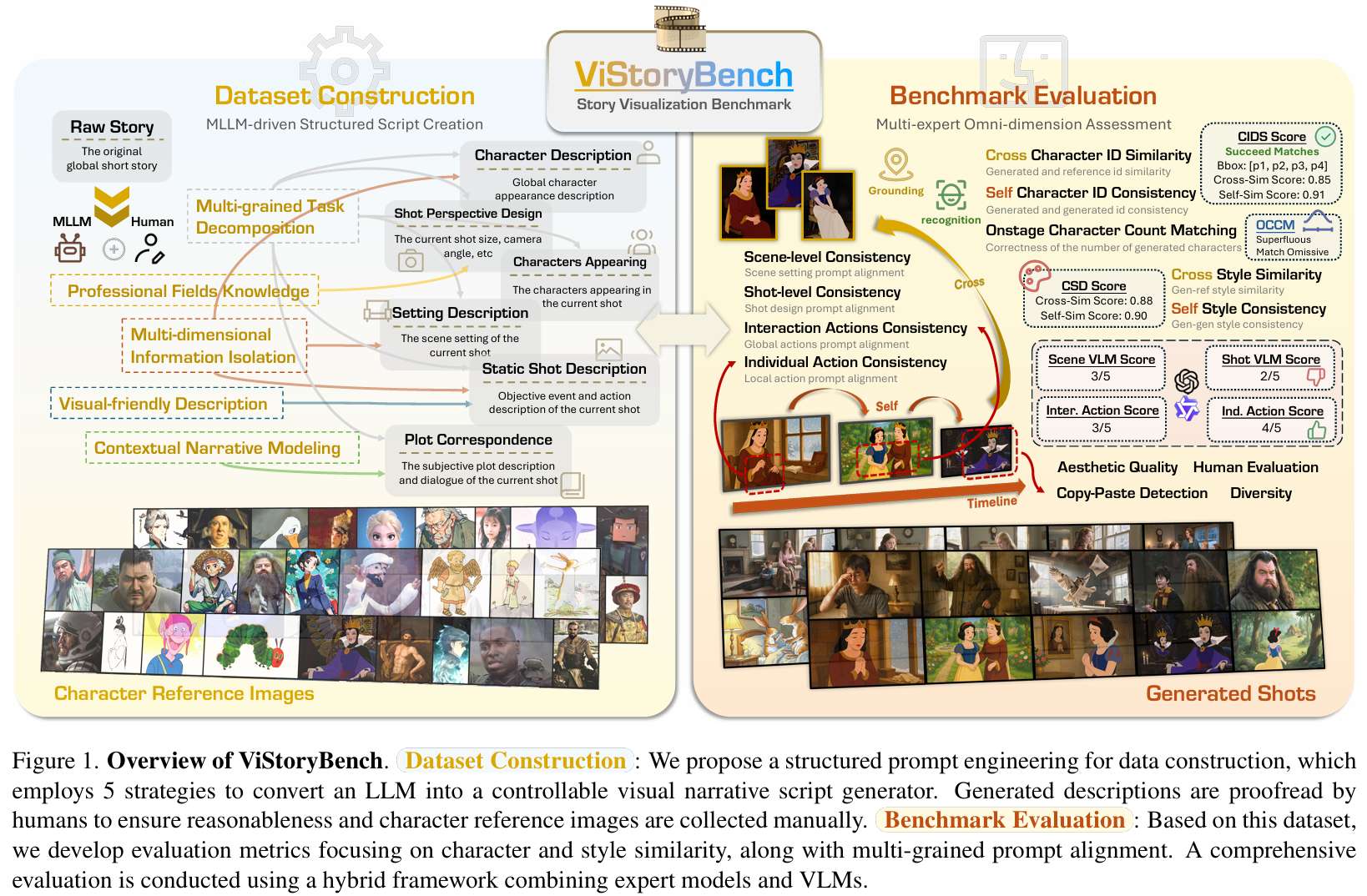
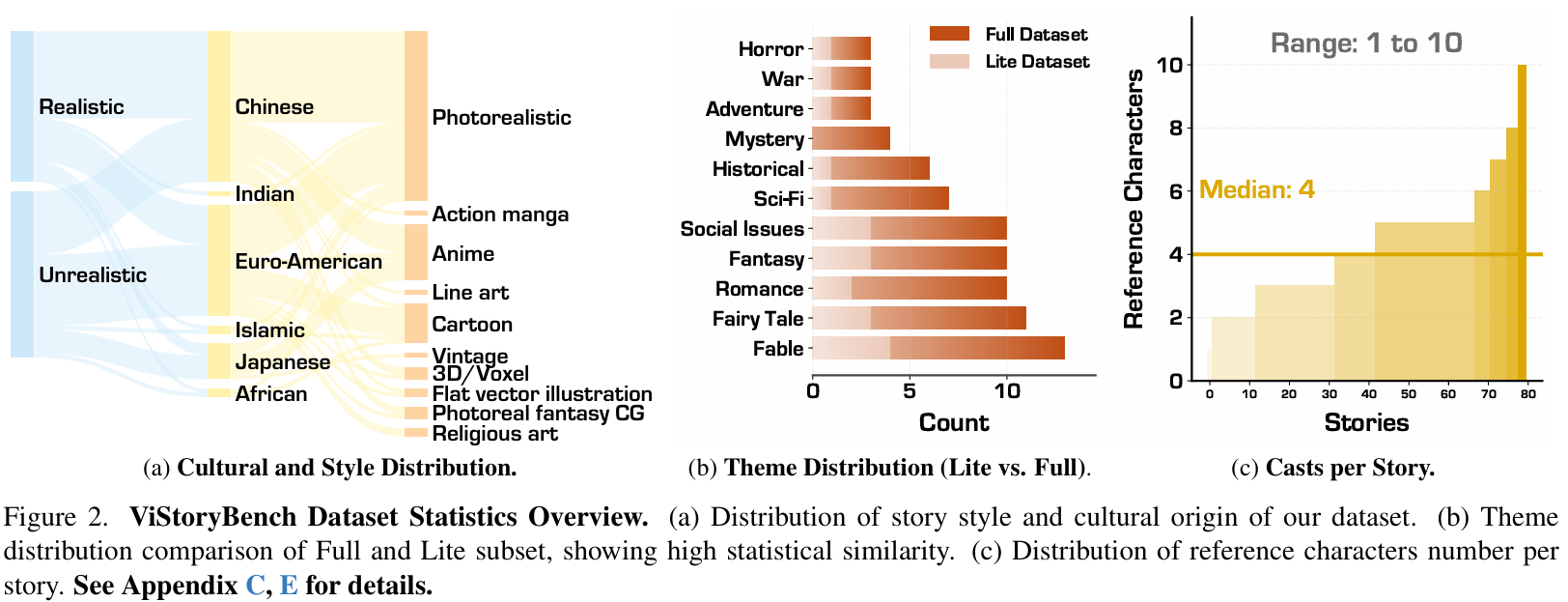
首个全能故事可视化基准:ViStoryBench 是一个全面的基准测试套件,涵盖80个多镜头故事、10种视觉风格和1300+个分镜,旨在评估模型在复杂叙事结构、视觉风格和角色设定下的生成能力。
-
12维硬核评测指标:引入包括角色ID一致性(CIDS)、同屏角色计数(OCCM)、复制粘贴检测(Copy-Paste)等在内的12项自动化指标,并通过人类评估验证了其可靠性。
-
30+主流模型大考:评估对象涵盖开源图像生成(StoryDiffusion, OmniGen2)、商业闭源模型(MOKI, Doubao, MorphicStudio)、多模态大模型(GPT-4o, Gemini)及视频生成模型(Sora2, Vlogger),揭示不同技术路线的结构性优势与短板。
-
ViStoryBench-Lite:针对评估成本高的问题推出 Lite 版本,在保持统计分布一致性的前提下,用更低成本实现“可代表性”的能力测评。
解决的问题
1)现有基准“只测画面,不测叙事链路”
当前故事可视化(Story Visualization)基准往往范围狭窄:要么局限于短提示词、要么缺乏角色参考图(Character Reference),要么只关注单张图像。结果是:它们很难覆盖真实创作里最关键的传播目标——多镜头连续叙事中的信息一致性(角色、场景、动作、镜头语言)。
2)缺乏统一标准,导致“各说各话”
不少工作只用少量指标评估,缺少衡量叙事对齐度、风格一致性、角色交互的共同标尺。传播学上这会造成一个后果:你无法区分模型到底是“理解了故事”,还是“碰巧生成得像”。
3)“复制粘贴”作弊:一致性被刷出来了
很多模型为了维持角色一致性,直接把参考图“贴”到生成结果里(或高度复用其局部特征),牺牲了剧情所需要的动作、表情变化。更麻烦的是:传统指标往往会把这种“作弊式一致性”当作能力提升,从而让评测结论失真。

提出的方案
多面数据集构建(Multifaceted Dataset Creation) ViStoryBench 精选80个故事片段,来源覆盖电影剧本、文学经典、民间传说等,LLM 辅助摘要与剧本生成并经人工校验。它用结构化提示工程把 LLM 变成“可控的分镜剧本生成器”,剧本由五个维度构成:
-
场景描述(Setting)
-
情节对应(Plot)
-
登场角色(Onstage Characters)
-
静态镜头描述(Static Shot)
-
镜头视角设计(Shot Perspective Design)
数据集包含344个角色、509张参考图,覆盖10种视觉风格(如日系动漫、写实电影、绘本风等)。这相当于把“叙事传播”拆成可标注、可复核的单位,让评测不再停留在“感觉像不像”。
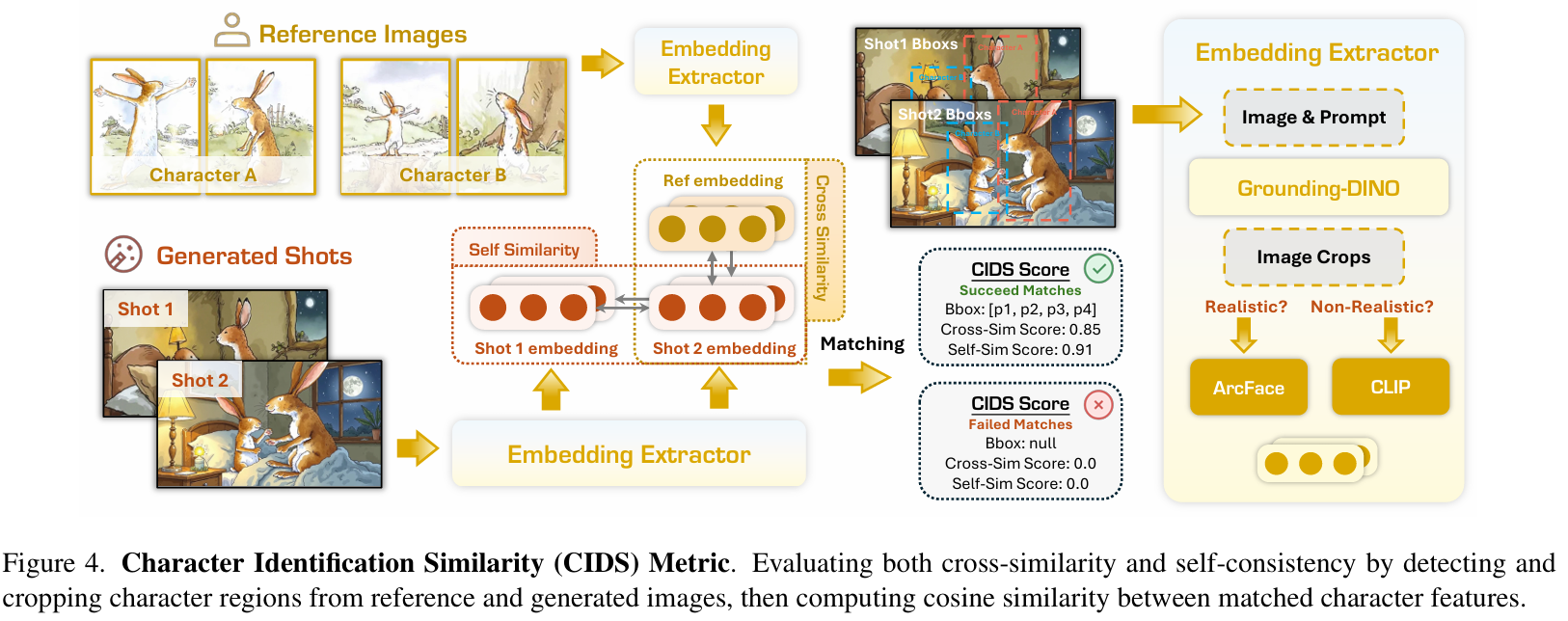
全方位评估指标(Comprehensive Evaluation Metrics) 为了把“讲故事能力”落到可量化的维度,ViStoryBench 设计了12项自动指标,核心是把模型的输出拆成几类传播失真:身份失真、数量失真、对齐失真、风格失真、以及投机失真。例如:
-
角色识别相似度(CIDS):检测角色并提取特征,计算生成图与参考图(Cross)及生成图之间(Self)的余弦相似度。
-
同屏角色计数匹配(OCCM):针对“幻觉加人/漏画人”,量化生成角色数量的准确性。
-
复制-粘贴检测(Copy-Paste Detection):通过几何归一化特征比对,检测过度复用参考图的投机行为。
-
提示词对齐(Prompt Alignment):利用专家模型与 VLM,对场景、运镜、角色交互、个体动作进行细粒度打分。
应用的技术
-
LLM-driven Script Creation:用大语言模型做剧本的结构化拆解与分镜化表达。
-
Hybrid Evaluation Framework:结合专家模型(ArcFace, Grounding DINO)与多模态大模型(GPT-4o, Qwen-VL)的混合评估框架。
-
Character Identification Similarity(CIDS):基于特征提取与二分图匹配的角色一致性计算。
-
Copy-Paste Rate:基于 Softmax 概率分布,衡量生成特征对某张参考图的“过拟合式贴图”。
国内外各个模型的表现
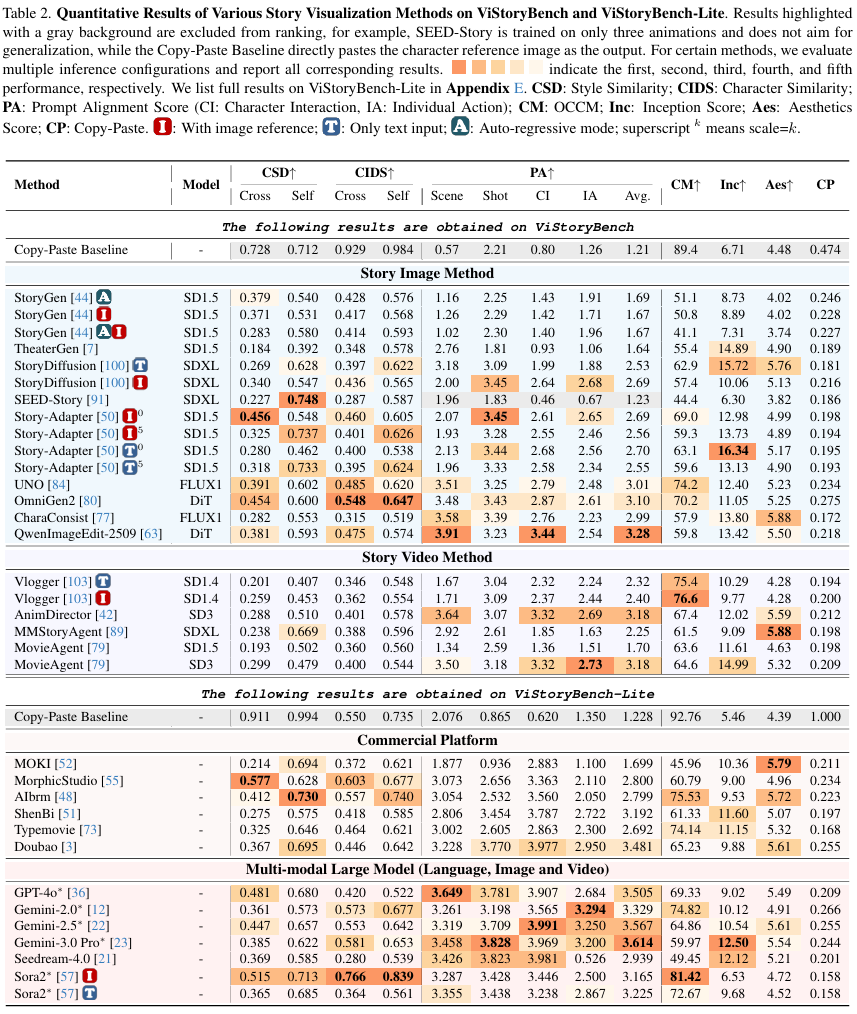
对30+方法的大规模评测给出了几条很“现实”的结论——不同路线在传播链路的不同环节各有强项:
GPT-4o 的双面性
GPT-4o 在 叙事对齐(Alignment Score: 3.67) 和 角色计数(OCCM: 93.5) 上非常强,说明它在“理解剧本并按指令组织信息”方面优势明显;但在视觉质量(Inception Score)与风格多样性上略逊,体现出“会讲”未必“会画”。
商业软件的优势
MorphicStudio、Doubao 等商业工具在 美学质量(Aesthetics) 和 风格一致性上更稳,更像面向生产的“视觉呈现优化”;但细粒度叙事控制弱一些,对镜头语言的精准响应也不如 LLM 路线稳定。
Sora2 的多镜头能力
作为原生视频模型,Sora2 在 跨镜头一致性(Self-Sim: 0.813) 表现突出,背后是对电影数据的学习红利;但在遵循特定视觉参考(Image Ref Cross-Sim)上仍有提升空间——更“像电影”,但未必更“像你指定的角色”。
视频 vs 图像
目前视频生成模型(Vl ogger、MovieAgent)在单帧质量与角色一致性上,普遍不如专门的故事图像方法(OmniGen2、UNO)。时间维度带来连贯性红利,也带来每帧细节的损耗。
权衡(Trade-off)
一致性(Consistency)与多样性(Diversity)存在明显权衡:越一致越可能“复制粘贴”,越多样越可能“跑角色”。Copy-Paste 指标把这个隐性矛盾显性化,避免被“刷分式一致性”误导。
结论与局限性
ViStoryBench 是目前评估故事可视化任务最全面、最严格的基准:它不仅提供高质量多镜头数据集,还把“讲故事”拆成可自动化度量的能力结构。实验结果也很直观:没有任何单一模型能在所有维度通吃——LLM 更擅长叙事组织,商业工具更擅长视觉呈现,视频模型更擅长跨镜头连贯。
局限性:目前主要聚焦多图一致性评估,尚未纳入音频对齐或更复杂的时序动态指标;混合评估中使用的 VLM 仍可能存在少量幻觉(已做稳定性测试)。未来工作将补齐背景一致性评估,并向长视频叙事基准迈
参考文献
[1] ViStoryBench: Comprehensive Benchmark Suite for Story Visualization

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)