强化学习 [page16][chapter8] Value Function Methods
在离散且有限的状态与动作空间中,该方法为每一个状态(或状态-动作对)分配独立的存储单元,以表格形式(如 Q 表)精确记录其对应的价值估计。:函数逼近器能够根据输入状态的特征自动产生输出,对未被访问过的状态也能给出合理的价值估计,从而显著加速学习进程,提升智能体在复杂环境中的适应性与决策能。,凭借其强大的非线性表征能力,能够拟合极其复杂的高维值函数,已成为解决像围棋、机器人控制等复杂问题的主流方法。
Google DeepMind在机器人强化学习中使用Vision Transformer,以图像作为状态输入,这无法用传统的表格方法表示。本章将解决此类问题。
我们继续探讨时间差分学习算法,但采用不同的状态/动作值表示方式。此前我们使用表格法,其虽直观却不适用于大规模状态/动作空间。为此,本章引入值函数逼近方法,这已成为标准解决方案,也为神经网络作为函数逼近器进入强化学习奠定了基础。值函数的概念还可扩展至策略函数,详见第9章。

目录:
- 值函数表示
- 值函数优化的目标函数
- 值函数优化算法
- 函数近似器的选择
- 值函数近似例子
- 理论分析
一 值函数表示: From table to function
1.1 表格型方法的局限
早期强化学习主要采用表格型方法来表示值函数。在离散且有限的状态与动作空间中,该方法为每一个状态(或状态-动作对)分配独立的存储单元,以表格形式(如 Q 表)精确记录其对应的价值估计。智能体通过查表获取价值并做出决策。
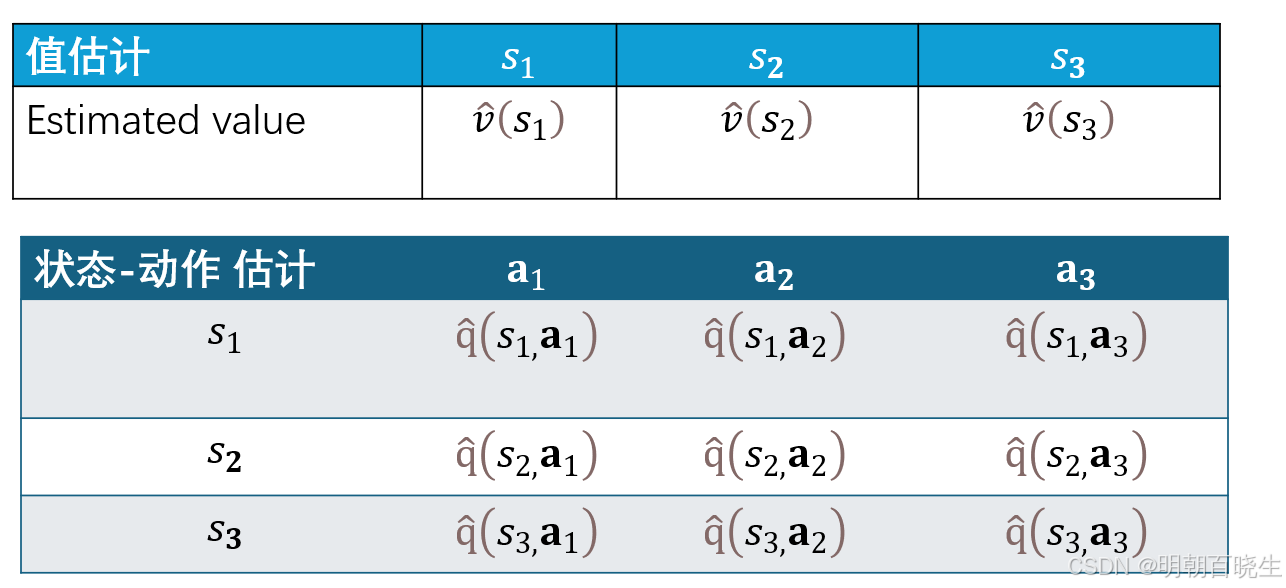
然而,表格型方法存在显著局限:
维数灾难:随着状态或动作空间规模增大,表格维度呈指数级增长,导致存储开销剧增,内存消耗不可承受。
计算低效:大规模表格的更新与查询计算复杂度高,学习速度缓慢。
泛化缺失:表格中每个单元的值独立估计和更新,无法将已学知识推广到未访问过的相似状态,造成数据利用率极低。
无法处理连续空间:对于连续状态或高维离散空间(例如围棋,其状态空间规模约为
,几乎无法为每个可能的状态分配表项,因此表格法在计算上完全不可行。
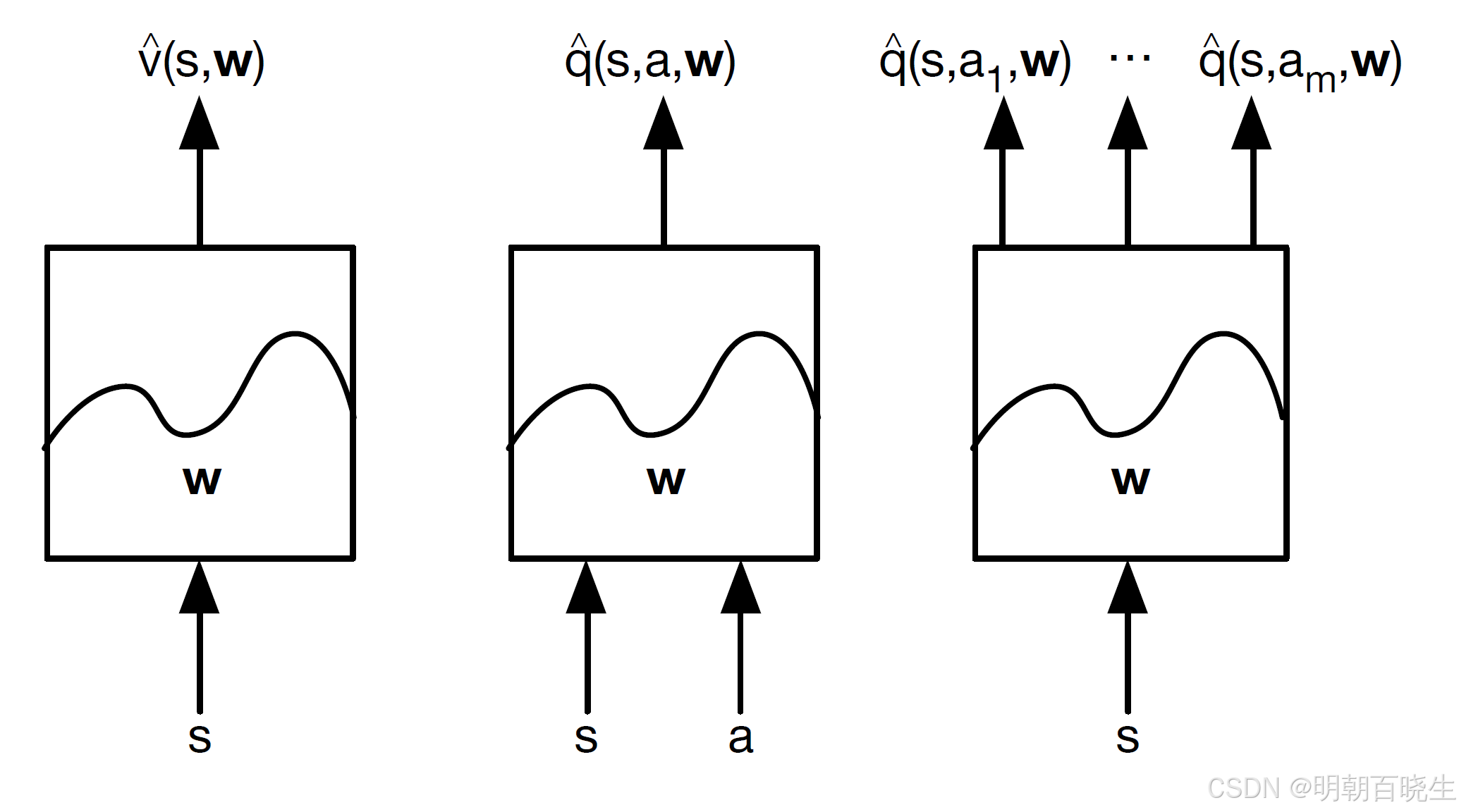
1.2 函数逼近方法
为克服上述局限,函数逼近被引入值函数表示中。其核心思想是使用一个参数化的函数 或
来近似真实的值函数
或
,其中 w 为可学习的参数向量。
该函数可以是:
-
线性逼近器:基于状态的特征向量进行线性组合,简单高效。
-
非线性逼近器:如深度神经网络,凭借其强大的非线性表征能力,能够拟合极其复杂的高维值函数,已成为解决像围棋、机器人控制等复杂问题的主流方法。
通常有如下几种
函数逼近的优势在于:
存储经济:只需存储参数 w,而非整个价值表,极大节约内存。
计算高效:通过梯度下降等优化方法批量更新参数,学习效率高。
具备泛化能力:函数逼近器能够根据输入状态的特征自动产生输出,对未被访问过的状态也能给出合理的价值估计,从而显著加速学习进程,提升智能体在复杂环境中的适应性与决策能
力。
二 值函数优化的目标函数
令 和
分别表示状态
的真实状态值和近似状态值。
待解决的问题: 是找到一个最优参数 w,使得 能够最佳地逼近每个状态 s的
。具体而言,目标函数为:
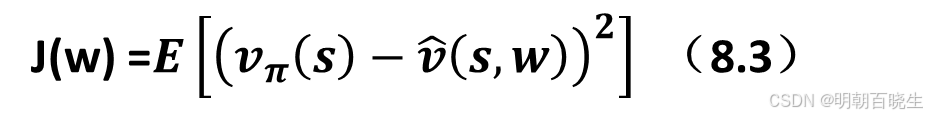
其中期望是关于随机变量计算的。既然 S 是一个随机变量,它的概率分布是什么?这个问题对于理解该目标函数至关重要。定义 S的概率分布有以下几种方式:
第一种方式 均匀分布(uniform distribution)
将每个状态的概率设为 1/n,将所有状态视为同等重要。在这种情况下,式 (8.3) 中的目标函数变为:
这是所有状态近似误差的平均值。然而,这种方式没有考虑给定策略下马尔可夫过程的实际动态特性。由于某些状态可能很少被策略访问,将所有状态视为同等重要可能并不合理。

第二种方式 平稳分布(stationary distribution)
平稳分布描述了马尔可夫决策过程的长期行为。更具体地说,在智能体执行给定策略足够长的时间后,智能体处于任何状态的概率可以用该平稳分布来描述
令
表示策略 π下马尔可夫过程的平稳分布。即智能体在长时间后访问状态 s 的概率为
。根据定义,
。那么,式 (8.3) 中的目标函数可以重写为:
这是一个加权平均的近似误差。被访问概率较高的状态被赋予更大的权重。
值得注意的是,dπ(s) 的值不易直接获得,因为它需要知道状态转移概率矩阵 Pπ
幸运的是,如下一节所示,我们无需计算 dπ(s) 的具体值来最小化该目标函数。此外,在介绍式 (8.4) 和 (8.5) 时,我们假设状态数量是有限的。当状态空间连续时,我们可以将求和替换为积分。
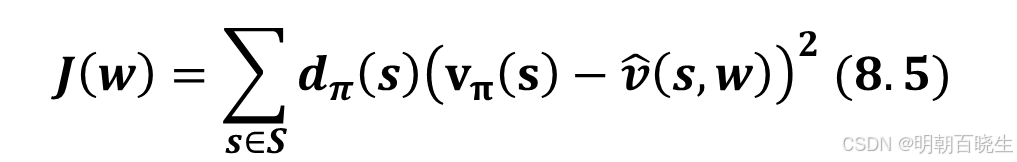
三 值函数优化算法
为了求解,目标函数J(w)的最小值 ,我们通过gradient descent algorithm 求解
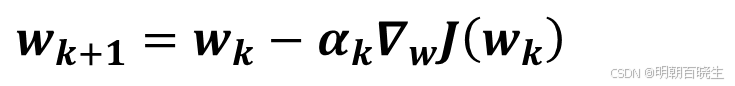
其中
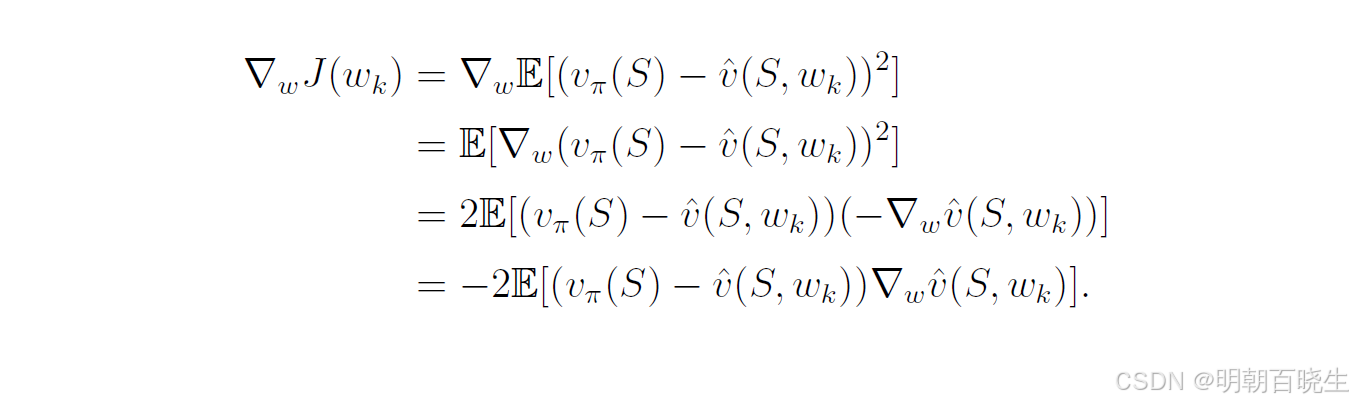
因此 gradient descent algorithm 为

其中,系数 2 置于 前时,为不失一般性可将其并入
中。(8.11)中的算法需要计算期望值。本着随机梯度下降法的思路,我们可以用随机梯度替代真实梯度。于是,(8.11)式变为

其中为随机变量S t时刻的采样值得注意的是,(8.12)式无法实际执行,因为它需要真实的状态值
,而该值未知且必须进行估计。我们可以用一个近似值来替代
,以使算法能够实际执行。可采用以下两种方法来实现这一点。
方法一 蒙特卡罗方法:
假设我们有一个片段(序列)
。设
为从状态
开始的折扣回报。那么,
的近似值。于是,(8.12)中的算法变为:
这就是采用函数近似法的蒙特卡罗学习算法。
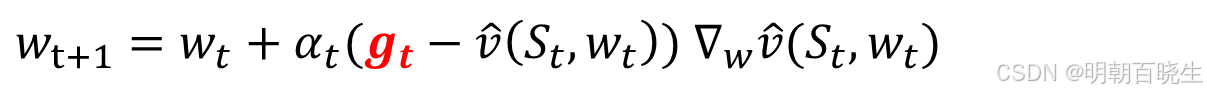
方法二 时间差分方法:
本着时间差分(TD)学习的思路,
可作为
: 当前策略即神经网络预测的值
这就是采用函数近似法的时间差分学习算法。该算法总结在算法8.1中。也可用Q-learning方式更新。
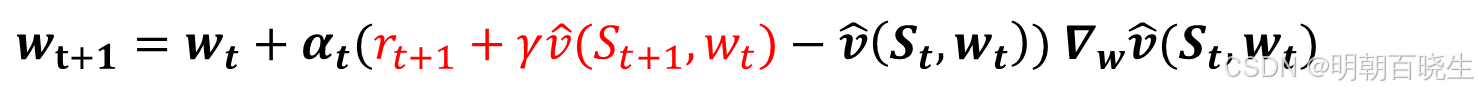
四 函数近似器的选择
要应用(8.13)中的时序差分(TD)算法,我们需要选择合适的。有两种方法可以实现这一点。第一种方法是使用人工神经网络作为非线性函数近似器。神经网络的输入是状态,输出是
,网络参数为 w。第二种方法是简单使用线性函数:


前面的TD 或者 SARSA,更新公式是一样的,少了一个梯度
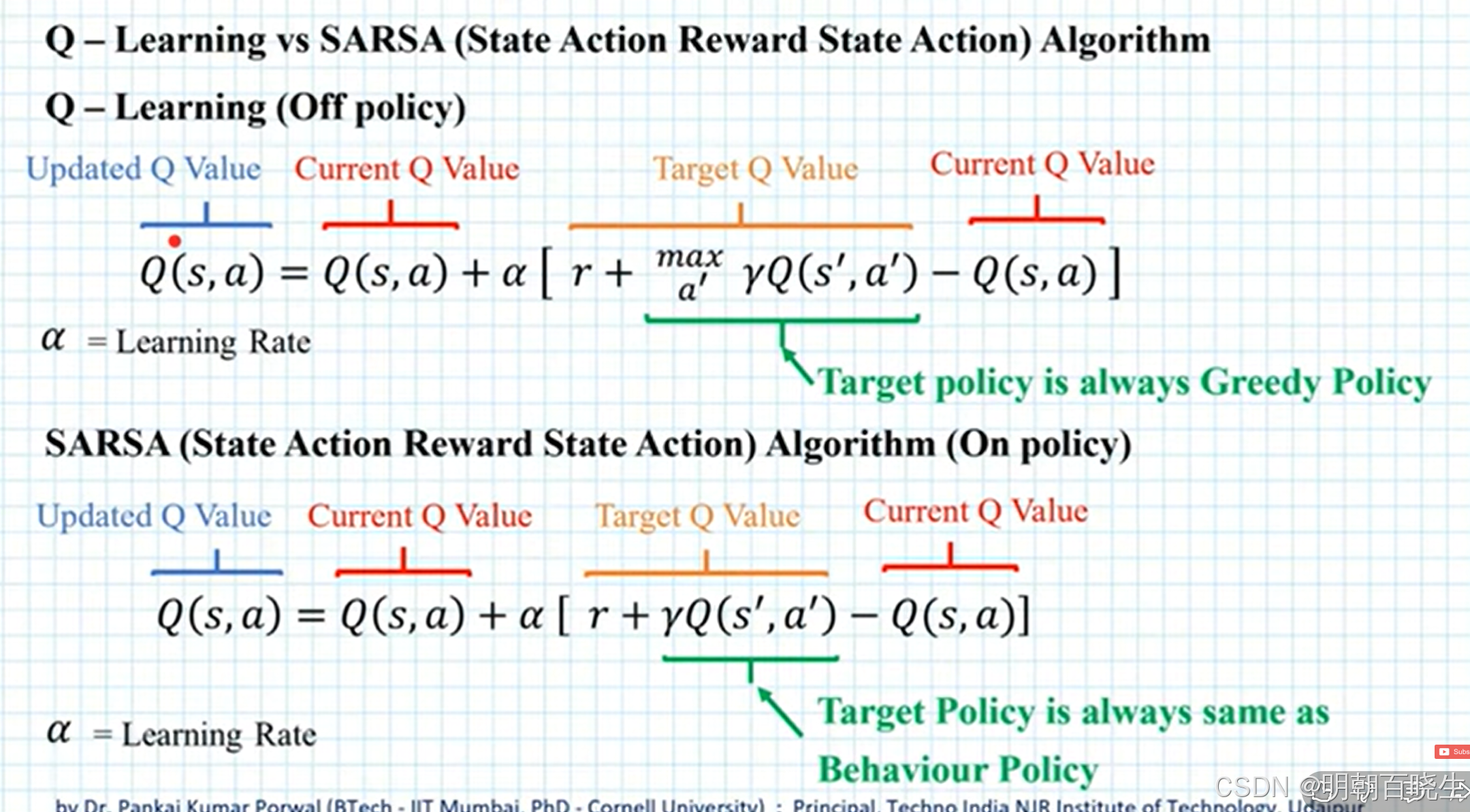
其中,ϕ(s)∈Rm 是状态 s 的特征向量。ϕ(s) 和 w 的长度均为 m,通常 m 远小于状态的数量。在线性情况下,梯度为:

将其代入(8.13)式可得:
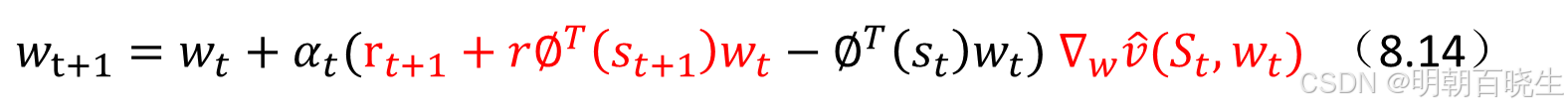
这就是线性函数近似的时序差分学习算法。我们将其简称为TD-线性算法。
从理论上讲,线性情况比非线性情况更容易理解。然而,其近似能力有限。对于复杂任务,选择合适的特征向量也并非易事。相比之下,人工神经网络作为黑箱通用非线性近似器,能够近似值函数,使用起来更为便捷。
尽管如此,研究线性情况仍然颇具意义。更好地理解线性情况有助于读者更好地掌握函数近似方法的思想。此外,对于本书所考虑的简单网格世界任务,线性情况已足够应对。更重要的是,从某种意义上说,线性情况仍然具有强大的能力,因为表格型方法可被视为一种特殊的线性情况
比如
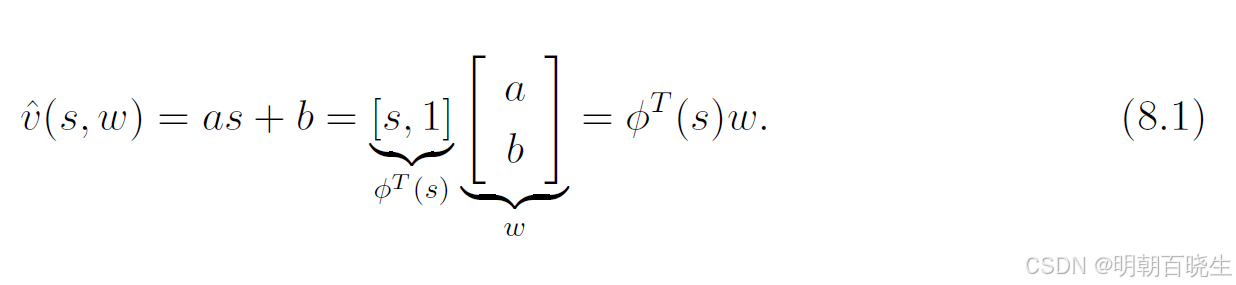
五 值函数近似例子

网格世界的示例如图 8.6 所示。给定策略在每个状态下,以 0.25 的均匀概率选择四个可能方向中的任意动作。我们的目标是估计在该随机策略下的状态价值函数,该网格世界共有 25 个状态。真实的状态价值如图 8.6(b) 所示,并在图 8.6(c) 中以三维曲面的形式可视化。
接下来,我们将展示如何使用少于 25 个参数来近似表示这 25 个状态价值。仿真实验设置如下:
使用给定策略生成 500 条采样轨迹,每条轨迹包含 500 个时间步,每条轨迹的初始状态-动作对从所有可能组合中均匀随机选择。此外,在每次仿真试验中,参数向量 w 进行随机初始化,其每个元素均从均值为 0、标准差为 1 的标准正态分布中独立抽取。我们设 rforbidden=rboundary=−1, rtarget=1,以及折扣因子 γ=0.9。
要实现基于线性函数近似的 TD 算法,首先需要为每个状态设计特征向量 ϕ(s)。特征向量的构造有多种方式,如下所述。
第一种类型的特征向量基于多项式基。
在网格世界示例中,一个状态 s 对应一个二维坐标位置。令 x 和 y 分别表示状态 s的列索引和行索引。为避免数值问题,我们将 x 和 y 归一化到 [−1,+1]区间内。在不引起歧义的情况下,归一化后的值仍用 x 和 y表示。那么,最简单的特征向量为:
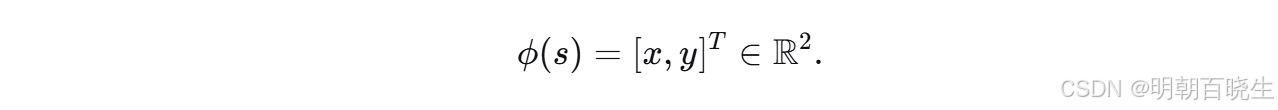
当权重向量 w 给定时,状态价值估计值
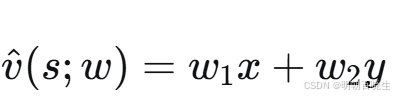
表示一个穿过原点的二维平面。由于真实状态价值曲面可能不经过原点,我们需要为该平面引入一个截距(偏置)项以提升近似能力。为此,考虑以下三维特征向量:
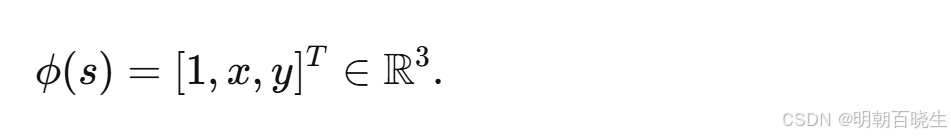
此时,近似状态价值为
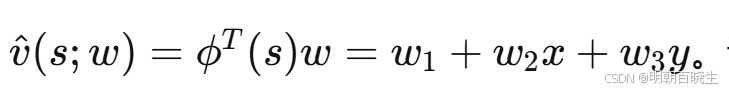
。该表达式对应一个不一定穿过原点的平面。值得注意的是ϕ(s) 也可以定义为 [x,y,1]T,元素顺序对算法没有影响。
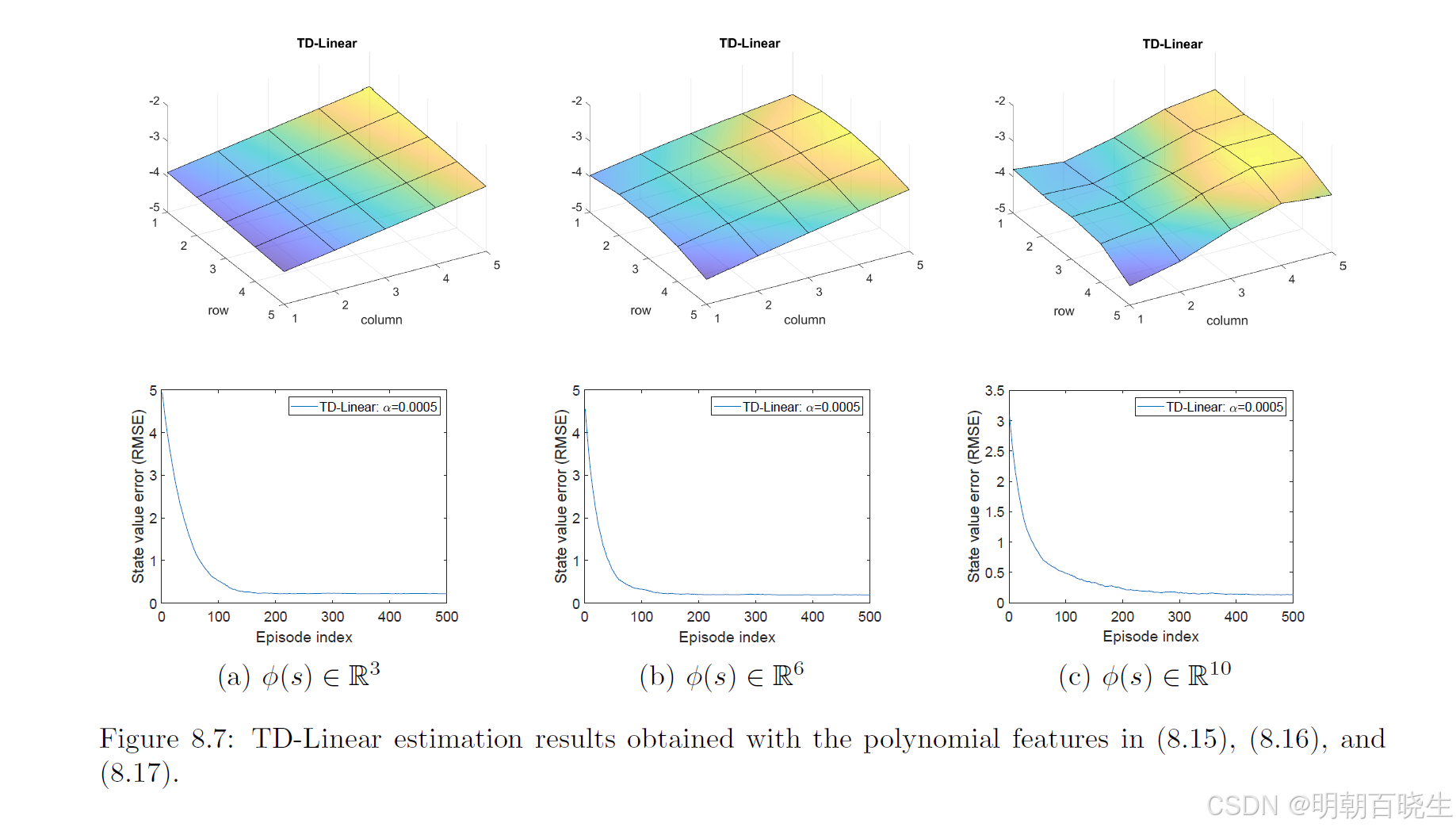
使用式 (8.15) 中特征向量的估计结果如图 8.7(a) 所示。可以看出,估计出的状态价值构成一个二维平面。尽管随着使用更多轨迹进行学习,估计误差会逐渐收敛,但由于二维平面的表示能力有限,最终误差无法降至零。
为了提升函数近似的表达能力,我们可以增加特征向量的维度。例如,考虑以下六维特征向量:
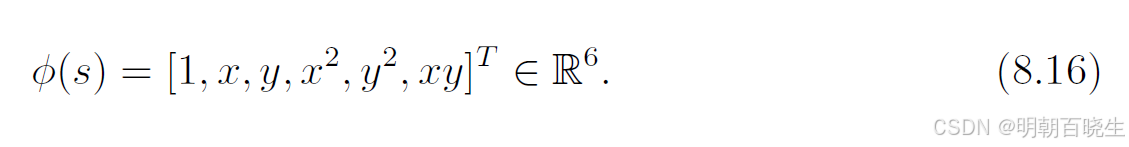
此时,
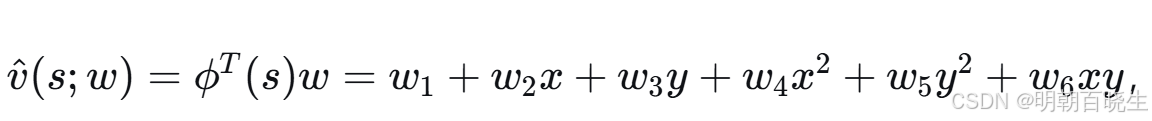
,这是一个二次曲面。我们还可以进一步增加维度:
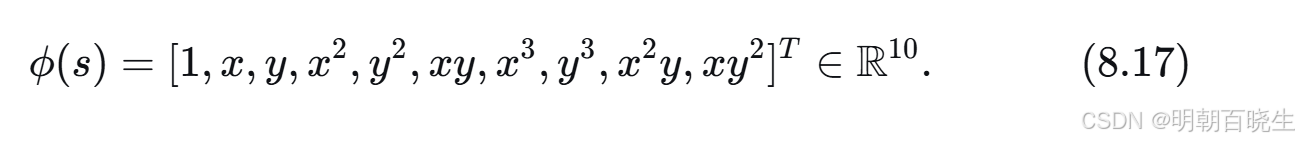
使用式 (8.16) 和式 (8.17) 的特征向量得到的估计结果分别如图 8.7(b) 和 (c) 所示。可以看出,特征向量维度越高,对状态价值的近似就越准确。然而,在上述所有情况下,由于线性函数近似器固有的表达能力限制,估计误差均无法收敛到零。
六 理论分析
至此,我们已完成对基于函数近似的时序差分(TD)学习方法的阐述。
价值函数近似的基本思想:
第一步: 确定优化的目标函数
第二步:梯度下降求解公式8.3
问题:的真实价值函数
未知
第三步: RM 算法求解(随机采样).从而导出了公式(8.13)中的TD算法。
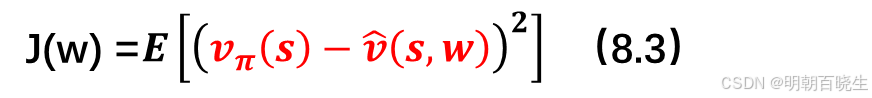
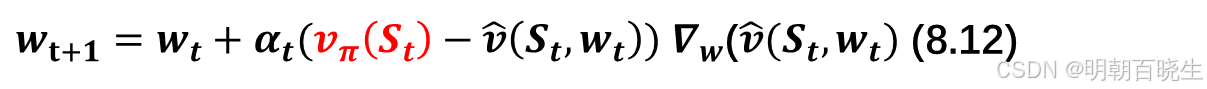
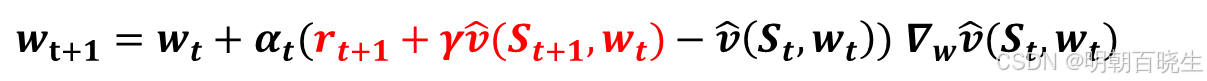
但它在数学上并不完全严谨。实际上算法优化的目标并不是8.3而是另外的公式
目标函数一:均方值误差
这是最直接的目标,旨在最小化近似值
与真实值
之间的差距。
局限在于,真实值 vπ(s)通常是未知的,因此该目标在实践中难以直接优化。
目标函数二:均方贝尔曼误差
由于真实值未知,我们转而利用贝尔曼方程作为自洽约束。贝尔曼误差衡量的是近似值在单步时序差分上的不一致性。
最小化 BE 试图让近似值函数满足贝尔曼方程。
问题:
然而,在函数逼近下,
跟
因为函数设计的问题可能永远无法相等,
导致不稳定
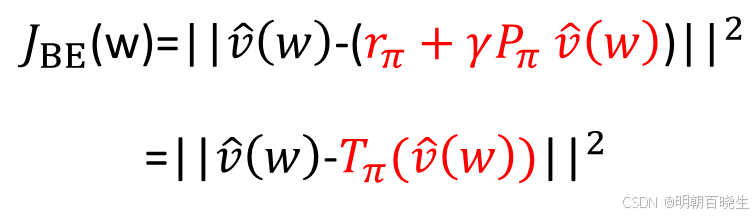
目标函数三:均方投影贝尔曼误差
为了解决 BE 的不稳定性,投影贝尔曼误差 被提出。其思想是:先计算贝尔曼算子作用后的值 然后将这个结果投影回我们函数逼近器所能表示的空间中,再计算误差。
M 是投影矩阵
关键优势:
最小化 PBE 是许多稳定算法(如线性情况下的 TD(0))的隐含优化目标,它确保了在函数逼近空间内的最优解,从而带来可靠的学习过程。
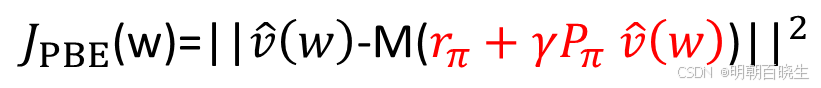
参考:
https://www.bilibili.com/video/BV1sd4y167NS?spm_id_from=333.788.videopod.episodes&p=44

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)