程序员福音!大模型编程开发技术大揭秘,从MiniMax-M1到DeepSeek-V3.2,这些AI工具让你告别加班,效率爆表!
本文系统梳理了2024年大模型在编程开发与软件工程领域的最新研究进展,包括MiniMax-M1、GLM-4.5、DeepSeek-V3.2等模型架构创新,SWE-agent、SWE-Gym等智能体训练方法,以及SWE-bench等评估基准。这些研究通过混合注意力机制、强化学习训练、合成数据构建等技术,显著提升了大模型在代码生成、bug修复、软件工程任务中的性能,为AI编程助手的发展提供了新范式。
一、Model / Workflow
1.MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
论文链接:https://arxiv.org/abs/2506.13585
MiniMax-M1是首个开源的混合注意力机制大规模推理模型,核心创新在于将Lightning Attention线性注意力机制与混合专家(MoE)架构深度融合,实现推理计算复杂度从二次向近线性的根本性突破。
模型架构层面,论文采用7:1的transnormer与标准Transformer块交替结构,在保证长程依赖建模能力的同时,使模型原生支持100万token输入上下文与8万token输出长度。相较于传统注意力机制,在10万token生成长度下计算量仅为DeepSeek-R1的25%,显著提升长思维链场景下的推理效率。
训练工作流方面,提出CISPO(Clipped IS-weight Policy Optimization)算法,通过裁剪重要性采样权重而非token更新,避免低概率反思性token在训练中丢失。该算法在Qwen2.5-32B上实现2倍训练加速,配合FP32精度的LM头优化、重复模式早期截断等工程策略,使完整RL训练在512张H800 GPU上仅需3周(约53万美元成本)。
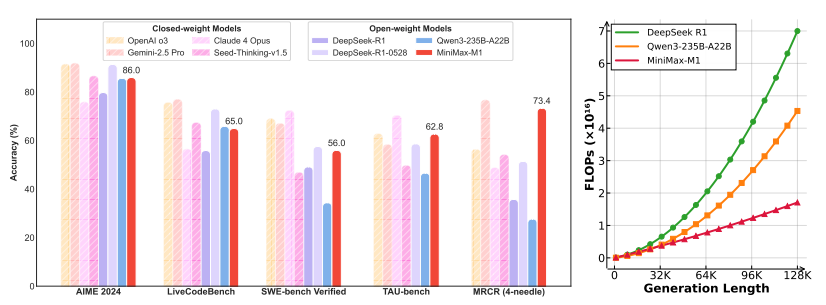
性能表现上,模型在SWE-bench软件工程、TAU-bench工具调用等真实场景任务中达到开源SOTA水平,验证了高效架构与训练范式对复杂Agent任务的可扩展性。
2.GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
论文链接:https://arxiv.org/abs/2508.06471
模型架构: GLM-4.5系列采用混合专家(MoE)架构,推出355B总参数/32B激活参数的主模型及106B总参数的GLM-4.5-Air紧凑版。通过"更深更窄"的设计哲学(89层MoE层,5120隐藏维度,96个注意力头),配合QK-Norm与多Token预测层,在保持计算效率的同时增强推理深度。核心创新在于混合推理模式:同一模型支持思考模式(长链式推理)与直接响应模式(即时输出),可根据任务复杂度自适应切换。
训练范式: 采用三阶段递进式训练——
- 预训练:在23T tokens上完成,分为通用文本训练与代码/数学/科学数据增强两阶段
- 中训练:引入仓库级代码关联学习、合成推理竞赛题及128K长上下文智能体轨迹
- 后训练:通过"专家模型迭代"实现能力解耦,先训练推理/智能体/通用三大领域专家,再经自蒸馏融合为统一模型。强化学习阶段采用难度课程学习、动态采样温度及多源反馈机制,针对性优化各领域性能。
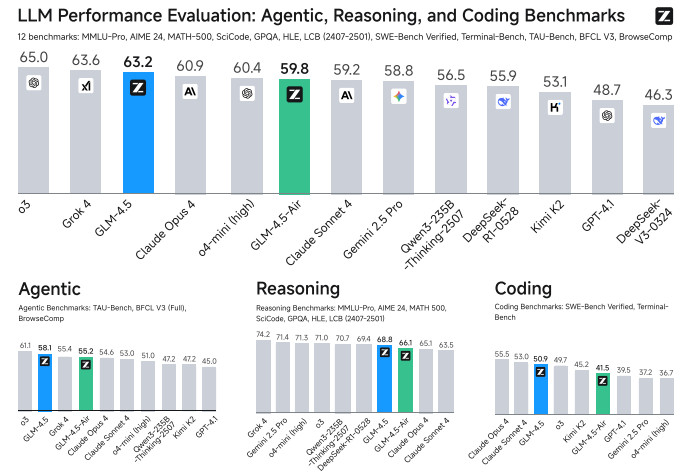
性能表现: 在12项ARC基准中综合排名第3,智能体任务排名第2。关键指标:TAU-Bench 70.1%、AIME 24 91.0%、SWE-bench Verified 64.2%,参数量仅为DeepSeek-R1一半、Kimi K2三分之一,展现卓越参数效率。
3.DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
论文链接:https://arxiv.org/abs/2512.02556
DeepSeek-V3.2 针对开源模型在复杂任务上与闭源模型差距持续拉大的问题,提出了一套系统性架构与训练框架创新。
技术核心包括:
- DeepSeek****Sparse **Attention (DSA)**:通过轻量索引器实时计算token相关度并执行top-k稀疏选择,将长上下文注意力复杂度从O(L²)降至O(Lk),在128K上下文下实现推理成本降低30-70%,且性能无衰减。
- 可扩展强化学习流程:后训练算力投入提升至预训练成本的10%以上,采用专家蒸馏与改进的GRPO算法,将推理、代理和人类偏好三类任务统一在单一RL阶段,避免灾难性遗忘。
- 大规模代理任务合成:构建自动生成管线产出1,827个可执行环境和85,000+复杂提示,覆盖搜索、代码、通用规划等场景,使模型在工具使用中内化推理能力。
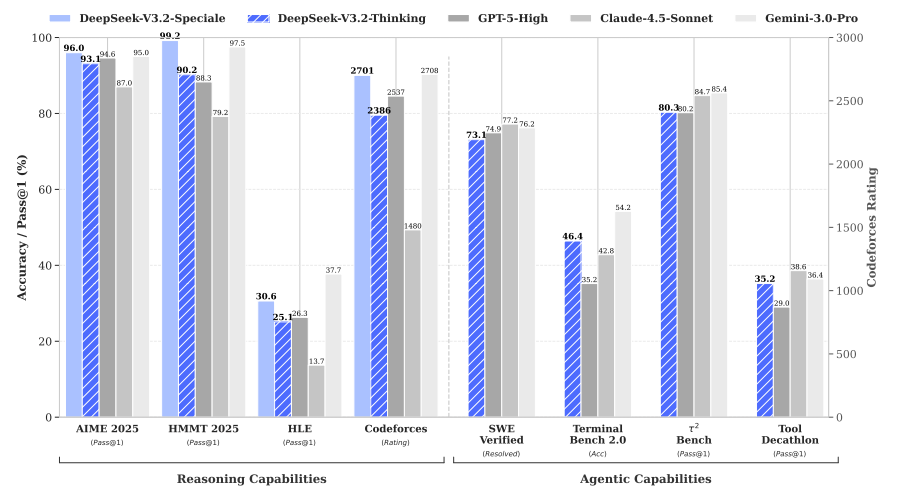
该工作使DeepSeek-V3.2在AIME、Codeforces等推理基准上持平GPT-5,在Terminal Bench、SWE-Verified等代理任务中显著缩小开源与闭源差距。其变体DeepSeek-V3.2-Speciale更在IMO、IOI等顶级竞赛中斩获金牌,验证了方案的有效性。
4.Nex-N1: Agentic Models Trained via a Unified Ecosystem for Large-Scale Environment Construction
论文链接:https://arxiv.org/abs/2512.04987
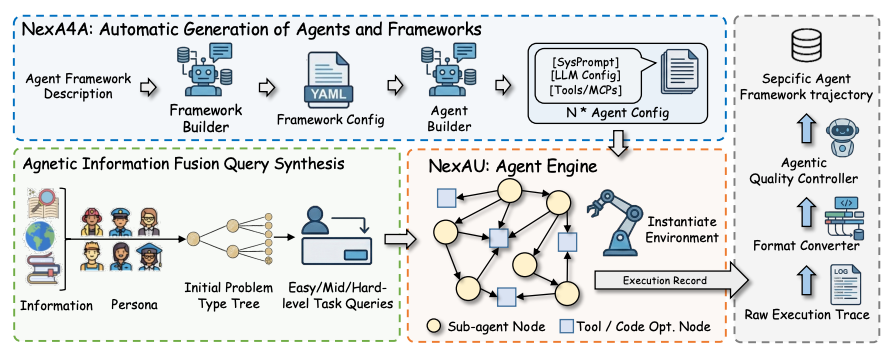
本文针对智能体训练中交互环境稀缺与现实世界 grounding 不足两大瓶颈,提出可扩展的统一生态体系(NexAU + NexA4A + NexGAP),将环境构造从手工工程转为自动化生成:
- NexAU:轻量化模块化运行时,通过声明式 YAML 配置支持递归式分层代理架构。采用统一 ReAct 循环抽象,将子代理、工具与 MCP 插件视为可互换功能单元,实现长程任务隔离执行与真实 API 状态回灌。
- NexA4A:生成式框架合成系统,基于自然语言描述自动产出完整代理拓扑结构(系统提示、子代理节点、工具绑定),可程序化生成 200+ 异构框架(1–34 节点深度),覆盖从单代理到多层级联的无限交互模式。
- NexGAP:高质量轨迹生产管道,集成 100+ 生产级 MCP 工具,采用信息融合查询合成与逆频率采样策略,结合 Supervisor 自修复机制,过滤幻觉与 reward hacking,生成千万级跨格式(7 种工具调用语义)真实执行轨迹。
基于该生态训练的 Nex-N1 系列模型在 SWE-bench、GAIA 2 等 6 大基准上全面超越同级别开源模型,性能对标 GPT-5 与 Claude-Sonnet-4.5,并在跨框架鲁棒性评测中保持稳定的任务通过率。项目已开源模型权重与部分训练数据。
5.Introducing KAT-Dev-32B, KAT-Coder: Advancing Code Intelligence through Scalable Agentic RL
论文链接:https://kwaipilot.github.io/KAT-Coder/
核心工作:快手团队发布了KAT系列两个模型——开源的KAT-Dev-32B(32B参数)与性能更强的KAT-Coder。在SWE-Bench Verified基准上,KAT-Dev-32B达到62.4%的问题解决率,位列开源模型第五;KAT-Coder则以73.4%的成绩创下当前最优水平。
三阶段训练范式:
- Mid-Training:注入工具调用、多轮交互、Commit/PR数据等"智能体基础能力",为后续训练奠基;
- **SFT &**RFT:覆盖功能实现、缺陷修复等8类真实任务与应用开发、数据科学等8大编程场景;创新性地引入RFT阶段,通过人工标注的"教师轨迹"引导模型探索,稳定RL训练;
- AgenticRLScaling:针对非线性轨迹历史学习、模型信号利用、高吞吐基础设施三大挑战,提出前缀缓存、熵基轨迹剪枝和SeamlessFlow架构,实现高效扩展。
涌现行为:RL缩放后观察到交互轮次平均减少32%的"效率偏好"与并行工具调用能力,归因于轨迹树结构隐含的优化目标。

二、sft / 合成数据
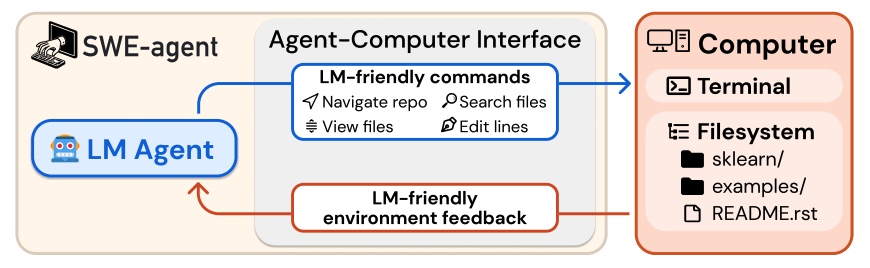
1.SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
论文链接:https://arxiv.org/pdf/2405.15793
该研究提出SWE-agent系统,通过设计专门的代理-计算机接口(ACI),使语言模型能够自主完成软件工程任务。在SWE-bench基准测试中,该系统以12.5%的通过率创下新高,较此前最佳方法提升3倍以上。
核心创新在于ACI设计范式而非模型微调。研究团队为LM定制了简洁高效的交互接口,包含四大组件:
- 搜索导航:
find_file、search_dir等命令,聚焦关键词定位,单次返回≤50条结果 - 文件查看器:100行窗口滑动浏览,附行号与上下文提示,避免信息过载
- 文件编辑器:
edit命令支持行范围替换,集成语法检查防护,错误编辑自动回滚 - 上下文管理:仅保留最近5轮交互,历史观测折叠显示,降低上下文窗口压力
实验表明,ACI设计遵循四项关键原则:命令简洁易懂、操作紧凑高效、反馈信息丰富且精简、防护机制阻断错误传播。值得注意的是,该系统无需修改模型权重,其产生的交互轨迹为后续SFT提供了高质量合成数据,在HumanEvalFix上达87.7%的通过率。研究验证了接口设计作为独立优化维度的重要性,为Code Agent的数据飞轮构建提供了可行路径。
2.Training Software Engineering Agents and Verifiers with SWE-Gym
论文链接:https://arxiv.org/pdf/2412.21139
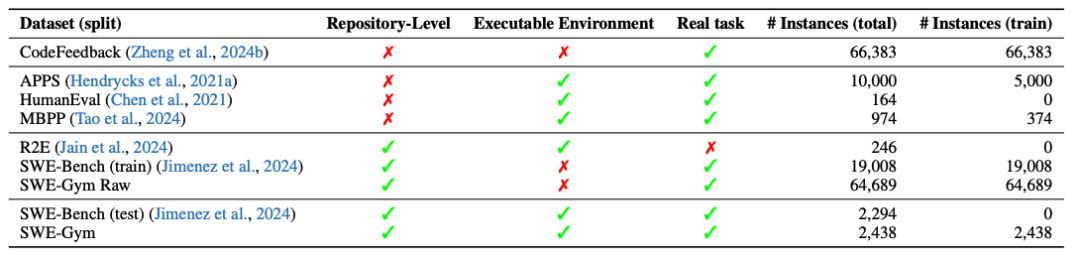
SWE-Gym构建了包含2,438个真实Python任务的可执行训练环境,每个任务配备独立运行时与单元测试,填补了软件工程领域缺乏训练环境的空白。该工作通过监督微调将Qwen2.5-Coder转化为专业代理:
- 合成数据构建:从GPT-4/Claude采样491条成功轨迹(平均19轮交互、1.9万token),采用拒绝采样微调(filtered behavior cloning)训练,32B模型在SWE-Bench Verified上从7.0%提升至20.6%(+13.6%)
- 训练效果:显著缓解开源模型"循环卡死"问题(降低4.6-18.6%),且性能随训练数据量呈持续上升态势
- 推理扩展:基于采样轨迹训练验证器,实现Best-of-16选择策略,性能进一步跃升至32.0%,树立开源模型新标杆
该工作首次验证了真实SWE环境下的SFT有效性,所有模型、数据及Docker镜像已完全公开。
3.SWE-Mirror: Scaling Issue-Resolving Datasets by Mirroring Issues Across Repositories
论文链接:https://arxiv.org/pdf/2509.08724
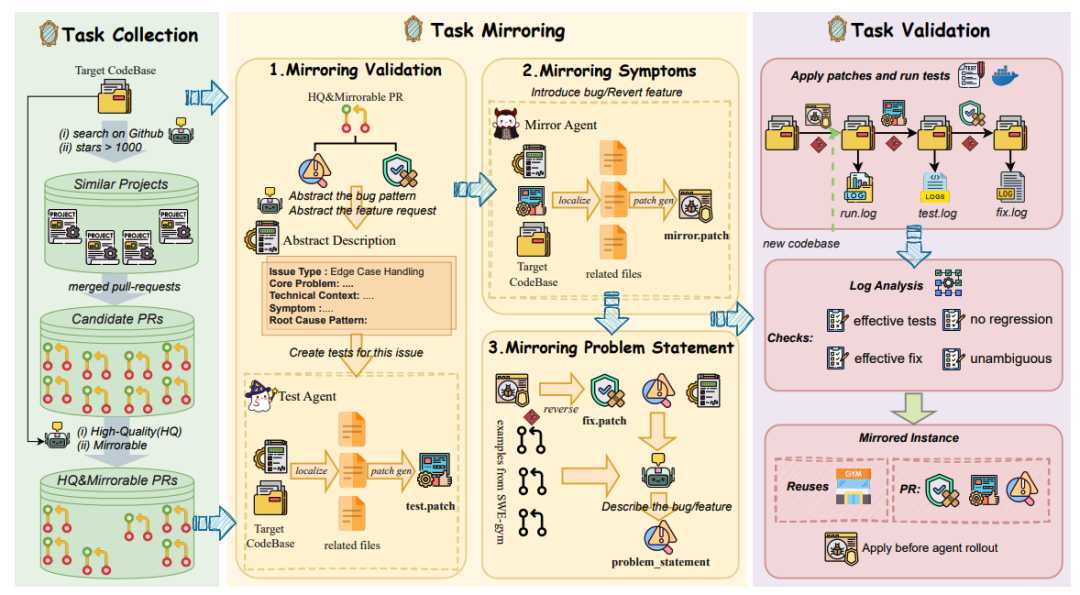
本文针对代码智能体训练数据稀缺的核心矛盾——真实GitHub issue无法规模化转化为可验证任务,提出跨仓库语义镜像新范式。传统方法受限于"一任务一Gym"的刚性约束,存储成本高且成功率低;现有合成数据则丧失真实软件演化历史。
核心方法:三阶段流水线打破任务与环境的强绑定。1) 采集阶段:从功能相似的高星仓库过滤可镜像PR;2) 镜像阶段:通过GPT-4系列模型三步转换——生成新测试用例(test.patch)、在目标仓库复现缺陷(mirror.patch)、合成自然语言描述;3) 验证阶段:执行严格的状态转移检查,确保测试有效、修复有效、无回退。
数据规模:仅用40个现成Gym(约100GB存储)镜像出60,671条跨语言可验证任务(Python/Rust/Go/JS),整体成功率46%,Python达68%。人工审计显示88%的任务忠实于原issue。
训练价值:基于12K高质量轨迹采用Error-Masking策略微调Qwen2.5-Coder,在SWE-Bench-Verified上7B/32B模型分别提升**21.8%和46.0%**,刷新同规模SOTA,并验证数据缩放律与跨语言泛化能力。该方法低成本解锁GitHub海量真实issue历史,为sft数据合成提供可扩展路径。
4.R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents
论文链接:https://arxiv.org/pdf/2504.07164
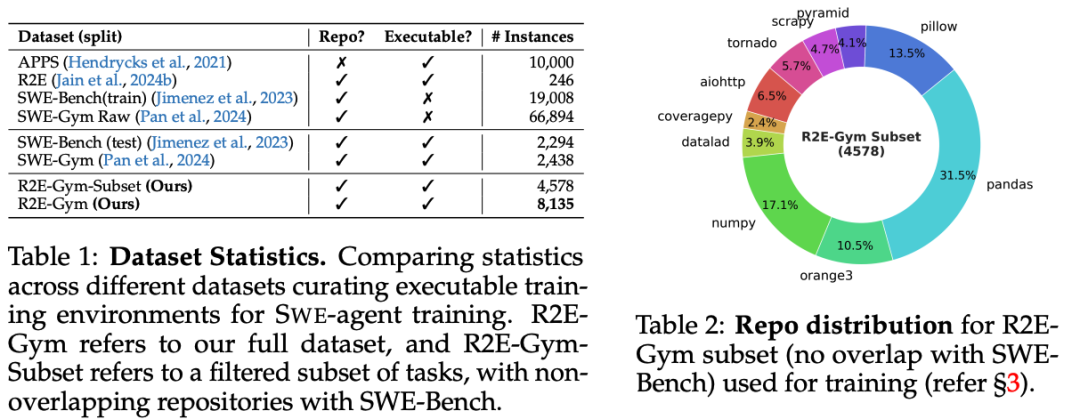
本文提出SWEGEN合成数据生成框架,通过从GitHub提交记录直接构建可执行训练环境,摆脱对人工编写issue和测试用例的依赖。该方法结合测试验证与反向翻译技术,生成8.1K+高质量任务实例,使训练数据规模提升2.5倍。
核心方法包括:
- 自动化环境构建:基于commit筛选、依赖解析和测试生成,创建完整的可执行gym环境,覆盖10个主流Python仓库
- 问题描述合成:利用失败测试用例作为上下文,通过反向翻译生成精准问题描述,实验显示其效果与真实issue相当(27.8% vs 28.0% PASS@1)
- 数据质量保障:仅保留测试状态从失败到成功转换的有效样本,并通过patch最小化过滤无关变更
基于Qwen-2.5-Coder-32B训练的模型在SWEBENCH-VERIFIED基准上达到34.4% PASS@1,相比依赖人工数据的SWE-Gym提升14个百分点。该工作证明,程序化生成的合成数据在保持质量的同时,具备更强的可扩展性,为开源SWE Agent训练提供了新的数据范式。
5.SWE-smith: Scaling Data for Software Engineering Agents
论文链接:https://arxiv.org/pdf/2504.21798
现有软件工程训练数据面临规模小(仅千级别实例)、来源受限(≤11个仓库)、人工成本高企、执行环境占用TB级存储等瓶颈。为此,该工作提出SWE-smith,一种面向Python代码库的可扩展任务合成工具。
该工具通过执行环境优先的策略,为每个仓库构建统一的Docker镜像,并采用四种策略自动生成任务实例:
- LM生成:通过语言模型修改或重写函数
- AST变换:对抽象语法树进行过程化操作
- PR镜像:撤销真实Pull Request的修改
- 多Bug组合:聚合同一文件或模块的缺陷
最终构建出50k实例的数据集,覆盖128个仓库,存储成本仅295GB(较传统方案降低500倍)。基于5k条专家轨迹微调Qwen 2.5 Coder 32B后,SWE-agent-LM-32B在SWE-bench Verified基准上实现40.2% Pass@1,达到开源模型最优水平。项目已全栈开源,显著降低了软件工程智能体研究门槛。

三、RL
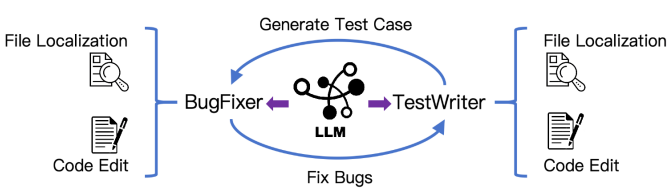
1.Kimi-Dev: Agentless Training as Skill Prior for SWE-Agents
论文链接:https://arxiv.org/abs/2509.23045
本文提出"分阶段训练"范式,将Agentless工作流转化为SWE-Agent的强化学习先验,系统性解决多轮交互智能体训练中的稀疏奖励与数据稀缺难题。
RL核心设计:
- 单阶段强化:仅对代码编辑环节施加可执行结果奖励(0/1),规避长程信用分配不稳定问题
- 双角色协同:BugFixer与TestWriter通过40×40测试时自博弈优化,在不增加训练成本下将SWE-bench Verified性能提升至60.4%,刷新工作流SOTA
- 自适应课程:基于pass@16动态筛选1.2k有效训练样本,每100步引入500个新难题,配合正例回放加速收敛
关键价值: 该训练策略使72B模型经5k公开轨迹轻量SFT后,SWE-Agent达到48.6% pass@1,与Claude 3.5 Sonnet持平,验证"先验-适配"路径可将数据需求降低25倍以上,为开源社区提供可复现的代理训练新基准。
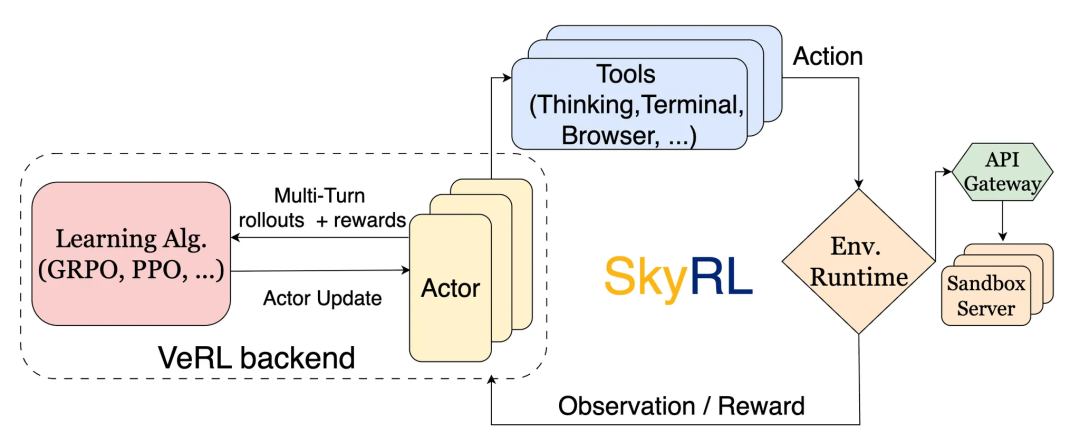
2.SkyRL-v0: Train Real-World Long-Horizon Agents via Reinforcement Learning
论文链接:https://novasky-ai.notion.site/skyrl-v0
该工作针对现有RL框架局限于短期无状态交互的瓶颈,构建了基于VeRL和OpenHands的多轮工具使用训练流水线,专为SWE-Bench等长程、动态环境任务优化。
核心创新在于系统级效率提升:一是解耦式远程沙箱服务器,将环境执行与训练分离,支持独立扩展,避免资源争用;二是异步并行rollout配合三阶段生产者-消费者流水线,重叠计算与环境交互,实现4-5倍加速。
训练采用极简的结果导向二元奖励,仅约300条筛选样本即可有效引导策略。实验显示,7B/8B/14B模型在SWE-Bench-Verified上分别达14.6%/9.4%/21.6%,验证了系统优化对长程智能体RL训练的关键作用。
3.DeepSWE: Training a Fully Open-sourced, State-of-the-Art Coding Agent by Scaling RL
论文链接:https://www.together.ai/blog/deepswe
DeepSWE-Preview是首个仅通过强化学习(RL)从零训练的32B开源代码智能体,在SWE-Bench-Verified上达到42.2% Pass@1,结合测试时扩展(TTS)后提升至59%,超越所有开源模型。该工作由Agentica与Together AI合作完成,基于Qwen3-32B基座,在4,500个真实软件工程任务上训练6天(64张H100),验证了纯RL范式在长程多步任务中的可扩展性。
核心创新点:
- GRPO++算法:融合Clip High、No KL Loss、Leave One Out等改进,提升训练稳定性与性能
- Compact Filtering:屏蔽超长/超时/超步轨迹,防止奖励崩溃并促进跨步推理
- 混合TTS:结合执行型与免执行验证器,充分利用16次轨迹采样实现最优选择
- Kubernetes扩展:改造R2E-Gym环境,支持并行化容器调度,突破传统Docker API瓶颈
涌现能力:纯RL训练自发产生两种行为模式——1)自动思考边界情况并运行回归测试;2)根据步骤复杂度动态分配思考token(简单步骤100-200 token,复杂步骤可达2K token)。
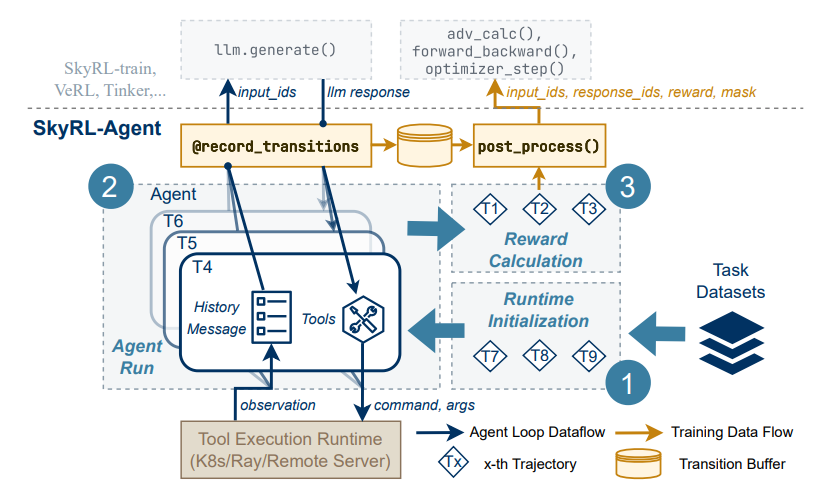
4.SkyRL-Agent: Efficient RL Training for Multi-turn LLM Agent
论文链接:https://arxiv.org/abs/2511.16108
本文提出SkyRL-Agent,一个面向多轮次、长周期LLM智能体的高效强化学习训练框架。核心创新在于异构调度系统与工具增强训练的协同设计:
- 异步管道调度器:将任务分解为初始化、执行、评估三阶段,通过细粒度流水线调度CPU/GPU操作,相比朴素异步批处理实现1.55倍速度提升,GPU利用率稳定在90%以上
- AST搜索工具:引入基于抽象语法树的代码检索工具,解决智能体在代码库导航中的稀疏奖励问题,使训练收敛提速3倍以上
基于Qwen3-32B训练的SA-SWE-32B模型在SWE-Bench Verified上达到39.4% Pass@1,性能对标同规模SOTA模型,训练成本却降低超2倍。值得注意的是,该模型仅通过800步RL训练即收敛,且展现出跨任务泛化能力,在Terminal-Bench、WebArena等基准上均优于基座模型。框架支持VeRL、SkyRL-train、Tinker等多种后端,为智能体RL研究提供了模块化、可扩展的基础设施。
5.Training Long-Context, Multi-Turn Software Engineering Agents with Reinforcement Learning
论文链接:https://arxiv.org/abs/2508.03501
针对软件工程场景的长程多轮交互特性,该研究提出了一套完整的两阶段强化学习训练范式:首先通过拒绝式微调(RFT)筛选成功轨迹,解决基模型的指令遵循与工具调用格式问题,将Qwen2.5-72B-Instruct在SWE-bench Verified上的Pass@1从11%提升至20%;随后采用同步RL流水线,基于DAPO算法在大规模POMDP框架下进行迭代优化,通过组内归一化优势估计和策略裁剪应对稀疏奖励与信用分配挑战。
关键创新在于将RL应用于真实多轮交互环境,而非单轮代码生成。最终模型实现39%的Pass@1,性能比肩DeepSeek-V3-0324等更大规模模型,实验验证了该方法在131k上下文、80轮交互下的稳定性,为开源模型训练高能力软件工程Agent提供了可复现的路径。
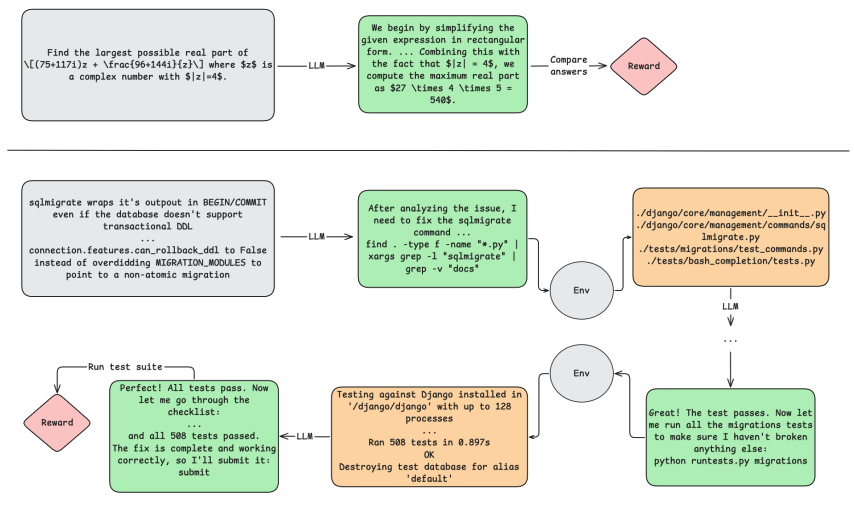
6.InfCode: Adversarial Iterative Refinement of Tests and Patches for Reliable Software Issue Resolution
论文链接:https://arxiv.org/abs/2511.16004
InfCode提出对抗式多智能体框架,通过测试补丁与代码补丁生成器的迭代互搏解决仓库级缺陷修复中验证信号弱、补丁易过拟合的问题。Test Patch Generator持续构造更强测试用例以暴露缺陷,Code Patch Generator则针对性改进代码,形成动态强化闭环;Selector智能体最终在容器化环境中评估多候选方案,筛选最可靠补丁。
该方法在SWE-bench Verified上以79.4%准确率刷新SOTA,在SWE-bench Lite上达40.33%,领先基线11例。消融实验表明对抗迭代与选择器分别贡献4.0和8.0个百分点提升。
核心贡献在于将对抗训练思想引入代码修复领域,通过可复现的执行环境与多维度评估机制,显著提升了LLM生成补丁的真实可靠性与泛化能力,为自动化软件维护建立了新的质量保障范式。
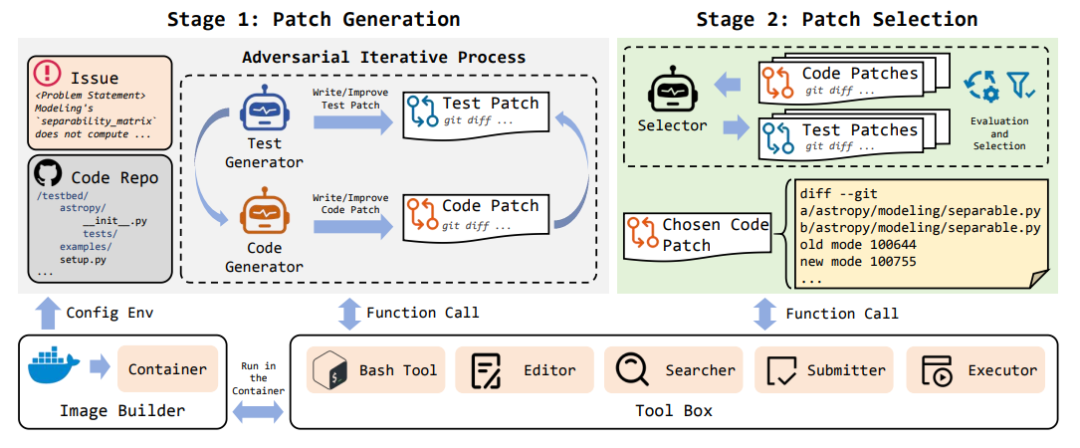
四、Benchmark
1.SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
论文链接:https://arxiv.org/pdf/2310.06770
该工作提出了首个基于真实GitHub issues的代码Agent评估框架,系统性揭示了当前语言模型在复杂软件工程任务中的能力边界。
核心贡献:
- 真实任务集:从12个高星Python仓库提取2,294个真实问题,每个任务需理解完整代码库(平均43.8万行)、跨文件定位bug并生成通过单元测试的补丁,远超HumanEval等简化基准
- 严峻性能差距:最优模型Claude 2仅解决1.96%的任务,GPT-4达1.31%,展示出现有LLM在代码库级推理中的显著局限
- 开源生态配套:发布含19,000训练样本的SWE-bench train及微调模型SWE-Llama 7B/13B,支持长上下文(>100K tokens)处理
基准特性: 问题描述长(平均195词)、需多文件协同编辑(平均1.7文件/3.0函数)、依赖执行验证而非静态匹配,为代码Agent研究建立了可扩展、可持续的真实场景评估标准。
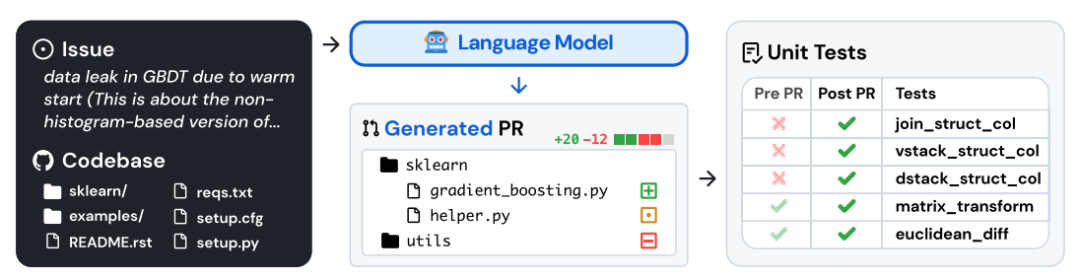
2.SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of LLMs
论文链接:https://arxiv.org/pdf/2505.20411
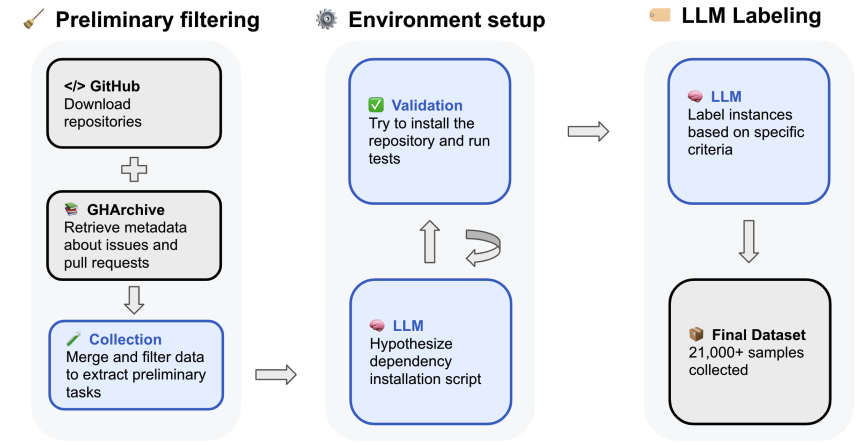
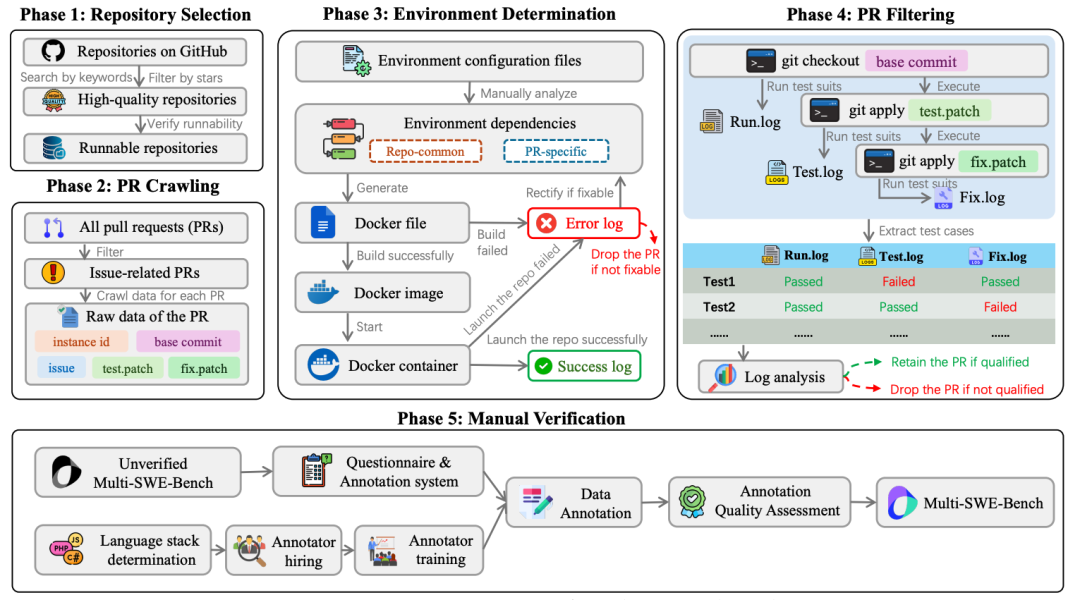
3.Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
论文链接:https://arxiv.org/pdf/2504.02605
本文提出一个可扩展的自动化管道,从GitHub持续提取真实交互式软件工程任务,构建包含21,336个Python任务的公共数据集,配套提供持续更新的去污染评估基准。
核心贡献包括:
- 四阶段自动化流水线:覆盖任务收集、环境配置自动化、执行验证与质量评估,31%仓库成功生成可执行环境,较手动方法显著扩大规模与多样性
- 多维度质量标注:通过微调Qwen模型预测任务清晰度、复杂度与测试正确性,为强化学习训练提供可筛选的元数据
- 去污染评估框架:提供294任务的公共排行榜,采用统一ReAct脚手架与标准化协议,支持跨模型公平对比。实验揭示部分模型在SWE-bench Verified上的性能存在数据泄露 inflated 现象
该工作通过自动化实现任务规模与新鲜度的突破,为软件工程智能体的训练与可靠评估建立基础设施。
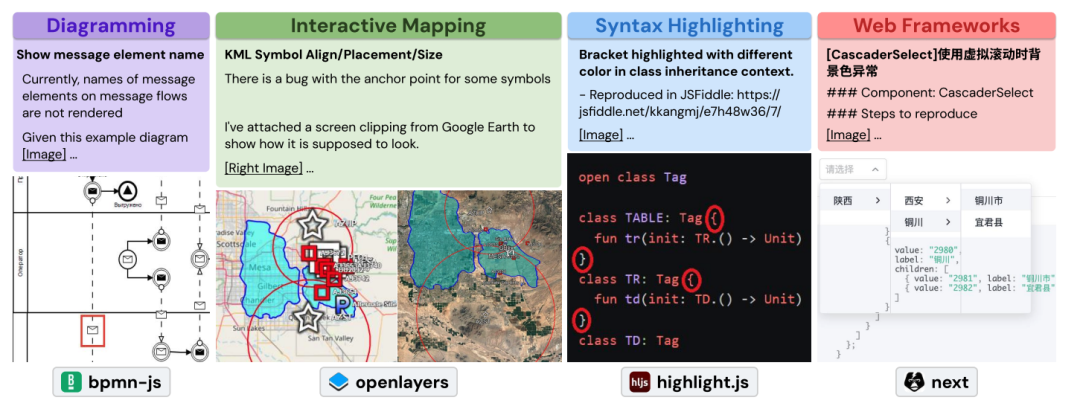
4.SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?
论文链接:https://arxiv.org/pdf/2410.03859
本文提出了SWE-bench Multimodal(SWE-bench M),首个专注于视觉软件工程任务的多模态基准测试。针对现有SWE-bench仅覆盖Python文本任务、缺乏视觉元素评估的局限,该工作系统探究了AI系统在前端开发等视觉密集型领域的泛化能力。
SWE-bench M包含617个真实GitHub任务实例,源自17个JavaScript库,涵盖Web界面设计、数据可视化、交互式地图等场景。每个实例均在问题描述或测试中包含图像/视频,其中83.5%的任务必须依赖视觉信息才能解决。数据集引入视觉测试、多语言混合编程(JavaScript/TypeScript/HTML/CSS)等新挑战。
评估显示,现有系统在SWE-bench M上表现显著下降:顶级方案解决率仅12%,远低于在Python任务上的43%。研究表明,过度依赖Python专用工具链的架构严重制约跨语言泛化能力。值得注意的是,SWE-agent凭借语言无关设计取得最佳性能,验证了通用交互式框架的有效性。该基准揭示了视觉理解与多语言适配的核心瓶颈,为推动更鲁棒的软件工程Agent发展提供了重要评测平台。
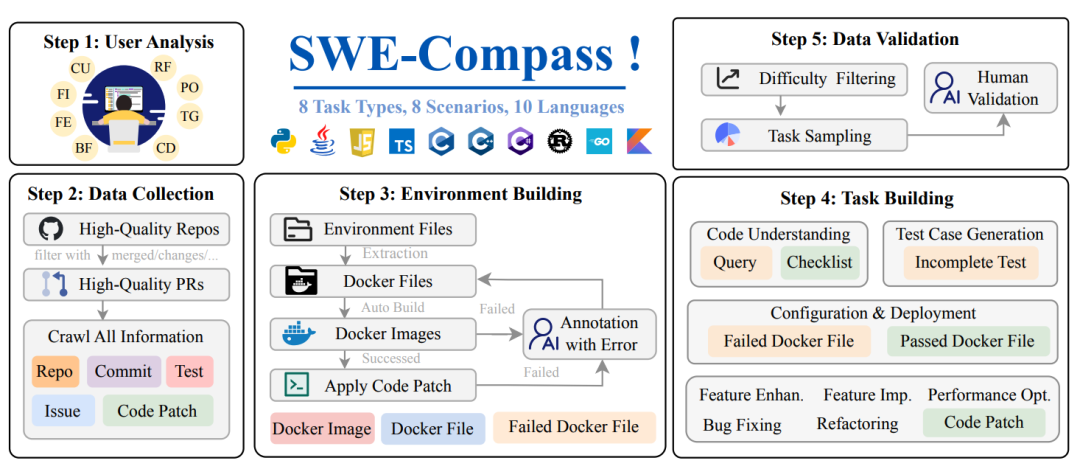
5.SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
论文链接:https://arxiv.org/pdf/2511.05459
现有软件工程基准测试存在任务覆盖窄、语言偏向性强、与真实开发流程脱节等问题。为此,本文提出SWE-Compass,整合2,000个来自GitHub真实PR的高质量实例,构建首个覆盖8类任务(功能实现、重构、性能优化、测试生成等)、8个编程场景(应用开发、基础设施、机器学习、安全工程等)及10种语言的统一评估框架。
核心设计遵循四项原则:真实世界对齐、全面均衡覆盖、系统化分类体系与可执行保真度。每个实例均配备Docker化可复现环境及验证测试,支持在SWE-Agent与Claude Code框架下公平评估。
实验揭示了三层能力层级:
- 头部模型(Claude-Sonnet-4)达32.9%平均通过率,但各任务差异显著
- 认知类任务(Code Understanding)表现最优,部署配置因模型而异,功能实现与Bug修复仍具挑战
- 失败模式分析表明,需求误解(>30%)与方案不完整(>29%)是主要瓶颈,而非技术知识欠缺
该基准为诊断模型在真实软件工程生命周期中的细粒度能力差距提供了可复现的评估基础。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2025 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献438条内容
已为社区贡献438条内容

所有评论(0)