告别 A100!教你用免费 Colab + Unsloth 跑通大模型蒸馏全流程
使用免费的Google Colab T4 GPU上,利用 Unsloth 加速库,让一个小巧轻便的模型(如 Qwen 2.5 1.5B)学会顶尖大模型(如 DeepSeek-V3)的知识
大模型的微调和蒸馏听起来总像是“富人的游戏”。一提到“模型蒸馏”,大家脑海里浮现的往往是几十张 A100 显卡并行运转的画面。
但今天,我要打破这个刻板印象。
作为一名普通开发者,完全可以在 Google Colab 的免费 T4 GPU(仅 15GB 显存) 上,利用 Unsloth 加速库,让一个小巧轻便的模型(如 Qwen 2.5 1.5B)学会顶尖大模型(如 DeepSeek-V3)的知识。我们使用到的硬件仅如下配置

在这篇文章中,我将手把手带你跑通这一全流程,并分享我在实战中踩过的坑和解决方案。
在显存受限的环境下(Colab T4),我们无法使用传统的 Logits 蒸馏(因为低配置下没法同时把 72B 的老师模型和 1.5B 的学生模型塞进显存)。所以,我们采用工业界最流行的基于数据的 SFT 蒸馏:
Teacher (老师):使用 DeepSeek 或 GPT-4 生成高质量的合成数据(QA对或思维链)。这相当于老师编写了一本“完美的教科书”。
Student (学生):利用这些数据,对小模型进行监督微调(SFT)。这相当于学生把教科书背下来,从而学会老师的逻辑。
我们的目标:在 Colab 上,用 Unsloth 对 Qwen-1.5B 进行 SFT 训练。
为什么是 Unsloth?
Unsloth 是目前的“微调神器”:
速度快:训练速度比原生快 2-5 倍。
省显存:通过手动重写 GPU Kernel,显存占用减少 60% 以上。
免费友好:它做了单卡环境优化的。
第一步:环境安装
# 1. 安装 Unsloth (指定 colab-new 分支以获得最新修复)
!pip install
"unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
# 2. 安装 trl 并跳过依赖检查,防止版本冲突
!pip install --no-deps "trl<0.9.0"
# 3. 强制更新必要的库
!pip install --upgrade peft accelerate bitsandbytes
第二步:加载学生模型
我们选用 Qwen/Qwen2.5-1.5B-Instruct。这是一个只有 15 亿参数的小钢炮,非常适合作为端侧模型。关键点在于开启 load_in_4bit,这能将显存占用压到极致。
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
load_in_4bit = True # 核心:开启4bit量化
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Qwen2.5-1.5B-Instruct",
max_seq_length = max_seq_length,
dtype = None, # 自动检测精度
load_in_4bit = load_in_4bit,
)
# 添加 LoRA 适配器 (Parameter-Efficient Fine-Tuning)
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
)
运行后会得到类似输出
第三步:准备蒸馏数据
这里我们使用清洗过的 Alpaca 数据集作为演示。它的格式是标准的 instruction (问题) 和 output (回答)。
注意:如果你使用其他数据集,一定要看清列名。如果是 ShareGPT 格式(包含 conversations),代码需要调整,否则会报 KeyError。
from datasets import load_dataset
# 加载数据集
dataset = load_dataset("yahma/alpaca-cleaned", split = "train[:1%]") # 仅取1%做演示
# 定义格式化函数 (适配 Qwen 的 ChatML 格式)
alpaca_prompt = """
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{}
{}<|im_end|>
<|im_start|>assistant
{}<|im_end|>
"""
EOS_TOKEN = tokenizer.eos_token
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input_text, output in zip(instructions, inputs, outputs):
# 处理可选的 input 字段
user_content = f"{instruction}\n\n{input_text}" if input_text else instruction
text = alpaca_prompt.format(user_content, "", output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
dataset = dataset.map(formatting_prompts_func, batched = True,)
# 打印一条数据检查 (Debug)
print(f"数据列名: {dataset.column_names}")
print(f"样例数据:\n{dataset[0]['text']}")
加载后打印检查效果:
第四步:开始训练
一切准备就绪,开始训练。
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4, # 模拟更大的 batch size
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit", # 8bit 优化器进一步省显存
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
trainer_stats = trainer.train()
在 T4 上,显存完全够用,非常稳定。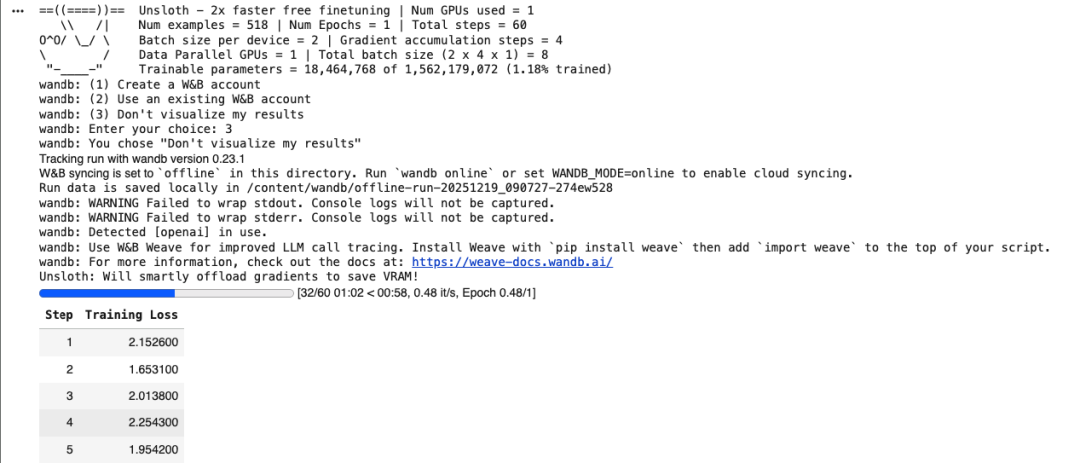
第五步:推理测试
训练完后,最激动的时刻来了。
FastLanguageModel.for_inference(model) # 开启推理模式
# 1. 专门的推理 Prompt (注意结尾没有 EOS,也没有 Assistant 的回答)
inference_prompt = """
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{}
{}<|im_end|>
<|im_start|>assistant
"""
# 2. 准备输入
inputs = tokenizer(
[
inference_prompt.format(
"请解释一下什么是量子纠缠?", # 用户问题
"",
)
], return_tensors = "pt").to("cuda")
# 3. 生成回答 (关键:调大 max_new_tokens)
outputs = model.generate(**inputs, max_new_tokens = 512, use_cache = True)
# 4. 打印结果
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
得到输出结果
总结:避坑 Checklist
如果你在运行过程中遇到了问题,请对照这份清单:
报错 KeyError: ‘instruction’:
原因:你用的数据集不是 Alpaca 格式,可能是 ShareGPT 格式。
解法:打印 dataset[0] 看看结构,如果包含 conversations,需要修改数据处理逻辑。
生成的回答只有半句话:
原因:max_new_tokens 默认值太小
解法:设置max_new_tokens为更大的值。
通过这套方案,我们实现了0成本、低显存、高效率的大模型蒸馏。
如果你手头有一些特定的行业数据(比如法律文档、医疗问答),不妨试试用这个方法,训练一个属于你自己的垂直领域小模型!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)