Tair的设计哲学:大规模分布式缓存的架构解构与工程启示
淘宝交易洪流催生了分布式存储引擎Tair,其核心设计包含:1)桶机制实现逻辑与物理解耦,通过二级映射支持平滑扩缩容和故障恢复;2)多存储引擎抽象,统一接口支持内存/SSD/磁盘等介质,实现成本优化;3)全链路多线程模型突破单线程瓶颈,性能达Redis 3倍;4)扩展数据结构封装业务语义,如原子性分布式锁。Tair启示现代架构应通过中间层解耦变化、深度定制业务场景、封装复杂性,推动存储系统从被动工具
当单机Redis无法支撑淘宝的交易洪流,一个从业务场景中生长出来的分布式存储引擎Tair,揭示了现代互联网架构在数据层演进的深层逻辑。
引言:场景驱动的架构诞生
在分布式系统的技术选型中,我们常面临一个经典问题:是选择经过社区验证的开源方案,还是针对自身业务进行深度定制?阿里云Tair的演进路径给出了一个清晰的答案:当业务规模与复杂性达到临界点时,源于场景的定制化架构往往能更精准地解决本质问题。
Tair并非对Redis的简单替代或克隆,而是阿里巴巴为应对电商场景下极致高并发、数据可靠性与复杂业务逻辑的挑战,从零构建的一套企业级分布式存储引擎。它回答了在超大规模下,如何平衡性能、一致性、成本与可运维性这一系列架构师的终极考题。
核心设计一:桶机制——逻辑与物理的优雅解耦
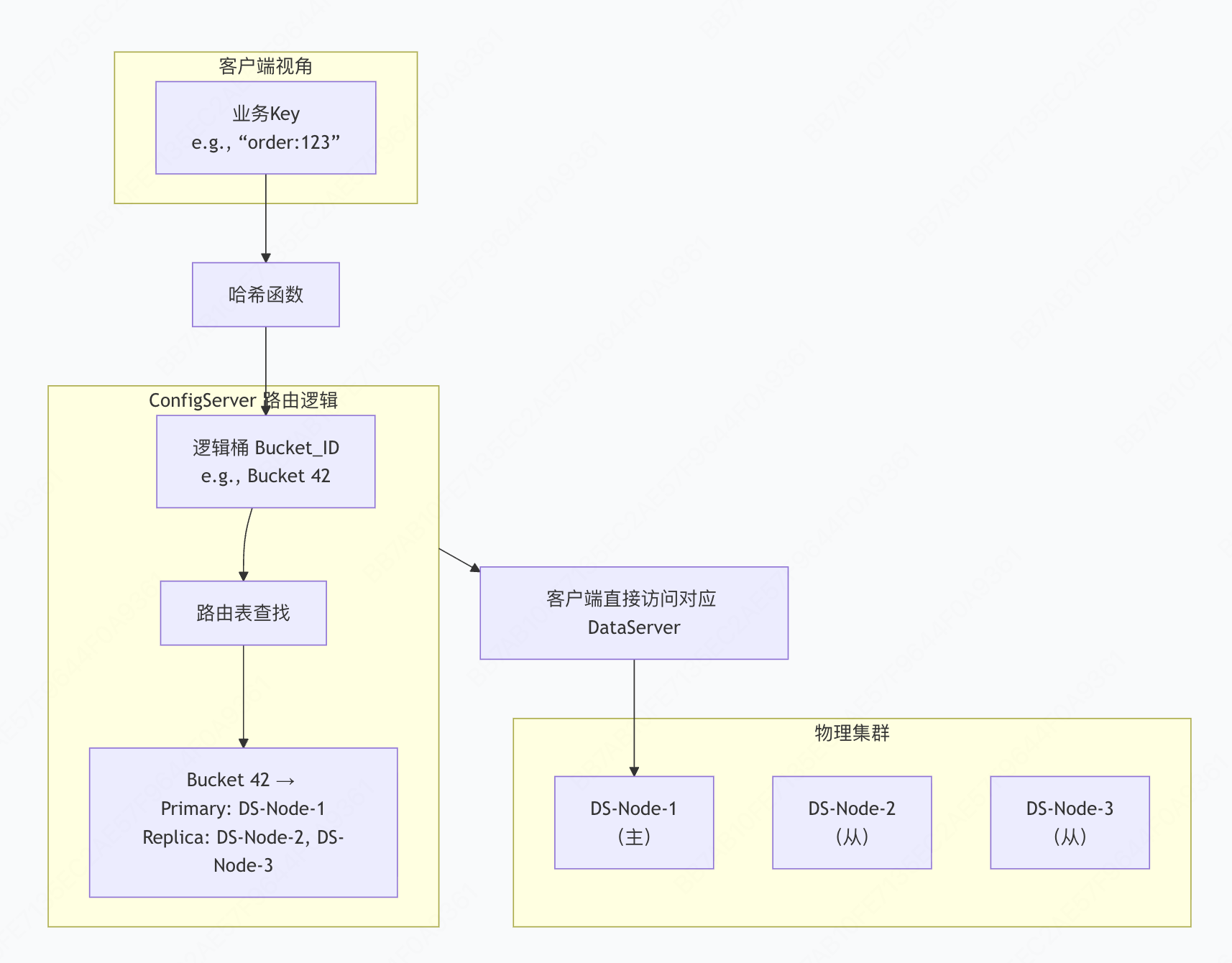
分布式系统的首要挑战是如何将数据均匀、高效且可管理地分布到大量节点上。Tair的答案是其核心的“桶”(Bucket)机制。
架构的精髓:两级映射
与许多直接将Key哈希映射到物理节点的系统不同,Tair引入了**“Key → 逻辑桶 → 物理DataServer”** 的二级映射架构。
- 第一层:确定性分片。通过一致性哈希算法,每个Key被永久映射到一个固定的逻辑桶(如Bucket 1023)。桶的数量在集群生命周期内是固定的(例如4096个),这保证了数据分布的逻辑稳定性。
- 第二层:动态路由。ConfigServer维护并下发一个轻量的路由表,定义每个逻辑桶当前由哪个DataServer(主)和哪些DataServer(从)负责。此映射可根据节点状态动态调整。
flowchart TD
subgraph Client[客户端视角]
K[业务Key<br>e.g., “order:123”]
end
K --> Hash[哈希函数]
Hash --> B[逻辑桶 Bucket_ID<br>e.g., Bucket 42]
subgraph Config[ConfigServer 路由逻辑]
B --> RT[路由表查找]
RT --> Mapping["Bucket 42 → <br>Primary: DS-Node-1<br>Replica: DS-Node-2, DS-Node-3"]
end
Config --> Access[客户端直接访问对应 DataServer]
subgraph Physical[物理集群]
DS1[DS-Node-1<br>(主)]
DS2[DS-Node-2<br>(从)]
DS3[DS-Node-3<br>(从)]
end
Access --> DS1
这种设计的工程优势是颠覆性的:
- 平滑的扩缩容:增加节点时,仅需由ConfigServer将一部分桶(如每个节点移出5%的桶)迁移至新节点。迁移过程是渐进和并行的,服务不间断,客户端无感知,与Redis Cluster的哈希槽迁移相比,控制粒度更细,影响面更小。
- 细粒度的故障恢复与负载均衡:一个DataServer故障,受影响的只是其负责的那几百个桶,而非半数数据。恢复时,这些桶可被快速、均匀地分摊到健康节点,实现秒级切换和精准的负载再平衡。
- 高效的路由管理:客户端缓存的路由表大小仅与桶的数量相关,与集群节点数无关,极大地减少了元数据的心跳与同步开销。
核心设计二:存储引擎抽象——统一接口下的多态实现
Tair深刻理解到,业务数据具有不同的温度和价值密度。因此,它创新性地定义了统一的存储引擎接口,底层支持多种存储介质,实现了 “一份业务代码,多种数据归宿” 的愿景。
表:Tair多存储引擎架构矩阵
| 引擎类型 | 核心介质 | 数据持久性 | 性能表现 | 典型业务场景 |
|---|---|---|---|---|
| MDB | 动态内存 | 异步持久化 | 微秒级,极致吞吐 | 热点缓存、会话存储 |
| LDB | SSD/高速磁盘 | 同步持久化 | 毫秒级,高性价比 | 温数据、用户历史订单 |
| RDB | 内存 | 可配 | 微秒级,支持复杂结构 | 需丰富数据结构的缓存 |
| NDB | 持久内存(PMem) | 同步持久化 | 近内存级,数据强可靠 | 交易流水、金融级数据 |
这一抽象层的战略意义在于:
- 成本效率的最优化:热数据用内存,温数据用SSD,冷数据用磁盘,业务无需改造即可通过配置实现数据的自动化分层存储。
- 业务逻辑的稳定性:无论底层是内存还是磁盘,上层应用访问的API和语义完全一致。数据在不同引擎间的迁移(如从MDB沉降到LDB)对业务透明。
- 技术栈的可持续演进:新的存储硬件(如傲腾持久内存)或引擎(如ZSTD压缩算法)可以插件化接入,保护已有投资。
核心设计三:全链路多线程——突破单线程的世纪瓶颈
在面对多核处理器成为标配的时代,Redis经典的单线程Reactor模型在处理超大流量、复杂命令或大Key时容易成为瓶颈。Tair则从架构上拥抱了并发,设计了全链路的多线程模型:
- 网络I/O线程组:专职处理连接管理、网络包的收发,将慢客户端的影响隔离。
- 工作线程组:核心业务线程,负责协议解析、命令执行、内存存取等。多线程并行处理请求,充分榨干多核CPU性能。
- 后端线程组:独立负责数据持久化、主从复制、跨集群同步等后台任务,不与前台请求争抢资源。
这种架构使得Tair在多核服务器上的性能扩展性近乎线性。在实测中,同等规格的Tair内存版性能可达开源Redis的3倍以上,尤其在高并发、混合读写场景下优势显著。它从根本上解决了单线程模型在处理耗时命令时引发的全局阻塞问题。
核心设计四:扩展数据结构——面向领域的语义化封装
Tair在100%兼容Redis数据结构的基础上,更进一步,提供了多种扩展数据结构(Modules)。这体现了其“将业务逻辑下沉”的设计哲学,旨在减少网络往返、简化客户端逻辑,并提供原子性的复杂操作。
经典案例:用exString实现分布式锁
传统Redis实现分布式锁需组合SETNX、EXPIRE等命令,存在原子性漏洞。Tair的exString(扩展字符串)原生集成了版本号和过期时间,通过CAD(Check And Delete)等原子指令,可优雅实现锁的获取与释放,彻底避免误删。
// 使用Tair exString实现安全、原子的分布式锁
public boolean tryLock(String key, String requestId, int expireSec) {
// setWithVersion: 原子操作,仅当key不存在(version=0)时创建,并设置过期
Result<DataEntry> result = tairClient.exString()
.setWithVersion(NAMESPACE, key, requestId, expireSec, 0);
return result.isSuccess(); // 成功即获得锁
}
public boolean unlock(String key, String requestId) {
// 1. 获取当前值以验证持有者
DataEntry entry = tairClient.get(NAMESPACE, key);
if (entry == null || !requestId.equals(entry.getValue())) {
return false; // 锁已过期或非持有者
}
// 2. 原子性地验证并删除
Result<Integer> cadResult = tairClient.exString()
.cad(NAMESPACE, key, entry.getVersion()); // CAD: Check And Delete
return cadResult.isSuccess();
}
其他扩展数据结构同样直击业务痛点:
- TairGIS:原生支持地理空间范围查询,性能远超基于GeoHash的应用层模拟。
- TairTS:针对时间序列数据优化,支持高精度压缩和预聚合,专为监控场景设计。
- TairVector:内置向量检索能力,直接服务于AI时代的推荐与搜索。
这些数据结构不是简单的API堆积,而是对领域知识的封装,让存储引擎能够理解业务语义,提供更高阶、更高效的原语操作。
架构启示与展望
回顾Tair的整体设计,我们可以提炼出对现代分布式系统构建具有普适价值的启示:
- 引入中间抽象层以解耦复杂变化:桶机制解耦了数据逻辑分布与物理拓扑,存储引擎抽象解耦了数据语义与存储介质。好的架构不是避免变化,而是隔离变化。
- 面向业务场景进行深度定制:从多线程模型到扩展数据结构,Tair的每一个特性都源于真实的业务痛点。技术架构的终极价值在于高效地解决业务问题,而非追求理论上的完美。
- 提供可配置的一致性、持久化与性能权衡:Tair不强加单一策略,而是将选择权交给架构师,体现了对复杂现实世界的尊重。工程是妥协的艺术,而好的平台应使这种妥协清晰且可控。
- 将复杂性封装在系统内部:无论是故障自动切换、数据平滑迁移,还是多引擎的统一接口,Tair都致力于将分布式固有的复杂性隐藏在内部,对外提供简洁的服务。降低使用者的认知负荷,是平台成功的关键。
Tair的演进,标志着一类新范式的兴起:存储系统正从通用的、被动的基础设施,演进为智能的、主动的业务数据服务层。它不再仅仅回答“数据在哪”,而是开始回答“数据能为你做什么”。对于每一位资深工程师和架构师而言,理解这种从“工具”到“伙伴”的转变,或许比掌握任何一个具体的技术细节都更为重要。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)