Nano Banana Pro (Gemini 3 Pro) 是低层视觉全能选手吗?
最近,文生图(Text-to-Image)模型的进化速度让人惊叹,它们在视觉内容创作领域掀起了一场革命。像Nano Banana Pro这样的商业产品(),更是吸引了无数眼球。不过,大家普遍关心的是,这个有着谷歌旗舰血统的强大模型除了能“画画”,能不能也作为一种通用的解决方案,去解决那些传统的、更基础的计算机视觉问题,比如图像去噪、超分辨率等?今天我们要解读的这篇技术报告,就深入探讨了这个关键问题
-
论文标题:Is Nano Banana Pro a Low-Level Vision All-Rounder? A Comprehensive Evaluation on 14 Tasks and 40 Datasets
-
论文作者:Jialong Zuo, Haoyou Deng, Hanyu Zhou, Jiaxin Zhu, Yicheng Zhang, Yiwei Zhang, Yongxin Yan, Kaixing Huang, Weisen Chen, Yongtai Deng, Rui Jin, Nong Sang, Changxin Gao
-
项目主页:https://lowlevelbanana.github.io/
最近,文生图(Text-to-Image)模型的进化速度让人惊叹,它们在视觉内容创作领域掀起了一场革命。像Nano Banana Pro这样的商业产品(实际上是谷歌 DeepMind 基于强大的 Gemini 3 Pro 多模态引擎构建的最新视觉生成系统),更是吸引了无数眼球。不过,大家普遍关心的是,这个有着谷歌旗舰血统的强大模型除了能“画画”,能不能也作为一种通用的解决方案,去解决那些传统的、更基础的计算机视觉问题,比如图像去噪、超分辨率等?
今天我们要解读的这篇技术报告,就深入探讨了这个关键问题:Nano Banana Pro算得上一个低层视觉的全能选手吗?
研究者们进行了一项非常全面的“零样本”(zero-shot)评测,覆盖了14个不同的低层视觉任务和40个多样化的数据集。他们没有对模型进行任何微调,仅仅通过简单的文本提示词,就将Nano Banana Pro与各个领域的顶尖(SOTA)专业模型进行了正面比较。
研究结果揭示了一个非常有趣的“二分”现象:一方面,Nano Banana Pro在主观视觉质量上表现卓越,它“脑补”出的高频细节常常让那些专业模型都相形见绌;但另一方面,在传统的、基于参考图像的量化指标(如PSNR、SSIM)上,它的得分却不尽人意。
评测方法:不教直接用的“零样本”评测
这项研究最核心的特点是“零样本”评测。这意味着研究者们没有用特定任务的数据去“教”Nano Banana Pro如何去雨、如何去雾,而是直接给它一个指令,让它自己想办法解决。
整个评测横跨了三大类共14种任务:
-
图像恢复:包括去雾、超分辨率、去雨、去阴影、去运动模糊、去散焦模糊、去噪、去反光、去光斑。
-
图像增强:包括低光照增强、水下图像增强、HDR成像。
-
图像融合:包括多焦点图像融合、红外与可见光图像融合。

这种全面的评估方式,能让我们清晰地看到,一个通用的生成式大模型在面对这些细分领域时的真实能力和局限性。
结果分析:惊艳的“优等生”与尴尬的“偏科生”
论文的核心发现,可以用“冰火两重天”来形容。Nano Banana Pro这位选手,一方面是视觉效果上的“优等生”,另一方面却是传统指标上的“偏科生”。
主观视觉质量:人眼可见的出色
在绝大多数任务中,Nano Banana Pro生成的结果在人眼看来都非常舒服。它不仅能完成任务(比如去除雨滴),还能对图像进行“脑补式”的优化,生成连原始的、作为标准答案的“真值图”(Ground Truth)都没有的、非常合理且清晰的细节。
图像去雨
例如,在去雨任务中,尽管大而密的雨痕严重遮挡了背景,导致颜色偏差和细节丢失,但Nano Banana Pro依然展现了强大的全局结构恢复能力。下面这张图里的吊桥缆绳结构,它恢复得就比很多监督学习的专业模型还要好,语义上更合理。

不过,它的表现也和雨的大小有关。雨小的时候,它能很好地保留原始色调和细节;雨大的时候,颜色就会出现偏移,细节也会丢失。

图像去模糊
在运动去模糊任务中,Nano Banana Pro在合成数据集(GoPro、HIDE)和真实世界数据集(RealBlur)上都展示了强大的恢复能力。它能成功恢复海报和招牌上的文字,甚至在高动态范围的场景下也处理得很好。


水下图像增强 (Underwater Image Enhancement)
水下环境由于光的吸收和散射,图像通常存在颜色失真(偏蓝或偏绿)、对比度低和细节模糊等问题。Nano Banana Pro 在处理这类图像时也表现出了其“双面性”。

从上图的成功案例可以看出,它能够有效校正色偏、显著提升对比度,并恢复场景的真实色彩和细节,视觉效果非常自然。
红外与可见光图像融合
在红外与可见光图像融合这个任务上,Nano Banana Pro的优势尤其明显。传统方法常常难以兼顾红外图像的目标高亮和可见光图像的背景纹理,但Nano Banana Pro生成的图像清晰度和对比度都极高,能够从源图像中挖掘和重建丰富的高频边缘信息。
下面这张图展示了它在MSRS数据集上的融合效果,无论是弱光下的行人目标,还是过曝区域的细节,都处理得相当不错。

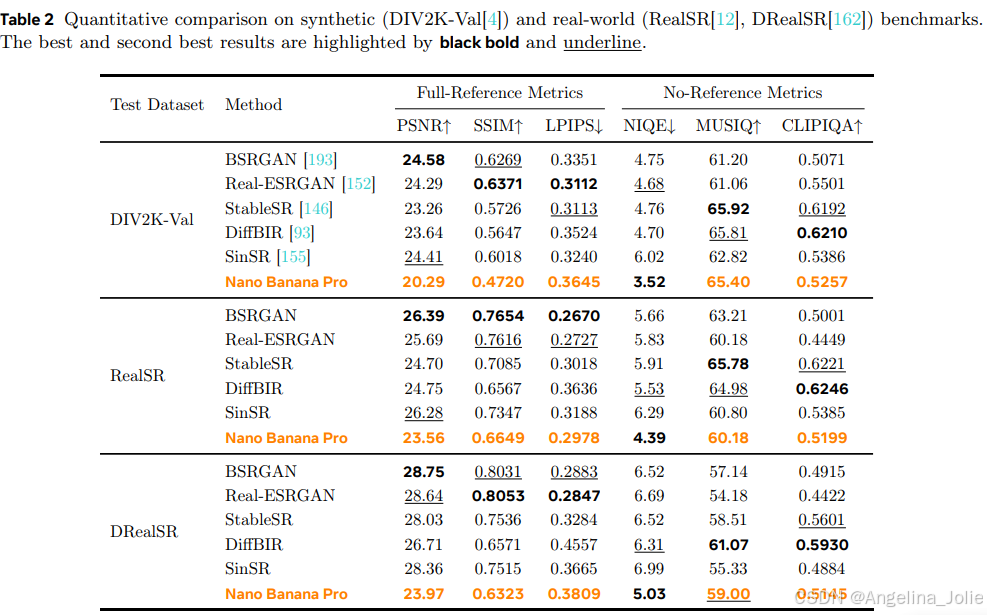
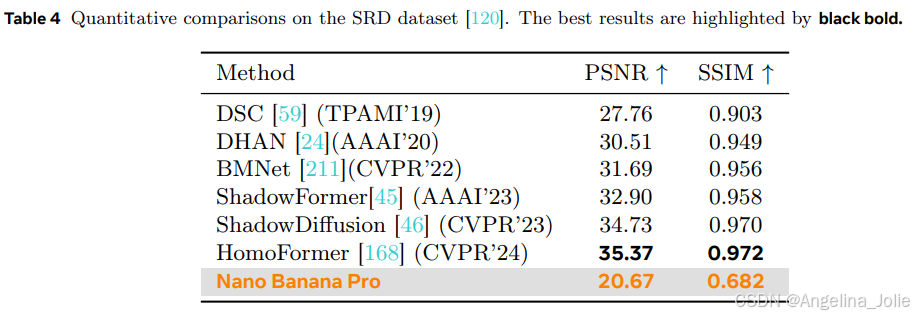
客观量化指标:全面的落后
尽管看起来效果拔群,但在传统的量化指标上,Nano Banana Pro却几乎全面落后于那些为特定任务“精修”过的专业模型。
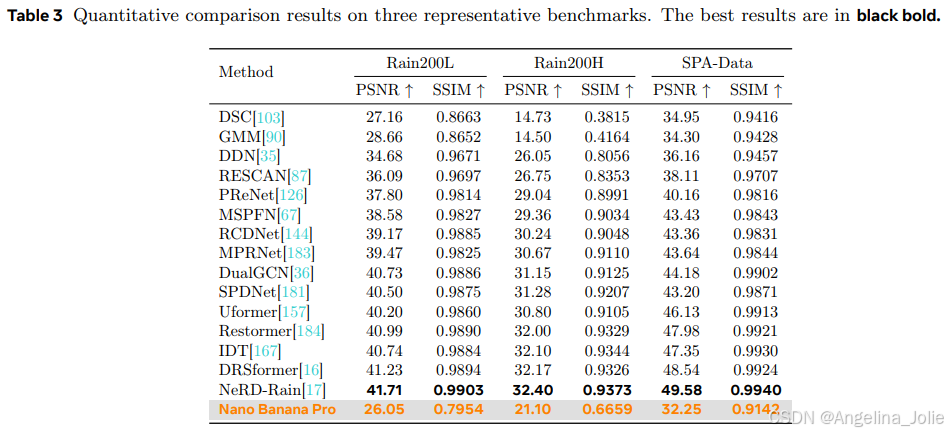
下表是去雨任务在三个主流数据集上的PSNR/SSIM指标对比,可以看到Nano Banana Pro与SOTA方法(如NeRD-Rain)存在巨大差距。
为什么会这样?
论文将这种差异归因于生成式模型固有的随机性(stochasticity)。
传统模型经过监督学习训练,目标是无限逼近一个给定的、唯一的“标准答案”(Ground Truth),追求的是像素级别的严格一致性。因此,它们在PSNR、SSIM这类衡量“相似度”的指标上得分很高。
而Nano Banana Pro这类生成式模型,它的目标是生成一个“合理”的、符合语义和人类审美的结果。它并不在乎生成的结果和那个唯一的“标准答案”在像素上是否一模一样。它可能会“创造性”地修复细节,甚至让结果比“标准答案”看起来更清晰、更合理。但这种“创造”在传统指标看来,就是“错误”,是与标准答案的“偏差”,得分自然就低了。
典型的失败案例
当然,Nano Banana Pro也并非完美,它在评测中也暴露了许多典型的“翻车”场景。
-
内容幻觉(Hallucination):这是生成式模型最常见的问题。在信息严重缺失的情况下,它会“脑补”出完全不存在的内容。比如在去阴影时,直接画出了一只新的手;在超分辨率时,生成了错误的文字。




一点思考
那么,回到最初的问题:Nano Banana Pro是低层视觉的全能选手吗?
这篇报告给出的答案是:还不是,但潜力巨大。
它证明了,像Nano Banana Pro这样的通用大模型,确实有能力在不经过任何特殊训练的情况下,仅凭简单的文本指令,就能应对多种多样的低层视觉任务,并且在“视觉效果”这个维度上,已经可以挑战甚至超越专业模型。
然而,“效果好但分数低”的矛盾也给我们带来了新的思考:我们是否需要为生成式AI设计新的评测体系? 当一个模型能创造出比“标准答案”更符合人眼审美的结果时,我们又该如何客观地评价它的好坏呢?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)