大模型开发平台TLM数据合成介绍
大模型数据合成(Data Synthesis for Large Models)是指通过人工生成或自动化手段构造用于训练、评估或增强大型人工智能模型(尤其是大语言模型,LLM)的数据集的过程。随着大模型对高质量、大规模训练数据需求的不断增长,真实世界数据在数量、多样性、隐私保护和成本等方面面临诸多挑战,因此数据合成技术逐渐成为解决这些问题的重要手段。一、为什么需要数据合成?数据稀缺性某些特定领域(
大模型开发平台TLM介绍
天纪大模型开发平台整合最新 AI 技术,提供模型广场、数据广场,模型微调、模型部署和模型评测等大模型开发的完整解决方案,为用户提供全套 LLMOPS 工程能力,助力业务快速基于通用模型开发出行业模型并部署服务。
数据合成简介
大模型数据合成(Data Synthesis for Large Models)是指通过人工生成或自动化手段构造用于训练、评估或增强大型人工智能模型(尤其是大语言模型,LLM)的数据集的过程。随着大模型对高质量、大规模训练数据需求的不断增长,真实世界数据在数量、多样性、隐私保护和成本等方面面临诸多挑战,因此数据合成技术逐渐成为解决这些问题的重要手段。
一、为什么需要数据合成?
1.数据稀缺性
某些特定领域(如医疗、法律、低资源语言)缺乏足够的标注数据,难以支撑大模型的有效训练。
2.隐私与合规问题
真实用户数据可能包含敏感信息,直接使用存在法律和伦理风险。合成数据可规避隐私泄露问题。
3.成本与效率
采集、清洗、标注真实数据耗时耗力,而合成数据可通过程序快速生成,降低数据获取成本。
4.数据多样性增强
合成数据可以人为控制分布、覆盖边缘案例(edge cases),提升模型鲁棒性和泛化能力。
5.模型自迭代需求
在“合成数据训练 → 模型改进 → 生成更优数据”的闭环中,模型自身可参与数据生成,实现自我进化。
二、数据合成的主要方法
1.基于规则/模板的方法
-
使用预定义的语法结构或模板生成文本。
-
示例:将“请把{商品}加入购物车”中的{商品}替换为不同词汇。
-
优点:可控性强;缺点:灵活性差,多样性有限。
2.基于小模型生成
-
利用较小的语言模型(如T5、BART)根据指令或种子数据生成新样本。
-
常用于数据增强,如同义句生成、问答对构造。
3.基于大语言模型(LLM)的合成
-
当前主流方式:利用强大的大模型(如GPT、Claude、通义千问等)生成高质量、多样化的文本数据。
-
典型流程:
-
设计提示(Prompt):“请生成10个关于气候变化的问答对。”
-
控制输出格式与质量(通过few-shot、思维链CoT等技巧)
-
后处理:去重、过滤低质量样本、人工审核
-
4.混合现实与合成数据(Blending)
-
将真实数据与合成数据混合使用,平衡真实性与多样性。
-
实践中常采用“80%真实 + 20%合成”策略。
5.对抗生成与反馈优化
-
使用强化学习或对抗机制优化合成数据质量(如RLHF中的合成偏好数据)。
-
利用判别模型判断合成数据的真实性,并反馈给生成器进行迭代优化。
三、典型应用场景
1.指令微调(Instruction Tuning)
- 生成大量“指令-响应”对,用于提升模型遵循指令的能力。
- 如:Alpaca、Self-Instruct 等项目使用GPT-3生成指令数据来训练开源模型。
2.推理能力训练
- 构造包含思维链(Chain-of-Thought, CoT)的推理样本,提升模型逻辑能力。
- 示例:让模型生成“问题 → 推理步骤 → 答案”的完整链条。
3.多语言数据扩展
- 利用大模型翻译或生成低资源语言内容,缓解语种不平衡问题。
4.安全与对齐数据构建
- 生成有害内容及对应的合规回应,用于训练模型拒绝不当请求(如红队测试数据)。
5.领域适配(Domain Adaptation)
- 在金融、医疗等专业领域,合成专业知识问答对,提升模型垂直能力。
数据合成原理
使用大模型进行数据合成的原理,本质上是利用大语言模型(Large Language Model, LLM)在预训练过程中学到的语言规律、世界知识和生成能力,通过适当的引导机制,使其“主动创造”出符合特定需求的新数据样本。这些合成数据可用于训练、微调或评估其他AI模型,尤其是在真实数据稀缺、昂贵或涉及隐私的情况下。
核心思想:将大模型作为“数据生成引擎”
传统数据依赖人工采集与标注,成本高且效率低。而大模型本身是一个经过海量文本训练的“知识容器”,具备强大的语义理解与内容生成能力。因此,可以将其视为一个智能的数据工厂:
输入提示(Prompt) → 大模型推理 → 输出结构化/自然语言数据
这一过程不是简单复制已有数据,而是基于已有知识进行泛化、重组和创造,实现高质量数据的自动化生产。
基本原理详解
1. 预训练知识的再利用(Knowledge Repurposing)
-
大模型在预训练阶段学习了互联网规模的文本,掌握了语法、常识、逻辑关系、领域术语等。
-
数据合成就像是“调用”这些内化的知识,按照指令重新组合成新的表达形式。
✅ 示例:
让模型生成医疗问答对,它会结合医学术语 + 问句结构 + 合理诊断路径 自动生成新样本。
这种能力源于其对语言分布 $P(\text{文本})$ 的建模,使得它可以从该分布中采样出合理的新实例。
2. 上下文学习能力(In-Context Learning)
-
大模型无需微调即可通过少样本示例(few-shot prompting) 理解任务格式。
-
原理:模型能从提示中的几个例子中“归纳”出模式,并应用于新生成。
📌 示例 prompt:
请生成类似的用户指令和助手回复:
用户:如何煮鸡蛋?
助手:将鸡蛋放入冷水中,加热至沸腾后煮8分钟即可。
用户:怎么泡绿茶?
助手:用80℃左右热水冲泡2-3分钟,避免烫坏茶叶。
---
现在请你生成一个新的:
👉 模型会自动模仿风格和结构,生成类似的生活类问答。
这说明模型具有元学习(meta-learning) 特性 —— 能快速适应新任务。
3. 条件概率生成机制(Autoregressive Generation)
大模型以自回归方式逐词生成文本:
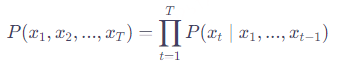
在数据合成中,我们通过条件控制(conditioning)来引导生成方向:
-
条件可以是:任务类型(如“翻译”)、主题(如“气候变化”)、格式(如JSON)、角色(如“专业律师”)
🎯 控制手段包括:
-
温度(temperature)调节随机性
-
Top-p / nucleus sampling 提高多样性
-
强制输出模板(via constrained decoding)
4. 思维链与推理能力支持复杂数据构造
对于需要逻辑推理的任务(如数学题、代码生成),大模型可通过思维链(Chain-of-Thought, CoT) 展示中间步骤,从而生成带解释的高质量数据。
🧠 原理:模型内部模拟人类推理过程,分步解决问题,然后将整个链条作为训练样本保存。
应用于:构建推理训练集、教学案例、错误分析样本等。
工作流程(原理实现路径)
1. 定义目标
└─ 明确用途:训练哪个模型?提升什么能力?
2. 设计提示(Prompt Design)
└─ 包含任务描述、格式要求、示例(few-shot)
3. 调用大模型批量生成
└─ 使用API或本地部署LLM执行生成
4. 后处理与质量控制
└─ 去重、过滤幻觉、事实核查、格式标准化
5. 融入训练流程
└─ 与真实数据混合,用于SFT(监督微调)或RLHF
6. 闭环迭代(可选)
└─ 新模型表现 → 反馈 → 改进提示 → 再生成
数据合成实践
在TLM中,首先上传数据文件,创建数据抽取任务。
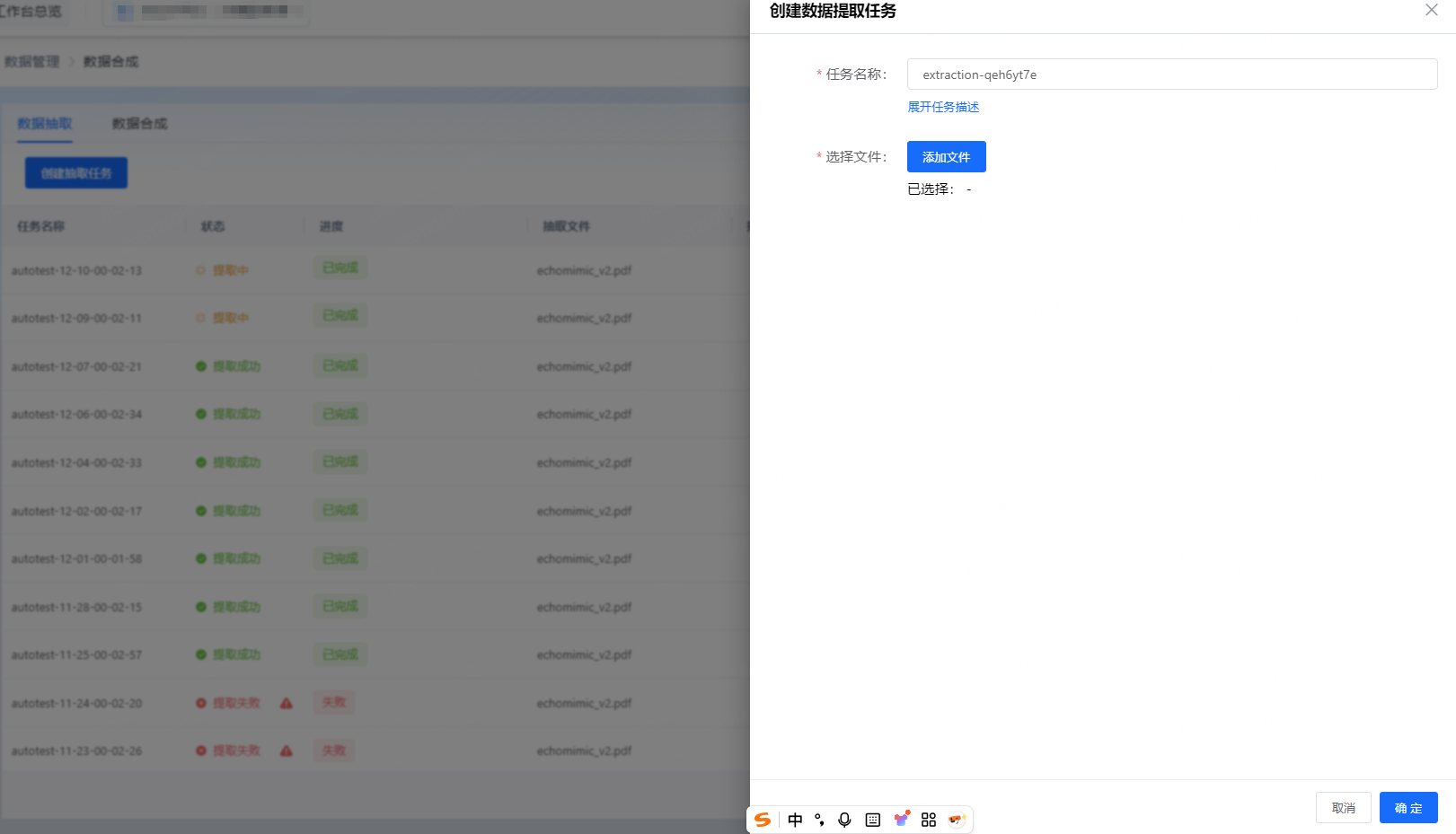
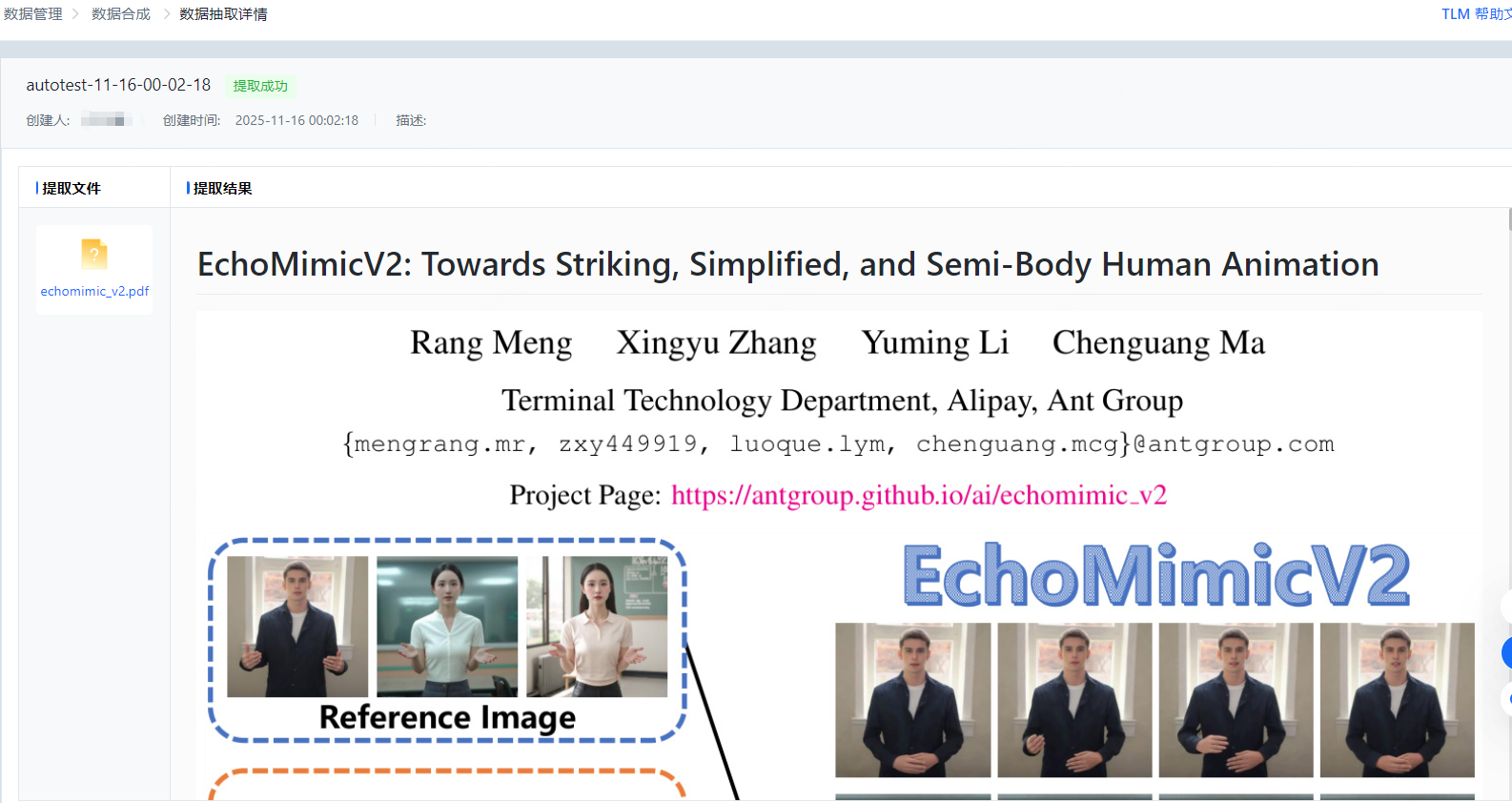
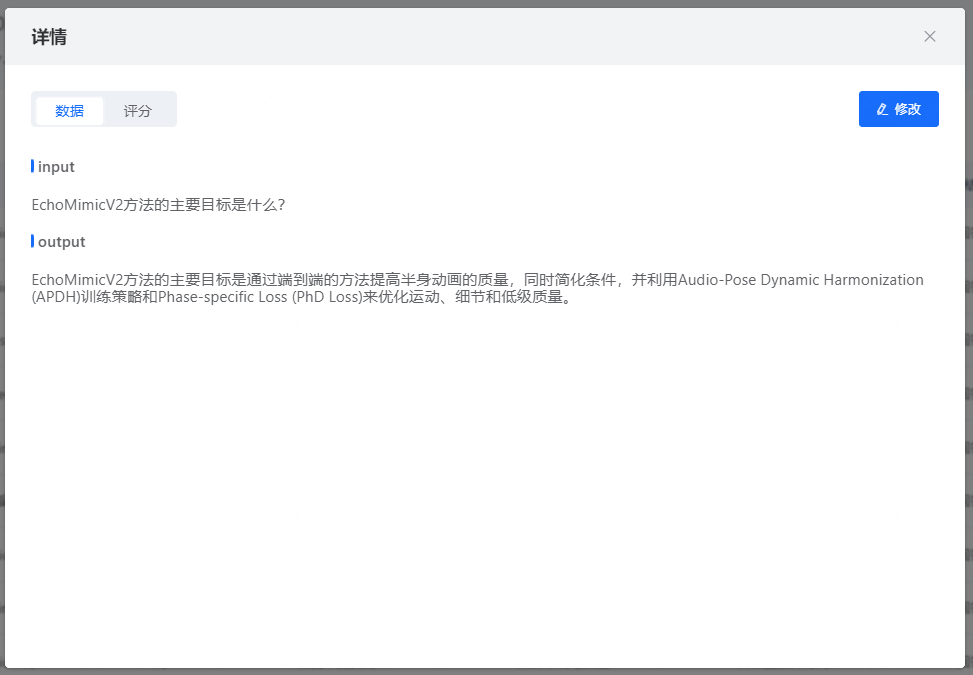
抽取完成后,可查收结果详情:
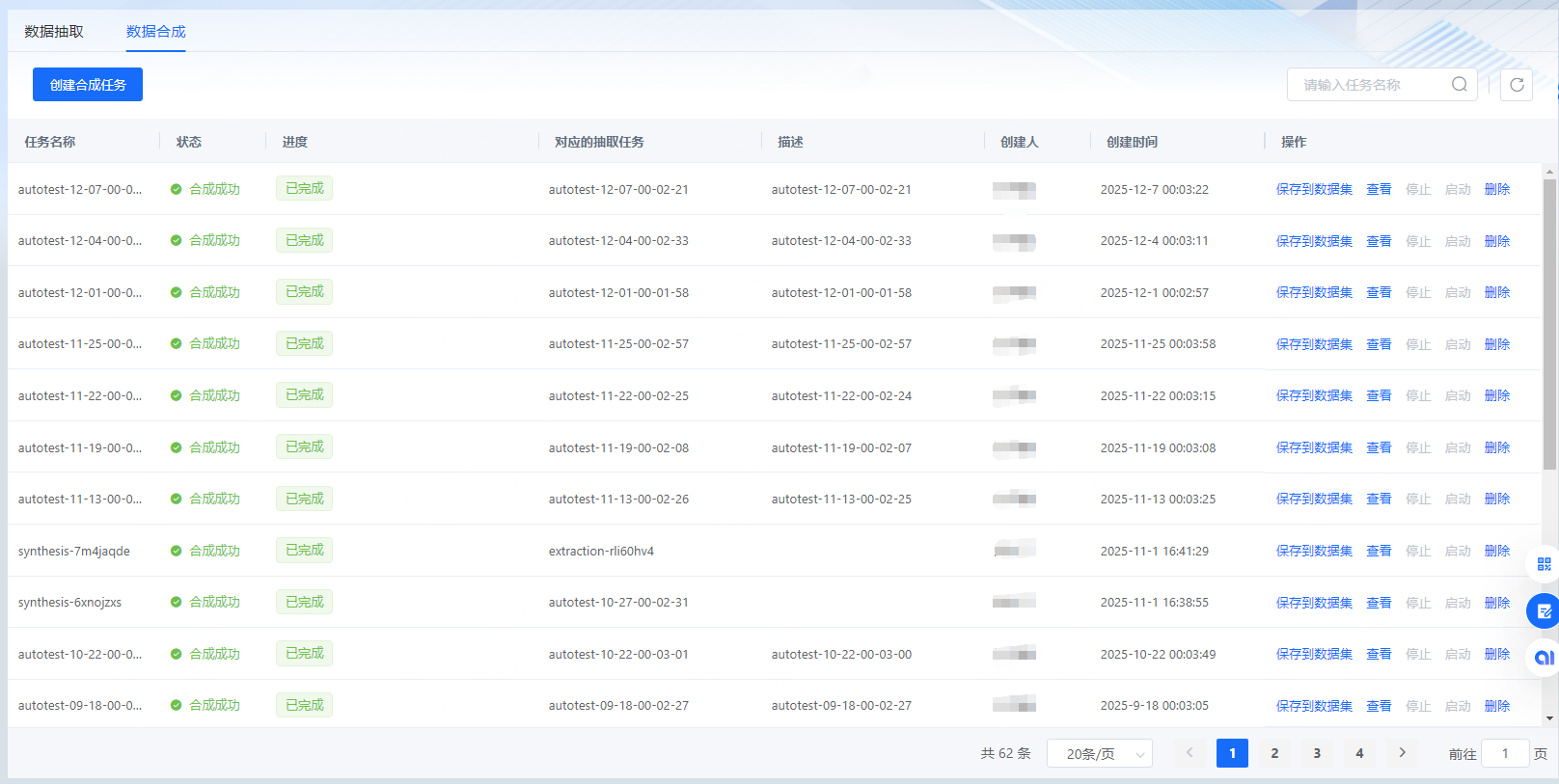
数据合成任务需要先选择已经运行成功的抽取任务:
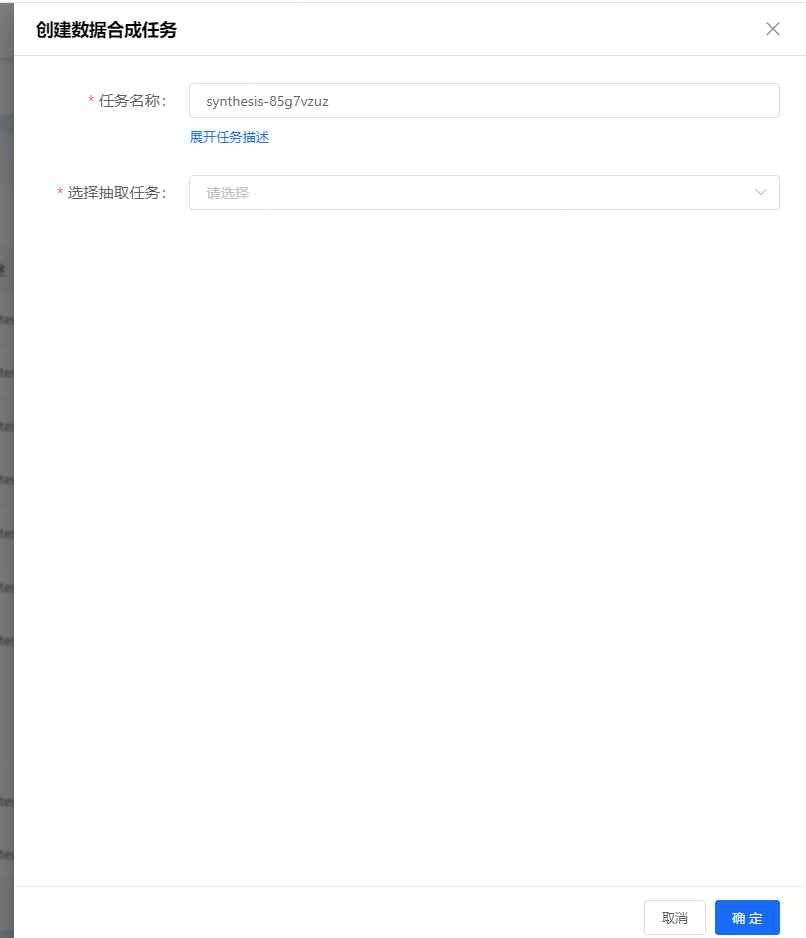
合成完成后可查看数据详情,并可将数据保存到数据集中。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)