液态神经网络原理
液态神经网络(LNN)不是“多一个模型”的锦上添花,而是AI 系统级瓶颈逼出来的换道求生。其核心优势包括:1. LNN 是目前唯一能把“时间变量”端到端学习出来、并给出数学可解释的深度学习架构,补上 AI 理论短板。2. 在“算力-内存-延迟”三角约束下,LNN 提供的是数量级级的硬指标改进,而非 5% 的软优化。3. 任何要把 AI 塞进“实时物理闭环”的场景,LNN 是目前公开唯一能同时满足低
液态神经网络(Liquid Neural Networks, LNNs)是近年来从生物神经系统启发而来的一类连续时间神经网络,其前沿进展和独特优势正使其成为AI领域的新兴热点。
Liquid AI 的 LFM 系列模型取得很好效果,3 B 参数就能在多项任务上持平或超越 7 B–13 B 的 Transformer;40 B-MoE 激活仅 12 B,可在单卡 A100 上跑 128 k 上下文
2025 年的 LFM 已经用实测数据证明:在同参数、同精度条件下,液态神经网络可以比 Transformer 更快、更省、更强;它率先撕开了“Transformer 唯一解”的口子,让“大模型架构换道”成为现实。
1. 核心原理:常微分方程 (ODE)
液态神经网络(Liquid Neural Networks, LNNs)是一种受生物启发(如线虫的神经系统)的新型深度学习架构。与传统神经网络在训练后参数就“固定”不同,LNN 的参数在推理阶段也能根据输入数据动态调整,表现得像“液体”一样具有流动性和自适应性。
传统神经网络(如 RNN 或 Transformer)通常在离散的时间步上处理信息(例如每秒处理一帧)。而 LNN 将神经元的状态视为连续时间的演化。它使用常微分方程 (ODE) 来描述神经元随时间的变化:

2. 为什么叫“液态”?💧
“液态”一词主要源于其流动时间常数 ($\tau$)。
在 LNN 中,这个常数不是固定的,而是与输入相关的。这意味着:
-
如果输入数据变化剧烈(如自动驾驶中突然出现的障碍物),网络可以调快“时钟”,更敏锐地反应。
-
如果输入平稳,网络可以放慢速度,节省计算资源。
液态神经网络(LNN)的核心在于它不只是一个静态的公式,而是一个描述动态演化的方程。
这种形态之所以存在,是因为它试图模拟生物神经元中电荷随时间流逝和输入信号变化的物理过程。让我们拆解这个基于常微分方程(ODE)的标准表达式:

这个公式实际上模仿了经典的 RC电路(电阻-电容电路) 或生物学中的 漏电整合触发(Leaky Integrate-and-Fire) 模型。
-
稳定性:左边的
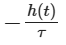 确保了系统不会无限制地膨胀,它提供了一种“拉回”的力量。
确保了系统不会无限制地膨胀,它提供了一种“拉回”的力量。 -
连续性:由于它是一个微分方程,LNN 可以处理任何时刻的输入,而不仅仅是固定间隔(如每秒一次)的数据。
3. LNN 的主要优势 🚀
相比于传统的循环神经网络 (RNN),LNN 具有以下显著特点:
|
特性 |
传统 RNN / LSTM |
液态神经网络 (LNN) |
|
时间处理 |
离散步长(固定间隔) |
连续时间(可处理不规则采样) |
|
参数性质 |
训练后固定(静态) |
运行中动态调整(液态/自适应) |
|
模型大小 |
通常需要成千上万个神经元 |
极度紧凑(几十个神经元即可完成任务) |
|
可解释性 |
类似黑盒 |
具有较强的物理/数学可解释性 |
总结
液态神经网络(LNN)不是“多一个模型”的锦上添花,而是AI 系统级瓶颈逼出来的换道求生。其核心优势包括:
1. LNN 是目前唯一能把“时间变量”端到端学习出来、并给出数学可解释的深度学习架构,补上 AI 理论短板。
2. 在“算力-内存-延迟”三角约束下,LNN 提供的是数量级级的硬指标改进,而非 5% 的软优化。
3. 任何要把 AI 塞进“实时物理闭环”的场景,LNN 是目前公开唯一能同时满足低延迟+高鲁棒+可解释的架构。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 52
52 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)