LangChain框架实战指南
本文为Java程序员提供Python AI开发入门指南,重点介绍LangChain框架。主要内容包括:1)LangChain的核心定位与生态全景,作为连接大语言模型与真实世界的桥梁;2)Java程序员快速掌握Python的语法对比与环境搭建;3)深入解析LangChain核心概念如Models、Chains、Agents等;4)LCEL(LangChain Expression Language)
Java程序员的Python AI开发入门
目录
第一章:初识LangChain
1.1 什么是LangChain
LangChain是一个开源的Python框架(也有JavaScript版本),专为简化基于大语言模型(LLM)的应用开发而设计。它提供了一套标准化的接口和工具,让开发者能够快速构建复杂的AI应用。
一句话理解: LangChain就像是连接LLM和真实世界的桥梁,它把复杂的AI能力封装成了易用的"积木",开发者只需要组装这些积木就能构建强大的AI应用。
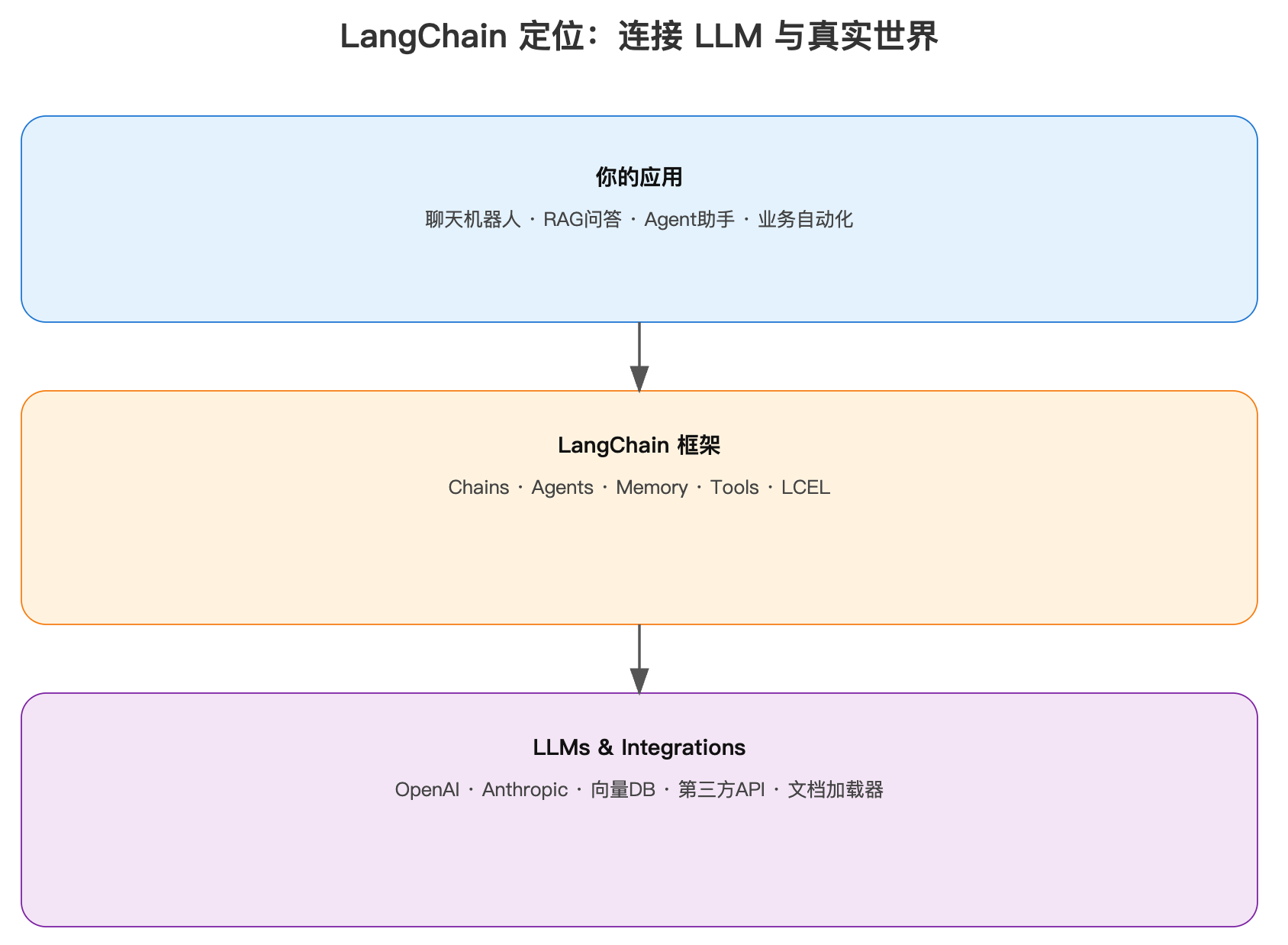
核心特点:
- 模块化设计:就像Java的Spring框架,LangChain提供了清晰的模块划分
- 可组合性:组件可以像乐高积木一样自由组合
- 生态丰富:支持100+种LLM和向量数据库
- 生产就绪:2025年发布1.0版本,稳定可靠
1.2 为什么需要LangChain
作为Java程序员,你可能会问:直接调用OpenAI API不就行了吗?为什么需要LangChain?
痛点一:重复造轮子
# ❌ 没有LangChain - 每次都要写这些基础代码
import openai
def chat_with_memory(messages, history):
# 手动管理对话历史
full_messages = history + messages
# 手动处理API调用
response = openai.ChatCompletion.create(
model="gpt-4",
messages=full_messages,
temperature=0.7
)
# 手动处理响应
answer = response.choices[0].message.content
# 手动更新历史
history.append({"role": "user", "content": messages[-1]["content"]})
history.append({"role": "assistant", "content": answer})
return answer, history
# ✅ 有了LangChain - 一行搞定
from langchain.memory import ConversationBufferMemory
from langchain_openai import ChatOpenAI
from langchain.chains import ConversationChain
chain = ConversationChain(
llm=ChatOpenAI(model="gpt-4"),
memory=ConversationBufferMemory()
)
answer = chain.invoke("你好")
对比感受: 就像在Java中,你不会每次都手写JDBC连接代码,而是使用Spring JdbcTemplate或Hibernate一样。
痛点二:复杂工作流难以管理
# ❌ 没有LangChain - 复杂流程难以维护
def complex_qa_system(question):
# Step 1: 检索相关文档
docs = search_vector_db(question)
# Step 2: 总结文档
summary = summarize(docs)
# Step 3: 生成答案
answer = generate_answer(question, summary)
# Step 4: 评估答案质量
if not is_good_answer(answer):
# 重新生成
answer = generate_answer_v2(question, docs)
return answer
# ✅ 有了LangChain - 声明式定义流程(LCEL)
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| ChatOpenAI()
| StrOutputParser()
)
answer = chain.invoke("问题")
对比感受: 就像Java的Stream API,用声明式代码替代命令式代码,更清晰、更易维护。
痛点三:缺乏生产级特性
直接调用API缺少:
- 错误重试:API调用失败怎么办?
- 成本控制:token使用如何监控?
- 可观测性:如何追踪调用链路?
- 缓存机制:如何避免重复调用?
LangChain内置了这些特性:
from langchain.cache import InMemoryCache
from langchain.callbacks import get_openai_callback
import langchain
# 启用缓存
langchain.llm_cache = InMemoryCache()
# 监控成本
with get_openai_callback() as cb:
result = chain.invoke("问题")
print(f"Token使用: {cb.total_tokens}, 成本: ${cb.total_cost}")
1.3 LangChain的核心定位
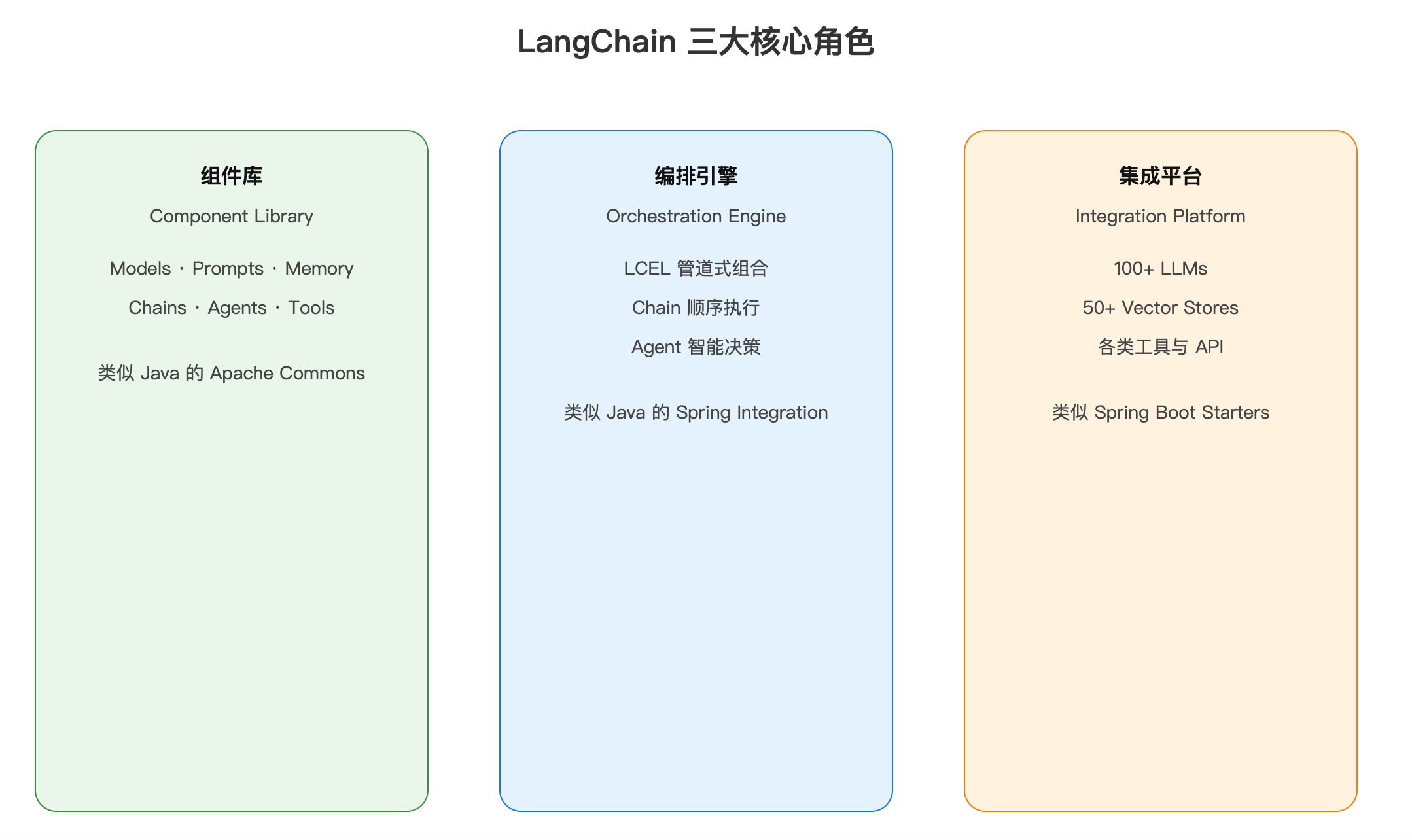
LangChain在AI应用开发中扮演三个核心角色:
1.4 LangChain生态全景
LangChain不是一个单一的库,而是一个完整的生态系统:
LangChain 生态系统
├── langchain-core # 核心抽象和接口
│ ├── Runnables # LCEL核心
│ ├── Prompts # 提示词模板
│ └── Output Parsers # 输出解析
│
├── langchain # 主库
│ ├── Chains # 链式调用
│ ├── Agents # 智能体
│ └── Memory # 记忆管理
│
├── langchain-community # 社区集成
│ ├── VectorStores # 各种向量数据库
│ ├── Document Loaders # 文档加载器
│ └── Tools # 工具集
│
├── langchain-[provider] # 官方集成包
│ ├── langchain-openai # OpenAI集成
│ ├── langchain-anthropic # Anthropic集成
│ └── langchain-google # Google集成
│
├── LangGraph # 复杂Agent编排
│ └── 状态图式工作流
│
└── LangSmith # 可观测性平台
├── 调试和追踪
├── 评估和测试
└── 监控和分析
安装建议:
# 基础安装
pip install langchain langchain-core
# 根据需要安装特定集成
pip install langchain-openai # OpenAI
pip install langchain-anthropic # Claude
pip install langchain-community # 社区工具
# 向量数据库
pip install chromadb # Chroma向量库
pip install faiss-cpu # FAISS向量库
# 文档处理
pip install pypdf # PDF支持
pip install unstructured # 各种文档格式
1.5 LangChain vs LangChain4j
作为Java程序员,你可能听说过LangChain4j。它们之间的关系是什么?
基本关系
| 维度 | LangChain (Python) | LangChain4j (Java) |
|---|---|---|
| 定位 | 原版框架,Python生态 | Java移植版,但不是简单移植 |
| 作者 | Harrison Chase创建 | 独立团队开发 |
| 设计理念 | Python风格,函数式 | Java风格,面向对象 |
| 成熟度 | ⭐⭐⭐⭐⭐ 1.0发布 | ⭐⭐⭐⭐ 1.0发布 |
| 生态 | ⭐⭐⭐⭐⭐ 最丰富 | ⭐⭐⭐⭐ 快速增长 |
| 更新速度 | ⭐⭐⭐⭐⭐ 最快 | ⭐⭐⭐⭐ 跟进及时 |
| 学习资源 | ⭐⭐⭐⭐⭐ 最多 | ⭐⭐⭐ 逐步完善 |
代码风格对比
# LangChain (Python) - 函数式风格
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 使用LCEL管道操作符 |
chain = (
ChatPromptTemplate.from_template("讲个关于{topic}的笑话")
| ChatOpenAI()
| StrOutputParser()
)
result = chain.invoke({"topic": "程序员"})
// LangChain4j (Java) - 面向对象风格
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.service.AiServices;
// 使用接口和注解
interface JokeAssistant {
@SystemMessage("你是一个幽默的助手")
String tellJoke(@UserMessage String topic);
}
JokeAssistant assistant = AiServices.create(
JokeAssistant.class,
OpenAiChatModel.withApiKey(apiKey)
);
String result = assistant.tellJoke("程序员");
如何选择?
选LangChain的理由:
- 原汁原味:最新特性第一时间体验
- 生态最强:集成最多,社区最活跃
- 学习资源:教程、文档、案例最丰富
- 多语言:掌握Python也能用JavaScript版
选LangChain4j的理由:
- 技术栈统一:全Java技术栈,无需切换语言
- Spring集成:与Spring Boot无缝集成
- 类型安全:Java的静态类型检查
- 团队技能:团队都是Java背景
我的建议:
- 学习和原型开发 → LangChain (Python),生态最强,迭代最快
- 企业Java项目 → LangChain4j,技术栈统一
- 两者都学 → 概念互通,学会一个另一个很容易
第二章:Java程序员的Python速成
在深入LangChain之前,让我们快速掌握Python基础。作为Java程序员,你会发现Python其实很简单。
2.1 Python基础语法对比
2.1.1 变量和类型
# Python - 动态类型,无需声明
name = "张三" # 字符串
age = 25 # 整数
height = 1.75 # 浮点数
is_student = True # 布尔值
scores = [90, 85, 88] # 列表(类似ArrayList)
person = {"name": "张三", "age": 25} # 字典(类似HashMap)
# Java对比
String name = "张三";
int age = 25;
double height = 1.75;
boolean isStudent = true;
List<Integer> scores = Arrays.asList(90, 85, 88);
Map<String, Object> person = new HashMap<>();
person.put("name", "张三");
person.put("age", 25);
重点:
- Python不需要
;结尾 - 使用缩进而非
{}表示代码块 - 变量名推荐
snake_case(Java是camelCase)
2.1.2 函数定义
# Python
def calculate_sum(a, b):
"""计算两数之和(这是文档字符串)"""
result = a + b
return result
# 调用
total = calculate_sum(10, 20)
# 默认参数
def greet(name, greeting="你好"):
return f"{greeting}, {name}!"
print(greet("张三")) # 输出:你好, 张三!
print(greet("张三", "Hello")) # 输出:Hello, 张三!
// Java对比
/**
* 计算两数之和
*/
public int calculateSum(int a, int b) {
int result = a + b;
return result;
}
// Java没有默认参数,需要方法重载
public String greet(String name) {
return greet(name, "你好");
}
public String greet(String name, String greeting) {
return greeting + ", " + name + "!";
}
2.1.3 类和对象
# Python
class Person:
# 构造函数
def __init__(self, name, age):
self.name = name # 实例变量
self.age = age
# 实例方法
def introduce(self):
return f"我是{self.name},{self.age}岁"
# 类方法
@classmethod
def from_birth_year(cls, name, birth_year):
age = 2025 - birth_year
return cls(name, age)
# 静态方法
@staticmethod
def is_adult(age):
return age >= 18
# 使用
person = Person("张三", 25)
print(person.introduce())
person2 = Person.from_birth_year("李四", 2000)
print(Person.is_adult(25))
// Java对比
public class Person {
private String name;
private int age;
// 构造函数
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 实例方法
public String introduce() {
return "我是" + name + "," + age + "岁";
}
// 工厂方法(对应Python的类方法)
public static Person fromBirthYear(String name, int birthYear) {
int age = 2025 - birthYear;
return new Person(name, age);
}
// 静态方法
public static boolean isAdult(int age) {
return age >= 18;
}
}
重点对照:
self=this__init__= 构造函数@classmethod≈ 工厂方法@staticmethod=static方法
2.1.4 条件和循环
# Python - if语句
age = 25
if age < 18:
print("未成年")
elif age < 60:
print("成年")
else:
print("老年")
# for循环
numbers = [1, 2, 3, 4, 5]
for num in numbers:
print(num)
# 带索引的循环
for i, num in enumerate(numbers):
print(f"索引{i}: {num}")
# 字典遍历
person = {"name": "张三", "age": 25}
for key, value in person.items():
print(f"{key}: {value}")
# 列表推导式(强大的特性!)
squares = [x**2 for x in range(10)] # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
evens = [x for x in range(10) if x % 2 == 0] # [0, 2, 4, 6, 8]
// Java对比
int age = 25;
if (age < 18) {
System.out.println("未成年");
} else if (age < 60) {
System.out.println("成年");
} else {
System.out.println("老年");
}
// for循环
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
for (Integer num : numbers) {
System.out.println(num);
}
// 带索引
for (int i = 0; i < numbers.size(); i++) {
System.out.println("索引" + i + ": " + numbers.get(i));
}
// Java 8 Stream(类似Python列表推导式)
List<Integer> squares = IntStream.range(0, 10)
.map(x -> x * x)
.boxed()
.collect(Collectors.toList());
2.1.5 异常处理
# Python
try:
result = 10 / 0
except ZeroDivisionError as e:
print(f"错误: {e}")
except Exception as e:
print(f"其他错误: {e}")
finally:
print("清理资源")
# 抛出异常
def divide(a, b):
if b == 0:
raise ValueError("除数不能为0")
return a / b
// Java对比
try {
int result = 10 / 0;
} catch (ArithmeticException e) {
System.out.println("错误: " + e.getMessage());
} catch (Exception e) {
System.out.println("其他错误: " + e.getMessage());
} finally {
System.out.println("清理资源");
}
// 抛出异常
public double divide(int a, int b) {
if (b == 0) {
throw new IllegalArgumentException("除数不能为0");
}
return (double) a / b;
}
2.1.6 导入和模块
# Python - 类似Java的import
import os # import整个模块
from os import path # 导入特定内容
from os.path import join as pjoin # 导入并重命名
from langchain_openai import * # 导入所有(不推荐)
# 使用
file_path = os.path.join("docs", "file.txt")
file_path2 = path.join("docs", "file.txt")
file_path3 = pjoin("docs", "file.txt")
// Java对比
import java.io.*; // 导入所有
import java.nio.file.Path; // 导入特定类
import java.nio.file.Paths;
import static java.nio.file.Paths.get; // 静态导入
// 使用
Path filePath = Paths.get("docs", "file.txt");
Path filePath2 = get("docs", "file.txt"); // 静态导入后
2.2 开发环境搭建
2.2.1 Python安装
# macOS/Linux - 使用pyenv(推荐)
curl https://pyenv.run | bash
pyenv install 3.11.0
pyenv global 3.11.0
# 或直接从官网下载:https://www.python.org/downloads/
# 推荐Python 3.10+
2.2.2 虚拟环境(类似Maven的本地仓库隔离)
# 创建虚拟环境(类似创建新的Maven项目)
python -m venv venv
# 激活虚拟环境
# macOS/Linux
source venv/bin/activate
# Windows
venv\Scripts\activate
# 安装依赖(类似Maven的dependency)
pip install langchain langchain-openai
# 导出依赖列表(类似pom.xml)
pip freeze > requirements.txt
# 从依赖列表安装(类似mvn install)
pip install -r requirements.txt
对比理解:
venv= Maven的本地仓库隔离requirements.txt=pom.xmlpip install=mvn dependency:get
2.2.3 IDE选择
推荐方案:
-
PyCharm - JetBrains出品,Java程序员最熟悉
- Community版免费 - 界面和快捷键与IDEA一致 - 调试体验一流 -
VS Code - 轻量级,配置Python插件
- 安装Python扩展 - 安装Pylance(类型检查) - 配置虚拟环境
2.3 常用库和工具
2.3.1 必备库对照
| Python库 | 作用 | Java对应 |
|---|---|---|
requests |
HTTP客户端 | Apache HttpClient |
pandas |
数据处理 | Apache Commons CSV |
numpy |
数值计算 | 无直接对应 |
pytest |
单元测试 | JUnit |
black |
代码格式化 | google-java-format |
pylint |
代码检查 | Checkstyle |
poetry |
依赖管理 | Maven/Gradle |
2.3.2 常用操作对照
# Python常用操作
# 1. 读文件
with open("file.txt", "r") as f:
content = f.read()
# with自动关闭文件(类似Java的try-with-resources)
# 2. HTTP请求
import requests
response = requests.get("https://api.example.com/data")
data = response.json()
# 3. 环境变量
import os
api_key = os.getenv("OPENAI_API_KEY")
# 4. JSON处理
import json
data = json.loads('{"name": "张三"}')
json_str = json.dumps(data)
# 5. 日期时间
from datetime import datetime
now = datetime.now()
formatted = now.strftime("%Y-%m-%d %H:%M:%S")
// Java对比
// 1. 读文件
try (BufferedReader reader = new BufferedReader(new FileReader("file.txt"))) {
String content = reader.lines().collect(Collectors.joining("\n"));
}
// 2. HTTP请求
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.example.com/data"))
.build();
HttpResponse<String> response = client.send(request,
HttpResponse.BodyHandlers.ofString());
// 3. 环境变量
String apiKey = System.getenv("OPENAI_API_KEY");
// 4. JSON处理(使用Gson或Jackson)
Gson gson = new Gson();
Map data = gson.fromJson("{\"name\": \"张三\"}", Map.class);
String jsonStr = gson.toJson(data);
// 5. 日期时间
LocalDateTime now = LocalDateTime.now();
String formatted = now.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
2.4 Python项目结构
my_langchain_project/
├── venv/ # 虚拟环境(类似.m2)
├── src/ # 源代码
│ ├── __init__.py # 标记为Python包
│ ├── main.py # 主程序
│ ├── chains/ # 链相关代码
│ │ ├── __init__.py
│ │ └── qa_chain.py
│ ├── agents/ # Agent相关
│ │ ├── __init__.py
│ │ └── search_agent.py
│ └── utils/ # 工具类
│ ├── __init__.py
│ └── helpers.py
├── tests/ # 测试代码
│ ├── __init__.py
│ └── test_chains.py
├── requirements.txt # 依赖列表(类似pom.xml)
├── .env # 环境变量
├── .gitignore # Git忽略文件
└── README.md # 项目说明
对比Java项目:
Java项目 Python项目
src/main/java/ → src/
src/test/java/ → tests/
pom.xml → requirements.txt
application.properties → .env
重点:
__init__.py:标记目录为Python包(Python 3.3+可省略,但推荐保留).env:存储环境变量(API密钥等),类似application.properties
本章小结:
恭喜!你已经掌握了Python基础。记住这几个关键点:
- 语法更简洁:无需分号、用缩进、动态类型
- 概念是相通的:类、函数、异常处理都一样
- 工具链类似:pip=Maven、venv=本地仓库隔离
- IDE熟悉:PyCharm和IDEA是一家
下一章我们将深入LangChain的核心概念,你会发现有了Python基础,理解LangChain会非常轻松!
第三章:LangChain核心概念
3.1 整体架构
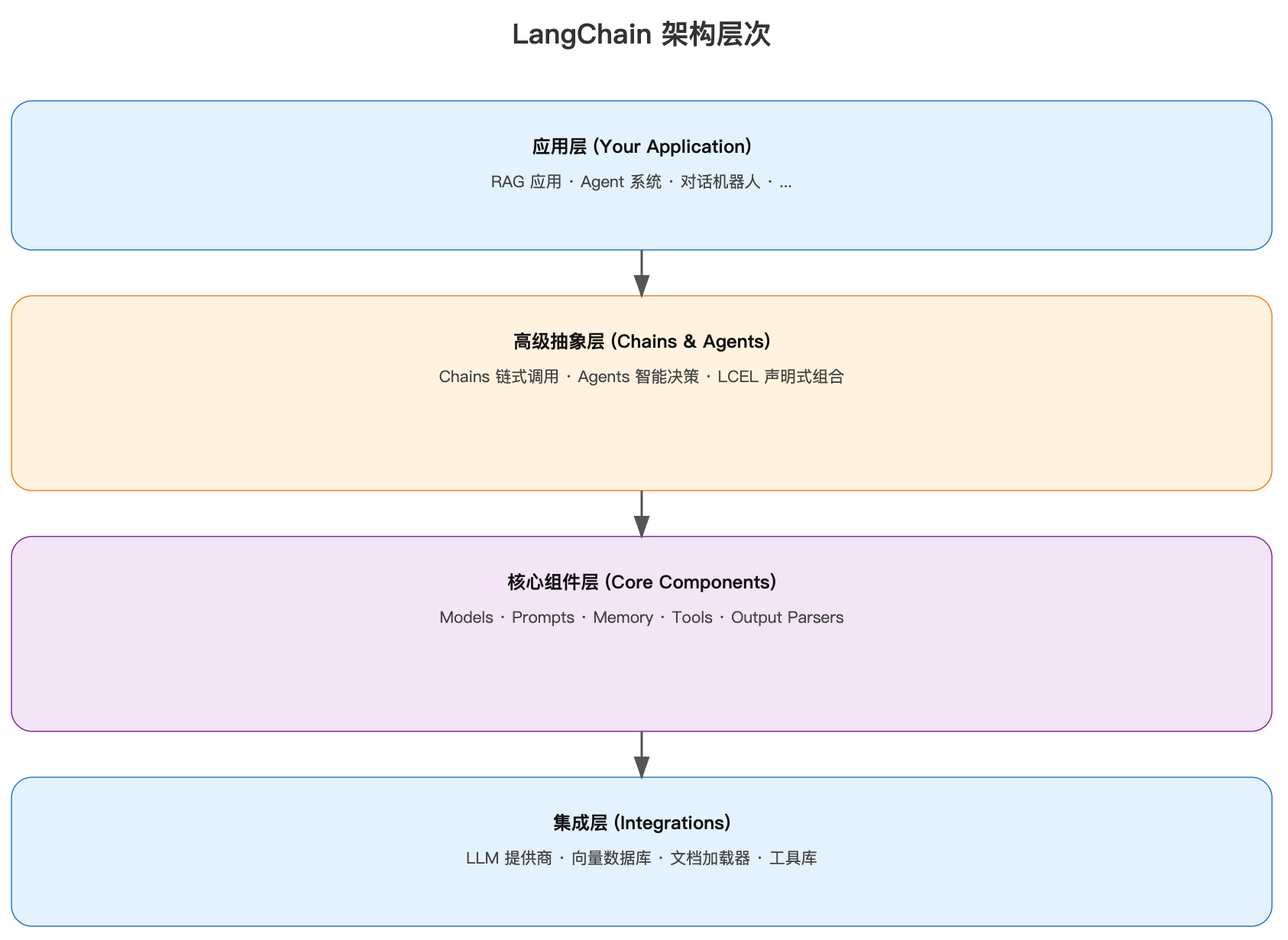
LangChain采用模块化、分层的架构设计,类似Spring框架的设计理念:
3.2 Models(模型)
Models是LangChain与LLM交互的核心抽象,类似JDBC的Connection。
3.2.1 LLM vs ChatModel
# LLM - 文本补全(类似早期的GPT-3)
from langchain_openai import OpenAI
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0.7,
max_tokens=1000
)
# 简单的文本补全
text = llm.invoke("写一首关于Python的诗")
print(text)
# ChatModel - 对话模型(现代推荐方式)
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(
model="gpt-4",
temperature=0.7
)
# 使用消息格式
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="你是一个Python专家"),
HumanMessage(content="解释什么是装饰器")
]
response = chat.invoke(messages)
print(response.content)
Java对比理解:
// 类似JDBC的不同驱动
Connection conn = DriverManager.getConnection(url); // JDBC抽象
// LangChain的Model也是抽象
ChatModel chat = new OpenAIChatModel(...); // OpenAI实现
ChatModel chat = new AnthropicChatModel(...); // Anthropic实现
// 接口一致,底层实现不同
3.2.2 模型配置
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(
model="gpt-4",
temperature=0.7, # 创造性 0-2,0最确定,2最随机
max_tokens=2000, # 最大输出token数
timeout=60, # 超时时间
max_retries=3, # 重试次数
api_key="sk-...", # API密钥(推荐用环境变量)
base_url="https://..." # 自定义API端点
)
# 流式输出(类似Stream API)
for chunk in chat.stream("讲个笑话"):
print(chunk.content, end="", flush=True)
# 批量调用
messages_list = [
[HumanMessage("1+1=?")],
[HumanMessage("2+2=?")],
]
responses = chat.batch(messages_list)
3.2.3 支持的模型
# OpenAI系列
from langchain_openai import ChatOpenAI, OpenAI
# Anthropic (Claude)
from langchain_anthropic import ChatAnthropic
# Google
from langchain_google_genai import ChatGoogleGenerativeAI
# 本地模型 (Ollama)
from langchain_community.llms import Ollama
# 国产模型
from langchain_community.chat_models import QianfanChatEndpoint # 文心一言
from langchain_community.chat_models import ChatTongyi # 通义千问
# 使用示例
chat_gpt4 = ChatOpenAI(model="gpt-4")
chat_claude = ChatAnthropic(model="claude-3-opus-20240229")
chat_gemini = ChatGoogleGenerativeAI(model="gemini-pro")
chat_local = Ollama(model="llama2")
3.3 Prompts(提示词)
Prompts是与LLM交互的"接口规范",类似API的请求格式。
3.3.1 Prompt模板
from langchain_core.prompts import PromptTemplate
# 基础模板(类似String.format)
template = "给我讲一个关于{topic}的{style}笑话"
prompt = PromptTemplate.from_template(template)
# 使用
formatted = prompt.format(topic="程序员", style="冷")
print(formatted) # 输出:给我讲一个关于程序员的冷笑话
# 链式调用
chain = prompt | chat
result = chain.invoke({"topic": "程序员", "style": "冷"})
Java对比:
// Java的字符串格式化
String template = "给我讲一个关于%s的%s笑话";
String formatted = String.format(template, "程序员", "冷");
// 或使用MessageFormat
MessageFormat mf = new MessageFormat("给我讲一个关于{0}的{1}笑话");
String formatted = mf.format(new Object[]{"程序员", "冷"});
3.3.2 ChatPrompt模板
from langchain_core.prompts import ChatPromptTemplate
# 定义聊天模板
template = ChatPromptTemplate.from_messages([
("system", "你是一个{role},专注于{domain}领域"),
("human", "{input}")
])
# 使用
messages = template.format_messages(
role="高级工程师",
domain="Java后端",
input="如何优化Spring Boot应用性能?"
)
response = chat.invoke(messages)
3.3.3 Few-shot提示
from langchain_core.prompts import FewShotPromptTemplate
# 示例
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
]
# 示例模板
example_template = """
Input: {input}
Output: {output}
"""
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template=example_template
)
# Few-shot模板
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Input: {input}\nOutput:",
input_variables=["input"]
)
print(few_shot_prompt.format(input="big"))
3.4 Chains(链)
Chains是LangChain的核心概念,用于组合多个组件形成工作流。
3.4.1 简单链
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 创建链的组件
prompt = ChatPromptTemplate.from_template("给我讲一个关于{topic}的笑话")
model = ChatOpenAI()
output_parser = StrOutputParser()
# 使用 | 操作符组合(LCEL语法)
chain = prompt | model | output_parser
# 调用
result = chain.invoke({"topic": "Python"})
print(result)
对比理解(类似Java Stream):
// Java Stream的管道操作
List<String> results = list.stream()
.filter(s -> s.length() > 3) // 过滤
.map(String::toUpperCase) // 转换
.collect(Collectors.toList()); // 收集
// LangChain的链式操作
chain = prompt | model | parser
result = chain.invoke(input)
3.4.2 顺序链(Sequential Chain)
from langchain.chains import LLMChain, SequentialChain
# 第一个链:生成剧本概要
synopsis_chain = LLMChain(
llm=chat,
prompt=PromptTemplate.from_template(
"给电影《{title}》写一个概要"
),
output_key="synopsis"
)
# 第二个链:基于概要写评论
review_chain = LLMChain(
llm=chat,
prompt=PromptTemplate.from_template(
"给这个电影概要写一个评论:\n{synopsis}"
),
output_key="review"
)
# 组合成顺序链
overall_chain = SequentialChain(
chains=[synopsis_chain, review_chain],
input_variables=["title"],
output_variables=["synopsis", "review"]
)
# 执行
result = overall_chain.invoke({"title": "黑客帝国"})
print(result["review"])
3.4.3 路由链(Router Chain)
from langchain.chains.router import MultiPromptChain
from langchain.chains import LLMChain
# 定义不同的提示模板
physics_template = """你是一个物理学家,回答问题:{input}"""
math_template = """你是一个数学家,回答问题:{input}"""
history_template = """你是一个历史学家,回答问题:{input}"""
prompt_infos = [
{
"name": "physics",
"description": "擅长回答物理问题",
"prompt_template": physics_template
},
{
"name": "math",
"description": "擅长回答数学问题",
"prompt_template": math_template
},
{
"name": "history",
"description": "擅长回答历史问题",
"prompt_template": history_template
}
]
# 创建路由链
destination_chains = {}
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = PromptTemplate(template=prompt_template, input_variables=["input"])
chain = LLMChain(llm=chat, prompt=prompt)
destination_chains[name] = chain
# 默认链
default_chain = LLMChain(
llm=chat,
prompt=PromptTemplate.from_template("回答问题:{input}")
)
# 创建多提示路由
chain = MultiPromptChain(
router_chain=..., # 路由决策
destination_chains=destination_chains,
default_chain=default_chain
)
3.5 Memory(记忆)
Memory让AI能够"记住"对话历史,实现多轮对话。
3.5.1 缓冲记忆
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
# 创建记忆
memory = ConversationBufferMemory()
# 创建对话链
conversation = ConversationChain(
llm=ChatOpenAI(),
memory=memory
)
# 多轮对话
print(conversation.invoke("我叫张三")["response"])
# 输出:你好张三!
print(conversation.invoke("我叫什么名字?")["response"])
# 输出:你叫张三。(记住了之前的对话)
# 查看记忆
print(memory.buffer)
Java对比:
// 类似ThreadLocal或Session存储
HttpSession session = request.getSession();
session.setAttribute("username", "张三");
// 后续请求能获取
String username = (String) session.getAttribute("username");
3.5.2 窗口记忆
from langchain.memory import ConversationBufferWindowMemory
# 只保留最近k轮对话
memory = ConversationBufferWindowMemory(k=2)
conversation = ConversationChain(
llm=chat,
memory=memory
)
# 第1轮
conversation.invoke("1+1=?")
# 第2轮
conversation.invoke("2+2=?")
# 第3轮
conversation.invoke("3+3=?")
# 第4轮 - 此时第1轮的对话已被遗忘
conversation.invoke("我第一个问题问的什么?")
# AI回答不出来,因为只记得最近2轮
3.5.3 摘要记忆
from langchain.memory import ConversationSummaryMemory
# 自动总结历史对话,节省token
memory = ConversationSummaryMemory(llm=chat)
conversation = ConversationChain(
llm=chat,
memory=memory
)
# 长对话后
memory.save_context(
{"input": "介绍一下Spring框架"},
{"output": "Spring是一个Java企业级应用框架...(很长的回答)"}
)
# 记忆会自动总结
print(memory.buffer)
# 输出:用户询问了Spring框架,助手进行了详细介绍。
3.6 Agents(智能体)
Agents是LangChain的高级特性,能够自主决策使用哪些工具。
3.6.1 基础Agent
from langchain.agents import create_react_agent, AgentExecutor
from langchain import hub
# 获取ReAct提示模板
prompt = hub.pull("hwchase17/react")
# 创建Agent
agent = create_react_agent(
llm=chat,
tools=tools, # 工具列表
prompt=prompt
)
# 创建执行器
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True # 显示思考过程
)
# 运行
result = agent_executor.invoke(
{"input": "北京明天天气怎么样?如果下雨提醒我带伞"}
)
执行流程:
用户:北京明天天气怎么样?如果下雨提醒我带伞
Agent思考:
Thought: 我需要先查询北京明天的天气
Action: search_weather
Action Input: {"city": "北京", "date": "明天"}
工具返回:
Observation: 北京明天小雨,15-22℃
Agent思考:
Thought: 天气预报显示会下雨,我应该提醒用户带伞
Action: send_reminder
Action Input: {"message": "明天北京有雨,记得带伞"}
工具返回:
Observation: 提醒已设置
Agent思考:
Thought: 我已经完成了任务
Final Answer: 北京明天有小雨,气温15-22℃。我已为你设置提醒:明天记得带伞。
3.6.2 Agent类型
# 1. Zero-shot ReAct - 最常用
from langchain.agents import create_react_agent
# 2. Conversational - 带记忆的对话Agent
from langchain.agents import create_conversational_agent
# 3. OpenAI Functions - 利用OpenAI的函数调用
from langchain.agents import create_openai_functions_agent
# 4. Structured Chat - 处理结构化输入
from langchain.agents import create_structured_chat_agent
3.7 Tools(工具)
Tools是Agent可以调用的外部功能。
3.7.1 内置工具
from langchain_community.tools import WikipediaQueryRun
from langchain_community.tools import DuckDuckGoSearchRun
# Wikipedia工具
wikipedia = WikipediaQueryRun()
result = wikipedia.run("Python programming language")
# 搜索工具
search = DuckDuckGoSearchRun()
result = search.run("最新的AI新闻")
3.7.2 自定义工具
from langchain.tools import tool
# 方式1:使用@tool装饰器
@tool
def calculate_sum(a: int, b: int) -> int:
"""计算两数之和"""
return a + b
# 方式2:继承BaseTool
from langchain.tools import BaseTool
from typing import Optional
class WeatherTool(BaseTool):
name = "weather"
description = "获取城市天气"
def _run(self, city: str) -> str:
# 实际调用天气API
return f"{city}的天气是晴天"
async def _arun(self, city: str) -> str:
# 异步版本
raise NotImplementedError()
# 使用
weather_tool = WeatherTool()
result = weather_tool.run("北京")
Java对比:
// 类似Java的@Component和策略模式
@Component
public class WeatherTool implements Tool {
@Override
public String getName() {
return "weather";
}
@Override
public String execute(String input) {
// 实现逻辑
return "晴天";
}
}
本章小结:
我们学习了LangChain的核心组件:
- Models:与LLM交互的抽象层(类似JDBC)
- Prompts:提示词模板(类似SQL模板)
- Chains:组件组合和工作流(类似Stream API)
- Memory:对话记忆管理(类似Session)
- Agents:智能决策引擎(类似智能路由)
- Tools:外部功能集成(类似Service组件)
掌握这些概念后,你就能理解LangChain是如何工作的了。下一章我们将深入LCEL,这是LangChain最强大的特性之一!
第四章:LCEL深入解析
4.1 什么是LCEL
LCEL(LangChain Expression Language)是LangChain的表达式语言,它让你用声明式的方式组合组件,而不是命令式编程。
一句话理解: LCEL就像Java的Stream API,用|(管道操作符)连接各个处理步骤。
# 传统方式(命令式)
prompt_value = prompt.format(topic="Python")
message = model.invoke(prompt_value)
output = parser.parse(message)
# LCEL方式(声明式)
chain = prompt | model | parser
output = chain.invoke({"topic": "Python"})
对比Java Stream:
// Java Stream
List<String> result = list.stream()
.filter(s -> s.length() > 3)
.map(String::toUpperCase)
.collect(Collectors.toList());
// LangChain LCEL
chain = prompt | model | parser
result = chain.invoke(input)
LCEL的核心优势
- 简洁性:用
|连接,一目了然 - 组合性:组件可以自由组合
- 流式支持:自动支持stream()
- 并行执行:自动并行处理
- 异步支持:天然支持async
- 可观测性:自动集成LangSmith追踪
4.2 LCEL核心语法
4.2.1 基础管道
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 创建组件
prompt = ChatPromptTemplate.from_template("给{topic}写一首诗")
model = ChatOpenAI()
parser = StrOutputParser()
# 组合成链
chain = prompt | model | parser
# 调用
result = chain.invoke({"topic": "春天"})
print(result)
# 流式输出
for chunk in chain.stream({"topic": "春天"}):
print(chunk, end="", flush=True)
# 批量处理
results = chain.batch([
{"topic": "春天"},
{"topic": "夏天"},
{"topic": "秋天"}
])
4.2.2 RunnablePassthrough(数据传递)
from langchain_core.runnables import RunnablePassthrough
# 场景:需要在链中传递原始输入
chain = (
{
"context": retriever, # 检索相关文档
"question": RunnablePassthrough() # 直接传递问题
}
| prompt
| model
| parser
)
# 相当于
def process(question):
context = retriever.invoke(question)
return prompt.invoke({
"context": context,
"question": question # 保持原始问题
})
Java理解:
// 类似Function.identity()
Function<String, String> passthrough = Function.identity();
// 或者
map(item -> {
return Map.of(
"context", retriever.apply(item),
"original", item // 保持原始值
);
})
4.2.3 RunnableParallel(并行执行)
from langchain_core.runnables import RunnableParallel
# 并行调用多个链
chain = RunnableParallel(
joke=prompt1 | model | parser, # 生成笑话
poem=prompt2 | model | parser, # 生成诗歌
story=prompt3 | model | parser # 生成故事
)
result = chain.invoke({"topic": "程序员"})
# 结果:{'joke': '...', 'poem': '...', 'story': '...'}
对比Java CompletableFuture:
CompletableFuture<String> joke = CompletableFuture.supplyAsync(() -> generateJoke());
CompletableFuture<String> poem = CompletableFuture.supplyAsync(() -> generatePoem());
CompletableFuture<String> story = CompletableFuture.supplyAsync(() -> generateStory());
CompletableFuture.allOf(joke, poem, story).join();
4.2.4 RunnableLambda(自定义逻辑)
from langchain_core.runnables import RunnableLambda
# 自定义处理函数
def length_function(text):
return len(text)
def multiply_by_two(x):
return x * 2
# 组合到链中
chain = (
prompt
| model
| parser
| RunnableLambda(length_function) # 计算长度
| RunnableLambda(multiply_by_two) # 乘以2
)
result = chain.invoke({"topic": "AI"})
Java对比:
// 类似Java的Function
Function<String, Integer> lengthFunction = String::length;
Function<Integer, Integer> multiplyByTwo = x -> x * 2;
int result = Stream.of("text")
.map(lengthFunction)
.map(multiplyByTwo)
.findFirst()
.get();
4.3 LCEL vs 传统Chain
对比示例
# ===== 传统Chain方式 =====
from langchain.chains import LLMChain
chain = LLMChain(
llm=model,
prompt=prompt,
output_parser=parser
)
result = chain.run(topic="Python")
# ===== LCEL方式 =====
chain = prompt | model | parser
result = chain.invoke({"topic": "Python"})
功能对比
| 特性 | 传统Chain | LCEL |
|---|---|---|
| 语法 | 类和配置 | 管道操作符 |
| 可读性 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 灵活性 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 流式支持 | 需手动实现 | 自动支持 |
| 并行执行 | 需手动实现 | 自动支持 |
| 异步支持 | 部分支持 | 完全支持 |
| 类型提示 | ⭐⭐ | ⭐⭐⭐⭐ |
| 调试追踪 | 需配置 | 自动集成 |
推荐:
- 新项目:优先使用LCEL
- 老项目:逐步迁移到LCEL
- 简单场景:LCEL更简洁
- 复杂场景:LCEL更灵活
4.4 LCEL高级特性
4.4.1 条件分支(RunnableBranch)
from langchain_core.runnables import RunnableBranch
# 根据条件选择不同的处理路径
branch = RunnableBranch(
(
lambda x: "code" in x["topic"].lower(),
prompt_code | model | parser # 代码相关
),
(
lambda x: "math" in x["topic"].lower(),
prompt_math | model | parser # 数学相关
),
prompt_general | model | parser # 默认
)
result = branch.invoke({"topic": "Python code"})
Java对比:
// 类似switch或if-else
Function<Input, Output> branch = input -> {
if (input.topic.contains("code")) {
return processCode(input);
} else if (input.topic.contains("math")) {
return processMath(input);
} else {
return processGeneral(input);
}
};
4.4.2 错误处理(Fallback)
from langchain_core.runnables import RunnableFallback
# 主链失败时使用备用链
primary_chain = prompt | expensive_model | parser
fallback_chain = prompt | cheap_model | parser
chain = primary_chain.with_fallbacks([fallback_chain])
# 如果expensive_model失败,自动使用cheap_model
result = chain.invoke({"topic": "AI"})
Java对比:
// 类似try-catch或Optional.orElse
try {
return primaryChain.process(input);
} catch (Exception e) {
return fallbackChain.process(input);
}
4.4.3 重试机制
# 自动重试
chain_with_retry = (prompt | model | parser).with_retry(
stop_after_attempt=3, # 最多重试3次
wait_exponential_jitter=True # 指数退避
)
result = chain_with_retry.invoke({"topic": "AI"})
4.4.4 配置运行时参数
# 定义可配置的链
configurable_chain = (
prompt
| model.configurable_fields(
temperature=ConfigurableField(
id="temperature",
name="LLM Temperature",
description="The temperature of the LLM"
)
)
| parser
)
# 使用不同配置
result1 = configurable_chain.invoke(
{"topic": "AI"},
config={"configurable": {"temperature": 0.9}}
)
result2 = configurable_chain.invoke(
{"topic": "AI"},
config={"configurable": {"temperature": 0.1}}
)
4.4.5 复杂RAG链示例
from langchain_core.runnables import RunnablePassthrough
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 1. 准备组件
vectorstore = Chroma(embedding_function=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
prompt = ChatPromptTemplate.from_template("""
根据以下上下文回答问题:
上下文:{context}
问题:{question}
答案:
""")
# 2. 构建链
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{
"context": retriever | format_docs,
"question": RunnablePassthrough()
}
| prompt
| model
| StrOutputParser()
)
# 3. 使用
answer = rag_chain.invoke("LangChain是什么?")
print(answer)
完整流程: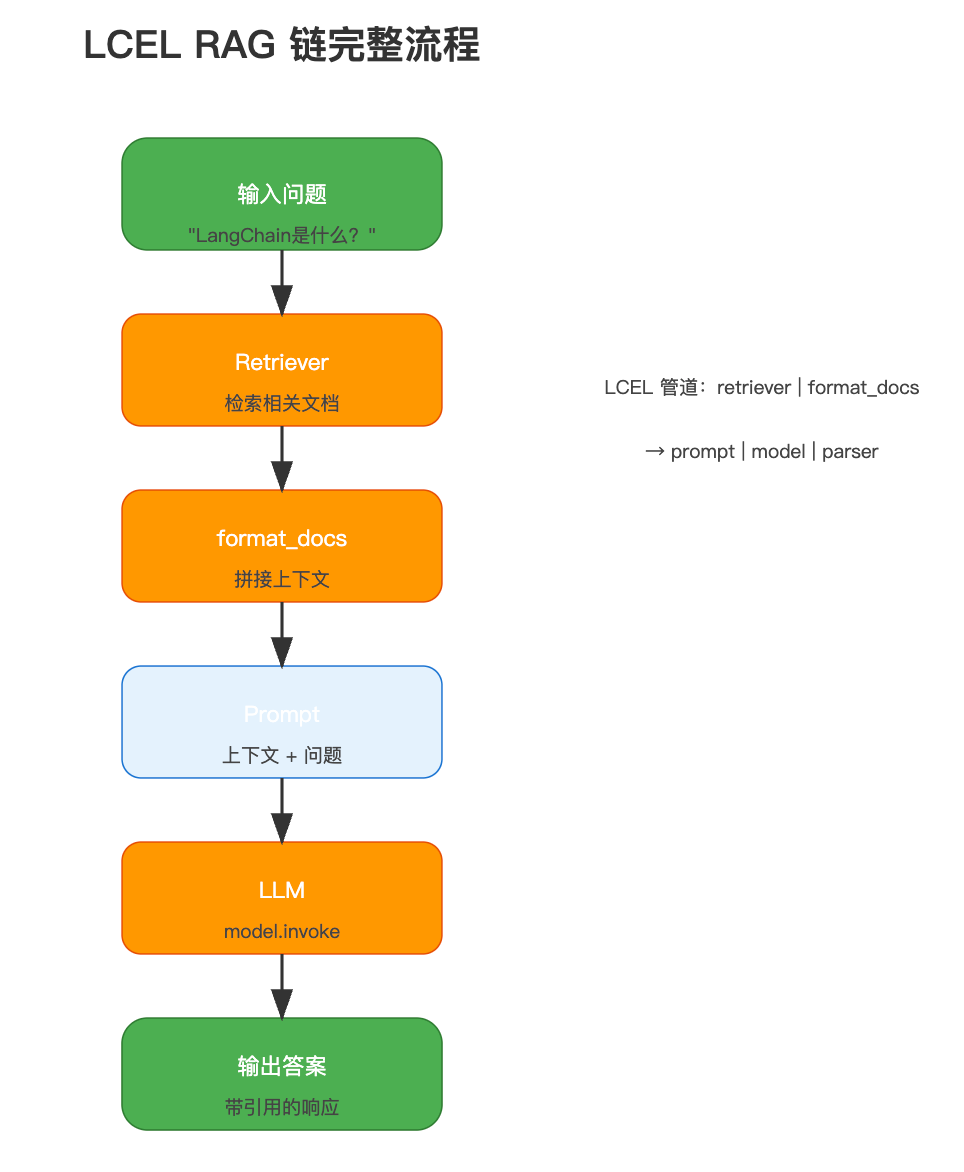
本章小结:
LCEL是LangChain的核心创新,它让链的构建变得:
- 更简洁:用
|替代复杂的类和配置 - 更强大:自动支持流式、并行、异步
- 更灵活:组件可以自由组合
- 更易调试:自动集成追踪
掌握LCEL后,你就能快速构建复杂的AI应用了!下一章我们将通过RAG实战,把LCEL应用到实际场景中。
第五章:RAG实战
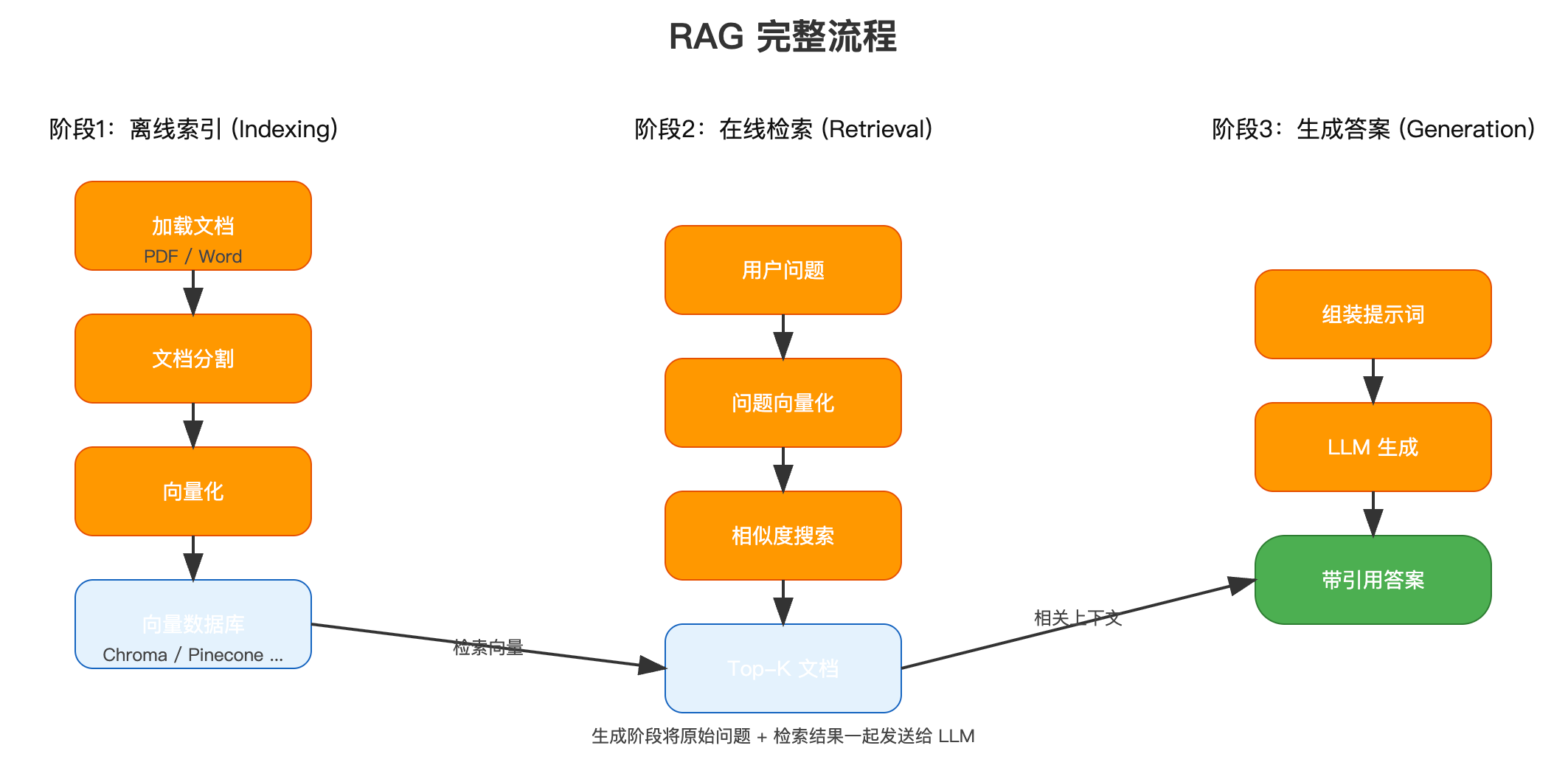
5.1 RAG基础概念
RAG(Retrieval-Augmented Generation,检索增强生成)是让LLM能够访问外部知识库的技术。
为什么需要RAG?
# ❌ 没有RAG - LLM只能靠训练数据
user: "我们公司2024年Q4的销售额是多少?"
llm: "抱歉,我不知道你们公司的财务数据。"
# ✅ 有了RAG - LLM可以查询文档
user: "我们公司2024年Q4的销售额是多少?"
rag_system:
1. 检索: 找到"2024_Q4_财报.pdf"
2. 提取: "Q4销售额:3.2亿元"
3. 生成: "根据2024年Q4财报,销售额为3.2亿元,同比增长15%。"
RAG工作流程
5.2 文档加载和处理
5.2.1 加载不同格式的文档
from langchain_community.document_loaders import (
PyPDFLoader,
TextLoader,
UnstructuredWordDocumentLoader,
UnstructuredMarkdownLoader,
CSVLoader
)
# PDF文档
pdf_loader = PyPDFLoader("docs/handbook.pdf")
pdf_docs = pdf_loader.load()
# 文本文件
txt_loader = TextLoader("docs/readme.txt")
txt_docs = txt_loader.load()
# Word文档
word_loader = UnstructuredWordDocumentLoader("docs/report.docx")
word_docs = word_loader.load()
# Markdown
md_loader = UnstructuredMarkdownLoader("docs/guide.md")
md_docs = md_loader.load()
# CSV
csv_loader = CSVLoader("data/sales.csv")
csv_docs = csv_loader.load()
# 查看文档结构
print(pdf_docs[0])
# Document(
# page_content="这是文档内容...",
# metadata={'source': 'docs/handbook.pdf', 'page': 0}
# )
Java对比:
// 类似Apache POI和其他文档解析库
PDDocument pdf = PDDocument.load(new File("handbook.pdf"));
PDFTextStripper stripper = new PDFTextStripper();
String text = stripper.getText(pdf);
5.2.2 文档分割(Chunking)
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
CharacterTextSplitter,
TokenTextSplitter
)
# 方式1: 递归字符分割(推荐)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个chunk的大小
chunk_overlap=200, # chunk之间的重叠
length_function=len, # 计算长度的函数
separators=["\n\n", "\n", " ", ""] # 分隔符优先级
)
chunks = text_splitter.split_documents(pdf_docs)
# 方式2: 按token分割
token_splitter = TokenTextSplitter(
chunk_size=500,
chunk_overlap=50
)
# 方式3: 按字符分割
char_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=1000,
chunk_overlap=200
)
# 查看分割结果
for i, chunk in enumerate(chunks[:3]):
print(f"Chunk {i}:")
print(chunk.page_content[:200])
print(f"Metadata: {chunk.metadata}")
print("-" * 50)
分割策略建议:
| 文档类型 | 推荐chunk_size | 推荐overlap | 说明 |
|---|---|---|---|
| 技术文档 | 800-1200 | 150-200 | 保持概念完整 |
| 法律文档 | 1000-1500 | 200-300 | 保持条款完整 |
| 聊天记录 | 500-800 | 100 | 保持对话连贯 |
| 代码文档 | 600-1000 | 100 | 保持函数完整 |
5.2.3 文档元数据增强
# 为每个chunk添加元数据
for chunk in chunks:
chunk.metadata["doc_type"] = "handbook"
chunk.metadata["department"] = "HR"
chunk.metadata["created_at"] = "2024-01-01"
# 添加chunk摘要
chunk.metadata["summary"] = generate_summary(chunk.page_content)
5.3 向量存储
5.3.1 Chroma(推荐入门)
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 创建embedding模型
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small"
)
# 创建向量存储
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db" # 持久化目录
)
# 相似度搜索
query = "公司的年假政策是什么?"
results = vectorstore.similarity_search(query, k=3)
for doc in results:
print(doc.page_content)
print("-" * 50)
# 带分数的搜索
results_with_scores = vectorstore.similarity_search_with_score(query, k=3)
for doc, score in results_with_scores:
print(f"Score: {score}")
print(doc.page_content[:200])
print("-" * 50)
5.3.2 FAISS(高性能)
from langchain_community.vectorstores import FAISS
# 创建FAISS索引
vectorstore = FAISS.from_documents(
documents=chunks,
embedding=embeddings
)
# 保存索引
vectorstore.save_local("faiss_index")
# 加载索引
loaded_vectorstore = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True
)
# MMR搜索(最大边际相关性,避免结果重复)
results = vectorstore.max_marginal_relevance_search(
query,
k=5,
fetch_k=20 # 先取20个候选,再选5个最多样的
)
5.3.3 向量库对比
| 向量库 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Chroma | 开发/原型 | 简单、开箱即用 | 性能一般 |
| FAISS | 生产环境 | 性能强、Facebook出品 | 需要自己管理元数据 |
| Pinecone | 云服务 | 无需运维、可扩展 | 收费 |
| Weaviate | 企业级 | 功能全、GraphQL | 复杂 |
| Milvus | 大规模 | 分布式、高性能 | 部署复杂 |
Java程序员理解:
// 向量存储类似缓存或数据库
// Chroma = H2Database (内嵌、开发用)
// FAISS = Caffeine (高性能、本地)
// Pinecone = Redis Cloud (云服务)
// Milvus = Elasticsearch (分布式、企业级)
5.4 构建完整RAG应用
5.4.1 基础RAG链
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 1. 加载文档
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader("./docs", glob="**/*.pdf")
docs = loader.load()
# 2. 分割文档
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(docs)
# 3. 创建向量存储
vectorstore = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings()
)
# 4. 创建检索器
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)
# 5. 创建提示模板
template = """
你是一个问答助手。基于以下上下文回答问题。
如果不知道答案,就说"我不知道",不要编造答案。
上下文:
{context}
问题:{question}
答案:
"""
prompt = ChatPromptTemplate.from_template(template)
# 6. 创建LLM
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# 7. 辅助函数
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 8. 构建RAG链(使用LCEL)
rag_chain = (
{
"context": retriever | format_docs,
"question": RunnablePassthrough()
}
| prompt
| llm
| StrOutputParser()
)
# 9. 使用
question = "公司的远程工作政策是什么?"
answer = rag_chain.invoke(question)
print(answer)
# 流式输出
for chunk in rag_chain.stream(question):
print(chunk, end="", flush=True)
Java对比整体流程:
// 类似以下Java代码的逻辑
public class RAGService {
private VectorStore vectorStore;
private LLM llm;
public String answer(String question) {
// 1. 检索相关文档
List<Document> docs = vectorStore.search(question, 5);
// 2. 格式化上下文
String context = docs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n\n"));
// 3. 构建提示
String prompt = String.format(
"上下文:%s\n\n问题:%s\n\n答案:",
context, question
);
// 4. 调用LLM
return llm.generate(prompt);
}
}
5.4.2 带对话历史的RAG
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import MessagesPlaceholder
# 创建记忆
memory = ConversationBufferMemory(
return_messages=True,
memory_key="chat_history"
)
# 带历史的提示模板
contextualize_q_prompt = ChatPromptTemplate.from_messages([
("system", "根据聊天历史和最新问题,重新表述一个独立的问题"),
MessagesPlaceholder("chat_history"),
("human", "{question}")
])
# 重新表述问题的链
contextualize_q_chain = contextualize_q_prompt | llm | StrOutputParser()
# 完整的RAG链
def get_contextualized_question(input_dict):
if input_dict.get("chat_history"):
return contextualize_q_chain
else:
return input_dict["question"]
rag_chain = (
RunnablePassthrough.assign(
context=get_contextualized_question | retriever | format_docs
)
| prompt
| llm
| StrOutputParser()
)
# 对话示例
print(rag_chain.invoke({
"question": "公司有哪些福利?",
"chat_history": []
}))
# 第二轮对话
print(rag_chain.invoke({
"question": "具体有多少天?", # 这里的"具体"指的是上文提到的年假
"chat_history": [
("human", "公司有哪些福利?"),
("ai", "公司提供年假、健康保险等福利...")
]
}))
5.4.3 高级RAG:重排序
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# 基础检索器
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
# 使用LLM提取相关内容
compressor = LLMChainExtractor.from_llm(llm)
# 压缩检索器(重排序)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
# 使用
compressed_docs = compression_retriever.get_relevant_documents(
"公司的年假政策"
)
# 对比
print("原始检索10个文档")
print("压缩后只保留真正相关的内容")
5.4.4 混合检索
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
# 向量检索器(语义搜索)
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# BM25检索器(关键词搜索)
bm25_retriever = BM25Retriever.from_documents(splits)
bm25_retriever.k = 5
# 混合检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.5, 0.5] # 两种方法各占50%权重
)
# 使用
docs = ensemble_retriever.get_relevant_documents("年假政策")
本章小结:
我们学会了构建完整的RAG应用:
- 文档加载:支持PDF、Word、Markdown等格式
- 文档分割:RecursiveCharacterTextSplitter
- 向量存储:Chroma(开发)、FAISS(生产)
- 构建RAG链:使用LCEL优雅组合
- 高级技巧:对话历史、重排序、混合检索
RAG是LangChain最实用的功能,掌握它你就能让LLM访问你的私有数据了!下一章我们将学习Agent,实现更智能的自主决策。
第六章:Agent实战
6.1 Agent基础
Agent是LangChain的高级特性,它能够自主决策使用哪些工具来完成任务。
Agent的工作原理
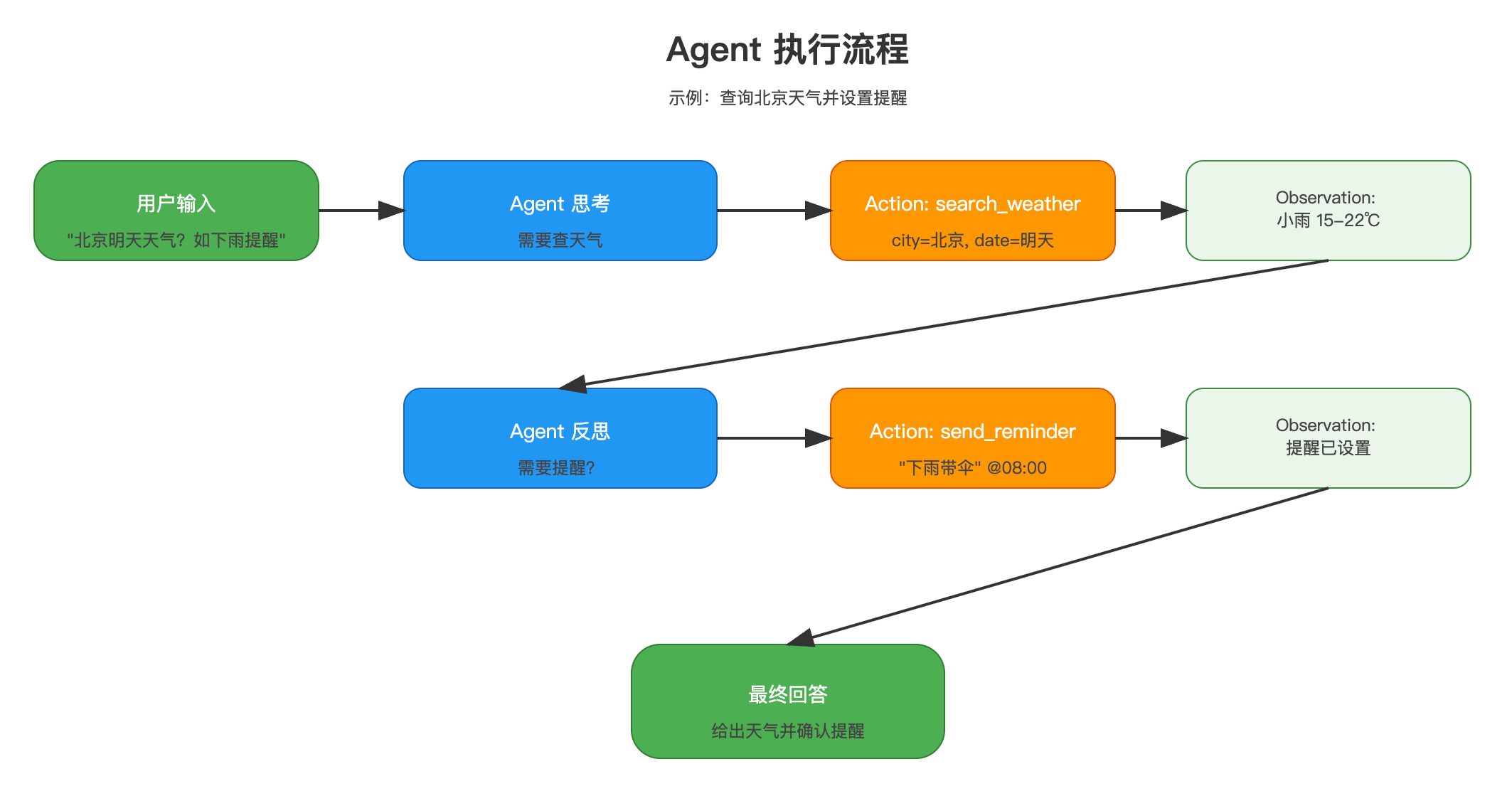
6.2 工具集成
6.2.1 内置工具
from langchain_community.tools import (
WikipediaQueryRun,
DuckDuckGoSearchRun,
PythonREPLTool
)
from langchain_community.utilities import WikipediaAPIWrapper
# Wikipedia工具
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
result = wikipedia.run("LangChain")
print(result)
# 搜索工具
search = DuckDuckGoSearchRun()
result = search.run("最新AI新闻")
print(result)
# Python执行工具(谨慎使用!)
python_repl = PythonREPLTool()
result = python_repl.run("print(1 + 1)")
6.2.2 自定义工具
from langchain.tools import tool
from typing import Optional
# 方式1:使用@tool装饰器(推荐)
@tool
def search_database(query: str) -> str:
"""在数据库中搜索信息"""
# 实际的数据库查询逻辑
results = db.query(f"SELECT * FROM users WHERE name LIKE '%{query}%'")
return f"找到{len(results)}条记录"
@tool
def send_email(to: str, subject: str, body: str) -> str:
"""发送邮件"""
# 实际的邮件发送逻辑
email_service.send(to, subject, body)
return f"邮件已发送到{to}"
# 方式2:继承BaseTool
from langchain.tools import BaseTool
class WeatherTool(BaseTool):
name = "weather"
description = "获取指定城市的天气信息。输入:城市名称"
def _run(self, city: str) -> str:
"""同步执行"""
# 调用天气API
weather_data = weather_api.get_weather(city)
return f"{city}的天气:{weather_data['condition']},温度{weather_data['temp']}℃"
async def _arun(self, city: str) -> str:
"""异步执行"""
# 异步调用天气API
weather_data = await weather_api.get_weather_async(city)
return f"{city}的天气:{weather_data['condition']},温度{weather_data['temp']}℃"
# 使用自定义工具
weather_tool = WeatherTool()
Java对比:
// 类似策略模式和@Component
public interface Tool {
String getName();
String getDescription();
String execute(String input);
}
@Component
public class WeatherTool implements Tool {
@Override
public String execute(String city) {
// 实现逻辑
return "晴天";
}
}
6.3 Agent类型
6.3.1 ReAct Agent(推荐)
ReAct = Reasoning + Acting(推理 + 行动)
from langchain.agents import create_react_agent, AgentExecutor
from langchain_openai import ChatOpenAI
from langchain import hub
# 1. 创建工具列表
tools = [
WeatherTool(),
search_database,
send_email
]
# 2. 创建LLM
llm = ChatOpenAI(temperature=0)
# 3. 获取ReAct提示模板
prompt = hub.pull("hwchase17/react")
# 4. 创建Agent
agent = create_react_agent(
llm=llm,
tools=tools,
prompt=prompt
)
# 5. 创建Agent执行器
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 显示思考过程
max_iterations=5, # 最大迭代次数
handle_parsing_errors=True # 处理解析错误
)
# 6. 运行
result = agent_executor.invoke({
"input": "查询北京天气,如果下雨就发邮件给zhang@example.com提醒带伞"
})
print(result["output"])
执行日志:
> Entering new AgentExecutor chain...
Thought: 我需要先查询北京的天气
Action: weather
Action Input: 北京
Observation: 北京的天气:小雨,温度18℃
Thought: 天气预报显示有雨,我需要发送提醒邮件
Action: send_email
Action Input: {"to": "zhang@example.com", "subject": "天气提醒", "body": "明天北京有雨,记得带伞"}
Observation: 邮件已发送到zhang@example.com
Thought: 我已经完成了任务
Final Answer: 北京明天有小雨,温度18℃。我已经发送邮件提醒zhang@example.com带伞。
> Finished chain.
6.3.2 Structured Chat Agent
处理结构化输入输出。
from langchain.agents import create_structured_chat_agent
# 适合需要结构化输入的工具
@tool
def book_flight(
origin: str,
destination: str,
date: str,
passengers: int
) -> str:
"""预订航班"""
return f"已预订{origin}到{destination}的航班,日期{date},乘客{passengers}人"
tools = [book_flight]
agent = create_structured_chat_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
result = agent_executor.invoke({
"input": "帮我订从北京到上海的机票,12月25日,2个人"
})
6.3.3 OpenAI Functions Agent
利用OpenAI的函数调用特性(最推荐)。
from langchain.agents import create_openai_functions_agent
from langchain_openai import ChatOpenAI
# 只适用于OpenAI模型
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
tools = [
weather_tool,
search_database,
send_email
]
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
为什么推荐OpenAI Functions:
- 更可靠的工具调用
- 更好的结构化输出
- 减少解析错误
- 原生支持多参数
6.4 实战案例
6.4.1 智能客服Agent
from langchain.tools import tool
from langchain.agents import create_react_agent, AgentExecutor
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# 定义工具
@tool
def query_order(order_id: str) -> str:
"""查询订单状态"""
# 模拟数据库查询
orders = {
"ORD001": "已发货,预计明天送达",
"ORD002": "正在配送中"
}
return orders.get(order_id, "订单不存在")
@tool
def查询FAQ(question: str) -> str:
"""查询常见问题"""
faqs = {
"退货": "30天内可无理由退货",
"保修": "产品保修期为1年"
}
for key, value in faqs.items():
if key in question:
return value
return "未找到相关FAQ"
@tool
def create_ticket(description: str, contact: str) -> str:
"""创建工单转人工"""
ticket_id = f"TKT{random.randint(1000, 9999)}"
return f"工单{ticket_id}已创建,客服将在30分钟内联系您"
# 创建Agent
tools = [query_order, 查询FAQ, create_ticket]
llm = ChatOpenAI(temperature=0)
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个专业的客服助手。你的职责是:
1. 友好礼貌地回答用户问题
2. 使用工具查询订单、FAQ等信息
3. 如果无法解决,创建工单转人工
注意:
- 订单查询需要订单号
- 创建工单需要问题描述和联系方式
- 始终保持专业和友好
"""),
("human", "{input}"),
("placeholder", "{agent_scratchpad}")
])
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
max_iterations=5
)
# 对话示例
print(agent_executor.invoke({
"input": "我想查询订单ORD001的状态"
}))
print(agent_executor.invoke({
"input": "你们的退货政策是什么?"
}))
print(agent_executor.invoke({
"input": "我的商品有质量问题,联系方式138xxxx0000"
}))
6.4.2 数据分析Agent
@tool
def execute_sql(query: str) -> str:
"""执行SQL查询(只读)"""
# 安全检查
if any(keyword in query.upper() for keyword in ["DROP", "DELETE", "UPDATE", "INSERT"]):
return "不允许执行写操作"
# 执行查询
result = db.execute(query)
return str(result)
@tool
def plot_chart(data_query: str, chart_type: str) -> str:
"""绘制图表"""
data = db.execute(data_query)
# 生成图表
chart_path = generate_chart(data, chart_type)
return f"图表已生成:{chart_path}"
@tool
def calculate(expression: str) -> str:
"""计算数学表达式"""
try:
result = eval(expression)
return str(result)
except Exception as e:
return f"计算错误:{e}"
# 数据分析Agent
tools = [execute_sql, plot_chart, calculate]
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个数据分析助手。你可以:
1. 执行SQL查询分析数据
2. 绘制图表可视化数据
3. 进行数学计算
示例:
- 用户:"2024年销售额是多少?"
→ 执行SQL: SELECT SUM(amount) FROM sales WHERE year=2024
- 用户:"绘制月度销售趋势图"
→ 先查询数据,再绘制折线图
"""),
("human", "{input}"),
("placeholder", "{agent_scratchpad}")
])
data_agent = create_react_agent(llm, tools, prompt)
data_executor = AgentExecutor(agent=data_agent, tools=tools, verbose=True)
# 使用
result = data_executor.invoke({
"input": "查询2024年总销售额,并与2023年对比,计算增长率"
})
6.4.3 多Agent协作
from langchain.agents import AgentExecutor, create_react_agent
# Agent 1: 研究助手
research_tools = [
WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()),
DuckDuckGoSearchRun()
]
research_agent = AgentExecutor(
agent=create_react_agent(llm, research_tools, research_prompt),
tools=research_tools
)
# Agent 2: 写作助手
@tool
def save_to_file(filename: str, content: str) -> str:
"""保存内容到文件"""
with open(filename, 'w') as f:
f.write(content)
return f"已保存到{filename}"
writing_tools = [save_to_file]
writing_agent = AgentExecutor(
agent=create_react_agent(llm, writing_tools, writing_prompt),
tools=writing_tools
)
# 协调者
class MultiAgentCoordinator:
def __init__(self, research_agent, writing_agent):
self.research_agent = research_agent
self.writing_agent = writing_agent
def process(self, task: str):
# 1. 研究阶段
research_result = self.research_agent.invoke({
"input": f"研究以下主题:{task}"
})
# 2. 写作阶段
writing_result = self.writing_agent.invoke({
"input": f"基于以下研究结果,写一篇文章:\n{research_result['output']}"
})
return writing_result
# 使用
coordinator = MultiAgentCoordinator(research_agent, writing_agent)
result = coordinator.process("LangChain的最新发展")
本章小结:
我们学习了Agent的核心概念和实战应用:
- Agent工作原理:推理→行动→观察的循环
- 工具定义:@tool装饰器和BaseTool类
- Agent类型:ReAct、Structured Chat、OpenAI Functions
- 实战案例:客服Agent、数据分析Agent、多Agent协作
Agent是LangChain最强大的功能,它让AI真正具备了自主能力!下一章我们将学习生产级实践,把这些技术应用到真实环境。
第七章:生产级实践
7.1 性能优化
7.1.1 缓存策略
import langchain
from langchain.cache import InMemoryCache, SQLiteCache
# 1. 内存缓存(开发环境)
langchain.llm_cache = InMemoryCache()
# 2. SQLite缓存(持久化)
langchain.llm_cache = SQLiteCache(database_path=".langchain.db")
# 3. Redis缓存(生产环境推荐)
from langchain.cache import RedisCache
import redis
redis_client = redis.Redis(host='localhost', port=6379)
langchain.llm_cache = RedisCache(redis_client)
# 使用(缓存自动生效)
llm = ChatOpenAI()
result1 = llm.invoke("讲个笑话") # 调用API
result2 = llm.invoke("讲个笑话") # 从缓存读取,不调用API
Java对比:
// 类似Spring Cache
@Cacheable(value = "llm-responses", key = "#prompt")
public String generateResponse(String prompt) {
return llm.invoke(prompt);
}
7.1.2 批量处理
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
# 批量调用(并行处理)
prompts = [
"1+1=?",
"2+2=?",
"3+3=?"
]
# 方式1:直接批量
results = llm.batch(prompts)
# 方式2:使用LCEL批量
from langchain_core.prompts import ChatPromptTemplate
chain = ChatPromptTemplate.from_template("{question}") | llm
results = chain.batch([
{"question": "1+1=?"},
{"question": "2+2=?"}
])
7.1.3 异步处理
import asyncio
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
async def process_async():
# 异步调用
result = await llm.ainvoke("讲个笑话")
return result
# 批量异步
async def process_batch_async():
tasks = [
llm.ainvoke("笑话1"),
llm.ainvoke("笑话2"),
llm.ainvoke("笑话3")
]
results = await asyncio.gather(*tasks)
return results
# 运行
result = asyncio.run(process_async())
results = asyncio.run(process_batch_async())
Java对比:
// 类似CompletableFuture
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> llm.invoke("笑话1"));
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> llm.invoke("笑话2"));
CompletableFuture.allOf(future1, future2).join();
7.2 错误处理
7.2.1 重试机制
from langchain_core.runnables import RunnableRetry
# 为链添加重试
chain_with_retry = (prompt | llm | parser).with_retry(
stop_after_attempt=3,
wait_exponential_jitter=True,
retry_if_exception_type=(RateLimitError, Timeout)
)
try:
result = chain_with_retry.invoke({"input": "问题"})
except Exception as e:
print(f"重试3次后仍失败:{e}")
7.2.2 Fallback机制
from langchain_core.runnables import RunnableFallback
# 主链失败时使用备用链
expensive_llm = ChatOpenAI(model="gpt-4")
cheap_llm = ChatOpenAI(model="gpt-3.5-turbo")
primary_chain = prompt | expensive_llm | parser
fallback_chain = prompt | cheap_llm | parser
chain = primary_chain.with_fallbacks([fallback_chain])
# 如果GPT-4失败(如限流),自动降级到GPT-3.5
result = chain.invoke({"input": "问题"})
7.2.3 错误处理最佳实践
from typing import Optional
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class RobustLLMService:
def __init__(self):
self.primary_llm = ChatOpenAI(model="gpt-4")
self.fallback_llm = ChatOpenAI(model="gpt-3.5-turbo")
def generate(self, prompt: str) -> Optional[str]:
try:
# 尝试主模型
result = self.primary_llm.invoke(prompt)
logger.info("使用GPT-4成功")
return result.content
except RateLimitError as e:
logger.warning(f"GPT-4限流,降级到GPT-3.5: {e}")
# 降级到备用模型
try:
result = self.fallback_llm.invoke(prompt)
return result.content
except Exception as e2:
logger.error(f"备用模型也失败:{e2}")
return None
except Exception as e:
logger.error(f"生成失败:{e}")
return None
# 使用
service = RobustLLMService()
result = service.generate("讲个笑话")
if result:
print(result)
else:
print("服务暂时不可用,请稍后重试")
7.3 监控和调试
7.3.1 LangSmith集成
import os
# 配置LangSmith
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "your-api-key"
os.environ["LANGCHAIN_PROJECT"] = "my-project"
# 正常使用,自动追踪
chain = prompt | llm | parser
result = chain.invoke({"input": "问题"})
# 所有调用会自动记录到LangSmith
# 可以在 https://smith.langchain.com 查看
7.3.2 回调函数
from langchain.callbacks import get_openai_callback, StdOutCallbackHandler
# 1. 成本追踪
with get_openai_callback() as cb:
result = chain.invoke({"input": "问题"})
print(f"Token使用:{cb.total_tokens}")
print(f"总成本:${cb.total_cost:.4f}")
# 2. 详细日志
from langchain.callbacks import StdOutCallbackHandler
chain_with_callback = chain.with_config(
callbacks=[StdOutCallbackHandler()]
)
result = chain_with_callback.invoke({"input": "问题"})
# 打印详细执行日志
7.3.3 自定义监控
from langchain.callbacks.base import BaseCallbackHandler
from typing import Any, Dict
class MetricsCollector(BaseCallbackHandler):
def __init__(self):
self.call_count = 0
self.total_tokens = 0
self.errors = 0
def on_llm_start(self, serialized: Dict[str, Any], prompts: list, **kwargs) -> None:
self.call_count += 1
logger.info(f"LLM调用开始 #{self.call_count}")
def on_llm_end(self, response, **kwargs) -> None:
# 记录token使用
if hasattr(response, 'llm_output'):
tokens = response.llm_output.get('token_usage', {})
self.total_tokens += tokens.get('total_tokens', 0)
def on_llm_error(self, error: Exception, **kwargs) -> None:
self.errors += 1
logger.error(f"LLM错误: {error}")
def get_metrics(self):
return {
"total_calls": self.call_count,
"total_tokens": self.total_tokens,
"errors": self.errors,
"avg_tokens_per_call": self.total_tokens / max(self.call_count, 1)
}
# 使用
metrics = MetricsCollector()
chain = (prompt | llm | parser).with_config(
callbacks=[metrics]
)
# 处理多个请求
for question in questions:
chain.invoke({"input": question})
# 查看指标
print(metrics.get_metrics())
7.4 最佳实践
7.4.1 环境变量管理
# .env 文件
"""
OPENAI_API_KEY=sk-...
ANTHROPIC_API_KEY=sk-ant-...
DATABASE_URL=postgresql://...
REDIS_URL=redis://...
"""
# 加载环境变量
from dotenv import load_dotenv
import os
load_dotenv()
# 使用
openai_key = os.getenv("OPENAI_API_KEY")
if not openai_key:
raise ValueError("OPENAI_API_KEY未设置")
llm = ChatOpenAI(api_key=openai_key)
Java对比:
// application.properties
openai.api.key=${OPENAI_API_KEY}
@Value("${openai.api.key}")
private String apiKey;
7.4.2 配置管理
from dataclasses import dataclass
from typing import Optional
@dataclass
class LLMConfig:
"""LLM配置"""
model: str = "gpt-3.5-turbo"
temperature: float = 0.7
max_tokens: int = 2000
timeout: int = 60
max_retries: int = 3
@dataclass
class RAGConfig:
"""RAG配置"""
chunk_size: int = 1000
chunk_overlap: int = 200
retriever_k: int = 5
embedding_model: str = "text-embedding-3-small"
class AppConfig:
"""应用配置"""
def __init__(self):
self.llm = LLMConfig()
self.rag = RAGConfig()
self.environment = os.getenv("ENVIRONMENT", "development")
@property
def is_production(self):
return self.environment == "production"
# 使用
config = AppConfig()
llm = ChatOpenAI(
model=config.llm.model,
temperature=config.llm.temperature,
max_tokens=config.llm.max_tokens
)
7.4.3 日志规范
import logging
from datetime import datetime
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(f'logs/app-{datetime.now().strftime("%Y%m%d")}.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
# 使用
class ProductionRAGService:
def __init__(self):
self.logger = logging.getLogger(self.__class__.__name__)
def answer(self, question: str) -> str:
self.logger.info(f"收到问题:{question[:100]}...")
try:
# 检索
docs = self.retriever.invoke(question)
self.logger.info(f"检索到{len(docs)}个文档")
# 生成答案
answer = self.chain.invoke(question)
self.logger.info(f"生成答案长度:{len(answer)}")
return answer
except Exception as e:
self.logger.error(f"回答失败:{e}", exc_info=True)
raise
7.4.4 单元测试
import pytest
from unittest.mock import Mock, patch
def test_rag_chain():
# 1. Mock LLM响应
mock_llm = Mock()
mock_llm.invoke.return_value = Mock(content="测试答案")
# 2. Mock检索器
mock_retriever = Mock()
mock_retriever.invoke.return_value = [
Mock(page_content="相关文档1"),
Mock(page_content="相关文档2")
]
# 3. 构建链
chain = build_rag_chain(mock_llm, mock_retriever)
# 4. 测试
result = chain.invoke("测试问题")
# 5. 断言
assert result == "测试答案"
mock_retriever.invoke.assert_called_once()
mock_llm.invoke.assert_called_once()
def test_agent_with_tools():
# 测试Agent工具调用
@tool
def mock_tool(input: str) -> str:
return f"处理了:{input}"
tools = [mock_tool]
agent = create_agent(tools)
result = agent.invoke({"input": "测试输入"})
assert "处理了:测试输入" in result["output"]
7.4.5 常见问题FAQ
Q1: Token使用量太大怎么办?
# 解决方案1:减小chunk大小
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 从1000降低到500
chunk_overlap=50
)
# 解决方案2:减少检索数量
retriever = vectorstore.as_retriever(search_kwargs={"k": 3}) # 从5降到3
# 解决方案3:使用更便宜的模型
llm = ChatOpenAI(model="gpt-3.5-turbo") # 而不是gpt-4
Q2: 如何处理超时?
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
timeout=30, # 30秒超时
max_retries=3, # 最多重试3次
request_timeout=30
)
Q3: 如何提高RAG准确性?
# 1. 优化chunk大小
# 2. 增加chunk重叠
# 3. 使用更好的embedding模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 4. 使用重排序
from langchain.retrievers import ContextualCompressionRetriever
# 5. 混合检索
from langchain.retrievers import EnsembleRetriever
本章小结:
生产级实践的关键要点:
- 性能优化:缓存、批量处理、异步
- 错误处理:重试、降级、友好错误
- 监控调试:LangSmith、回调、自定义指标
- 最佳实践:配置管理、日志、测试
总结
恭喜你完成LangChain的学习之旅!让我们回顾关键要点:
核心收获
-
LangChain是什么
- Python AI应用开发框架
- 提供统一API访问LLM和工具
- LCEL让组件组合变得优雅
-
为什么选择LangChain
- 避免重复造轮子
- 丰富的生态系统
- 生产就绪的特性
-
怎么用LangChain
- Models:与LLM交互
- Prompts:提示词模板
- Chains:工作流编排
- Agents:智能决策
- RAG:知识库集成
Java程序员的优势
学完本指南,你已经掌握:
- Python基础语法(对比Java理解)
- LangChain核心概念(映射到Java生态)
- LCEL声明式编程(类似Stream API)
- 生产级实践(熟悉的工程化思维)
学习资源
官方资源:
中文资源:
实战教程:
最后的话:
作为Java程序员,你已经具备了扎实的编程基础和工程化思维。LangChain(Python)和LangChain4j(Java)两者各有优势:
- LangChain:生态最强、迭代最快、学习资源最多
- LangChain4j:技术栈统一、类型安全、Spring集成
我的建议是:两者都学,融会贯通。
用LangChain(Python)快速验证想法和学习最新特性,用LangChain4j(Java)实现稳定的生产应用。这样你就能在AI应用开发领域游刃有余!
现在就开始你的AI之旅吧!🚀

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)