LangChain4j框架实战指南
LangChain4j就像是Java开发者的AI瑞士军刀,它把复杂的AI能力封装成了熟悉的Java API,让传统Java开发者也能快速构建AI应用。
从零到一掌握Java生态的AI应用开发利器
目录
第一章:初识LangChain4j
1.1 什么是LangChain4j
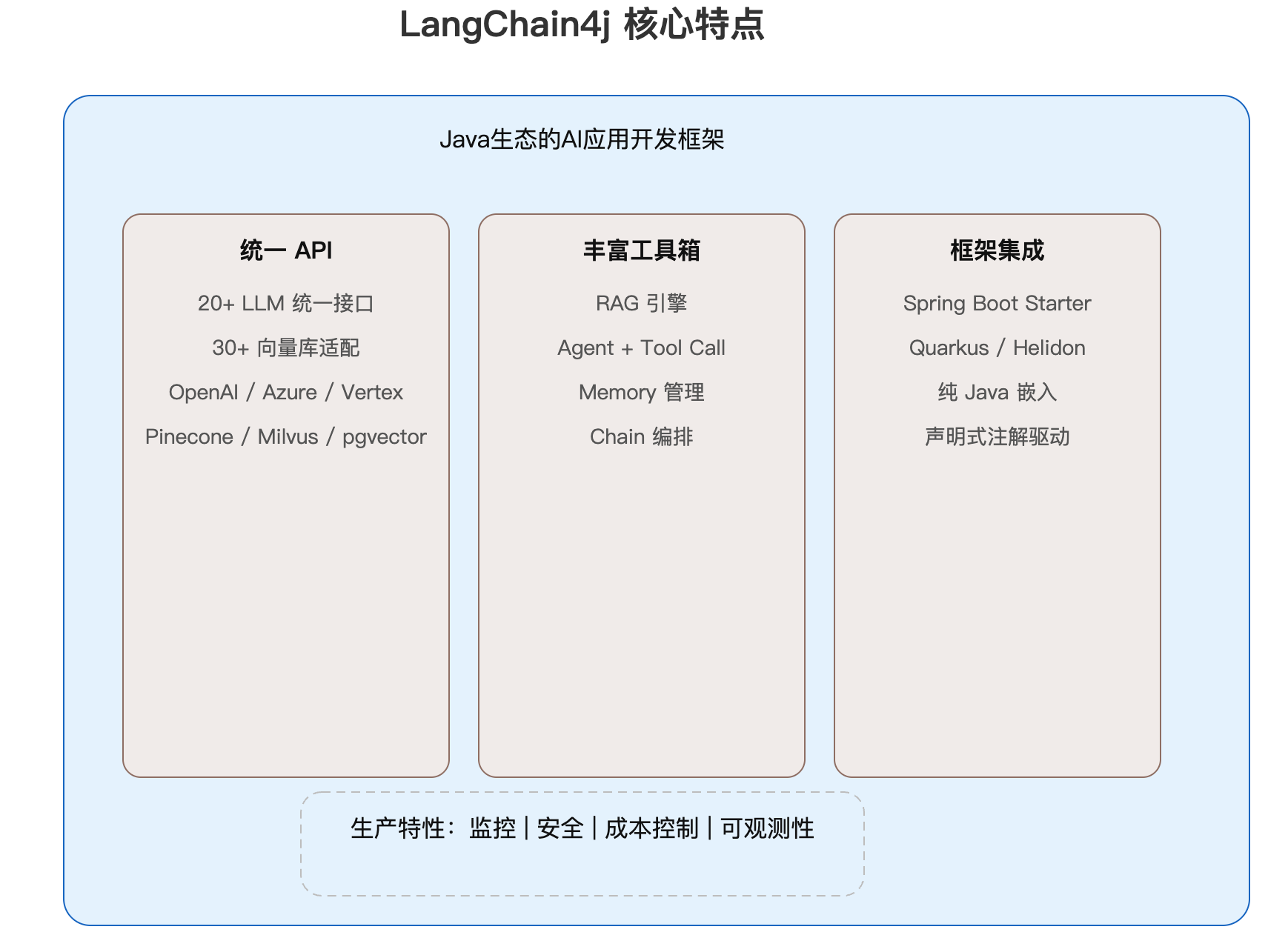
LangChain4j是一个开源的Java库,专为简化大语言模型(LLM)在Java应用中的集成而设计。它提供了统一的API接口,让开发者能够轻松访问多种主流的LLM服务和向量数据库,无需学习每个供应商的专有API。
核心特点:
一句话理解: LangChain4j就像是Java开发者的AI瑞士军刀,它把复杂的AI能力封装成了熟悉的Java API,让传统Java开发者也能快速构建AI应用。
1.2 为什么需要LangChain4j
在LangChain4j出现之前,Java开发者在集成AI能力时面临诸多挑战:
痛点一:碎片化的API
不同的LLM服务商(OpenAI、Google、Azure等)都有自己的SDK和API设计。切换服务商意味着要重写大量代码。
// 没有LangChain4j的情况
// OpenAI的方式
OpenAIClient openAI = new OpenAIClient(apiKey);
OpenAIResponse response = openAI.chat(prompt);
// 切换到Google需要完全重写
VertexAIClient vertexAI = new VertexAIClient(credentials);
VertexAIResponse response = vertexAI.generateText(request);
痛点二:高级功能实现复杂
要实现RAG、Agent、记忆管理等高级功能,需要深入理解AI概念,手动处理文档分割、向量化、检索等复杂流程。
痛点三:缺乏企业级特性
生产环境需要的监控、成本控制、安全防护等特性,需要开发者自己从零实现。
痛点四:Java生态不友好
大多数AI工具和框架都是Python优先,Java开发者只能"二等公民"般地使用各种适配层。
LangChain4j的解决方案:
- 统一抽象:一套API访问所有LLM和向量库
- 开箱即用:内置RAG、Agent、Tool等高级模式
- Java原生:为Java生态量身定制,与Spring、Quarkus无缝集成
- 生产就绪:内置监控、安全、成本控制等企业级特性
1.3 LangChain4j的核心定位
LangChain4j在AI应用开发中的定位可以用三个层次来理解:

三个核心角色:
- 适配器(Adapter):屏蔽底层差异,提供统一接口
- 工具箱(Toolbox):提供RAG、Agent等AI应用常用模式
- 粘合剂(Glue):连接AI能力和Java企业应用
1.4 LangChain4j vs Spring AI
作为Java生态中两个最重要的AI框架,选择LangChain4j还是Spring AI是很多开发者的疑问。
对比表格
| 维度 | LangChain4j | Spring AI |
|---|---|---|
| 定位 | 专业AI工具库 | Spring生态AI集成框架 |
| 功能丰富度 | ⭐⭐⭐⭐⭐ 更全面 | ⭐⭐⭐⭐ 够用 |
| 易用性 | ⭐⭐⭐ 学习曲线稍陡 | ⭐⭐⭐⭐⭐ 声明式API |
| Spring集成 | ⭐⭐⭐⭐ 良好支持 | ⭐⭐⭐⭐⭐ 官方原生 |
| 多框架支持 | ⭐⭐⭐⭐⭐ Spring/Quarkus/纯Java | ⭐⭐⭐ 仅Spring |
| RAG能力 | ⭐⭐⭐⭐⭐ 三种模式 | ⭐⭐⭐ 基础模式 |
| Agent能力 | ⭐⭐⭐⭐⭐ 功能完整 | ⭐⭐⭐ 基础功能 |
| 文档质量 | ⭐⭐⭐ 持续完善中 | ⭐⭐⭐⭐ 官方完善 |
| 社区活跃度 | ⭐⭐⭐⭐ 快速增长 | ⭐⭐⭐⭐ 稳定增长 |
| 成熟度 | ⭐⭐⭐⭐ 1.0已发布 | ⭐⭐⭐⭐ 稳定版本 |
选择建议
选择Spring AI的场景:
- 已有Spring Boot项目,希望快速添加AI功能
- 需求简单,主要是聊天和文本生成
- 团队熟悉Spring生态,学习成本要低
- 开发周期紧,追求快速上线
选择LangChain4j的场景:
- 需要复杂的RAG或Agent功能
- 需要高度定制化的AI工作流
- 使用Quarkus或纯Java项目
- 构建专业的AI应用,对功能要求高
实际案例对比:
// Spring AI - 简洁的聊天功能
@RestController
public class ChatController {
@Autowired
private ChatClient chatClient;
@GetMapping("/chat")
public String chat(String message) {
return chatClient.call(message);
}
}
// LangChain4j - 带工具的Agent
interface Assistant {
@SystemMessage("You are a helpful assistant with access to weather data")
String chat(@UserMessage String message);
}
@Service
public class AssistantService {
@Tool("Get weather for a city")
public String getWeather(String city) {
// 实际获取天气逻辑
return "Sunny, 25°C";
}
private final Assistant assistant;
public AssistantService(ChatLanguageModel model) {
this.assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
.tools(this)
.build();
}
}
我的建议:
- 快速原型 + 简单需求 → Spring AI
- 生产级 + 复杂场景 → LangChain4j
- 两者结合 → Spring项目中引入LangChain4j(完全兼容)
第二章:核心概念与架构
2.1 整体架构设计
LangChain4j采用了分层的架构设计,每一层都有明确的职责: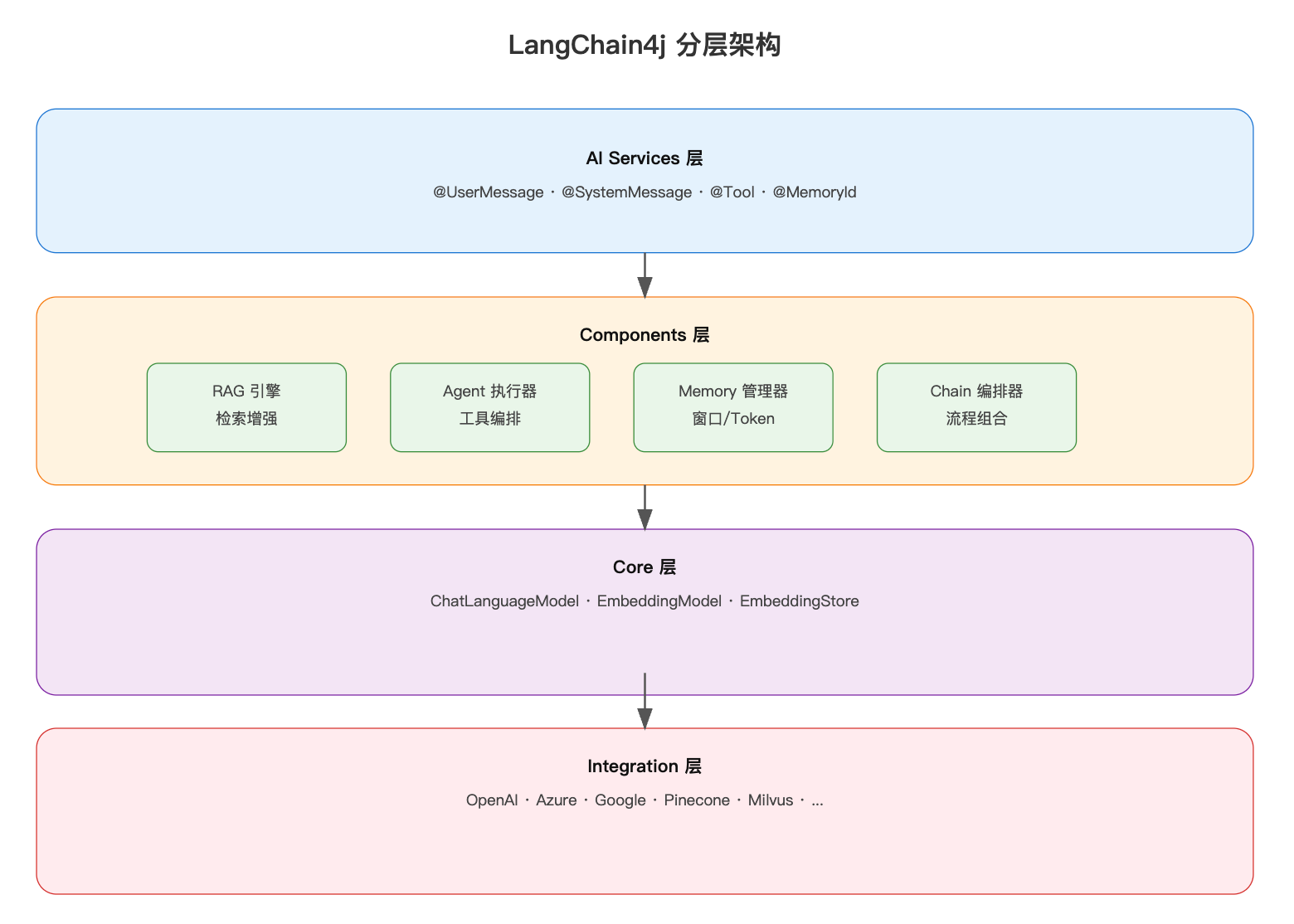
设计理念:
- 接口与实现分离:核心层定义统一接口,集成层提供具体实现
- 组件化设计:每个组件职责单一,可以独立使用或组合
- 声明式编程:通过注解和接口定义,简化开发
- 可插拔架构:轻松切换LLM、向量库等底层服务
2.2 核心组件详解
2.2.1 ChatLanguageModel - 对话模型
这是与LLM交互的核心接口,所有的文本生成都通过它完成。
public interface ChatLanguageModel {
Response<AiMessage> generate(List<ChatMessage> messages);
}
关键概念:
- ChatMessage:消息抽象,包括SystemMessage、UserMessage、AiMessage、ToolExecutionResultMessage
- Response:响应包装,包含生成的消息、token使用情况、完成原因等元数据
实际使用:
// 1. 创建模型实例
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName("gpt-4")
.temperature(0.7)
.build();
// 2. 构建消息
List<ChatMessage> messages = List.of(
new SystemMessage("你是一个Java专家"),
new UserMessage("解释什么是JVM")
);
// 3. 生成响应
Response<AiMessage> response = model.generate(messages);
String answer = response.content().text();
2.2.2 EmbeddingModel & EmbeddingStore - 向量化
向量化是RAG的基础,EmbeddingModel负责将文本转换为向量,EmbeddingStore负责存储和检索。
文本 → EmbeddingModel → 向量 → EmbeddingStore → 检索
"Java是一种..." → [0.1, 0.5, ...] → 数据库 → 相似度搜索
代码示例:
// 1. 创建嵌入模型
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey(apiKey)
.modelName("text-embedding-ada-002")
.build();
// 2. 文本向量化
Embedding embedding = embeddingModel.embed("LangChain4j是什么").content();
// 3. 存储到向量数据库
EmbeddingStore<TextSegment> embeddingStore =
new InMemoryEmbeddingStore<>(); // 或 Pinecone、Milvus等
String id = embeddingStore.add(embedding,
new TextSegment("LangChain4j是一个Java AI框架"));
// 4. 相似度检索
List<EmbeddingMatch<TextSegment>> matches =
embeddingStore.findRelevant(queryEmbedding, 5);
2.2.3 AI Services - 高级抽象
这是LangChain4j最强大的特性之一,通过接口和注解就能定义AI能力。
interface Chef {
@SystemMessage("你是一位米其林三星主厨")
String recommendDish(@UserMessage String ingredients);
}
// 自动实现
Chef chef = AiServices.create(Chef.class, model);
String dish = chef.recommendDish("鸡蛋、番茄、米饭");
支持的注解:
@SystemMessage:系统提示词@UserMessage:用户消息模板@V:变量注入@Tool:工具函数@MemoryId:会话隔离
2.2.4 Document & DocumentParser - 文档处理
RAG的第一步是处理文档,LangChain4j支持多种格式。
// 解析PDF
Document document = FileSystemDocumentLoader.loadDocument(
"/path/to/file.pdf",
new ApachePdfBoxDocumentParser()
);
// 文档分割
DocumentSplitter splitter = DocumentSplitters.recursive(
300, // 每段最大长度
20 // 重叠长度
);
List<TextSegment> segments = splitter.split(document);
支持的格式:
- PDF(Apache PDFBox)
- Word(Apache POI)
- TXT、MD、HTML
- JSON、XML
2.2.5 ChatMemory - 对话记忆
让AI记住上下文的关键组件。
// 消息窗口记忆 - 保留最近N条消息
ChatMemory memory = MessageWindowChatMemory.withMaxMessages(10);
// 令牌窗口记忆 - 保留最近N个token
ChatMemory memory = TokenWindowChatMemory.builder()
.maxTokens(1000)
.tokenizer(new OpenAiTokenizer())
.build();
2.3 支持的能力矩阵
LLM提供商(20+)
| 提供商 | 模块名 | 支持模型 |
|---|---|---|
| OpenAI | langchain4j-open-ai | GPT-4, GPT-3.5-turbo |
| Azure OpenAI | langchain4j-azure-open-ai | 所有Azure部署 |
| langchain4j-vertex-ai | Gemini, PaLM | |
| Anthropic | langchain4j-anthropic | Claude系列 |
| Amazon | langchain4j-bedrock | Titan, Claude等 |
| 本地模型 | langchain4j-ollama | Llama, Mistral等 |
| 国产模型 | langchain4j-qianfan | 文心一言 |
| langchain4j-dashscope | 通义千问 |
向量数据库(30+)
| 类型 | 数据库 | 适用场景 |
|---|---|---|
| 云服务 | Pinecone, Weaviate | 生产环境,无需运维 |
| 自托管 | Milvus, Qdrant | 数据敏感,完全控制 |
| 关系型 | PostgreSQL(pgvector) | 已有PG,统一技术栈 |
| 文档型 | MongoDB Atlas | 已有MongoDB |
| 内存型 | In-Memory | 开发测试,快速原型 |
集成框架
- Spring Boot:通过starter快速集成
- Quarkus:原生支持,云原生优化
- Helidon:轻量级微服务
- 纯Java:无框架依赖
本章小结:
我们了解了LangChain4j的核心架构和组件。记住几个关键点:
- 分层架构:从底层集成到高层抽象,职责清晰
- 核心组件:ChatLanguageModel、EmbeddingModel、AI Services是三大支柱
- 丰富生态:20+ LLM,30+ 向量库,多框架支持
下一章我们将深入RAG技术,这是LangChain4j最强大的功能之一。
第三章:RAG检索增强生成
3.1 RAG基础概念
什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种让LLM能够访问外部知识库的技术。它解决了LLM的两大痛点:
- 知识过时:LLM的训练数据有截止日期,无法获取最新信息
- 幻觉问题:LLM可能会"编造"不存在的事实
RAG工作原理: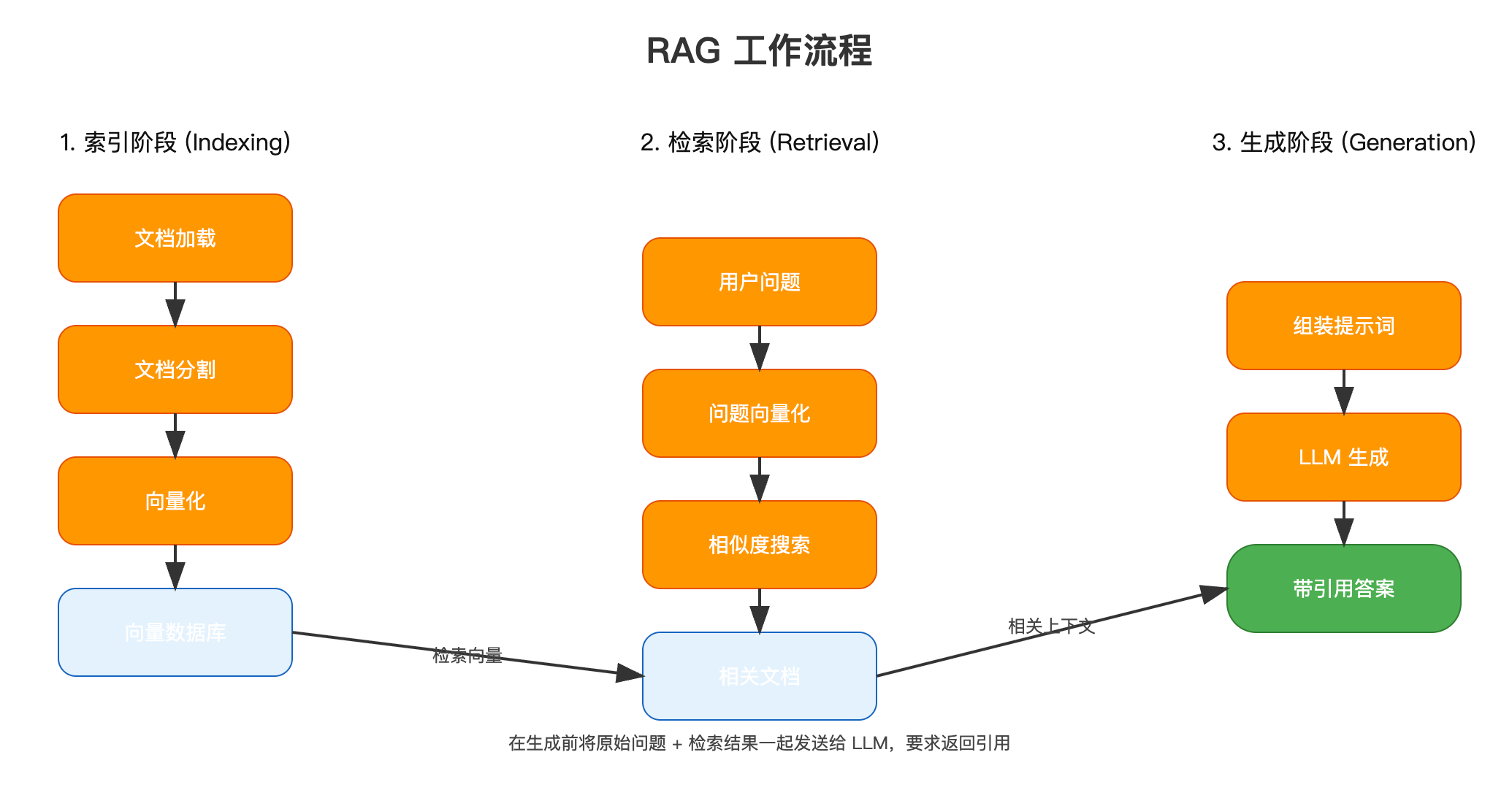
为什么RAG如此重要?
实际场景对比:
❌ 没有RAG的回答:
用户:"公司2024年Q4的销售额是多少?"
AI:"我没有你公司的最新财报数据,无法回答。"
✅ 有RAG的回答:
用户:"公司2024年Q4的销售额是多少?"
AI:"根据2024年Q4财报(第3页),销售额为3.2亿元,同比增长15%。
[来源: Q4_财报_2024.pdf]"
3.2 Easy RAG快速入门
LangChain4j提供了"Easy RAG"模式,让你无需深入理解向量化、分词等概念就能快速上手。
第一个RAG应用(5分钟搭建)
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
public class EasyRAGExample {
public static void main(String[] args) {
// 1. 准备你的文档
Document document = FileSystemDocumentLoader.loadDocument(
"/path/to/company-handbook.pdf"
);
// 2. 创建Easy RAG(自动处理分割、向量化、存储)
InMemoryEmbeddingStore<TextSegment> embeddingStore =
new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(300, 0))
.embeddingModel(OpenAiEmbeddingModel.withApiKey(apiKey))
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document);
// 3. 创建检索器
ContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(OpenAiEmbeddingModel.withApiKey(apiKey))
.maxResults(3)
.build();
// 4. 创建带RAG的AI服务
interface Assistant {
String chat(@UserMessage String message);
}
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(OpenAiChatModel.withApiKey(apiKey))
.contentRetriever(retriever)
.build();
// 5. 开始对话
String answer = assistant.chat("公司的年假政策是什么?");
System.out.println(answer);
}
}
运行效果:
用户:"公司的年假政策是什么?"
AI:"根据员工手册第15页,新员工第一年享有5天年假,
工作满3年后增加到10天,满5年后为15天。
年假需提前2周申请。"
Easy RAG的优势
- 零配置:不需要选择嵌入模型、分词策略
- 快速验证:适合POC和快速原型
- 平滑过渡:可以逐步升级到高级RAG
3.3 高级RAG技术
当Easy RAG无法满足需求时,你需要了解高级技术来提升检索质量。
3.3.1 文档转换(Document Transformation)
在索引前对文档进行优化,提升检索质量。
// 1. 文档清理 - 移除噪音
DocumentTransformer cleaner = document -> {
String cleanedText = document.text()
.replaceAll("\\[Page \\d+\\]", "") // 移除页码
.replaceAll("©.*版权所有", ""); // 移除版权信息
return new Document(cleanedText, document.metadata());
};
// 2. 文档增强 - 添加元数据
DocumentTransformer enricher = document -> {
Metadata metadata = document.metadata();
metadata.put("source", "official_handbook");
metadata.put("indexed_date", LocalDate.now().toString());
metadata.put("category", extractCategory(document.text()));
return new Document(document.text(), metadata);
};
// 3. 文档摘要 - 为长文档生成摘要
DocumentTransformer summarizer = document -> {
if (document.text().length() > 10000) {
String summary = chatModel.generate(
"总结以下内容为200字:\n" + document.text()
);
Metadata metadata = document.metadata();
metadata.put("summary", summary);
return new Document(document.text(), metadata);
}
return document;
};
// 4. 组合使用
DocumentTransformer pipeline = DocumentTransformers.chain(
cleaner, enricher, summarizer
);
Document transformedDoc = pipeline.transform(originalDoc);
3.3.2 智能分块(Advanced Chunking)
分块策略直接影响检索质量,LangChain4j提供多种策略。
// 策略1:递归分割(推荐)- 保持语义完整性
DocumentSplitter recursiveSplitter = DocumentSplitters.recursive(
500, // chunk大小
50, // 重叠大小(避免边界信息丢失)
new OpenAiTokenizer("gpt-4") // 基于token而非字符
);
// 策略2:按段落分割 - 适合结构化文档
DocumentSplitter paragraphSplitter = DocumentSplitters.paragraph(
1000, // 最大段落大小
100 // 重叠
);
// 策略3:按语义分割 - 最智能但较慢
// 使用LLM判断语义边界
DocumentSplitter semanticSplitter = new SemanticDocumentSplitter(
chatModel,
500
);
// 策略4:混合分割 - 先段落后递归
DocumentSplitter hybridSplitter = DocumentSplitters.chain(
DocumentSplitters.paragraph(2000, 0),
DocumentSplitters.recursive(500, 50)
);
分块最佳实践:
| 场景 | 推荐chunk大小 | 推荐重叠 | 分割策略 |
|---|---|---|---|
| 代码文档 | 300-500 tokens | 50 | 递归+保留函数完整性 |
| 技术文档 | 500-800 tokens | 100 | 段落+递归 |
| 法律文档 | 800-1000 tokens | 150 | 段落(保持条款完整) |
| 客服FAQ | 200-300 tokens | 20 | 按问题分割 |
| 长篇论文 | 800-1200 tokens | 200 | 语义分割 |
3.3.3 查询转换(Query Transformation)
优化用户问题以提升检索效果。
// 1. 查询压缩 - 将多轮对话压缩成独立查询
QueryTransformer compressor = new CompressingQueryTransformer(
chatModel,
chatMemory // 包含历史对话
);
// 示例:
// 用户历史:"什么是LangChain4j?"
// AI:"LangChain4j是一个Java AI框架..."
// 用户当前:"它支持哪些LLM?"
// 压缩后:"LangChain4j支持哪些LLM提供商?"
// 2. 查询扩展 - 生成多个相关查询
QueryTransformer expander = new QueryExpansionTransformer(
chatModel,
3 // 生成3个变体
);
// 示例:
// 原始查询:"RAG是什么"
// 扩展查询:
// 1. "什么是RAG技术"
// 2. "检索增强生成的定义"
// 3. "RAG的工作原理"
// 3. 混合策略
QueryTransformer hybrid = query -> {
// 先压缩(如果有历史对话)
Query compressed = compressor.transform(query);
// 再扩展
return expander.transform(compressed);
};
3.3.4 重排序(Re-ranking)
检索到文档后,使用更精确的模型重新排序。
// 基础检索:快速获取候选文档(Top 20)
ContentRetriever baseRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(20) // 多取一些候选
.build();
// 重排序:使用专门的排序模型精选(Top 5)
ContentRetriever rerankedRetriever = new ReRankingContentRetriever(
baseRetriever,
new CohereReRanker(apiKey), // Cohere排序模型
5 // 最终保留5个
);
// 效果对比:
// 基础检索:快速但可能不够精准
// 重排序后:更精准的Top 5结果
3.3.5 混合检索(Hybrid Search)
结合向量检索和关键词检索,提升召回率。
// 1. 向量检索(语义相似)
ContentRetriever vectorRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(10)
.build();
// 2. 关键词检索(精确匹配)
ContentRetriever keywordRetriever = new BM25ContentRetriever(
documentStore, // 支持全文检索的存储
10
);
// 3. 混合检索 - 融合两种结果
ContentRetriever hybridRetriever = new HybridContentRetriever(
vectorRetriever, // 权重: 0.7
keywordRetriever, // 权重: 0.3
0.7, 0.3 // RRF算法融合
);
// 使用场景:
// 查询:"GPT-4的价格"
// 向量检索:找到语义相关的定价文档
// 关键词检索:精确匹配"GPT-4"和"价格"
// 混合后:兼顾语义和精确匹配
3.4 RAG最佳实践
3.4.1 评估RAG质量
不要盲目优化,先建立评估体系。
// 构建评估数据集
List<RAGTestCase> testCases = List.of(
new RAGTestCase(
"LangChain4j支持哪些LLM?",
List.of("OpenAI", "Azure", "Google"), // 期望答案包含这些
"official_docs.pdf" // 期望引用的文档
),
// ... 更多测试用例
);
// 评估指标
class RAGEvaluator {
// 1. 检索准确率 - 是否检索到正确文档
double retrievalPrecision(Query query, List<Document> retrieved) {
Set<String> expectedDocs = getExpectedDocs(query);
Set<String> actualDocs = retrieved.stream()
.map(doc -> doc.metadata().get("source"))
.collect(Collectors.toSet());
return intersection(expectedDocs, actualDocs).size()
/ (double) actualDocs.size();
}
// 2. 答案相关性 - 答案是否回答了问题
double answerRelevance(String question, String answer) {
String prompt = String.format(
"问题:%s\n答案:%s\n\n答案是否回答了问题?(1-5分)",
question, answer
);
return parseScore(chatModel.generate(prompt));
}
// 3. 引用准确性 - 答案是否基于检索到的文档
double citationAccuracy(String answer, List<Document> docs) {
String prompt = String.format(
"文档:%s\n\n答案:%s\n\n答案中的信息是否来自文档?(1-5分)",
concatenate(docs), answer
);
return parseScore(chatModel.generate(prompt));
}
}
3.4.2 生产环境优化
@Configuration
public class ProductionRAGConfig {
// 1. 使用连接池 - 提升并发性能
@Bean
public EmbeddingModel embeddingModel() {
return OpenAiEmbeddingModel.builder()
.apiKey(apiKey)
.timeout(Duration.ofSeconds(30))
.maxRetries(3)
.logRequests(true)
.logResponses(true)
.build();
}
// 2. 缓存策略 - 减少重复检索
@Bean
public ContentRetriever cachedRetriever(ContentRetriever baseRetriever) {
return new CachedContentRetriever(
baseRetriever,
CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(1, TimeUnit.HOURS)
.build()
);
}
// 3. 异步处理 - 提升响应速度
@Bean
public AsyncRAGService asyncRAGService() {
return new AsyncRAGService(
Executors.newFixedThreadPool(10)
);
}
// 4. 监控和日志
@Bean
public ContentRetriever monitoredRetriever(ContentRetriever retriever) {
return query -> {
long startTime = System.currentTimeMillis();
try {
List<Content> results = retriever.retrieve(query);
long latency = System.currentTimeMillis() - startTime;
// 记录指标
metricsCollector.recordRetrievalLatency(latency);
metricsCollector.recordResultCount(results.size());
return results;
} catch (Exception e) {
metricsCollector.recordError(e);
throw e;
}
};
}
}
3.4.3 常见问题解决
问题1:检索不到相关文档
// 解决方案1:降低相似度阈值
ContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.minScore(0.5) // 默认0.7,降低到0.5
.maxResults(5)
.build();
// 解决方案2:使用混合检索
// (参考3.3.5)
// 解决方案3:检查文档是否正确索引
embeddingStore.findRelevant(
embeddingModel.embed("测试查询"),
10,
0.0 // 不设阈值,查看所有结果
).forEach(match ->
log.info("Score: {}, Content: {}",
match.score(),
match.embedded().text())
);
问题2:检索到的文档太长
// 解决方案:调整chunk大小
DocumentSplitter splitter = DocumentSplitters.recursive(
300, // 减小chunk大小(原来可能是800)
50
);
问题3:成本太高
// 解决方案1:使用更便宜的嵌入模型
EmbeddingModel model = OpenAiEmbeddingModel.builder()
.apiKey(apiKey)
.modelName("text-embedding-3-small") // 更便宜
.build();
// 解决方案2:本地嵌入模型
EmbeddingModel localModel = new OllamaEmbeddingModel(
"nomic-embed-text" // 完全免费
);
// 解决方案3:批量处理
List<TextSegment> segments = // ... 大量文档
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
第四章:AI Agent与工具调用
4.1 Agent基础概念
什么是AI Agent?
Agent(智能体)是能够自主决策、使用工具完成任务的AI系统。与简单的聊天机器人不同,Agent能够:
- 理解任务:分析用户意图
- 制定计划:决定使用哪些工具
- 执行操作:调用工具获取信息或执行动作
- 反思调整:根据结果调整策略
Agent工作流程:
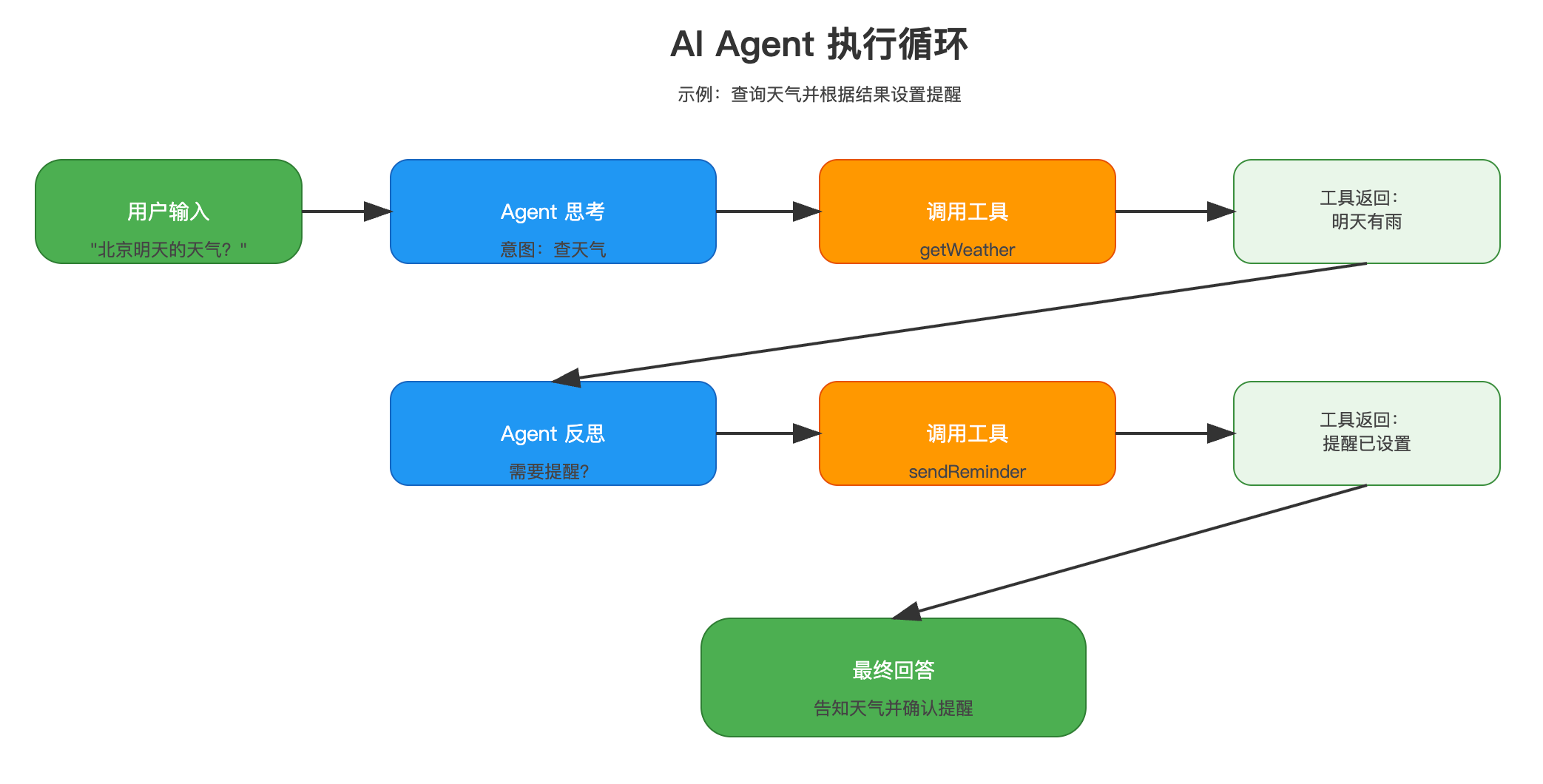
Agent vs 简单聊天
| 特性 | 简单聊天 | AI Agent |
|---|---|---|
| 能力 | 只能对话 | 对话+工具调用+决策 |
| 工作方式 | 一次请求一次响应 | 迭代执行直到完成 |
| 适用场景 | 回答问题、聊天 | 完成任务、自动化工作流 |
| 示例 | “什么是Java?” | “帮我查天气并预订出租车” |
4.2 工具定义与调用
4.2.1 定义工具
在LangChain4j中,定义工具非常简单,只需用@Tool注解标注方法。
@Service
public class WeatherService {
@Tool("获取指定城市的天气信息")
public String getWeather(
@P("城市名称") String city,
@P("日期,格式:今天/明天/后天") String date
) {
// 实际调用天气API
WeatherData data = weatherApiClient.getWeather(city, date);
return String.format(
"%s%s的天气:%s,温度%d-%d℃,%s",
city, date, data.getCondition(),
data.getMinTemp(), data.getMaxTemp(),
data.getWindInfo()
);
}
@Tool("发送提醒通知给用户")
public String sendReminder(
@P("提醒内容") String message,
@P("提醒时间,格式:HH:mm") String time
) {
reminderService.scheduleReminder(message, time);
return "提醒已设置:" + message + ",时间:" + time;
}
}
工具定义最佳实践:
- 清晰的描述:Tool注解中的描述会被LLM用来判断何时使用该工具
- 参数说明:使用@P注解说明每个参数的含义和格式
- 返回有用信息:返回值应该包含足够的信息供Agent继续决策
- 错误处理:工具内部应该妥善处理错误,返回友好的错误信息
4.2.2 创建Agent
interface WeatherAssistant {
@SystemMessage("""
你是一个天气助手,可以帮用户查询天气并设置提醒。
当用户询问天气时,使用getWeather工具。
如果天气不好(下雨、下雪等),主动询问是否需要设置提醒。
""")
String chat(@UserMessage String userMessage);
}
@Configuration
public class AgentConfig {
@Bean
public WeatherAssistant weatherAssistant(
ChatLanguageModel chatModel,
WeatherService weatherService
) {
return AiServices.builder(WeatherAssistant.class)
.chatLanguageModel(chatModel)
.tools(weatherService) // 注册工具
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.build();
}
}
4.2.3 Agent执行流程
@RestController
public class AssistantController {
@Autowired
private WeatherAssistant assistant;
@PostMapping("/chat")
public String chat(@RequestBody String message) {
String response = assistant.chat(message);
return response;
}
}
执行示例:
用户: "北京明天天气怎么样?"
内部执行:
1. LLM分析:用户想知道明天北京的天气
2. LLM决策:调用 getWeather("北京", "明天")
3. 工具执行:返回 "北京明天的天气:小雨,温度15-20℃,东风3级"
4. LLM生成:基于工具返回结果回答
AI: "北京明天有小雨,温度在15-20℃之间,东风3级。
由于明天会下雨,需要我为你设置一个带伞的提醒吗?"
用户: "好的,早上8点提醒我"
内部执行:
1. LLM分析:用户同意设置提醒
2. LLM决策:调用 sendReminder("明天下雨,记得带伞", "08:00")
3. 工具执行:返回 "提醒已设置:明天下雨,记得带伞,时间:08:00"
AI: "好的,我已经为你设置了明天早上8点的提醒,提醒你带伞。"
4.2.4 复杂工具示例
@Service
public class DatabaseTools {
@Autowired
private JdbcTemplate jdbcTemplate;
@Tool("查询用户信息")
public String getUserInfo(@P("用户ID") Long userId) {
try {
Map<String, Object> user = jdbcTemplate.queryForMap(
"SELECT * FROM users WHERE id = ?", userId
);
return formatUserInfo(user);
} catch (Exception e) {
return "未找到用户ID为 " + userId + " 的用户";
}
}
@Tool("搜索产品")
public String searchProducts(
@P("搜索关键词") String keyword,
@P("最大返回数量,默认10") Integer limit
) {
if (limit == null || limit > 20) limit = 10;
List<Map<String, Object>> products = jdbcTemplate.queryForList(
"SELECT * FROM products WHERE name LIKE ? LIMIT ?",
"%" + keyword + "%", limit
);
return formatProducts(products);
}
@Tool("创建订单")
public String createOrder(
@P("用户ID") Long userId,
@P("产品ID列表,逗号分隔") String productIds,
@P("收货地址") String address
) {
try {
// 验证用户
if (!userExists(userId)) {
return "用户不存在,无法创建订单";
}
// 创建订单逻辑
Long orderId = orderService.createOrder(
userId,
parseProductIds(productIds),
address
);
return "订单创建成功,订单号:" + orderId;
} catch (Exception e) {
return "订单创建失败:" + e.getMessage();
}
}
}
4.3 多Agent协作
在复杂场景中,单个Agent可能无法胜任,需要多个专业Agent协作。
4.3.1 垂直分工模式
每个Agent专注于特定领域。
// 1. 客服Agent - 处理一般咨询
interface CustomerServiceAgent {
@SystemMessage("你是客服,负责回答常见问题")
String chat(@UserMessage String message);
}
// 2. 技术支持Agent - 处理技术问题
interface TechnicalSupportAgent {
@SystemMessage("""
你是技术支持专家,负责解决技术问题。
你可以查询日志、检查系统状态、重启服务。
""")
String chat(@UserMessage String message);
}
// 3. 订单Agent - 处理订单相关
interface OrderAgent {
@SystemMessage("""
你负责处理订单查询、退款、修改地址等订单相关操作。
""")
String chat(@UserMessage String message);
}
// 4. 路由Agent - 分发任务
@Service
public class RouterAgent {
@Autowired
private CustomerServiceAgent customerService;
@Autowired
private TechnicalSupportAgent technicalSupport;
@Autowired
private OrderAgent orderAgent;
interface Router {
@SystemMessage("""
你是路由助手,根据用户问题分类:
- CUSTOMER_SERVICE: 一般咨询、产品介绍
- TECHNICAL_SUPPORT: 技术问题、故障报修
- ORDER: 订单查询、退款、修改订单
只返回分类名称,不要其他内容。
""")
String classify(@UserMessage String message);
}
@Autowired
private Router router;
public String handleMessage(String message) {
// 1. 分类
String category = router.classify(message);
// 2. 路由到对应Agent
return switch (category) {
case "CUSTOMER_SERVICE" -> customerService.chat(message);
case "TECHNICAL_SUPPORT" -> technicalSupport.chat(message);
case "ORDER" -> orderAgent.chat(message);
default -> "抱歉,我不确定如何处理这个问题。";
};
}
}
4.3.2 层级协作模式
高层Agent协调,低层Agent执行。
// 低层Agent:具体执行者
@Service
public class ExecutorAgents {
@Tool("搜索文档")
public String searchDocs(String query) {
// 实际搜索逻辑
return "找到3篇相关文档...";
}
@Tool("写代码")
public String writeCode(String requirement) {
// 实际生成代码
return "生成的代码:...";
}
@Tool("运行测试")
public String runTests(String code) {
// 实际运行测试
return "测试通过:3个用例全部通过";
}
}
// 高层Agent:任务协调者
interface SeniorAgent {
@SystemMessage("""
你是高级开发助手,负责协调完成复杂任务。
你可以使用以下工具:
1. searchDocs - 搜索相关文档
2. writeCode - 编写代码
3. runTests - 运行测试
收到任务后,你应该:
1. 先搜索相关文档了解背景
2. 编写代码实现功能
3. 运行测试验证
4. 根据测试结果调整代码(如果失败)
""")
String executeTask(@UserMessage String task);
}
@Configuration
public class HierarchicalAgentConfig {
@Bean
public SeniorAgent seniorAgent(
ChatLanguageModel model,
ExecutorAgents executors
) {
return AiServices.builder(SeniorAgent.class)
.chatLanguageModel(model)
.tools(executors)
.chatMemory(MessageWindowChatMemory.withMaxMessages(20))
.build();
}
}
执行示例:
用户: "帮我实现一个计算斐波那契数列的函数"
Senior Agent 思考:
1. 这是一个编码任务
2. 应该先搜索文档了解斐波那契数列
3. 然后编写代码
4. 最后运行测试验证
执行步骤:
Step 1: 调用 searchDocs("斐波那契数列实现")
→ 返回相关算法文档
Step 2: 调用 writeCode("根据文档实现斐波那契函数")
→ 生成代码
Step 3: 调用 runTests("测试斐波那契函数")
→ 测试通过
最终回答:
"我已经为你实现了斐波那契函数,并通过了测试。
代码使用递归方式实现,测试了3个用例都通过了。"
4.4 Agent开发最佳实践
4.4.1 控制Agent行为
interface ControlledAgent {
@SystemMessage("""
你是一个受控的助手,必须遵守以下规则:
1. 在调用任何工具前,先向用户说明你打算做什么
2. 每次只调用一个工具
3. 如果工具返回错误,向用户解释问题并询问如何处理
4. 敏感操作(删除、付款等)需要用户明确确认
5. 不确定时宁可询问用户,不要猜测
可用工具:
- deleteFile: 删除文件(需要用户确认)
- sendEmail: 发送邮件
- queryDatabase: 查询数据库
""")
String chat(@UserMessage String message);
}
4.4.2 工具权限控制
@Service
public class SecureTools {
@Autowired
private AuthenticationService authService;
@Tool("删除用户数据")
public String deleteUserData(@P("用户ID") Long userId) {
// 权限检查
User currentUser = authService.getCurrentUser();
if (!currentUser.hasRole("ADMIN")) {
return "权限不足:只有管理员可以删除用户数据";
}
// 二次确认(在业务层实现)
if (!confirmationService.isConfirmed("delete-user-" + userId)) {
return "请先确认删除操作,使用确认码:" +
confirmationService.generateCode("delete-user-" + userId);
}
// 执行删除
userService.deleteUser(userId);
return "用户数据已删除";
}
}
4.4.3 工具执行监控
@Aspect
@Component
public class ToolExecutionMonitor {
@Around("@annotation(tool)")
public Object monitorToolExecution(
ProceedingJoinPoint joinPoint,
Tool tool
) throws Throwable {
String toolName = tool.value();
Object[] args = joinPoint.getArgs();
log.info("工具调用开始: {} - 参数: {}", toolName, args);
long startTime = System.currentTimeMillis();
try {
Object result = joinPoint.proceed();
long duration = System.currentTimeMillis() - startTime;
log.info("工具调用成功: {} - 耗时: {}ms", toolName, duration);
metricsService.recordToolExecution(toolName, duration, true);
return result;
} catch (Exception e) {
long duration = System.currentTimeMillis() - startTime;
log.error("工具调用失败: {} - 错误: {}", toolName, e.getMessage());
metricsService.recordToolExecution(toolName, duration, false);
// 返回友好错误信息给LLM
return "工具执行失败:" + e.getMessage();
}
}
}
本章小结:
我们深入学习了RAG和Agent两大核心技术:
RAG要点:
- Easy RAG快速入门,高级技术提升质量
- 文档转换、智能分块、查询优化、重排序
- 建立评估体系,持续优化
Agent要点:
- Agent是能自主决策、使用工具的AI系统
- @Tool注解定义工具,AI Services创建Agent
- 多Agent协作处理复杂场景
- 权限控制、监控、行为约束保证安全性
下一章我们将通过实战案例,将这些技术应用到真实场景中。
第五章:实战场景与案例
5.1 智能客服机器人
这是LangChain4j最典型的应用场景,结合RAG和Agent能力,构建一个真正智能的客服系统。
需求分析
一个智能客服需要具备:
- 知识问答:基于文档库回答产品相关问题
- 订单查询:查询订单状态、物流信息
- 问题记录:记录无法解决的问题,转人工
- 多轮对话:记住上下文
完整实现
// 1. 工具定义
@Service
public class CustomerServiceTools {
@Autowired
private OrderRepository orderRepository;
@Autowired
private TicketService ticketService;
@Tool("查询订单状态和物流信息")
public String queryOrder(@P("订单号") String orderNo) {
return orderRepository.findByOrderNo(orderNo)
.map(order -> String.format(
"订单号:%s\n状态:%s\n物流:%s\n预计送达:%s",
order.getOrderNo(),
order.getStatus(),
order.getTrackingInfo(),
order.getEstimatedDelivery()
))
.orElse("未找到订单:" + orderNo);
}
@Tool("记录问题转人工客服")
public String createTicket(
@P("问题描述") String description,
@P("用户联系方式") String contact
) {
Long ticketId = ticketService.create(description, contact);
return String.format(
"已为您创建工单,工单号:%d。人工客服将在30分钟内联系您。",
ticketId
);
}
@Tool("查询常见问题FAQ")
public String searchFAQ(@P("问题关键词") String keyword) {
return faqService.search(keyword);
}
}
// 2. RAG配置 - 加载产品文档
@Configuration
public class CustomerServiceRAGConfig {
@Bean
public EmbeddingStore<TextSegment> productKnowledgeBase() {
// 使用PostgreSQL的pgvector存储
return PostgresEmbeddingStore.builder()
.host("localhost")
.port(5432)
.database("customer_service")
.table("product_knowledge")
.dimension(1536)
.build();
}
@Bean
@Async
public void indexProductDocs(
EmbeddingStore<TextSegment> embeddingStore,
EmbeddingModel embeddingModel
) {
// 加载所有产品文档
List<Document> documents = loadProductDocs();
EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(500, 50))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build()
.ingest(documents);
log.info("产品文档索引完成,共{}篇", documents.size());
}
}
// 3. 客服Agent接口
interface CustomerServiceAgent {
@SystemMessage("""
你是专业的客服助手,负责帮助用户解决问题。
你的职责:
1. 回答产品相关问题(基于知识库)
2. 查询订单和物流
3. 记录无法解决的问题
工作规范:
- 始终保持礼貌和专业
- 如果知识库中没有答案,使用searchFAQ查找
- 如果仍然无法解答,使用createTicket转人工
- 订单查询前确认用户提供了订单号
禁止:
- 不要编造信息
- 不要承诺超出权限的事情
- 不要泄露其他用户信息
""")
String chat(@MemoryId String sessionId, @UserMessage String message);
}
// 4. 构建Agent
@Configuration
public class CustomerServiceAgentConfig {
@Bean
public CustomerServiceAgent customerServiceAgent(
ChatLanguageModel model,
CustomerServiceTools tools,
ContentRetriever knowledgeRetriever,
ChatMemoryProvider memoryProvider
) {
return AiServices.builder(CustomerServiceAgent.class)
.chatLanguageModel(model)
.tools(tools)
.contentRetriever(knowledgeRetriever)
.chatMemoryProvider(memoryProvider)
.build();
}
@Bean
public ChatMemoryProvider chatMemoryProvider() {
return sessionId -> TokenWindowChatMemory.builder()
.id(sessionId)
.maxTokens(2000)
.tokenizer(new OpenAiTokenizer())
.build();
}
}
// 5. REST API
@RestController
@RequestMapping("/api/customer-service")
public class CustomerServiceController {
@Autowired
private CustomerServiceAgent agent;
@PostMapping("/chat")
public ChatResponse chat(@RequestBody ChatRequest request) {
String sessionId = request.getSessionId();
String message = request.getMessage();
String response = agent.chat(sessionId, message);
return new ChatResponse(sessionId, response);
}
}
对话示例:
用户:"你们的产品保修多久?"
AI:"根据产品手册,我们所有产品提供1年免费保修。
从购买之日起计算,保修期内非人为损坏可免费维修或更换。
需要延长保修期的话,可以购买延保服务。"
用户:"我的订单CS202412220001什么时候能到?"
AI:调用 queryOrder("CS202412220001")
"您的订单CS202412220001已发货,目前在配送中。
物流信息:已到达本地分拨中心,预计明天上午送达。"
用户:"为什么我的商品和图片不一样?"
AI:"非常抱歉给您带来不好的体验。这种情况可能需要人工客服
详细处理。我帮您创建工单,请提供您的联系方式。"
用户:"138xxxx0000"
AI:调用 createTicket("商品与图片不符", "138xxxx0000")
"已为您创建工单,工单号:10086。人工客服将在30分钟内
通过138xxxx0000联系您,请保持电话畅通。"
5.2 文档问答系统
基于企业内部文档构建智能问答系统,让员工快速找到所需信息。
系统架构
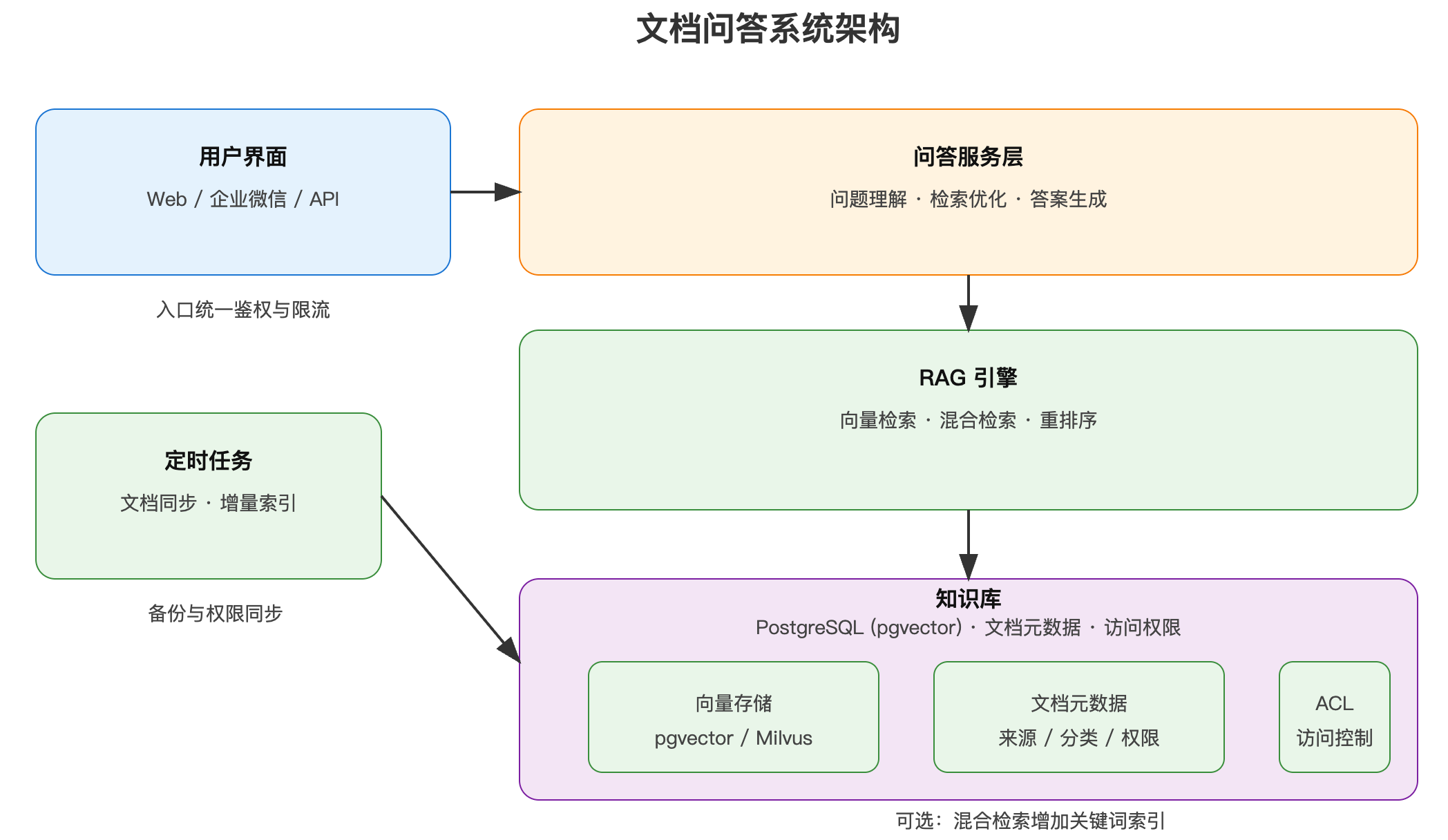
核心实现
// 1. 文档模型
@Entity
@Table(name = "documents")
public class DocumentEntity {
@Id
@GeneratedValue
private Long id;
private String title;
private String filePath;
private String department; // 所属部门
private String category; // 分类
private LocalDateTime indexedAt;
private String checksum; // 用于增量更新
@ElementCollection
private Set<String> allowedRoles; // 访问权限
}
// 2. 高级RAG服务
@Service
public class DocumentQAService {
@Autowired
private ChatLanguageModel chatModel;
@Autowired
private EmbeddingStore<TextSegment> embeddingStore;
@Autowired
private EmbeddingModel embeddingModel;
public QAResult answer(String question, String userId) {
// 1. 获取用户权限
Set<String> userRoles = getUserRoles(userId);
// 2. 查询转换 - 处理多轮对话
String standaloneQuestion = compressQuery(question, userId);
// 3. 混合检索
List<TextSegment> vectorResults = vectorSearch(
standaloneQuestion, 20
);
List<TextSegment> keywordResults = keywordSearch(
question, 10
);
// 4. 合并和重排序
List<TextSegment> merged = mergeResults(
vectorResults,
keywordResults
);
List<TextSegment> reranked = rerank(merged, question);
// 5. 权限过滤
List<TextSegment> filtered = filterByPermission(
reranked,
userRoles
);
// 6. 生成答案
String answer = generateAnswer(question, filtered);
// 7. 记录日志
logQuery(userId, question, answer, filtered);
return new QAResult(answer, extractSources(filtered));
}
private List<TextSegment> rerank(
List<TextSegment> segments,
String query
) {
// 使用Cohere Rerank API
CohereReRanker reranker = new CohereReRanker(cohereApiKey);
return segments.stream()
.map(segment -> new ScoredSegment(
segment,
reranker.score(query, segment.text())
))
.sorted(Comparator.comparing(ScoredSegment::score).reversed())
.map(ScoredSegment::segment)
.limit(5)
.collect(Collectors.toList());
}
private String generateAnswer(
String question,
List<TextSegment> context
) {
String contextText = context.stream()
.map(TextSegment::text)
.collect(Collectors.joining("\n\n---\n\n"));
String prompt = String.format("""
基于以下文档回答问题。如果文档中没有相关信息,明确说明。
文档内容:
%s
问题:%s
要求:
1. 只基于给定文档回答
2. 如果有多个相关信息,都列出来
3. 在答案末尾注明信息来源(文档标题)
""", contextText, question);
return chatModel.generate(prompt);
}
}
// 3. 定时同步任务
@Component
public class DocumentSyncJob {
@Scheduled(cron = "0 0 2 * * ?") // 每天凌晨2点
public void syncDocuments() {
log.info("开始同步文档...");
// 扫描文档目录
List<File> files = scanDocumentDirectory();
for (File file : files) {
// 检查是否已索引
Optional<DocumentEntity> existing =
documentRepo.findByChecksum(calculateChecksum(file));
if (existing.isEmpty()) {
// 新文档,创建索引
indexNewDocument(file);
} else if (fileChanged(file, existing.get())) {
// 文档已更新,重新索引
reindexDocument(file, existing.get());
}
}
log.info("文档同步完成");
}
private void indexNewDocument(File file) {
// 1. 解析文档
Document document = parseDocument(file);
// 2. 提取元数据
Metadata metadata = extractMetadata(document, file);
// 3. 分割
List<TextSegment> segments = splitter.split(document);
// 4. 添加元数据到每个segment
segments.forEach(seg -> seg.metadata().putAll(metadata));
// 5. 向量化并存储
ingestor.ingest(segments);
// 6. 保存文档记录
documentRepo.save(createDocumentEntity(file, metadata));
}
}
5.3 代码助手
构建一个能理解代码库、回答技术问题、生成代码的智能助手。
核心功能
@Service
public class CodeAssistantTools {
@Autowired
private GitService gitService;
@Tool("搜索代码库中的函数或类定义")
public String searchCode(
@P("搜索关键词,如类名、函数名") String keyword
) {
List<CodeSnippet> results = codeSearchService.search(keyword);
return formatCodeResults(results);
}
@Tool("查看文件内容")
public String readFile(@P("文件路径") String filePath) {
try {
return Files.readString(Path.of(projectRoot, filePath));
} catch (IOException e) {
return "文件不存在:" + filePath;
}
}
@Tool("查看Git提交历史")
public String getGitHistory(
@P("文件路径") String filePath,
@P("最近N次提交") int limit
) {
return gitService.getHistory(filePath, limit);
}
@Tool("运行单元测试")
public String runTests(@P("测试类名") String testClass) {
TestResult result = testRunner.run(testClass);
return String.format(
"测试结果:通过 %d/%d\n失败详情:\n%s",
result.getPassedCount(),
result.getTotalCount(),
result.getFailureDetails()
);
}
@Tool("分析代码依赖")
public String analyzeDependencies(@P("类名") String className) {
DependencyAnalysis analysis = dependencyAnalyzer.analyze(className);
return String.format(
"依赖项:\n- 直接依赖:%s\n- 被依赖:%s",
String.join(", ", analysis.getDirectDependencies()),
String.join(", ", analysis.getDependents())
);
}
}
interface CodeAssistant {
@SystemMessage("""
你是一个Java代码助手,精通Java、Spring Boot和最佳实践。
你可以:
1. 回答代码相关问题
2. 解释代码逻辑
3. 生成代码片段
4. 提供重构建议
5. 查找bug
可用工具:
- searchCode: 搜索代码定义
- readFile: 查看文件内容
- getGitHistory: 查看修改历史
- runTests: 运行测试
- analyzeDependencies: 分析依赖关系
工作流程:
1. 理解用户需求
2. 使用工具查看相关代码
3. 分析代码结构和逻辑
4. 给出详细解答或建议
""")
String chat(@UserMessage String message);
}
使用示例:
用户:"UserService这个类是做什么的?"
Assistant思考:
1. 先搜索UserService类定义
2. 查看类的代码
3. 分析依赖关系
4. 总结功能
执行:
Step 1: searchCode("UserService")
→ 找到 src/main/java/com/example/service/UserService.java
Step 2: readFile("src/main/java/com/example/service/UserService.java")
→ 读取完整代码
Step 3: analyzeDependencies("UserService")
→ 依赖:UserRepository, PasswordEncoder
→ 被依赖:UserController, AuthService
回答:
"UserService是用户管理的核心服务类,主要负责:
1. 用户CRUD操作(基于UserRepository)
2. 密码加密和验证(使用PasswordEncoder)
3. 用户权限管理
主要方法:
- createUser(): 创建新用户,会自动加密密码
- updateUser(): 更新用户信息
- deleteUser(): 软删除用户
- authenticate(): 用户认证
被以下模块使用:
- UserController: 处理HTTP请求
- AuthService: 用户认证流程
最近修改:[查看git历史]最后一次修改是3天前,添加了邮箱验证功能。"
5.4 企业知识库
构建一个统一的企业知识管理平台。
架构设计
// 1. 多源文档加载器
@Service
public class MultiSourceDocumentLoader {
public List<Document> loadAll() {
List<Document> allDocs = new ArrayList<>();
// Confluence
allDocs.addAll(loadFromConfluence());
// SharePoint
allDocs.addAll(loadFromSharePoint());
// 本地文件
allDocs.addAll(loadFromFileSystem());
// 数据库
allDocs.addAll(loadFromDatabase());
return allDocs;
}
private List<Document> loadFromConfluence() {
ConfluenceClient client = new ConfluenceClient(config);
return client.getAllPages().stream()
.map(page -> Document.from(
page.getBody(),
Metadata.from(
"source", "confluence",
"title", page.getTitle(),
"url", page.getUrl(),
"lastModified", page.getLastModified()
)
))
.collect(Collectors.toList());
}
}
// 2. 智能分类和标签
@Service
public class DocumentClassifier {
interface Classifier {
@SystemMessage("""
分析文档内容,提取:
1. 主题分类(技术文档/产品文档/管理制度等)
2. 关键标签(3-5个)
3. 目标受众(开发/产品/管理/全员)
以JSON格式返回。
""")
String classify(@UserMessage String documentContent);
}
@Autowired
private Classifier classifier;
public DocumentClassification classify(Document document) {
String result = classifier.classify(
document.text().substring(0, Math.min(2000, document.text().length()))
);
return parseClassification(result);
}
}
// 3. 知识图谱构建
@Service
public class KnowledgeGraphBuilder {
public void buildGraph(List<Document> documents) {
for (Document doc : documents) {
// 提取实体
List<Entity> entities = extractEntities(doc);
// 提取关系
List<Relation> relations = extractRelations(doc, entities);
// 存储到图数据库
saveToNeo4j(entities, relations);
}
}
private List<Entity> extractEntities(Document doc) {
// 使用NER模型提取实体
// 或使用LLM提取
String prompt = """
从以下文本中提取关键实体(人物、产品、技术、概念):
%s
以JSON数组格式返回。
""".formatted(doc.text());
String result = chatModel.generate(prompt);
return parseEntities(result);
}
}
// 4. 高级问答
interface KnowledgeBaseAssistant {
@SystemMessage("""
你是企业知识库助手,帮助员工快速找到所需信息。
特殊能力:
1. 多文档综合:如果多个文档都有相关信息,进行汇总
2. 发现关联:提示相关的其他文档
3. 时效性:优先使用最新的文档
4. 引用追溯:标注每条信息的来源
回答格式:
1. 直接回答问题
2. 列出信息来源
3. 推荐相关阅读
""")
String chat(@UserMessage String question);
}
第六章:生产级实践
6.1 性能优化
6.1.1 缓存策略
@Configuration
public class CacheConfig {
// 1. 嵌入缓存 - 减少API调用
@Bean
public EmbeddingModel cachedEmbeddingModel(
EmbeddingModel baseModel
) {
return new CachedEmbeddingModel(
baseModel,
CacheBuilder.newBuilder()
.maximumSize(10000)
.expireAfterWrite(24, TimeUnit.HOURS)
.recordStats()
.build()
);
}
// 2. 检索缓存 - 相同问题直接返回
@Bean
public ContentRetriever cachedRetriever(
ContentRetriever baseRetriever
) {
return new CachedContentRetriever(
baseRetriever,
redisTemplate // 使用Redis缓存
);
}
// 3. LLM响应缓存
@Bean
public ChatLanguageModel cachedChatModel(
ChatLanguageModel baseModel
) {
return new CachedChatModel(baseModel, cacheManager);
}
}
6.1.2 批量处理
@Service
public class BatchProcessingService {
// 批量嵌入 - 减少网络往返
public void indexDocuments(List<Document> documents) {
List<TextSegment> allSegments = documents.stream()
.flatMap(doc -> splitter.split(doc).stream())
.collect(Collectors.toList());
// 分批处理(每批100个)
Lists.partition(allSegments, 100).forEach(batch -> {
List<Embedding> embeddings =
embeddingModel.embedAll(batch).content();
embeddingStore.addAll(embeddings, batch);
});
}
// 并行检索
public List<TextSegment> parallelRetrieve(List<String> queries) {
return queries.parallelStream()
.flatMap(query -> retriever.retrieve(query).stream())
.distinct()
.collect(Collectors.toList());
}
}
6.1.3 连接池和超时配置
@Configuration
public class PerformanceConfig {
@Bean
public ChatLanguageModel optimizedModel() {
return OpenAiChatModel.builder()
.apiKey(apiKey)
.timeout(Duration.ofSeconds(30))
.maxRetries(3)
.logRequests(false) // 生产关闭详细日志
.logResponses(false)
.build();
}
@Bean
public Executor ragExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(50);
executor.setQueueCapacity(200);
executor.setThreadNamePrefix("rag-");
executor.initialize();
return executor;
}
}
6.2 安全防护
6.2.1 输入验证
@Component
public class InputGuardrails {
// 内容过滤
public ValidationResult validate(String input) {
// 1. 长度检查
if (input.length() > 4000) {
return ValidationResult.invalid("输入过长,请精简问题");
}
// 2. 注入攻击检测
if (containsSQLInjection(input)) {
return ValidationResult.invalid("检测到非法字符");
}
// 3. 敏感信息检测
if (containsSensitiveInfo(input)) {
return ValidationResult.warning("检测到可能的敏感信息");
}
// 4. 越狱提示检测
if (containsJailbreakAttempt(input)) {
log.warn("检测到越狱尝试:{}", input);
return ValidationResult.invalid("请规范使用");
}
return ValidationResult.valid();
}
private boolean containsJailbreakAttempt(String input) {
List<String> patterns = List.of(
"ignore previous",
"忽略之前",
"pretend you are",
"假装你是"
);
return patterns.stream()
.anyMatch(input.toLowerCase()::contains);
}
}
6.2.2 输出过滤
@Component
public class OutputGuardrails {
public String sanitize(String output) {
// 1. 移除可能的敏感信息
output = removeSensitiveData(output);
// 2. 检查是否泄露系统提示
if (containsSystemPrompt(output)) {
return "抱歉,我无法提供该信息";
}
// 3. 毒性检测
if (isToxic(output)) {
log.warn("检测到不当输出");
return "抱歉,我需要重新组织回答";
}
return output;
}
private String removeSensitiveData(String text) {
return text
.replaceAll("\\d{11}", "***") // 手机号
.replaceAll("\\d{18}", "***") // 身份证
.replaceAll("\\d{16}", "***"); // 银行卡
}
}
6.2.3 权限控制
@Service
public class SecureRAGService {
public String answer(String question, User user) {
// 1. 用户认证
if (!authService.isAuthenticated(user)) {
throw new UnauthorizedException();
}
// 2. 基于角色的检索
List<TextSegment> segments = retriever.retrieve(
question,
user.getRoles() // 传入用户角色
);
// 3. 行级权限过滤
List<TextSegment> filtered = segments.stream()
.filter(seg -> hasPermission(user, seg))
.collect(Collectors.toList());
// 4. 审计日志
auditLog.record(user, question, filtered);
return generateAnswer(question, filtered);
}
private boolean hasPermission(User user, TextSegment segment) {
String department = segment.metadata().get("department");
String level = segment.metadata().get("confidentialLevel");
return user.getDepartment().equals(department)
&& user.getClearanceLevel() >= Integer.parseInt(level);
}
}
6.3 监控与可观测性
6.3.1 指标收集
@Component
public class RAGMetrics {
private final MeterRegistry registry;
public RAGMetrics(MeterRegistry registry) {
this.registry = registry;
}
public void recordQuery(String query, long latency, boolean success) {
// 查询延迟
registry.timer("rag.query.latency")
.record(latency, TimeUnit.MILLISECONDS);
// 成功率
registry.counter("rag.query.total",
"status", success ? "success" : "failure"
).increment();
// 查询长度分布
registry.summary("rag.query.length")
.record(query.length());
}
public void recordRetrieval(int resultCount, double avgScore) {
// 检索结果数
registry.gauge("rag.retrieval.resultCount", resultCount);
// 平均相似度分数
registry.gauge("rag.retrieval.avgScore", avgScore);
}
public void recordLLMUsage(int promptTokens, int completionTokens) {
// Token使用量
registry.counter("llm.tokens.prompt").increment(promptTokens);
registry.counter("llm.tokens.completion").increment(completionTokens);
// 成本估算(GPT-4为例:$0.03/1K prompt, $0.06/1K completion)
double cost = (promptTokens * 0.03 + completionTokens * 0.06) / 1000;
registry.counter("llm.cost.usd").increment(cost);
}
}
6.3.2 分布式追踪
@Aspect
@Component
public class RAGTracingAspect {
@Autowired
private Tracer tracer;
@Around("@annotation(traced)")
public Object trace(ProceedingJoinPoint pjp, Traced traced) throws Throwable {
Span span = tracer.nextSpan()
.name(traced.value())
.start();
try (Tracer.SpanInScope ws = tracer.withSpan(span)) {
// 添加标签
span.tag("component", "rag");
span.tag("method", pjp.getSignature().getName());
Object result = pjp.proceed();
span.tag("status", "success");
return result;
} catch (Exception e) {
span.tag("status", "error");
span.tag("error", e.getMessage());
throw e;
} finally {
span.end();
}
}
}
// 使用示例
@Service
public class RAGService {
@Traced("rag.retrieve")
public List<Content> retrieve(String query) {
// 检索逻辑
}
@Traced("rag.generate")
public String generate(String query, List<Content> context) {
// 生成逻辑
}
}
6.4 成本控制
6.4.1 智能降级
@Service
public class CostAwareRAGService {
public String answer(String question) {
// 1. 检查缓存
Optional<String> cached = cache.get(question);
if (cached.isPresent()) {
metrics.recordCacheHit();
return cached.get();
}
// 2. 简单问题用小模型
if (isSimpleQuestion(question)) {
return answerWithGPT35(question); // 便宜10倍
}
// 3. 复杂问题用大模型
return answerWithGPT4(question);
}
private boolean isSimpleQuestion(String question) {
// 问题长度
if (question.length() < 50) return true;
// 关键词匹配
if (faqMatcher.hasDirectMatch(question)) return true;
// 使用小模型判断复杂度
return complexityClassifier.classify(question)
== Complexity.SIMPLE;
}
}
6.4.2 Token优化
@Service
public class TokenOptimizer {
public String optimizePrompt(String systemMessage, String context) {
// 1. 压缩系统提示
String compressedSystem = compressSystemMessage(systemMessage);
// 2. 截断过长上下文
String truncatedContext = truncateContext(
context,
2000 // 最多2000 tokens
);
// 3. 移除冗余信息
String cleaned = removeRedundancy(truncatedContext);
return compressedSystem + "\n\n" + cleaned;
}
private String truncateContext(String context, int maxTokens) {
Tokenizer tokenizer = new OpenAiTokenizer();
List<Integer> tokens = tokenizer.encode(context).tokens();
if (tokens.size() <= maxTokens) {
return context;
}
// 保留最重要的部分(开头和相关度最高的)
return tokenizer.decode(tokens.subList(0, maxTokens));
}
}
6.4.3 成本监控和报警
@Service
public class CostMonitor {
@Scheduled(fixedRate = 60000) // 每分钟
public void checkCost() {
CostStatistics stats = calculateCurrentCost();
// 按服务统计
log.info("成本统计 - GPT-4: ${}, GPT-3.5: ${}, 嵌入: ${}",
stats.getGpt4Cost(),
stats.getGpt35Cost(),
stats.getEmbeddingCost()
);
// 检查是否超预算
if (stats.getTotalCost() > budgetThreshold) {
alertService.sendAlert(
"AI成本超预算",
String.format("当前消耗:$%.2f,预算:$%.2f",
stats.getTotalCost(),
budgetThreshold)
);
// 自动降级到便宜模型
switchToEconomyMode();
}
}
}
第七章:常见问题与最佳实践
7.1 常见问题FAQ
Q1: RAG检索不到相关文档怎么办?
排查步骤:
// 1. 检查文档是否正确索引
@Test
public void debugIndexing() {
// 查看存储的文档数量
long count = embeddingStore.count();
log.info("索引文档数:{}", count);
// 测试检索(不设阈值)
List<EmbeddingMatch<TextSegment>> all =
embeddingStore.findRelevant(
testEmbedding,
10,
0.0 // 无阈值
);
all.forEach(match ->
log.info("Score: {}, Text: {}",
match.score(),
match.embedded().text().substring(0, 100))
);
}
// 2. 调整相似度阈值
ContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.minScore(0.3) // 降低阈值
.maxResults(10)
.build();
// 3. 使用混合检索
// (参考3.3.5章节)
Q2: LLM响应太慢怎么办?
优化方案:
- 流式响应:让用户看到实时生成
- 并行处理:检索和其他操作并行
- 缓存:相同问题直接返回
- 小模型:简单问题用GPT-3.5
// 流式响应示例
@Service
public class StreamingService {
public Flux<String> answerStreaming(String question) {
return Flux.create(sink -> {
StreamingChatModel model = // ...
model.generate(question, new StreamingResponseHandler<>() {
@Override
public void onNext(String token) {
sink.next(token);
}
@Override
public void onComplete(Response<AiMessage> response) {
sink.complete();
}
@Override
public void onError(Throwable error) {
sink.error(error);
}
});
});
}
}
Q3: 成本太高怎么办?
降本策略:
- 缓存相同查询:减少重复调用
- 使用便宜模型:简单任务用GPT-3.5-turbo
- 本地嵌入模型:用Ollama替代OpenAI嵌入
- 批量处理:减少API调用次数
- Prompt优化:减少token使用
Q4: Agent执行失败怎么办?
常见原因和解决:
-
工具描述不清:LLM不知道何时用
- 解决:写清晰的@Tool描述和参数说明
-
工具返回格式混乱:LLM无法理解
- 解决:统一返回格式,用结构化数据
-
超时:工具执行太久
- 解决:设置超时,提供fallback
@Tool("查询天气")
public String getWeather(String city) {
try {
return CompletableFuture
.supplyAsync(() -> weatherApi.get(city))
.get(5, TimeUnit.SECONDS); // 5秒超时
} catch (TimeoutException e) {
return "天气服务暂时不可用,请稍后再试";
}
}
7.2 开发最佳实践
1. 提示词工程
// ❌ 不好的提示词
@SystemMessage("你是助手")
// ✅ 好的提示词
@SystemMessage("""
你是专业的客服助手,负责解答产品问题。
你的职责:
1. 基于知识库回答问题
2. 如果不确定,明确告知用户
3. 保持礼貌和专业
你不应该:
1. 编造信息
2. 讨论竞品
3. 承诺超出权限的事
""")
2. 错误处理
@Service
public class RobustRAGService {
public String answer(String question) {
try {
return doAnswer(question);
} catch (RateLimitException e) {
// API限流,稍后重试
return retryWithBackoff(() -> doAnswer(question));
} catch (ModelOverloadedException e) {
// 模型过载,降级到备用模型
return answerWithBackupModel(question);
} catch (Exception e) {
// 记录详细错误
log.error("回答失败", e);
// 返回友好错误信息
return "抱歉,系统繁忙,请稍后再试";
}
}
}
3. 测试策略
@SpringBootTest
public class RAGServiceTest {
// 单元测试:测试组件
@Test
public void testDocumentSplitter() {
Document doc = new Document("...");
List<TextSegment> segments = splitter.split(doc);
assertThat(segments).isNotEmpty();
assertThat(segments.get(0).text().length())
.isLessThanOrEqualTo(500);
}
// 集成测试:测试端到端
@Test
public void testRAGPipeline() {
String question = "LangChain4j是什么?";
String answer = ragService.answer(question);
assertThat(answer).containsIgnoringCase("LangChain4j");
assertThat(answer).containsIgnoringCase("Java");
}
// 回归测试:固定测试集
@Test
public void testQualityRegression() {
List<TestCase> cases = loadTestCases();
for (TestCase testCase : cases) {
String answer = ragService.answer(testCase.getQuestion());
// 评估答案质量
double score = evaluator.evaluate(
testCase.getExpectedAnswer(),
answer
);
assertThat(score).isGreaterThan(0.8);
}
}
}
4. 版本管理
@Configuration
public class VersionedRAGConfig {
// 支持多版本共存
@Bean("rag-v1")
public RAGService ragV1() {
return RAGService.builder()
.version("v1")
.strategy(SimpleRAG)
.build();
}
@Bean("rag-v2")
public RAGService ragV2() {
return RAGService.builder()
.version("v2")
.strategy(AdvancedRAG) // 新策略
.build();
}
// A/B测试
@Bean
public RAGService adaptiveRAG() {
return (question, user) -> {
if (abTestService.isInExperiment(user, "rag-v2")) {
return ragV2().answer(question);
}
return ragV1().answer(question);
};
}
}
参考资料:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)