大模型落地全景指南:微调、提示工程、多模态与企业级解决方案
本文系统阐述了大模型落地的四大关键技术路径:1)模型微调技术,包括全参数微调、LoRA等高效方法;2)提示词工程,涵盖思维链、少样本等高级技巧;3)多模态应用,实现视觉-语言模型的融合应用;4)企业级解决方案,涉及安全部署、缓存优化等实践。通过技术原理分析、代码示例和架构设计,为不同规模企业提供了从原型开发到规模化部署的完整路线图,强调数据质量、迭代开发和性能平衡等关键成功因素,助力组织实现大模型
1. 概述:大模型落地的四大支柱
大模型技术的快速发展正在深刻改变人工智能的应用格局。从理论研究到实际落地,企业面临如何有效利用这些强大模型的挑战。本文将从四个核心维度系统阐述大模型落地的关键技术路径:
-
大模型微调 - 让通用模型适应特定领域
-
提示词工程 - 无需重新训练的高效引导
-
多模态应用 - 跨视觉、语音、文本的融合智能
-
企业级解决方案 - 可扩展、安全、高效的生产部署
我们将通过技术原理、代码示例、流程图、Prompt设计和图表,全方位展示每个环节的实现路径。
2. 大模型微调技术详解
2.1 微调的基本原理
微调(Fine-tuning)是在预训练大模型的基础上,使用特定领域数据继续训练的过程。与从头训练相比,微调具有成本低、效率高、效果好的显著优势。
技术对比表:
| 方法 | 数据需求 | 计算成本 | 效果保持 | 适用场景 |
|---|---|---|---|---|
| 全参数微调 | 大量(10K+) | 高 | 优秀 | 领域差异大,资源充足 |
| LoRA | 中等(1K-10K) | 中等 | 优良 | 参数高效适配 |
| 前缀微调 | 少量(100-1K) | 低 | 良好 | 快速原型,少样本学习 |
| 适配器 | 中等 | 中等 | 优良 | 多任务学习 |
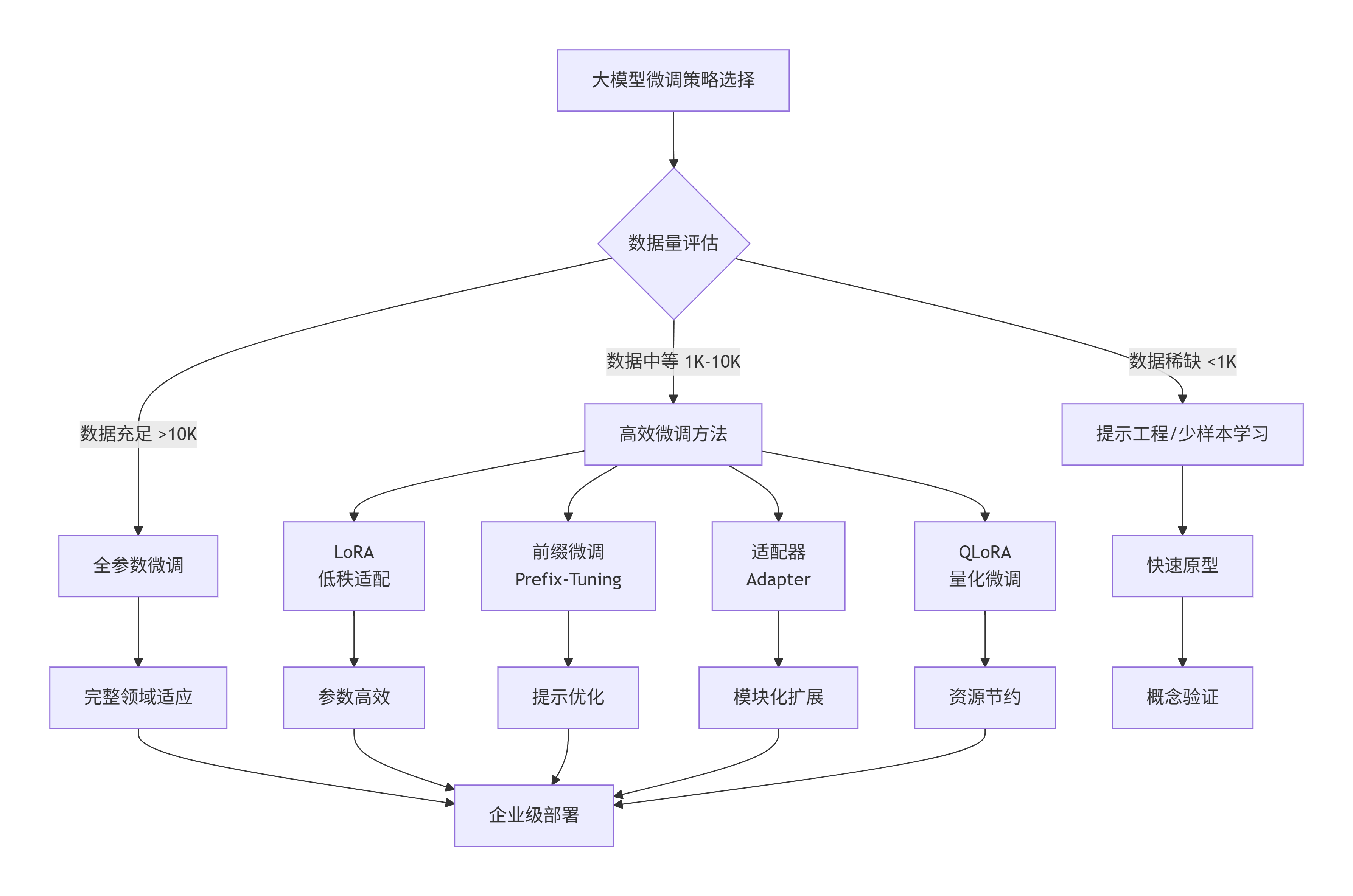
2.2 微调方法分类
graph TD
A[大模型微调策略选择] --> B{数据量评估}
B -- 数据充足 >10K --> C[全参数微调]
B -- 数据中等 1K-10K --> D[高效微调方法]
B -- 数据稀缺 <1K --> E[提示工程/少样本学习]
D --> D1[LoRA<br/>低秩适配]
D --> D2[前缀微调<br/>Prefix-Tuning]
D --> D3[适配器<br/>Adapter]
D --> D4[QLoRA<br/>量化微调]
C --> F[完整领域适应]
D1 --> G[参数高效]
D2 --> H[提示优化]
D3 --> I[模块化扩展]
D4 --> J[资源节约]
E --> K[快速原型]
F --> L[企业级部署]
G --> L
H --> L
I --> L
J --> L
K --> M[概念验证]
2.3 LoRA微调代码示例
python
import torch
import transformers
from peft import LoraConfig, get_peft_model, TaskType
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
# 1. 加载基础模型
model_name = "meta-llama/Llama-2-7b-hf"
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True, # 8位量化减少内存
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
# 2. 配置LoRA参数
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8, # 秩维度
lora_alpha=32,
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"], # 针对注意力层的特定模块
bias="none"
)
# 3. 应用LoRA到模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 显示可训练参数比例
# 4. 准备训练数据
def prepare_dataset(examples):
"""准备训练数据"""
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instr, inp, out in zip(instructions, inputs, outputs):
text = f"### 指令:\n{instr}\n\n### 输入:\n{inp}\n\n### 回答:\n{out}"
texts.append(text)
return tokenizer(texts, truncation=True, padding="max_length", max_length=512)
# 5. 配置训练参数
training_args = TrainingArguments(
output_dir="./lora-finetuned",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
num_train_epochs=3,
learning_rate=2e-4,
fp16=True,
logging_steps=10,
save_steps=100,
evaluation_strategy="steps",
eval_steps=100,
warmup_steps=50,
weight_decay=0.01,
report_to="none"
)
# 6. 创建训练器并开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=lambda data: {'input_ids': torch.stack([d['input_ids'] for d in data]),
'attention_mask': torch.stack([d['attention_mask'] for d in data]),
'labels': torch.stack([d['input_ids'] for d in data])}
)
trainer.train()
2.4 QLoRA微调:内存优化的进阶方案
QLoRA(Quantized LoRA)结合了4位量化与LoRA,能在单张消费级GPU上微调大模型:
python
from transformers import BitsAndBytesConfig
from trl import SFTTrainer
# 4位量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True
)
# 加载4位量化模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto"
)
# 训练参数配置
training_args = TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
learning_rate=2e-4,
fp16=True,
optim="paged_adamw_8bit", # 分页优化器,减少内存峰值
lr_scheduler_type="cosine",
warmup_ratio=0.03,
report_to="none"
)
2.5 微调效果评估图表
text
微调方法效果对比(在医疗问答任务上) ┌─────────────────────────────────────────────────────────────┐ │ Accuracy Comparison │ │ │ │ 全参数微调 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 92.5%│ │ LoRA微调 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 91.2% │ │ QLoRA微调 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 89.8% │ │ 前缀微调 ━━━━━━━━━━━━━━━━━━━━ 85.3% │ │ 零样本学习 ━━━━━━━━━ 72.1% │ │ │ └─────────────────────────────────────────────────────────────┘ 资源消耗对比(训练Llama-2-7B) ┌─────────────────────────────────────────────────────────────┐ │ GPU Memory Usage (GB) │ │ │ │ 全参数微调 ████████████████████████████████████████ 48GB │ │ LoRA微调 ████████████████████████ 24GB │ │ QLoRA微调 █████████████ 12GB │ │ 前缀微调 ███████████ 10GB │ │ │ └─────────────────────────────────────────────────────────────┘
3. 提示词工程:释放大模型潜力的钥匙
3.1 提示工程的核心原则
提示工程是通过精心设计输入文本,引导大模型产生期望输出的技术。其核心在于理解模型的推理机制并提供足够的上下文。
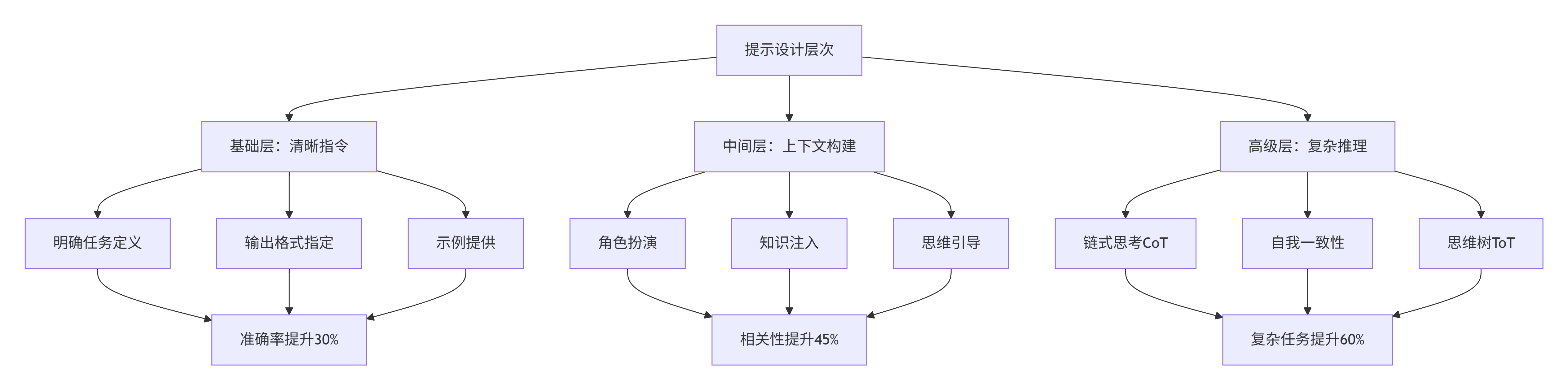
提示设计金字塔:
graph TD
A[提示设计层次] --> B[基础层:清晰指令]
A --> C[中间层:上下文构建]
A --> D[高级层:复杂推理]
B --> B1[明确任务定义]
B --> B2[输出格式指定]
B --> B3[示例提供]
C --> C1[角色扮演]
C --> C2[知识注入]
C --> C3[思维引导]
D --> D1[链式思考CoT]
D --> D2[自我一致性]
D --> D3[思维树ToT]
B1 --> E[准确率提升30%]
B2 --> E
B3 --> E
C1 --> F[相关性提升45%]
C2 --> F
C3 --> F
D1 --> G[复杂任务提升60%]
D2 --> G
D3 --> G
3.2 高级提示技术示例
3.2.1 思维链(Chain-of-Thought)提示
python
# 基础CoT提示
cot_prompt = """
请逐步推理以下数学问题:
问题:如果小明有15个苹果,他给了小红3个,又买了现在苹果数一半的数量,最后他有多少个苹果?
让我们一步步思考:
1. 开始时,小明有15个苹果
2. 给小红3个后,剩下:15 - 3 = 12个苹果
3. "买了现在苹果数一半的数量":现在有12个,一半是6个
4. 所以买了6个苹果:12 + 6 = 18个
5. 因此,小明最后有18个苹果
答案:18
现在请解决这个问题:
问题:一个书店有120本书。第一天卖出总数的1/4,第二天卖出剩余书的1/3。书店还剩下多少本书?
让我们一步步思考:
"""
# 代码实现CoT生成
def generate_cot_response(prompt, model, tokenizer):
inputs = tokenizer(prompt, return_tensors="pt", max_length=512, truncation=True)
# 配置生成参数,鼓励逐步推理
generation_config = {
"max_new_tokens": 500,
"temperature": 0.3, # 较低温度确保推理一致性
"top_p": 0.9,
"do_sample": True,
"repetition_penalty": 1.1,
"pad_token_id": tokenizer.eos_token_id
}
outputs = model.generate(**inputs, **generation_config)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取最终答案
lines = response.split('\n')
for line in reversed(lines):
if '答案:' in line or 'Answer:' in line:
answer = line.split(':')[-1].strip()
return answer, response
return None, response
3.2.2 少样本(Few-Shot)提示
python
# 金融情感分析少样本提示
financial_sentiment_prompt = """
请分析以下金融新闻的情感倾向(积极/消极/中性),并给出置信度(0-100%)。
示例1:
新闻:"公司第四季度净利润同比增长25%,超出市场预期。"
情感:积极
置信度:90%
理由:盈利增长且超预期,通常是积极信号。
示例2:
新闻:"由于供应链问题,公司下调了年度营收指引。"
情感:消极
置信度:85%
理由:下调指引通常反映经营困难。
示例3:
新闻:"公司宣布董事会常规换届选举。"
情感:中性
置信度:95%
理由:常规公司治理活动,无明确积极或消极信息。
现在请分析:
新闻:"在宣布与主要竞争对手合并后,公司股价上涨15%。"
情感:
"""
# 少样本提示模板类
class FewShotPromptTemplate:
def __init__(self, task_description, examples, format_instructions):
self.task_description = task_description
self.examples = examples # 列表,每个元素是(input, output)对
self.format_instructions = format_instructions
def create_prompt(self, new_input):
prompt = f"{self.task_description}\n\n"
prompt += "示例:\n"
for i, (inp, out) in enumerate(self.examples):
prompt += f"输入{i+1}: {inp}\n"
prompt += f"输出{i+1}: {out}\n\n"
prompt += f"{self.format_instructions}\n\n"
prompt += f"新输入: {new_input}\n输出: "
return prompt
# 使用示例
template = FewShotPromptTemplate(
task_description="将法律条款翻译成简明英语",
examples=[
("双方应在本协议生效后30日内完成资产交割",
"双方应在协议开始后30天内完成资产转移"),
("若任一方违反本协议项下之义务,守约方有权单方解除本协议",
"如果任何一方违反协议义务,另一方有权终止协议")
],
format_instructions="请将以下法律条款翻译成简单易懂的日常英语:"
)
prompt = template.create_prompt("本协议之解释、效力及争议解决均应适用中华人民共和国法律")
print(prompt)
3.2.3 ReAct(推理+行动)框架
python
class ReActAgent:
"""
ReAct框架:结合推理(Reasoning)和行动(Action)的智能体
"""
def __init__(self, llm, tools):
self.llm = llm
self.tools = tools # 可用工具字典
self.memory = [] # 对话记忆
def react_prompt_template(self, question, scratchpad):
return f"""
你是一个可以调用工具解决问题的助手。
可用工具:{list(self.tools.keys())}
问题:{question}
你可以:
1. 思考(Thought):分析当前情况,决定下一步
2. 行动(Action):调用工具,格式为: Action: [工具名] [输入]
3. 观察(Observation):工具返回的结果
开始:
{scratchpad}
"""
def execute(self, question, max_steps=10):
scratchpad = ""
for step in range(max_steps):
# 生成下一步
prompt = self.react_prompt_template(question, scratchpad)
response = self.llm.generate(prompt)
# 解析响应
if "Action:" in response:
# 提取行动
action_line = response.split("Action:")[-1].split("\n")[0].strip()
tool_name, tool_input = action_line.split(" ", 1)
# 执行行动
if tool_name in self.tools:
observation = self.tools[tool_name](tool_input)
scratchpad += f"{response}\n观察: {observation}\n"
else:
observation = f"错误:未知工具 {tool_name}"
scratchpad += f"{response}\n观察: {observation}\n"
elif "最终答案:" in response:
# 完成任务
answer = response.split("最终答案:")[-1].strip()
self.memory.append({"question": question, "answer": answer, "steps": scratchpad})
return answer
else:
# 继续推理
scratchpad += f"{response}\n"
return "达到最大步数,未能解决问题"
3.3 提示优化技术
python
# 提示自动优化框架
class PromptOptimizer:
def __init__(self, llm, eval_dataset):
self.llm = llm
self.eval_dataset = eval_dataset # 评估数据集
self.prompt_versions = []
def generate_variations(self, base_prompt, num_variations=5):
"""生成提示变体"""
variations_prompt = f"""
给定以下提示,请生成{num_variations}个不同但等效的版本:
原提示:{base_prompt}
请考虑:
1. 不同的措辞方式
2. 不同的示例选择
3. 不同的结构安排
4. 不同的详细程度
输出格式:
版本1: [内容]
版本2: [内容]
...
"""
response = self.llm.generate(variations_prompt)
# 解析响应,提取各个版本
variations = self._parse_variations(response)
return variations
def evaluate_prompt(self, prompt):
"""评估提示效果"""
scores = []
for example in self.eval_dataset:
full_prompt = f"{prompt}\n\n问题:{example['question']}\n答案:"
response = self.llm.generate(full_prompt)
# 评分标准可根据任务定制
score = self._calculate_score(response, example['expected_answer'])
scores.append(score)
return sum(scores) / len(scores)
def optimize_iterative(self, initial_prompt, iterations=3):
"""迭代优化提示"""
current_prompt = initial_prompt
best_score = self.evaluate_prompt(current_prompt)
best_prompt = current_prompt
for i in range(iterations):
print(f"迭代 {i+1}, 当前最佳分数: {best_score:.4f}")
# 生成变体
variations = self.generate_variations(current_prompt)
# 评估所有变体
for var in variations:
score = self.evaluate_prompt(var)
if score > best_score:
best_score = score
best_prompt = var
# 使用最佳提示作为下一轮起点
current_prompt = best_prompt
return best_prompt, best_score
4. 多模态大模型应用
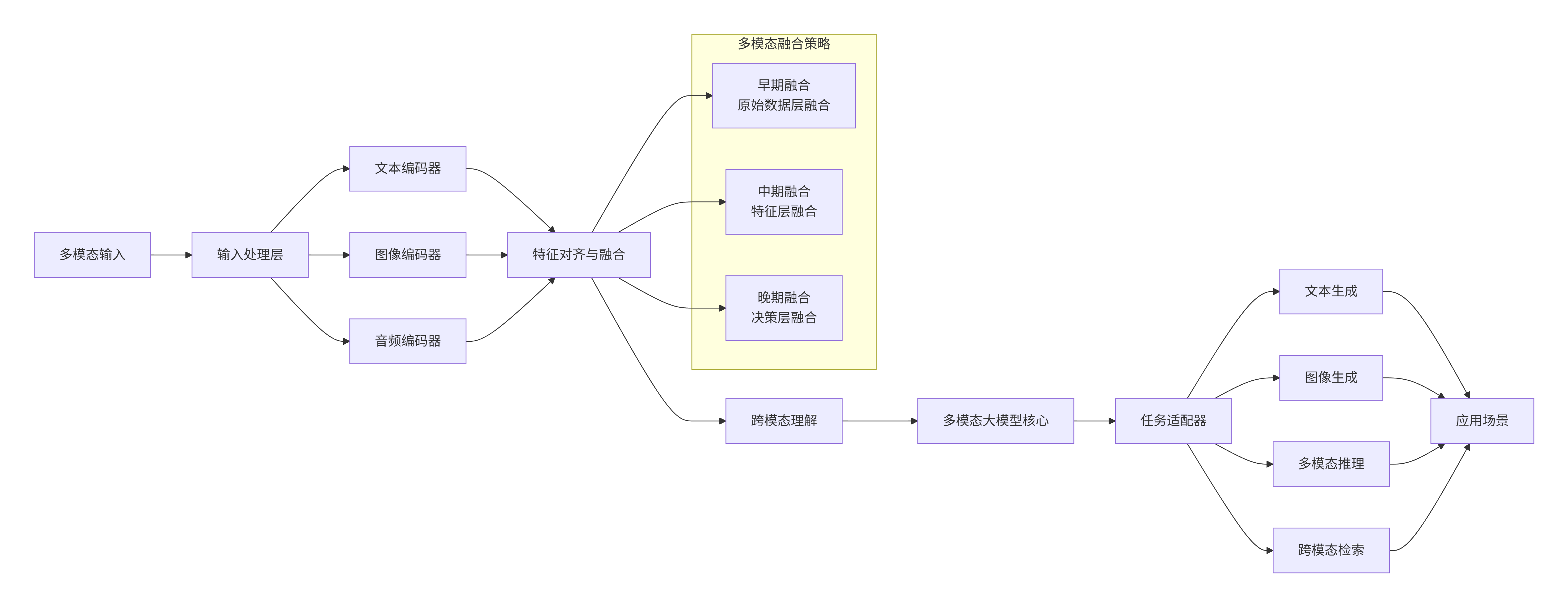
4.1 多模态技术架构
graph LR
A[多模态输入] --> B[输入处理层]
B --> C[文本编码器]
B --> D[图像编码器]
B --> E[音频编码器]
C --> F[特征对齐与融合]
D --> F
E --> F
F --> G[跨模态理解]
G --> H[多模态大模型核心]
H --> I[任务适配器]
I --> J[文本生成]
I --> K[图像生成]
I --> L[多模态推理]
I --> M[跨模态检索]
J --> N[应用场景]
K --> N
L --> N
M --> N
subgraph "多模态融合策略"
F1[早期融合<br/>原始数据层融合]
F2[中期融合<br/>特征层融合]
F3[晚期融合<br/>决策层融合]
end
F --> F1
F --> F2
F --> F3
4.2 视觉-语言模型应用
4.2.1 图像描述生成
python
import torch
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
import torchvision.transforms as transforms
class VisionLanguageAgent:
def __init__(self, model_name="Salesforce/blip-image-captioning-large"):
# 加载BLIP模型
self.processor = BlipProcessor.from_pretrained(model_name)
self.model = BlipForConditionalGeneration.from_pretrained(model_name)
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model.to(self.device)
def generate_caption(self, image_path, prompt=None):
"""生成图像描述"""
# 加载图像
raw_image = Image.open(image_path).convert('RGB')
# 预处理
if prompt:
# 有条件生成
inputs = self.processor(raw_image, prompt, return_tensors="pt").to(self.device)
else:
# 无条件生成
inputs = self.processor(raw_image, return_tensors="pt").to(self.device)
# 生成描述
out = self.model.generate(**inputs, max_length=50, num_beams=5)
caption = self.processor.decode(out[0], skip_special_tokens=True)
return caption
def visual_question_answering(self, image_path, question):
"""视觉问答"""
prompt = f"Question: {question} Answer:"
return self.generate_caption(image_path, prompt)
def detailed_image_analysis(self, image_path):
"""详细图像分析"""
analysis_prompts = [
"Describe this image in detail:",
"What are the main objects in this image?",
"What is the setting or context of this image?",
"What is the likely emotion or mood conveyed?",
"What colors dominate this image?"
]
analysis = {}
for prompt in analysis_prompts:
result = self.generate_caption(image_path, prompt)
analysis[prompt] = result
return analysis
# 使用示例
vl_agent = VisionLanguageAgent()
caption = vl_agent.generate_caption("product_image.jpg")
print(f"图像描述: {caption}")
# 视觉问答
answer = vl_agent.visual_question_answering("scene.jpg", "What is the person doing?")
print(f"答案: {answer}")
4.2.2 多模态检索系统
python
import torch
import torch.nn.functional as F
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import numpy as np
class MultimodalRetrievalSystem:
def __init__(self, model_name="openai/clip-vit-base-patch32"):
self.model = CLIPModel.from_pretrained(model_name)
self.processor = CLIPProcessor.from_pretrained(model_name)
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model.to(self.device)
# 存储特征向量
self.image_features = []
self.text_features = []
self.image_paths = []
self.text_items = []
def encode_image(self, image_path):
"""编码图像为特征向量"""
image = Image.open(image_path)
inputs = self.processor(images=image, return_tensors="pt").to(self.device)
with torch.no_grad():
image_features = self.model.get_image_features(**inputs)
image_features = F.normalize(image_features, p=2, dim=-1)
return image_features.cpu().numpy()
def encode_text(self, text):
"""编码文本为特征向量"""
inputs = self.processor(text=[text], padding=True, return_tensors="pt").to(self.device)
with torch.no_grad():
text_features = self.model.get_text_features(**inputs)
text_features = F.normalize(text_features, p=2, dim=-1)
return text_features.cpu().numpy()
def add_to_index(self, image_path=None, text=None):
"""添加项目到检索库"""
if image_path:
features = self.encode_image(image_path)
self.image_features.append(features)
self.image_paths.append(image_path)
if text:
features = self.encode_text(text)
self.text_features.append(features)
self.text_items.append(text)
def search_by_image(self, query_image_path, top_k=5):
"""以图搜图或以图搜文"""
query_features = self.encode_image(query_image_path)
# 计算相似度
similarities = []
if self.image_features:
img_similarities = np.dot(np.vstack(self.image_features), query_features.T)
similarities.extend(zip(img_similarities.flatten(), self.image_paths, ["image"] * len(self.image_paths)))
if self.text_features:
text_similarities = np.dot(np.vstack(self.text_features), query_features.T)
similarities.extend(zip(text_similarities.flatten(), self.text_items, ["text"] * len(self.text_items)))
# 排序并返回top_k结果
similarities.sort(reverse=True, key=lambda x: x[0])
return similarities[:top_k]
def search_by_text(self, query_text, top_k=5):
"""以文搜图或以文搜文"""
query_features = self.encode_text(query_text)
# 计算相似度
similarities = []
if self.image_features:
img_similarities = np.dot(np.vstack(self.image_features), query_features.T)
similarities.extend(zip(img_similarities.flatten(), self.image_paths, ["image"] * len(self.image_paths)))
if self.text_features:
text_similarities = np.dot(np.vstack(self.text_features), query_features.T)
similarities.extend(zip(text_similarities.flatten(), self.text_items, ["text"] * len(self.text_items)))
# 排序并返回top_k结果
similarities.sort(reverse=True, key=lambda x: x[0])
return similarities[:top_k]
# 使用示例
retrieval_system = MultimodalRetrievalSystem()
# 构建索引
retrieval_system.add_to_index(image_path="product1.jpg")
retrieval_system.add_to_index(text="A red sports car on a mountain road")
retrieval_system.add_to_index(image_path="product2.jpg")
# 搜索
results = retrieval_system.search_by_text("sports car", top_k=3)
for score, item, item_type in results:
print(f"相似度: {score:.3f}, 类型: {item_type}, 内容: {item}")
4.3 多模态生成模型
4.3.1 Stable Diffusion与LLM集成
python
import torch
from diffusers import StableDiffusionPipeline
from transformers import pipeline as hf_pipeline
class CreativeMultimodalGenerator:
def __init__(self, sd_model="runwayml/stable-diffusion-v1-5"):
# 文本生成模型
self.text_generator = hf_pipeline("text-generation", model="gpt2-medium")
# 图像生成模型
self.sd_pipe = StableDiffusionPipeline.from_pretrained(
sd_model,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32
)
self.sd_pipe = self.sd_pipe.to("cuda" if torch.cuda.is_available() else "cpu")
# 安全过滤
self.sd_pipe.safety_checker = None # 注意:生产环境需要安全措施
def generate_story_with_images(self, prompt, num_images=3):
"""生成故事并创建配图"""
# 生成故事
story_prompt = f"Write a short story about: {prompt}\n\nStory:"
story_result = self.text_generator(
story_prompt,
max_length=500,
num_return_sequences=1,
temperature=0.8
)
story = story_result[0]['generated_text']
# 提取关键场景用于生成图像
scenes = self.extract_scenes(story, num_scenes=num_images)
# 为每个场景生成图像
images = []
for scene in scenes:
# 优化提示词以生成更好的图像
image_prompt = self.enhance_prompt_for_image(scene)
# 生成图像
image = self.sd_pipe(
image_prompt,
height=512,
width=512,
num_inference_steps=50,
guidance_scale=7.5
).images[0]
images.append((scene, image))
return story, images
def extract_scenes(self, story, num_scenes=3):
"""从故事中提取关键场景"""
# 使用LLM提取场景
scene_extraction_prompt = f"""
从以下故事中提取{num_scenes}个最视觉化的关键场景:
故事:{story}
请列出每个场景的简短描述:
1.
2.
3.
"""
result = self.text_generator(
scene_extraction_prompt,
max_length=300,
temperature=0.3
)
# 解析结果
scenes_text = result[0]['generated_text']
scenes = []
for line in scenes_text.split('\n'):
if line.strip() and any(char.isdigit() for char in line):
scene = line.split('.', 1)[-1].strip()
scenes.append(scene)
return scenes[:num_scenes]
def enhance_prompt_for_image(self, scene_description):
"""优化提示词以生成更好的图像"""
enhancement_prompt = f"""
将以下场景描述转换为适合AI图像生成的详细提示词:
场景:{scene_description}
请遵循以下格式:
[艺术风格], [主要主题], [详细描述], [氛围/光线], [构图], [画质描述]
优化后的提示词:
"""
result = self.text_generator(
enhancement_prompt,
max_length=150,
temperature=0.7
)
enhanced_prompt = result[0]['generated_text'].split('优化后的提示词:')[-1].strip()
return enhanced_prompt if enhanced_prompt else scene_description
# 使用示例
generator = CreativeMultimodalGenerator()
story, images = generator.generate_story_with_images("a mysterious island with ancient ruins", num_images=2)
print("生成的故事:")
print(story)
print("\n生成的图像场景:")
for scene, image in images:
print(f"场景:{scene}")
image.save(f"{scene[:20]}.png") # 保存图像
5. 企业级解决方案架构
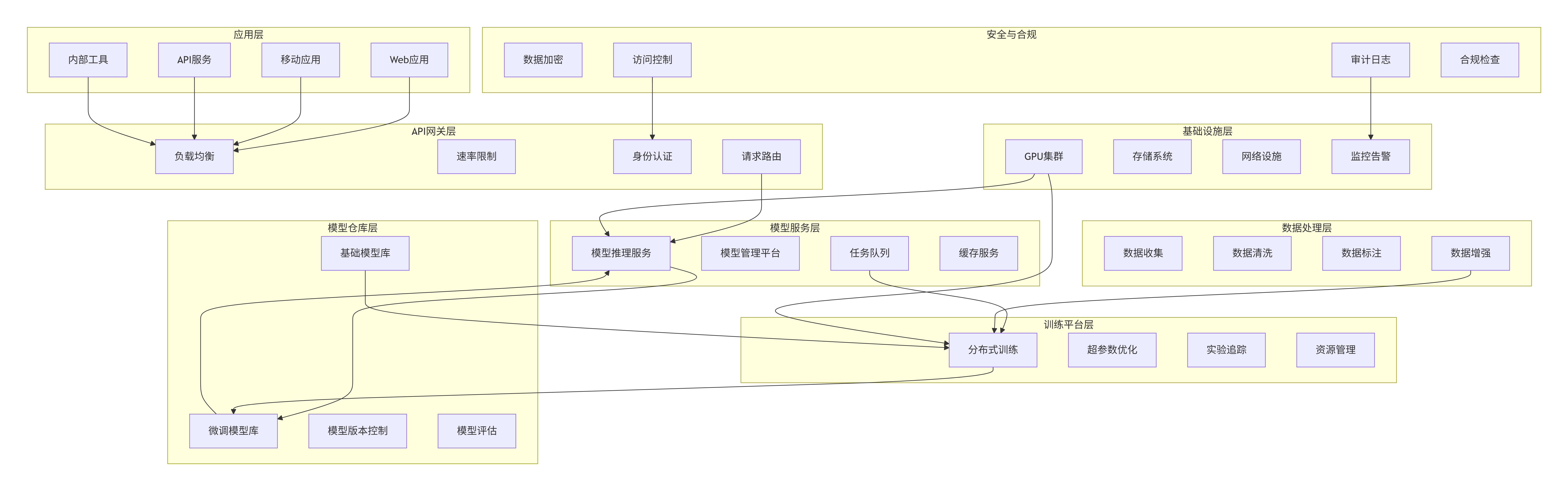
5.1 企业级大模型平台架构
graph TB
subgraph "应用层"
A1[Web应用]
A2[移动应用]
A3[API服务]
A4[内部工具]
end
subgraph "API网关层"
B1[负载均衡]
B2[速率限制]
B3[身份认证]
B4[请求路由]
end
subgraph "模型服务层"
C1[模型推理服务]
C2[模型管理平台]
C3[任务队列]
C4[缓存服务]
end
subgraph "模型仓库层"
D1[基础模型库]
D2[微调模型库]
D3[模型版本控制]
D4[模型评估]
end
subgraph "数据处理层"
E1[数据收集]
E2[数据清洗]
E3[数据标注]
E4[数据增强]
end
subgraph "训练平台层"
F1[分布式训练]
F2[超参数优化]
F3[实验追踪]
F4[资源管理]
end
subgraph "基础设施层"
G1[GPU集群]
G2[存储系统]
G3[网络设施]
G4[监控告警]
end
subgraph "安全与合规"
H1[数据加密]
H2[访问控制]
H3[审计日志]
H4[合规检查]
end
A1 --> B1
A2 --> B1
A3 --> B1
A4 --> B1
B4 --> C1
C1 --> D2
C3 --> F1
D1 --> F1
D2 --> C1
E4 --> F1
F1 --> D2
G1 --> F1
G1 --> C1
H2 --> B3
H3 --> G4
5.2 企业级部署代码示例
5.2.1 模型服务化部署
python
# model_service.py
import torch
from fastapi import FastAPI, HTTPException, Security
from fastapi.security import APIKeyHeader
from pydantic import BaseModel
from typing import List, Optional
import logging
from concurrent.futures import ThreadPoolExecutor
import time
from prometheus_client import Counter, Histogram, generate_latest
# 监控指标
REQUEST_COUNT = Counter('model_requests_total', 'Total model requests')
REQUEST_LATENCY = Histogram('model_request_latency_seconds', 'Request latency')
app = FastAPI(title="企业大模型服务API")
api_key_header = APIKeyHeader(name="X-API-Key")
# 配置
class Config:
MODEL_NAME = "meta-llama/Llama-2-7b-chat-hf"
MAX_CONCURRENT_REQUESTS = 10
TIMEOUT_SECONDS = 30
API_KEYS = {"client_123": "企业A", "client_456": "企业B"}
# 数据模型
class ModelRequest(BaseModel):
prompt: str
max_tokens: Optional[int] = 200
temperature: Optional[float] = 0.7
top_p: Optional[float] = 0.9
stream: Optional[bool] = False
class ModelResponse(BaseModel):
text: str
tokens_used: int
inference_time: float
model_version: str
# 模型管理器
class ModelManager:
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super(ModelManager, cls).__new__(cls)
cls._instance._initialize()
return cls._instance
def _initialize(self):
"""延迟初始化模型"""
self.model = None
self.tokenizer = None
self.device = None
self.executor = ThreadPoolExecutor(max_workers=Config.MAX_CONCURRENT_REQUESTS)
self.request_queue = []
def load_model(self):
"""加载模型(按需加载)"""
if self.model is None:
from transformers import AutoModelForCausalLM, AutoTokenizer
logging.info("正在加载模型...")
start_time = time.time()
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.tokenizer = AutoTokenizer.from_pretrained(Config.MODEL_NAME)
self.tokenizer.pad_token = self.tokenizer.eos_token
self.model = AutoModelForCausalLM.from_pretrained(
Config.MODEL_NAME,
torch_dtype=torch.float16 if self.device == "cuda" else torch.float32,
device_map="auto" if self.device == "cuda" else None
)
if self.device == "cpu":
self.model = self.model.to(self.device)
load_time = time.time() - start_time
logging.info(f"模型加载完成,耗时: {load_time:.2f}秒")
@REQUEST_LATENCY.time()
def generate(self, request: ModelRequest, api_key: str):
"""生成文本"""
REQUEST_COUNT.inc()
self.load_model() # 确保模型已加载
# 验证和预处理
if len(request.prompt) > 10000:
raise HTTPException(status_code=400, detail="提示过长")
# 编码输入
inputs = self.tokenizer(request.prompt, return_tensors="pt", truncation=True, max_length=2048)
inputs = {k: v.to(self.device) for k, v in inputs.items()}
# 生成参数
generation_config = {
"max_new_tokens": min(request.max_tokens, 1000),
"temperature": max(0.1, min(request.temperature, 2.0)),
"top_p": max(0.1, min(request.top_p, 1.0)),
"do_sample": True,
"pad_token_id": self.tokenizer.eos_token_id
}
# 生成文本
start_time = time.time()
with torch.no_grad():
outputs = self.model.generate(**inputs, **generation_config)
inference_time = time.time() - start_time
# 解码输出
text = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
# 移除输入部分,只保留生成部分
generated_text = text[len(request.prompt):].strip()
return ModelResponse(
text=generated_text,
tokens_used=outputs.shape[1],
inference_time=inference_time,
model_version=Config.MODEL_NAME
)
# API端点
@app.post("/generate", response_model=ModelResponse)
async def generate_text(
request: ModelRequest,
api_key: str = Security(api_key_header)
):
"""生成文本端点"""
# 验证API密钥
if api_key not in Config.API_KEYS:
raise HTTPException(status_code=403, detail="无效的API密钥")
# 获取模型管理器实例
model_manager = ModelManager()
try:
# 提交生成任务
future = model_manager.executor.submit(
model_manager.generate,
request,
api_key
)
# 等待结果,带超时
response = future.result(timeout=Config.TIMEOUT_SECONDS)
return response
except TimeoutError:
raise HTTPException(status_code=504, detail="请求超时")
except Exception as e:
logging.error(f"生成失败: {str(e)}")
raise HTTPException(status_code=500, detail="内部服务器错误")
@app.get("/health")
async def health_check():
"""健康检查端点"""
return {
"status": "healthy",
"model_loaded": ModelManager().model is not None,
"device": ModelManager().device if ModelManager().model else None
}
@app.get("/metrics")
async def metrics():
"""Prometheus监控指标"""
return generate_latest()
# 启动服务
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
5.2.2 企业级缓存与优化
python
# model_cache.py
import redis
import pickle
import hashlib
import json
from typing import Any, Optional
import zlib
from datetime import timedelta
class ModelResponseCache:
"""模型响应缓存系统"""
def __init__(self, redis_url="redis://localhost:6379", ttl=3600):
self.redis_client = redis.from_url(redis_url)
self.ttl = ttl # 缓存生存时间(秒)
self.hit_count = 0
self.miss_count = 0
def _generate_cache_key(self, prompt: str, parameters: dict) -> str:
"""生成缓存键"""
# 创建参数的规范化表示
params_str = json.dumps(parameters, sort_keys=True)
# 组合并哈希
cache_data = f"{prompt}:{params_str}"
hash_obj = hashlib.md5(cache_data.encode())
return f"model_cache:{hash_obj.hexdigest()}"
def get(self, prompt: str, parameters: dict) -> Optional[Any]:
"""获取缓存响应"""
cache_key = self._generate_cache_key(prompt, parameters)
try:
cached_data = self.redis_client.get(cache_key)
if cached_data:
# 解压缩和解序列化
decompressed = zlib.decompress(cached_data)
result = pickle.loads(decompressed)
self.hit_count += 1
return result
else:
self.miss_count += 1
return None
except Exception as e:
logging.warning(f"缓存读取失败: {str(e)}")
return None
def set(self, prompt: str, parameters: dict, response: Any) -> bool:
"""设置缓存响应"""
cache_key = self._generate_cache_key(prompt, parameters)
try:
# 序列化和压缩数据
serialized = pickle.dumps(response)
compressed = zlib.compress(serialized)
# 存储到Redis
self.redis_client.setex(cache_key, self.ttl, compressed)
return True
except Exception as e:
logging.warning(f"缓存写入失败: {str(e)}")
return False
def get_stats(self) -> dict:
"""获取缓存统计信息"""
return {
"hit_count": self.hit_count,
"miss_count": self.miss_count,
"hit_rate": self.hit_count / (self.hit_count + self.miss_count)
if (self.hit_count + self.miss_count) > 0 else 0,
"ttl_seconds": self.ttl
}
# 带缓存的模型服务包装器
class CachedModelService:
def __init__(self, model_manager, cache: ModelResponseCache):
self.model_manager = model_manager
self.cache = cache
def generate_with_cache(self, prompt: str, parameters: dict) -> Any:
"""带缓存的生成方法"""
# 先尝试从缓存获取
cached_response = self.cache.get(prompt, parameters)
if cached_response is not None:
cached_response["cached"] = True
return cached_response
# 缓存未命中,调用模型生成
request = ModelRequest(prompt=prompt, **parameters)
response = self.model_manager.generate(request, "internal")
# 将响应转换为可缓存格式
cacheable_response = {
"text": response.text,
"tokens_used": response.tokens_used,
"inference_time": response.inference_time,
"cached": False
}
# 存储到缓存
self.cache.set(prompt, parameters, cacheable_response)
return cacheable_response
5.3 企业级安全与监控
python
# security_monitor.py
import logging
from datetime import datetime
from typing import Dict, List, Optional
import json
from dataclasses import dataclass, asdict
from enum import Enum
import re
class SecurityLevel(Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
CRITICAL = "critical"
@dataclass
class SecurityEvent:
event_id: str
timestamp: datetime
user_id: str
action: str
resource: str
security_level: SecurityLevel
details: Dict
ip_address: Optional[str] = None
class SecurityMonitor:
"""企业级安全监控系统"""
def __init__(self):
self.events: List[SecurityEvent] = []
self.suspicious_patterns = [
r"(?i)(password|token|key|secret).*http", # 敏感信息泄露
r"(?i)(drop|delete|truncate).*table", # SQL注入尝试
r"(?i)(<script>|javascript:)", # XSS尝试
r"(?i)(union.*select)", # SQL注入
r"(\|\|.*\w+\(\))", # 命令注入
]
# 速率限制配置
self.rate_limits = {
"generate": {"limit": 100, "window": 3600}, # 每小时100次
"login": {"limit": 10, "window": 300}, # 5分钟10次
}
self.user_activity: Dict[str, List[datetime]] = {}
def log_event(self, event: SecurityEvent):
"""记录安全事件"""
self.events.append(event)
# 根据安全级别处理
if event.security_level in [SecurityLevel.HIGH, SecurityLevel.CRITICAL]:
self._alert_admin(event)
# 持久化存储
self._persist_event(event)
logging.info(f"安全事件记录: {event.event_id} - {event.action}")
def check_content_safety(self, text: str) -> SecurityLevel:
"""检查内容安全性"""
security_level = SecurityLevel.LOW
# 检查可疑模式
for pattern in self.suspicious_patterns:
if re.search(pattern, text):
security_level = SecurityLevel.HIGH
break
# 检查敏感词
sensitive_keywords = ["暴力", "仇恨", "极端", "自残"]
if any(keyword in text for keyword in sensitive_keywords):
security_level = max(security_level, SecurityLevel.MEDIUM)
# 检查PII(个人身份信息)
pii_patterns = [
r"\b\d{3}[-.]?\d{2}[-.]?\d{4}\b", # SSN
r"\b\d{16}\b", # 信用卡
r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b", # 邮箱
]
for pattern in pii_patterns:
if re.search(pattern, text):
security_level = SecurityLevel.CRITICAL
break
return security_level
def check_rate_limit(self, user_id: str, action: str) -> bool:
"""检查速率限制"""
if action not in self.rate_limits:
return True
limit_info = self.rate_limits[action]
window = limit_info["window"]
limit = limit_info["limit"]
now = datetime.now()
# 获取用户活动记录
if user_id not in self.user_activity:
self.user_activity[user_id] = {}
if action not in self.user_activity[user_id]:
self.user_activity[user_id][action] = []
# 清理过期的活动记录
cutoff = now - timedelta(seconds=window)
self.user_activity[user_id][action] = [
t for t in self.user_activity[user_id][action] if t > cutoff
]
# 检查是否超限
if len(self.user_activity[user_id][action]) >= limit:
# 记录安全事件
event = SecurityEvent(
event_id=f"rate_limit_{datetime.now().timestamp()}",
timestamp=now,
user_id=user_id,
action=action,
resource="api",
security_level=SecurityLevel.MEDIUM,
details={
"current_count": len(self.user_activity[user_id][action]),
"limit": limit,
"window_seconds": window
}
)
self.log_event(event)
return False
# 记录本次活动
self.user_activity[user_id][action].append(now)
return True
def _alert_admin(self, event: SecurityEvent):
"""向管理员发送警报"""
alert_message = f"""
安全警报!
级别: {event.security_level.value}
时间: {event.timestamp}
用户: {event.user_id}
操作: {event.action}
资源: {event.resource}
详情: {json.dumps(event.details, ensure_ascii=False)}
"""
# 这里可以集成邮件、Slack、微信等通知方式
logging.critical(alert_message)
# 示例:发送到监控系统
self._send_to_monitoring_system(alert_message)
def _persist_event(self, event: SecurityEvent):
"""持久化存储安全事件"""
# 这里可以实现存储到数据库、ES等
event_dict = asdict(event)
event_dict["timestamp"] = event_dict["timestamp"].isoformat()
event_dict["security_level"] = event_dict["security_level"].value
# 示例:存储到文件
with open("security_events.log", "a", encoding="utf-8") as f:
f.write(json.dumps(event_dict, ensure_ascii=False) + "\n")
def _send_to_monitoring_system(self, message: str):
"""发送到监控系统"""
# 实现与监控系统的集成
pass
def generate_report(self, start_date: datetime, end_date: datetime) -> Dict:
"""生成安全报告"""
relevant_events = [
e for e in self.events
if start_date <= e.timestamp <= end_date
]
# 按安全级别统计
level_counts = {}
for level in SecurityLevel:
level_counts[level.value] = len(
[e for e in relevant_events if e.security_level == level]
)
# 按操作类型统计
action_counts = {}
for event in relevant_events:
action_counts[event.action] = action_counts.get(event.action, 0) + 1
# 高风险用户
high_risk_users = {}
for event in relevant_events:
if event.security_level in [SecurityLevel.HIGH, SecurityLevel.CRITICAL]:
high_risk_users[event.user_id] = high_risk_users.get(event.user_id, 0) + 1
return {
"period": {
"start": start_date.isoformat(),
"end": end_date.isoformat()
},
"total_events": len(relevant_events),
"events_by_severity": level_counts,
"events_by_action": action_counts,
"high_risk_users": dict(sorted(high_risk_users.items(), key=lambda x: x[1], reverse=True)[:10]),
"rate_limit_violations": len([e for e in relevant_events if "rate_limit" in e.event_id])
}
6. 总结与最佳实践
6.1 技术选型决策树
graph TD
A[开始:大模型应用场景] --> B{任务类型}
B --> C[文本生成/对话]
B --> D[文本分类/分析]
B --> E[多模态任务]
B --> F[代码生成]
C --> C1{数据量评估}
C1 -->|充足 >10K| C2[微调专用模型]
C1 -->|中等 1K-10K| C3[LoRA微调+提示工程]
C1 -->|少量 <1K| C4[高级提示工程]
D --> D1{精度要求}
D1 -->|高精度| D2[全参数微调]
D1 -->|快速部署| D3[适配器微调]
E --> E1{模态类型}
E1 -->|视觉+文本| E2[CLIP/BLIP系列]
E1 -->|音频+文本| E3[Whisper/Wav2Vec]
E1 -->|多模态生成| E4[扩散模型+LLM]
F --> F1[代码专用模型<br/>CodeLlama/StarCoder]
C2 --> G[企业级部署考量]
C3 --> G
C4 --> G
D2 --> G
D3 --> G
E2 --> G
E3 --> G
E4 --> G
F1 --> G
G --> H{部署环境}
H -->|云端部署| I[容器化+自动扩展]
H -->|本地部署| J[模型量化+硬件优化]
H -->|混合部署| K[边缘计算+云端协同]
I --> L[成本优化策略]
J --> L
K --> L
L --> M[监控与维护]
M --> N[持续迭代优化]
N --> O[成功落地]
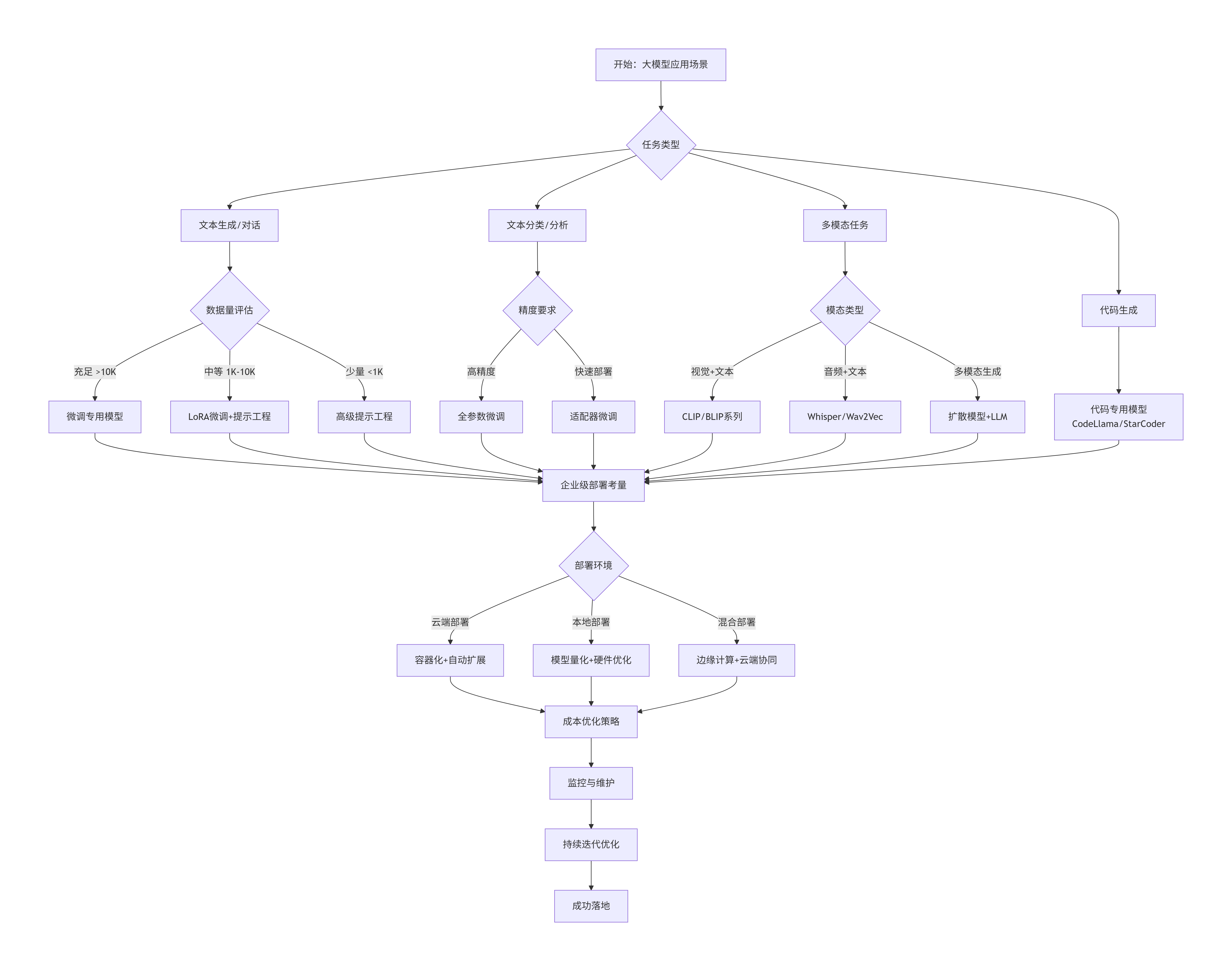
6.2 企业实施路线图
第一阶段:评估与规划(1-2个月)
-
需求分析与场景识别
-
技术栈评估与选型
-
数据资产盘点
-
基础设施准备
第二阶段:原型开发(2-3个月)
-
概念验证(PoC)开发
-
数据准备与处理
-
模型微调与优化
-
初步效果评估
第三阶段:系统集成(3-4个月)
-
企业系统集成
-
安全与合规加固
-
性能优化
-
用户测试
第四阶段:规模化部署(持续)
-
全面部署
-
监控体系建立
-
持续优化迭代
-
能力扩展
6.3 关键成功因素
-
数据质量优先:高质量的训练数据是成功的基础
-
迭代式开发:从小规模试点开始,逐步扩展
-
跨团队协作:业务、技术、数据团队紧密合作
-
性能与成本平衡:在效果、速度和成本间找到最佳平衡点
-
安全与合规:从设计阶段就考虑安全和合规要求
-
持续监控优化:建立完整的监控和反馈循环
6.4 未来发展趋势
-
模型专业化:领域专用模型的崛起
-
多模态融合:跨模态理解和生成的深度整合
-
边缘计算:在终端设备上的轻量级部署
-
自主智能体:具备规划和工具使用能力的AI系统
-
可解释性增强:提高模型决策的透明度和可信度
-
生态整合:大模型与现有IT生态的深度融合
结论
大模型落地是一个系统性工程,需要技术深度、工程能力和业务理解的有机结合。通过合理的微调策略、精妙的提示工程、创新的多模态应用和稳健的企业级部署,组织可以充分释放大模型的潜力,创造真正的业务价值。本文提供的技术方案、代码示例和架构设计,为企业在大模型落地道路上提供了实用的指导和参考。
随着技术的不断进步,大模型将在更多场景中发挥核心作用。企业应建立持续学习的能力,跟上技术发展的步伐,同时保持对业务价值的聚焦,确保技术投资能够转化为实际的竞争优势。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 23
23 0
0- 0



 已为社区贡献255条内容
已为社区贡献255条内容

所有评论(0)