【C++ 】STL详解(六)—手撸一个属于你的 list!
Node<T>allocatornullptr_sizeO(N)代码语言:javascriptAI代码解释。
·
- 节点的定义:每个节点
Node<T>存储数据以及前后指针,形成双向链表。 - 空间配置器:虽然在简化实现中忽略了
allocator,但实际应用中它有助于优化内存管理。 - 节点构造:节点通过构造函数初始化数据,并默认将指针设为
nullptr。 - 大小优化:通过
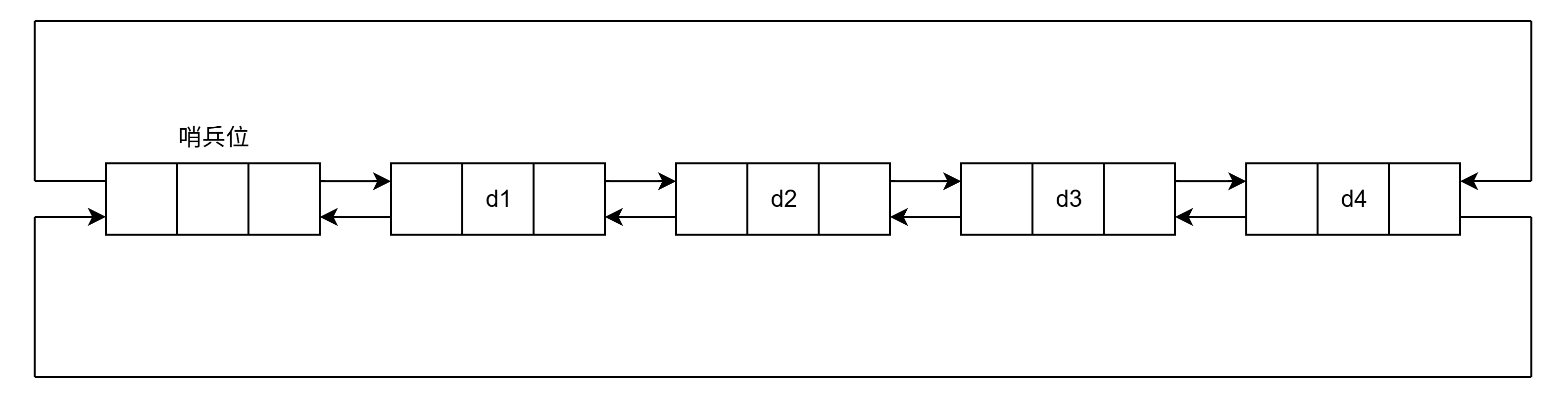
_size成员变量,避免了传统链表的O(N)大小计算,提升效率。 - 哨兵节点:链表总是包含一个哨兵节点,用于统一处理链表的插入、删除等操作。
- 显示实例化:通过模板实例化,可以灵活创建不同类型的链表。
代码语言:javascript
AI代码解释
namespace dh
{
// 定义一个结构体来表示双向链表中的节点
template<class T>
struct list_node
{
T _data; // 存储节点的数据,类型由模板参数'T'指定,支持任意类型的数据。
list_node<T>* _next; // 指向下一个节点的指针。
list_node<T>* _prev; // 指向上一个节点的指针。
list_node(const T& x = T())
: _data(x) // 初始化节点数据为传入参数'x',如果没有传入则默认初始化为T类型的默认值。
, _next(nullptr) // 初始化指向下一个节点的指针为nullptr(表示链表末尾)。
, _prev(nullptr) // 初始化指向上一个节点的指针为nullptr(表示链表头部)。
{}
};
//定义一个双向链表类
template<class T>
class list
{
typedef list_node<T> Node; // 为'list_node<T>'定义一个别名'Node',简化代码书写。
public:
private:
Node* sentinel;//指向哨兵节点的指针,作为链表的头节点,形成环形链表。
size_t _size;
};
}二、构造函数
当我们没有数据的时候 如何实现这个双线链表?(为了简化双向链表的实现,我们使用一个哨兵节点,该节点不存储实际数据,而是作为占位符,始终存在于链表中。哨兵节点的
prev和next指针都指向自己,形成一个环形链表结构。这样,无论链表是否为空,头尾操作都可以统一进行,避免了空链表和非空链表的特殊处理,从而简化了链表的插入、删除等操作逻辑。)

代码语言:javascript
AI代码解释
list()
{
// 创建哨兵节点,构造函数,初始化链表。
sentinel = new Node; // 创建一个新的节点作为哨兵节点,并为其动态分配内存。
sentinel->_next = sentinel; // 将哨兵节点的next指针指向自己,形成一个环形链表。
sentinel->_prev = sentinel; // 将哨兵节点的prev指针指向自己,形成环形链表。
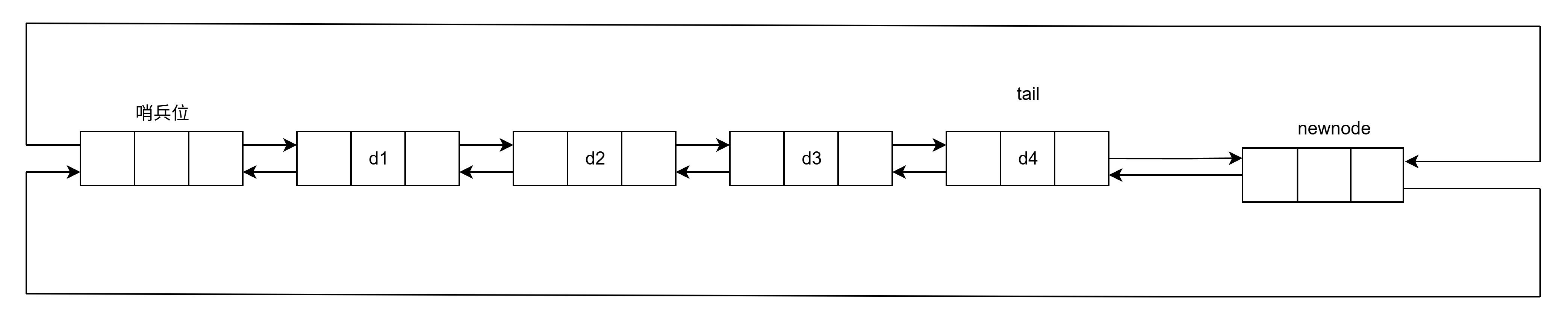
}push_back的实现
代码语言:javascript
AI代码解释
void push_back(const T& x)
{
// 在链表的尾部添加一个新的元素。
Node* newnode = new Node(x); // 创建一个新的节点 'newnode',并初始化其数据为'x'。
Node* tail = sentinel->_prev; // 获取当前链表的尾节点(即哨兵节点的前一个节点),tail指向最后一个有效节点。
tail->_next = newnode; // 将尾节点的next指针指向新创建的节点 'newnode',表示尾节点的后继节点是 'newnode'。
newnode->_prev = tail; // 将新节点的prev指针指向尾节点,表示新节点的前驱节点是 'tail'。
newnode->_next = sentinel; // 将新节点的next指针指向哨兵节点,表示新节点是链表的最后一个节点,形成环形结构。
sentinel->_prev = newnode; // 将哨兵节点的prev指针指向新节点 'newnode',表示哨兵节点的前驱节点是 'newnode',保持环形结构。
} 三、简单迭代器的模拟实现
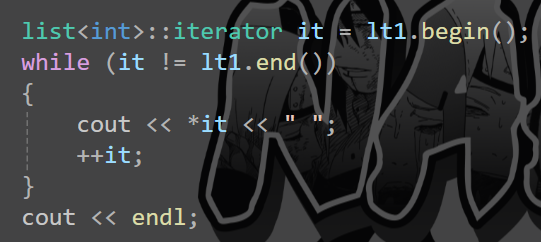
- 迭代器模拟指针行为: 迭代器本质上就是模拟指针的行为,通过解引用 (
*) 获取数据,通过递增 (++) 向后迭代获取下一个元素。 通过指针解引用获取数据,使用++移动到下一个元素。 std::list的迭代器与指针行为的差异:std::list是由多个独立的节点构成,每个节点包含数据和指向前后节点的指针。每个节点的物理位置是不连续的,因此不能像std::vector或std::string那样直接使用指针操作。在list中,迭代器指向的是 节点 而不是节点中的数据。通过解引用得到的是整个节点,而不是存储在节点中的数据。- 迭代器不能使用常规指针行为: 由于节点的内存位置不连续,使用
++操作符会导致访问到未知的空间,而不是简单地跳到下一个数据位置。由于std::list的节点在内存中分散,常规的指针行为(如*和++)无法直接工作,需要通过更复杂的方式来模拟指针行为。 - 自定义结构体封装节点指针: 为了能够在
std::list的迭代器中模拟指针的行为,我们需要一个结构体来封装节点的指针。该结构体通过重载*和++运算符来模拟指针操作。我们使用struct而不是class,因为我们需要频繁访问结构体的成员,且希望通过结构体的默认公开成员避免过多的友元函数或访问成员函数。 - 模板类迭代器的实现: 由于
std::list是一个模板类,存储的数据类型是动态的,因此我们需要为迭代器使用模板类__list_iterator<T>,而不是简单的__list_iterator。这种方式能够确保迭代器适应不同数据类型的std::list。 下面是你所要求的总结,并以点的形式接在前面的内容后面: - 避免命名冲突: 由于每个容器都可能有自己的迭代器类型,为了避免命名冲突,
std::list的迭代器被命名为__list_iterator,而不是简单使用iterator。如果容器使用统一的iterator名称,可能会与其他容器的迭代器类型产生冲突。因此,为了避免这种情况,std::list使用__list_iterator<T>来命名自己的迭代器类型,并通过typedef将其定义为iterator,提供给外部使用,确保与其他容器的迭代器不发生命名冲突。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)