兵棋对抗中的关键工作方向(逐渐细化中)
本文基于OODA理论构建兵棋推演智能体系统,分为四个关键技术层面:1)对抗空间表示,通过深度学习提取战场特征;2)态势评估推理,运用对手建模和预测算法;3)策略生成优化,针对完美/非完美信息博弈采用不同算法;4)行动协同控制,实现多智能体路径规划与协同执行。
OODA循环 的发明人是美国陆军上校约翰·包以德(1927-1997),因而又被称为 包以德循环。 OODA循环理论的基本观点是:武装冲突可以看作是敌对双方互相较量谁能更快更好地完成“观察—调整—决策—行动”的循环程序。 双方都要从观察开始,观察自己、观察环境和敌人。 基于观察,获取相关的外部信息,根据感知到的外部威胁,及时调整系统,做出应对决策,并采取相应行动。
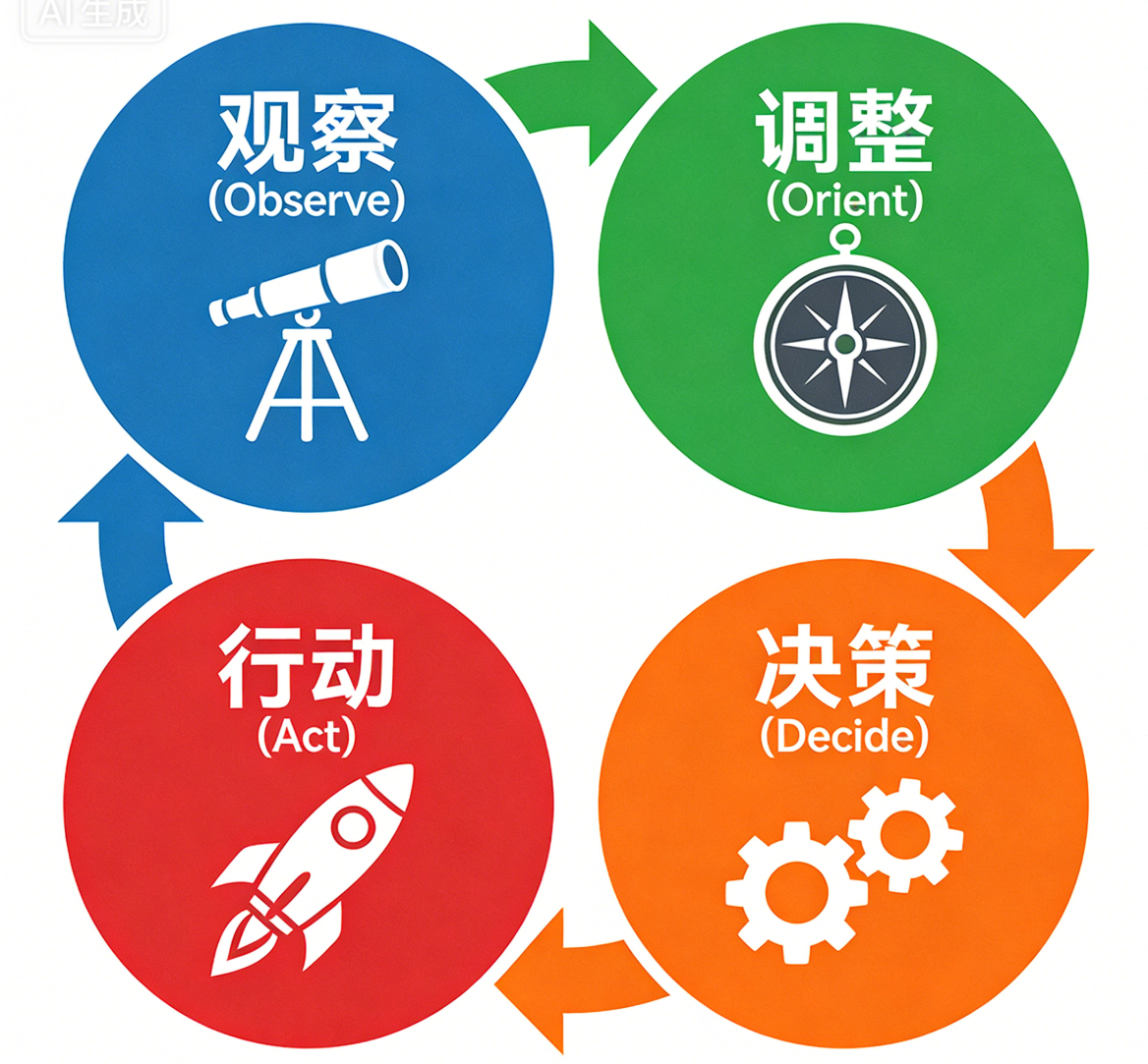
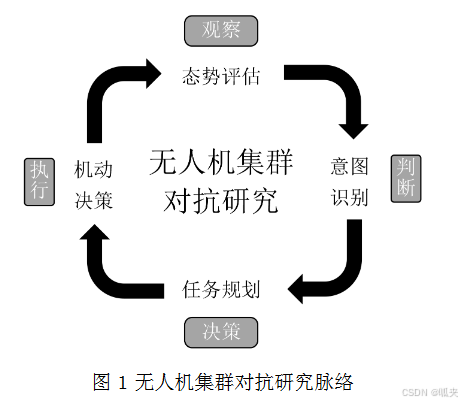
在兵棋对抗这一复杂系统中,基于OODA环(观察-判断-决策-行动)理论,可以将具体工作内容细化为以下四个核心层面及其关键技术要点,以确保智能体能够在高度不确定的虚拟战场环境中进行有效对抗。
一、对抗空间表示
对抗空间表示是构建兵棋推演环境的基础,关键在于如何将战场元素转化为计算机可处理的数据模型。
-
环境与算子特征提取
-
地图特征提取:利用卷积神经网络(CNN)自动学习地图中的地形、障碍物、关键通道等空间特征,为路径规划和战术选择提供支持。
-
算子特征编码:通过全连接网络或嵌入技术,对作战单元(如不同型号的飞机、舰艇)的属性(如速度、攻击力、防御力)进行高效编码。同时,可借助 Transformer 模型捕捉多个算子之间的全局依赖关系,或使用 LSTM 网络处理时序动态信息。
-
-
奖励函数设计
-
设计合理的奖励函数是驱动智能体学习正确行为的关键。除了基础的胜负、战损奖励外,可采用 RND(随机网络蒸馏) 来激励智能体探索未知或新颖的战场状态;使用 Hindsight 经验回放 技术,使智能体即使在没有达成最终目标的情况下,也能从过往经验中学习。
-
二、态势评估推理
态势评估推理旨在使智能体能够理解当前战场状况并预测未来变化,其核心工作在于对战场信息的深度加工。
-
对手建模与意图识别
-
通过如 DRON(深度强化对手网络)、GCN-RA(基于图卷积网络和心理特征)、GAT-LSTM(结合图注意力网络与LSTM)等算法,对对手的战术模式、决策风格和心理特征进行建模,从而推断其潜在意图和未来可能行动。
-
采用如 hierarchical_OM(基于心智理论的多层次对手建模)等算法,构建更深层次的对手模型。
-
-
战场预测与威胁评估
-
运用如 DFP(差分未来预测) 等算法,预测未来多个时间步的战场关键属性变化(如敌方兵力位置、资源消耗),为前瞻性决策提供依据。
-
基于实时态势数据,对敌方目标的威胁等级进行排序和计算,识别关键威胁点,为资源调配提供支持。相关技术包括“紫冬智剑”等群队AI共享算法实现的透视分析。
-
三 、策略生成优化
策略生成优化聚焦于在复杂博弈环境下为智能体生成最优行动方案,其工作内容根据信息条件的不同而有显著差异。
-
完美信息博弈:在战场信息完全透明的情况下,可应用 MCTS(蒙特卡洛树搜索) 进行大规模决策树搜索;使用 DDPG(深度确定性策略梯度)、PPO(近端策略优化) 等深度强化学习算法训练智能体策略。
-
非完美信息博弈:这是兵棋对抗的常态,信息不完全。需要采用 NFSP(神经虚拟自我博弈)、CFR(反事实遗憾最小化) 及其变体(如 Deep CFR)等专门算法来处理信息不对称问题。PSRO(策略空间响应预言) 框架也常用于寻找稳健的博弈论均衡策略。
-
多人博弈与协同:当对抗涉及多个智能体时,重点在于解决智能体间的协作与竞争关系。可采用 MADDPG、QMIX(其核心是单调值函数分解)等多智能体强化学习算法,实现智能体之间的有效协同。
四、行动协同控制
行动协同控制是将高层策略转化为具体、可执行动作的最后环节,确保作战意图能够精准落地。
-
路径规划与机动控制:为单个或多个作战单元规划从当前位置到目标位置的安全高效路径。经典算法如 A* 及其动态版本 D* 常用于解决此类问题。在多智能体场景下,还需考虑避碰和队形保持。
-
多智能体协同执行:通过 VDN(值分解网络)、QMIX 等算法,将团队整体的价值函数分解到每个智能体,从而学习出协同动作策略。在兵棋推演平台的推演模块中,会触发相应的动作响应、碰撞响应等,并统计战损比、资源消耗等对抗指标。
-
平台与推演管理:这包括利用推演回放分析模块对推演过程进行复盘;在军民融合兵棋推演平台中,还会通过辅助保障决策模块生成后勤物资消耗总量及分布,为保障指挥提供决策依据。
五、其他
--另一种总结
六大类工作地图(比 OODA 更细致):
Ⅰ. 对抗建模与不完全信息建模(Cognitive / Belief)
回答:我面对的对手是谁?他在想什么?我知道多少?
已经列了很多(DRON / hierarchical OM / 心智理论),这里升格一下:
可做工作包括:
-
对手策略表征
-
离散策略族(Aggressive / Defensive / Deceptive)
-
连续心理参数(风险偏好、理性度、欺骗概率)
-
-
信念更新
-
POMDP / I-POMDP
-
Bayesian belief update
-
Particle belief tracking
-
-
认知层建模
-
Theory of Mind(0阶/1阶/2阶)
-
Bounded rationality(有限理性)
-
📌 这是最核心、最有“研究味”的方向
Ⅱ. 对抗态势理解与评价(Situation Assessment)
回答:现在局势好还是坏?危险在哪里?机会在哪里?
你现在有“态势评估”“威胁评估”,但可以明确拆成三层:
-
状态抽象
-
地图 → 控制区 / 通道 / chokepoint
-
单位 → 编组 / 功能节点
-
-
价值评估
-
Control value(占控)
-
Attrition value(消耗)
-
Tempo / Initiative
-
-
不确定性评估
-
信息完整度
-
预测方差
-
最坏情况(robust value)
-
📌 很多评价者其实更能理解“态势评估”而不是“RL loss”。
Ⅲ. 策略生成与博弈求解(Game Solving / Policy Search)
回答:在这个博弈结构下,我该怎么决策?
你列得非常全,我帮你换一个“研究友好”的分层方式:
| 博弈维度 | 可做工作 |
|---|---|
| 信息结构 | 完美 / 非完美 / 延迟 / 噪声 |
| 参与者 | 两人 / 多人 / 联盟 |
| 关系 | 零和 / 非零和 / 混合 |
| 时间 | 同步 / 异步 / 分层 |
| 解概念 | Nash / Stackelberg / Exploitability |
📌 研究工作 = 在某一维做假设简化,然后证明“更好”
Ⅳ. 学习机制与训练范式(Learning Paradigm)
回答:我怎么学得更快、更稳、更像人?
你现在主要是 RL,这里还能扩:
-
模仿 + 强化
-
Imitation → RL fine-tuning
-
Dataset aggregation (DAgger)
-
-
自博弈
-
Population-based training
-
League training
-
-
课程学习
-
想定复杂度递增
-
对手难度递进
-
-
跨想定泛化
-
Domain randomization
-
Zero-shot transfer
-
📌 这是工程 + 实验最容易出结果的地方。
Ⅴ. 协同与组织结构(Coordination / Command)
回答:多单位如何像“一个人”一样行动?
不只是 VDN / QMIX,还包括:
-
指挥层级建模
-
Commander–Executor
-
Task allocation
-
-
编组与角色
-
Scout / Striker / Support
-
-
通信约束
-
带宽限制
-
延迟
-
误传
-
📌 非常适合兵棋多单位系统。
Ⅵ. 评测、对抗与解释(Evaluation & Explainability)
回答:你这个 AI 到底好在哪?
-
Exploitability
-
Win-rate vs baseline
-
Strategy diversity
-
鲁棒性(对未知对手)
-
可解释性(策略图、热力图、决策路径)
📌 往往先信“评测”,再信“模型”。
参考:
对抗智能体人工智能算法索引_dron算法-CSDN博客
李德毅院士:用脑和认知科学解开博伊德环之谜 - 安全内参 | 决策者的网络安全知识库

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)