从0开始实现语言模型完成生成任务(bigram language model,neural network,MLP,BatchNorm,kaiming init,waveNet)
本文详细记录了从零构建神经网络语言模型生成英文名字的进阶之路:从基础的二元语法统计起步,逐步演进至包含 Embedding 层的 MLP,并通过 Kaiming 初始化与批归一化优化训练,最终实现 WaveNet 架构以捕捉长序列依赖。文章通过监控激活值与梯度分布的可视化手段,深入解析了模型从简单概率统计到深度特征提取的工程实践与数学原理。
本博客为博主学习Andrej Karpathy中Neural Networks:from zero to hero系列中做的笔记,在为自己梳理思路的同时希望也能为大家提供一些帮助。
目录
5.2.4、调试代码四(更新量与数据量之比随时间变化的动态监控图)
视频源地址:
(102) The spelled-out intro to language modeling: building makemore - YouTube![]() https://www.youtube.com/watch?v=PaCmpygFfXo&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ&index=2Building makemore Part 2: MLP (youtube.com)
https://www.youtube.com/watch?v=PaCmpygFfXo&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ&index=2Building makemore Part 2: MLP (youtube.com)![]() https://www.youtube.com/watch?v=TCH_1BHY58I&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ&index=3(102) Building makemore Part 3: Activations & Gradients, BatchNorm - YouTube
https://www.youtube.com/watch?v=TCH_1BHY58I&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ&index=3(102) Building makemore Part 3: Activations & Gradients, BatchNorm - YouTube![]() https://www.youtube.com/watch?v=P6sfmUTpUmc&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ&index=4
https://www.youtube.com/watch?v=P6sfmUTpUmc&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ&index=4
视频原作者Github源代码地址:
视频中涉及MLP模型架构的论文地址:
bengio03a.dvi (jmlr.org)![]() https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
视频中涉及何恺明(Kaiming)参数初始化论文地址:
1502.01852 (arxiv.org)![]() https://arxiv.org/pdf/1502.01852视频中涉及Batch Normalizaiton的论文地址:
https://arxiv.org/pdf/1502.01852视频中涉及Batch Normalizaiton的论文地址:
1502.03167 (arxiv.org)![]() https://arxiv.org/pdf/1502.03167
https://arxiv.org/pdf/1502.03167
视频中设计waveNet模型的论文地址:
1609.03499 (arxiv.org)![]() https://arxiv.org/pdf/1609.03499
https://arxiv.org/pdf/1609.03499
关于Kaiming init参考文档的网页地址:
关于batch normal参考文档的网页地址:
本博客将从0开始构建一个二元语法的概率模型(bigramModel)-->到简单的神经网络模型-->到多特征输入的MLP神经网络模型来完成一个名字的生成任务(即随机流式生成一个英语名字)-->并介绍不同的优化手段方法来更好地构建模型-->再介绍一些通过可视化诊断模型的方法-->并在最后实现一个waveNet模型来完成相同任务;作者的思路会用 "块引用" 与 "Thinking:" 标识,来回顾自己的思考过程同时希望给大家一个好的构建过程。
一、构建bigram language model进行生成
Thinking:在构建bigram language model之前,确定一下我们要做的事:我们的目标是构建一个模型完成一个随机生成名字的任务,用二元语法语言模型(即通过前一个字母(a,b,c...)预测后一个字母(a,b,c...),以此类推,直至名字(单词)生成完毕),所以 第一 我们需要对数据集进行预处理,再编辑数据集里每一个样本,标注好 开始 和 结尾 使模型知道什么时候结束;第二 从统计学抽象角度上,我们要做的是模拟一种概率分布(函数),即在名字生成中 每个字母后面一种字母的概率的分布,本质上是字母组合的分布(aa -> 0.002, ab -> 0.003 .... ba -> 0.03...)一共26*26种概率情况(不考虑开始符和结束符)。因此思路就明晰了:我们要把数据集每一个样本中的每两个字母取出来,统计字母组合(ab,ce,bb...)的数量(频数),之后把频数变为概率,之后根据此概率逐步生成字母组成一个单词,这样就达成目标了。
1.1、数据准备
1.1.1、数据预处理
首先下载数据集names.txt到本地同目录,用以下代码查看数据集前五的内容(样本)-->不同的英文名
words = open('names.txt','r').read().splitlines()
print(words[:5])
# ['emma', 'olivia', 'ava', 'isabella', 'sophia']接下来我们试着取出数据集中的每个样本,添加开始符与结束符("."),并把每个单词变为列表形式方便后续的任务
for w in words[:3]:
chs = ["."] + list(w) + ["."]
print(chs, type(chs))
'''
['.', 'e', 'm', 'm', 'a', '.'] <class 'list'>
['.', 'o', 'l', 'i', 'v', 'i', 'a', '.'] <class 'list'>
['.', 'a', 'v', 'a', '.'] <class 'list'>
'''1.1.2、 统计组合频数
计算字母组合的数量,并用字典b来存储统计结果(因为要建立从组合类别到数字的映射)。这里用zip方法(输入两个列表,比如对于第一个单词,输入['.', 'e', 'm', 'm', 'a', '.'] 和 ['e', 'm', 'm', 'a', '.'],输出迭代器同时取出组合 '.' 和 'e' ,当其中一个列表遍历完后(后者元素少一先遍历结束),一个for循环结束进行下一个单词['.', 'o', 'l', 'i', 'v', 'i', 'a', '.']的遍历,以此类推),这里b[bigram] = b.get(bigram, 0 ) + 1 中的 get(bigram, 0 )为当字典b里没有该组合则默认为0,有就+1。通过b,items()来查看前五个元素
b = {}
for w in words:
chs = ["."] + list(w) + ["."]
for ch1, ch2 in zip(chs, chs[1:]):
bigram = (ch1, ch2)
b[bigram] = b.get(bigram, 0) + 1
print(list(b.items())[:5])
'''
[(('.', 'e'), 1531),
(('e', 'm'), 769),
(('m', 'm'), 168),
(('m', 'a'), 2590),
(('a', '.'), 6640)]
'''用sorted方法按统计数量从大到小进行排序(原理为用lambda函数按照元素kv进行排序-->元素kv为元组 (('n', '.'), 6763),因为按照数量,所以为kv[1] --> 6763, 由于默认为从小到大而我们要求的是降序,所以为-kv[1] --> -6763,这样就可以-6763,-6640...-2,-1,0得到我们的排序了)
bigram_sort = sorted(b.items(), key = lambda kv : -kv[1])
print(bigram_sort[:10])
'''
[(('n', '.'), 6763),
(('a', '.'), 6640),
(('a', 'n'), 5438),
(('.', 'a'), 4410),
(('e', '.'), 3983),
(('a', 'r'), 3264),
(('e', 'l'), 3248),
(('r', 'i'), 3033),
(('n', 'a'), 2977),
(('.', 'k'), 2963)]
'''接下来我们要实现的是字母到索引,索引到字母的映射表,来方便我们后续的生成任务。通过c = ['.'] + sorted(list(set(''.join(words))))取出26个字母和".",然后用enumerate方法来建立迭代器,得到c2i(chars to index),i2c的两个字典
c = ['.'] + sorted(list(set(''.join(words))))
c2i = {s:i for i,s in enumerate(c)}
i2c = {i:s for i,s in enumerate(c)}
print(c2i)
'''
{'.': 0,
'a': 1,
'b': 2,
'c': 3,
'd': 4,
'e': 5,
'f': 6,
'g': 7,
'h': 8,
'i': 9,
'j': 10,
'k': 11,
'l': 12,
'm': 13,
'n': 14,
'o': 15,
'p': 16,
'q': 17,
'r': 18,
's': 19,
't': 20,
'u': 21,
'v': 22,
'w': 23,
'x': 24,
'y': 25,
'z': 26}
'''1.1.3 、用矩阵表示频数及其可视化
为了方便模型取数和之后的softmax频数到概率的转变,我们用一个27*27的方阵(矩阵)来表示我们统计的频数,这里用torch.zeros()方法进行实现
import torch
N = torch.zeros([27,27], dtype=torch.int32)
for w in words:
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
idx1 = c2i[ch1]
idx2 = c2i[ch2]
N[idx1,idx2] +=1
print(N)
'''
tensor([[ 0, 4410, 1306, 1542, 1690, 1531, 417, 669, 874, 591, 2422, 2963,
1572, 2538, 1146, 394, 515, 92, 1639, 2055, 1308, 78, 376, 307,
134, 535, 929],
[6640, 556, 541, 470, 1042, 692, 134, 168, 2332, 1650, 175, 568,
2528, 1634, 5438, 63, 82, 60, 3264, 1118, 687, 381, 834, 161,
182, 2050, 435],
[ 114, 321, 38, 1, 65, 655, 0, 0, 41, 217, 1, 0,
103, 0, 4, 105, 0, 0, 842, 8, 2, 45, 0, 0,
0, 83, 0],
[ 97, 815, 0, 42, 1, 551, 0, 2, 664, 271, 3, 316,
116, 0, 0, 380, 1, 11, 76, 5, 35, 35, 0, 0,
3, 104, 4],
[ 516, 1303, 1, 3, 149, 1283, 5, 25, 118, 674, 9, 3,
60, 30, 31, 378, 0, 1, 424, 29, 4, 92, 17, 23,
0, 317, 1],
[3983, 679, 121, 153, 384, 1271, 82, 125, 152, 818, 55, 178,
3248, 769, 2675, 269, 83, 14, 1958, 861, 580, 69, 463, 50,
132, 1070, 181],
[ 80, 242, 0, 0, 0, 123, 44, 1, 1, 160, 0, 2,
20, 0, 4, 60, 0, 0, 114, 6, 18, 10, 0, 4,
0, 14, 2],
[ 108, 330, 3, 0, 19, 334, 1, 25, 360, 190, 3, 0,
32, 6, 27, 83, 0, 0, 201, 30, 31, 85, 1, 26,
0, 31, 1],
[2409, 2244, 8, 2, 24, 674, 2, 2, 1, 729, 9, 29,
185, 117, 138, 287, 1, 1, 204, 31, 71, 166, 39, 10,
0, 213, 20],
[2489, 2445, 110, 509, 440, 1653, 101, 428, 95, 82, 76, 445,
1345, 427, 2126, 588, 53, 52, 849, 1316, 541, 109, 269, 8,
89, 779, 277],
[ 71, 1473, 1, 4, 4, 440, 0, 0, 45, 119, 2, 2,
9, 5, 2, 479, 1, 0, 11, 7, 2, 202, 5, 6,
0, 10, 0],
[ 363, 1731, 2, 2, 2, 895, 1, 0, 307, 509, 2, 20,
139, 9, 26, 344, 0, 0, 109, 95, 17, 50, 2, 34,
0, 379, 2],
[1314, 2623, 52, 25, 138, 2921, 22, 6, 19, 2480, 6, 24,
1345, 60, 14, 692, 15, 3, 18, 94, 77, 324, 72, 16,
0, 1588, 10],
[ 516, 2590, 112, 51, 24, 818, 1, 0, 5, 1256, 7, 1,
5, 168, 20, 452, 38, 0, 97, 35, 4, 139, 3, 2,
0, 287, 11],
[6763, 2977, 8, 213, 704, 1359, 11, 273, 26, 1725, 44, 58,
195, 19, 1906, 496, 5, 2, 44, 278, 443, 96, 55, 11,
6, 465, 145],
[ 855, 149, 140, 114, 190, 132, 34, 44, 171, 69, 16, 68,
619, 261, 2411, 115, 95, 3, 1059, 504, 118, 275, 176, 114,
45, 103, 54],
[ 33, 209, 2, 1, 0, 197, 1, 0, 204, 61, 1, 1,
16, 1, 1, 59, 39, 0, 151, 16, 17, 4, 0, 0,
0, 12, 0],
[ 28, 13, 0, 0, 0, 1, 0, 0, 0, 13, 0, 0,
1, 2, 0, 2, 0, 0, 1, 2, 0, 206, 0, 3,
0, 0, 0],
[1377, 2356, 41, 99, 187, 1697, 9, 76, 121, 3033, 25, 90,
413, 162, 140, 869, 14, 16, 425, 190, 208, 252, 80, 21,
3, 773, 23],
[1169, 1201, 21, 60, 9, 884, 2, 2, 1285, 684, 2, 82,
279, 90, 24, 531, 51, 1, 55, 461, 765, 185, 14, 24,
0, 215, 10],
[ 483, 1027, 1, 17, 0, 716, 2, 2, 647, 532, 3, 0,
134, 4, 22, 667, 0, 0, 352, 35, 374, 78, 15, 11,
2, 341, 105],
[ 155, 163, 103, 103, 136, 169, 19, 47, 58, 121, 14, 93,
301, 154, 275, 10, 16, 10, 414, 474, 82, 3, 37, 86,
34, 13, 45],
[ 88, 642, 1, 0, 1, 568, 0, 0, 1, 911, 0, 3,
14, 0, 8, 153, 0, 0, 48, 0, 0, 7, 7, 0,
0, 121, 0],
[ 51, 280, 1, 0, 8, 149, 2, 1, 23, 148, 0, 6,
13, 2, 58, 36, 0, 0, 22, 20, 8, 25, 0, 2,
0, 73, 1],
[ 164, 103, 1, 4, 5, 36, 3, 0, 1, 102, 0, 0,
39, 1, 1, 41, 0, 0, 0, 31, 70, 5, 0, 3,
38, 30, 19],
[2007, 2143, 27, 115, 272, 301, 12, 30, 22, 192, 23, 86,
1104, 148, 1826, 271, 15, 6, 291, 401, 104, 141, 106, 4,
28, 23, 78],
[ 160, 860, 4, 2, 2, 373, 0, 1, 43, 364, 2, 2,
123, 35, 4, 110, 2, 0, 32, 4, 4, 73, 2, 3,
1, 147, 45]], dtype=torch.int32)
'''视频中为了能够更直观地表示频数我们通过matplotlib库的以下两个方式进行可视化(可视化代码不做解释)
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(N)
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(16, 16))
plt.imshow(N, cmap='Blues')
for i in range(27):
for j in range(27):
chstr = i2c[i] + i2c[j]
plt.text(j, i, chstr, ha='center', va='bottom', color='gray')
plt.text(j, i, N[i, j].item(), ha='center', va='top', color='gray')
plt.axis('off')
plt.show() 由图可知组合"a.", "an", "n."的频数很高,也符合直觉
由图可知组合"a.", "an", "n."的频数很高,也符合直觉
1.2、 构建模型
1.2.1、将频数映射到概率
我们取出N的第一行(代表着"..", ".a", ".b", ".c" ... )进行分析,可知N为一个27*27的一个tensor变量,dtype为int32。如果我们要把它变为概率,必须先将int32转化为float类型来存储小数(int32取值范围为-2147483648到2147483647,不包括小数)
N1 = N[0,:]
print(N1)
'''
tensor([ 0, 4410, 1306, 1542, 1690, 1531, 417, 669, 874, 591, 2422, 2963,
1572, 2538, 1146, 394, 515, 92, 1639, 2055, 1308, 78, 376, 307,
134, 535, 929], dtype=torch.int32)
'''按以下方式得到概率
N1 = N[0,:]
N1.float()
N1 = N1 / N1.sum()
'''
tensor([0.0000, 0.1377, 0.0408, 0.0481, 0.0528, 0.0478, 0.0130, 0.0209, 0.0273,
0.0184, 0.0756, 0.0925, 0.0491, 0.0792, 0.0358, 0.0123, 0.0161, 0.0029,
0.0512, 0.0642, 0.0408, 0.0024, 0.0117, 0.0096, 0.0042, 0.0167, 0.0290])
'''同理可得,通过以下方式将整个矩阵按行(也可以按列,但为了方便计算选择按行)转为概率矩阵(实际含义为,每个字符后面字符的概率),这里的sum()方法中dim=1代表索引1在这里表示按行((27,27)-->(27,1))进行sum操作,keepdim=True代表保持维度不变,因为归一化(或求和)维度会“压缩”掉,形状减少一个维度((1,27)-->(1,)),虽然True或False都可以进行广播,但是推荐使用keepdim=True
P = N.float()
P /= (P + 1).sum(dim=1, keepdim=True)
pirnt(P[:3])
'''
tensor([[0.0000, 0.1376, 0.0407, 0.0481, 0.0527, 0.0478, 0.0130, 0.0209, 0.0273,
0.0184, 0.0755, 0.0924, 0.0490, 0.0792, 0.0357, 0.0123, 0.0161, 0.0029,
0.0511, 0.0641, 0.0408, 0.0024, 0.0117, 0.0096, 0.0042, 0.0167, 0.0290],
[0.1958, 0.0164, 0.0160, 0.0139, 0.0307, 0.0204, 0.0040, 0.0050, 0.0688,
0.0487, 0.0052, 0.0167, 0.0745, 0.0482, 0.1604, 0.0019, 0.0024, 0.0018,
0.0962, 0.0330, 0.0203, 0.0112, 0.0246, 0.0047, 0.0054, 0.0605, 0.0128],
[0.0427, 0.1201, 0.0142, 0.0004, 0.0243, 0.2451, 0.0000, 0.0000, 0.0153,
0.0812, 0.0004, 0.0000, 0.0385, 0.0000, 0.0015, 0.0393, 0.0000, 0.0000,
0.3151, 0.0030, 0.0007, 0.0168, 0.0000, 0.0000, 0.0000, 0.0311, 0.0000]])
'''1.2.2、 建立模型进行名字生成,模型推理(1)
我们使用torch.multinomial()方法进行名字生成,其通过参数p来输出相应概率的索引(概率越大,就越容易生成对应的索引)
p = P[0,:]
out = torch.multinomial(p, num_samples=5, replacement=True)
print(out)
# tensor([18, 1, 1, 18, 7])通过torch.Generator().manual.seed()方法来生成固定种子,来确定每次生成的随机数一致,定义一个函数来随机生成名字(通过对照映射表找到相应字符后一字符的分布概率,根据此概率进行抽样返回tensor变量a,用item()方法使其以int类型返回,再通过映射表返回索引对照的字符添加到name里直至遇到结束符),并运行10次
g = torch.Generator().manual_seed(2147483647)
def nomial(ad):
name = f'{ad}'
while True:
p = P[c2i[ad]]
a = torch.multinomial(p, num_samples=1, replacement=True, generator=g).item()
ad = i2c[a]
name += ad
if ad == '.':
break
print(name)
for i in range(10):
nomial('.')
'''
.mor.
.axx.
.minaymoryles.
.kondlaisah.
.anchshizarie.
.odaren.
.iaddash.
.h.
.jhinatien.
.egushl.
'''从结果上看生成的名字并不是特别理想,我们可以先与没有进行统计的模型(随机字母生成的方式)进行对比对照
g = torch.Generator().manual_seed(2147483647)
def nomial(ad):
name = f'{ad}'
while True:
# p = P[c2i[ad]]
p = torch.rand(27)
p /= p.sum()
a = torch.multinomial(p,num_samples=1,replacement=True,generator=g).item()
ad = i2c[a]
name += ad
if ad == '.':
break
print(name)
for i in range(10):
nomial('.')
'''
.qwtbbyxbrqppypvtzmfuaoulorcjudid.
.qomxmtzcvojbuceqjqfjgghfvnfiejsssjwoisgfizxms.
.hebw.
.bfjjxraiqipervivqefpqiq.
.deciabjtmoolc.
.yswvapmkmvttycgzdfxhwrnmcoelwzvmzxrqkgoupqpewstvkhoudkwvhdlsuzymsucvwsqebdyglgouhj.
.hkiplnnqkoomaorcnz.
.htzry.
.zleifgn.
.ogzzvvlpxxpqwhvbxavtcaoxwliryowgtughqrigmnw.
'''这样一对比,我构建的二元语法模型生成的名字还是较优的!
二、构建神经网络模型进行生成
当我们建立了序列生成的基本范式,接下来就构建一个神经网络来实现这个任务吧
Thinking: 每当我们要建立一个神经网络时,首先我们想到的应该是 第一 预期是什么(要模拟一个关于谁的分布);第二构建计算目前与期望的差值(选择构建损失函数)。在这里我们的目标或者说预期是拟合一个在英文名中字母组合(随机变量)的分布,我们将从每个单词里得到所有的字母组合的似然(似然与概率不同,概率评估可能性(即在参数已知,数据未知的情况下预测数据出现的可能性,用于描述随机现象分布),似然评估合理性(即在参数未知,数据已知的情况下评估参数取值的合理性,用于参数估计))----因为我们已知数据,即前面得到的tensor变量N(P),即字母组合计数表(概率表),所以我们将用即将建立的神经网络模型输出得到的字符对应的字符组合的概率来评估输出的合理性,即似然,再通过得到每个单词的每个字母组合的负对数似然之和来建立似然函数,进行最大似然估计,即采用交叉熵损失函数计算损失,用该损失来进行反向传播计算梯度,更新,以此为一个训练周期,最终得到我们训练后的模型。从宏观上来说,前向传播过程为x -->nn -->softmax : y -->loss。以上对于新同学可能有点晦涩,没关系,我们依旧可以按照以下步骤慢慢来理解
2.1、怎么评估一个英语名字出现的合理性?
我们用以下代码块来直观表示,我们从words选前三个举例。对前三个单词,计算它们在当前 bigram 概率模型 P 下的平均负对数似然(即损失),并打印每个字符对的概率和对数概率。具体流程是:对每个单词,先加上首尾的“.”,然后遍历所有相邻字符对(bigram),查表得到它们的概率作为 likelihood,取对数后累加负对数似然,最后输出每个 bigram 的概率、对数概率,以及该单词的平均损失。我们将以平均损失来衡量一个英语名字出现的合理性
for w in words[:3]:
neg_log_likelihood = 0.0
count = 0
print(w)
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
count += 1
idx1 = c2i[ch1]
idx2 = c2i[ch2]
likelihood = P[idx1][idx2]
log_likelihood = torch.log(likelihood)
neg_log_likelihood += -log_likelihood
print(f'{ch1}{ch2}, probability:{likelihood:.4f}, log_likelihood:{log_likelihood}')
print(f'average_negative_log_likelihood,i.e.loss:{(neg_log_likelihood / count).item()}\n' )
'''
emma
.e, probability:0.0478, log_likelihood:-3.0416879653930664
em, probability:0.0376, log_likelihood:-3.2806472778320312
mm, probability:0.0252, log_likelihood:-3.6812613010406494
ma, probability:0.3884, log_likelihood:-0.9458120465278625
a., probability:0.1958, log_likelihood:-1.6306569576263428
average_negative_log_likelihood,i.e.loss:2.5160131454467773
olivia
.o, probability:0.0123, log_likelihood:-4.399013519287109
ol, probability:0.0778, log_likelihood:-2.5542047023773193
li, probability:0.1773, log_likelihood:-1.729726791381836
iv, probability:0.0152, log_likelihood:-4.1881890296936035
vi, probability:0.3504, log_likelihood:-1.048723816871643
ia, probability:0.1379, log_likelihood:-1.9811002016067505
a., probability:0.1958, log_likelihood:-1.6306569576263428
average_negative_log_likelihood,i.e.loss:2.504516363143921
ava
.a, probability:0.1376, log_likelihood:-1.9837344884872437
av, probability:0.0246, log_likelihood:-3.7052907943725586
va, probability:0.2469, log_likelihood:-1.3986784219741821
a., probability:0.1958, log_likelihood:-1.6306569576263428
average_negative_log_likelihood,i.e.loss:2.1795902252197266
'''如果我们生成的名字不常见,比如"ablhznznns",会发现其平均负对数似然(即损失average_negative_log_likelihood,i.e.loss)很高,而一个常见的名字"mike",最终的损失却很低。换句话说,如果"ablhznznns", "mike"是我们之后建立的模型的输出,我们可以通过这种方式来衡量我们输出结果的好坏,即我们模型的好坏
for w in ["ablhznznns", "mike"]:
...
'''
ablhznznns
.a, probability:0.1376, log_likelihood:-1.9837344884872437
ab, probability:0.0160, log_likelihood:-4.1381049156188965
bl, probability:0.0385, log_likelihood:-3.2558536529541016
lh, probability:0.0014, log_likelihood:-6.601301670074463
hz, probability:0.0026, log_likelihood:-5.945813179016113
zn, probability:0.0016, log_likelihood:-6.407292366027832
nz, probability:0.0079, log_likelihood:-4.840868949890137
zn, probability:0.0016, log_likelihood:-6.407292366027832
nn, probability:0.1038, log_likelihood:-2.264840841293335
ns, probability:0.0151, log_likelihood:-4.189981937408447
s., probability:0.1437, log_likelihood:-1.9397811889648438
average_negative_log_likelihood,i.e.loss:4.361351490020752
mike
.m, probability:0.0792, log_likelihood:-2.5362327098846436
mi, probability:0.1883, log_likelihood:-1.669537901878357
ik, probability:0.0251, log_likelihood:-3.684826374053955
ke, probability:0.1766, log_likelihood:-1.7336804866790771
e., probability:0.1948, log_likelihood:-1.635947585105896
average_negative_log_likelihood,i.e.loss:2.252044916152954
'''以下是我们计算流程对应的数学公式:
1. 以查表得到它们的概率作为 likelihood,建立似然函数(X为随机变量,theta为模型参数)
2. 每个单词的likelihood,为字母组(bigram)概率的累积(N为每个单词bigram的个数)
3. 取对数,得到对数似然(取对数使概率累积变成线性累加,方便后续计算和求梯度)
4. 取对数似然的负,让它变成正数,方便进行反向传播,之后再得到平均负对数似然(即损失),这里表示是每个单词的损失或者说每个单词的合理性
2.2、开始神经网络构建工作
2.2.1、准备数据集
神经网络构建工作第一步,构建模型需要的训练集。很显然,从words取出每个单词每个字母,错位对应,注意的是构建完把X,Y转为tensor类型,以满足后续前向传播的格式要求
xs = []
ys = []
for w in words:
chs = ['.'] + list(w) + ['.']
for ch1, ch2 in zip(chs, chs[1:]):
idx1 = c2i[ch1]
idx2 = c2i[ch2]
xs.append(idx1)
ys.append(idx2)
xs = torch.tensor(xs)
ys = torch.tensor(ys)
num = xs.nelement()
print(f'xs:{xs}')
print(f'ys:{ys}')
print(f'examples:{num}')
'''
xs:tensor([ 0, 5, 13, ..., 25, 26, 24])
ys:tensor([ 5, 13, 13, ..., 26, 24, 0])
examples:228146
'''xs代表真实值输入,ys代表真实值输出
2.2.2、前向传播
这里构建的神经网络本质上是模拟之前的矩阵N,进行类似的查表操作(即用W来模拟N,每次输入x结合参数矩阵W类似N根据矩阵乘法查得到x之后27个字符的计数count再转化为概率),所以我们将构建一个27*27的参数矩阵W,并在这之前用one_hot_encoding对xs进行编码,使它从1维变成27维来满足与W进行矩阵乘法
这里我们使用torch库中的one_hot()方法进行编码,编码后注意转为float类型进行矩阵乘法(因为后续的计算都是建立在float32的数据类型)。由打印结果可知onehot编码 x(里面是字符的编号,比如 [0, 5, 13])转换成 one-hot 编码的形式,每个编号变成一个长度为 27 的向量,只有对应编号的位置是 1,其余都是 0
import torch.nn.functional as F
x = xs[:3]
xenc = F.one_hot(x,27).float()
print(x)
print(xenc)
plt.imshow(xenc)
'''
tensor([ 0, 5, 13])
tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.]])
'''
同时附上图直观理解
接下来设置大小为27*27的参数矩阵W,有两种方式来理解该矩阵:第一,为一个输入为27,共27个神经元的一层线性网络(无激活函数);第二,认为是一个之前建立的27*27的字母组(bigram)查找表N。我们采用torch.randn()方法来生成参数,randn方法会生成符合标准正态分布的随机数,同时通过torch.Generator().manual_seed()方法来设置种子使得每次生成的随机数一致,最后记得设置requires_grad=True使得反向传播时能够计算梯度
g = torch.Generator().manual_seed(2147483647)
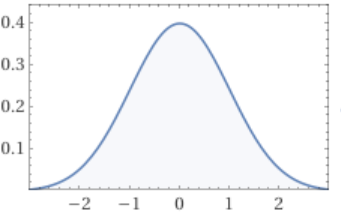
W = torch.randn((27, 27), generator=g, requires_grad=True)所以由标准正态分布图(纵轴代表概率)可知,生成的参数大致在-3,3之间,0左右
下图解释了one-hot与参数矩阵进行矩阵相乘的作用,相当于在参数矩阵中取对应索引的值,理解这个,接下来运算就明晰了
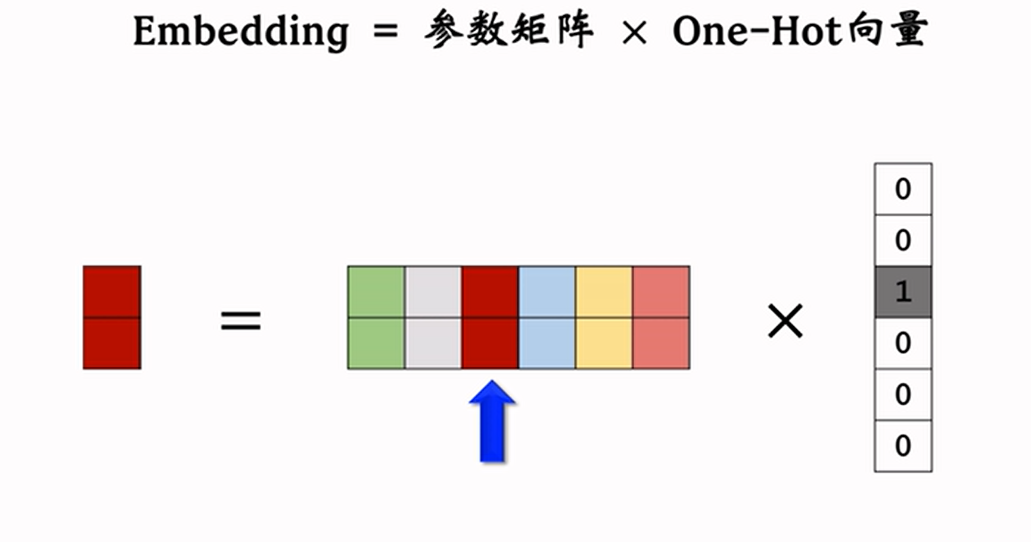
现在我们就要计算像bigramModel里的count,通过one-hot的编码与参数矩阵进行相乘得到输入的x字母对应值count(这里的@代表矩阵乘法),但是由于我们的W参数矩阵分布,这个count并不像实际数字一样规整例如17就代表频数17,而是小数,所以我们一般把其称为log_counts,即logits(可以粗略理解是count取对数的结果)
logits = xenc @ W # predict log_counts
print(logits.shape)
print(logits[:2])
'''
torch.Size([228146, 27])
tensor([[ 1.5674e+00, -2.3729e-01, -2.7385e-02, -1.1008e+00, 2.8588e-01,
-2.9643e-02, -1.5471e+00, 6.0489e-01, 7.9136e-02, 9.0462e-01,
-4.7125e-01, 7.8682e-01, -3.2843e-01, -4.3297e-01, 1.3729e+00,
2.9334e+00, 1.5618e+00, -1.6261e+00, 6.7716e-01, -8.4039e-01,
9.8488e-01, -1.4837e-01, -1.4795e+00, 4.4830e-01, -7.0730e-02,
2.4968e+00, 2.4448e+00],
[ 4.7236e-01, 1.4830e+00, 3.1748e-01, 1.0588e+00, 2.3982e+00,
4.6827e-01, -6.5650e-01, 6.1662e-01, -6.2197e-01, 5.1007e-01,
1.3563e+00, 2.3445e-01, -4.5585e-01, -1.3132e-03, -5.1161e-01,
5.5570e-01, 4.7458e-01, -1.3867e+00, 1.6229e+00, 1.7197e-01,
9.8846e-01, 5.0657e-01, 1.0198e+00, -1.9062e+00, -4.2753e-01,
-2.1259e+00, 9.6041e-01]], grad_fn=<SliceBackward0>)
'''前面我们完成从 x -->nn 的过程,接下来就是完成nn -->softmax : y -->loss的过程了。count或者说logits转为概率类似在第一部分频数映射到概率的方式,唯一不同的是要先进行exp()操作将logits全化为正数。
#softmax
counts = logits.exp()
probs = counts / counts.sum(dim=1, keepdim=True) #probability for next character
以下为softmax的数学公式(对于 228146*27 的矩阵 logits 每一行进行softmax操作,其中这里K为27,j为每行的每个元素)
之后再对得到的概率算出前面提到的平均负对数似然,即损失。其中probs[torch.arange(num), ys]代表取出样本对应ys的概率。
#loss
loss = -probs[torch.arange(num), ys].log().mean()
print(f'loss:{loss.item()}')
all_likelihood = probs[torch.arange(num),ys]
print(all_likelihood.shape)
print(all_likelihood[:3])
'''
loss:3.758953809738159
torch.Size([228146])
tensor([0.0123, 0.0181, 0.0267], grad_fn=<SliceBackward0>)
'''到这里我们就完成了一次前向传播!
2.2.3、反向传播与参数更新
注意在反向传播前,对梯度grad进行归0,使用backward()方法即可进行反向传播计算梯度
#backward pass
W.grad = None # set to the gradient
loss.backward()最后进行梯度更新操作即可(这里设置学习率为0.1)
#update
W.data += -0.1 * W.grad以上一次完整的训练就完成了!
接下来我们把之前的操作整合在一起,进行20次训练
#train with gradient descent
for i in range(10):
#forward pass
xenc = F.one_hot(xs,27).float() #one-hot encoding
logits = xenc @ W # predict log_counts
#softmax
counts = logits.exp()
probs = counts / counts.sum(dim=1, keepdim=True) #probability for next character
#loss
loss = -probs[torch.arange(num),ys].log().mean()
print(f"loss:{loss.item()}")
#backward pass
W.grad = None # set to the gradient
loss.backward()
#update
W.data += -0.1 * W.grad
'''
loss:3.7686190605163574
loss:3.7677001953125
loss:3.7667829990386963
loss:3.765866279602051
loss:3.76495099067688
loss:3.7640366554260254
loss:3.7631237506866455
loss:3.762211322784424
loss:3.761300802230835
loss:3.7603907585144043
'''2.2.4、模型推理(2)
不断调整学习率进行训练直至得到一个合适的损失,用以下代码测试我们的神经网络模型名字生成效果
#inference
# g = torch.Generator().manual_seed(2147483647)
for i in range(5):
ix = 0
out = []
while True:
#before:
# p = P[ix]
#now:
xenc = F.one_hot(torch.tensor([ix]),27).float() #one-hot encoding
logits = xenc @ W # predict log_counts
counts = logits.exp()
p = counts / counts.sum(dim=1, keepdim=True) #probability for next character
ix = torch.multinomial(p, num_samples=1, replacement=True, generator=g).item()
out.append(i2c[ix])
if ix == 0:
break
print(''.join(out))
'''
an.
allawaiairynarle.
are.
ahamon.
taiellledahamera.
lbjelusl.
ja.
amyda.
jeyndkanakyn.
jon.
'''总体效果与我们的第一部分的bigramModel类似
为了防止模型过拟合,我们可以进一步引入L2正则化,其原理是通过减小loss而让使W接近0,从而近似均匀分布,或者说让惩罚参数变大,让模型参数尽量小,从而防止过拟合,提高泛化能力
这里把lambda设置为0.01,并取平均
loss = -probs[torch.arange(num),ys].log().mean() + 0.01 * (W**2).mean() #regularization三、构建三元特征输入的MLP进行生成
在这个部分,我们将构建下图模型来完成同样的任务
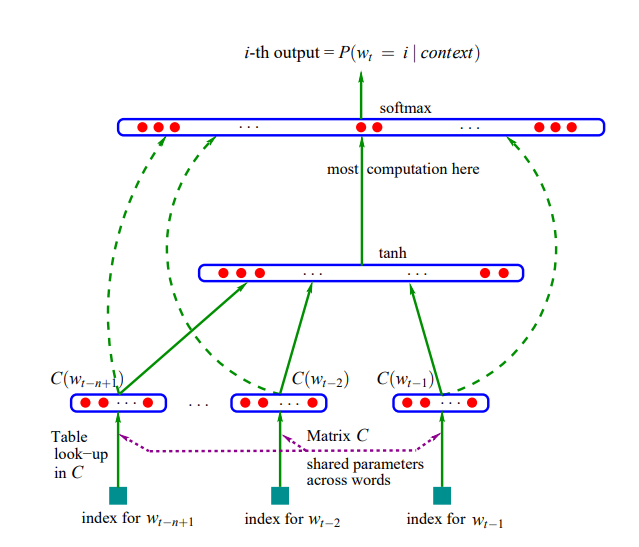
Thinking: 在构建之前先对上图模型进行分析,图中的架构看起来较为复杂,实际还好。我们从下往上逐层分析,三个index_for_w代表单词中某个字母的前三个的字母的索引,通过嵌入矩阵C,同时把三个字母索引嵌入转为三个多维向量,再通过MLP输入层,隐藏层(从低维到高维,再从高维到低维,最后tanh激活)以tanh激活函数输出logits,最后用softmax层完成从logits到概率的映射计算交叉熵损失。分析完成我们开始构建吧!
3.1、数据处理与构建数据集
首先引入相关包和数据
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
%matplotlib inline
words = open('names.txt','r').read().splitlines()3.1.1、构建映射表与数据集
建立映射表
chars = sorted(list(set(''.join(words))))
s2i = {s:i+1 for i,s in enumerate(chars)}
s2i['.'] = 0
i2s = {i:s for s,i in s2i.items()}我们通过以下方法建立数据集X,Y(可以先取前3个单词查看数据集结构),原理是将前三个单词(每个单词末尾加上句点.)转化为训练神经网络的输入输出对。block_size=3,所以用长度为3的上下文(context)预测下一个字符。初始 context 是 [0, 0, 0],每遇到一个字符 c,就把当前 context 加入 X,把 c 的索引加到 Y,然后 context 滑动窗口(去掉最左边,加上当前字符索引)。这样,X 里每一行都是长度为3的“历史”,Y 是下一个要预测的字符索引。最后将 X、Y 转为 tensor,方便后续送入模型
X, Y = [], []
block_size = 3
context = [0] * block_size
for w in words[:3]:
w = w + '.'
print(w)
for c in w:
idx = s2i[c]
X.append(context)
Y.append(idx)
print(''.join(i2s[i] for i in context),'---->',c)
context = context[1:] + [idx]
X = torch.tensor(X)
Y = torch.tensor(Y)
print(X.shape, X)
print(Y.shape, Y)
'''
emma.
... ----> e
..e ----> m
.em ----> m
emm ----> a
mma ----> .
olivia.
ma. ----> o
a.o ----> l
.ol ----> i
oli ----> v
liv ----> i
ivi ----> a
via ----> .
ava.
ia. ----> a
a.a ----> v
.av ----> a
ava ----> .
torch.Size([16, 3]) tensor([[ 0, 0, 0],
[ 0, 0, 5],
[ 0, 5, 13],
[ 5, 13, 13],
[13, 13, 1],
[13, 1, 0],
[ 1, 0, 15],
[ 0, 15, 12],
[15, 12, 9],
[12, 9, 22],
[ 9, 22, 9],
[22, 9, 1],
[ 9, 1, 0],
[ 1, 0, 1],
[ 0, 1, 22],
[ 1, 22, 1]])
torch.Size([16]) tensor([ 5, 13, 13, 1, 0, 15, 12, 9, 22, 9, 1, 0, 1, 22, 1, 0])
'''3.1.2、划分训练集,验证集,测试集
为了以后更科学地衡量模型的泛化能力,并且让模型训练、调参和最终评估都能各自独立、互不影响,我们可以将数据集按 8:1:1 的比例分成训练集(train)、验证集(dev/valid)、测试集(test)。并在划分之前我们可以先把处理数据的代码封装成一个函数build_dataset
def build_dataset(dataset):
X, Y = [], []
block_size = 3
context = [0] * block_size
for w in dataset:
w = w + '.'
for c in w:
idx = s2i[c]
X.append(context)
Y.append(idx)
context = context[1:] + [idx]
return torch.tensor(X),torch.tensor(Y)接下来用random库中的shuffle方法对数据集进行打乱,最后用以下代码得到相应数据集(提供两种方式进行划分)
# perm = torch.randperm(len(X))
# Xtr, Ytr, Xdev, Ydev, Xte, Yte = X[perm][:n], Y[perm][:n], X[perm][n:m], Y[perm][n:m], X[perm][m:], Y[perm][m:]
n = int(len(words)*0.8)
m = int(len(words)*0.9)
import random
random.shuffle(words)
Xtr, Ytr = build_dataset(words[:n])
Xdev, Ydev = build_dataset(words[n:m])
Xte, Yte = build_dataset(words[m:])
print(Xtr.shape, Ytr.shape, Xdev.shape, Ydev.shape, Xte.shape, Yte.shape)
'''
(torch.Size([182449, 3]),
torch.Size([182449]),
torch.Size([22847, 3]),
torch.Size([22847]),
torch.Size([22850, 3]),
torch.Size([22850]))
'''3.2、开始搭建模型
现在就可以开始建立我们的模型了,我们以样本量为32举例
3.2.1、前向传播
首先构建嵌入矩阵进行嵌入层的搭建,目的是把离散的字符编号转成连续的向量,便于后续神经网络处理。C = torch.randn((27,2),generator=g) 创建了一个形状为 (27, 2) 的嵌入矩阵,每个字符(包括起始符号 .)都有一个2维的向量表示。emb = C[X] 利用花式索引(fancy indexing),把输入 X(每一行是3个字符的编号)映射成对应的嵌入向量,得到的 emb 形状是 (样本数, 3, 2),即每个 context 里的每个字符都被转换成了2维向量
g = torch.Generator().manual_seed(2147483647)
C = torch.randn((27, 2),generator=g)
emb = C[X] #fancy indexing -->it's a way of indexing
print(emb.shape)
'''
torch.Size([32, 3, 2])
'''接下来构建MLP隐藏层,W1 = torch.randn((6,100)) 创建了一个形状为 (6, 100) 的权重矩阵,表示输入维度为 6,输出维度为 100。b1 = torch.randn(100) 创建了一个长度为 100 的偏置向量。用emb.view(-1,6)方法 把嵌入向量展平成二维张量,每行为一个样本,6 是输入特征数(因为 block_size=3,每个字符2维嵌入,3×2=6)。emb.view(-1,6) @ W1 + b 先做矩阵乘法,再加偏置,得到 shape 为 (样本数, 100) 的输出。torch.tanh() 对输出加上 tanh 激活函数,引入非线性。
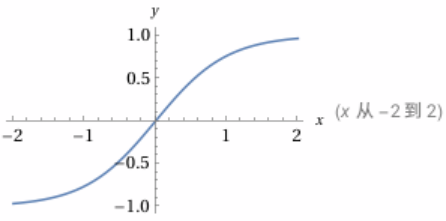
W1 = torch.randn((6,100))
b1 = torch.randn(100)
h = torch.tanh(emb.view(-1,6) @ W1 + b1) #-1 means emb.shape[0] or 32
print(W1.shape, b1.shape)
print(h.shape)
'''
torch.Size([6, 100]), torch.Size([100])
torch.Size([32, 100])
'''接下来通过最后一层线性变换,得到每个样本对27个类别(字符)的打分logits
W2 = torch.randn((100,27))
b2 = torch.randn(27)
logits = h @ W2 +b2
print(logits.shape)
'''
torch.Size([32, 27])
'''最后在训练的过程中我们省略从softmax到之后的取对数取负算损失,直接采用F.cross_entropy()方法来计算交叉熵损失
loss = F.cross_entropy(logits,Y)
print(loss.item())
'''
15.08108139038086
'''以上我们就完成了一次前向传播!
3.2.2、反向传播与参数更新
首先用列表parameters打包好我们构建的模型里的参数,并确定梯度(这里建议重新初始化参数矩阵,再进行一次前向传播,以免反向传播失败)
parameters = [C, W1, b1, W2, b2]
for p in parameters:
p.requires_grad = True用以下代码进行反向传播计算梯度,参数更新(这里学习率设置为0.1),也注意在backward前对所有参数进行梯度归零
#backward pass
for p in parameters:
p.grad = None
loss.backward()
#update
for p in parameters:
p.data += -0.1 * p.grad这样一次训练就完成了!
3.2.3、模型整合
最后我们把以上建立数据集,前向传播反向传播的代码整合在一起并为了提高模型拟合能力将嵌入矩阵C变为27*10其它参数变为以下代码形式,用torch.randint(Xtr.shape[0],(batch,))设置minibatch来控制每次训练的样本量。并用for循环进行10次的训练
n = int(len(words)*0.8)
m = int(len(words)*0.9)
import random
random.shuffle(words)
Xtr, Ytr = build_dataset(words[:n])
Xdev, Ydev = build_dataset(words[n:m])
Xte, Yte = build_dataset(words[m:])g = torch.Generator().manual_seed(2147483647)
C = torch.randn((27,10), generator=g)
W1 = torch.randn((30,200), generator=g)
b1 = torch.randn(200, generator=g)
W2 = torch.randn((200,27), generator=g)
b2 = torch.randn(27, generator=g)
parameters = [C, W1, b1, W2, b2]
batch = 32
lr_default = 0.1
for p in parameters:
p.requires_grad = Truefor i in range(10):
#minibatch
mb = torch.randint(Xtr.shape[0],(batch,))
#forward pass
emb = C[Xtr[mb]] #fancy indexing -->it's a way of indexing
h = torch.tanh(emb.view(-1,30) @ W1 + b1)
logits = h @ W2 +b2
loss = F.cross_entropy(logits,Ytr[mb])
print(loss.item())
#backward pass
for p in parameters:
p.grad = None
loss.backward()
#update
# lr = lrs[i] if i < 5000 else 0.1
lr = lr_default
# lr = 0.01
for p in parameters:
p.data += -lr * p.grad
'''
23.849689483642578
26.4879207611084
26.20933723449707
19.649185180664062
24.141056060791016
22.229476928710938
23.843032836914062
23.06414031982422
21.969547271728516
21.187782287597656
'''由输出可以发现,我们得到的loss并不是阶梯式下降的,而是螺旋式下降,这是因为我们从整个训练集中挑选minibatch进行训练,所以这是正常现象
同时在训练前添加lossi与stepi变量,循环内添加以下代码同时进行1000次训练,画图直观展示训练过程
lossi = []
stepi = []
for i in range(1000):
...
lossi.append(torch.log10(loss)) #log对结果展示进行压缩
stepi.append(i)
plt.plot(stepi,lossi)由图可得损失螺旋下降(其中纵轴代表log10_loss,横轴代表训练步数)
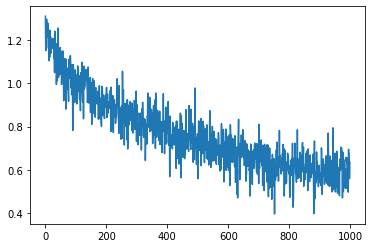
同时在全局训练集和测试集上得到损失进行对比
#forward in train dataset
emb = C[Xtr]
h = torch.tanh(emb.view(-1,30) @ W1 + b1)
logits = h @ W2 +b2
loss = F.cross_entropy(logits,Ytr)
print(loss.item())
'''
3.823867082595825
'''#forward in dev dataset
emb = C[Xdev]
h = torch.tanh(emb.view(-1,30) @ W1 + b1)
logits = h @ W2 +b2
loss = F.cross_entropy(logits,Ydev)
print(loss.item())
'''
3.868291139602661
'''3.2.4、(附)怎么理解嵌入层?
为了直观理解,我们可以在把嵌入层改在二维的基础上训练。下图是没有进行任何训练下,每个字母(字符,这里包括".")嵌入到二维的分布情况(视频中通过以下代码进行绘制)
plt.figure(figsize=(8, 8))
plt.scatter(C[:, 0].data, C[:, 1].data, s=200)
for i in range(C.shape[0]):
plt.text(C[i, 0].item(), C[i, 1].item(), i2s[i], ha="center", va="center", color='white')
plt.grid('minor')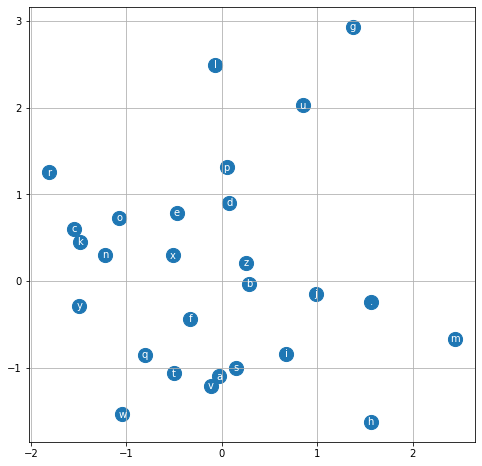
由图可知没训练后的嵌入会使每个字母的分布杂乱无章,以下是训练1000次后嵌入到二维的分布情况图
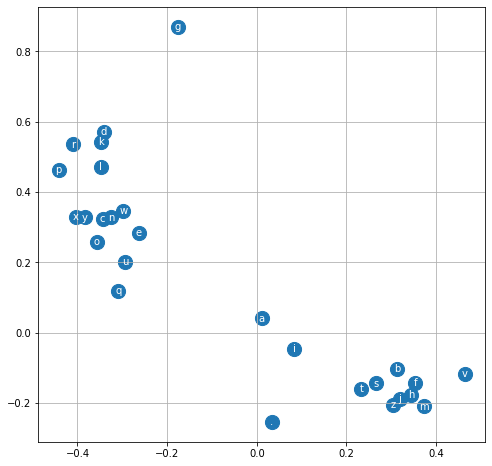
由图可知,训练后字符明显集中,有较多聚集。这是因为训练后,随着模型不断根据损失函数反向传播和参数更新,嵌入矩阵 C 的每一行(即每个字符的向量)会被调整,使得模型能更好地根据上下文预测下一个字符。这样,语义相近或在名字中经常一起出现的字符,其嵌入向量会被优化到更接近的位置,而不常一起出现的字符则会被拉远。而随着嵌入层维度的提高,字符的划分会越来越明显,从而使得模型效果越来越好
3.2.5、模型推理(3)
最后我们用训练完成后的模型进行名字生成,并在logits到p的映射中直接采用softmax方法(因为torch.softmax 会自动做“减去最大值”的操作,这样可以防止输入 logits 很大或很小时出现溢出或下溢,保证计算结果不会变成无穷大或0,提升了数值安全性和鲁棒性)生成20个名字
#inference
for _ in range(20):
out = []
context = [0]*3
while True:
emb = C[torch.tensor([context])] # [context]使context变成1x3的矩阵
h = torch.tanh(emb.view(-1,30) @ W1 + b1)
logits = h @ W2 +b2
p = F.softmax(logits, dim=1)
inx = torch.multinomial(p, num_samples=1,replacement=True).item()
context = context[1:] + [inx]
out.append(i2s[inx])
if inx == 0:
break
print(''.join(out))
'''
ksnyur.
rtsie.
arie.
rukerue.
arely.
arrayziea.
rtssa.
arzah.
ili.
rtezores.
utbesphis.
ara.
ktehanija.
rtde.
rtrone.
illele.
arda.
rike.
qhinpe.
rtoneyrlirvi.
'''我们第三部分生成的名字结果相比前两次改善很大,合理性也很高,例如"arely", "ara", "arde", "rike" 等都符合自然拼读习惯
四、对我们建立的模型进行调优
4.0、引子
首先对我们的代码进行整理(这里博主用的是notebook格式,所以如果有报错请依次按块运行)
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
%matplotlib inline
words = open('names.txt','r').read().splitlines()
a = sorted(list(set(''.join(words))))
i2s = {i+1:s for i,s in enumerate(a)}
i2s[0] = '.'
s2i = {s:i for i,s in i2s.items()}
vocab_size = len(i2s)
def build_dataset(dataset, block_size=3):
X = []
Y = []
context = [0] * block_size
for w in dataset:
w = list(w) + ['.']
# print(''.join(w))
for i in w:
ix = s2i[i]
X.append(context)
Y.append(ix)
# print(f"{''.join(i2s[c] for c in context)}--->{i}")
context = context[1:] + [ix]
return torch.tensor(X),torch.tensor(Y)
import random
random.seed(42)
random.shuffle(words)
n1 = int(len(words)*0.8)
n2 = int(len(words)*0.9)
block_size = 3
Xtr, Ytr = build_dataset(words[:n1])
Xdev, Ydev = build_dataset(words[n1:n2])
Xte, Yte = build_dataset(words[n2:])
# Xtr.shape, Xdev.shape, Xte.shape
n_embd = 10
n_hidden = 200
batch_size = 32
g = torch.Generator().manual_seed(2147483647)
C = torch.randn((vocab_size, n_embd), generator=g)
W1 = torch.randn(((block_size * n_embd), n_hidden), generator=g)
b1 = torch.randn(n_hidden, generator=g)
W2 = torch.randn((n_hidden,vocab_size), generator=g)
b2 = torch.randn(vocab_size, generator=g)
parameters = [C, W1, b1, W2, b2]
print(f'num_para:{sum(p.nelement() for p in parameters)}')
for p in parameters:
p.requires_grad = True
'''
num_para:11897
'''用以下代码进行训练(博主将max_steps调整为200001是为了输出完整,可调为200000),额外设置lossi,与lossinormal来存储每一次训练后的损失用于画图
max_steps = 200001
batch_size = 32
lossi = []
lossinormal = []
for i in range(max_steps):
# minibatch
ix = torch.randint(0, Xtr.shape[0], (batch_size,))
Xb, Yb = Xtr[ix], Ytr[ix]
# forward pass
emb = C[Xb]
embcat = emb.view(emb.shape[0], -1)
hpreact = embcat @ W1 + b1
h = torch.tanh(hpreact)
logits = h @ W2 + b2
loss = F.cross_entropy(logits, Yb)
# backward pass
for p in parameters:
p.grad = None
loss.backward()
# update
lr = 0.1 if i < 100000 else 0.01
for p in parameters:
p.data += -lr * p.grad
# track stats
if i % 10000 == 0:
print(f'{i:7d}/{max_steps - 1:7d}: {loss.item():.4f}')
lossi.append(loss.log10().item())
lossinormal.append(loss.item())
'''
0/ 200000: 26.1154
10000/ 200000: 2.7339
20000/ 200000: 2.9979
30000/ 200000: 2.0122
40000/ 200000: 2.5672
50000/ 200000: 2.2564
60000/ 200000: 2.1457
70000/ 200000: 2.2872
80000/ 200000: 2.1682
90000/ 200000: 2.4726
100000/ 200000: 2.4766
110000/ 200000: 2.3234
120000/ 200000: 1.9719
130000/ 200000: 2.3515
140000/ 200000: 2.1549
150000/ 200000: 2.0060
160000/ 200000: 2.5863
170000/ 200000: 2.4039
180000/ 200000: 2.1578
190000/ 200000: 2.1810
200000/ 200000: 1.9234
'''用以下代码来得到训练过程可视化结果
plt.plot(lossinormal)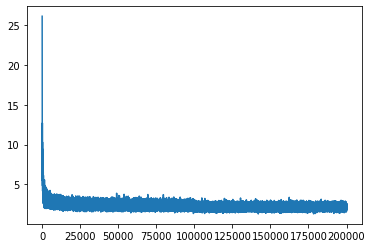
可以看出不是很美观,我们对原始损失取log10进行压缩来达到下图效果
plt.plot(lossi)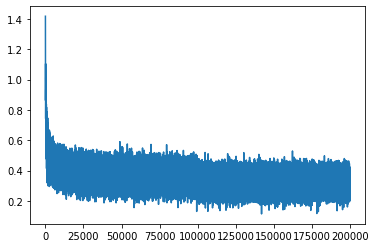
好的,由上图可知,训练损失整体呈曲棍状(hockey shape)。具体上看,初始训练得到的损失特别大(26左右),之后急速下降至3,后缓慢曲折降低。很显然,一个大致的损失是在3以内的,而刚开始的26的损失是我们不希望看到的,我们希望模型开始训练时就在期望损失3的基础上进行降低而不是一个很高的值同时加快我们的训练速度,而这里就存在调优的空间,因此本章节将讨论Kaiming init,batch normal两个方法来对我们的模型进行优化。
4.1、Kaiming init(何恺明初始化)
这里我们将理解并采用Kaiming init来解决初始损失很大的问题(我们这里直接提供初始化方法,对这个方法背后原理感兴趣的同学可以移步至4.1.2)
4.1.1、初始化方法
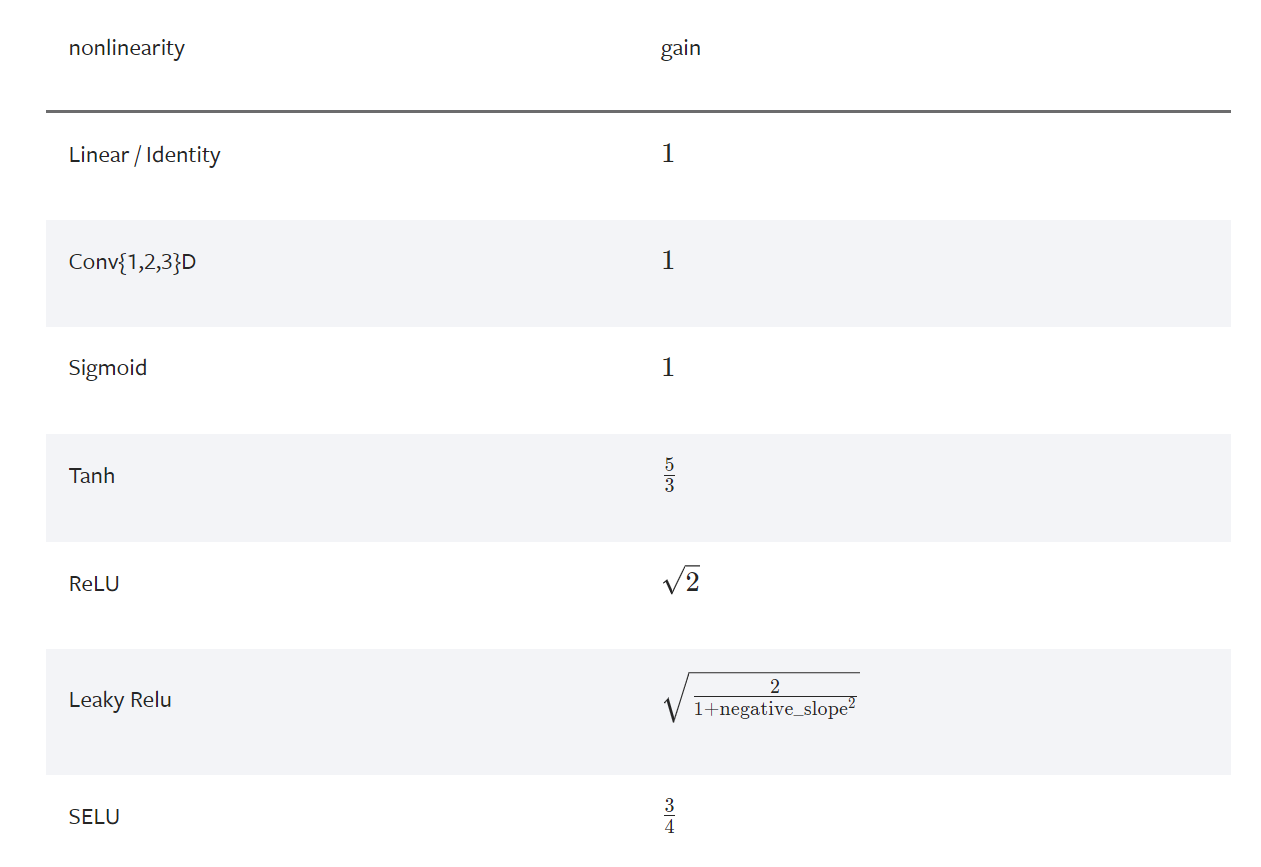
这里只需对我们的初始参数按照规则进行缩放即可,因为我们这里采用的是tanh激活函数,所以gain增益为(5/3)
n_embd = 10
n_hidden = 200
batch_size = 32
g = torch.Generator().manual_seed(2147483647)
C = torch.randn((vocab_size, n_embd), generator=g)
W1 = torch.randn(((block_size * n_embd), n_hidden), generator=g) * (5/3)/((block_size * n_embd)**0.5)
b1 = torch.randn(n_hidden, generator=g) * 0.01
W2 = torch.randn((n_hidden,vocab_size), generator=g) * 0.01
b2 = torch.randn(vocab_size, generator=g) * 0 #更希望分布均值趋于0,因此取消偏置
parameters = [C, W1, b1, W2, b2]
print(f'num_para:{sum(p.nelement() for p in parameters)}')
for p in parameters:
p.requires_grad = True此时再重新初始化,进行训练就可以解决这个问题了
0/ 200000: 3.3104
10000/ 200000: 2.1356
20000/ 200000: 2.4082
30000/ 200000: 2.1202
40000/ 200000: 2.1482
50000/ 200000: 2.3789
60000/ 200000: 2.3490
70000/ 200000: 2.0163
80000/ 200000: 1.9522
90000/ 200000: 2.3462
100000/ 200000: 2.1679
110000/ 200000: 1.7762
120000/ 200000: 2.1983
130000/ 200000: 2.5157
140000/ 200000: 2.0230
150000/ 200000: 1.9756
160000/ 200000: 1.7598
170000/ 200000: 2.2854
180000/ 200000: 2.0296
190000/ 200000: 1.6147
200000/ 200000: 2.0863此时训练过程图并没有呈曲棍状态,损失很好地从3开始下降
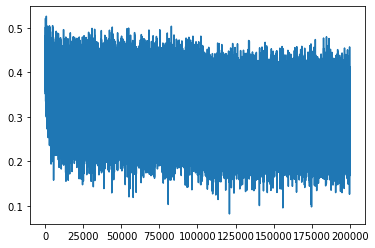
这里附上kaiming init缩放公式与不同激活函数对应的gain增益
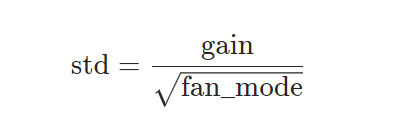
4.1.2、Kaiming init背后原理(简略版)
这里将简单介绍该初始化背后原理,想深度了解可查看原论文
Thinking: 当我们探究解决办法时,我们要对现象进行深入地剖析,即第一,为什么我们损失的预期值是三而不是其它数字?第二,是什么导致开始损失会那么多和训练速度的快慢?第三,通过什么样的方式可以把问题解决?
首先我们发现我们期望的损失值并不是偶然,而是 -ln(1 / vocab_size) = 3.2958得来的,意味着模型预测结果满足均匀分布时的损失,可以理解为模型预测的针对每个字符都是一样的概率(1/27)时模型的损失。因此我们希望模型初始时的损失应该在这个数字左右,即希望模型初始化时预测的结果符合均匀分布。
那为什么开始的损失会很大,通过以下实验可发现,若权重初始值过大,Logits的绝对值可能极大,导致 Softmax 对应概率接近0或1(极端置信),从而使初始损失增大(如实验中的 loss_b = −ln(4.1461e−04)≈11.8),远远大于期望损失(均匀分布时的损失 loss_o )和服从标准正态分布的损失( loss_a )
logits_a = torch.randn(5)
prob_a = torch.softmax(logits_a, dim= 0)
logits_b = a * 10
prob_b = torch.softmax(logits_b, dim= 0)
loss_o = -torch.log(torch.tensor(1/5))
loss_a = -prob_a[2].log()
loss_b = -prob_b[2].log()
print(prob_a)
print(prob_b)
print(f"期望损失:{loss_o.item()}\n普通大小:{loss_a.item()}\n扩大十倍:{loss_b.item()}")
'''
tensor([0.3731, 0.0139, 0.0407, 0.0818, 0.4905])
tensor([9.3405e-15, 4.1461e-04, 7.7351e-06, 2.9168e-05, 9.9955e-01])
期望损失:1.6094379425048828
普通大小:3.2008838653564453
扩大十倍:11.769744873046875
'''因此初始化时应使模型最后算出的 logits 控制在一个很小的范围里或者使其服从标准正态分布。此时问题又来了,我们不能控制最后 logits 的结果的分布情况,相反我们只能控制最开始的参数分布情况,但事实证明即使我们把初始参数服从标准正态分布,最后损失依然很大——模型中的每一层都会使初始的最初的分布发生改变,最后导致 logits 分布的发生异常,从而导致初始损失很大。所以每一层是如何使最初X的分布发生变化的呢?
emb = C[Xb]
embcat = emb.view(emb.shape[0], -1)
hpreact = embcat @ W1 + b1
h = torch.tanh(hpreact)
logits = h @ W2 + b2
loss = F.cross_entropy(logits, Yb)由我们的 forward pass 可以看出最初的X经历了一次矩阵乘法,tanh()函数,和又一次的矩阵乘法变成了 logits ,所以我们只要控制每一次变化后X的分布范围大小(方差)不变就可使初始损失分布正常,从而降低损失
此时我们不妨从数学的角度分析矩阵乘法(Y = W @ X)是如何改变原始输入X分布的方差,为了更好地分析,我们假设X,W都服从标准正态分布:
1. 展开矩阵乘法的表达式:
2. 计算 Var(Y):
由于W和X互相独立且均值为 0,可以利用方差的性质,方差满足:
因此
又因为
且W,X均值都为 0,所以
总结,在矩阵乘法 Y = W @ X 中,输入 X 的方差变动规律为:
加入激活层后(假设激活层为ReLU,论文原文为ReLU)(Z = W @ X, Y = ReLU(Z)),假设计算出的Z服从均值为0的对称分布,对于均值为0的对称分布,ReLU会“丢弃”一半的信号(负半轴),因此输出的方差会减半
如果要控制X的分布方差不变,即Var(Y)=Var(X),那么需满足
最终
其中 d 为 fan_mode 即 W 的维度,而2对应的就是ReLU激活函数的增益 gain 。所以我们通过分别对W1乘以(5/3)/((block_size * n_embd)**0.5),W2乘以0.01,来使得 embcat 的分布的方差到 logits依旧保持不变,来控制logits分布范围,从而来降低初始 loss 大小,同时运用这钟方式来防止梯度消失或梯度爆炸从而提高训练效率(对于这个本文不再具体阐述,感兴趣者自行查阅),以上就是kiaming初始化的简略原理解析
4.2、Batch Normalization(批归一化)
这里我们将采用BN(批归一化)的方法,即添加BN层来改进我们的模型
4.2.1、批归一化方法
这里在我们前向传播中的预激活值 hpreact 进行层归一化处理(添加BN层)即可,这里由于是批归一化,所以对 hpreact 在0维度上(批次维度)进行均值计算或标准差计算;同时设置 keepdim = True 对齐格式使得后续广播正常运行;并在参数设置部分中初始化 bngain(仿射系数)、bnbias(偏置系数),并添加至 parameters 列表中告知模型此为需学习的参数
# forward pass
emb = C[Xb]
embcat = emb.view(emb.shape[0], -1)
hpreact = embcat @ W1 + b1
#BN
hpreact = bngain * (hpreact - hpreact.mean(0, keepdim = True) / hpreact.std(0, keepdim = Ture) + bnbias
h = torch.tanh(hpreact)
logits = h @ W2 + b2
loss = F.cross_entropy(logits, Yb) n_embd = 10
n_hidden = 200
batch_size = 32
g = torch.Generator().manual_seed(2147483647)
C = torch.randn((vocab_size, n_embd), generator=g)
W1 = torch.randn(((block_size * n_embd), n_hidden), generator=g) * (5/3)/((block_size * n_embd)**0.5)
b1 = torch.randn(n_hidden, generator=g) * 0.01
W2 = torch.randn((n_hidden,vocab_size), generator=g) * 0.01
b2 = torch.randn(vocab_size, generator=g) * 0 #更希望分布趋于0,因此取消偏置
bngain = torch.ones((1, n_hidden))
bnbias = torch.zeros((1, n_hidden))
parameters = [C, W1, b1, W2, b2, bnbias, bnbias] # the parameters need to learn这样我们就成功完成BN处理了,但是目前还不太完善:
当模型在测试或者推理阶段,输入的batch(批次)不同,或者很小,甚至为1(训练时 batch 是固定的),计算的批次均值和标准差就不稳定,导致模型输出不稳定,与训练时效果不同。此时我们在测试阶段应该采用固定滑动平均的批次均值和标准差。将上面的BN代码替换为以下部分,其中 bnmeani 和 bnstdi 是当前 batch 的均值和标准差,用于训练时对每个 batch 的数据做归一化;bnmean_running 和 bnstd_running 是 “滑动平均” 得到的全局均值和标准差,用于测试/推理时对新数据做归一化,由于这两个参数通过以下方式更新(训练)所以在前添加 with torch.no_grad:语句 避免添加至计算图中计算梯度。此外,因为BN层中bnbias的存在可以将线性变换hpreact = embcat @ W1 + b1中的b1去掉,避免不必要的运算
这里要根据训练时的批次设置 momentum(滑动平均系数,动量,即数值0.999),如果批次很大,可设置大些。因为批次越大,均值方差越稳定也越符合总体全局的分布情况,就不怎么需要新batch的影响了,所以减小 bni 前的系数,从而增大 bnrun 前的系数 momentum
hpreact = embcat @ W1 + #b1
bnmeani = hpreact.mean(0, keepdim=True)
bnstdi = hpreact.std(0, keepdim = True)
hpreact = bngain * (hpreact - bnmeani) / bnstdi + bnbias #批归一化
with torch.no_grad:
bnmean_running = 0.999 * bnmean_running + 0.001 * bnmeani
bnstd_running = 0.999 * bnstd_running + 0.001 * bnstdi
h = torch.tanh(hpreact) 同时在参数设置部分里初始化参数 bnmean_running 、bnstd_running(这里均值初始 zeros,标准差初始 ones)
bngain = torch.ones((1, n_hidden))
bnbias = torch.zeros((1, n_hidden))
bnmean_running = torch.zeros((1, n_hidden))
bnstd_running = torch.ones((1, n_hidden))测试时换上bnmean_running 、bnstd_running,提高模型泛化能力和稳定性
@torch.no_grad()
def split_loss(split):
x, y = {
'train': (Xtr, Ytr),
'val' : (Xdev, Ydev),
'test' : (Xte, Yte),
}[split]
emb = C[x]
embcat = emb.view(emb.shape[0], -1)
hpreact = embcat @ W1 + #b1
hpreact = bngain * (hpreact - bnmean_running) / bnstd_running + bnbias
h = torch.tanh(hpreact)
logits = h @ W2 + b2
loss = F.cross_entropy(logits, y)
print(f'{split:5}: {loss.item()}')4.2.2、批归一化原理(简略版)
这里将简单介绍该方法背后原理,想深度了解可查看原论文
批归一化通过按批次进行归一标准化使最终结果接近标准正态分布(不添加仿射与偏置系数时),进而让每一层激活前的分布更稳定,从而提高训练效率和稳定性,同时也可以避免某些数值过于极端,导致梯度消失或爆炸(因为如果正常流程训练,同一批次样本的嵌入数值可能出现极端值,在深层网络反向传播中,极端值中极大值(极小值)会使该层相关参数梯度也变大(变小),再在链式求导的过程中,相关参数梯度会成指数型变大(20*3*2.5....)或指数型变小( 0.1*0.002*0.1.....)进而导致参数更新(学习)幅度过大或不更新,从而使训练效率下降)
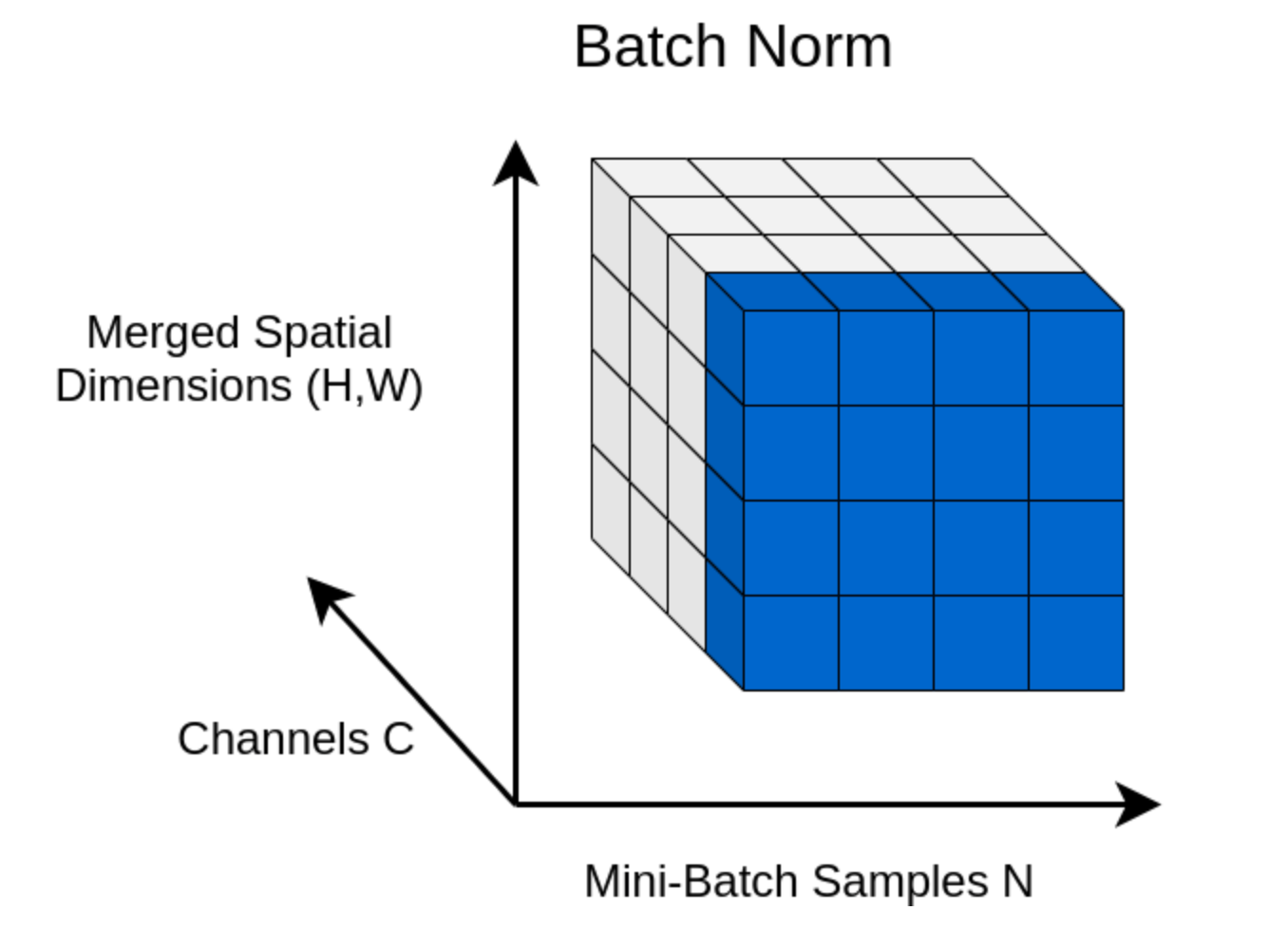
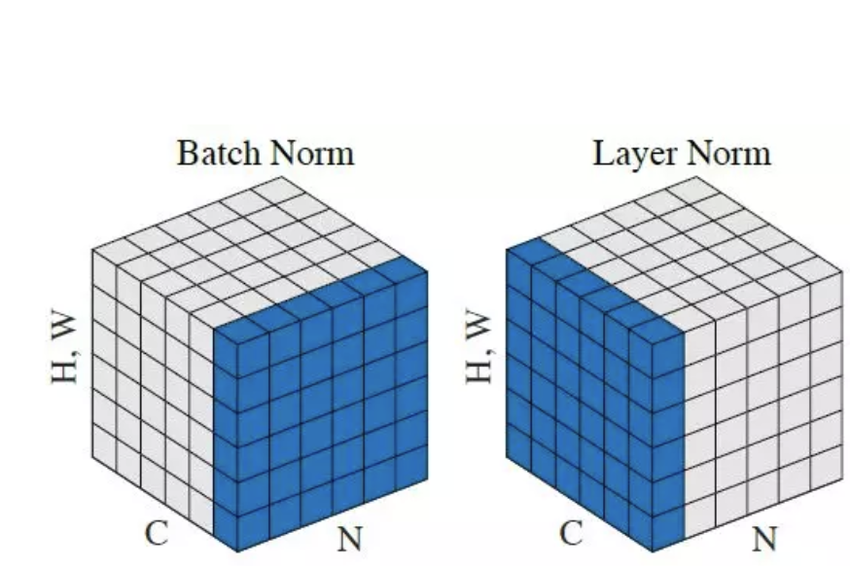
由上图(可能大家有点难以理解,因为这是卷积神经网络下的表示,在这里我们可以把 C 看作嵌入特征维度,(H, W)看作样本维度,N 就是批次维度(本文与图又略微有些不同,本文的案例一共两维(样本数,嵌入),所以根据图应该是蓝色的一柱而不是前面一墙))可看出,批归一化针对每个特征维度(如每个通道),在一个batch的所有样本,而本文没有覆盖的层归一化针对的是每个样本,在该样本的所有特征维度
distribution_un = torch.distributions.uniform.Uniform(-8, 8)
B = distribution_un.sample([5,6])
print(B, B.mean(), B.std(),'\n')
B = (B - B.mean(0, keepdim= True)) / B.std(0, keepdim= True)
print(B, B.mean(), B.std())
'''
tensor([[-1.8211, -4.0766, -4.2061, -0.4739, 7.4383, -6.5117],
[ 6.6283, 0.7573, -5.8306, 5.2195, 4.2608, -2.6610],
[ 5.3638, 0.9277, 6.9286, 5.9941, -0.1956, -5.0632],
[ 2.3594, 1.4474, 3.5610, -0.5998, 4.5420, 4.3209],
[-1.6365, 5.2778, 7.4352, -1.7727, 1.4311, -6.0032]])
tensor(1.1014) tensor(4.3804)
tensor([[-1.0282, -1.4863, -0.9285, -0.5905, 1.3308, -0.7482],
[ 1.1438, -0.0329, -1.1893, 0.9751, 0.2584, 0.1175],
[ 0.8188, 0.0183, 0.8590, 1.1881, -1.2458, -0.4225],
[ 0.0464, 0.1746, 0.3184, -0.6251, 0.3533, 1.6871],
[-0.9808, 1.3263, 0.9403, -0.9476, -0.6967, -0.6338]])
tensor(-7.9473e-09) tensor(0.9097)
'''由以上代码可知矩阵B通过批归一化,数值变得更集中,同时整体分布接近标准正态分布。但是由于各批次耦合,数据也丧失了部分统计特征(例如 B 第五批数据中第三维的数值是最大值但归一化后,变成了第二维)但这通常不会影响模型性能
这里附上数学公式,方便大家理解:
针对批次维度
首先根据所有批次,算出每一层(一共 m 批次)的均值μ
再算出每一层的方差σ
对所有参数进行标准化处理,并添加 ε 防止被除数为0
最后对所有参数添加 γ 和 β 进行伸缩平移变换即可
五、对我们建立的模型进行诊断
5.1、模型的PyTorch规范化包装过程
class Linear:
def __init__(self, fan_in, fan_out, bias = True):
self.weights = torch.randn((fan_in, fan_out), generator=g) / fan_in**0.5
self.bias = torch.zeros(fan_out) if bias else None
def __call__(self, x):
self.out = x @ self.weights
if self.bias is not None:
self.out += self.bias
return self.out
def parameters(self):
return [self.weights] + ([] if self.bias is None else [self.bias])
class BatchNorm1d:#hpreact-->hpreact, bngain, bnbias
def __init__(self, dim, eps=1e-5, momentum=0.1):
self.eps = eps
self.momentum = momentum
self.training = True
# parameters trained with backprop
self.gamma = torch.ones(dim)
self.beta = torch.zeros(dim)
# buffets trained with a running 'momentum update'
self.running_mean = torch.zeros(dim)
self.running_var = torch.ones(dim)
def __call__(self, x):
# calculate the forward poss
if self.training:
xmean = x.mean(0, keepdim=True)
xvar = x.var(0, keepdim=True, unbiased=True)
else:
xmean = self.running_mean
xvar = self.running_var
xhat = (x - xmean) / torch.sqrt(xvar + self.eps)
self.out = self.gamma * xhat + self.beta
#update the buffers
if self.training:
with torch.no_grad():
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * xmean
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * xvar
return self.out
def parameters(self):
return [self.gamma, self.beta]
class Tanh:
def __call__(self, x):
self.out = torch.tanh(x)
return self.out
def parameters(self):
return []
n_embd = 10
n_hidden = 100
g = torch.Generator().manual_seed(2147483647)
C = torch.randn((vocab_size, n_embd), generator=g)
layers = [
Linear(n_embd * block_size, n_hidden), Tanh(),
Linear( n_hidden, n_hidden), Tanh(),
Linear( n_hidden, n_hidden), Tanh(),
Linear( n_hidden, n_hidden), Tanh(),
Linear( n_hidden, n_hidden), Tanh(),
Linear( n_hidden, vocab_size)
]
#initial
with torch.no_grad():
layers[-1].weights *= 0.1
for layer in layers[:-1]:
if isinstance (layer, Linear):
layer.weights *= 5/3
#parameters
parameters = [C] + [p for layer in layers for p in layer.parameters()]
print(len(parameters))
print(sum(p.nelement() for p in parameters))
for p in parameters:
p.requires_grad = True5.2、模型训练的监控诊断与可视化
针对我们新创建的pytorch框架下的模型进行训练,训练max_steps次(200000),同时每次随机抓取batch_size个数据(32)进行前向传播
max_steps = 200000
batch_size = 32
lossi = []
for i in range(max_steps):
#mini batch
ix = torch.randint(0, Xtr.shape[0], (batch_size,))
Xb, Yb = Xtr[ix], Ytr[ix]
#forward pass
emb = C[Xb]
x = emb.view(emb.shape[0], -1)
for layer in layers:
x = layer(x)
loss = F.cross_entropy(x, Yb)
#backward pass
for layer in layers:
layer.out.retain_grad() #保留每一层输出的grad
for p in parameters:
p.grad = None
loss.backward()
#update
lr = 0.1 if i < 100000 else 0.01
for p in parameters:
p.data += -lr * p.grad
#track stats
if i % 10000 == 0:
print(f'{i:7d}/{max_steps:7d}: {loss.item():.4f}')
lossi.append(loss.log10().item()) 5.2.1、调试代码一(激活值分布)
这段代码的主要目的是可视化神经网络中每一层激活值(Activation)的分布情况。帮助我们观察是否存在梯度消失(Gradient Vanishing)或神经元饱和(Saturation)的问题。对于代码输出的三个部分:
-
mean(均值):希望接近 0。如果偏离太远,可能说明初始化存在偏置 -
std(标准差):衡量激活值的离散程度。如果std变得非常小(例如趋近于 0),说明网络出现了梯度消失 -
saturated(饱和度):统计输出值绝对值大于 0.97 的比例。由于 Tanh 函数在正负1附近梯度几乎为0,如果饱和度过高(接近1.00),神经元就会“死掉”,参数将无法更新。所以我们希望该值较低
针对于直方图可视化部分:
-
hx是直方图的横坐标(激活值的取值范围) -
hy是纵坐标(概率密度)
理想情况:我们会看到一个类似正态分布的曲线(中间高,两边低)。随着层数增加,曲线的宽度(std)能保持相对稳定。糟糕情况(饱和):曲线呈现“U型”,即大部分值都挤在-1和1两端。这意味着该层几乎所有神经元都处于饱和状态,训练会非常缓慢。糟糕情况(坍缩):所有层的曲线都变得非常尖锐且集中在0附近,这意味着神经元失去了表达能力
# visualize histograms
plt.figure(figsize=(20, 4)) # width and height of the plot
legends = []
for i, layer in enumerate(layers[:-1]): # note: exclude the output layer
if isinstance(layer, Tanh):
t = layer.out
print(f'Layer {i:2d} {layer.__class__.__name__:10s}: mean {t.mean():+.2f}, std {t.std():.2f}, saturated: {(t.abs() > 0.97).float().mean():.2f}')#希望较低
hy, hx = torch.histogram(t, density=True)
plt.plot(hx[:-1].detach(), hy.detach())
legends.append(f'layer {i} ({layer.__class__.__name__})')
plt.legend(legends)
plt.title('activation distribution')
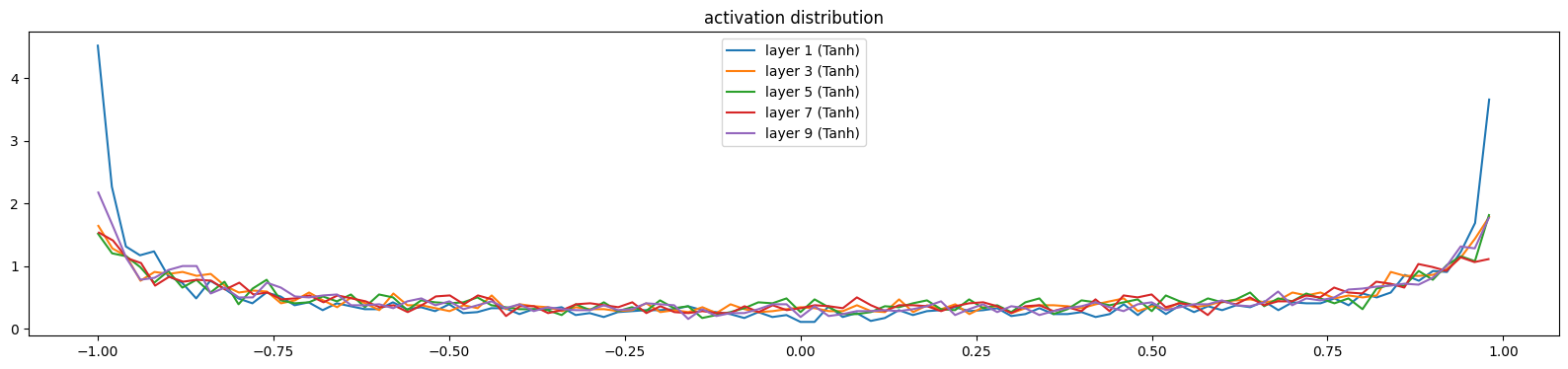
当模型没有添加任何归一化层时,是以下诊断效果(训练了100次的模型)
'''
Layer 1 Tanh : mean -0.05, std 0.76, saturated: 0.21
Layer 3 Tanh : mean -0.00, std 0.70, saturated: 0.10
Layer 5 Tanh : mean -0.00, std 0.68, saturated: 0.09
Layer 7 Tanh : mean -0.02, std 0.68, saturated: 0.08
Layer 9 Tanh : mean -0.03, std 0.70, saturated: 0.11
'''
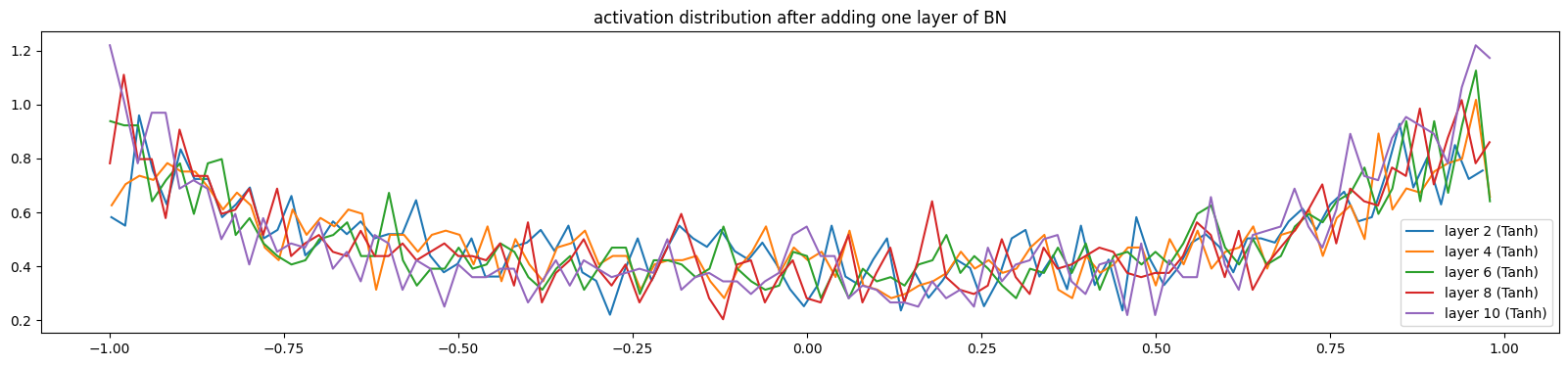
当我们逐步添加BN层,数据分布会逐渐健康(训练了100次的模型),激活值饱和度降低,数据波动幅度增大
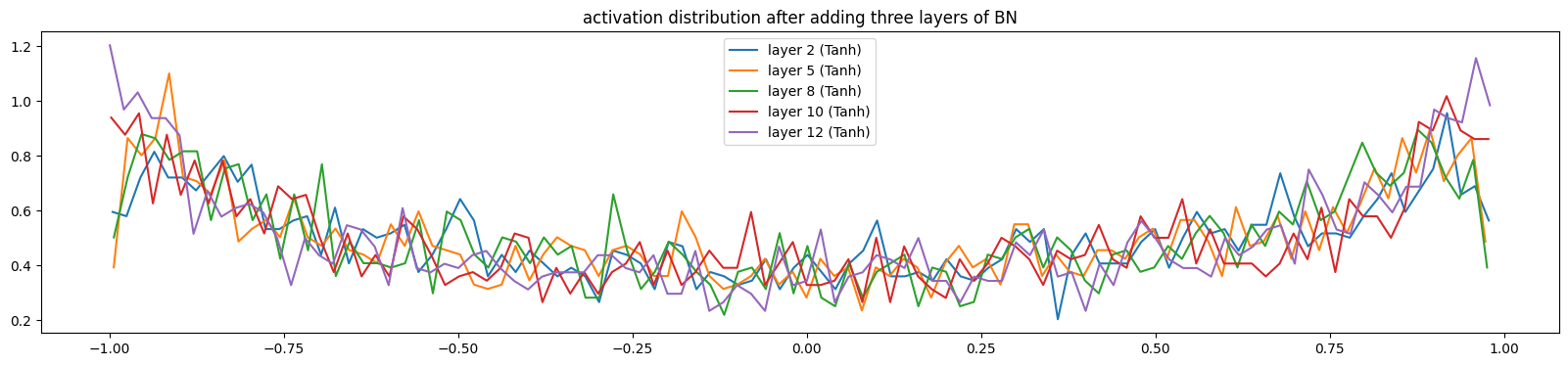
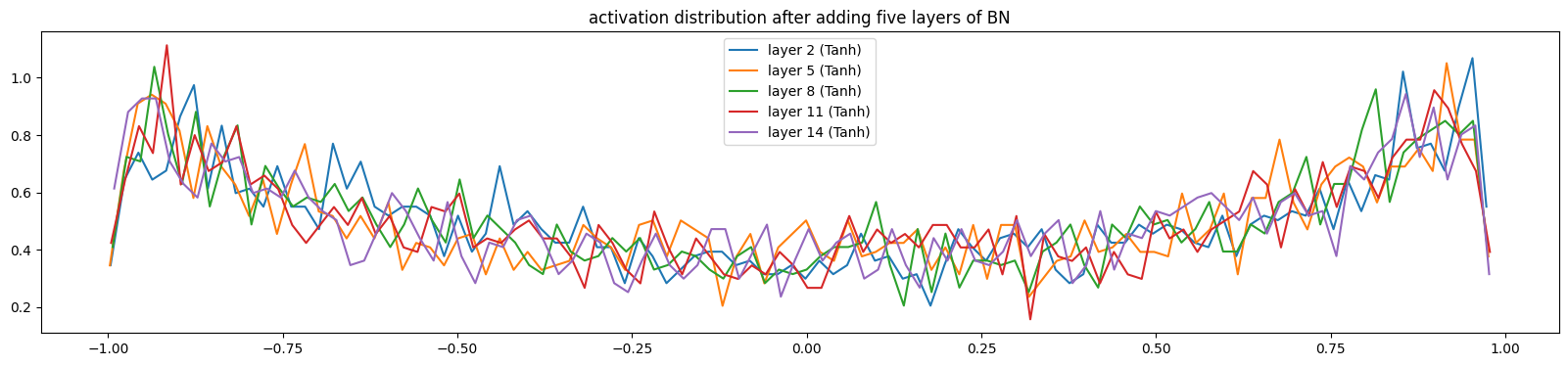
5.2.2、调试代码二(输出梯度分布)
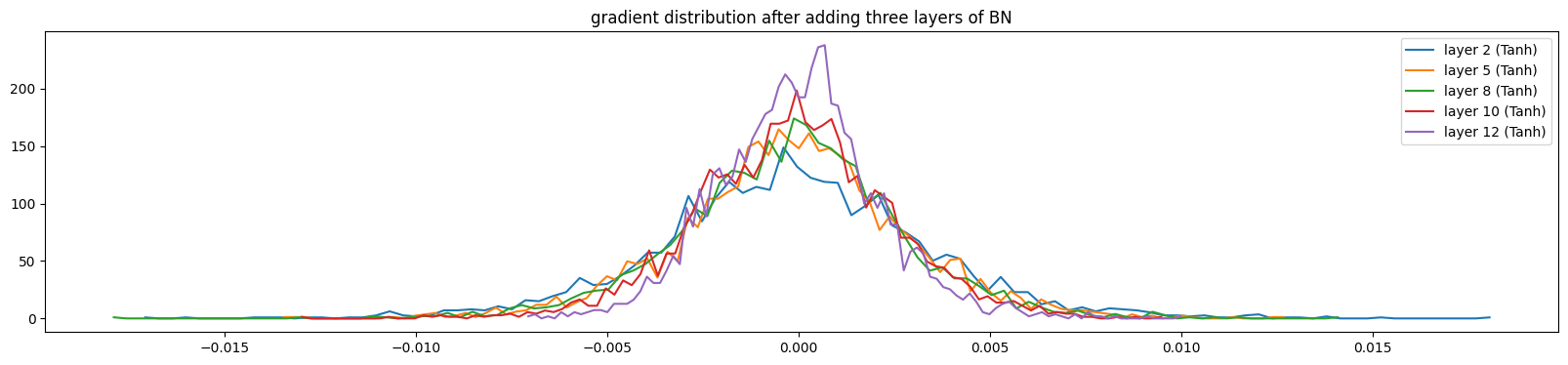
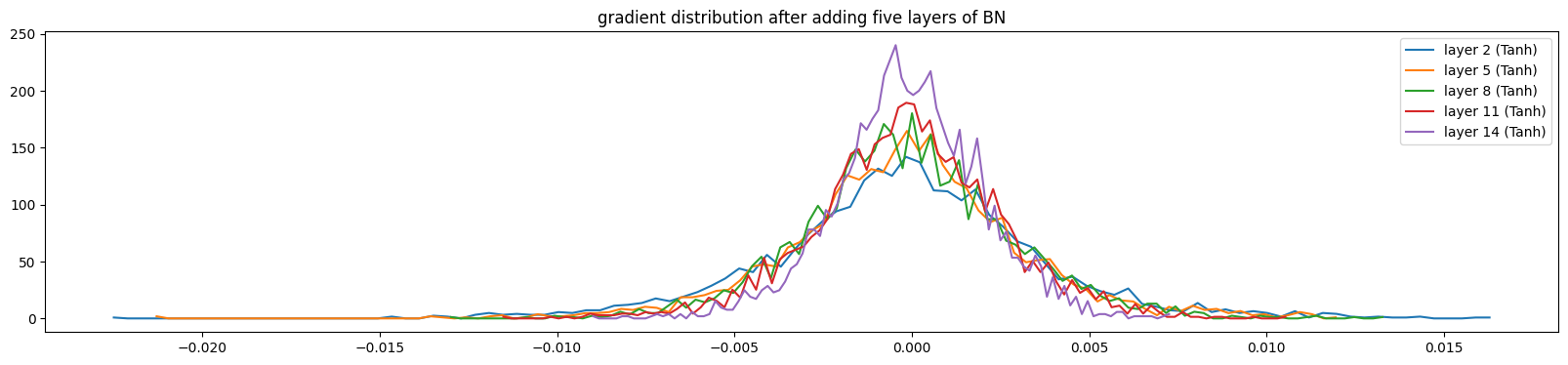
这段代码的主要目的是可视化神经网络中每一层的输出梯度(Gradient)的分布情况。帮助我们观察是否存在梯度消失(Gradient Vanishing)或梯度爆炸(Gradient explosion)的问题来确定模型反向传播的健康性。对于代码的输出:
-
mean:通常应该非常接近 0 -
std:这是最关键的指标。如果std变得极小(例如 10^{-7}甚至更小),就意味着发生了梯度消失(Gradient Vanishing)
针对直方图可视化部分可以直观地看到梯度在跨越不同层时的变化趋势:
-
健康的梯度分布: 每一层的曲线虽然会有所不同,但它们的宽度(标准差)应该大致保持在同一数量级。这意味着信号可以平稳地从输出层传回输入层。
-
梯度消失 (Vanishing Gradients): 你会发现靠近输出层的梯度曲线比较宽,但随着层数往前推(靠近输入层),曲线变得越来越“瘦”、越来越尖锐,最后几乎缩成一条线。这意味着前几层的参数几乎不会更新。
-
梯度爆炸 (Exploding Gradients): 如果
std随着层数往前推反而变得极大,或者数值直接变成了NaN(在图中消失或报错),说明权重初始化过大或没有合适的归一化。
# visualize histograms
plt.figure(figsize=(20, 4)) # width and height of the plot
legends = []
for i, layer in enumerate(layers[:-1]): # note: exclude the output layer
if isinstance(layer, Tanh):
t = layer.out.grad
print(f'Layer {i:2d} {layer.__class__.__name__:10s}: mean {t.mean():+.2f}, std {t.std():.2f}')
hy, hx = torch.histogram(t, density=True)
plt.plot(hx[:-1].detach(), hy.detach())
legends.append(f'layer {i} ({layer.__class__.__name__})')
plt.legend(legends)
plt.title('gradient distribution')
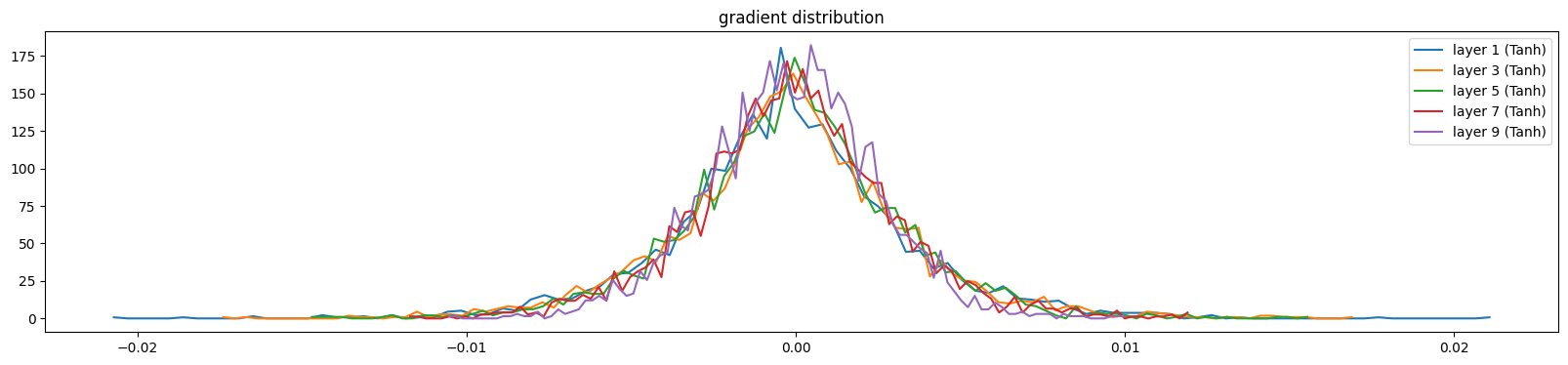
当模型没有添加任何归一化层时,是以下诊断效果(训练了1000次的模型)
'''
Layer 1 Tanh : mean -0.00, std 0.00
Layer 3 Tanh : mean -0.00, std 0.00
Layer 5 Tanh : mean +0.00, std 0.00
Layer 7 Tanh : mean +0.00, std 0.00
Layer 9 Tanh : mean -0.00, std 0.00
'''
当我们逐步添加BN层,数据分布会逐渐健康(训练了1000次的模型),输出梯度波动变大,方差增大,分布范围变广
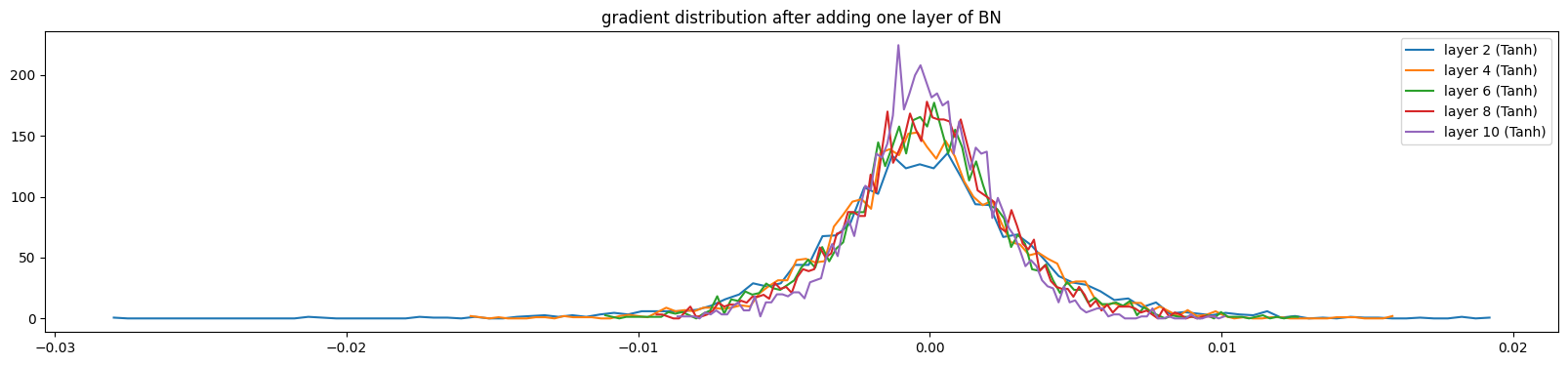
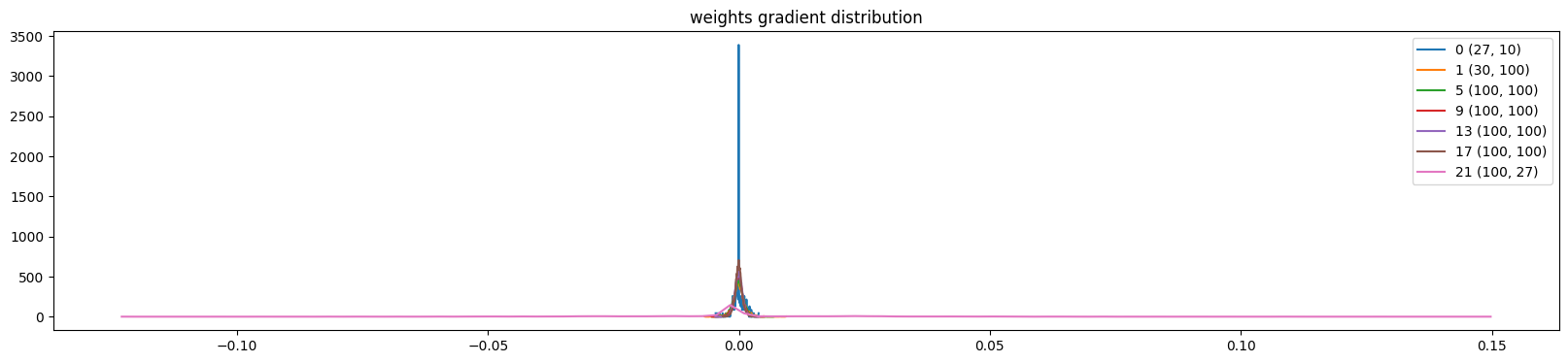
5.2.3、调试代码三(权重梯度分布)
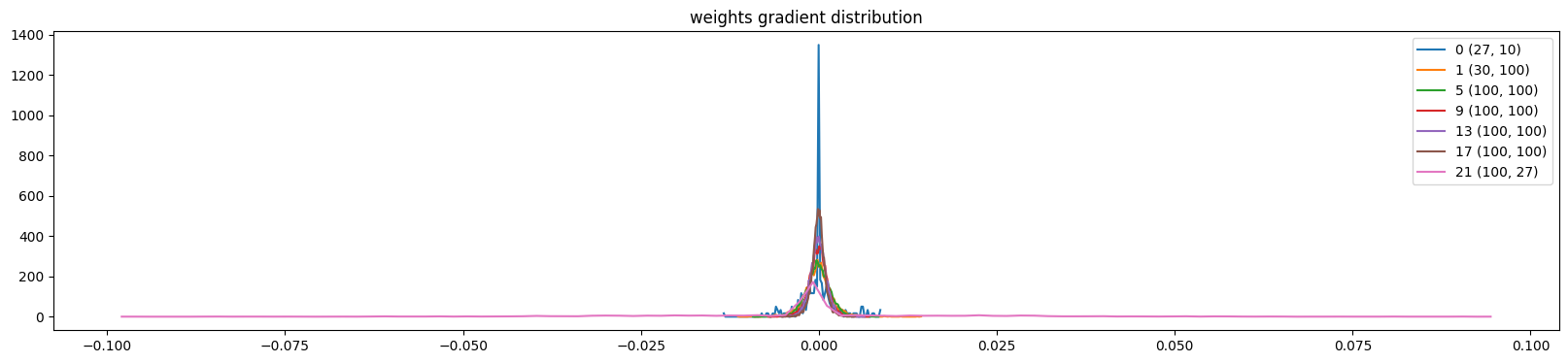
这段代码的目的是通过可视化权重梯度分布,量化“更新量相对于权重本身的大小”,来科学地调整学习率。对于代码输出指标:
-
t.std():梯度的标准差,代表了本次更新步长的大小 -
p.std():权重本身的标准差(代表参数当前的量级) -
mean:权重梯度的均值
-
std:权重梯度的标准差
-
grad:data ratio:它反映了本次更新对原有权重的“冲击”有多大。比率很大,更新步子跨得太大,会破坏权重中已经学到的特征。比率很小,更新太慢,网络学不动
plt.figure(figsize=(20, 4)) # width and height of the plot
legends = []
for i, p in enumerate(parameters):
t = p.grad
if p.ndim == 2:
print('weight %10s | mean %+f | std %e | grad:data ratio %e' % (tuple(p.shape), t.mean(), t.std(), t.std()/p.std()))#理想值处在1e-3,经验法则,训练较为健康
hy, hx = torch.histogram(t, density=True)
plt.plot(hx[:-1].detach(), hy.detach())
legends.append(f'{i} {tuple(p.shape)}')
plt.legend(legends)
plt.title('weights gradient distribution');当模型的学习率设置为1e-3(0.001),是以下诊断效果(训练了1000次的模型)
'''
weight (27, 10) | mean +0.000000 | std 2.636292e-03 | grad:data ratio 2.634386e-03
weight (30, 100) | mean -0.000001 | std 2.040283e-03 | grad:data ratio 6.542231e-03
weight (100, 100) | mean -0.000037 | std 1.767478e-03 | grad:data ratio 1.063974e-02
weight (100, 100) | mean -0.000014 | std 1.331869e-03 | grad:data ratio 7.933269e-03
weight (100, 100) | mean -0.000015 | std 1.156112e-03 | grad:data ratio 6.915307e-03
weight (100, 100) | mean -0.000009 | std 9.392737e-04 | grad:data ratio 5.612843e-03
weight (100, 27) | mean +0.000000 | std 1.993712e-02 | grad:data ratio 1.837942e+00
'''
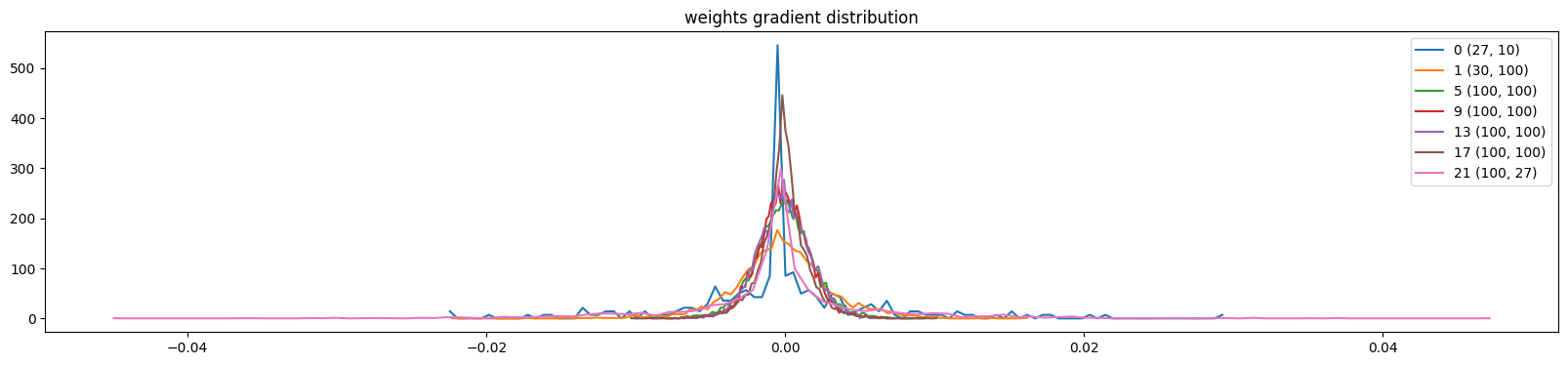
当模型的学习率设置为10(太大),是以下诊断效果(训练了1000次的模型),权重梯度分布更广,不稳定
'''
weight (27, 10) | mean -0.000000 | std 6.268097e-03 | grad:data ratio 6.082317e-03
weight (30, 100) | mean -0.000010 | std 3.285154e-03 | grad:data ratio 9.669649e-03
weight (100, 100) | mean -0.000019 | std 1.963488e-03 | grad:data ratio 1.049611e-02
weight (100, 100) | mean -0.000037 | std 1.716541e-03 | grad:data ratio 9.344053e-03
weight (100, 100) | mean -0.000024 | std 1.745233e-03 | grad:data ratio 9.574808e-03
weight (100, 100) | mean +0.000003 | std 1.593141e-03 | grad:data ratio 8.835938e-03
weight (100, 27) | mean +0.000000 | std 6.593126e-03 | grad:data ratio 5.146150e-02
'''
当模型的学习率设置为1e-5(0.00001)(太小),是以下诊断效果(训练了1000次的模型),权重梯度分布严重狭窄且极度趋于0
'''
weight (27, 10) | mean -0.000000 | std 1.124562e-03 | grad:data ratio 1.123748e-03
weight (30, 100) | mean -0.000009 | std 1.265874e-03 | grad:data ratio 4.059065e-03
weight (100, 100) | mean +0.000001 | std 1.095069e-03 | grad:data ratio 6.592019e-03
weight (100, 100) | mean -0.000004 | std 9.170544e-04 | grad:data ratio 5.462427e-03
weight (100, 100) | mean -0.000005 | std 8.179796e-04 | grad:data ratio 4.892764e-03
weight (100, 100) | mean -0.000003 | std 7.225646e-04 | grad:data ratio 4.317848e-03
weight (100, 27) | mean -0.000000 | std 2.202191e-02 | grad:data ratio 2.227489e+00
'''
5.2.4、调试代码四(更新量与数据量之比随时间变化的动态监控图)
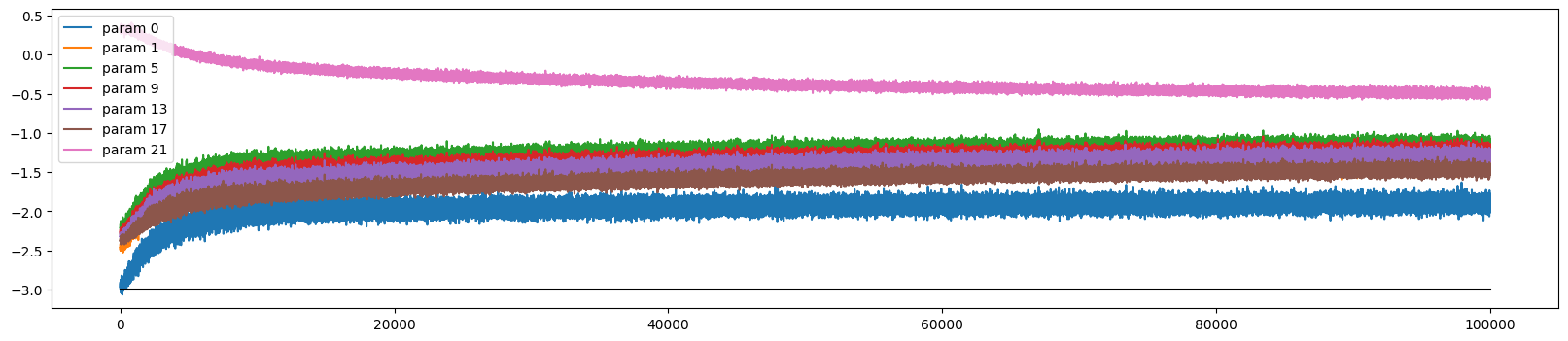
这段代码的核心目的是观察模型参数更新的节奏是否在整个训练过程中保持合理。验证学习率衰减:使用了学习率调度器(LR Scheduler),会看到这些曲线随着训练进行缓慢下降。检测训练震荡:如果曲线剧烈跳动,说明学习率可能过高,模型在损失平面上“乱跳”。检测学习停滞:如果所有曲线都远低于 -3 这条线(基准线),说明模型已经停止学习,或者学习率设置得过于保守。
plt.figure(figsize=(20, 4))
legends = []
for i, p in enumerate(parameters):
if p.ndim == 2:
plt.plot([ud[j][i] for j in range(len(ud))])
legends.append('param %d' % i)
plt.plot([0, len(ud)], [-3, -3], 'k') # these ratios should be ~1e-3, indicate on plot
plt.legend(legends);当模型的学习率设置为1e-3(0.001),是以下诊断效果(训练了100000次的模型)
六、构建waveNet模型进行生成
6.1、代码的进一步优化(前置改动)
在构建waveNet模型之前我们先优化一下我们的代码。在我们基类块,添加Eembeding、Flatten、Sequential类的定义来取代部分冗余代码
class Embedding:
def __init__(self, num_embeddings, embedding_dim):
self.weight = torch.randn(num_embeddings, embedding_dim)
def __call__(self, IX):
self.out = self.weight[IX]
return self.out
def parameters(self):
return [self.weight]
class Flatten:
def __call__(self, x):
self.out = x.view(x.shape[0], -1)
return self.out
def parameters(self):
return []
class Sequential:
def __init__(self, layers):
self.layers = layers
def __call__(self, x):
for layer in self.layers:
x = layer(x)
self.out = x
return self.out
def parameters(self):
return [p for layer in self.layers for p in layer.parameters()]有了Embedding类和Flatten类,我们就可以通过添加这些层来取代以下代码
...
Embedding(vocab_size, n_embd),
Flatten(),
...
C = torch.randn((vocab_size, n_embd), generator=g)
emb = C[Xb]
x = emb.view(emb.shape[0], -1)同时定义Sequential类,来装载模型,进一步简化前向传播的过程
model = Sequential([
Embedding(vocab_size, n_embd),
Flatten(),
Linear(n_embd * block_size, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, vocab_size)
])
#after
#forward pass
logits = model(Xb)
loss = F.cross_entropy(logits, Yb)
#before
#forward pass
emb = C[Xb]
x = emb.view(emb.shape[0], -1)
for layer in layers:
x = layer(x)
loss = F.cross_entropy(x, Yb)6.2、waveNet模型的搭建
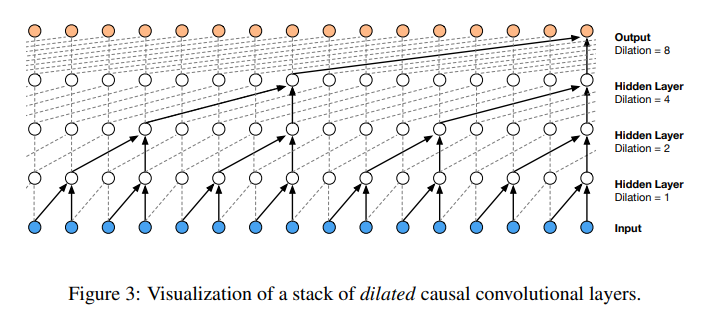
Thinking: 上图来源于原论文,这里我们只是采取waveNet模型的架构作为灵感来改进我们的模型,最后完成名字生成的任务。所以不用过度纠结上图和原论文的严谨性。本质上,这一部分是在三元特征输入的MLP基础(本博客第三部分)上进行的,在第三部分我们构建MLP来捕捉前三个字母的分布(X)和后一个字母(Y)的分布之间的联系进而完成名字生成任务。所以我们想,如果构造一个模型来捕捉前四个,五个,六个甚至八个字母(上图是16个)的分布和后一个字母的分布之间的联系,这样的效果会不会更好?但是实际上,如果输入信息过多,模型就“消化”不下,而waveNet通过类似卷积操作来“一口一口消化”,从而高效提取特征,最终解决了“消化”不下的问题,从而更好地完成了名字生成的任务
6.2.1、重新设置数据集
这里我只需将block_size参数设置为8,方便我们后续的操作,并重新生成数据集
block_size = 8
def build_dataset(dataset, block_size=8):
...
print(Xtr[:5])
print(Ytr[:5])
'''
tensor([[ 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 5],
[ 0, 0, 0, 0, 0, 0, 5, 12],
[ 0, 0, 0, 0, 0, 5, 12, 9],
[ 0, 0, 0, 0, 5, 12, 9, 1]])
tensor([ 5, 12, 9, 1, 14])
'''6.2.2、开始搭建模型
我们的洞察是,针对8个输入数据,每两个分组进行学习,之后每四个分组进行学习,最后整体进行学习。
1 2 3 4 5 6 7 8 -->
(1 2) (3 4) (5 6) (7 8) -->
(1 2 3 4) (5 6 7 8) -->
(1 2 3 4 5 6 7 8)通过以下简化的前向传播代码来看,对于嵌入后的数据(4, 8, 10)(这里将批次设置为4),我们应该把它分成(4,4,10*2)-->(4, 2, 10*4) -->(4,1,10*8),同时在每个箭头中间都构建一个隐藏层来进行学习意味着每种范式都添加一层神经网络进行学习,所以我们的模型架构应该是(4,4,10*2)-->NN-->(4, 2, ?) -->NN-->(4,1,?)-->NN-->logits
#设置以下模型
model = Sequential([
Embedding(vocab_size, n_embd),
Flatten(), Linear(n_embd * block_size, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, vocab_size)
])
ix = torch.randint(0, Xtr.shape[0], (4,))
Xb, Yb = Xtr[ix], Ytr[ix]
logits = model(Xb)
for layer in model.layers:
print(layer.__class__.__name__,':', tuple(layer.out.shape))
'''
Embedding : (4, 8, 10)
Flatten : (4, 80)
Linear : (4, 200)
BatchNorm1d : (4, 200)
Tanh : (4, 200)
Linear : (4, 27)
'''所以经过以上洞察,我们将模型改为以下架构 (这里注意对齐各个层之间的维度)。改动之前对我们Flatten类进行重新定义,添加一个参数 n 使其更灵活。这里的squeeze方法的作用是去除张量中维度为1的轴从而压缩张量
class FlattenConsective:
def __init__(self, n):
self.n = n
def __call__(self, x):
B, T, C = x.shape
x = x.view(B, T//self.n, C*self.n)
if x.shape[1] == 1:
x = x.squeeze(1)
self.out = x
return self.out
def parameters(self):
return []model = Sequential([
Embedding(vocab_size, n_embd),
FlattenConsective(2), Linear(n_embd * 2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
FlattenConsective(2), Linear(n_hidden * 2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
FlattenConsective(2), Linear(n_hidden * 2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, vocab_size)
])这样就完成了waveNet模型的搭建了,接着我们再进行一次前向传播来观察各层的输出形状是否符合预期
'''
Embedding : (4, 8, 10)
FlattenConsective : (4, 4, 20)<--
Linear : (4, 4, 200)
BatchNorm1d : (4, 4, 200)
Tanh : (4, 4, 200)
FlattenConsective : (4, 2, 400)<--
Linear : (4, 2, 200)
BatchNorm1d : (4, 2, 200)
Tanh : (4, 2, 200)
FlattenConsective : (4, 400)<--
Linear : (4, 200)
BatchNorm1d : (4, 200)
Tanh : (4, 200)
Linear : (4, 27)
'''值得注意的是,我们的batchnorm只能接收2维的张量,对于更改后的模型我们应该重新定义batchnorm使其能够兼容三维的张量,并在前两维上进行归一化。这里通过简单的代码来解释
#before
s = torch.arange(36).float()
s = s.view(2,3,6)
a = s.mean(0, keepdim=True)
print(s,a, a.shape)
'''
tensor([[[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10., 11.],
[12., 13., 14., 15., 16., 17.]],
[[18., 19., 20., 21., 22., 23.],
[24., 25., 26., 27., 28., 29.],
[30., 31., 32., 33., 34., 35.]]])
torch.Size([2, 3, 6])
tensor([[[ 9., 10., 11., 12., 13., 14.],
[15., 16., 17., 18., 19., 20.],
[21., 22., 23., 24., 25., 26.]]])
torch.Size([1, 3, 6])
以上只对0维的元素进行计算
'''
#after
s = torch.arange(36).float()
s = s.view(2,3,6)
a = s.mean((0,1), keepdim=True)
print(s,s.shape, a, a.shape)
'''
tensor([[[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10., 11.],
[12., 13., 14., 15., 16., 17.]],
[[18., 19., 20., 21., 22., 23.],
[24., 25., 26., 27., 28., 29.],
[30., 31., 32., 33., 34., 35.]]])
torch.Size([2, 3, 6])
tensor([[[15., 16., 17., 18., 19., 20.]]])
torch.Size([1, 1, 6])
以上对0,1维的元素都进行了计算,能够成功对三维的张量进行批归一化
'''class BatchNorm1d:#hpreact-->hpreact, bngain, bnbias
def __init__(self, dim, eps=1e-5, momentum=0.1):
self.eps = eps
self.momentum = momentum
self.training = True
# parameters trained with backprop
self.gamma = torch.ones(dim)
self.beta = torch.zeros(dim)
# buffets trained with a running 'momentum update'
self.running_mean = torch.zeros(dim)
self.running_var = torch.ones(dim)
def __call__(self, x):
# calculate the forward poss
if self.training:#<--这里改动即可
if x.ndim == 2:
dim = 0
if x.ndim == 3:
dim = (0,1)
xmean = x.mean(dim, keepdim=True)
xvar = x.var(dim, keepdim=True, unbiased=True)
else:
xmean = self.running_mean
xvar = self.running_var
xhat = (x - xmean) / torch.sqrt(xvar + self.eps)
self.out = self.gamma * xhat + self.beta
#update the buffers
if self.training:
with torch.no_grad():
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * xmean
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * xvar
return self.out
def parameters(self):
return [self.gamma, self.beta]6.2.3、模型测试与模型推理(4)
这里将我们嵌入维度(n_embd)设置为20,隐藏层(n_hidden)设置为200,批次(batch_size)设置为32,训练200000次
n_embd = 20
n_hidden = 200
model = Sequential([
Embedding(vocab_size, n_embd),
FlattenConsective(2), Linear(n_embd * 2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
FlattenConsective(2), Linear(n_hidden * 2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
FlattenConsective(2), Linear(n_hidden * 2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, vocab_size)
])
# parameters init
with torch.no_grad():
model.layers[-1].weights *= 0.1
parameters = model.parameters()
print(sum(p.nelement() for p in parameters))
for p in parameters:
p.requires_grad = True、
max_steps = 200000
batch_size = 32
lossi = []
for i in range(max_steps):
#mini batch
ix = torch.randint(0, Xtr.shape[0], (batch_size,))
Xb, Yb = Xtr[ix], Ytr[ix]
#forward pass
logits = model(Xb)
loss = F.cross_entropy(logits, Yb)
#backward pass
for p in parameters:
p.grad = None
loss.backward()
#update
lr = 0.1 if i < 100000 else 0.01
for p in parameters:
p.data += -lr * p.grad
#track stats
if i % 10000 == 0:
print(f'{i:7d}/{max_steps:7d}: {loss.item():.4f}')
lossi.append(loss.log10().item())
得到训练损失图
plt.plot(torch.tensor(lossi).view(-1, 100).mean(1))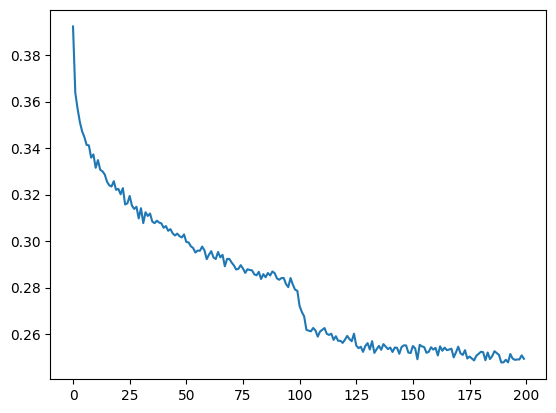
对训练好的模型进行测试
for layer in model.layers:
layer.training = False
@torch.no_grad()
def split_loss(split):
x, y = {
'train': (Xtr, Ytr),
'val' : (Xdev, Ydev),
'test' : (Xte, Yte),
}[split]
logits = model(x)
loss = F.cross_entropy(logits, y)
print(f'{split:5}: {loss.item()}')
split_loss('train')
split_loss('val')
split_loss('test')
'''
train: 1.7191288471221924
val : 2.0752551555633545
test : 2.0733449459075928
'''最后进行模型推理,名字生成
# sample from the model
for _ in range(20):
out = []
context = [0] * block_size # initialize with all ...
while True:
# forward pass the neural net
logits = model(torch.tensor([context]))
probs = F.softmax(logits, dim=1)
# sample from the distribution
ix = torch.multinomial(probs, num_samples=1).item()
# shift the context window and track the samples
context = context[1:] + [ix]
out.append(ix)
# if we sample the special '.' token, break
if ix == 0:
break
print(''.join(itos[i] for i in out)) # decode and print the generated word'''
moliyah.
aleksie.
leonathanna.
nyzie.
jannyson.
adiana.
caileigh.
nukima.
lyannah.
alexanda.
lainah.
alan.
zakira.
ayna.
lentona.
akamai.
geylani.
leona.
remelle.
malany.
'''通过以上生成的结果并对于模型推理(1,2,3)发现,模型效果确实很好,很大一部分都具有可读性,合理性
感谢您能看到这里,有什么疑问意见可以留在评论区或者私信我,我们一起进步,共同学习!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)