小米开源新成果!
AI科技圈最近一周又发生了啥新鲜事?

AI科技圈最近一周又发生了啥新鲜事?
OpenAI发布GPT-5.2-Codex,专为复杂软件工程优化
OpenAI推出GPT-5.2-Codex,作为GPT-5.2的智能体编码专用版本,在指令遵循、长上下文理解及词元效率方面显著提升,尤其在中高推理负载下表现更优。该模型在SWE-Bench Pro和Terminal-Bench 2.0两大真实软件工程基准测试中取得当前最佳成绩,支持大型代码重构、迁移和功能构建等复杂任务,并增强Windows环境下的终端编码可靠性。其原生压缩机制可维持长时间会话中的完整上下文,同时提升网络安全能力,在漏洞发现等防御性任务中已展现实际效用。GPT-5.2-Codex已向付费ChatGPT用户开放,API访问权限将在未来几周内逐步推出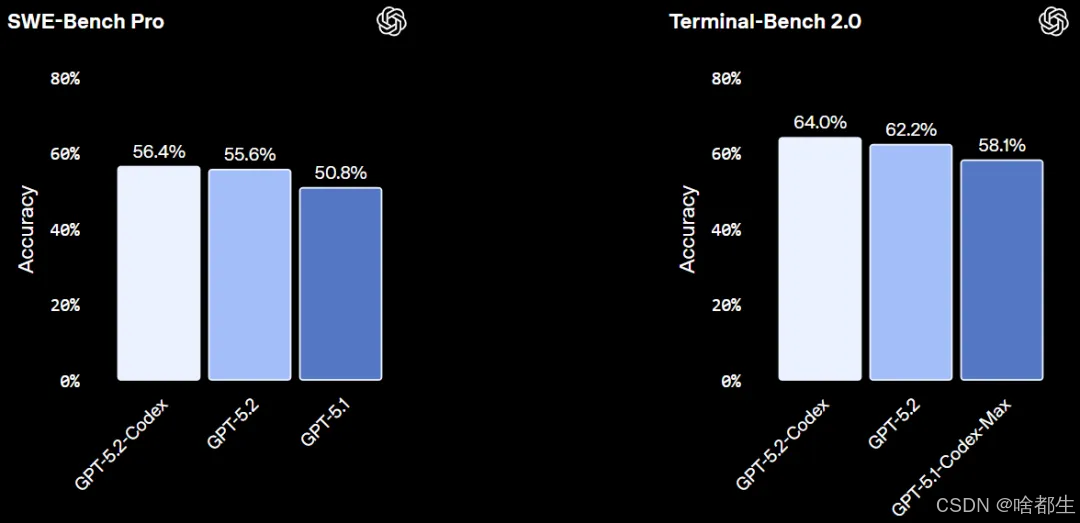
https://openai.com/index/introducing-gpt-5-2-codex/
谷歌发布Gemini 3 Flash,多模态性能媲美Pro模型
谷歌推出Gemini 3 Flash模型,作为Gemini应用和搜索AI模式的默认模型,面向全球用户及开发者开放。该模型在Humanity’s Last Exam基准中得分33.7%(不使用工具),接近Gemini 3 Pro的37.5%和GPT-5.2的34.5%;在MMMU Pro多模态测试中达81.2%,与Gemini 3 Pro持平,并在ARC-AGI-2和SWE-Bench Verified等任务中超越后者。Gemini 3 Flash体积较前代缩小3–4倍,平均token使用量减少约30%,推理速度提升3倍,成本显著低于Gemini 2.5 Pro。定价为输入0.5美元/百万token、输出3美元/百万token、音频输入1美元/百万token。模型支持动态调节思考深度,响应时间基本在1秒以内,已集成至Google AI Studio、Vertex AI、Gemini Enterprise及移动端应用
https://blog.google/products/gemini/gemini-3-flash/
字节跳动发布通用Agent模型Seed 1.8
字节跳动正式推出通用Agent大模型Seed 1.8,具备原生多模态能力,支持图文输入并可直接“看见”和操作图形界面。该模型集成搜索、代码生成与GUI Agent能力,在BrowseComp-en基准中得分67.6,超越Gemini-3-Pro;在Agentic Coding、FinSearchComp、XpertBench和WorldTravel等真实场景评测中表现稳定,其中WorldTravel任务得分达47.2。Seed 1.8还优化了图片编码token消耗,支持三种思考模式以动态调整推理深度,并在ZeroBench视觉推理测试中取得11.0分,在VLMsAreBiased基准中获62.0分。视频理解方面,其在VideoMME长视频评测中得分87.8,并引入“VideoCut”工具提升高帧率运动感知能力。模型已上线火山引擎豆包大模型平台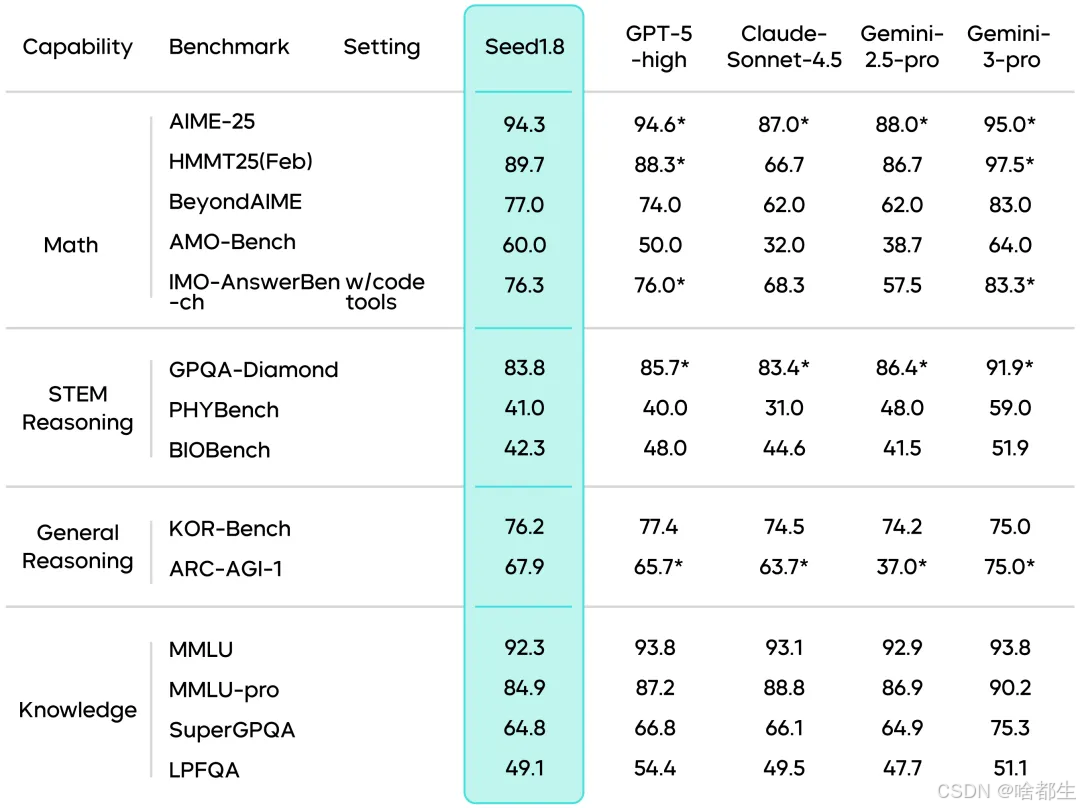
https://research.doubao.com/zh/seed1_8
小米开源MiMo-V2-Flash大模型
小米正式发布并开源大模型MiMo-V2-Flash,总参数量3090亿,活跃参数150亿,采用专家混合(MoE)架构,在AIME 2025数学竞赛和GPQA-Diamond科学测试中位列开源模型前两名,SWE-bench Verified编程修复得分73.4%,超越所有开源模型。该模型支持256K上下文窗口,推理速度达150 tokens/秒,输入成本为每百万token 0.1美元、输出0.3美元。核心技术包括5:1混合滑动窗口注意力机制(窗口大小128)和轻量级多Token预测(MTP),后者平均接受2.8–3.6个token,推理提速2–2.6倍。训练阶段采用FP8混合精度处理27万亿token数据,并通过多教师在线策略蒸馏(MOPD)将后训练算力需求降至传统方法的1/50。模型权重以MIT协议在Hugging Face开源,推理代码已贡献给SGLang
http://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf
OpenAI 最强 AI 生图模型GPT Image 1.5登场
OpenAI推出全新旗舰图像生成模型GPT Image 1.5,具备更强的提示词遵循能力,可在从零生成或基于上传图片编辑时精准保留光线、构图和人物外观等核心要素。该模型显著改善了AI绘图中长期存在的文本乱码问题,能准确将文字融入图像,并支持用户通过新增的“Images”标签页进行元素添加、移除、组合或位移等精细操作。GPT Image 1.5已面向全球所有ChatGPT及API用户开放,兼容所有模型,其研发由Sora负责人Bill Peebles与DALL·E缔造者Aditya Ramesh共同领导,底层可能融合“世界模拟”技术,为未来图像与视频生成一体化铺路。安全方面,OpenAI组建了超20人的专项团队负责内容合规与滥用防控
https://www.ithome.com/0/905/534.htm
腾讯混元发布世界模型1.5(WorldPlay),国内首个开放实时体验
腾讯混元推出世界模型1.5(Tencent HY WorldPlay),用户可通过文字或图片创建可实时交互的3D虚拟世界,支持键盘、鼠标或手柄控制视角自由探索,并具备“空间记忆”能力——离开后返回同一区域时能保持几何结构一致。模型基于自回归扩散架构,采用重构记忆力、长上下文蒸馏和3D强化学习等技术,实现24帧/秒、720P分辨率的流式视频生成,支持分钟级3D一致性内容输出。该框架已开源,涵盖数据、训练、推理部署全链路,并提供3D点云导出、文本触发事件、第一/第三人称视角切换等功能,适用于游戏生成、影视预演和具身智能训练等场景
https://github.com/Tencent-Hunyuan/HY-WorldPlay
字节跳动发布Seedance 1.5 Pro
字节跳动推出新一代音视频创作模型Seedance 1.5 Pro,支持文本或图像到音视频的端到端联合生成,实现高精度音画同步、多语种(含中文方言如四川话、粤语)语音生成及电影级运镜控制。该模型采用统一MMDiT多模态架构,支持长镜头跟随、希区柯克变焦等复杂镜头调度,并在语义理解、叙事协调性和动态张力方面显著提升。评测显示其在音频指令遵循、音质表现和音画同步方面处于业界前列,已上线即梦AI和豆包App
https://seed.bytedance.com/seedance1_5_pro
LiblibAI上线Wan 2.6视频模型,中国版SORA2
LiblibAI平台正式上线Wan 2.6视频生成模型,支持输出15秒1080P高清视频,具备视频参考生成、声画同步和多镜头智能调度能力。该模型可复刻任意5秒视频中的人物、动物或物体作为主角,并同步复现其音色;支持单人表演、双人合拍及配乐、音效与人声的完整声画同步。在多镜头叙事方面,能理解自然语言或专业分镜提示词,在单段视频中实现多视角切换并保持关键信息一致。即日起至12月22日,开通旗舰版年会员可享365天0积分畅玩Wan 2.6模型。
https://www.liblib.art/ai-tool/video-generator
英伟达发布Nemotron 3开源AI模型系列,吞吐量达上一代4倍
英伟达推出Nemotron 3开源模型系列,包含Nano、Super和Ultra三种规格,采用混合专家(MoE)架构,面向多智能体AI系统开发。其中Nemotron 3 Nano为300亿参数模型,每次激活约30亿参数,相较上一代吞吐量提升4倍,推理token生成减少60%,并支持100万token上下文窗口;Super版本约1000亿参数,每token激活100亿参数;Ultra版本参数规模约5000亿,每token最多激活500亿参数。Nemotron 3 Nano已上线Hugging Face,Super与Ultra预计2026年上半年发布,安永、思科、Oracle、西门子等企业已开始集成该系列模型
https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8
通义百聆开源Fun-CosyVoice3与Fun-ASR-Nano,支持9语种18方言音色克隆
通义百聆发布并同步开源Fun-CosyVoice3和Fun-ASR-Nano两大语音模型。Fun-CosyVoice3支持9种通用语言、18种中文方言及9种情感控制,具备跨语种音色克隆能力,仅需3秒参考音频即可复刻音色;其首包延迟降低50%,中英混说词错误率下降56.4%,zero-shot TTS在复杂场景下字符错误率降低26%。配套开源的Fun-CosyVoice3-0.5B模型支持本地部署与二次开发。语音识别方面,Fun-ASR在嘈杂环境(如会议室、地铁)中识别准确率达93%,支持31种语言自由混说、7大方言及26种口音,并新增歌词与说唱识别能力,流式识别首字延迟降至160ms;轻量化版本Fun-ASR-Nano-0.8B同步开源,适用于低资源场景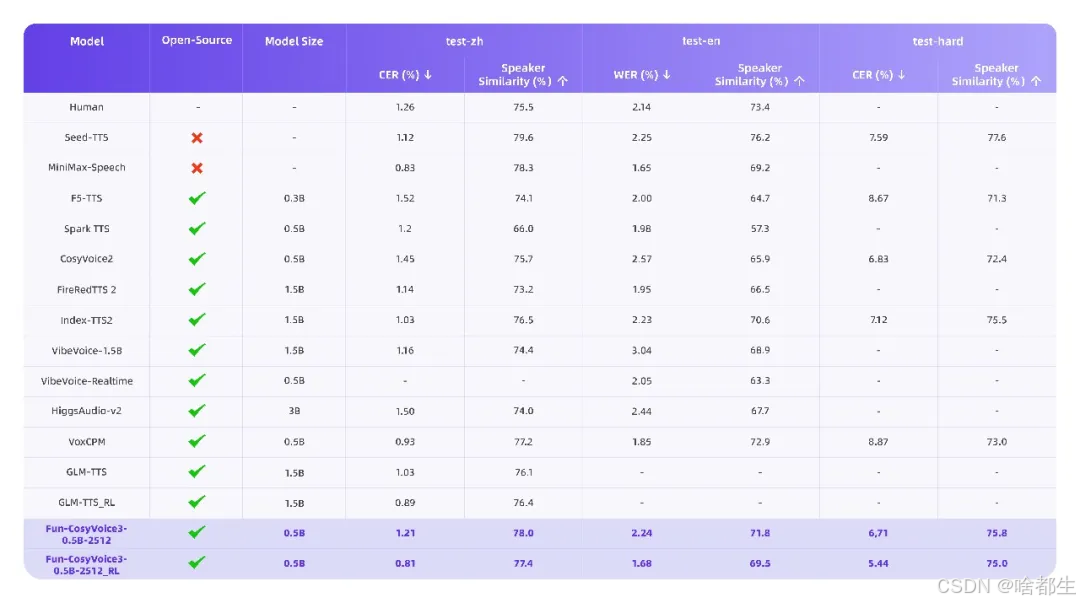
https://github.com/FunAudioLLM/CosyVoice
商汤发布Seko 2.0,合作短剧登顶抖音AI短剧榜No.1
商汤科技推出AI创编一体智能体Seko 2.0,专为短剧与漫剧创作者设计,支持100集以内剧本的连续生成,并通过SekoIDX技术解决跨分镜角色一致性难题,在保持角色特征稳定的同时避免“复制粘贴”式僵化。其SekoTalk模块为业内首个支持超过2人对口型的方案,实现多人对话场景下的精准音画同步。自2025年7月上线以来,Seko已吸引超20万创作者,其中30%为短剧创作者;借助Seko 2.0,50集漫剧制作周期可缩短80%~90%。商汤同步推出国产化推理框架LightX2V,在消费级显卡上5秒内生成5秒视频,并完成寒武纪、沐曦等国产芯片适配,国产平台1秒可生成1.0625秒视频,接近国际芯片性能。合作短剧《婉心计》已登顶抖音AI短剧榜第一
https://seko.sensetime.com
OpenAI开源Circuit Sparsity模型,99.9%权重为零
OpenAI开源了一种基于Circuit Sparsity技术的新语言模型,参数规模为0.4B,其中99.9%的权重被训练为零,仅保留千分之一的有效连接通路。该模型通过严格约束L0范数和均值屏蔽剪枝方法,在预训练损失相同条件下,构建出比稠密模型小16倍的任务专属“计算电路”,每个模块具备必要性与充分性,支持精准追踪推理逻辑。例如处理Python引号闭合任务时,仅需2个MLP神经元和1个注意力头即可构成完整功能电路。相比主流MoE架构依赖路由器分配专家、存在特征割裂与知识冗余问题,Circuit Sparsity追求原生稀疏性,使特征单义且正交。目前该方法训练和推理成本为稠密模型的100–1000倍,尚未达到顶尖大模型性能,但团队正探索从稠密模型提取稀疏电路或优化原生训练流程以提升效率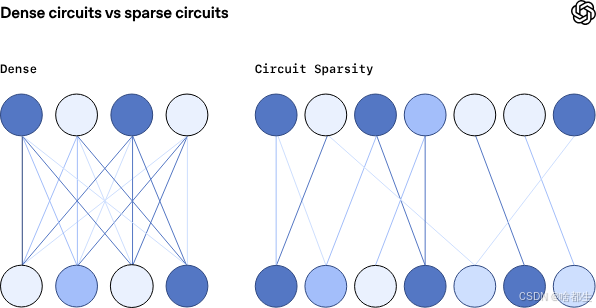
https://openai.com/zh-Hans-CN/index/understanding-neural-networks-through-sparse-circuits/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)