EAT: Self-Supervised Pre-Training with Efficient Audio Transformer论文阅读
自监督学习(SSL)已成为音频表示学习的关键方法,其灵感来源于自然语言处理 [Devlin et al., 2018;Radford et al., 2018]、计算机视觉 [Chen et al., 2020;He et al., 2020] 以及语音处理 [Hsu et al., 2021;Ma et al., 2023] 中的成功经验。SSL 的优势在于能够利用海量未标注数据,使模型有效学习
1 引言
自监督学习(SSL)已成为音频表示学习的关键方法,其灵感来源于自然语言处理 [Devlin et al., 2018; Radford et al., 2018]、计算机视觉 [Chen et al., 2020; He et al., 2020] 以及语音处理 [Hsu et al., 2021; Chen et al., 2022b; Ma et al., 2023] 中的成功经验。SSL 的优势在于能够利用海量未标注数据,使模型有效学习数据特征。
音频领域 SSL 成功的关键在于掩码自编码器(masked autoencoder)模型和自举(bootstrap)方法,这两种方法因其从输入数据中提取丰富特征的能力而备受推崇。基于重建的方法(如 BERT [Devlin et al., 2018] 和 MAE [He et al., 2022])通过从有限的未掩码上下文中预测全局信息来学习表示;相比之下,BYOL [Grill et al., 2020] 及其衍生方法则通过在线网络与目标网络,在数据增强的基础上执行预测任务,实现持续的自学习。这些技术已被成功迁移到音频 SSL 模型中。
例如,SSAST [Gong et al., 2022]、MAE-AST [Baade et al., 2022] 和 Audio-MAE [Huang et al., 2022] 专注于从掩码片段中重建音频频谱图;而 BYOL-A [Niizumi et al., 2021]、ATST [Li and Li, 2022] 和 M2D [Niizumi et al., 2023] 则在增强后的频谱图数据上采用基于自举框架的自学习方式,在预训练阶段学习音频潜在表示。
尽管已有诸多进展,预训练的高昂计算成本仍是主要瓶颈。例如,Audio-MAE 试图通过高掩码率并仅将未掩码片段送入编码器来提升编码效率,但这通常需要复杂的解码器(如 SwinTransformer [Liu et al., 2021]),反而延长了训练过程。其他音频 SSL 模型则通过简化学习任务来加速预训练。例如,BEATs [Chen et al., 2022a] 使用分词器(tokenizer)将目标特征离散化,从而在每次迭代中聚焦语义丰富的音频标记,但这种量化方法可能导致客观信息丢失,并需要更多预训练轮次。
因此,我们提出高效音频 Transformer(EAT)模型,专为高效学习音频语义并在下游任务中实现卓越性能而设计。EAT 舍弃了传统重建音频片段或预测离散特征的方法,转而在预训练中采用一种独特的“话语-帧目标”(UFO),将全局话语级与局部帧级表示协同用于预测任务。这种融合音频频谱图中全局与局部信息的双层级目标,显著增强了模型对音频片段的理解能力。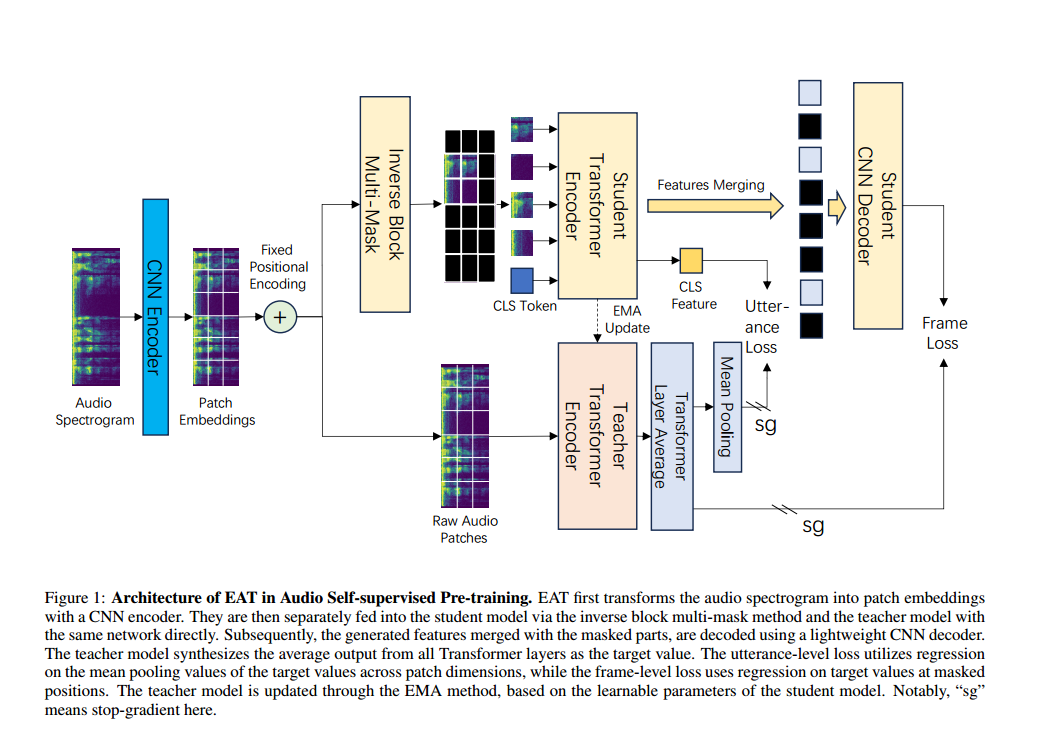



如图 1 所示,EAT 采用自举框架:学生模型持续使用教师模型生成的目标特征进行更新,而教师模型则通过指数移动平均(EMA)机制逐步更新,类似于 MoCo [He et al., 2020]。
在预训练任务方面,EAT 采用掩码语言建模(MLM),掩码率为 80%,聚焦于下采样音频频谱图的块嵌入(patch embeddings),并辅以固定的正弦位置嵌入。受 data2vec 2.0 [Baevski et al., 2023] 在图像模态中掩码方法的启发,EAT 在音频块上采用“反向块多掩码”(inverse block multi-mask)策略。该方法以块为单位保留未掩码数据,从而形成更大范围的局部连续区域,增加了提取音频语义和预测掩码特征的难度。同时,多掩码策略也补偿了教师模型在预训练中需对完整原始音频块进行编码所带来的计算开销。通过对学生模型输入多个掩码克隆(仅编码掩码部分),显著提升了数据利用效率。
最后,我们设计了一种非对称网络架构,结合复杂的 Transformer 编码器与轻量级 CNN 解码器,高效解码特征,实现精确的帧级特征预测。
凭借高效的自学习机制,EAT 能够有效获取关键音频特征。实验表明,EAT 在大幅减少总训练时长的前提下,在多个音频与语音分类数据集上均达到 SOTA 性能,充分体现了其在音频领域卓越的泛化能力和学习效率。
我们的主要贡献总结如下:
• 提出一种新颖的“话语-帧目标”(UFO),用于音频 SSL 预训练中的潜在表示学习,并验证了话语级学习在预训练中的关键作用。
• 采用源自 data2vec 2.0 的反向块多掩码方法,在音频块上使用高掩码率,显著加速音频自举框架下的预训练过程。实验表明,EAT 在预训练效率上大幅超越先前的音频 SSL 模型。
• 在多个主流音频相关数据集上取得 SOTA 结果。相关代码与预训练模型已开源,以促进社区发展。
2 相关工作
2.1 自举方法
自举方法最初由 BYOL [Grill et al., 2020] 引入自监督学习领域。BYOL 架构包含两个组件:目标编码器(target encoder)和预测器网络(predictor network)。目标编码器负责生成代表性目标,而预测器网络则尝试使用输入数据的增强版本来预测这些目标。预测器通过预测目标进行更新,而目标编码器则通过动量更新(源自 MoCo [He et al., 2020])进行缓慢演化。该方法启发了一系列后续的自监督视觉模型,如 DINO [Caron et al., 2021]、SimSiam [Chen and He, 2021] 和 MoCo v3 [Chen et al., 2021]。
将自举方法拓展至多模态,data2vec [Baevski et al., 2022] 及其升级版 data2vec 2.0 [Baevski et al., 2023] 代表了自监督学习的重要进展。这些模型采用基于掩码的技术构建对比预训练任务,显著提升了预训练效率。其方法还涉及回归多个神经网络层的表示,而非仅关注顶层输出。
受 BYOL-A [Niizumi et al., 2021] 和 M2D [Niizumi et al., 2023] 等模型的启发,我们的 EAT 模型也将自举方法应用于音频领域,旨在提升音频特征学习能力的同时提高预训练效率。
2.2 自监督音频预训练
音频领域的自监督学习(SSL)通常利用大量未标注数据进行广泛预训练,以学习音频潜在特征。在选择领域内预训练数据时,主要有两种策略:一是联合预训练,即同时使用语音和通用音频数据,如 SS-AST [Gong et al., 2022] 和 MAE-AST [Baade et al., 2022];二是更常见的做法——仅使用通用音频数据进行预训练,如 MaskSpec [Chong et al., 2023]、MSM-MAE [Niizumi et al., 2022]、Audio-MAE [Huang et al., 2022] 以及我们的 EAT 模型。
不同音频 SSL 模型在各组件上采用多种方法。在输入数据方面,wav2vec 2.0 [Baevski et al., 2020] 和 data2vec 处理原始波形,而大多数其他模型(包括 EAT)则使用梅尔频谱图提取特征。在预训练任务方面,采用掩码语言建模(MLM)技术的模型(如 MAE-AST、Audio-MAE 和 EAT)对音频块施加较高的掩码率;而 BYOL-A [Niizumi et al., 2021] 和 ATST [Li and Li, 2022] 则使用 mixup、随机缩放裁剪(RRC)等增强技术,提供多样化的听觉视角。
预训练目标也因模型而异。例如,Audio-MAE 和 MAE-AST 采用 MAE 风格的任务,通过未掩码数据重建原始频谱图块;BEATs [Chen et al., 2022c] 则使用分词器进行离散化语义特征预测;而 data2vec、BYOL-A 和 M2D 等模型则聚焦于预测潜在表示。在 EAT 中,我们将表示预测任务改进为“话语-帧目标”(UFO),以同时考虑音频频谱图中的全局与局部信息。
3 方法
EAT 受 data2vec 2.0 [Baevski et al., 2023] 和 Audio-MAE [Huang et al., 2022] 的启发,融合了自举(bootstrap)与掩码建模(masked modeling)方法,以高效学习音频频谱图的潜在表示。在此过程中,我们设计了一种非对称网络架构:使用标准 Transformer 编码器处理可见块(未掩码区域),并采用轻量级 CNN 解码器对所有特征(包括掩码位置)进行完整解码。该架构实现了快速预训练——复杂编码仅作用于较小数据(可见块),而更简单的解码器则处理全部数据(可见特征与掩码标记)。此外,EAT 独特地结合了帧级损失(聚焦潜在表示重建)与话语级损失(面向全局表示预测)。这种简洁的组合使模型能够有效捕捉原始音频数据中的局部细节与整体趋势,显著提升性能。
图1展示了我们的 EAT 模型及其各组件细节,预训练与微调流程如下所述。
3.1 模型架构
带位置编码的块嵌入(Patch Embedding with Positional Encoding)

话语-帧目标(Utterance-Frame Objective, UFO)
EAT 在预训练阶段引入了话语-帧目标(UFO)函数,有效融合了音频表示预测中的全局话语级损失与局部帧级损失。这种双焦点策略是上下文目标预测的重要进步。


预训练中的掩码策略(Masking Strategies in Pre-training)
EAT 模型高效学习音频表示的关键在于其掩码策略。在 EAT 中,块嵌入在送入编码器前采用高达 80% 的掩码率。如此高的掩码率大幅减少了 Transformer 需处理的数据量(类似 MAE 的做法),从而显著提升训练速度。更重要的是,它提高了掩码学习的难度,迫使模型仅凭有限的可见输入从整个音频频谱图中推断出被掩码部分的特征。

3.2 预训练细节
EAT 模型在预训练阶段包含约 9300 万参数,微调阶段(移除 CNN 解码器后)为 8800 万参数,与其他标准 base 规模的音频 SSL 模型参数量相当。我们采用卷积核大小为 (16,16)、步长为 16 的 CNN 编码器对音频频谱图进行下采样,确保在时间和频率维度上提取非重叠的块特征。学生模型与教师模型的编码器均采用 12 层 ViT-B [Dosovitskiy et al., 2020] 结构。为加速解码,EAT 使用一个 6 层二维 CNN 解码器,包含 (3,3) 卷积核、LayerNorm [Ba et al., 2016] 和 GELU 激活函数 [Hendrycks and Gimpel, 2016]。

3.3 微调细节
在微调阶段,EAT 使用学生 Transformer 编码器(共12层)生成潜在表示,并将原始的 CNN 学生解码器替换为一个线性分类层以预测音频类别。此外,我们引入多种数据增强技术,充分挖掘模型在预训练阶段习得的频谱图特征理解能力,这对提升 EAT 在特定下游任务中的领域适应能力至关重要。
微调时采用的音频增强包括:SpecAug [Park et al., 2019]、mixup [Zhang et al., 2017]、droppath [Huang et al., 2016]、音频滚动(audio rolling)以及随机噪声注入。特别地,mixup 直接应用于频谱图,与 EAT 预训练阶段聚焦频谱图潜在表示的设计保持一致。在分类任务中,我们使用 CLS 标记进行最终预测,第 4.3 节的实验表明,该方法优于平均池化(mean pooling)策略。
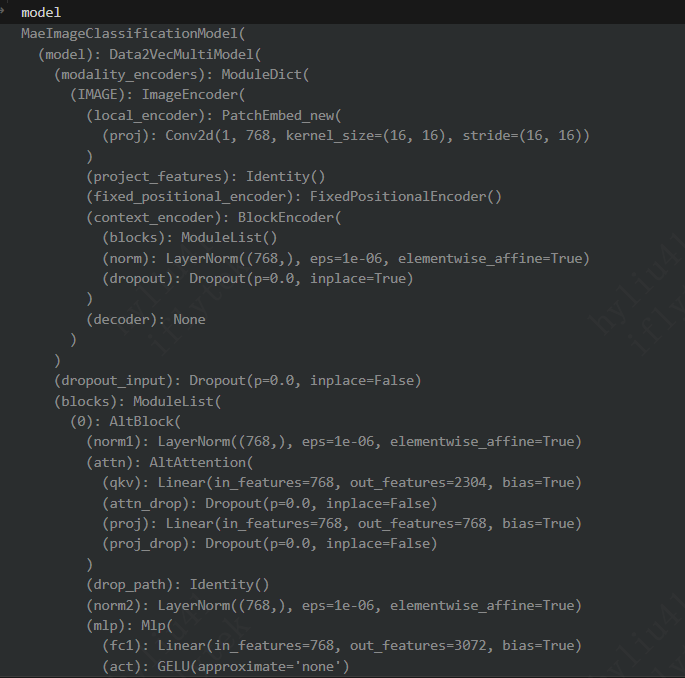
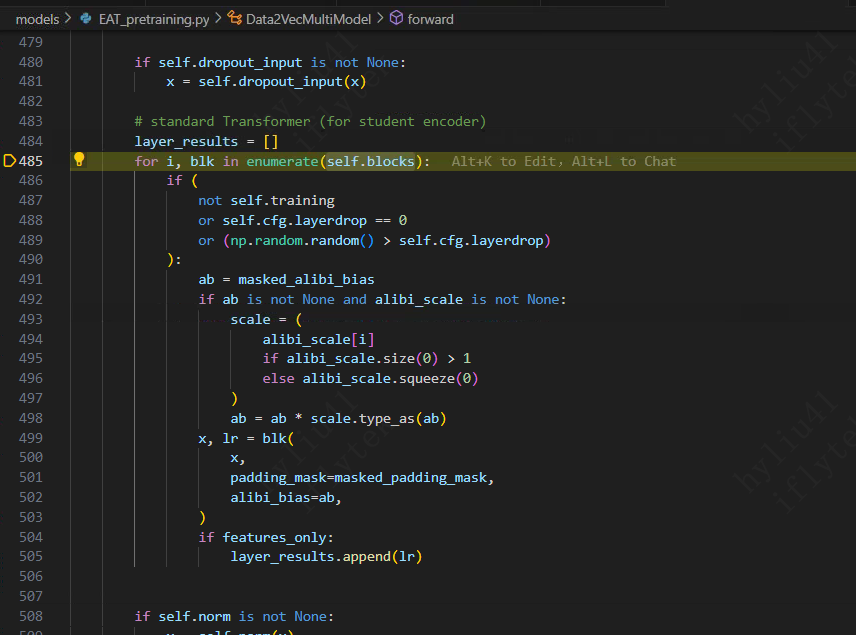
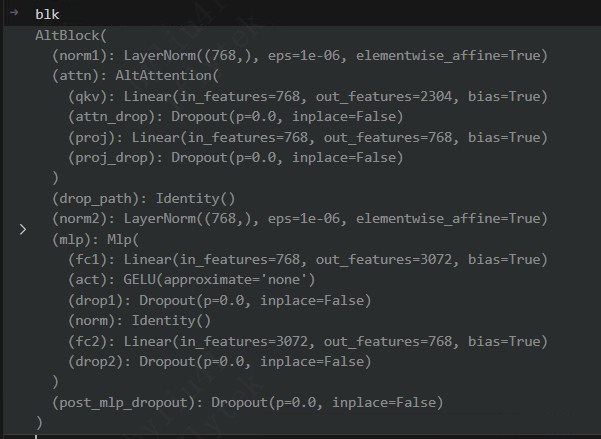
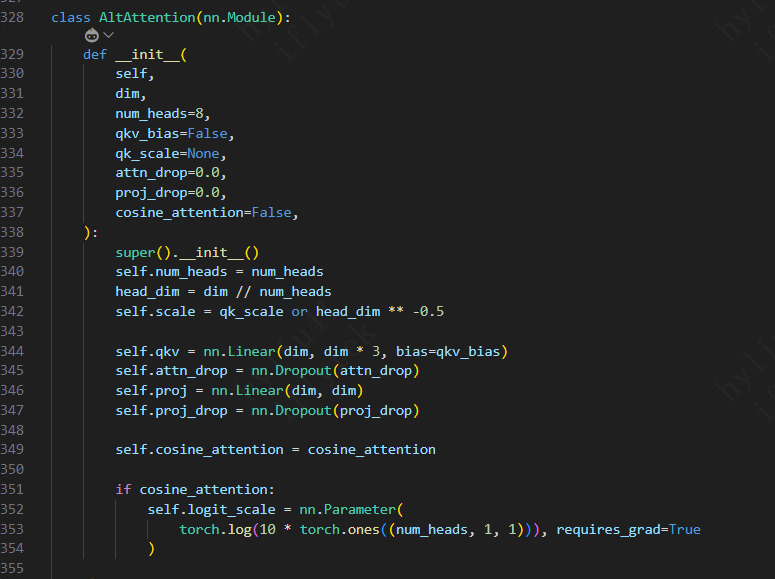
首先进入EAT_pretrain



4 实验
我们在 AudioSet-2M(AS-2M) 数据集 [Gemmeke et al., 2017] 上对 EAT 进行预训练,并通过在 AS-2M、AS-20K 和 环境声音分类(ESC-50) [Piczak, 2015] 数据集上的音频分类微调,以及在 Speech Commands V2(SPC-2) [Warden, 2018] 数据集上的语音分类微调,评估其性能。
4.1 实验设置
AudioSet(AS-2M, AS-20K)
AudioSet 包含约两百万段来自 YouTube 视频的 10 秒音频片段,涵盖 527 个类别。在实验中,我们下载并处理了其中 1,912,134 段作为非平衡集合(AS-2M),20,550 段作为平衡集合(AS-20K),另有 18,884 段用于评估。由于这些片段具有多标签特性,我们采用 平均精度均值(mAP) 作为评测指标,即对所有类别分别计算平均精度后取平均。
环境声音分类(ESC-50)
ESC-50 数据集包含 2,000 段音频,每段时长 5 秒,均匀分布于 50 个语义类别中。我们在评估中采用 五折交叉验证:每折使用 400 段作为验证集,其余用于训练。最终指标为五折验证准确率的平均值。
语音命令 V2(SPC-2)
SPC-2 是一个语音识别中的关键词检测任务,包含 35 个特定语音指令。数据集包括 84,843 条训练录音、9,981 条验证录音和 11,005 条测试录音,每条录音时长 1 秒。我们采用 SUPERB 基准 [Yang et al., 2021] 提供的数据划分进行准确率评估。
训练细节


4.2 主要结果
模型性能
表 1 展示了 EAT 与其他音频模型在 AS-2M、AS-20K、ESC-50 和 SPC-2 数据集上的分类评估结果。我们将对比模型分为有监督预训练和自监督预训练两类。为公平比较,我们的主要基准聚焦于自监督预训练模型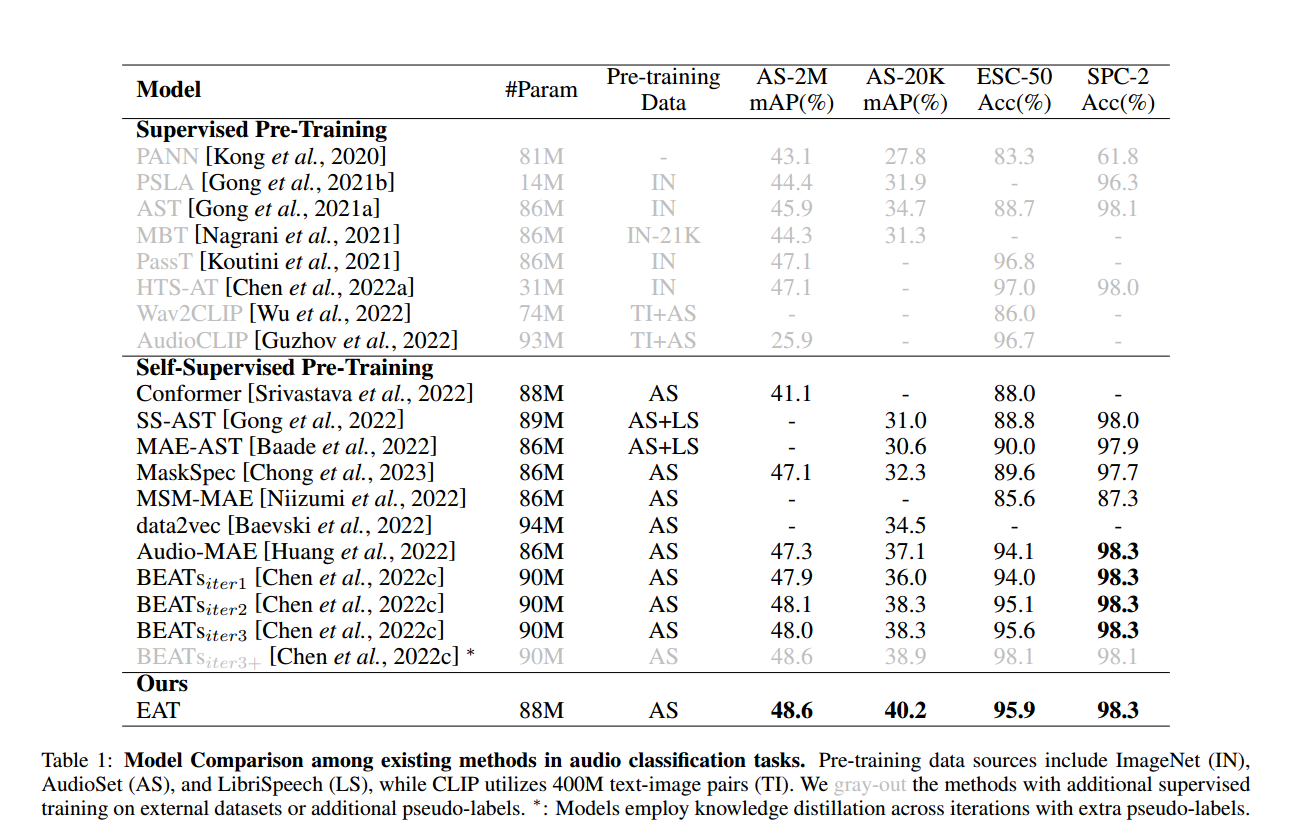
在音频分类任务中,EAT 在 AS-2M、AS-20K 和 ESC-50 上均取得了当前最优(SOTA)性能:
在 AS-2M 上,EAT 达到 48.6% mAP,比此前 SOTA 高出 0.6%;
在 AS-20K 上,EAT 取得 40.2% mAP,超越此前 SOTA 1.9%;
在 ESC-50 上,EAT 实现了 95.9% 的准确率,将平均错误率从 4.4% 降至 4.1%。
这些结果充分证明 EAT 能够高效捕捉并理解音频数据中的全局与局部特征,从而在具有挑战性的音频分类任务中表现卓越。
在语音分类领域,EAT 同样表现出色。尽管我们的主要实验聚焦于通用音频数据,但 EAT 在 SPC-2 语音命令任务中也展现了强大能力,达到了 98.3% 的准确率,与此前 SOTA 模型相当。这凸显了 EAT 的通用性及其在各类音频与语音任务中的广泛适用性。
预训练效率
相比以往 SOTA 的音频自监督学习模型,EAT 在预训练阶段展现出显著更高的效率。如表 2 所示,EAT 仅需 10 个 epoch 的预训练,其总训练时间比 BEATsiter3 缩短 15.65 倍,比 Audio-MAE 缩短 10.02 倍。此外,如图 3 所示,EAT 在仅 2 个 epoch 后就达到 Audio-MAE 的性能水平,并在第 5 个 epoch 时超越 BEATsiter3。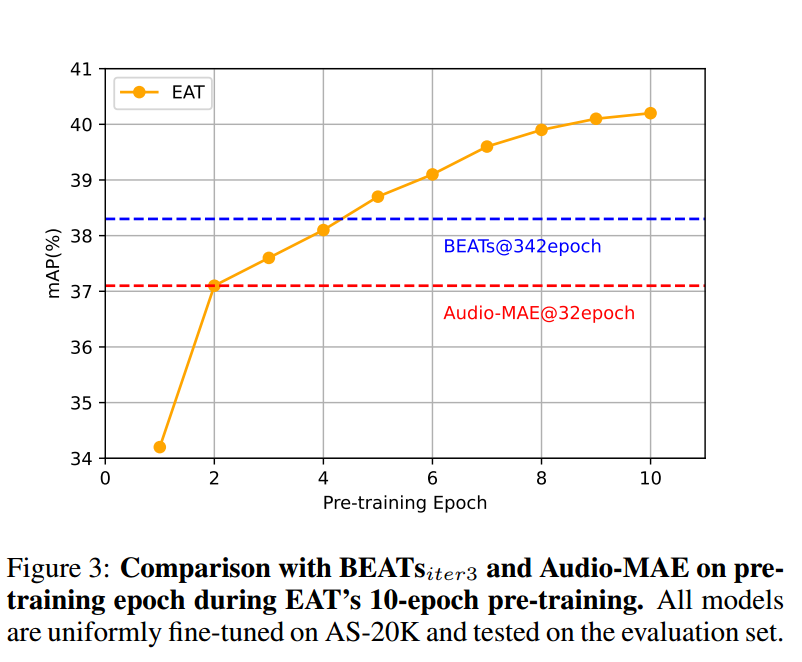
这种大幅提升的训练效率极大降低了计算资源需求,使得高性能基础音频 SSL 模型的预训练变得更加可行。
EAT 的效率优势主要源于两个关键设计:
高掩码率(80%):大量音频数据在送入学生编码器前被掩码,显著减少实际处理的数据量,提升批处理吞吐能力,并充分利用并行计算优势;
话语-帧目标(UFO)函数:不同于传统频谱块重建目标,UFO 仅需轻量解码。因此,EAT 采用轻量级 CNN 解码器进行特征预测,而非像 Audio-MAE 那样使用复杂的 Transformer 解码模块,大幅加速预训练过程。
这一“少而精”的高效训练能力,很大程度上得益于 EAT 在话语-帧联合预训练中采用的多掩码策略:通过对同一音频块嵌入施加多种不同的块掩码,生成多个克隆样本,使模型能从多个视角“聆听”碎片化音频,从而获得比单一视角更全面的理解。尽管每次更新的单个批次输入规模减小,但该策略显著提升了每段音频的数据利用率,从而大幅增强模型效率。
4.3 消融研究
我们进行了全面的消融实验,以评估 EAT 中关键组件的贡献。所有变体均在 AS-2M 上预训练 10 个 epoch,随后在 AS-20K 上微调。
话语级学习的作用
我们通过分析预训练中话语损失权重 λ 的影响,以及微调阶段CLS 标记预测方法的有效性,深入探究了话语级学习的重要性。

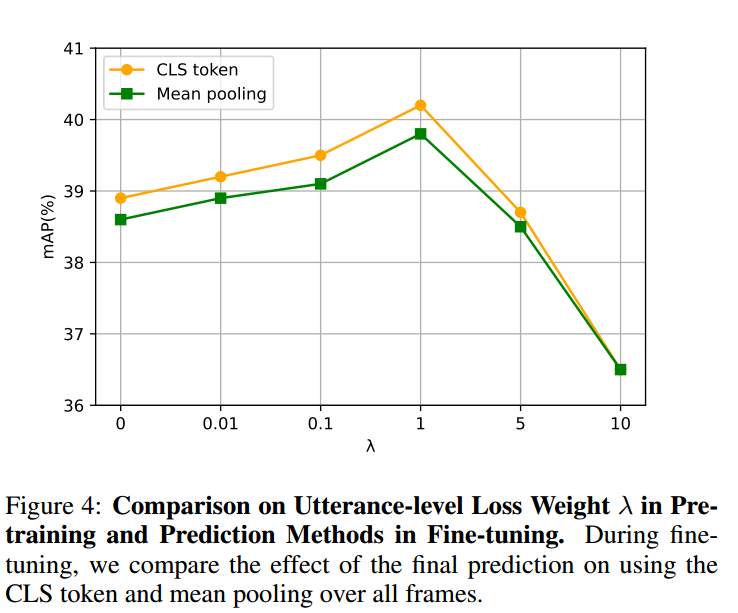
此外,图 4 还显示,使用 CLS 标记进行预测明显优于平均池化(mean pooling) 方法。虽然平均池化(对所有块维度的编码器输出取平均)在许多音频 SSL 模型中效果良好,但 EAT 在预训练中通过增大话语损失权重强化了对全局特征的学习,从而使可学习的 CLS 标记更擅长提取全局信息,进而在分类任务中取得更优表现。
总结:
在预训练中合理设置话语损失权重,有助于 EAT 更关注音频频谱图的全局特征,促进更全面的潜在表示学习;而在微调阶段采用 CLS 标记进行预测,则能有效利用这些全局特征,进一步提升音频分类性能。
音频块上的反向块掩码(Inverse Block Masking on Audio Patches)
在探索预训练阶段掩码策略的影响时,我们观察到 EAT 性能存在显著差异。表 3 显示,相较于随机掩码(块大小 S=1×1),在音频块上采用反向块掩码(块大小 S>1×1)能带来更优性能。特别地,当反向块大小设为 S=5×5 时,EAT 取得了最高的评估 mAP,达到 40.2%。
我们进一步开展了使用灵活块尺寸采样的掩码实验,即在预训练过程中随机保留不同形状的块(如 5×5、6×4、8×3 等)。实验结果与仅使用 5×5 块的情况相近,表明块的形状对性能影响有限。真正起关键作用的是块的尺寸和数量。在固定 80% 掩码率的前提下,适当增大块尺寸(相应减少保留块的总数)对提升模型性能至关重要。
当块尺寸较小时,大量保留的块零散分布在音频频谱图中,使模型更容易推断被掩码部分,从而限制了其对音频表示的深层理解;
相反,使用足够大的块进行反向掩码,能有效降低可见块与被掩码块之间的互信息,迫使模型从更受限的已知信息中学习特征,并更准确地预测未知区域。
5 结论
本文提出了一种高效音频 Transformer(Efficient Audio Transformer, EAT) 模型,用于高效且有效的音频自监督学习。EAT 的突出优势在于大幅加速预训练过程的同时,仍能取得卓越的性能表现。
EAT 设计的核心创新在于引入了话语-帧目标(Utterance-Frame Objective, UFO)损失函数,该方法被证明在学习音频潜在表示方面极为有效:
通过在预训练阶段平衡话语级损失与帧级损失的权重,并结合微调阶段基于 CLS 标记的预测机制,EAT 能够高效捕捉音频的全局语义特征;
在多个音频与语音分类任务(包括 AudioSet、ESC-50 和 SPC-2)上,EAT 均取得了当前最优(SOTA)结果,整体性能超越现有的 base 规模音频自监督学习模型。
此外,EAT 采用高掩码率(80%)下的反向块多掩码策略处理音频频谱块,显著提升了训练效率——其预训练速度比 Audio-MAE 和 BEATs 等模型快十倍以上。
展望未来,我们计划进一步扩展 EAT 的模型规模,以探索其性能上限;同时,我们也将研究音频与语音的联合训练,利用 EAT 模型深入探究这两个领域之间的相互作用与协同潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)