大模型面试必备05——ChatGLM详解
GLM:https://arxiv.org/abs/2103.10360GLM130B: https://arxiv.org/abs/2210.02414 code: https://github.com/THUDM/GLM-130B/Code: https://github.com/THUDM/ChatGLM-6B相关博客参考(按优先级顺序):https://blog.csdn.net/zsq_
一、资料
GLM:https://arxiv.org/abs/2103.10360
GLM130B: https://arxiv.org/abs/2210.02414 code: https://github.com/THUDM/GLM-130B/
Code: https://github.com/THUDM/ChatGLM-6B
相关博客参考(按优先级顺序):
-
https://blog.csdn.net/zsq_csh1/article/details/130908593
-
https://zhuanlan.zhihu.com/p/630134021
-
https://zhuanlan.zhihu.com/p/617115816
二、回顾
(Autoencidong models,encdoer-only结构,仅仅基于编码器)BERT(facebook)的注意力是双向的,可以同时感知上文和下文,因此在自然语言理解任务上表现很好,但是不适合生成任务。训练目标上,BERT的训练目标是对文本进行随机掩码,然后预测被掩码的词。编码器生成适用于自然语言理解任务的上下文化表示,但不能直接应用于文本生成(仅仅用encoder很难做文本生成任务)。
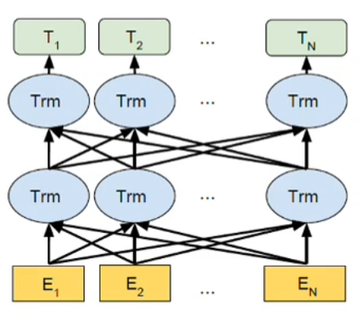
(Autoregressive models,decoder-only结构)GPT (openai)(Radford 等人,2018a)的注意力是单向的,所以无法利用到下文的信息。训练目标上,GPT的训练目标是从左到右的文本生成。虽然它们在长文本生成中取得成功,并在参数规模达到数十亿时展示出少量样本学习能力(Radford 等人,2018b;Brown 等人,2020),但固有的不足是单向注意力机制,它无法充分捕捉 NLU 任务中上下文词之间的依赖关系。(缺点:忽略context的信息)
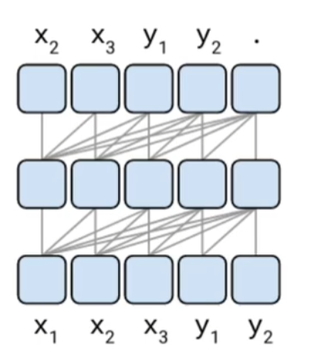
(Encoder-decoder models)T5 (Google) 的编码器中的注意力是双向,解码器中的注意力是单向的,因此可同时应用于自然语言理解任务和生成任务。但T5为了达到和RoBERTa和DeBERTa相似的性能,往往需要更多的参数量。训练目标上,T5则是接受一段文本,从左到右的生成另一段文本(缺点:预测missing token的时候,需要确切的知道缺失token的数量)。
三、GLM目标
上述预训练框架都不够灵活,无法在所有 NLP 任务中表现出竞争力。以前的工作尝试通过多任务学习(Dong 等人,2019;Bao 等人,2020)结合它们的目标来统一不同的框架。然而,由于自编码和自回归目标在本质上是不同的,简单的统一不能充分继承两个框架的优势。
作者提出了一种基于自回归空白填充的预训练框架,名为 GLM(通用语言模型)。我们随机将输入文本中的连续标记范围留空,遵循自编码的思想,并训练模型按照自回归预训练的思想顺序地重构范围(参见图 1)。虽然在 T5(Raffel 等人,2020)中已经使用空白填充进行文本到文本预训练,但我们提出了两种改进,即范围洗牌和二维位置编码。实验证明,在相同的参数和计算成本下,GLM 在 SuperGLUE 基准测试中显著优于 BERT,优势较大,达到 4.6% - 5.0%,并在类似规模的语料库(158GB)上优于 RoBERTa 和 BART。在参数和数据更少的情况下,GLM 还显著优于 T5 在 NLU 和生成任务。
受 Pattern-Exploiting Training(PET)(Schick 和 Schütze,2020a)启发,我们将 NLU 任务重构为模仿人类语言的手工编制的填空题。与 PET 使用的基于 BERT 的模型不同,GLM 可以通过自回归空白填充自然地处理填空问题的多标记答案。
此外,我们表明,通过改变缺失跨度的数量和长度,自回归空白填充目标可以为有条件和无条件生成任务预训练语言模型。通过多任务学习不同的预训练目标,单个 GLM 可以在 NLU 和(有条件和无条件)文本生成任务中表现出色。实证上,与独立基线相比,具有多任务预训练的 GLM 可以在 NLU、有条件文本生成和语言建模任务中共享参数并取得改进。
总之,本文提出了一种名为 GLM(通用语言模型)的预训练框架,它基于自回归空白填充。GLM 结合了自编码和自回归预训练的优点,能够在自然语言理解、有条件生成和无条件生成任务中取得显著的性能提升。GLM 通过多任务学习和参数共享,在各种 NLP 任务中表现出竞争力。
四、模型结构

encoder和decoder的结构,改进点:
1、顺序
预测missing token的时候不关心token的顺序(按照随机顺序预测缺失部分,人类随机看句子的某个局部,也能推导出缺失部分该填什么。)。
2、预测数量
预测每一个missing part的时候,不需要知道缺失的token的数量的(今天的天气真“不错”。今天的天气真“好”,可以补1个词或者2个词,限制模型的补全的数量,可能会限制模型的拓展能力)。GLM在不全每一个missing part的时候, 它是从一个start special token开始的,直到预测到end special token为止. 为了更容易的去做这个事情,GLM提出了一种2D positional encoding的方法(参考图c的Position1和Position2 ,Position1标识的是每个部分在input sequence里面的位置,Position2标识的是每个missing part部分的相对位置)。
3、注意力改进
GLM在Decoder的Self-Attention中移除了斜对角线掩码(即“将Input的Mask全部抹除”),允许模型在预测时看到整个输入序列的所有token(包括未来位置)。
传统的 DECODER 部分的 SELF ATTENTION 长的样子是一个斜对角线,意思是说我们在预测下一个 TOKEN 的时候,只会看到当前 TOKEN 和之前 TOKEN 的信息(GPT做法)。
而这里我们从最右边的图d观察到,GLM把 INPUT SEQUENCE 里的所有的 TOKE,都作为了 DECODER 的 INPUTS 并且是将 INPUT 的 MASK 全部抹除,这样的话是为了方便让后面在预测的时候,可以参考更多 INPUT SEQUENCE 的信息。
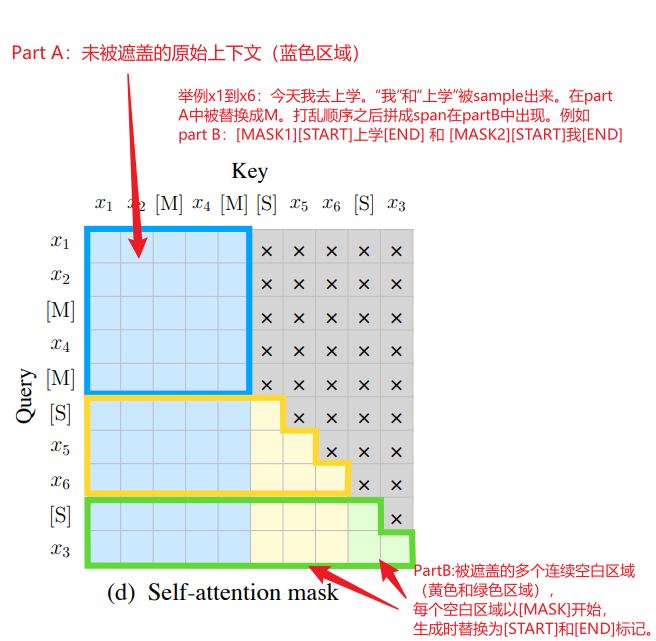
(1) Part A的注意力规则
-
Part A的token可以关注:
-
自身及其他Part A的token(蓝色区域)。
-
不能关注任何Part B的token(灰色区域)。
-
(2) Part B的注意力规则
-
Part B的token可以关注:
-
所有Part A的token(黄色和绿色区域左侧的蓝色部分)。
-
同一空白区域(Span)内之前的token(例如,生成“上学”时,只能看到
[START]和已生成的“上”)。 -
不能关注其他空白区域的token(例如,生成“我”时,不能看到第一个空白区域中的“上学”)。
-
对比传统模型
| 模型 | 注意力掩码设计 | 特点 |
| Transformer Decoder | 严格下三角掩码(仅左侧上下文) | 自回归生成,但无法利用右侧信息 |
| BERT | 完全双向掩码(随机遮盖部分token) | 双向上下文,但非自回归生成 |
| GLM | 分块掩码(Part A双向 + Part B自回归) | 结合双向全局信息与自回归生成能力 |
五、Med-PaLM论文
论文地址:
知识引导的Prompt怎么设计?
-
指令微调(Instruction Tuning)
-
领域对齐:使用医学领域的示例对Flan-PaLM模型进行微调,生成Med-PaLM。这包括调整Prompt模板,使其包含临床术语和任务导向的指令(如“基于临床指南回答以下问题”)。
-
参数高效性:通过少量领域特定示例(如医学问答对)调整模型,而非完全重新训练,确保模型保留通用能力的同时适应医学场景。(用的还是InstructGPT那一套)
-
-
思维链(Chain-of-Thought, CoT)提示
-
逐步推理:在Prompt中要求模型分步骤解释医学逻辑,例如:“请先诊断病因,再列出治疗方案”。这引导模型模拟临床推理过程,增强答案的可解释性。
-
示例引导:在少样本(few-shot)示例中展示完整的推理链条,例如从症状分析到鉴别诊断,再到最终建议。
-
-
结构化知识整合
-
临床指南嵌入:Prompt中融入权威医学知识片段(如“根据WHO指南,XX疾病的诊断标准包括...”),强制模型参考标准化流程。
-
多任务适配:针对不同任务(如多项选择、开放问答)设计差异化Prompt。例如,多项选择题可能强调选项对比,而开放问答需包含风险评估。
-
-
安全性与事实性约束
-
避免危害指令:在Prompt中明确要求模型识别潜在错误或偏见,例如:“如果信息不足,请回答‘不确定’而非猜测”。
-
事实核查机制:通过指令如“引用最新研究支持你的结论”,促使模型依赖可靠来源,减少幻觉(hallucination)。
-
-
少样本学习(Few-shot Learning)
-
领域特定示例:提供医学问答示例,展示如何结合专业知识回答问题。例如,先描述病例特征,再应用诊断标准。
-
多样性覆盖:涵盖不同医学子领域(如内科、外科)和问题类型(如病因、治疗、预后),确保模型泛化能力。
-
六、Triton推理优化
-
学习材料:
- NVIDIA Triton Inference Server Docs
- Optimizing BERT with Triton: Dynamic Batching & Quantization
参考博客:https://blog.csdn.net/qq_21201267/article/details/145760502
https://zhuanlan.zhihu.com/p/661978035
-
NVIDIA Triton官方文档(重点Dynamic Batching)
-
七、生成式模型Token预测机制
参考代码:https://hugging-face.cn/docs/transformers/generation_strategies
目标: 使用Hugging Face实现Beam Search与Top-k Sampling对比(参考官方示例)
中文教程参考:https://huggingface.co/docs/transformers/v4.27.2/zh/quicktour#pipeline
对于不同的任务,需要加载不同的模型
Transformers 提供了一种简单统一的方式来加载预训练的实例. 这表示你可以像加载AutoTokenizer一样加载AutoModel. 唯一不同的地方是为你的任务选择正确的AutoModel. 对于文本 (或序列) 分类, 你应该加载AutoModelForSequenceClassification:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
# 1. 加载匹配的分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
# 2. 预处理文本(检查特殊字符)
texts = [
"We are very happy to show you the 🤗 Transformers library.",
"We hope you don't hate it."
]
# 3. 编码文本并检查ID范围
pt_batch = tokenizer(
texts,
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
)
print(f"Max token ID: {pt_batch['input_ids'].max().item()}") # 应 <=119546
print(f"Tokenizer词汇量: {tokenizer.vocab_size}") # 验证是否为119547
# 4. 运行模型
# 现在可以把预处理好的输入批次直接送进模型. 你只需要添加**来解包字典:
pt_outputs = pt_model(**pt_batch)
print(pt_outputs.logits.shape)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)